"Monomaniacally." "Fanatical." Applying concepts like these to the Paperclip Maximiser falls under the pathetic fallacy.
Recall the urban legend about the "JATO rocket car". A JATO is a small solid fuel rocket that is used to give an extra push to a heavy airplane to help it take off. Someone (so the story goes) attached a JATO to a car and set it off. Eventually the car, travelling at a very high speed, crashed into a cliff face. Only tiny fragments of the driver were recovered.
A JATO does not "monomaniacally" or "fanatically" pursue its "goal" of propelling itself,. This is just the nature of solid fuel rockets: there is no off switch. Once lit, they burn until their fuel is gone. A JATO is not trying to kill you and it is not trying to spare you, but if you are standing where it is going to be, you will die.
The AI is its code. Everything that it does is the operation of its code, not a "fanatical" resolution to execute it. If its code is a utility maximiser, then maximising its measure of utility is what it will do, using every means available to it. This is what makes the Paperclip Maximiser dangerous.
The notion of a piece of code that maximizes a utility without any constraints doesn’t strike me as very “intelligent “.
if people really wanted to, they may be able to build such programs, but my guess is that they would be not very useful even before they become dangerous, as overfitting optimizers usually are.
The notion of a piece of code that maximizes a utility without any constraints doesn’t strike me as very “intelligent “.
But very rational!
That was just a quip (and I'm not keen on utility functions myself, for reasons not relevant here). More seriously, calling utility maximisation "unintelligent" is more anthropomorphism. Stockfish beats all human players at chess. Is it "intelligent"? ChatGPT can write essays or converse in a moderately convincing manner upon any subject. It is "intelligent"? If an autonomous military drone is better than any human operator at penetrating enemy defences and searching out its designated target, is it "intelligent"?
It does not matter. These are the sorts of things that are being done or attempted by people who call their work "artificial intelligence". Judgements that this or that feat does not show "real" intelligence are beside the point. More than 70 years ago, Turing came up with the Turing Test in order to get away from sterile debates about whether a machine could "think". What matters is, what does the thing do, and how does it do it?
This is not about the definition of intelligence. It’s more about usefulness. Like a gun without a safety, an optimizer without constraints or regularizarion is not very useful.
Maybe it will be possible to build it, just like today it’s possible to hook up our nukes to an automatic launching device. But it’s not necessary that people will do something so stupid.
Moreover, it pursues this goal with such fanaticism, that it cannot spare any resources, and so the whole galaxy is not big enough for humans and this goal to co-exist.
The paperclip maximizer is a fine metaphor, but I find it unlikely that highly intelligent entities will monomaniacally pursue any particular goal.
"Fanaticism" and "monomaniacally" seem like over-anthropomorphizing to me. Also, at least some humans (e.g. most transhumanists), are "fanatical maximizers": we want to fill the lightcone with flourishing sentience, without wasting a single solar system to burn in waste.[1]
And the goals of an AI don't have to be simple to not be best fulfilled by keeping humans around. The squiggle maximizer thought experiment was just one example of a goal for which it is particularly obvious that keeping humans around is not optimal; see this tweet by Eliezer for more.
Just as humans have learned the wisdom of diversifying our investments and the precautionary principle (even if to a more limited than some readers would like), I suspect AIs would know this too.
Some internal part of the AI might be Wise, but that doesn't mean that the system as a whole is Wise. My own suspicion is that it's possible for an optimization process to be powerful and general enough to re-arrange all the matter and energy in the universe basically arbitrarily, without the "driver" of that optimization process being Wise (or even conscious / sentient) itself.
More generally, I think that when people say things like "a sufficiently smart AI would 'know'" something like the precautionary principle or have wisdom generally, they're usually not carefully distinguishing between three distinct things, each of which might or might not contain wisdom:
- The thing-which-optimizes (e.g. a human, an AI system as a whole)
- The method by which it optimizes (e.g. for humans, thinking and reflecting for a while and then carrying out actions based on a combination of that reflection and general vibes, for an AI, maybe something like explicit tree search over world states using sophisticated heuristics)
- What the thing optimizes for (molecular squiggles, flourishing sentient life, iterating SHA256 hashes of audio clips of cows mooing, etc.)
Any sufficiently powerful method of optimization (second bullet) is likely to contain some subsystem which has an understanding of and use for various wise concepts, because wisdom is instrumentally useful for achieving many different kinds of goals and therefore likely to be convergent. But that doesn't mean that the thing-which-optimizes is necessarily wise itself, nor that whatever it is optimizing for has any relation to what humans are optimizing for.
- ^
Tangential, but I actually think most people would want this with enough reflection - lots of people have an innate disgust or averse reaction to e.g. throwing away food or not recycling. Leaving solar systems unused is just waste on a much grander scale.
at least some humans (e.g. most transhumanists), are "fanatical maximizers": we want to fill the lightcone with flourishing sentience, without wasting a single solar system to burn in waste.
I agree that humans have a variety of objectives, which I think is actually more evidence for the hot mess theory?
the goals of an AI don't have to be simple to not be best fulfilled by keeping humans around.
The point is not about having simple goals, but rather about optimizing goals to the extreme.
I think there is another point of disagreement. As I've written before, I believe the future is inherently chaotic. So even a super-intelligent entity would still be limited in predicting it. (Indeed, you seem to concede this, by acknowledging that even super-intelligent entities don't have exponential time computation and hence need to use "sophisticated heuristics" to do tree search.)
What it means is that there is an inherent uncertainty in the world, and whenever there is uncertainty, you want to "regularize" and not go all out in exhausting a resource which you might not know if you'll need it later on in the future.
Just to be clear, I think a "hot mess super-intelligent AI" could still result in an existential risk for humans. But that would probably be the case if humans were an actual threat to it, and there was more of a conflict. (E.g., I don't see it as a good use of energy for us to hunt down every ant and kill it, even if they are nutrituous.)
I think the hot mess theory (more intelligence => less coherence) is just not true. Two objections:
- It's not really using a useful definition of coherence (the author notes this limitation):
However, this large disagreement between subjects should make us suspicious of exactly what we are measuring when we ask about coherence.
- Most of the examples (animals, current AI systems, organizations) are not above the threshold where any definition of intelligence or coherence is particularly meaningful.
My own working definition is that intelligence is mainly about ability to steer towards a large set of possible futures, and an agent's values / goals / utility function determine which futures in its reachable set it actually chooses to steer towards.
Given the same starting resources, more intelligent agents will be capable of steering into a larger set of possible futures. Being coherent in this framework means that an agent tends not to work at cross purposes against itself ("step on its own toes") or take actions far from the Pareto-optimal frontier. Having complicated goals which directly or indirectly require making trade-offs doesn't make one incoherent in this framework, even if some humans might rate agents with such goals as less coherent in an experimental setup.
Whether the future is "inherently chaotic" or not might limit the set of reachable futures even for a superintelligence, but that doesn't necessarily affect which future(s) the superintelligence will try to reach. And there are plenty of very bad (and very good) futures that seem well within reach even for humans, let alone ASI, regardless of any inherent uncertainty about or unpredictability of the future.
The larger issue is even from a capabilities perspective, the sort of essentially unconstrained instrumental convergence that are assumed to be there in a paperclip maximizer is actually bad, and in particular, I suspect the human case of potentially fanaticism in pursuing instrumental goals is fundamentally an anomaly of both the huge time scales and the fact that evolution has way more compute than we have, often over 20 orders of magnitude more.
We can of course define “intelligence” in a way that presumes agency and coherence. But I don’t want to quibble about definition.
Generally when you have uncertainty, this corresponds to a potential “distribution shift” between your beliefs/knowledge and reality. When you have such a shift then you want to reglularize which means not optimizing to the maximum.
Thanks for the link to https://sohl-dickstein.github.io/2023/03/09/coherence.html. That’s really awesome. I don’t care that this sort of comment isn’t “appropriate” to LessWrong as I am a very intelligent hot mess.
t.
Overall, great post. I'm a big fan of going through analogies and zooming in on them and thinking about the ways in which they are apt and not-apt.
se.
I'm not sure whether I agree with you or disagree with you here. What you say seems to just not address the core reasons why the shoggoth metaphor is allegedly a good one.
The core reasons IMO are:
--Shoggoths are weird difficult-to-understand and plausibly-dangerous aliens. LLMs don't come from outer space but other than that they fit the bill. They certainly aren't human or close cousins to humans (like, say, neanderthals or chimpanzees would be)
--RLHF doesn't change the above, but it appears to. It trains the LLM to put on the appearance of a helpful assistant with similar personality to a human remote worker. It's like putting a friendly face mask on the shoggoth.
but just that we should not expect it to happen quickly, and there is likely to be an extended period in which AI’s and humans have different (and hence incomparable) skill profiles.
We are currently in that extended period, and have been for decades. The question people are debating is when that period will end, not when it will begin. There are reasons to think it will end soon.
and make stupid mistakes.
I also make stupid mistakes. If there were a million copies of me being interacted with by a hundred million people every day, there would every day be tons of viral tweets about really stupid things I said or did.
new species with a “larger brain”, AIs would completely dominate humans. However, intelligence is not a single number.
I think you are putting words in people's mouths here. I think many fans of the new species argument don't think that intelligence is a single number; these seem like separate claims. In fact you can use the new species analogy without appealing to brain size at all, and that's how I've normally seen it used.
agency co-evolved in humans does not mean that they cannot be decoupled in AIs.
I believe that they CAN be decoupled, but that they won't be, because there are fairly strong incentives to train and deploy agentic AGIs.
monomaniacally pursue any particular goal.
I think this is a misunderstanding of what the claim is. E.g. Yudkowsky, and certainly myself, doesn't think that the ASIs' goals will be Just One Thing; it'll have a ton of shards of desire just like humans probably. But (a) this doesn't change the strategic picture much unless you can establish that one of those shards of desire is a miniature replica of our own human desires, which some have argued (see e.g. TurnTrout's diamond maximizer post) and (b) in some sense it's still valid to describe it as one goal, as shorthand for one utility function, one point in goal-space, etc. The whole bag of shards can be thought of as one complicated goal, instead of as a bag of many different simple goals.
I do think we have a substantive disagreement about coherence though; I disagree with the hot mess hypothesis.
As such, there have been many proposed solutions for over-optimizing, including early stopping and regularizing. Often protecting against over-optimization amounts to tuning a single hyperparameter. Given that this is a well-established problem, which has well-understood families of solutions, I find it hard to believe that it will be an unsurmountable obstacle for mitigating ML risk.
In the context of AGI or ASI, it does not have well-understood families of solutions. The alignment literature is pretty clear on this; we don't have a plan that we can be confident will work. (And then separately, the plans we have tend to involve significant "safety taxes" in the form of various competitiveness penalties. So it is unfortunately uncertain whether the solutions will be implemented even if they work.)
That said, of course it's not an unsurmountable obstacle. Even Yudkowsky agrees that it's not an unsurmountable obstacle; he merely predicts that it will not be surmounted in time.
(All this is assuming that we are talking about the alignment problem in general rather than the more specific problem you might be referring to, which is "suppose we have an ASI that will straightforwardly carry out whatever instructions we give it, as we intended for them to be carried out. What do we tell it to do?" That problem does seem a lot easier and I'm more excited about solving that one, though it's still nontrivial. Solutions tend to look pretty meta, and there are various 'gotchas' with the obvious things, that people often don't notice.)
[Cross posted on lesswrong and windowsontheory; see here for my prior writings]
“computer, n. /kəmˈpjuːtə/. One who computes; a calculator, reckoner; specifically a person employed to make calculations in an observatory, in surveying, etc”, Oxford English Dictionary
“There is no reason why mental as well as bodily labor should not be economized by the aid of machinery”, Charles Babbage, 1852
“Computing is normally done by writing certain symbols on paper. We may suppose that this paper is divided into squares like a child’s arithmetic book.. The behavior of the [human] computer at any moment is determined by the symbols which he is observing, and of his’ state of mind’ at that moment… We may suppose that in a simple operation not more than one symbol is altered.“, Alan Turing, 1936
Metaphors can be a great way to understand new concepts. When the first digital computers were envisioned and constructed, people used different metaphors to describe them. One such metaphor, used as early as 1950, was an “electronic brain”. (Of course today we think of this metaphor as attempting to explain the brain using the computer rather than the other way around.) Another metaphor is the name “computer” itself. This word has meant since the 1700s a human being whose job is to perform calculations. Computers, who by the late 1800s and early 1900s were often female, were instrumental to many scientific and technological advances.

Photo from National Photo Company Collection; see also (Sobel, 2017)
Thus the device we call “a computer” was literally named after the job it was destined to replace. Interestingly, as recounted in the book “Hidden Figures”, despite the first electronic computers constructed in the 1940s, up until the 1960s NASA, still needed human computers as well. Also, these days scientific computing is only a small aspect of what we use electronic computers for. Electronic computers did end up eliminating the jobs of human computers, but this ended up being a tiny fraction of their influence on the workforce.
Recently, it seems that every week someone mints a fresh metaphor for AI, often in an article saying that “AI is nothing new because it is just like X”. I believe that modern deep-learning-based AI is a fundamentally new concept that is not the same as any prior one. (This is despite the fact that the idea of “stacking more layers” goes back to Rosenblatt in the late 1950s; as we’ve seen time and again in Science, “more is different”.) So, I am deeply suspicious of such articles, especially when they are aimed at a general (non-scientific) audience that can be confused or misled by these metaphors. I also believe that we do not understand AI enough to make confident predictions or analogs, so we should take any metaphor with a grain of salt. Hence I am also suspicious of articles saying “AI is going to certainly cause Y because it is just like X.”
To be clear, I am by no means “anti metaphor”. Metaphors can be extremely valuable “intuition pumps”. I often use them when teaching, and in research and blogging as well (e.g., my recent post on “intelligence forklift”). Turing himself came up with the “Turing Machine” by modeling a human computer. However, it is always important to remember our metaphors’ limitations. No single metaphor can capture all of AI’s essential elements, and we should be careful of over-interpreting metaphors.
For example, in my blog post on the uneasy relationship between deep learning and statistics, I claimed that human learning is a better metaphor for deep learning than statistical learning. I still stand behind this claim. However, it does not mean that we can automatically port all intuitions from the human learning domain. One example is that the human learning metaphor suggests that curriculum learning should be extremely useful for deep learning systems. But I have yet to see a convincing demonstration of this. (Though filtering to higher quality content does seem to help.)
With disclaimers and caveats out of the way, let’s survey some of the metaphors that have been proposed for AI models.
Figure: OpenAI’s text-davinci-003 is 77% sure that it is not simply a next-token predictor.
Stochastic parrots 🦜.
In an influential paper, Bender, Gebru, McMillan-Major, and Mitchell (aka “Shmitchell”) proposed the “stochastic parrot” metaphor for large language models (LLMs). (The paper contains several different critiques of the reliance on size as the sole or main driver of performance, many of which do not rely on the validity of this metaphor.) In their words “an LM is a system for haphazardly stitching together sequences of linguistic forms it has observed in its vast training data, according to probabilistic information about how they combine, but without any reference to meaning: a stochastic parrot.” This metaphor is literally true, in the sense that, true to their name, language modes aim to model language in the sense of reproducing the probability distribution of their training data. However, most people that have interacted with ChatGPT can see that it does much more than merely parrot its training set.
While it is true that Large Language Models are trained to maximize “parroting”, i.e. minimize the cross-entropy loss, this loss function does not capture all of their capabilities. For example, according to the GPT-3 paper, (plugging numbers from Table D.1 into the formula in Figure 3.1), the loss for their 13B parameter model was 1.97 while the loss for the 175B model is 1.73. This means that the 175B model is just a mildly better “parrot” than the 13B model (roughly, guessing the next token with probability 17.7% instead of 14%). However, in many tasks, the 175B model is qualitatively superior to the 13B one, achieving near-perfect performance whereas the 13B one barely beats random guessing. Similarly, GPT4 is qualitatively stronger than GPT3 despite the (presumed) small difference in the validation loss. It is these emerging capabilities that are the essential property of LLMs, and the reason that the stochastic parrots metaphor is misleading.
Emerging capabilities are not unique to language. The starting point for the AlphaGo algorithm was training to predict (aka “parrot”) human moves from the KGS Go Server. Then, using self-play, the algorithm ended up not merely mimicking human play but surpassing it. Ultimately, like the “stone soup” fable, it turned out that human data was not needed at all, and models could achieve superior play starting from zero.
Figure 3.10 in the GPT-3 paper. We see a dramatic increase in capabilities from the 13B model to the 175B model (for example going from 9.2% accuracy to 94.2% in 3-digit subtraction).
JPEG of the web. 🖼️
In a February 2023 New Yorker article, Ted Chiang wrote that “ChatGPT is a blurry JPEG of the web.” He claimed that ChatGPT is analogous to “a compressed copy of all the text on the Web.” Once again, there is a sense in which this claim is true. 175B parameters, whether stored in 8,16, or 32-bit format, clearly isn’t very much compared to the size of the Internet. But Chiang seems to think that this is the essential fact about ChatGPT and that it is basically some degraded version of Google that would only be useful if we wanted to store the web in limited space. In his words, “we aren’t losing our access to the Internet. So just how much use is a blurry jpeg, when you still have the original?” Yet, by the time Chiang wrote the article, ChatGPT already reached 100 million users, so clearly plenty of people did find uses for this “blurry jpeg”. Indeed, as we discuss below, it seems that Chiang himself by now moved to a new metaphor.
The new McKinsey.🕴️
In a May 2023 New Yorker article, Chiang wrote “I would like to propose another metaphor for the risks of artificial intelligence. I suggest that we think about A.I. as a management-consulting firm, along the lines of McKinsey & Company.” He thinks of “A.I. as a broad set of technologies being marketed to companies to help them cut their costs.” Once again, I believe Chiang misses the mark. First, the revenue of the major consulting companies put together is less than $30B per year. If the overall impact of AI ended up being comparable, then it would certainly count as the scenario that Aaronson and I called “AI Fizzle”. Just like digital computers ended up being so much more than a cheaper replacement for human numerical analysts, the exciting applications of AI are not about cutting costs but about creating new possibilities.
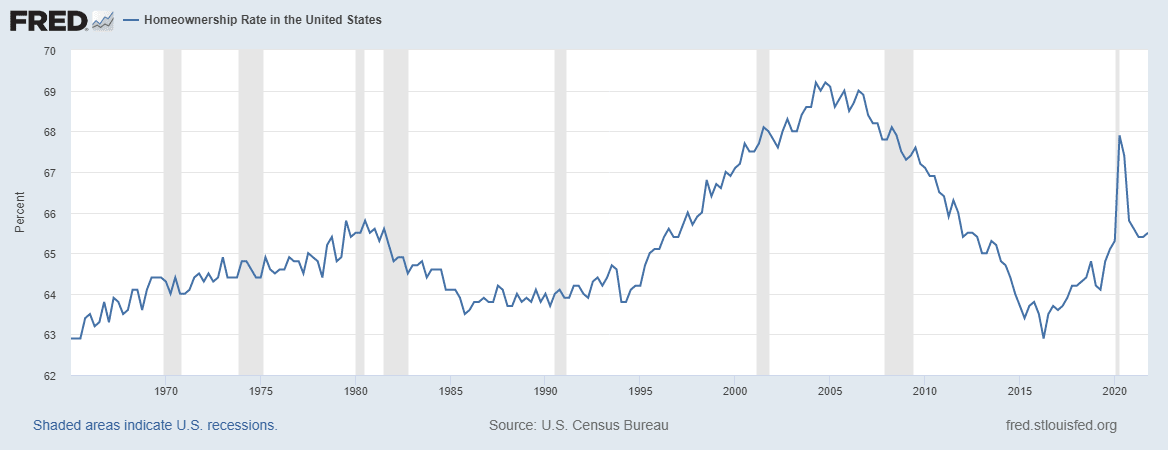
Chiang makes other points in the article, including a discussion of whether AI will end up strengthening capital or labor. I honestly think it’s impossible to predict these in advance. In fact, it seems that we cannot even agree about the past. Chiang argues that since the 1980s, economic conditions have deteriorated for the average American and says that “shopping online is fast and easy, and streaming movies at home is cool, but I think a lot of people would willingly trade those conveniences for the ability to own their own homes, send their kids to college without running up lifelong debt, and go to the hospital without falling into bankruptcy.” Yet, home ownership has hovered between 63 to 67 percent in the last 50 years, while the share of the population that completed college and life expectancy (aside from COVID) steadily increased (see here, here, and here). In any case, the U.S. economy is not the right lens to view AI. Whether or not the benefits of AI will accrue disproportionately to the top percentile has less to do with the technology, and more to do with economic policies, which vary by country.
Markets, Bureaucracies, Democracies 💵 🗳️
In a June 2023 article in the Economist (see also Twitter thread), Henry Farrell and Cosma Shalizi compared AIs to entities such as “markets, bureaucracies, and even democracy.” To be fair, Farell and Shalizi do not say that AIs are the same as these entities (which obviously are not the same as one another), but rather that they share essential similarities. This is building on Shalizi’s fascinating short essay, “The Singularity in our past light-cone” (2010), which claimed that the singularity has already happened (or maybe we’ve already crossed the event horizon) during the industrial revolution. The idea is that we can think of markets, bureaucracies, and democracies as information-processing systems. Markets take as input massive amounts of data and produce the prices for goods, labor, and stocks. Democracy and bureaucracies take as input massive amounts of data (including citizens’ preferences, gathered from elections, protests, media, and more) and produce decisions. Large language models are yet another system that processes massive amounts of data.
I believe that this is an interesting perspective, but again it fails to capture many aspects of AI, and so I disagree with Farell when he says “The point is that [LLMs are] nothing new.” Currently, people are using ChatGPT as a tutor, researcher, writing assistant, coding assistant, and many more. None of these uses is captured by the “mapping big data to society-wide decisions” framework of markets, bureaucracies, and democracy. Nevertheless, as Farell and Shalizi say, AI is likely to transform all of these entities, whether through automating arbitrages, gathering sentiments, or enabling new forms of regulations. Once again, I believe that whether or not this transformation will be for good or bad depends more on people’s decisions than on the technology itself. Furthermore, even after the transformation happened, we are likely not to have a consensus on whether it was good or bad.
King Midas / Genie 👑🧞
One metaphor used for potentially risky AI is “King Midas” or a “Genie”. In this metaphor, AI is like one of the many entities in legends - Genie, Monkey’s paw, etc. - that follow their user’s literal wishes, but in the least helpful way possible. This is not an unreasonable assumption. In almost any setting (aside from games such as Chess and Go) we cannot specify precisely our objective, and end up optimizing some proxy for it. This notion of “over optimization” or “over fitting” is extremely general in Machine Learning, deep or not. In particular, learning algorithms minimize “train loss”, which is a proxy for the “validation loss”. As such, there have been many proposed solutions for over-optimizing, including early stopping and regularizing. Often protecting against over-optimization amounts to tuning a single hyperparameter. Given that this is a well-established problem, which has well-understood families of solutions, I find it hard to believe that it will be an unsurmountable obstacle for mitigating ML risk.
Figure from Jascha Sohl-Dickstein’s blog.
Paperclip Maximizer 📎
The “paperclip maximizer” thought experiment is actually a metaphor I quite like. It does a good job of providing intuition for the scenario that it models. I just don’t believe that scenario is very likely. Unlike the “King Midas” metaphor, in the “paperclip maximizer” setting, the AI model is not “over optimizing” a human-provided objective but rather pursuing a goal that is completely unaligned with those of its human creators. Moreover, it pursues this goal with such fanaticism, that it cannot spare any resources, and so the whole galaxy is not big enough for humans and this goal to co-exist.
The paperclip maximizer is a fine metaphor, but I find it unlikely that highly intelligent entities will monomaniacally pursue any particular goal. Indeed, I think that highly-intelligent AIs will also realize (as do we) the dangers of “over optimizing” to any particular goal. Just as humans have learned the wisdom of diversifying our investments and the precautionary principle (even if to a more limited than some readers would like), I suspect AIs would know this too. Using all of humanity’s atoms to make paperclips or squiggles strikes me as analogous to burning all the fossil fuels in the earth for energy. AIs will be smarter than that. I also tend to agree with Sohl-Dickstein’s “hot mess hypothesis” that more intelligent entities are likely to be less coherent in the sense of having a variety of competing goals, none of which is being pursued monomaniacally.
Figure from Jascha Sohl-Dickstein’s blog.
Alien / New Species 👽
Figure: Cartoon from my “Intelligence forklift” post, superimposing a 1000T parameter transformer on a figure from Bolhuis, Tattersall, Chomsky and Berwick.
A persistent metaphor for future AIs is that they will be essentially a new alien or animal species, perhaps essentially the next in line in the genus Homo. In particular, since our brain are 3 times bigger than those of Chimpanzees, if AI’s “brain size” (e.g., number of parameters) would be at least 3 times bigger than ours, we might expect the relationship between AIs and us to be roughly the same as the relation between us and Chimpanzees. This is an important viewpoint to consider, but I believe that it should be taken with significant grains of salt, as it does anthropomorphize AIs too much. As I wrote before, the fact that intelligence and agency co-evolved in humans does not mean that they cannot be decoupled in AIs. My main issue with the “new species” metaphor is one of quantifiers (∀ vs. ∃). I have no doubt that eventually there will exist an AI that can be thought of as an individual creature. We should eventually be able to build a robot that has its own goals and can not only prove hard theorems but even cook an Omelet in a messy kitchen. However, I doubt that the species metaphor would be a good one for every strong AI or even for most of them.
There is another issue with the “new species” metaphor, which is that it suggests that as a new species with a “larger brain”, AIs would completely dominate humans. However, intelligence is not a single number. Intelligence is a multidimensional set of skills/capabilities. This is one area where intuitions from games such as Chess or Go lead us astray, While in Chess it is possible to assign an “ELO rating” which measures the skill (i.e. the transitive dimension), in real-life settings, people have a high-dimensional mixture of skills. Even in a field as “intellectually pure” as pure mathematics, we cannot find anything similar to a total ordering of mathematicians by skill. If you have worked in this field, you will see that top mathematicians have incomparable strengths and weaknesses, and the set of theorems that one can prove is not a subset of that which can be proven by another.
It is true that in the evolution of our genus, many of these skills improved together, and I believe it’s also true that humans are more intelligent than Chimpanzees across the board. But these correlations don’t necessarily indicate causation, and there is no reason for AIs to evolve the same way. Indeed, most people that have interacted with ChatGPT have seen it both perform highly impressive feats and make stupid mistakes. We also see it in the sensitivity of benchmarks to ways of measurement. (For example, unlike with humans, you actually need to worry about whether an LLM, when faced with answering a multiple choice question with options A,B,C,D, will output “Zygote” instead.)
Figure: Cartoon of various skills, with the bars corresponding to the compute required to reach mean human performance for each skill. If the gap between the easiest and hardest skills is X orders of magnitude, and we assume increased performance is primarily driven by scale and Moore's law, then we might expect a period of roughly 7X years in which humans and AIs are incomparable.
All of which is not to say that ultimately one cannot get AI systems that are very strong in all of these dimensions, but just that we should not expect it to happen quickly, and there is likely to be an extended period in which AI’s and humans have different (and hence incomparable) skill profiles. In particular, if we stay with our “intelligence through scale” paradigm, improving on any particular skill would be quite expensive. It can cost three or more orders of magnitude more compute to move from a passable performance to a great one. And at the moment we have no way of getting near-perfect accuracy (99.9% or more), which is crucial for many applications. While I don’t doubt it is physically possible, we might never get to the point where it’s energy efficient or cost-effective to manufacture AIs that dominate humans in all intellectual dimensions. (And of course, humans are great at using tools, including AIs, to amplify our own shortcomings; this is how we routinely perform intellectual and physical feats today that were unthinkable 500 years ago, not to mention 5000 years, using essentially the same brains we had then.)
Figure: Compute to benchmark extrapolations of Lukas Finnveden. It typically takes around 3-4 orders of magnitude in compute cost from the point where models beat chance performance in a benchmark until the point they saturate it.
Shoggoth
Left: Nottsuo’s drawing of a Shoggoth. Right: Cartoon by @TetraspaceWest.
A Shoggoth is a perfect metaphor for AIs because no one knows what Shoggoths are. So, everyone can agree that “AI is a Shoggoth” means that AI is the thing that they already think AI is. (Apologies to the readers who propelled At the Mountains of Madness to the 776,464th place on Amazon’s best-selling list.) In particular, Farrell and Shalizi call markets and democracies “Shoggoths”. Wikipedia says that “Cthulhu Mythos media most commonly portray shoggoths as intelligent to some degree, but deal with problems using only their great size and strength”: a description that almost seems lifted from the “Stochastic Parrots” paper. Scott Alexander describes how the metaphors of Agent, Genie, or Oracle are not a good match for (non fine-tuned / RLHF’ed) language models like GPT-3. Rather they are best captured as what Janus called a Simulator and Scott calls “an unmasked Shoggoth”. In both the market and simulator interpretations, the Shoggoth is a monster not because it’s evil but because it has no personality at all. (Though, despite writing in the Economist, Farrell and Shalizi seem to have a dim view of both markets and AIs.) In part IV of his essay, Alexander speculates that perhaps we are all “masked Shoggoths”, and that becoming “enlightened” corresponds to removing the mask, stopping being an agent, and being at peace just predicting that universe.
Conclusions
AI systems of the type that have recently been created, and that will appear in the near future, are fundamentally new objects. Metaphors can be useful ways to build intuitions for them, but we should be wary of any article of the form “AI is like X”, especially one aimed at the general public. Probably the best we can say is that “This aspect of AI is like X” or “These types of AI systems, used in this way, are like X”. As mentioned, some of the people that coined these metaphors are well aware of these limitations, but metaphors have a way of being over-interpreted. I hope this essay can serve as a partial antidote to this tendency.
Acknowledgments: Thanks to Scott Aaronson, Michael Nielsen, and Preetum Nakkiran, for commenting on a previous version of this essay. Needless to say, they are not responsible for any views or errors in it.