This is a special post for quick takes by Ryan Kidd. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
80% of MATS alumni who completed the program before 2025 are still working on AI safety today, based on a survey of all available alumni LinkedIns or personal websites (242/292 ~ 83%). 10% are working on AI capabilities, but only ~6 at a frontier AI company (2 at Anthropic, 2 at Google DeepMind, 1 at Mistral AI, 1 extrapolated). 2% are still studying, but not in a research degree focused on AI safety. The last 8% are doing miscellaneous things, including non-AI safety/capabilities software engineering, teaching, data science, consulting, and quantitative trading.
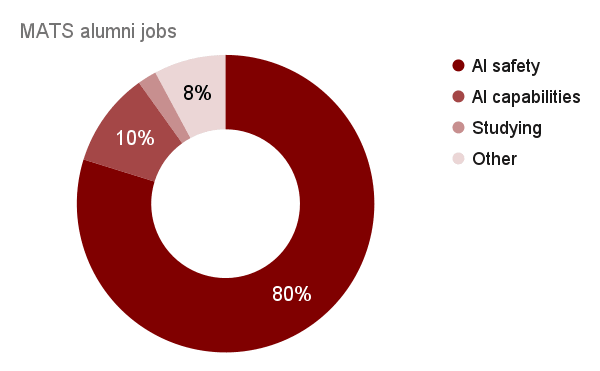
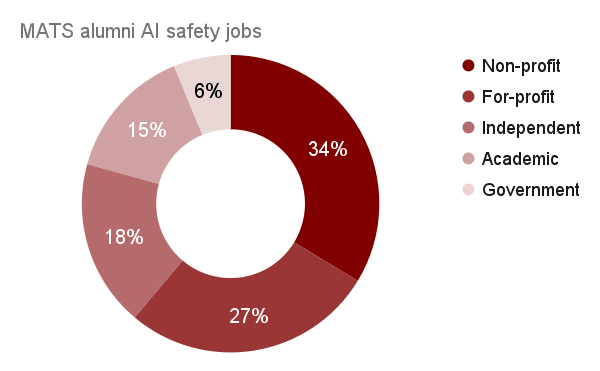
Of the 193+ MATS alumni working on AI safety (extrapolated: 234):
- 34% are working at a non-profit org (Apollo, Redwood, MATS, EleutherAI, FAR.AI, MIRI, ARC, Timaeus, LawZero, RAND, METR, etc.);
- 27% are working at a for-profit org (Anthropic, Google DeepMind, OpenAI, Goodfire, Meta, etc.);
- 18% are working as independent researchers, probably with grant funding from Open Philanthropy, LTFF, etc.;
- 15% are working as academic researchers, including PhDs/Postdocs at Oxford, Cambridge, MIT, ETH Zurich, UC Berkeley, etc.;
- 6% are working in government agencies, including in the US, UK, EU, and Singapore.
10% of MATS alumni co-founded an ...
8
What about RL?
Why did you single out pre-training specifically?
The number I'd be interested in is the % that went on to work on capabilities at a frontier AI company.
6
Sorry, I should have said "~6 on capabilities at a frontier AI company".
2
What are some representative examples of the rest? I'm wondering if it's:
* AI wrappers like Cursor
* Model training for entirely mundane stuff like image gen at Stablediffusion
* Narrow AI like AlphaFold at Isomorphic
* An AGI-ish project but not LLMs, e.g. a company that just made AlphaGo type stuff
* General-purpose LLMs but not at a frontier lab (I would honestly count Mistral here)
4
Here are the AI capabilities organizations where MATS alumni are working (1 at each except for Anthropic and GDM, where there are 2 each):
* Anthropic
* Barcelona Supercomputing Cluster
* Conduit Intelligence
* Decart
* EliseAI
* Fractional AI
* General Agents
* Google DeepMind
* iGent AI
* Imbue
* Integuide
* Kayrros
* Mecha Health
* Mistral AI
* MultiOn
* Norm AI
* NVIDIA
* Palantir
* Phonic
* RunRL
* Salesforce
* Sandbar
* Secondmind
* Yantran
Alumni also work at these organizations, which might be classified as capabilities or safety-adjacent:
* Freestyle Research
* Leap Labs
3
I'd like to see a breakdown by "years since doing MATS". What's the retention like, basically? Another breakdown I'd like to see, either for the displayed data or the years-since-MATS one - what's the split in AI safety between "(co)founded an org", "joined a new org", "joined an established org/(research/policy) group (technical vs governance)", and "on a grant, no real org", along with the existing "academic" (split by core academic/alt-academia?), "government" (which country?), and for-profit (maybe a breakdown of product type?). In any case, thanks for posting this!
2
UK AISI is a government agency, so the pie chart is probably misleading on that segment!
4
Oh, shoot, my mistake.
2
I'm curious to see if I'm in this data, so I can help make it more accurate by providing info.
2
Hi Nicholas! You are not in the data as you were not a MATS scholar, to my knowledge. Were you a participant in one of the MATS training programs instead? Or did I make a mistake?
2[comment deleted]
Someone recently shared an interesting minimal model of electoral politics with me. Elected officials are influenced by two primary groups: voters and donors. Sometimes voter and donor interests align, but often they don't. Voters are the ultimate deciders, but they are only really swayed by the top-3 most salient issues. On those issues, elected officials side with voters, but on the rest they tend to side with donors. It's simply too costly for elected officials to go against donors on low-public salience issues; they can spend the donated money on campaigning for the top-salience issues, after all!
One interesting low-salience issue is AI policy. Voters are generally anti-AI (they don't like datacenters, automated surveillance, or recommender systems) but donors (often tech billionaires) are pro-AI. As AI is currently a low-salience issue for US voters (at least relative to the broader economy, healthcare, and immigration), politicians are siding with donors. For meaningful political action on AI, one would need either: AI to become a top-3 salience issue to voters (e.g., via job loss, weaponization, or warning shots); or more anti-AI donors to mobilize.
Anton Leicht has a good extension of this model, saying that if neither voters nor donors prioritize an issue, then policy can be shaped by technocratic experts. Right after ChatGPT’s release, AI policy briefly looked like that. People wanted some kind of policy response, and the only people with detailed proposals were AI safety experts, so they set the agenda for a while (e.g. UK AI Safety Summit, international AISI network, voluntary corporate commitments to mitigate catastrophic risk, Biden EO). But that window was short. Once businesses saw that AI policy proposals could hurt their interests (e.g. during the SB 1047 debate or when discussing restrictions on open source), they stepped in. Now anti-regulation donors generally have the upper hand over the AI policy wonks, and it'll take real pressure from voters or pro-safety donors to pass policies that the business interests oppose.
Brings to mind an old NYT article[1] that indicated that there's no clear correlation between voter preferences and enacted policies. Was there a more recent study that contradicted this?
Edit: Figure 2 in the paper I linked seems to point in this direction, but only on 70-30 issues. On all other issues, more salience among voters actually decreases likelihood of action.
- ^
I can't find it; it's buried in partisan slop headlines from more recent years, but I found a Princeton study that might've been the inspiration.
6
One aspect of the study was that nothing what they looked at strongly correlated with enacted policies. Spencer Greenberg used the paper as an example of importance hacking.
-1
I think "there is no strong correlation between the beliefs of the voting public and the policies that are enacted, but that's slightly less true for the rich" is a reasonably meaningful takeaway. I've seen people use the paper to claim that the rich run everything, but I don't know that that's the meaning the authors intended to imply.
7
It's not a meaningful takeaway, that's why Spencer Greenberg points it out as a bad paper.
The correlation is in the particular model, that's bad at explaining what policies are enacted, that a particular set of scientists used for their study. Just assuming that this generalizes is not warranted.
One aspect is that policies that are actually passed by Congress are much more than a one sentence position that you can poll people on but often laws that span hundreds of pages with lots of details that matter.
0
I don't think appeal to complexity works here. The fundamental purpose of democratic government is to handle the implementation of the policies that the population wants. If 70 percent of the population wants to, say, replace all the busses with trams, there will certainly be any number of unintended implementation details, but the end result should be a country in which the busses have been replaced with trams. If the population consistently prefers policy direction X, and the government consistently does the opposite, then that is a meaningful indication that something is wrong with the system.
This isn't to say that the paper is flawless or even good, but "a policy being desired by the population doesn't correlate with Congress enacting it" does seem like a meaningful finding. I do with I still had the NYT article that replicated this finding, IIRC their methodology was different and seemed quite strong.
2
This is one way to look at it, but it's not what philosophers like Rousseau meant with the word democracy when they argued for democracy being desirable. His idea of democracy was more about policies that are in the interests of the general population. The key idea of representative democracy is that there are a lot of decisions that can be made that are in your interests but where you don't understand what you want the decision to be.
As far as complexity goes, take Obama implementing Obama care. Before the election he made the promise of not making backroom deals and doing the reform in a way that doesn't rise health care costs. He made backroom deals with Big Pharma and insurance companies to get their lobbyists to support Obama care. Those deals resulted in increased health care costs.
He couldn't hold both the promise of not making backroom deals and getting insurance for people with preconditions. If you have a voter who both wanted no backroom deals and getting people with preconditions insured Obama did 50% of what the voter wants, so you can model it as Obama's work on Obamacare being uncorrelated with the desires of the those Democratic voters.
But if you would ask those voters whether they think Obama did what they wanted, I think many of them would say that Obamacare was a good step forward even if not perfect.
[...]
NYT articles don't replicate findings. They might be about studies that replicate findings.
1
I think representing it like that boils down to 'good-ism', where anything can be argued to be democracy so long as you believe or claim to believe that it's good, and anyone you dislike is an "enemy of democracy" on the basis that they're bad. Most people believe that democracy refers to a specific system of government, so, whether you believe words' meanings come from what is most useful or what is most accepted, I think both point to "what the people want" being a more desirable definition of democracy, since it is at least broadly concrete and verifiable, as opposed to "what is best for the people", which is nebulous and subject to manipulation.
Less practically, I would object to any definition of democracy in which North Korea can call itself one and not be trivially refuted.
----------------------------------------
[...]
I think "mandate that insurance companies cover preconditions" is a concrete policy item, and "I won't make backroom deals" isn't really a concrete policy item. I get what you're saying - sometimes multiple policies that are all popular contradict each other, but I don't think this is sufficient to explain the gap between the public's desires and the government's actions.
[...]
As I recall, they had methodology and data collection methods outlined. I could be misremembering.
2
Yes, to the specific system of government that are representative democracies like the United States. Most people consider systems that aren't direct democracy but representative democracies as democracies.
You try to argue that a system like the United States that most people would consider to be a democracy isn't.
[...]
What the people want is cheaper goods and a better economy. Representative democracy allows delegating the task of finding the best policies to achieve that outcome to elected politicians. It's not a system designed around asking people directly for the policies they want implemented.
When speaking about democracies we are talking about whether peoples interests are represented. I think it's quite easy to argue that in North Korea people's interests aren't represented well quite independent from polling North Korea's population about what policy preferences they have and comparing them to what policies get implemented.
If you ask the average North Korean whether different companies should be able to pay their employees different wages, I think there's a good chance that the average North Korean would not say that it's important for them to be able to do so and might say it's fair for every worker to get the same wage. On the other, hand the fact that wages allow market dynamics to happen that make the economy work and thus is in the interest of the average North Korean is also clear.
[...]
You are speaking about that in the abstract, not about the two as measured by the a given study. A given study can very well measure them in ways that come to strange conclusions. The fact that the study isn't able to explain much of the government actions is an indication that it's not good at it modeling the dynamic.
[...]
In the age of LLMs, the effort to go to look for an article one has forgotten isn't that high as it was a few years ago.
2
That's probably a fairly common view, and I don't quite disagree, but it seems somewhat naive or in the whole "governments and democratic institutions act in the public interest" camp of poli-sci.
While perhaps a bit difficult to fully separate from the suggested purpose, I do see democracy very much as a way of managing factional conflict view some more peaceful social mechanism that just brute force, winners get their way. Pure democracy might be similar but I think Constitutional type democracies do try to provide some base protection for the "loosing" side(s) while still promoting discussion and compromise over simple force.
Not sure how much that might shift the views and interpretations in this discussion but seems that if we start from a potentially partial or incorrect premise we'll not find the conclusions that fruitful or insightful.
8
Credit to Daniel Eth, who inspired this.
3
This sentence isn't parsing for me, should it be "to go against voters"?
4
Thanks, fixed!
2
Does this model match with some long standing political models that look through the lens of concentrated and diversified interests? Votes are a very diverse bunch but doners, individually and within some fairly well defined groups, tend to have so very well defined interests driving their political involvement.
2
That model suggests that beliefs of the elected officials themselves don't matter, the beliefs of congressional staffers don't matter, the beliefs of career bureaucrats don't matter.
2
That sounds pretty much true to me for two reasons:
1. Elected officials will tend to campaign on positions that they actually believe, because being honest is easier than lying.
2. The liars tend to care more about holding office than about their personal vision of what policies the government should have. If they lie to get elected, they still have to vote for what their constituents want (on high-salience issues), or else they won't get re-elected.
2
I think you underrate the complexity of the decisions that are made when it comes to policy.
Most people also don't account when they make statements like that, that there's a field of political science out there. When they try to run the numbers, things aren't as straightforward as the easy model would suggest.
1
An alternate phrasing of this would be looking at what the current top-3 high salience issues are for different elected officials, and what would have to change about AI policy for AI policy to dethrone one of these issues. I imagine IA policy is quite far from usurping immigration or other high-salience issues
-5
AI safety field-building in Australia should accelerate. My rationale:
- OpenAI opened a Sydney office in Dec 2025 and Anthropic is planning to open a Sydney office in 2026. These offices may hire safety staff from local talent, or partner with local auditing, evaluation, and security companies, including Harmony Intelligence, Good Ancestors, and Gradient Institute.
- An Australian AISI was announced for early 2026 and is currently hiring. The UK AISI has benefited from close partnerships with Apollo Research, METR, and the LISA office community. There is a community space in Sydney, the Sydney AI Safety Space, and two field-building organizations, AI Safety ANZ and TARA, but these could expand substantially.
- Australia seems like a prime location for datacenter build-out. OpenAI published an "AI blueprint" for Australia, calling for datacenter build-out, and started building a $4.6B datacenter in Sydney in Dec 2025. Australia is a NATO partner, Five Eyes member, and member of the AUKUS security partnership with the US and UK; it's much more secure and aligned with US/UK interests than Saudi Arabia. Australia is the second-largest exporter of thermal coal, has vast solar and wind resources
Piggybacking: If people have strong opinions on, or interest in contributing to, said fieldbuilding, I'd be very happy to connect - you can reach me at michael.kerrison@aisafetyanz.com.au :)
Also piggybacking, if anybody is Sydney-based or visiting Sydney, you are welcome to work out of the SydneyAISafetySpace.org (SASS) for free.
4
We're not free at the Melbourne AI Safety Hub, but we are all terribly charming.
I am a volunteer with PauseAI Australia, so if anyone wants to connect with our very, very small group, that would be great. We are pushing politicians on superintelligence.
My sense of priorities for an Australian AISI.
Priorities
- Enable safe and secure frontier AI training and deployment in Australia
- Build pathways around copyright restriction that prevents frontier AI companies from building training datacenters in Australia; the OpenAI datacenter being built in Sydney is for inference only
- Frontier AI will change the nature of work, shape international power, and potentially change what it means to be human and Australia doesn’t have a seat at the table; fix this
- Create jobs and opportunities for Australians to build and contribute to safe and secure AI in Australia, rather than all going overseas
- Set clear national guidelines for AI safety, security, and transparency
- Advance Australian interests in AI safety and security internationally
- Contribute to frontier AI evaluations and safety research like UK AISI, US CAISI
- Leverage Australia’s role as a “middle power” to create beneficial AI outcomes
- Share resources with the international network of
Enable safe and secure frontier AI training and deployment in Australia
- Build pathways around copyright restriction that prevents frontier AI companies from building training datacenters in Australia; the OpenAI datacenter being built in Sydney is for inference only
What. What is "safe frontier AI training"? We clearly have no way of doing this.
Please do not go to Australia and get them to make building datacenters cheaper.
All the other things do seem useful, but this is the first item on the list and seems really bad!
8[anonymous]
I'm not sure that I follow why ai safety work should be colocated with data centre build outs. I don't think many ai safety researchers would have much of anything to do with data centre infrastructure, and as far as I can tell they may aswell be located on the moon.
Very positive on a diversification of AI safety opportunities though.
One reason is that hosting data centers can give countries political influence over AI development, increasing the importance of their governments having reasonable views on AI risks.
6
Exactly! Also:
* AI safety researchers tend to have reasonable views on AI safety and can serve as local advisors to governments, which probably trust foreign experts less.
* Securing datacenters for SL5 to prevent proliferation of AGI is really hard and likely requires significant AI security expertise in government and local defence contractors.
* A regulatory market approach to AI safety (possibly only useful pre-superintelligence) requires competent local auditors, standard-setters, and insurers.
4[anonymous]
That seems a stronger argument for AI safety policy experts (such as the ones that the aps is beginning to hire) as opposed to safety researchers.
Maybe there's an argument that policy experts might chat with researchers at local cafes or meetups e.t.c., but it's quite second order and it seems like a relatively small benefit compared to the wealth of human capital you'd get opening a safety lab somewhere like India.
4
Yoshua Bengio, Paul Christiano, Geoffrey Irving seem more like technical AI safety experts than AI policy experts, but they arguably have strong influence on governments.
2
I suspect that some LWers would interpret this as a (bad) argument for countries to build datacenters so they can exercise political control over AGI. I don't think this works.
6
What should be done? I think:
* Office hubs: Expand SASS, which is in close proximity to the new OpenAI and Anthropic offices in Sydney. Start an AI safety hub in Canberra to support the new AISI. Successful AI safety hubs have benefited from prominent founding member organizations like ARC, CG, Redwood, and MIRI (for Constellation) and Apollo, BlueDot, and MATS (for LISA). Similarly, SASS should bring together orgs like the Gradient Institute and Harmony Intelligence in a shared space, and the new Canberra hub should be built around Good Ancestors. Office hubs can benefit member orgs by providing cheaper returns to scale, hosting shared networking events, facilitating collaboration, and providing a pipeline of strong new recruits in the form of office guests and members.
* Training programs: Expand TARA and the Sydney AI Safety Fellowship program, focusing on accelerating top talent and building local mentorship capacity for future programs. Don't focus on maximizing impact on participants; this is less important than reducing the mentorship bottleneck, which is best served by boosting the most advanced participants.
* Academic labs: Build relationships with AI/CS academics at UniMelb, Monash, USyd, ANU, UTS, UNSW, UA, UQ, etc. Help launch AI safety courses like Roy Rinberg and Boaz Barak did at Harvard. Other course inspiration is provided by Stanford and CAIS. Start AI safety academic labs like UC Berkeley CHAI, MIT AAG, NYU ARG, Bau Lab, Stanford HAI, CMU FOCAL, etc.
* Conferences: Run an annual AI safety conference like the Australian AI Safety Forum 2024, bringing together academia, industry, government, and nonprofit field-builders. EAGx is probably not enough, as many people from academia, industry, and government likely won't attend.
2
Could you clarify? Do you mean that if you have the chance to support someone new who would gain a lot since they haven't participated in many AI safety programs or the chance to support someone more advanced, you'd suggest picking the later? With the reasoning being that the former might look like a better bet because of more room to make a difference, however boosting the latter increases the supply of mentors and therefore actually ends up benefiting beginners as least as much.
5
Yes, I would generally support picking the latter as they have a "faster time to mentorship/research leadership/impact" and the field seems currently bottlenecked on mentorship and research leads, not marginal engineers (though individual research leads might feel bottlenecked on marginal engineers).
We should prioritize people who already have research or engineering experience or a very high iteration speed as we are operating under time constraints; AGI is coming soon. Additionally, I think "research taste" will be more important than engineering ability given AI automation and this takes a long time to build; better to select people with existing research experience they can adapt from another field (also promotes interdisciplinary knowledge transfer).
I talk more about it here.
2
Tom Everitt did his PhD in Australia too. (As did I, FWIW.)
2
Ramana Kumar!
1
Perth also exists!
The Perth Machine Learning Group sometimes hosts AI Safety talks or debates. The most recent one had 30 people attend at the Microsoft Office with a wide range of opinions. If anyone is passing through and is interested in meeting up or giving a talk, you can contact me.
There are a decent amount of technical machine learning people in Perth, mainly coming from mining and related industries (Perth is somewhat like the Houston of Australia).
1
@yanni kyriacos
1
I am interested. I've already been talking to several of the people involved, but I'm Melbourne based so I have been limited in my ability to interact.
1
@megasilverfist there are quite a few of us based in Melbourne. HMU.
As part of MATS' compensation reevaluation project, I scraped the publicly declared employee compensations from ProPublica's Nonprofit Explorer for many AI safety and EA organizations (data here) in 2019-2023. US nonprofits are required to disclose compensation information for certain highly paid employees and contractors on their annual Form 990 tax return, which becomes publicly available. This includes compensation for officers, directors, trustees, key employees, and highest compensated employees earning over $100k annually. Therefore, my data does not include many individuals earning under $100k, but this doesn't seem to affect the yearly medians much, as the data seems to follow a lognormal distribution, with mode ~$178k in 2023, for example.
I generally found that AI safety and EA organization employees are highly compensated, albeit inconsistently between similar-sized organizations within equivalent roles (e.g., Redwood and FAR AI). I speculate that this is primarily due to differences in organization funding, but inconsistent compensation policies may also play a role.
I'm sharing this data to promote healthy and fair compensation policies across the ecosystem. I believe th...
7
I decided to exclude OpenAI's nonprofit salaries as I didn't think they counted as an "AI safety nonprofit" and their highest paid current employees are definitely employed by the LLC. I decided to include Open Philanthropy's nonprofit employees, despite the fact that their most highly compensated employees are likely those under the Open Philanthropy LLC.
4
It's also worth noting that almost all of these roles are management, ML research, or software engineering; there are very few operations, communications, non-ML research, etc. roles listed, implying that these roles are paid significantly less.
I am a Manifund Regrantor. In addition to general grantmaking, I have requests for proposals in the following areas:
- Funding for AI safety PhDs (e.g., with these supervisors), particularly in exploratory research connecting AI safety theory with empirical ML research.
- An AI safety PhD advisory service that helps prospective PhD students choose a supervisor and topic (similar to Effective Thesis, but specialized for AI safety).
- Initiatives to critically examine current AI safety macrostrategy (e.g., as articulated by Holden Karnofsky) like the Open Philanthropy AI Worldviews Contest and Future Fund Worldview Prize.
- Initiatives to identify and develop "Connectors" outside of academia (e.g., a reboot of the Refine program, well-scoped contests, long-term mentoring and peer-support programs).
- Physical community spaces for AI safety in AI hubs outside of the SF Bay Area or London (e.g., Japan, France, Bangalore).
- Start-up incubators for projects, including evals/red-teaming/interp companies, that aim to benefit AI safety, like Catalyze Impact, Future of Life Foundation, and YCombinator's request for Explainable AI start-ups.
- Initiatives to develop and publish expert consensus on AI safety macr
1
"Physical community spaces for AI safety in AI hubs outside of the SF Bay Area or London (e.g., Japan, France, Bangalore)"- I love this initiative. Can we also consider Australia or New Zealand in the upcoming proposal?
3
In theory, sure! I know @yanni kyriacos recently assessed the need for an ANZ AI safety hub, but I think he concluded there wasn't enough of a need yet?
4
Hi! I think in Sydney we're ~ 3 seats short of critical mass, so I am going to reassess the viability of a community space in 5-6 months :)
2
@yanni kyriacos when will you post about TARA and Sydney AI Safety Hub on LW? ;)
1
SASH isn't official (we're waiting on funding).
Here is TARA :)
https://www.lesswrong.com/posts/tyGxgvvBbrvcrHPJH/apply-to-be-a-ta-for-tara
Hourly stipends for AI safety fellowship programs, plus some referents. The average AI safety program stipend is $26/h.
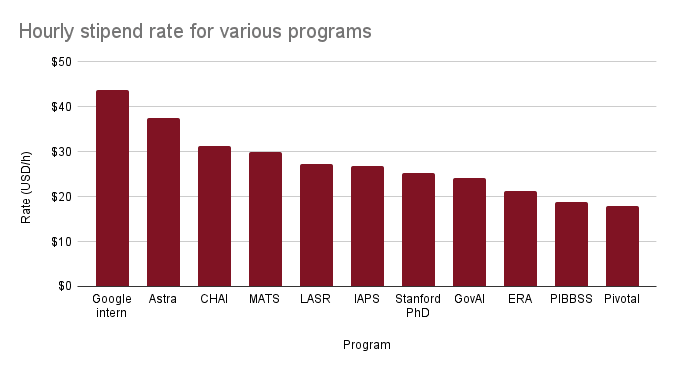
Edit: updated figure to include more programs.
7
Y'know @Ryan, MATS should try to hire the PIBBSS folks to help with recruiting. IMO they tend to have the strongest participants of the programs on this chart which I'm familiar with (though high variance).
2
That's interesting! What evidence do you have of this? What metrics are you using?
6
My main metric is "How smart do these people seem when I talk to them or watch their presentations?". I think they also tend to be older and have more research experience.
5
I think there some confounders here:
* PIBBSS had 12 fellows last cohort and MATS had 90 scholars. The mean/median MATS Summer 2024 scholar was 27; I'm not sure what this was for PIBBSS. The median age of the 12 oldest MATS scholars was 35 (mean 36). If we were selecting for age (which is silly/illegal, of course) and had a smaller program, I would bet that MATS would be older than PIBBSS on average. MATS also had 12 scholars with completed PhDs and 11 in-progress.
* Several PIBBSS fellows/affiliates have done MATS (e.g., Ann-Kathrin Dombrowski, Magdalena Wache, Brady Pelkey, Martín Soto).
* I suspect that your estimation of "how smart do these people seem" might be somewhat contingent on research taste. Most MATS research projects are in prosaic AI safety fields like oversight & control, evals, and non-"science of DL" interpretability, while most PIBBSS research has been in "biology/physics-inspired" interpretability, agent foundations, and (recently) novel policy approaches (all of which MATS has supported historically).
Also, MATS is generally trying to further a different research porfolio than PIBBSS, as I discuss here, and has substantial success in accelerating hires to AI scaling lab safety teams and research nonprofits, helping scholars found impactful AI safety organizations, and (I suspect) accelerating AISI hires.
3
I think this is less a matter of my particular taste, and more a matter of selection pressures producing genuinely different skill levels between different research areas. People notoriously focus on oversight/control/evals/specific interp over foundations/generalizable interp because the former are easier. So when one talks to people in those different areas, there's a very noticeable tendency for the foundations/generalizable interp people to be noticeably smarter, more experienced, and/or more competent. And in the other direction, stronger people tend to be more often drawn to the more challenging problems of foundations or generalizable interp.
So possibly a MATS apologist reply would be: yeah, the MATS portfolio is more loaded on the sort of work that's accessible to relatively-mid researchers, so naturally MATS ends up with more relatively-mid researchers. Which is not necessarily a bad thing.
3
I don't agree with the following claims (which might misrepresent you):
* "Skill levels" are domain agnostic.
* Frontier oversight, control, evals, and non-"science of DL" interp research is strictly easier in practice than frontier agent foundations and "science of DL" interp research.
* The main reason there is more funding/interest in the former category than the latter is due to skill issues, rather than worldview differences and clarity of scope.
* MATS has mid researchers relative to other programs.
9
Y'know, you probably have the data to do a quick-and-dirty check here. Take a look at the GRE/SAT scores on the applications (both for applicant pool and for accepted scholars). If most scholars have much-less-than-perfect scores, then you're probably not hiring the top tier (standardized tests have a notoriously low ceiling). And assuming most scholars aren't hitting the test ceiling, you can also test the hypothesis about different domains by looking at the test score distributions for scholars in the different areas.
6
We don't collect GRE/SAT scores, but we do have CodeSignal scores and (for the first time) a general aptitude test developed in collaboration with SparkWave. Many MATS applicants have maxed out scores for the CodeSignal and general aptitude tests. We might share these stats later.
1
FWIW from what I remember, I would be surprised if most people doing MATS 7.0 did not max out the aptitude test. Also, the aptitude test seems more like an SAT than anything measuring important procedural knowledge for AI safety.
2
Are these PIBBSS fellows (MATS scholar analog) or PIBBSS affiliates (MATS mentor analog)?
2
Fellows.
4
Note that governance/policy jobs pay less than ML research/engineering jobs, so I expect GovAI, IAPS, and ERA, which are more governance focused, to have a lower stipend. Also, MATS is deliberately trying to attract top CS PhD students, so our stipend should be higher than theirs, although lower than Google internships to select for value alignment. I suspect that PIBBSS' stipend is an outlier and artificially low due to low funding. Given that PIBBSS has a mixture of ML and policy projects, and IMO is generally pursuing higher variance research than MATS, I suspect their optimal stipend would be lower than MATS', but higher than a Stanford PhD's; perhaps around IAPS' rate.
2
That said, maybe you are conceptualizing of an "efficient market" that principally values impact, in which case I would expect the governance/policy programs to have higher stipends. However, I'll note that 87% of MATS alumni are interested in working at an AISI and several are currently working at UK AISI, so it seems that MATS is doing a good job of recruiting technical governance talent that is happy to work for government wages.
1
No, I meant that the correlation between pay and how-competent-the-typical-participant-seems-to-me is, if anything, negative. Like, the hiring bar for Google interns is lower than any of the technical programs, and PIBBSS seems-to-me to have the most competent participants overall (though I'm not familiar with some of the programs).
2
I don't think it makes sense to compare Google intern salary with AIS program stipends this way, as AIS programs are nonprofits (with associated salary cut) and generally trying to select against people motivated principally by money. It seems like good mechanism design to pay less than tech internships, even if the technical bar for is higher, given that value alignment is best selected by looking for "costly signals" like salary sacrifice.
I don't think the correlation for competence among AIS programs is as you describe.
Interesting, thanks! My guess is this doesn't include benefits like housing and travel costs? Some of these programs pay for those while others don't, which I think is a non-trivial difference (especially for the bay area)
4
Yes, this doesn't include those costs and programs differ in this respect.
4
Is “CHAI” being a CHAI intern, PhD student, or something else? My MATS 3.0 stipend was clearly higher than my CHAI internship stipend.
4
CHAI interns are paid $5k/month for in-person interns and $3.5k/month for remote interns. I used the in-person figure. https://humancompatible.ai/jobs
5
Then the MATS stipend today is probably much lower than it used to be? (Which would make sense since IIRC the stipend during MATS 3.0 was settled before the FTX crash, so presumably when the funding situation was different?)
6
MATS lowered the stipend from $50/h to $40/h ahead of the Summer 2023 Program to support more scholars. We then lowered it again to $30/h ahead of the Winter 2023-24 Program after surveying alumni and determining that 85% would be accept $30/h.
2
I’d be curious to know if there’s variability in the “hours worked per week” given that people might work more hours during a short program vs a longer-term job (to keep things sustainable).
2
I'm not sure!
1
LASR (https://www.lasrlabs.org/) is giving a £11,000 stipend for a 13 week program, assuming 40h/week it works out to ~$27
3
Updated figure with LASR Labs and Pivotal Research Fellowship at current exchange rate of 1 GBP = 1.292 USD.
2
That seems like a reasonable stipend for LASR. I don't think they cover housing, however.
I made a Google Scholar page for MATS. This was inspired by @Esben Kran's Google Scholar for Apart Research. Eleuther AI subsequently made one too. I think all AI safety organizations and research programs should consider making Google Scholar pages to better share research and track impact.
5
Here is a plot of the annual citations received by MATS, EleutherAI, and Apart research, adjusted so they start on the same year. The three organizations are somewhat comparable, as they leverage large networks of external collaborators: MATS mentors/fellows, EleutherAI Discord, Apart sprint participants.
The EleutherAI data fits a logistic curve perfectly, asymptoting to ~18.5k citations/year. I can't fit the others as at least 4 data points are needed to fit a logistic curve.
4
The top-10 most-cited papers that MATS contributed to are (all with at least 290 citations)
1. Representation Engineering: A Top-Down Approach to AI Transparency
2. Sparse autoencoders find highly interpretable features in language models
3. Towards understanding sycophancy in language models
4. Steering Language Models With Activation Engineering
5. Steering Llama 2 via Contrastive Activation Addition
6. Refusal in language models is mediated by a single direction
7. The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning
8. The Reversal Curse: LLMs trained on" A is B" fail to learn" B is A"
9. LLM Evaluators Recognize and Favor Their Own Generations
10. Finding neurons in a haystack: Case studies with sparse probing
Compare this to the top-10 highest-karma LessWrong posts that MATS contributed to (all with over 200 karma):
1. SolidGoldMagikarp (plus, prompt generation)
2. Steering GPT-2-XL by adding an activation vector (arXiv)
3. Transformers Represent Belief State Geometry in their Residual Stream (arXiv)
4. Understanding and Controlling a Maze-Solving Policy Network (arXiv)
5. Emergent Misalignment: Narrow finetuning can produce broadly misaligned LLMs (arXiv)
6. Refusal in LLMs is mediated by a single direction (arXiv)
7. Natural Abstractions: Key Claims, Theorems, and Critiques
8. Distillation Robustifies Unlearning (arXiv)
9. Mechanistically Eliciting Latent Behaviors in Language Models
10. Neural networks generalize because of this one weird trick
Why does the AI safety community need help founding projects?
- AI safety should scale
- Labs need external auditors for the AI control plan to work
- We should pursue many research bets in case superalignment/control fails
- Talent leaves MATS/ARENA and sometimes struggles to find meaningful work for mundane reasons, not for lack of talent or ideas
- Some emerging research agendas don’t have a home
- There are diminishing returns at scale for current AI safety teams; sometimes founding new projects is better than joining an existing team
- Scaling lab alignment teams are bottlenecked by management capacity, so their talent cut-off is above the level required to do “useful AIS work”
- Research organizations (inc. nonprofits) are often more effective than independent researchers
- “Block funding model” is more efficient, as researchers can spend more time researching, rather than seeking grants, managing, or other traditional PI duties that can be outsourced
- Open source/collective projects often need a central rallying point (e.g., EleutherAI, dev interp at Timaeus, selection theorems and cyborgism agendas seem too delocalized, etc.)
- There is (imminently) a market for for-profit AI safety companies and value-al
8
I agree with this, I'd like to see AI Safety scale with new projects. A few ideas I've been mulling:
- A 'festival week' bringing entrepreneur types and AI safety types together to cowork from the same place, along with a few talks and lot of mixers.
- running an incubator/accelerator program at the tail end of a funding round, with fiscal sponsorship and some amount of operational support.
- more targeted recruitment for specific projects to advance important parts of a research agenda.
It's often unclear to me whether new projects should actually be new organizations; making it easier to spin up new projects, that can then either join existing orgs or grow into orgs themselves, seems like a promising direction.
4
I'm surprised this one was included, it feels tail-wagging-the-dog to me.
0
I would amend it to say "sometimes struggles to find meaningful employment despite having the requisite talent to further impactful research directions (which I believe are plentiful)"
This still reads to me as advocating for a jobs program for the benefit of MATS grads, not safety. My guess is you're aiming for something more like "there is talent that could do useful work under someone else's direction, but not on their own, and we can increase safety by utilizing it".
6
I expect that Ryan means to say one of the these things:
1. There isn't enough funding for MATS grads to do useful work in the research directions they are working on, that have already been vouched for by senior alignment researchers (especially their mentors) to be valuable. (Potential examples: infrabayesianism)
2. There isn't (yet) institutional infrastructure to support MATS grads to do useful work together as part of a team focused on the same (or very similar) research agendas, and that this is the case for multiple nascent and established research agendas. They are forced to go to academia and disperse across the world instead of being able to work together in one location. (Potential examples: selection theorems, multi-agent alignment (of the sort that Caspar Oesterheld and company work on))
3. There aren't enough research managers in existing established alignment research organizations or frontier labs to enable MATS grads to work on the research directions they consider extremely high value, and would benefit from multiple people working together on (Potential examples: activation steering)
I'm pretty sure that Ryan does not mean to say that MATS grads cannot do useful work on their own. The point is that we don't yet have the institutional infrastructure to absorb, enable, and scale new researchers the way our civilization has for existing STEM fields via, say, PhD programs or yearlong fellowships at OpenAI/MSR/DeepMind (which are also pretty rare). AFAICT, the most valuable part of such infrastructure in general is the ability to co-locate researchers working on the same or similar research problems -- this is standard for academic and industry research groups, for example, and from experience I know that being able to do so is invaluable. Another extremely valuable facet of institutional infrastructure that enables researchers is the ability to delegate operations and logistics problems -- particularly the difficulty of finding grant funding, int
2
@Elizabeth, Mesa nails it above. I would also add that I am conceptualizing impactful AI safety research as the product of multiple reagents, including talent, ideas, infrastructure, and funding. In my bullet point, I was pointing to an abundance of talent and ideas relative to infrastructure and funding. I'm still mostly working on talent development at MATS, but I'm also helping with infrastructure and funding (e.g., founding LISA, advising Catalyze Impact, regranting via Manifund) and I want to do much more for these limiting reagents.
4
Also note that historically many individuals entering AI safety seem to have been pursuing the "Connector" path, when most jobs now (and probably in the future) are "Iterator"-shaped, and larger AI safety projects are also principally bottlenecked by "Amplifiers". The historical focus on recruiting and training Connectors to the detriment of Iterators and Amplifiers has likely contributed to this relative talent shortage. A caveat: Connectors are also critical for founding new research agendas and organizations, though many self-styled Connectors would likely substantially benefit as founders by improving some Amplifier-shaped soft skills, including leadership, collaboration, networking, and fundraising.
4
I interpret your comment as assuming that new researchers with good ideas produce more impact on their own than in teams working towards a shared goal; this seems false to me. I think that independent research is usually a bad bet in general and that most new AI safety researchers should be working on relatively few impactful research directions, most of which are best pursued within a team due to the nature of the research (though some investment in other directions seems good for the portfolio).
I've addressed this a bit in thread, but here are some more thoughts:
* New AI safety researchers seem to face mundane barriers to reducing AI catastrophic risk, including funding, infrastructure, and general executive function.
* MATS alumni are generally doing great stuff (~78% currently work in AI safety/control, ~1.4% work on AI capabilities), but we can do even better.
* Like any other nascent scientific/engineering discipline, AI safety will produce more impactful research with scale, albeit with some diminishing returns on impact eventually (I think we are far from the inflection point, however).
* MATS alumni, as a large swathe of the most talented new AI safety researchers in my (possibly biased) opinion, should ideally not experience mundane barriers to reducing AI catastrophic risk.
* Independent research seems worse than team-based research for most research that aims to reduce AI catastrophic risk:
* "Pair-programming", builder-breaker, rubber-ducking, etc. are valuable parts of the research process and are benefited by working in a team.
* Funding insecurity and grantwriting responsibilities are larger for independent researchers and obstruct research.
* Orgs with larger teams and discretionary funding can take on interns to help scale projects and provide mentorship.
* Good prosaic AI safety research largely looks more like large teams doing engineering and less like lone geniuses doing maths. Obviously, some lone genius researchers (espec
2
I don't believe that, although I see how my summary could be interpreted that way. I agree with basically all the reasons in your recent comment and most in the original comment. I could add a few reasons of my own doing independent grant-funded work sucks. But I think it's really important to track how founding projects tracks to increased potential safety instead of intermediates, and push hard against potential tail wagging the dog scenarios.
I was trying to figure out why this was important to me, given how many of your points I agree with. I think it's a few things:
* Alignment work seems to be prone to wagging the dog, and is harder to correct, due to poor feedback loops.
* The consequences of this can be dire
* making it harder to identify and support the best projects.
* making it harder to identify and stop harmful projects
* making it harder to identify when a decent idea isn't panning out, leading to people and money getting stuck in the mediocre project instead of moving on.
* One of the general concerns about MATS is it spins up potential capabilities researchers. If the market can't absorb the talent, that suggests maybe MATS should shrink.
* OTOH if you told me that for every 10 entrants MATS spins up 1 amazing safety researcher and 9 people who need makework to prevent going into capabilities, I'd be open to arguments that that was a good trade.
I just left a comment on PIBBSS' Manifund grant proposal (which I funded $25k) that people might find interesting.
...Main points in favor of this grant
- My inside view is that PIBBSS mainly supports “blue sky” or “basic” research, some of which has a low chance of paying off, but might be critical in “worst case” alignment scenarios (e.g., where “alignment MVPs” don’t work, or “sharp left turns” and “intelligence explosions” are more likely than I expect). In contrast, of the technical research MATS supports, about half is basic research (e.g., interpretability, evals, agent foundations) and half is applied research (e.g., oversight + control, value alignment). I think the MATS portfolio is a better holistic strategy for furthering AI alignment. However, if one takes into account the research conducted at AI labs and supported by MATS, PIBBSS’ strategy makes a lot of sense: they are supporting a wide portfolio of blue sky research that is particularly neglected by existing institutions and might be very impactful in a range of possible “worst-case” AGI scenarios. I think this is a valid strategy in the current ecosystem/market and I support PIBBSS!
- In MATS’ recent post, “Talent Needs of
Main takeaways from a recent AI safety conference:
- If your foundation model is one small amount of RL away from being dangerous and someone can steal your model weights, fancy alignment techniques don’t matter. Scaling labs cannot currently prevent state actors from hacking their systems and stealing their stuff. Infosecurity is important to alignment.
- Scaling labs might have some incentive to go along with the development of safety standards as it prevents smaller players from undercutting their business model and provides a credible defense against lawsuits regarding unexpected side effects of deployment (especially with how many tech restrictions the EU seems to pump out). Once the foot is in the door, more useful safety standards to prevent x-risk might be possible.
- Near-term commercial AI systems that can be jailbroken to elicit dangerous output might empower more bad actors to make bioweapons or cyberweapons. Preventing the misuse of near-term commercial AI systems or slowing down their deployment seems important.
- When a skill is hard to teach, like making accurate predictions over long time horizons in complicated situations or developing a “security mindset,” try treating human
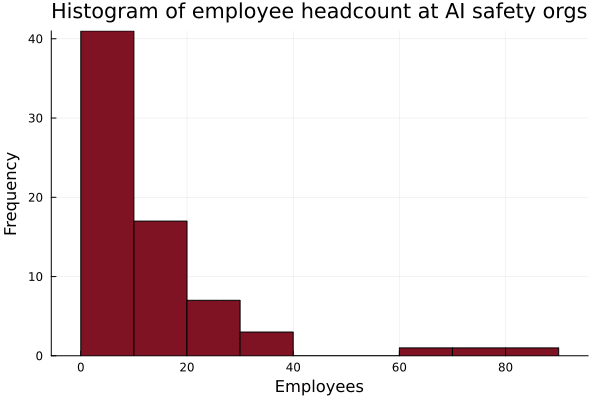
I did a quick inventory on the employee headcount at AI safety and safety-adjacent organizations. The median AI safety org has 10 8 employees. I didn't include UK AISI, US AISI, CAIS, and the safety teams at Anthropic, GDM, OpenAI, and probably more, as I couldn't get accurate headcount estimates. I also didn't include "research affiliates" or university students in the headcounts for academic labs. Data here. Let me know if I missed any orgs!
9
Apparently the headcount for US corporations follows a power-law distribution, apart from mid-sized corporations, which fit a lognormal distribution better. I fit a power law distribution to the data (after truncating all datapoints with over 40 employees, which created a worse fit), which gave p(x)∼399x−1.29. This seems to imply that there are ~400 independent AI safety researchers (though note that p(x) is probability density function and this estimate might be way off); Claude estimates 400-600 for comparison. Integrating this distribution over x∈[1,∞) gives ~1400 (2 s.f.) total employees working on AI safety or safety-adjacent work (∞ might be a bad upper bound, as the largest orgs have <100 employees).
2
I've seen you use "upper bound" and "underestimate" twice in this thread, and I want to lightly push back against this phrasing. I think the likely level of variance in these estimates is much too high for them to be any sort of bounds or to informatively be described as "under" any estimate.
That is, although your analysis of the data you have may imply, given perfect data, an underestiamte or upper bound, I think your data is too imperfect for those to be useful descriptions with respect to reality. Garbage in, garbage out, as they say.
The numbers are still useful, and if you have a model of the orgs that you missed, the magnitude of your over-counting, or a sensitivity analysis of your process, these would be interesting to hear about. But these will probably take the form more as approximate probability distributions more than a binary bigger-or-smaller-than-truth shots from the hip.
2
By "upper bound", I meant "upper bound b on the definite integral ∫bap(x)dx". I.e., for the kind of hacky thing I'm doing here, the integral is very sensitive to the choice of bounds a,b. For example, the integral does not converge for a=0. I think all my data here should be treated as incomplete and all my calculations crude estimates at best.
I edited the original comment to say "∞ might be a bad upper bound" for clarity.
2
Yeah, I think we're in agreement, I'm just saying the phrase "upper bound" is not useful compared to eg providing various estimates for various bounds & making a table or graph, and a derivative of the results wrt the parameter estimate you inferred.
4
So, conduct a sensitivity analysis on the definite integral with respect to choices of integration bounds? I'm not sure this level of analysis is merited given the incomplete data and unreliable estimation methodology for the number of independent researchers. Like, I'm not even confident that the underlying distribution is a power law (instead of, say, a composite of power law and lognormal distributions, or a truncated power law), and the value of p(1) seems very sensitive to data in the vicinity, so I wouldn't want to rely on this estimate except as a very crude first pass. I would support an investigation into the number of independent researchers in the ecosystem, which I would find useful.
2
I think again we are on the same page & this sounds reasonable, I just want to argue that "lower bound" and "upper bound" are less-than-informative descriptions of the uncertainty in the estimates.
4
I definitely think that people should not look at my estimates and say "here is a good 95% confidence interval upper bound of the number of employees in the AI safety ecosystem." I think people should look at my estimates and say "here is a good 95% confidence interval lower bound of the number of employees in the AI safety ecosystem," because you can just add up the names. I.e., even if there might be 10x the number of employees as I estimated, I'm at least 95% confident that there are more than my estimate obtained by just counting names (obviously excluding the 10% fudge factor).
8
A couple thousand brave souls standing between humanity and utter destruction. Kinda epic from a storytelling narrative where the plucky underdog good guys win in the end.... but kinda depressing from a realistic forecast perspective.
Can humanity really not muster more researchers to throw at this problem? What an absurd coordination failure.
7
Assuming that I missed 10% of orgs, this gives a rough estimate for the total number of FTEs working on AI safety or adjacent work at ~1000, not including students or faculty members. This is likely an underestimate, as there are a lot of AI safety-adjacent orgs in areas like AI security and robustness.
5
Leap Labs, Conjecture, Simplex, Aligned AI, and the AI Futures Project seem to be missing from the current list.
5
Thanks! I wasn't sure whether to include Simplex, or the entire Obelisk team at Astera (which Simplex is now part of), or just exclude these non-scaling lab hybrid orgs from the count (Astera does neuroscience too).
4
I presume you counted total employees and not only AI safety researchers, which would be the more interesting number, esp. at GDM.
6
I counted total employees for most orgs. In the spreadsheet I linked, I didn't include an estimate for total GDM headcount, just that of the AI Safety and Alignment Team.
4
How did you determine the list of AI safety and adjacent organizations?
6
I was very inclusive. I looked at a range of org lists, including those maintained by 80,000 Hours and AISafety.com.
3
You can add AE Studio to the list.
2
Most of the staff at AE Studio are not working on alignment, so I don't think it counts.
2
Yeah, I think it's like maybe 5 people's worth of contribution from AE studio. Which is something, but not at all comparable to the whole company being full-time on alignment.
I'm interested in determining the growth rate of AI safety awareness to aid field-building strategy. Applications to MATS have been increasing by 70% per year. Do any other field-builders have statistics they can share?
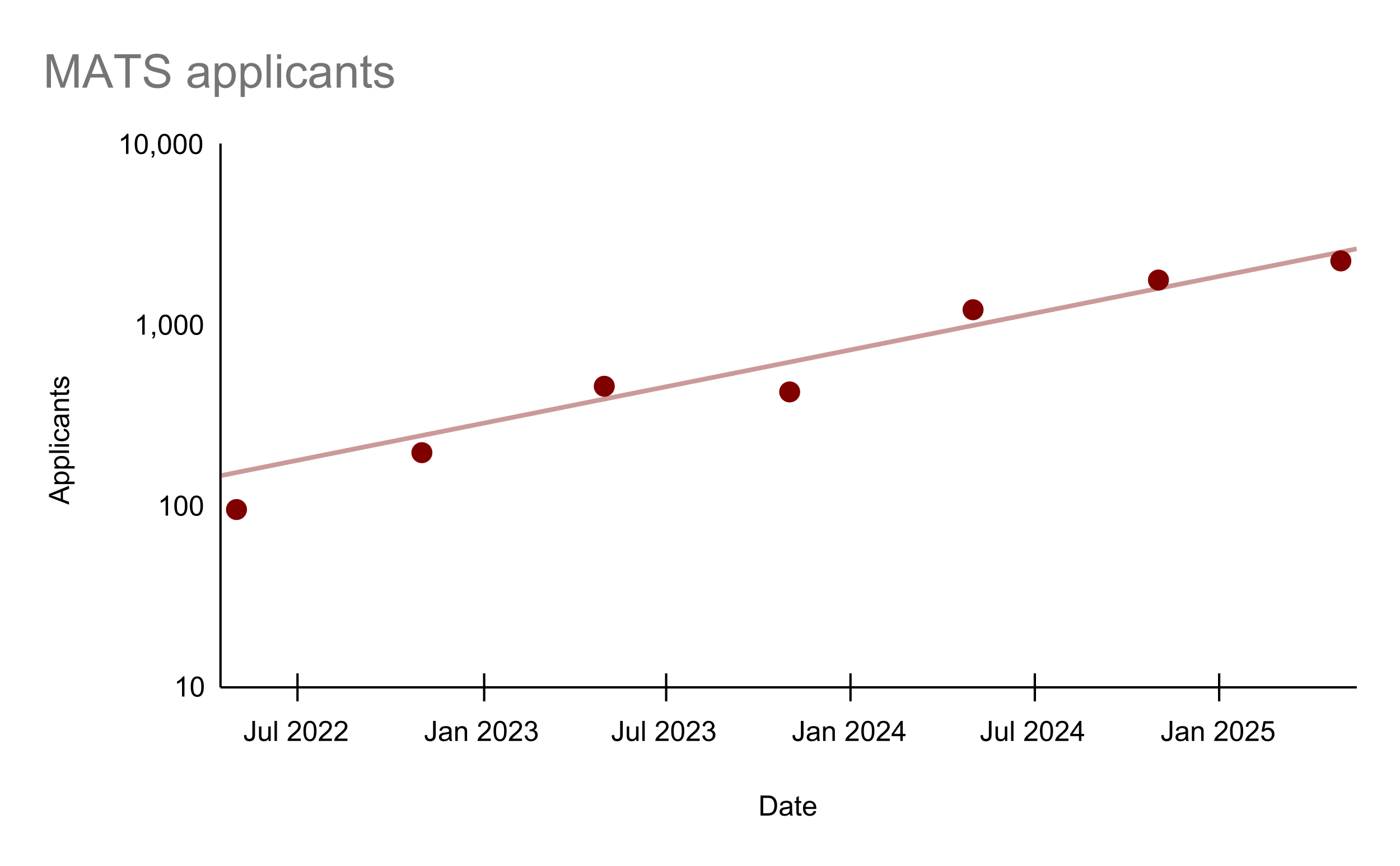
4
(This is a fun statistic but feels too ad-like for LW)
(Edit: The new version feels fine)
5
Any alternative framing/text you recommend? I think it's a pretty useful statistic for AI safety field-building.
Without the question at the end it would feel less ad-like, like it doesn't to me feel like you are honestly asking that question.
It's also that this correlates with applications opening for the next MATS, and your last post had a very similar statistic correlating with the same window, so my guess is there is indeed some ad-like motivation (I think it's fine for MATS to advertise a bit on LW, though shortform is a kind of tricky medium for that because we don't have a frontpage/personal distinction for shortform and I don't want people to optimize around the lack of that distinction).
I don't know, it feels to me like a relatively complicated aggregate of a lot of different things. Some messages that would have caused me to feel less advertised towards:
- "FYI, applications to MATS have been increasing 70% a year: [graph]. ARENA has seen also quite high growth rates [graph or number]. We've also seen a lot of funding increase over the same period, my best guess something similar like X. I wonder whether ~70% or something is aggregate growth rate of the field." (Of course one would have to check here, and I am not saying you have to do all of this work)
- "MATS applicati
2
I've updated the OP to reflect my intention better. Also, thanks for reminding me re. advertising on LW; MATS actually hasn't made an ad post yet and this seems like a big oversight!
4
Agree! IMO seems like there should be one.
3
I feel like there should be an indicator for posts that have been edited, like youtube comments pictured here. Its often important context for the content of a post or comment that it has been edited since original posting. Maybe even a way to see the dif history? (Though this would be a tougher ask for site devs)
5
There is an indicator! The indicator only shows up if you edit it more than half an hour after posting, to avoid lots of false-positives on typo checks or quick edits. In this case all the editing ended up happening within that window.
If you edit outside of that window it looks like this:
1
Ah somehow never noticed this thank you! 30 minute policy seems good, though it comes with the potential flaw of failing to notate an actual content update if its done quickly (as happened here). Still think diff history would be cool and would alleviate that problem, though its rather nitpicky/minor.
3
Yep, I think some diff history would be good, just haven't gotten around to building the UI for it, and if we do add UI for it, I would want some ability for authors to remove information permanently, in a way that is admin-reviewed, and that requires a bunch of kind of complicated UI.
3
Josh Landes shared that BlueDot Impact's application rate has been increasing by 4.7x/year.
2
Also of interest: MATS mentor applications have been growing linearly at a rate of +70/year. We are now publicly advertising for mentor applications for the first time (previously, we sent out mass emails and advertised on Slack workspaces), which might explain the sub-exponential growth. Giving the exponential growth in applicants and linear growth in mentors, the latter seems to be the limiting constraint still.
Technical AI alignment/control is still impactful; don't go all-in on AI gov!
- Liability incentivizes safeguards, even absent regulation;
- Cheaper, more effective safeguards make it easier for labs to meet safety standards;
- Concrete, achievable safeguards give regulation teeth.
Also there's a good chance AI gov won't work, and labs will just have a very limited safety budget to implement their best guess mitigations. Or maybe AI gov does work and we get a large budget, we still need to actually solve alignment.
9
There are definitely still benefits to doing alignment research, but this only justifies the idea that doing alignment research is better than doing nothing.
IMO the thing that matters (for an individual making decisions about what to do with their career) is something more like "on the margin, would it be better to have one additional person do AI governance or alignment/control?"
I happen to think that given the current allocation of talent, on-the-margin it's generally better for people to choose AI policy. (Particularly efforts to contribute technical expertise or technical understanding/awareness to governments, think-tanks interfacing with governments, etc.) There is a lot of demand in the policy community for these skills/perspectives and few people who can provide them. In contrast, technical expertise is much more common at the major AI companies (though perhaps some specific technical skills or perspectives on alignment are neglected.)
In other words, my stance is something like "by default, anon technical person would have more expected impact in AI policy unless they seem like an unusually good fit for alignment or an unusually bad fit for policy."
2
I'm open to this argument, but I'm not sure it's true under the Trump administration.
2
My understanding is that AGI policy is pretty wide open under Trump. I don't think he and most of his close advisors have entrenched views on the topic.
If AGI is developed in this Admin (or we approach it in this Admin), I suspect there is a lot of EV on the table for folks who are able to explain core concepts/threat models/arguments to Trump administration officials.
There are some promising signs of this so far. Publicly, Vance has engaged with AI2027. Non-publicly, I think there is a lot more engagement/curiosity than many readers might expect.
This isn't to say "everything is great and the USG is super on track to figure out AGI policy" but it's more to say "I think people should keep an open mind– even people who disagree with the Trump Admin on mainstream topics should remember that AGI policy is a weird/niche/new topic where lots of people do not have strong/entrenched/static positions (and even those who do have a position may change their mind as new events unfold.)"
1
What are your thoughts on the relative value of AI governance/advocacy vs. technical research? It seems to me that many of the technical problems are essentially downstream of politics; that intent alignment could be solved, if only our race dynamics were mitigated, regulation was used to slow capabilities research, and if it was given funding/strategic priority.
0
This is exactly the message we need more people to hear.
What’s missing from most conversations is this: Frontier liability will cause massive legal bottlenecks soon, regulations are nowhere near ready (not even in the EU with the AI Act).
Law firms and courts will need technical safety experts.
Not just to inform regulation, but to provide expert opinions when opaque model behaviors cause harm downstream, often in ways that weren’t detectable during testing.
The legal world will be forced to allocate responsibility in the face of emergent, stochastic failure modes. Without technical guidance, there are no safeguards to enforce, and no one to translate model failures into legal reasoning.
I analyzed the research interests of the 454 Action Editors on the Transactions on Machine Learning Research (TMLR) Editorial Board to determine what proportion of ML academics are interested in AI safety (credit to @scasper for the idea).
- 14% of editors listed any of "robustness", "trustworthy", "interpretable", "safety", "alignment", "evaluation", or "security" as a research interest.
- 10% of editors listed any of "trustworthy", "interpretable", "safety", "alignment", "evaluation", or "security" as a research interest. I excluded "robustness" as much of this research is considered more "capabilities" than "safety".
- 3.7% of editors listed "safety" or "alignment" as a research interest.
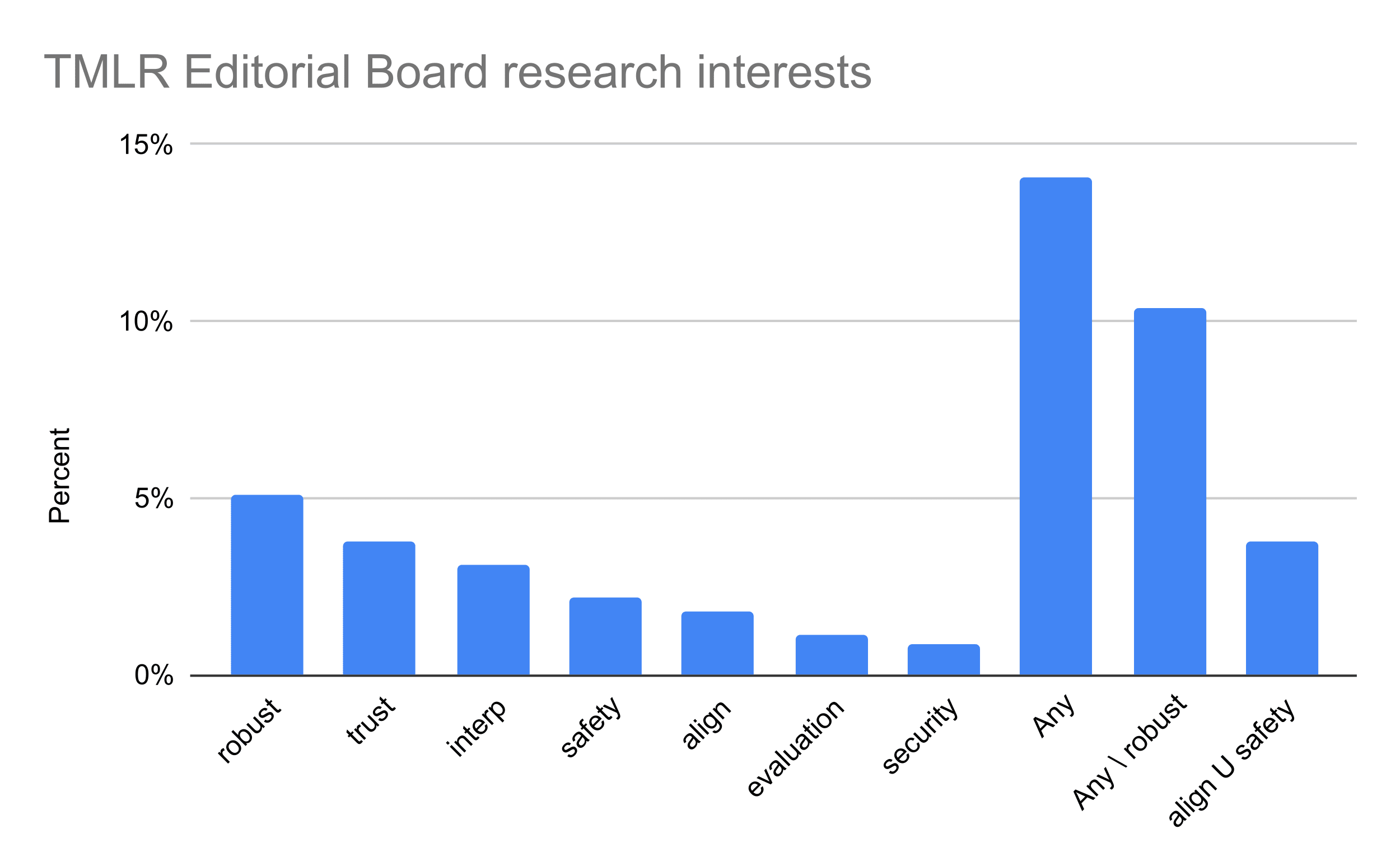
2
Gemini 3 estimates that there are 15-20k core ML academics and 100-150k supporting PhD students and Postdocs worldwide. If the TMLR sample is representative, this indicates that there are:
* ~20k academics interested in any of the above research areas.
* ~15k academics interested in the non-robustness research areas.
* ~5k academics interested in AI safety or alignment (note that this might include RLHF).
1
"Gemini 3 estimates that there are 15-20k core ML academics and 100-150k supporting PhD students and Postdocs worldwide."
In my opinion, this seems way too high. What was the logic or assumptions it used?
Crucial questions for AI safety field-builders:
- What is the most important problem in your field? If you aren't working on it, why?
- Where is everyone else dropping the ball and why?
- Are you addressing a gap in the talent pipeline?
- What resources are abundant? What resources are scarce? How can you turn abundant resources into scarce resources?
- How will you know you are succeeding? How will you know you are failing?
- What is the "user experience" of my program?
- Who would you copy if you could copy anyone? How could you do this?
- Am I better than the counterfactual?
- Who are your clients? What do they want?
SFF-2025 S-Process funding results have been announced! This year, the S-process gave away ~$34M to 88 organizations. The mean (median) grant was $390k ($241k).
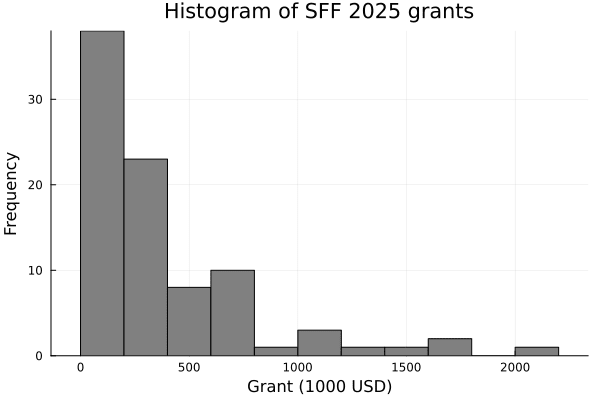
It seems plausible to me that if AGI progress becomes strongly bottlenecked on architecture design or hyperparameter search, a more "genetic algorithm"-like approach will follow. Automated AI researchers could run and evaluate many small experiments in parallel, covering a vast hyperparameter space. If small experiments are generally predictive of larger experiments (and they seem to be, a la scaling laws) and model inference costs are cheap enough, this parallelized approach might be be 1) computationally affordable and 2) successful at overcoming the architecture bottleneck.
6
My vague understanding is this is kinda what capabilities progress ends up looking like in big labs. Lots of very small experiments playing around with various parameters people with a track-record of good heuristics in this space feel should be played around with. Then a slow scale up to bigger and bigger models and then you combine everything together & "push to main" on the next big model run.
I'd also guess that the bottleneck isn't so much on the number of people playing around with the parameters, but much more on good heuristics regarding which parameters to play around with.
3
This Dwarkesh timestamp with Jeff Dean & Noam Shazeer seems to confirm this.
[...]
That would mostly explain this question as well: "If parallelized experimentation drives so much algorithmic progress, why doesn't gdm just hire hundreds of researchers, each with small compute budgets, to run these experiments?"
It would also imply that it would be a big deal if they had an AI with good heuristics for this kind of thing.
4
Don’t double update! I got that information from that same interview!
5
I expect mech interp to be particularly easy to automate at scale. If mech interp has capabilities externalities (e.g., uncovering useful learned algorithms or "retargeting the search"), this could facilitate rapid performance improvements.
Update on MATS applications trends:
- Mentor applications seem to be growing 2.2x/year and we accepted 20% as primary mentors for 10.0 (Summer 2026).
- Fellow applications seem to be growing 1.8x/year (counting only applicants who applied to at least one mentor) and we plan to accept 5% for 10.0.
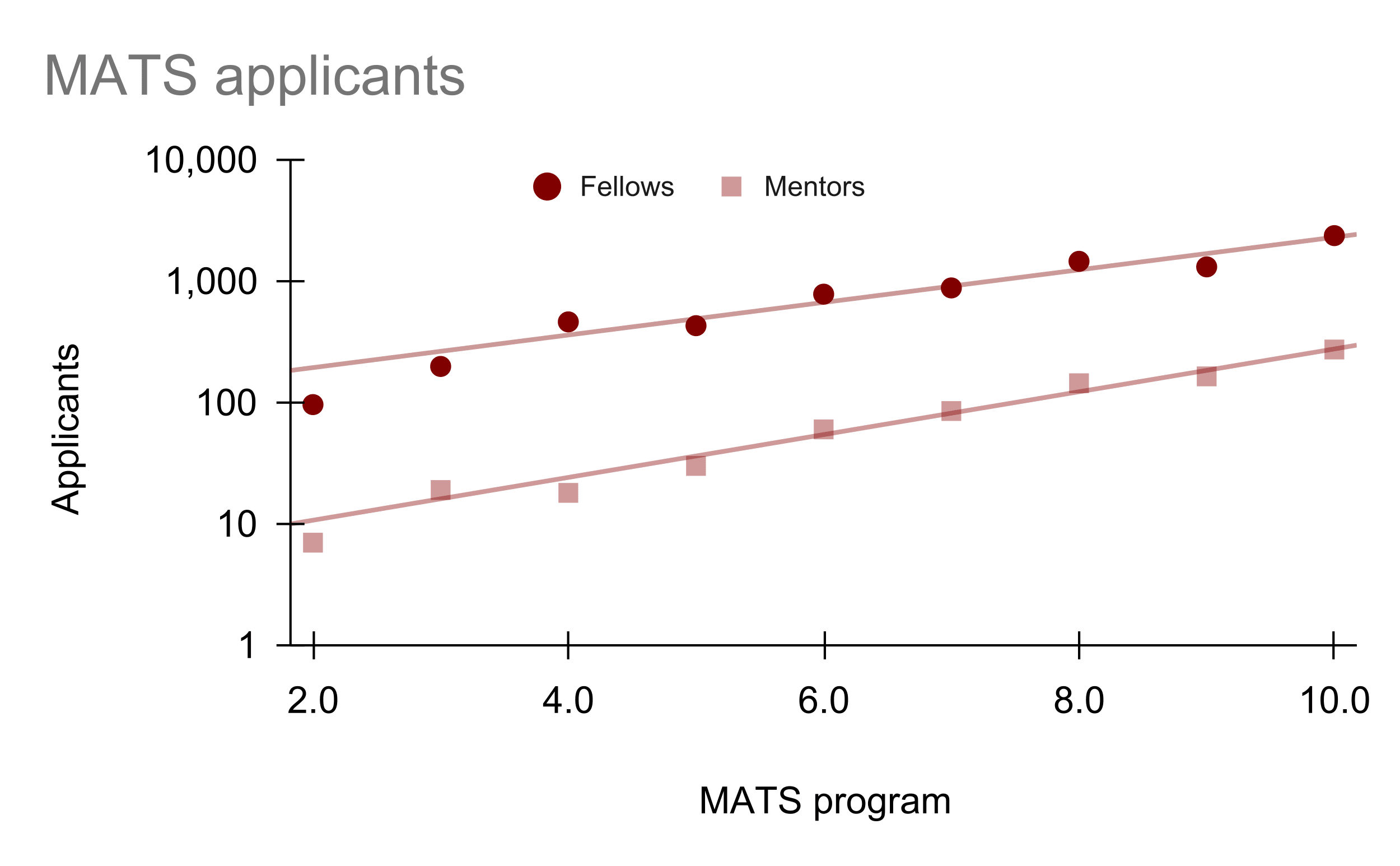
2
Interesting. Do you have the stats for the rate of growth in the number of mentors meeting your bar (ignoring capacity constraints, ie that you think would be a good mentor)? I'm surprised the rate of growth there is higher and I'm not sure if this is MATS becoming higher profile and drawing in more existing mentors, more people who are not suitable for being a mentor applying or AI safety actually making progress on the mentorship bottleneck
5
This is a hard question to answer precisely, as we have changed the metrics by which we have evaluated potential mentors several times. The average quality of mentors we accept has grown each program, by my lights. I weakly think that the average quality of mentors applying has also grown, though much slower.
3
I think that the distribution of mentors we are drawing from is slowing growing to include more highly respected academics and industry professionals by percentage. I think this increases the average quality of our mentor applicant pool, but I understand that this is might be controversial. Note that I still think our most impactful mentors are well-known within the AI safety field and most of the top-50 most impactful researchers in AI safety apply to mentor at MATS.
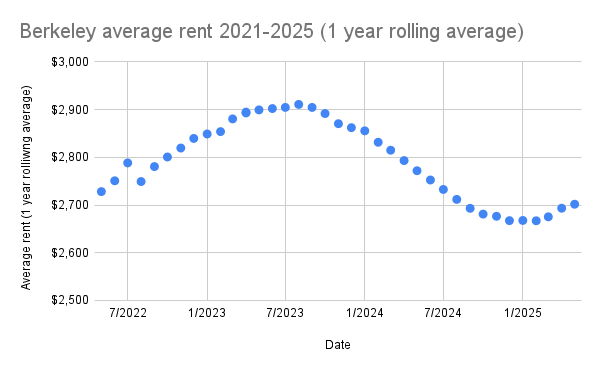
Not sure this is interesting to anyone, but I compiled Zillow's data on 2021-2025 Berkeley average rent prices recently, to help with rent negotiation. I did not adjust for inflation; these are the raw averages at each time.
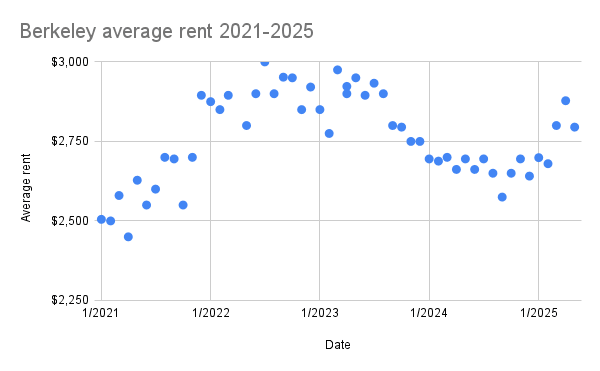
An incomplete list of possibly useful AI safety research:
- Predicting/shaping emergent systems (“physics”)
- Learning theory (e.g., shard theory, causal incentives)
- Regularizers (e.g., speed priors)
- Embedded agency (e.g., infra-Bayesianism, finite factored sets)
- Decision theory (e.g., timeless decision theory, cooperative bargaining theory, acausal trade)
- Model evaluation (“biology”)
- Capabilities evaluation (e.g., survive-and-spread, hacking)
- Red-teaming alignment techniques
- Demonstrations of emergent properties/behavior (e.g., instrumental powerseeking)
- Interpretabili
3
A systematic way for classifying AI safety work could use a matrix, where one dimension is the system level:
* A monolithic AI system, e.g., a conversational LLM
* A cyborg, human + AI(s)
* A system of AIs with emergent qualities (e.g., https://numer.ai/, but in the future, we may see more systems like this, operating on a larger scope, up to fully automatic AI economy; or a swarm of CoEms automating science)
* A human+AI group, community, or society (scale-free consideration, supports arbitrary fractal nestedness): collective intelligence
* The whole civilisation, e.g., Open Agency Architecture
Another dimension is the "time" of consideration:
* Design time: research into how the corresponding system should be designed (engineered, organised): considering its functional ("capability", quality of decisions) properties, adversarial robustness (= misuse safety, memetic virus security), and security.
* Manufacturing and deployment time: research into how to create the desired designs of systems successfully and safely:
* AI training and monitoring of training runs.
* Offline alignment of AIs during (or after) training.
* AI strategy (= research into how to transition into the desirable civilisational state = design).
* Designing upskilling and educational programs for people to become cyborgs is also here (= designing efficient procedures for manufacturing cyborgs out of people and AIs).
* Operations time: ongoing (online) alignment of systems on all levels to each other, ongoing monitoring, inspection, anomaly detection, and governance.
* Evolutionary time: research into how the (evolutionary lineages of) systems at the given level evolve long-term:
* How the human psyche evolves when it is in a cyborg
* How humans will evolve over generations as cyborgs
* How groups, communities, and society evolve.
* Designing feedback systems that don't let systems "drift" into undesired state over evolutionary time.
* Considering system prop
AI alignment threat models that are somewhat MECE (but not quite):
- We get what we measure (models converge to the human++ simulator and build a Potemkin village world without being deceptive consequentialists);
- Optimization daemon (deceptive consequentialist with a non-myopic utility function arises in training and does gradient hacking, buries trojans and obfuscates cognition to circumvent interpretability tools, "unboxes" itself, executes a "treacherous turn" when deployed, coordinates with auditors and future instances of itself, etc.);
- Coordination failur
2
Great overview! I find this helpful.
Next to intrinsic optimisation daemons that arise through training internal to hardware, suggest adding extrinsic optimising "divergent ecosystems" that arise through deployment and gradual co-option of (phenotypic) functionality within the larger outside world.
AI Safety so far research has focussed more on internal code (particularly CS/ML researchers) computed deterministically (within known statespaces, as mathematicians like to represent). That is, rather than complex external feedback loops that are uncomputable – given Good Regulator Theorem limits and the inherent noise interference on signals propagating through the environment (as would be intuitive for some biologists and non-linear dynamics theorists).
So extrinsic optimisation is easier for researchers in our community to overlook. See this related paper by a physicist studying origins of life.
1
Cheers, Remmelt! I'm glad it was useful.
I think the extrinsic optimization you describe is what I'm pointing toward with the label "coordination failures," which might properly be labeled "alignment failures arising uniquely through the interactions of multiple actors who, if deployed alone, would be considered aligned."
Reasons that scaling labs might be motivated to sign onto AI safety standards:
- Companies who are wary of being sued for unsafe deployment that causes harm might want to be able to prove that they credibly did their best to prevent harm.
- Big tech companies like Google might not want to risk premature deployment, but might feel forced to if smaller companies with less to lose undercut their "search" market. Standards that prevent unsafe deployment fix this.
However, AI companies that don’t believe in AGI x-risk might tolerate higher x-risk than ideal safet...
How fast should the field of AI safety grow? An attempt at grounding this question in some predictions.
- Ryan Greenblatt seems to think we can get a 30x speed-up in AI R&D using near-term, plausibly safe AI systems; assume every AIS researcher can be 30x’d by Alignment MVPs
- Tom Davidson thinks we have <3 years from 20%-AI to 100%-AI; assume we have ~3 years to align AGI with the aid of Alignment MVPs
- Assume the hardness of aligning TAI is equivalent to the Apollo Program (90k engineer/scientist FTEs x 9 years = 810k FTE-years); therefore, we need ~
I appreciate the spirit of this type of calculation, but think that it's a bit too wacky to be that informative. I think that it's a bit of a stretch to string these numbers together. E.g. I think Ryan and Tom's predictions are inconsistent, and I think that it's weird to identify 100%-AI as the point where we need to have "solved the alignment problem", and I think that it's weird to use the Apollo/Manhattan program as an estimate of work required. (I also don't know what your Manhattan project numbers mean: I thought there were more like 2.5k scientists/engineers at Los Alamos, and most of the people elsewhere were purifying nuclear material)
5
There's the standard software engineer response of "You cannot make a baby in 1 month with 9 pregnant women". If you don't have a term in this calculation for the amount of research hours that must be done serially vs the amount of research hours that can be done in parallel, then it will always seem like we have too few people, and should invest vastly more in growth growth growth!
If you find that actually your constraint is serial research output, then you still may conclude you need a lot of people, but you will sacrifice a reasonable amount of growth speed for attracting better serial researchers.
(Possibly this shakes out to mathematicians and physicists, but I don't want to bring that conversation into here)
3
I also note that 30x seems like an under-estimate to me, but also too simplified. AIs will make some tasks vastly easier, but won't help too much with other tasks. We will have a new set of bottlenecks once we reach the "AIs vastly helping with your work" phase. The question to ask is "what will the new bottlenecks be, and who do we have to hire to be prepared for them?"
If you are uncertain, this consideration should lean you much more towards adaptive generalists than the standard academic crop.
Attendees at the top-four AI conferences have been growing at 1.26x/year on average. Data is from Our World in Data. I skipped 2020-2021 for all conferences and 2022 for ICLR, as these conferences were virtual due to the COVID pandemic and had increased virtual attendance.
One could infer from these growth rates that the academic field of AI is growing 1.26x/year. Interestingly, the AI safety field (including technical and governance) seems to be growing at 1.25x/year.
3
Open question: how fast did the field of cybersecurity grow since the launch of the internet?
2
In contrast to the apparent exponential growth in AI conference attendees, the number of AI publications since 2013 has grown quadratically (data from the Standford HAI 2025 AI Index Report). Quadratic growth in publications suggests that a linearly (constantly) increasing number of researchers are producing publications at a linear (constant) rate. Extrapolating a little, this growth rate suggests there will be 3.7M cumulative publications by 2030 (since 2013).
If the AI researcher growth rate is linear, the exponential growth of AI conference attendees might be due to increased industry presence. Also, it's possible that the attendee growth rate is also quadratic.
Types of organizations that conduct alignment research, differentiated by funding model and associated market forces:
- Academic research groups (e.g., Krueger's lab at Cambridge, UC Berkeley CHAI, NYU ARG, MIT AAG);
- Research nonprofits (e.g., ARC Theory, MIRI, FAR AI, Redwood Research);
- "Mixed funding model" organizations:
- "Alignment-as-a-service" organizations, where the product directly contributes to alignment (e.g., Apollo Research, Aligned AI, ARC Evals, Leap Labs);
- "Alignment-on-the-side" organizations, where product revenue helps funds alignment research
Can the strategy of "using surrogate goals to deflect threats" be countered by an enemy agent that learns your true goals and credibly precommits to always defecting (i.e., Prisoner's Dilemma style) if you deploy an agent against it with goals that produce sufficiently different cooperative bargaining equilibria than your true goals would?
3
This is a risk worth considering, yes. It’s possible in principle to avoid this problem by “committing” (to the extent that humans can do this) to both (1) train the agent to make the desired tradeoffs between the surrogate goal and original goal, and (2) not train the agent to use a more hawkish bargaining policy than it would’ve had without surrogate goal training. (And to the extent that humans can’t make this commitment, i.e., we make honest mistakes in (2), the other agent doesn’t have an incentive to punish those mistakes.)
If the developers do both these things credibly—and it's an open research question how feasible this is—surrogate goals should provide a Pareto improvement for the two agents (not a rigorous claim). Safe Pareto improvements are a generalization of this idea.
MATS' goals:
- Find + accelerate high-impact research scholars:
- Pair scholars with research mentors via specialized mentor-generated selection questions (visible on our website);
- Provide a thriving academic community for research collaboration, peer feedback, and social networking;
- Develop scholars according to the “T-model of research” (breadth/depth/epistemology);
- Offer opt-in curriculum elements, including seminars, research strategy workshops, 1-1 researcher unblocking support, peer study groups, and networking events;
- Support high-impact&n
"Why suicide doesn't seem reflectively rational, assuming my preferences are somewhat unknown to me," OR "Why me-CEV is probably not going to end itself":
- Self-preservation is a convergent instrumental goal for many goals.
- Most systems of ordered preferences that naturally exhibit self-preservation probably also exhibit self-preservation in the reflectively coherent pursuit of unified preferences (i.e., CEV).
- If I desire to end myself on examination of the world, this is likely a local hiccup in reflective unification of my preferences, i.e., "failure of pres
Are these framings of gradient hacking, which I previously articulated here, a useful categorization?
...
- Masking: Introducing a countervailing, “artificial” performance penalty that “masks” the performance benefits of ML modifications that do well on the SGD objective, but not on the mesa-objective;
- Spoofing: Withholding performance gains until the implementation of certain ML modifications that are desirable to the mesa-objective; and
- Steering: In a reinforcement learning context, selectively sampling environmental states that will either leave the mesa-objecti
How does the failure rate of a hierarchy of auditors scale with the hierarchy depth, if the auditors can inspect all auditors below their level?