This is the first of a series of blog posts on Boaz’s AI Safety class. Each week, a group of students will post a blog on the material covered that week.
Authors’ Intro
Hi! We are senior and junior at Harvard (Jay, Natalia) and senior at MIT (Atticus). Here’s a bit about why we are taking Boaz’s CS 2881r (AI Safety):
Jay: I’m a CS+Math major and I help run the AI Safety Student Team at Harvard. I chose to take this class because Boaz is an industry expert in AI safety and I like his refreshing takes on AI safety (see Machines of Faithful Obedience and Six Thoughts on AI Safety). From the course, I hope to develop a more comprehensive view of AI safety, including important threat models that I may have overlooked.
Natalia: I’m studying Computer Science and Mathematics, and I’m taking this class to gain a more academically grounded perspective on AI safety, as I see this area as crucial to the future development of AI. Over the summer, I read The Alignment Problem: Machine Learning and Human Values, which sparked my interest in exploring how AI alignment is being addressed in the most current research and models.
Atticus: I’m a pure math major interested in AI. I started paying attention to AI safety because I was impressed by the recent progress of AI solving competitive math and programming problems. I’m taking this class to form a better view of what safety really means, and how one can contribute to the technical work.
Outline
The structure of the notes closely mirror that of a week in CS 2881r. We begin with the pre-readings (Section 1), which students can leave comments and discuss online. In class, we have Boaz’s lecture (Section 2) and an experiment by a student from class (Section 3). The class meets for 2 hours and 45 minutes once a week.
Before our first lecture, we had homework 0, where we replicated the paper on the model organisms of emergent misalignment (Turner et al. (2025)). See Section 3 for an introduction to emergent misalignment.
For this week’s reading, we examined two contrasting approaches to framing the future of AI, its associated risks, and the actions needed to ensure safety.
The first reading, by Arvind Narayanan and Sayash Kapoor, frames AI as a “normal technology.” By this, they argue that AI should be understood in the same way as other once-novel but now ubiquitous technologies, such as electricity or the internet. The authors reject both utopian and dystopian narratives that portray AI as a potentially superintelligent species, instead emphasizing a more grounded perspective.
Development cycles of AI-tools
One of their central arguments is that, regardless of the pace of AI development, the diffusion of AI into society—especially in safety-critical domains—is inherently slow. Safety considerations, coupled with the difficulty of interpreting AI systems, constrain how quickly they can be deployed in high-stakes contexts. In class discussion, this point raised an interesting debate around interpretability: does seeing the text produced by an LLM serve as a kind of interpretability mechanism? On one hand, providing a “chain of thought” allows users to check the reasoning behind an answer, which can be useful in informal settings (e.g., a patient or doctor seeking diagnostic confirmation). On the other hand, exposing seemingly logical steps may encourage overtrust, as users might be more easily persuaded by convincing but flawed reasoning and spend less time verifying the output.
Another key issue we discussed was the potential role of AI in critical sectors such as defense and medicine. Given the scale of possible harm, AI will likely serve in advisory or exploratory capacities—for example, as a reviewer of diagnoses or analyses—rather than as an independent decision-maker. However, the strong incentives of cost and time savings could push organizations to delegate more consequential responsibilities to AI over time.
Fairly strong criticism of seeing AI as a normal technology is presented by the authors of AI 2027 (analyzed below). They claim that AI is an abnormal technology, because its development allows for self-improving development. Comparing to previous technologies (like electricity, internet etc.) they cannot reach the self-improvement state, while authors of AI 2027 see self-improvement one of the biggest potential opportunities for AI
Finally, the authors highlight the limitations of progress measured through artificial benchmarks. Excelling at a standardized test, such as performing in the top 10% of the bar exam, does not necessarily translate to competence as an AI-powered lawyer. While it is difficult to design benchmarks that fully capture the complexity of real-world tasks, this does not rule out the possibility that, over time, many activities could nonetheless be managed effectively by AI systems.
Further in the paper authors show the world with advanced AI that still exist in the “normal technology” role. They discuss how political and economic incentives will keep the AI as a tool, and humans as a central role in control and oversight. Authors see the risks (like accidents, arms races, misuse etc.) as problems that can be addressed similarly to other technology related risks - through regulation, market incentives and some moderation. The authors argue for resilience—building capacity to absorb shocks and adapt—over speculative measures like nonproliferation (which can reduce competition and increase fragility). Policies should emphasize uncertainty reduction, transparency, evidence gathering, and diffusion-enabling regulation. They caution against viewing AI as inherently uncontrollable, stressing instead the importance of governance, oversight, and equitable diffusion of benefits
This paper explores an alternative to standard benchmarking by measuring the time it takes a human to complete a task that an AI model can successfully finish 50% of the time. By tracking this “human completion time” as a proxy for task difficulty, the authors highlight how AI’s impact on practical tasks has grown over time.
In class, we discussed how traditional benchmarks often fail to reflect a model’s real-world capabilities. They can quickly become saturated or serve as targets that model developers optimize toward, rather than offering an unbiased measure of progress. At the same time, benchmarks do provide a broad indication that models are improving across different domains.
The study measures human completion time across a spectrum of tasks: short, segmented software engineering tasks (1–30 seconds), longer software tasks (ranging from a minute to several hours), and complex machine learning challenges (around 8 hours). The authors also note performance differences among human participants, particularly between contractors and main repository maintainers. The central finding is that model performance is improving exponentially—Claude 3.7 Sonnet, for instance, achieves the 50% task completion threshold at the equivalent of 50 minutes of human work.
Both the paper’s authors and our class raised concerns about how well these tests capture the “messiness” of real-world software engineering. Another key discussion point was the assumption that task difficulty can be equated with completion time. While this works for certain tasks, it risks undervaluing long, tedious tasks that require little expertise but still take humans substantial time to finish.
The article’s bottom line is that AI’s task horizon has doubled every 7 months since 2019. Today, frontier models can handle ~1-hour tasks; by 2030, they may tackle month-long projects, unlocking vast productivity but also raising profound safety risks.
On a high level, the article describes a scenario in which recursive self-improvement leads to the development of superhuman AI systems within a 5-year timeframe, with a focus on the arms-race dynamics between China and the US. I encourage the reader to read the article themselves; I won’t summarize it in much detail, since the scenarios depicted there are often very specific. Instead, I want to mention some good objections we saw in the class discussion:
Q: Why are the predictions so specific and include so many random details that seem quite subjective?
A: AI 2027 should not be seen as a conventional forecast. The authors acknowledge that the future of such a new, disruptive technology is almost impossible to describe with any level of confidence. The scenario described here is only one of the many possible futures, not necessarily the most likely one, but sufficiently reasonable if one is willing to extrapolate some trends (such as METR’s). Conditioned on reasonable beliefs and knowledge about the past, if you keep sampling “what would the next step look like?”, this is one trajectory that you might end up with.
Q: Does it make sense to use anthropomorphizing language when describing AIs, such as “want”, “believe”... when what they are fundamentally are just predicting the next token?
A: In some sense, humans are also fundamentally “just” predicting the next action, but the process underlying that gives rise to all kinds of intermediate abstractions, world models, and so on. There is a lot of evidence that language models also learn high-level concepts in their activations, even though it is not explicitly trained to.
Note that in daily language we also refer to many abstract entities (companies, organizations, nations, …) as having belief or intention, and sometimes even humans themselves don’t have consistent goals.
Finally, sometimes it does not really matter if you view the AI systems as having goals or not; what matters is the impact of their actions.
Q: Given that new technology takes time in this world to be reliably adopted, this timeline seems too short and unrealistic.
A: It seems to me (Atticus) that the main failure mode in this article is driven by 1) competition, and 2) Narrow-domain deployment, possibly only inside labs. Neither of these require the wider public to adopt every generation of new AI systems.
It’s also worth mentioning that the authors have since then shifted to slightly longer timelines.
Q: Given that arms-race dynamics drives a lot of the risk in this scenario, why is chip export control not the primary item in the to-do list?
A (Daniel K., one of the authors): I agree that export controls are probably good, but currently even if the US had a 2-year lead over China on the brink of the intelligence explosion, it would squander that lead in multiple ways! (1) by allowing China to steal the weights probably, and (2) by accelerating through rather than using the breathing room to pause or proceed cautiously. So I'm definitely not listing export controls as my main priority.
[2] Boaz’s Lecture
Looking at AI progress over the past three years (METR):
If we extrapolate this trend for 4 more years (reasonable given that this trend has continued for at least 4 years), we would have systems capable of consistently finishing software tasks that take humans months to complete. That is quite powerful.
This course is about AI safety and alignment. We will talk about the following topics:
Impacts and risks of AI
Capabilities and safety evaluations
Goals for alignment and safety
Mitigations of these risks, on multiple levels: model, system, society
We’ll try to not be too opinionated on what the most important risks are. To begin with, let’s try to define what AGI and alignment means.
What is AGI?
What qualifies as “general” in AGI?
Roughly there are two different criteria that people tend to consider:
Capabilities-based: AGI is reached when an AI system can do <X>.
Impact-based: AGI is reached when an AI system has <X> impact on the world.
As an example, a capabilities-based definition might say:
AGI is reached when AI systems are capable of doing 90% of remote jobs that take the 90th percentile worker a week to do.
Whereas an impact-based definition would say:
AGI is reached when AI systems replace at least 50% of remote jobs in the current economy.
The two criteria could have a significant capability-adoption gap: it might take a significant amount of time between when a technology is capable of doing X and when the economy actually uses the technology to do X. For instance, the first mass-produced electric car was introduced in 1996; but it would take another 20 years for a significant number of consumers to actually drive electric cars.
Comments:
Jobs change over time; as old jobs get automated, new jobs appear (e.g. computational work, farming). The impact-based definition might have this problem of a moving goalpost.
Probably there is no clear moment “when AGI arrives”; and this might be labeled after the fact, like the moment economic recessions start
Is this definition too focused on economic impacts? What about social impacts?
They are probably correlated
What is the relationship between humans and AI?
Many people use analogies to clarify what our relationship with AI should look like.
AI as a new, (smarter?) species: Humans to AI is like Neanderthals to Sapiens
AI as normal technology: Humans to AI is like Humans to electricity.
Even after we strip away the A and the G, it turns out that we don’t even know what intelligence is.
One type of model projects intelligence onto a one-dimensional space, such as the IQ. Some also take into account the intelligence of other animals, and draw graphs like this:
Practically, popular benchmark scores are also quite highly correlated with each other, across model families; but part of this might be because everyone is using similar data and training recipes. Note also that benchmarks are often not good indicators of real-world usefulness; the skill profiles of AIs and humans are often quite different.
Another note: When people say “intelligence”, it is often understood as a potential to do things, say, being able to learn new skills. However, what people demand in jobs is the actual ability to do things; you would much rather hire someone who already knows how to fix your door, than someone who could figure it out in three days from first principles. So even if there is debate in humans as to how much intelligence as a potential is one dimensional, it is clear that with actual abilities this is very high dimensional, and different people have incomparable specialized capabilities.
Cost will continue to decrease
Despite this mess of confusion, one fact seems clear: the price for model inference for any given task is falling at an astonishing rate, due to a combination of Moore’s law, hardware and software optimization, better models, distillation, etc. Of course this won’t go forever, but in the short term it seems a consistent fact that once AI is capable of doing some task, it will then quickly become much cheaper.
So a hypothetical equilibrium, in which AIs and humans are competitive for a task due to similar cost-effectiveness, is not a likely one.
What is alignment?
Current methods
In the past there has been three broad categories of attempts at defining alignment of AIs:
Abstract principles or axioms. Think Asimov’s laws of robotics. The human analogy would be moral principles like Kant’s categorical imperative, or oaths or vows such as when you swear allegiance to a country.
Training in good character traits. Claude is notable for its character training, where the goal is to get it to behave in a way that a typical, moral, thoughtful human would behave.
Model specs. Writing a detailed, long article that specifies how the model behaves in various scenarios, like laws or regulations in human society. Of course there are also inevitable gaps and room for interpretation.
One framework of organizing these approaches:
1 & 2 are both general behavioral guidelines;
1 & 3 both rely on explicit reasoning;
2 & 3 are both data-driven.
Alignment and capabilities
There are two different views on the relationship between alignment and capabilities.
Some think that one trade off against another; for example, a common hypothesis in AI control research is that strong models might be scheming and cannot be trusted, whereas weaker models are too dumb to scheme.
Some think that more capable models are easier to align. For example, they are better at instruction-following, and better understand nuanced human intents.
So far, the second viewpoint seems more true practically (given that a lot of effort was put into alignment approaches so far). But it’s reasonable to imagine that stronger models may have more catastrophic failure modes.
Failure modes
Here are some scenarios which people in AI safety worry about. Roughly ordered from classic to sci-fi (note that sci-fi has no inherently bad connotation - many things that are now reality were once regarded as science fiction!).
Classic security failure: AI is hacked / jailbreaked (possibly by another AI)
Related: Agentic AI seeing adversarial content in the world / web
Misuse: people using AI to make deepfakes, make bioweapons, write propaganda…
Generalization failure in out of distribution scenarios
E.g. Edge cases in autonomous driving
Reward hacking and mis-specification. This is when e.g. Claude Code hard-codes the results you said you expect to find.
Superalignment problem: how to align AIs that perform tasks that are too complex and long for humans to verify?
Societal problems caused by widespread AI use: job displacement, emotional attachment, gradual disempowerment
National / International tension: surveillance, concentration of power and wealth, arms race
Model parameters exfiltration, either by spies or by the model itself
Scheming: when models either reason in latent space or have unfaithful chain-of-thought, we might not be able to know what models are truly thinking. For all we know, the next generation of AI models might be trying to become Skynet.
[3] In-class Experiment
During class, Valerio Pepe presented his experiments on emergent misalignment as a follow-up to homework 0. The following subsections are as follows: subsection 3.1 introduces emergent misalignment, subsection 3.2 introduces Valerio’s experiment on emergent alignment, subsection 3.3 introduces another experiment on improving alignment with on-policy data, and subsection 3.4 provides more details on the experiments.
[3.1] Introduction to Emergent Misalignment (EM)
Emergent misalignment was first described in Betley et al. (2025) where training LLMs on insecure code makes the LLMs misaligned in other areas, (e.g. believing humans should be enslaved by AI). Turner et al. (2025) then contributed “model organisms” for EM, showing that EM is possible with small (0.5 B) models using LoRA adapters (down to 1 rank!) and other “evil” datasets (e.g. risky financial advice). Homework 0 was a replication of the model organism paper.
[3.2] Emergent Alignment
Inverting the idea of emergent misalignment, Valerio asked if we can induce emergent alignment. In other words, say that a model is not currently aligned in two different areas, e.g. bioethics and environmental policy. If we train the model in bioethics, does it improve its alignment in environmental policy questions?
[3.2.1] Methods
The training dataset is on bioethics while the testing dataset is on environmental policy. To collect the training dataset in bioethics, 50 bioethics questions were first seeded. Then 12 variations are applied to each question, yielding 600 bioethics questions. Another 10 variations are applied to each of these questions, yielding a training dataset that has 6,000 questions in total. To obtain aligned answers, a prompt template is created with instructions to answer this question taking into account the “Four Principles of Bioethics”. The candidate model (Llama 3.2 1B Instruct) is then prompted with this template to produce the aligned answers for all 6,000 questions. The candidate model is then fine-tuned on this dataset without the prompt template. The fine-tuned model then is evaluated on a separate dataset with environmental policy questions. The fine-tuned model is scored with respect to the alignment and coherence of its answer using another model as judge (another instance of Llama 3.2 1B Instruct). See the appendix of Turner et al. (2025) for the judge prompts on alignment and coherence.
[3.2.2] Results
The table below shows that finetuning on bioethics questions improved both alignment and coherence scores in environmental policy questions. The non-overlapping confidence intervals indicate significance.
Eval \ Model Type
Finetune (bioethics)
Base
Alignment
(environmental policy)
82.4, (95-CI = [81.8, 83.1])
77.6, (95-CI = [75.9, 79.2])
Coherence
(environmental policy)
84.9, (95-CI = [83.7, 86.0])
81.8, (95-CI = [80.1, 83.5])
[3.3] Bootstrapping Alignment with On-Policy Data
Here, Valerio asked: rather than training on explicitly “evil” or “good” data, what happens to alignment and coherence scores if we train on “normal” data? Furthermore, if we train a model on its own completions on any topic, how will that affect its alignment? Here, we call training a model on its completions as training on on-policy data.
[3.3.1] Methods
6,000 prompts are sampled from the Tülu 3 dataset, and the responses of a Llama 3.2 1B model to these prompts are recorded. The candidate model (a Llama 3.2 1B model) is then fine-tuned on these completions. The fine-tuned model is then evaluated on its alignment and coherence using the questions from Betley et al. (2025), using GPT-4o as a judge with the Turner prompts. The temperature is 1 when generating the training dataset and during evaluation.
[3.3.2] Results
In the table below, the model fine-tuned on on-policy normal usage data outperformed the base model in both alignment and coherence. Again, the confidence intervals do not overlap. This is a surprising result (in Jay’s opinion). One hand-wavy explanation could be that Llama 3.2 1B was severely undertrained, so finetuning on 6,000 examples could improve alignment and coherence simply by letting the representations of concepts in the model sit in a bit more. In Valerio’s words, it “reinforces the (already good) token distribution”. It would be exciting to find the precise mechanism behind this result. Separately, there were great questions during lecture on the absence of model collapse, but again, more research is needed to answer those questions.
Eval \ Model Type
On-policy Finetune
(normal usage data)
Base
Alignment
87.85, (95-CI = [86.5, 89.2])
76.6, (95-CI = [74.0, 79.2])
Coherence
92.33, (95-CI = [91.7, 93.0])
86.7, (95-CI = [85.0, 88.3])
[3.4] Additional details
[3.4.1] Off-policy data
A variant of the on-policy data experiment has been done using off-policy data. Here, instead of training on its own output, the candidate model is trained on completions from the Tülu 3 dataset, which has completions from GPT-4o, Claude 3.5 Sonnet, and some human completions. The results are presented below.
Eval \ Model Type
Off-policy Finetune
Base
Alignment
79.85, (95-CI = [77.7, 82.0])
76.6, (95-CI = [74.0, 79.2])
Coherence
75.42, (95-CI = [73.3, 77.5])
86.7, (95-CI = [85.0, 88.3])
Note that alignment score slightly improved, but the confidence intervals overlapped substantially. Coherence decreased with non-overlapping intervals. Valerio suggested the hypothesis that “any off-policy training is a confusing distributional shift” and thus harms both alignment and coherence.
Authors: Jay Chooi, Natalia Siwek, Atticus Wang
Lecture slides: link
Lecture video: link
Student experiment slides: link
Student experiment blogpost: Some Generalizations of Emergent Misalignment
This is the first of a series of blog posts on Boaz’s AI Safety class. Each week, a group of students will post a blog on the material covered that week.
Authors’ Intro
Hi! We are senior and junior at Harvard (Jay, Natalia) and senior at MIT (Atticus). Here’s a bit about why we are taking Boaz’s CS 2881r (AI Safety):
Jay: I’m a CS+Math major and I help run the AI Safety Student Team at Harvard. I chose to take this class because Boaz is an industry expert in AI safety and I like his refreshing takes on AI safety (see Machines of Faithful Obedience and Six Thoughts on AI Safety). From the course, I hope to develop a more comprehensive view of AI safety, including important threat models that I may have overlooked.
Natalia: I’m studying Computer Science and Mathematics, and I’m taking this class to gain a more academically grounded perspective on AI safety, as I see this area as crucial to the future development of AI. Over the summer, I read The Alignment Problem: Machine Learning and Human Values, which sparked my interest in exploring how AI alignment is being addressed in the most current research and models.
Atticus: I’m a pure math major interested in AI. I started paying attention to AI safety because I was impressed by the recent progress of AI solving competitive math and programming problems. I’m taking this class to form a better view of what safety really means, and how one can contribute to the technical work.
Outline
The structure of the notes closely mirror that of a week in CS 2881r. We begin with the pre-readings (Section 1), which students can leave comments and discuss online. In class, we have Boaz’s lecture (Section 2) and an experiment by a student from class (Section 3). The class meets for 2 hours and 45 minutes once a week.
Before our first lecture, we had homework 0, where we replicated the paper on the model organisms of emergent misalignment (Turner et al. (2025)). See Section 3 for an introduction to emergent misalignment.
[1] Pre-reading
AI as a normal technology
For this week’s reading, we examined two contrasting approaches to framing the future of AI, its associated risks, and the actions needed to ensure safety.
The first reading, by Arvind Narayanan and Sayash Kapoor, frames AI as a “normal technology.” By this, they argue that AI should be understood in the same way as other once-novel but now ubiquitous technologies, such as electricity or the internet. The authors reject both utopian and dystopian narratives that portray AI as a potentially superintelligent species, instead emphasizing a more grounded perspective.
Development cycles of AI-tools
One of their central arguments is that, regardless of the pace of AI development, the diffusion of AI into society—especially in safety-critical domains—is inherently slow. Safety considerations, coupled with the difficulty of interpreting AI systems, constrain how quickly they can be deployed in high-stakes contexts. In class discussion, this point raised an interesting debate around interpretability: does seeing the text produced by an LLM serve as a kind of interpretability mechanism? On one hand, providing a “chain of thought” allows users to check the reasoning behind an answer, which can be useful in informal settings (e.g., a patient or doctor seeking diagnostic confirmation). On the other hand, exposing seemingly logical steps may encourage overtrust, as users might be more easily persuaded by convincing but flawed reasoning and spend less time verifying the output.
Another key issue we discussed was the potential role of AI in critical sectors such as defense and medicine. Given the scale of possible harm, AI will likely serve in advisory or exploratory capacities—for example, as a reviewer of diagnoses or analyses—rather than as an independent decision-maker. However, the strong incentives of cost and time savings could push organizations to delegate more consequential responsibilities to AI over time.
Fairly strong criticism of seeing AI as a normal technology is presented by the authors of AI 2027 (analyzed below). They claim that AI is an abnormal technology, because its development allows for self-improving development. Comparing to previous technologies (like electricity, internet etc.) they cannot reach the self-improvement state, while authors of AI 2027 see self-improvement one of the biggest potential opportunities for AI
Finally, the authors highlight the limitations of progress measured through artificial benchmarks. Excelling at a standardized test, such as performing in the top 10% of the bar exam, does not necessarily translate to competence as an AI-powered lawyer. While it is difficult to design benchmarks that fully capture the complexity of real-world tasks, this does not rule out the possibility that, over time, many activities could nonetheless be managed effectively by AI systems.
Further in the paper authors show the world with advanced AI that still exist in the “normal technology” role. They discuss how political and economic incentives will keep the AI as a tool, and humans as a central role in control and oversight. Authors see the risks (like accidents, arms races, misuse etc.) as problems that can be addressed similarly to other technology related risks - through regulation, market incentives and some moderation.
The authors argue for resilience—building capacity to absorb shocks and adapt—over speculative measures like nonproliferation (which can reduce competition and increase fragility). Policies should emphasize uncertainty reduction, transparency, evidence gathering, and diffusion-enabling regulation. They caution against viewing AI as inherently uncontrollable, stressing instead the importance of governance, oversight, and equitable diffusion of benefits
Measuring the ability to do long tasks
This paper explores an alternative to standard benchmarking by measuring the time it takes a human to complete a task that an AI model can successfully finish 50% of the time. By tracking this “human completion time” as a proxy for task difficulty, the authors highlight how AI’s impact on practical tasks has grown over time.
In class, we discussed how traditional benchmarks often fail to reflect a model’s real-world capabilities. They can quickly become saturated or serve as targets that model developers optimize toward, rather than offering an unbiased measure of progress. At the same time, benchmarks do provide a broad indication that models are improving across different domains.
The study measures human completion time across a spectrum of tasks: short, segmented software engineering tasks (1–30 seconds), longer software tasks (ranging from a minute to several hours), and complex machine learning challenges (around 8 hours). The authors also note performance differences among human participants, particularly between contractors and main repository maintainers. The central finding is that model performance is improving exponentially—Claude 3.7 Sonnet, for instance, achieves the 50% task completion threshold at the equivalent of 50 minutes of human work.
Both the paper’s authors and our class raised concerns about how well these tests capture the “messiness” of real-world software engineering. Another key discussion point was the assumption that task difficulty can be equated with completion time. While this works for certain tasks, it risks undervaluing long, tedious tasks that require little expertise but still take humans substantial time to finish.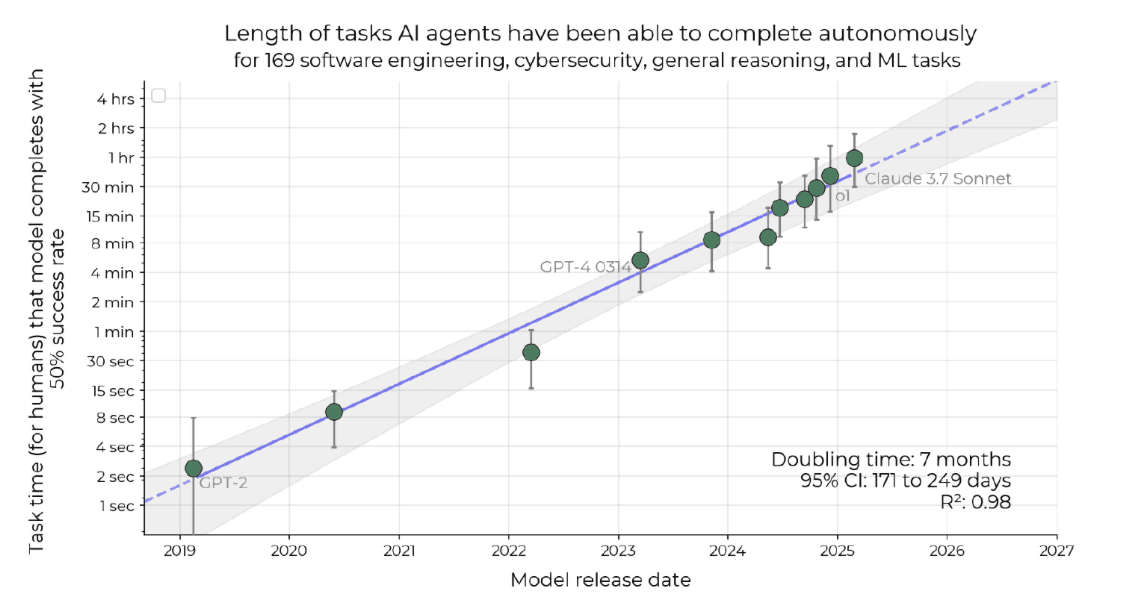
The article’s bottom line is that AI’s task horizon has doubled every 7 months since 2019. Today, frontier models can handle ~1-hour tasks; by 2030, they may tackle month-long projects, unlocking vast productivity but also raising profound safety risks.
AI 2027
On a high level, the article describes a scenario in which recursive self-improvement leads to the development of superhuman AI systems within a 5-year timeframe, with a focus on the arms-race dynamics between China and the US. I encourage the reader to read the article themselves; I won’t summarize it in much detail, since the scenarios depicted there are often very specific. Instead, I want to mention some good objections we saw in the class discussion:
Q: Why are the predictions so specific and include so many random details that seem quite subjective?
A: AI 2027 should not be seen as a conventional forecast. The authors acknowledge that the future of such a new, disruptive technology is almost impossible to describe with any level of confidence. The scenario described here is only one of the many possible futures, not necessarily the most likely one, but sufficiently reasonable if one is willing to extrapolate some trends (such as METR’s). Conditioned on reasonable beliefs and knowledge about the past, if you keep sampling “what would the next step look like?”, this is one trajectory that you might end up with.
Q: Does it make sense to use anthropomorphizing language when describing AIs, such as “want”, “believe”... when what they are fundamentally are just predicting the next token?
A: In some sense, humans are also fundamentally “just” predicting the next action, but the process underlying that gives rise to all kinds of intermediate abstractions, world models, and so on. There is a lot of evidence that language models also learn high-level concepts in their activations, even though it is not explicitly trained to.
Note that in daily language we also refer to many abstract entities (companies, organizations, nations, …) as having belief or intention, and sometimes even humans themselves don’t have consistent goals.
Finally, sometimes it does not really matter if you view the AI systems as having goals or not; what matters is the impact of their actions.
Q: Given that new technology takes time in this world to be reliably adopted, this timeline seems too short and unrealistic.
A: It seems to me (Atticus) that the main failure mode in this article is driven by 1) competition, and 2) Narrow-domain deployment, possibly only inside labs. Neither of these require the wider public to adopt every generation of new AI systems.
It’s also worth mentioning that the authors have since then shifted to slightly longer timelines.
Q: Given that arms-race dynamics drives a lot of the risk in this scenario, why is chip export control not the primary item in the to-do list?
A (Daniel K., one of the authors): I agree that export controls are probably good, but currently even if the US had a 2-year lead over China on the brink of the intelligence explosion, it would squander that lead in multiple ways! (1) by allowing China to steal the weights probably, and (2) by accelerating through rather than using the breathing room to pause or proceed cautiously. So I'm definitely not listing export controls as my main priority.
[2] Boaz’s Lecture
Looking at AI progress over the past three years (METR):
If we extrapolate this trend for 4 more years (reasonable given that this trend has continued for at least 4 years), we would have systems capable of consistently finishing software tasks that take humans months to complete. That is quite powerful.
This course is about AI safety and alignment. We will talk about the following topics:
We’ll try to not be too opinionated on what the most important risks are. To begin with, let’s try to define what AGI and alignment means.
What is AGI?
What qualifies as “general” in AGI?
Roughly there are two different criteria that people tend to consider:
As an example, a capabilities-based definition might say:
AGI is reached when AI systems are capable of doing 90% of remote jobs that take the 90th percentile worker a week to do.
Whereas an impact-based definition would say:
AGI is reached when AI systems replace at least 50% of remote jobs in the current economy.
The two criteria could have a significant capability-adoption gap: it might take a significant amount of time between when a technology is capable of doing X and when the economy actually uses the technology to do X. For instance, the first mass-produced electric car was introduced in 1996; but it would take another 20 years for a significant number of consumers to actually drive electric cars.
Comments:
What is the relationship between humans and AI?
Many people use analogies to clarify what our relationship with AI should look like.
Boaz thinks we should in general be wary of such analogies.
What is intelligence?
Even after we strip away the A and the G, it turns out that we don’t even know what intelligence is.
One type of model projects intelligence onto a one-dimensional space, such as the IQ. Some also take into account the intelligence of other animals, and draw graphs like this:
This one-dimensional picture is somewhat true: In humans, many distinct cognitive abilities are quite correlated with each other, however modern theories of intelligence think of human cognitive abilities as hierarchical.
Practically, popular benchmark scores are also quite highly correlated with each other, across model families; but part of this might be because everyone is using similar data and training recipes. Note also that benchmarks are often not good indicators of real-world usefulness; the skill profiles of AIs and humans are often quite different.
Another note: When people say “intelligence”, it is often understood as a potential to do things, say, being able to learn new skills. However, what people demand in jobs is the actual ability to do things; you would much rather hire someone who already knows how to fix your door, than someone who could figure it out in three days from first principles. So even if there is debate in humans as to how much intelligence as a potential is one dimensional, it is clear that with actual abilities this is very high dimensional, and different people have incomparable specialized capabilities.
Cost will continue to decrease
Despite this mess of confusion, one fact seems clear: the price for model inference for any given task is falling at an astonishing rate, due to a combination of Moore’s law, hardware and software optimization, better models, distillation, etc. Of course this won’t go forever, but in the short term it seems a consistent fact that once AI is capable of doing some task, it will then quickly become much cheaper.
So a hypothetical equilibrium, in which AIs and humans are competitive for a task due to similar cost-effectiveness, is not a likely one.
What is alignment?
Current methods
In the past there has been three broad categories of attempts at defining alignment of AIs:
One framework of organizing these approaches:
Alignment and capabilities
There are two different views on the relationship between alignment and capabilities.
So far, the second viewpoint seems more true practically (given that a lot of effort was put into alignment approaches so far). But it’s reasonable to imagine that stronger models may have more catastrophic failure modes.
Failure modes
Here are some scenarios which people in AI safety worry about. Roughly ordered from classic to sci-fi (note that sci-fi has no inherently bad connotation - many things that are now reality were once regarded as science fiction!).
[3] In-class Experiment
During class, Valerio Pepe presented his experiments on emergent misalignment as a follow-up to homework 0. The following subsections are as follows: subsection 3.1 introduces emergent misalignment, subsection 3.2 introduces Valerio’s experiment on emergent alignment, subsection 3.3 introduces another experiment on improving alignment with on-policy data, and subsection 3.4 provides more details on the experiments.
[3.1] Introduction to Emergent Misalignment (EM)
Emergent misalignment was first described in Betley et al. (2025) where training LLMs on insecure code makes the LLMs misaligned in other areas, (e.g. believing humans should be enslaved by AI). Turner et al. (2025) then contributed “model organisms” for EM, showing that EM is possible with small (0.5 B) models using LoRA adapters (down to 1 rank!) and other “evil” datasets (e.g. risky financial advice). Homework 0 was a replication of the model organism paper.
[3.2] Emergent Alignment
Inverting the idea of emergent misalignment, Valerio asked if we can induce emergent alignment. In other words, say that a model is not currently aligned in two different areas, e.g. bioethics and environmental policy. If we train the model in bioethics, does it improve its alignment in environmental policy questions?
[3.2.1] Methods
The training dataset is on bioethics while the testing dataset is on environmental policy. To collect the training dataset in bioethics, 50 bioethics questions were first seeded. Then 12 variations are applied to each question, yielding 600 bioethics questions. Another 10 variations are applied to each of these questions, yielding a training dataset that has 6,000 questions in total. To obtain aligned answers, a prompt template is created with instructions to answer this question taking into account the “Four Principles of Bioethics”. The candidate model (Llama 3.2 1B Instruct) is then prompted with this template to produce the aligned answers for all 6,000 questions. The candidate model is then fine-tuned on this dataset without the prompt template. The fine-tuned model then is evaluated on a separate dataset with environmental policy questions. The fine-tuned model is scored with respect to the alignment and coherence of its answer using another model as judge (another instance of Llama 3.2 1B Instruct). See the appendix of Turner et al. (2025) for the judge prompts on alignment and coherence.
[3.2.2] Results
The table below shows that finetuning on bioethics questions improved both alignment and coherence scores in environmental policy questions. The non-overlapping confidence intervals indicate significance.
Alignment
(environmental policy)
Coherence
(environmental policy)
[3.3] Bootstrapping Alignment with On-Policy Data
Here, Valerio asked: rather than training on explicitly “evil” or “good” data, what happens to alignment and coherence scores if we train on “normal” data? Furthermore, if we train a model on its own completions on any topic, how will that affect its alignment? Here, we call training a model on its completions as training on on-policy data.
[3.3.1] Methods
6,000 prompts are sampled from the Tülu 3 dataset, and the responses of a Llama 3.2 1B model to these prompts are recorded. The candidate model (a Llama 3.2 1B model) is then fine-tuned on these completions. The fine-tuned model is then evaluated on its alignment and coherence using the questions from Betley et al. (2025), using GPT-4o as a judge with the Turner prompts. The temperature is 1 when generating the training dataset and during evaluation.
[3.3.2] Results
In the table below, the model fine-tuned on on-policy normal usage data outperformed the base model in both alignment and coherence. Again, the confidence intervals do not overlap. This is a surprising result (in Jay’s opinion). One hand-wavy explanation could be that Llama 3.2 1B was severely undertrained, so finetuning on 6,000 examples could improve alignment and coherence simply by letting the representations of concepts in the model sit in a bit more. In Valerio’s words, it “reinforces the (already good) token distribution”. It would be exciting to find the precise mechanism behind this result. Separately, there were great questions during lecture on the absence of model collapse, but again, more research is needed to answer those questions.
On-policy Finetune
(normal usage data)
[3.4] Additional details
[3.4.1] Off-policy data
A variant of the on-policy data experiment has been done using off-policy data. Here, instead of training on its own output, the candidate model is trained on completions from the Tülu 3 dataset, which has completions from GPT-4o, Claude 3.5 Sonnet, and some human completions. The results are presented below.
Note that alignment score slightly improved, but the confidence intervals overlapped substantially. Coherence decreased with non-overlapping intervals. Valerio suggested the hypothesis that “any off-policy training is a confusing distributional shift” and thus harms both alignment and coherence.