Can you make the relevance of this research more tangible by giving an informal example of Alice and Bob "observing" two different correlated variables, as well as a shared "latent variable"? I have difficulty imagining what those variables would model in practice.
Thanks for the question, I should have been thinking more about pedagogy. Consider a situation where Alice and Bob have two different camera feeds observing the same room, as below.
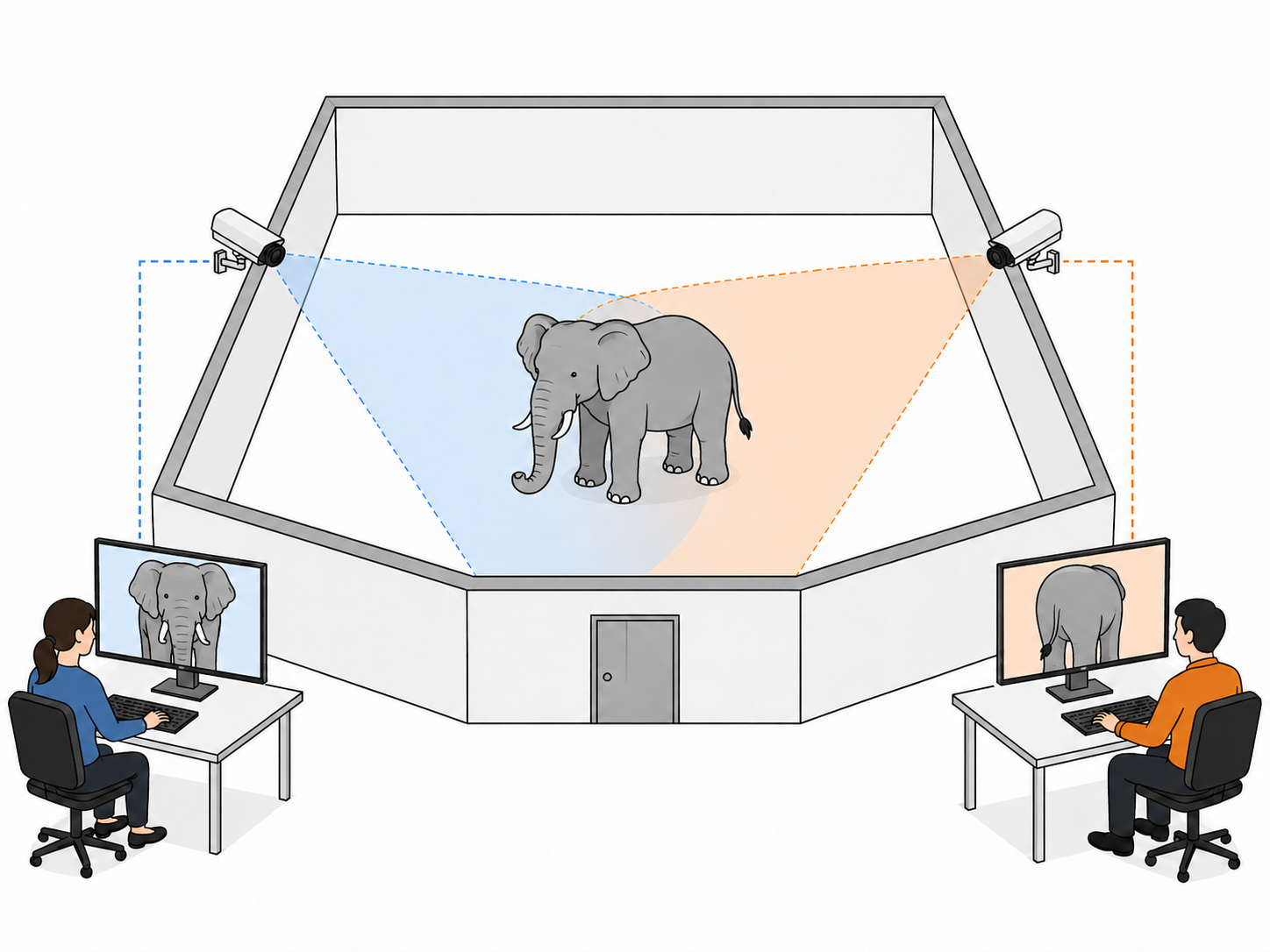
Alice's feed is
Gács–Körner asks if Alice and Bob can each apply some function to their own camera feed—without communicating—and be certain they get the same answer? The answer is basically no. Alice sees the front of the elephant; Bob sees the back. Any image Alice sees is compatible with many possible images on Bob's screen, and vice versa, because the feeds are a lossy projection of the underlying latent. The only functions guaranteed to agree are constant ones which carry no information. That's what
Mutual Information measures how much one feed tells you about the other statistically. In this example, MI is large: if Alice see the front of an elephant through her feed, she can infer a lot about what Bob's feed should look like. It quantifies how many bits of uncertainty about Bob's feed get eliminated by seeing Alice's.
Wyner asks: what's the simplest explanation that fully accounts for the correlation? I.e., what variable
I just published another post, the introduction to my research direction, where I talk about why I think this is relevant!
Read the introduction for the motivation.
This is the first content post in a planned cluster on exact results for natural latents. Here, I connect some established results in classical information theory to natural latents.
Suppose Alice observes
It turns out "the thing they share" has two classical formalizations in information theory, they disagree with each other, and they both disagree with mutual information. The specific pattern of this disagreement is (I claim at the end) exactly the subject matter of natural latents.
This post is a quick introduction.
What can both parties extract? (Gács–Körner, 1973)
The most literal reading of "the thing they share" is a random variable
The Gács–Körner common information
There's a nice picture of what
The only extractable common randomness is the name of the connected component they already know they are in. This immediately reveals the property that makes
Worked Example: Brittleness
Let
ε
0
1 bit
1.000 bits
0.01
0 bits
0.955 bits
0.1
0 bits
0.714 bits
At ε = 0 the shared bit is extractable and
One percent noise destroys extractable common structure entirely, while destroying almost none of the statistical common structure.
This is essentially the tiny-mixtures problem. It's why the natural latents framework had to be built on approximations. Exact common variables are measure-zero objects.
What does it take to simulate the correlation? (Wyner, 1975)
Wyner approaches "the thing they share" from the opposite direction. Instead of asking what can be extracted from the correlation, ask what it takes to simulate it: find a latent
The Wyner common information is
In natural-latents language, this should look familiar: the constraint is exactly zero mediation error. Wyner's quantity is the minimum complexity of an exact mediator.
Notice
Worked Example: Binary
Let
The optimal mediator is pretty: let
where
quantity
value
0 bits
0.531 bits
0.873 bits
So for a 10%-noisy bit: nothing is extractable, ~half a bit is shared statistically, and ~7/8 of a bit is needed to explain the sharing.
Worked Example: Gaussian
Consider unit-variance jointly Gaussian
The optimal mediator is a
Then the mediation is exact by construction, and the complexity works out to
At
As
The sandwich, and when there's actually a "thing"
So we have, for every pair of variables,
with both gaps typically open. When does the sandwich collapse? Exactly when there's a variable
The collapse condition is structurally fragile. It requires the support to decompose and the dependence to be carried entirely by the decomposition. Generic distributions, and all nondegenerate Gaussian ones, fail it. "The thing two variables share" does not, in general, exist; what exist are the two ends of a sandwich and the gap between them.
The sandwich is the natural latents problem
Recall the natural latent conditions on a latent
I think this demonstrates why the natural latents framework is necessarily a theory of approximation: exact objects require the collapse of an inequality that is generically open. I claim this sharpens the question the framework needs answered. If exact naturality means sitting at both ends at once, then approximate naturality is about how close you can get to both ends at once, and the two gaps become two error floors:
Pointers
Gács & Körner (1973) and Wyner (1975) of course; Witsenhausen (1975) for the maximal-correlation characterization of common variables; the bivariate Gaussian
Next post: Approximate Natural Latents have Exact Prices.
I share a short script (linked at the end) that reproduces the numerics of all worked examples in this post.
Convention note: in this post, logarithms are base 2 throughout. All quantities are in bits.