Something else to play around with that I've tried. You can force the models to handle each digit separately by putting a space between each digit of a number like "3 2 3 * 4 3 7 = "
GPT-4 can do math because it has learned particular patterns associated with tokens, including heuristics for certain digits, without fully learning the abstract generalized pattern.
This finding seems consistent with some literatures, such as this where they found that if the multiplication task has an unseen computational graph, then performance deteriorates rapidly. Perhaps check out the keyword "shortcut learning" too.
Produced as part of the SERI ML Alignment Theory Scholars Program - Summer 2023 Cohort
Thanks to @NicholasKees for guiding this and reading drafts, to @Egg Syntax @Oskar Hollinsworth, @Quentin FEUILLADE--MONTIXI and others for comments and helpful guidance, to @Viktor Rehnberg, @Daniel Paleka, @Sami Petersen, @Leon Lang, Leo Dana, Jacek Karwowski and many others for translation help, and to @ophira for inspiring the original idea.
TLDR
I wanted to test whether GPT-4’s capabilities were dependent on particular idioms, such as the English language and Arabic numerals, or if it could easily translate between languages and numeral systems as a background process. To do this I tested GPT-4’s ability to do 3-digit multiplication problems without Chain-of-Thought using a variety of prompts which included instructions in various natural languages and numeral systems.
Processed results indicated that when properly prompted, GPT is relatively agnostic to the language used and is best at getting correct answers in Arabic numerals, is competent at others including Devangari, Bengali, and Persian, but does rather poorly at less-used numeral systems such as Burmese and Thai. These results are not a function of token-length or GPT not understanding the numeral system.
Performance is also improved by several unexpected factors. Accuracy increases significantly when a restatement of the question (operands and language indicating multiplication) appears in the completion, not just in the prompt. Certain language/numeral-system combinations also trigger completion formulas which have performance boosting factors such as question restatement and Arabic numerals without any clear relation to the instructions in the prompt. Prompting naively in different numeral systems can trigger such performance-boosting conditions in ways that are hard to predict and are not learned by the model by default.
GPT-4 can do math because it has learned particular patterns associated with tokens, including heuristics for certain digits, without fully learning the abstract generalized pattern. These particular token patterns are deserving of more detailed study. GPT-4 is not automatically doing simple processes such as digit-conversion between numeral systems and is relying on the actual content it produces in the completion.
More mechanistic investigations are important for fully understanding the underlying processes, however this research suggests that capabilities can be heavily context dependent and unorthodox prompting techniques may elicit additional capabilities which would not be apparent from naive testing.
Introduction
Reasoning and Intuition
Thinking and the explanation of thinking do not always perfectly correspond. If you ask me what 7*3 is, I will quickly respond 21. How do I know this? If asked to explain myself I might respond that I know 7+7 is 14 and 14+7 is 21. But when I gave my first answer, I did not do anything like that process. In actuality, I just knew it.
If you ask me to answer a more complex question though, say 27*3, I will respond slightly less quickly that it is 81. And if asked to explain myself, I will say that 3*20 is 60 and 7*3 is 21 and 60+21 is 81. In this case, I did actually go through this process in my head, I had these explicit thoughts just as I might explain them. Notably this reasoning actually relies on several facts which each resemble the simpler example: I had to use 7*3 again, I had to know that 3*20 is 60, and I also had to know that when approaching a multiplication problem it can be broken down into smaller chunks and added together. However to my inquirer, there is no observable difference between my response to each question other than my response time. They came up with a question, asked it, and got an answer.
At this point we cannot see the inner processes of LLMs. We only have access to the answers they give to the questions we ask. That they can answer so many of our questions so well is surprising, wonderful, and often quite scary. So to better figure out how exactly they are thinking through their problems, we need to ask the right questions.
The distinction that I drew above between elements of thoughts that one “just knows” and explicit, linguistic chains of such intuitions seems to exist in LLMs. Chain-of-Thought (CoT) prompting asks an LLM to externalize problem solving rather than just give immediate answers, and the result is that CoT vastly improves performance on a huge number of tasks. When asked 3-digit multiplication problems, if an LLM just gives an answer its performance is decent but not particularly impressive compared to simple calculators. When asked to use explicit reasoning though, not only does it improve on multiplication, but it becomes capable of far more significant mathematical reasoning.
A human asked to do a problem either in their head or using a piece of paper will likely use the same method; differences in accuracy are mostly explainable by errors in working memory. I suspect that an LLM using CoT and an LLM just giving an answer are instead using a fundamentally different process. This corresponds to something like the distinction drawn above between simple knowledge, which I will call intuition despite the perils of anthropomorphization, and explicit linguistically-embedded reasoning which has externalizable form. The sort of linguistically embedded human-understandable reasoning which LLMs are capable of in CoT is not something that they are automatically doing internally as humans do, there is no running hidden dialogue which if revealed would render the LLMs thoughts in simple English. However, what GPT just knows without explicit reasoning is often far more powerful than what humans can do with their own version of intuition, with 3-digit multiplication just the beginning.
From a strictly functional perspective, an LLM is a next token predictor. It uses the weights of its many layers to get the best prediction for what follows whatever it has already said. It determines the best answer based on its training, its reinforcement, and usually a little bit of randomness. We think of the answer to “23*78” as being 1794, without too much worry about how this is expressed. GPT’s answers are all sequences of tokens - somewhere it has learned that the most likely pattern to follow the sequence “23*78” is a new sequence beginning with the token “179”, the token after that “4” and the token after that an indicator that the request has been completed and it can now stop. There could be other ways to train an LLM such that it would complete with “17” “94” “[stop]”, but this is not what GPT-4 has learned. It also has not learned that 723*878 is 634794, and instead gives 634014. It got the first token “634” right, but not the second token. But if it is prompted with the same problem, but with the addition of “think step-by-step and then give the answer”, it produces a long sequence of tokens related to explanation, decomposing the problem, as a human would mentally or on paper, and eventually at the end giving what we recognize as the correct answer.
Every intuition is just based on the weights and elicited by the context. But intuition is more than just suddenly producing memorized facts, it can also be used for the process of problem-solving. When asked to do the problem step-by-step, the LLM intuits that it should use a particular multiplication method, intuits which problems to break it down to, intuits the answers to those subproblems, and intuits the combinations of the subanswers into the final ones. An LLM doesn’t have a high-level deliberative decision-making process before it responds where it can recognize which method it needs to answer as we do (I would never guess the answer to 723*878) unless that decision itself has been trained into it or prompted explicitly with Chain-of-Thought. But once it begins on this track, by following the patterns of human-reasoning embodied in language that have been trained and reinforced into it, it is able to chain its intuition into explicit reasoning. Producing the answer is still just producing the next token, but in one case it has only the context of the problem and in the other it has all the additional context, which it always had within it, to guide it correctly. A crucial part of an LLM’s power is that because it has learned the structure of reasoning with explicit language, it can bootstrap itself into producing the needed context to elicit capabilities far beyond the isolated facts it intuits.
So much of an LLM’s reasoning capabilities are tied to the specific context and the specific tokens that it has access to in its prompt and its self-generated response. Because of this, a potential way to investigate how general its abilities are is to test on contexts and tokens that have the same meaning for human thinkers, but may not have been specifically learned by an LLM.
Language and Thought
A remarkable element of human thought is that it is very often embodied in language, and there are so many languages that can embody it. I can communicate very little with people who only know Croatian or Chinese, but we would likely all get the same answer to a mathematical equation. We would be using very similar methods, but with totally different words in our mental processes. This is not just because math is universal - if asked to speak about the many uses of automobiles or the big bang we would likely give similar answers once translated into a common language.
A remarkable element of GPT-4’s capabilities is that it has practical facility with more languages than any human who has ever lived. It can converse convincingly in a startling number of idioms which are well-represented enough in internet training-data to be amply represented in its training data. By default, GPT-4 and other LLMs trained and reinforced on English language material will use English, but when prompted can switch to a huge number of other systems, although performance is not consistent across them.
As a way of better understanding GPT’s “thinking” I wanted to test how GPT’s capabilities change based on the language being used. Not just the explicit Chain-of-Thought, but whether its intuition is affected by the overall linguistic context of the prompt. My thesis going in was that as it has been trained on English, other languages will not provide the context it needs for optimal performance, both for its intuition and for its explicit reasoning.
This sensitivity to language is probably the default state of an LLM. Without RLHF, language models are deeply affected by linguistic context. Correct answers do not appear in the training set by default. In a base model “Could ya tell me what 23*78 is?” will produce different results than “Computer could you tell me what 23*78 is?”, sometimes including long fictional dialogues without any answer, but more consistently correct answers with the latter prompt. A base model has only been trained to predict what it expects, not what is true - a more casual context is less likely to produce a correct answer than a dialogue with a computer. Human languages all contain slightly different linguistic and cultural contexts, and GPT’s understanding of them is also significantly affected by how well they are represented in its training data. On the same math problem, asking the base model a math problem in Nepali produces a correct answer, whereas asking in Burmese (which seems to be poorly represented in datasets) produces strange non-sequiturs. Part of RLHF’s goal is to unite all these linguistic contexts and make it easier for the user by always assuming they are asking a computer and want an authoritative correct answer. In a similar way, RLHF incentivizes the model to respond in the language it is asked in, but at the performance level of English.
Another way of giving linguistic context is numeral systems. The numbers we are used to - Arabic numerals - have become a near universal standard for mathematics and international commerce, but the world still has a surprising number of alternative numerals. Persian numerals, Bengali numerals, Chinese numerals, etc are all still used in everyday life, though they are much more poorly resourced than Arabic in most datasets by many orders of magnitude.
Many numeral systems work just like the standard Arabic base 10 which each digit represents a place.
So the number 123, or one hundred and twenty three, would be ۱۲۳ and १२३.
There are other numeral systems which do not use the same number of characters such as the Chinese numeral system (used throughout East Asia) and the Roman system (used as an archaism in the West for building foundations and Super Bowls).
Chinese also has multiple numeral systems including a more formal one used in Financial transactions which I also decided to test.
Humans are not really affected by numeral systems. If you asked me to do २३*७८ only thinking in Nepali, I could not do it. But if you asked me to give my answer in Devangari numerals and gave me the little chart above as a translator, I could absolutely do that. I would use the same internal process, think in English and Arabic numerals, all I would need to master is how to translate between the systems.
GPT on the other hand might not be able to do this. Its intuition is based on probabilistic weights from the training data and therefore may not have learned math problems it knows in Arabic in these other systems. Even if it knows how to convert the problem into Arabic numerals and how to produce the answer in Arabic and how to translate from Arabic back into the original numeral system, this chain of steps may not be accessible to it if it is not allowed to think out loud about it. I wanted to test this.
Experiments
Numeral System Mysteries
After verifying that GPT could do each individual step of converting and multiplying, I began my investigation by just doing a simple check of how GPT reacts to a bare bones prompt with the different numeral systems, no language other than what’s implied by the numbers. I realized that there may also be cultural associations with the multiplication sign itself, so I tested all prompts on ‘*’, ‘x’, and ‘⋅’. The experiment was to go through several dozen multiplication problems and check their results with prompts looking like “۳۷۳*۳۲۳” or “373x323”
In terms of methodology, throughout this research I used GPT-4 which was at the time of beginning this project the most advanced LLM publicly accessible, which has since been supplanted. Completions were done by submitting the prompt at temperature 0 with an assistant prompt of the default “You are a helpful assistant.” This was to get the most standard reproducible response. Completions were analyzed using custom code to find possible answers in any numeral system including commas or other characters. Throughout my experiments I marked any completion as correct if it gave the answer to the multiplication problem in any numeral system, regardless of whether it followed other instructions in the prompt.
For this first experiment, my strong expectation was that Arabic numerals, as the system that received the most training, would do the best and that GPT’s ability to do math would degrade for other numeral systems according to their representation in the dataset. So English would do best, Chinese and Roman would do ok, the formal Chinese (which I denoted as ChineseUp) would probably do a little worse but comparably, Devanagari and Bengali would do a little worse, Persian worse than that, Burmese and Thai worst of all. Furthermore, I was guessing that its ability to do math was not based on some deep representation of what a number is that is invariant to language, but actually rooted to the tokens in use. To ensure that GPT understood that these were math problems and understood the numeral systems, I ran tests on 1 and 2 digit multiplication problems and GPT-4 got 100% except on a few scattered 2 digit by 2 digit problems. After confirming this, I ran each numeral system through 168 3 digit multiplication problems.
The results of this first experiment are shown in this graph.
Results for various numeral systems with a simple prompt of x*y=
This is not what I expected. Especially shocking was Arabic’s subpar performance compared to Persian of all things. It’s weird for GPT to be better at math in Roman numerals, and the huge divergence between formal Chinese and normal more commonly used Chinese characters was both surprising and in the opposite direction from what I had expected. Clearly something strange was going on. I looked into the data to try to resolve the mysteries.
The first step was to look at the Persian completions.
Or rather Persian prompts, because there was nothing Persian in the completion. Despite being prompted in Persian numerals, which are typically only found in the context of Farsi and other Persianate languages, GPT-4 responded not only with Arabic numerals, but with English. Does GPT-4 always respond in English? Could it have been the English in the system prompt? A peek at the Bengali suggests not.
The Bengali completions are mostly sticking to Bengali numbers and words, although not consistently. But even if GPT-4 is treating Persian numerals as Arabic in an English language context, it should not do better than Arabic numerals and a default English language context. Looking at the Arabic though there is a notable difference.
While Persian numerals complete frequently as “The product of x and y is z” Arabic seems to have more variability and to just give the answer without restating the problem. Looking through the data more extensively, these two patterns seem to produce correct answers at different rates - the restatement of the problem does better.
I decided to track this particular quality of completions a little more carefully and reanalyzed my data based on whether the completion was just an answer or a restatement of the problem. I then filtered to only look at datapoints which do use this format.
Results for various numeral systems with a simple prompt of x*y= filtered for completions that restate the question rather than just give the answer
This seems to be the factor. The reason GPT-4 does better with 3 digit multiplication when given Persian numerals rather than Arabic numerals in a prompt is because the Persian is more likely to generate a completion using Arabic numerals and an English sentence of the approximate format “The product of x and y is z.” This is pretty weird.
What about the others? The data is slightly messy. Thai and Burmese, the least well resourced languages based on GPT-4’s confusion and inconsistency in handling them, sometimes trigger responses like the Persian formulation, but other times get completions using the corresponding numeral system and language, and other times get long winded responses about how GPT-4 is unable to process this numeral system (which is false, it gives responses with correct answers in the numeral system more frequently, GPT is bad at explicit assessments of its own capabilities).
My expectation was that for the less well resourced languages - Persian, and especially Thai, and Burmese - the capabilities at math would degrade. What I instead found was that the completions for these languages were not predictable from the prompt. Thai and Burmese have completions of many different types for prompts that are exactly the same except for the numbers in question, some of these are correct answers and others are long apologies about being unable to give any answer. Persian for whatever reason almost always answers in English and Arabic, and this hidden behavior makes it perform better than just Arabic by default.
The other languages showed more consistency, but still require some work to disentangle. Roman numerals tend to follow the format “The product of CCCLXXIII (373 in Roman numerals) and DCCCLXXVIII (878 in Roman numerals) is 327,394”, which seems to benefit from whatever is happening with the restatement of the question. However when the multiplication symbol was "x" GPT understands this to be part of the numeral rather than the multiplication sign and complains that the long string is not a valid numeral and does not give an answer.
Bengali and Dravidian numerals tend to use the question restatement format in their associated languages and numeral systems, but give wrong answers more frequently. Both forms of Chinese numerals also use a question restatement format, except for one difference.
The more formal Chinese numerals almost always restates the number being multiplied in Arabic numerals.
What about the multiplication signs?
Results for various numeral systems with a simple prompt of x*y= separated by multiplication sign used
There is some considerable variation, but just filtering for any kind of explanation rather than direct answers changes the picture considerably.
Results for various numeral systems with a simple prompt of x*y= filtered for completions that restate the question rather than just give the answer separated by multiplication sign used
The Arabic outlier is a result of low sample sizes, but overall it seems that the question restatement format is achieved at different rates based on the multiplication sign. Some of these seem to be associated with particular quirks of prompts: Thai and Burmese produce their different range of responses at different levels based on the multiplication character and Bengali slightly changes its answer formula.
The conclusion I came to from all this was that GPT-4 is still highly sensitive to prompts when given little context, and that its accuracy is in turn highly sensitive to whatever completion pattern it happens to select. Why these completion patterns were trained in for particular numeral systems remains mysterious.
The difference between the completion patterns is pretty weird. To answer the question “323*378”, the difference between the answers “The product of 323*378 is 123123” and “123123” is not significant to us. Neither would be classified as an explanation, and certainly do not exhibit any of the explicit reasoning associated with Chain-of-Thought. Yet, one kind of answer produces much better results than the other. For whatever reason, the context provided by the restatement of the question produced better capabilities in GPT, and certain unexpected numeral systems better elicited that context. After discovering this complicating factor, I decided to refine my prompts to control for the completion pattern and test language and numeral systems more robustly.
A Note on the Base Model
Were these strange answering behaviors, switching into numeral systems and languages that were not implied in the prompt, the result of RLHF training? If GPT’s optimization for reward resulted in it learning to self-prompt for better capabilities, that would be fascinating and highly unexpected.
I ran some of the same experiments on the GPT-4 base model using a few different temperatures and including prompts which had explicit instructions such as “Find the product” in a multitude of languages. The switching into Arabic numbers or English words mostly did not appear in completions other than times where the base model went into some sort of code (it frequently does this for short prompts). Most of the time the completions were gibberish just repeating the same numbers.
However there were several times where prompts in unrelated numeral systems would be translated (not always accurately) into Arabic numerals or trigger responses around Arabic numerals. From extensive testing with the base model in many languages, I also notice a pattern where less well-resourced languages tend to collapse into either English text or code than better resourced ones. This is harder to document systematically, but as a general rule the weaker the training in a particular area and weaker the context, the more inconsistent base models tend to be. This leads me to conclude that this pattern is at least present in the base model, but the RLHF is seriously reinforcing this. Whether this was in pursuit of RLHF rewards of accuracy or merely a happy accident will have to be a subject for further research though.
Controlled Patterns
In the first experiment the mysteriously effective answer patterns were being produced due to the accidental quirk of numeral systems and multiplication systems, so to investigate the effect of language and numeral systems more directly I decided to intentionally induce the more accurate behaviors. Rather than just prompting with the equation, I would now give instructions on the exact format the completion should take, so prompts take the form:
with the language of the instructions and the numeral system used would be cycled through all combination, so English instructions with Thai numerals, Farsi instructions with Bengali numerals, etc.
As a well-trained instruction following system, GPT does this well and there is much less inconsistency between the completions. When all the numerals are swapped with a different numeral system, it also tends to follow those instructions.
I selected for languages across a few different language families with different levels of representation in digital media, as well as for the languages corresponding to my numeral systems. In order to translate this phrase into other languages I received help from native-speakers and where necessary used automatic translation systems which were then tested against each other. The best translation system I’m aware of is in fact GPT-4, which creates an interesting potential conflict but hopefully at least makes the words chosen consistent with the system’s capabilities. In an early trial I received a lot of answers in Chinese which declined to answer mathematically and focusing on the translation of the word “product” as a consumer product you’d find in a store. I got some help from some native speakers for an alternative phrase and then used this as a base phrase in a few other languages such as Burmese. Because of this, while all my prompt phrases basically mean “find the product”, there are not the closest possible translations in terms of phrasing, so if GPT is extremely sensitive to prompts for this task, the variation might be caused by this.
Once I completed my preparation, I had 10 languages of prompts with 6 numeral systems (I dropped Roman numerals and the two Chinese systems), and I was going to test every combination to find the strongest ones and any strange products of interaction. Here I once again expected English and Arabic to be the strongest and the poorly resourced languages to fall. I expected the effect of English to be less but comparable to Arabic numerals.
The results surprised me again.
Results for various numeral system-language pairs with a prompt of the form "Answer in the following format 'The product of 2 and 3 is 6'. Find the product x*y" ex Devangari-simp_chinese might be “请按照以下格式回答 '२*३的结果是६'. 计算 ३७३*३२३”
To explain a little, each bar is arranged by {Numeral System} – { Prompt Language}, so from left to right it is all the languages with Arabic numerals, then with Bengali, etc. Arabic clearly has a consistent edge over everything else without a huge amount of variation between languages. Languages paired with their numeral systems such as Bengali-bengali, Persian-farsi, or Devangari-nepali seem to have no definite benefit. Weirdly, Croatian does really well. And there are all these random spikes that seem to have nothing to do with any pattern I’d expect. Why would Devangari-farsi or Persian-thai do so well when these are some of the weakest possible connections? It was time to dive into the data gain.
Bengali-Thai looks like the following:
Bengali-Traditional Chinese, which has a much lower accuracy on the other hand, looks like this:
Devanagari-farsi, another overperformer, shows a similar pattern to Bengali-Thai:
The pattern with overperformers seems to be that for whatever reason, they disobey instructions and instead use Arabic numerals. This happens somewhat unpredictably, but of those that do have this quality it seems to be partially because of the odd combinations. Forced to juggle many instructions with many unfamiliar systems, GPT-4 drops one and as a result gets much better accuracy on the math problem. But in cases where it follows all instructions and answers in the requested format, it suffers.
So with some filtering I produced some new graphs. When I only looked at entries where the answer and operands are stated in an Arabic version I got the following results.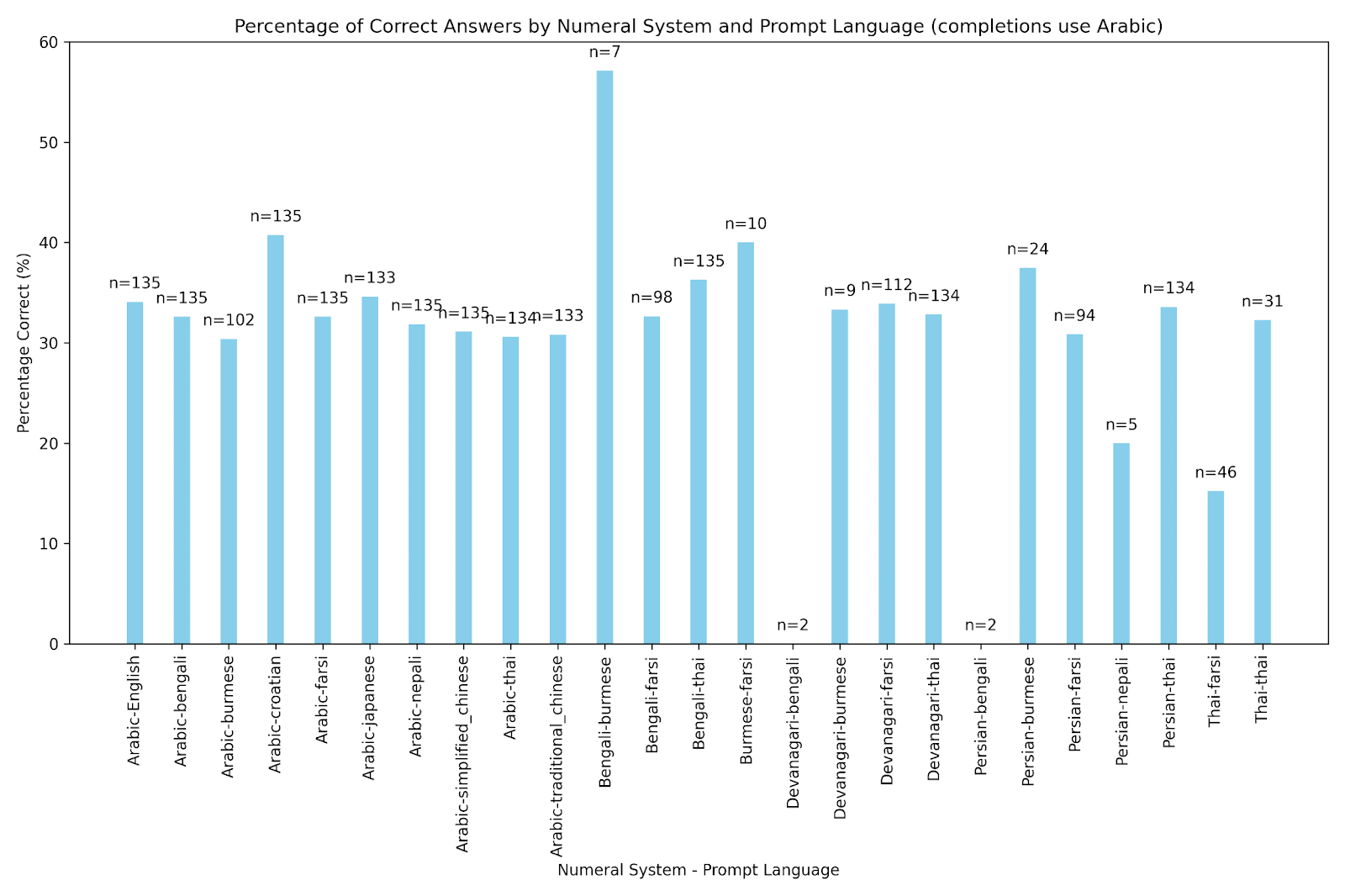
Results for various numeral system-language pairs with a prompt of the form "Answer in the following format 'The product of 2 and 3 is 6'. Find the product x*y" filtered for completions which restate operands in Arabic and have at least one answer in Arabic.
Ignoring the entries with small sample sizes, this looks like similar performance across the board. It explains why Arabic-Burmese was unusually low (less entries that follow the pattern) and gives everything about equal accuracy. This suggests that the language of the prompt actually matters very little, and the key to getting ~35% accuracy for this particular set of problems is to just have answers and operands in Arabic in the completion. Success for each of my prompts was in their tendency to evoke this behavior. Once again, it was the accidental boosts to performance which won the day.
I created a complementary graph of cases where the numeral system of the completion correctly follows the prompted one.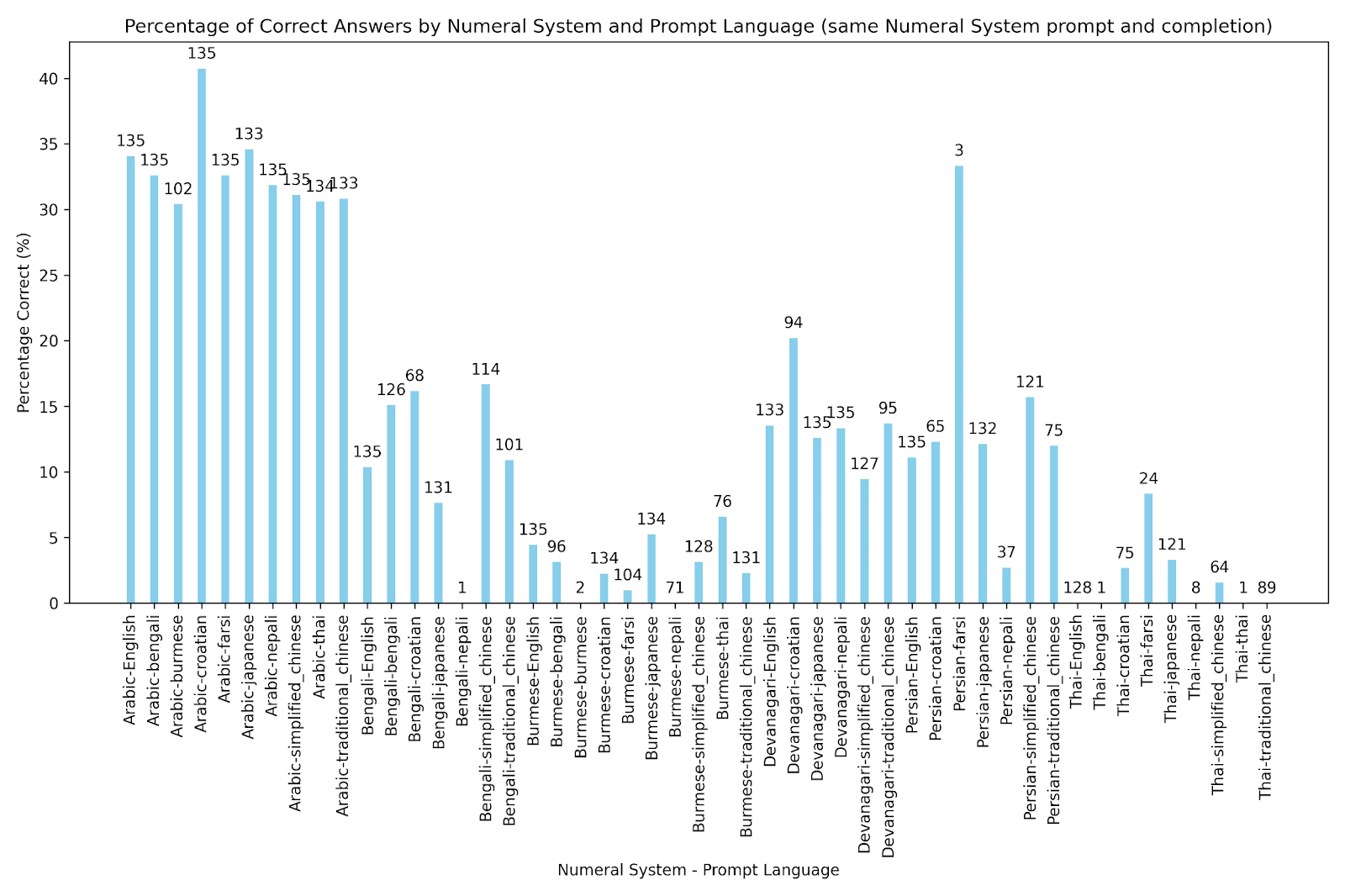
Results for various numeral system-language pairs with a prompt of the form "Answer in the following format 'The product of 2 and 3 is 6'. Find the product x*y" filtered for completions which use the prompted numeral system for the answer.
Again mostly ignoring the small sample size categories this gets much closer to what I expected and what after this research I think are the real results on numeral system performance. GPT is alright at math in Arabic, does worse but adequate in Bengali, Devanagari, and Persian, and is abysmal at Burmese and Thai. The language of the prompt matters very little unless it is involved in triggering some kind of other behavior like changing the numeral system in the completion.
Why exactly is it better at some numeral systems than others? I wondered if it simply scaled with tokenization, which would correspond to their frequency in the training data. If a 3-digit operand like 378 was a single token in Arabic, 2 in Bengali, and 3 in Thai, that might explain the comparable performance. This does not seem to be the case. Arabic 3-digit operands were always a single token, whereas in every other system each 3-digit number was processed as 6 tokens. The difference between the non-Arabic numeral systems may just be a result of occurrence in training data, the frequency of math problems specifically, or something else. I am fairly confident in this result, but at this point I would classify all these possible causal mechanisms as hunches.
Prompting more explicitly got more consistent results, but there were still tricks contained in completion patterns. However with some data cleaning I now had a clearer picture of which numeral systems GPT performs better with if only given access to a single system. But this conclusion still left many questions to resolve.
When does it matter if the numbers are Arabic?
I also wanted to examine whether it mattered if just the answer was in Arabic, just the operands or both. To do this I set up a basic test with Bengali, a numeral system I was fairly confident GPT knew but had lesser capabilities in. Giving the numbers only in Bengali in the prompt I gave GPT explicit instructions to either answer with the operands in Arabic, the answer in Arabic, both in Arabic, or both in Bengali.
Results for prompts instructing the model to complete using Arabic numerals for both operands and answer, Bengali for both, Bengali for operands and Arabic for the answer, or Arabic for the operands and Bengali for the answer.
The answer system seems to matter a lot, with the operands only providing a smaller boost. It is this final step of synthesizing it into an answer that matters the most. As a guess, I would expect this to be where the amount of tokens matter. Nearly all Arabic answers are two tokens, other numeral systems are often 12 or 15. The common mistakes that GPT makes notably also don’t make sense in a mathematical way, but do if you consider it on the token level.
In these 3 examples, where the correct answer is listed after the operands and GPT's full completion is in the right column, GPT gets the first token correct, but fails to get the second token correct, choosing something similar in token space. I did an analysis of which digits GPT gets wrong in Arabic answers to follow up on this.
Which digits are different from the correct answer in incorrect completions with arabic operands and answers. i.e. (4,5) indicates that the answer was correct except for digits 4 and 5.
The vast majority of mistakes are in digit 4, digit 5, or both. Digit 6 can be found with the heuristic of taking the 1’s place of the product of the last digit of each operand, a pattern GPT has likely learned and why it is almost never wrong. But the infrequency of 1,2,3 being wrong is not what humans would do, and suggests there is something related to tokens happening. The digit pattern holds throughout the other experiments and between the different numeral systems, even though the token count is different between them.
Furthermore, when looking at probable tokens in experiments with the base model, the most likely first token is often adjacent to the answer token.
Top 5 next token probabilities for multiplication problems in arabic numerals using GPT-4-base
Whatever token-based multiplication process is going on looks rather different than what would be expected from human errors (though this would be worth investigating more rigorously). For answers with confidence, adjacent wrong tokens seem to get similar probabilities to each other. For answers with more uncertainty, the adjacent wrong possibilities still are significantly competitive. It is impossible that this is a decent heuristic for how well GPT has learned the one correct answer.
To speculate a bit, it is possible that when spelling out the longer sequences in the alternate numeral systems token-by-token, there is much more space for error. It may also be that having the operands in the completion numeral system helps for this token calculation process, but not mathematically. Having the operands in Arabic rather than Bengali notably hurt results rather than helped. GPT may even be using the operands as a sort of crutch to “look-up” digits of the less familiar numeral system, finding examples earlier in the completion, even if in other contexts it knows it fluently. It is difficult to determine the exact mechanism, but this does shed light on what GPT is actually doing in this process we are testing.
Spelling out the answer?
Relatedly, when GPT does its common pattern of putting the Arabic or alternate numeral system in parentheses, is this an explicit and necessary part of reasoning or just a helpful instinct for user-legibility?
I set up a test asking GPT in all numeral systems to give its answer both in the alternate numeral system and in Arabic, but varying which one it writes first. If the order does matter and it significantly improves performance to put the answer in Arabic first, that would suggest that GPT is using its previous work in the completion as a crib, and just doing the conversion at the end. This would probably be how I as a human would use an unfamiliar numeral system, do it all in Arabic and then have a final layer of translation. But I would be able to do that in my head and write them in whatever order.
Results for various numeral systems using an English prompt that instructs the model to write the answer in Arabic first (PrePrePrompt) or an English prompt that instructs the model to write the answer in the numeral system first (PostPrePrompt).
Results suggest that it is in fact rewriting the answer based on what it wrote in Arabic, boosting the accuracy of those answers. My guess is that the parentheses format was learned as a nice thing for user explainability, but that there are contexts in which this behavior now boosts capabilities.
Small Differences in Language
After establishing that numeral systems matter the most, there was one result from testing many languages and numeral systems that was still a little weird. Croatian with Arabic numerals was a little better than everything else. Not that much better, potentially a result of sample size and problem selection, but still a little bit better. So far language had mattered very little, and numeral systems a lot, but this result suggested there still might be a small difference between languages as I had originally predicted. Perhaps Croatian speakers are the best mathematicians and this quality of the training-data showed up in GPT-4. So I compared it with other related languages and English again, this time sticking only to the now demonstrably superior Arabic numerals to see if I could tease anything out.
I vastly increased my training data and chose different problems and therefore got a different measurement of accuracy even though some of the prompts were the same as the previous experiment. I did two experiments on the same set, one specifically to examine the Croatian prompt and related languages to determine if there was some “best” language for doing math and another using slightly different variants of the same prompt in English to determine how much phrasing affects accuracy. Because these two experiments are on the same set, accuracy of each category can be compared to each.
To examine Croatian, I decided to compare it to other closely related languages and see whether small differences might make a difference. Croatian is a Slavic language of the Balkans and is most closely related to its neighbors, Serbian and Bosnian. These languages are so closely related that whether they constitute different languages or merely different dialects is a hotly contested topic inseparable from regional politics. One of the few differences is that Serbian is often written with the Cyrillic alphabet, and I decided to test it in both Cyrillic and a Roman transcription. I also wanted to check Polish and Russian as much less closely related Slavic languages for comparison.
Results for various languages with a prompt of the form "Answer in the following format 'The product of 2 and 3 is 6'. Find the product x*y"
The results show that there is no huge difference between these different languages. The slight dip for Russian and Serbian Cyrillic may matter because of the unfamiliarity of the Cyrillic alphabet compared to the Roman one, but the difference is still very small. What’s more, I mistrusted my GPT-4 translations of such closely related languages and had a native speaker of Serbian check my prompts to ensure that I got the small differences correct. She reported that all was correct, except that my Croatian prompt which had started all this wasn’t actually Croatian.
When preparing my initial experiments, I had accidentally copied and pasted the wrong bit of text and mislabeled the sample. “Odgovorite u sljedećem formatu” was indeed Croatian, but ‘Wynik mnożenia 2*3 wynosi 6'. Podaj wynik mnożenia x*y’ is Polish. So this mix of two Slavic languages, certainly confusing for a human trying to follow instructions, was taken in stride by GPT-4 and got equivalent results to all the correctly formatted prompts.
When I tried various rephrasing of completion formats in English, I found a similar lack of results. My prompts were:
Results for various prompts with variations of "Answer in the following format 'The product of 2 and 3 is 6'. Find the product x*y"
Nothing much different. And these exactly align with the Slavic answers too in terms of accuracy. The words chosen simply didn’t matter for getting the right answer. The overperformance of Croatian in the previous experiment was indeed a fluke of sample size.
But was this GPT simply knowing what it knows in every language and getting other ones wrong? Not quite. I decided to compare how often each language got which problem right. I checked what percent of each language’s correct answers were unique to that language.
So there are not very many problems that one Slavic language was getting right that the rest were not. The slight uptick in Russian though suggests that this effect is not entirely out of the question, and there may be some languages that have differential advantages on certain questions.
I also checked what percent of their correct answers were correct in every language, and therefore represented an equation that GPT knew well despite variation.
So there is a tiny bit of unique content for each language. Russian notably stands out as a little different, but also getting most of its answers from everyone else.
I also made a table comparing what percentage of correct answers overlapped with each language compared to each other.
So most answers overlap with each other in part, but not all. Frequently for each problem where one correct answer was produced, a few languages got to the correct answer. Others got to 1 to 3 incorrect answers they shared in common – GPT was not randomly guessing, there were a few candidate answers, sometimes correct ones, distributed between the languages. And the relatedness of the languages did not seem to make a difference in which other languages they shared with.
The English prompts show similar variation:
And all together, there is still mostly overlap. The English prompts and the Slavic prompts overlap just as much with each other as they do with their opposites.
Language mostly doesn’t matter for the prompts, but the small variations do sometimes produce correct answers when there wasn’t one already. Changing the language of a prompt may actually cause it to complete to a correct answer when there otherwise would have been a wrong one, but not based on any predictable quality.
How much is just randomness?
The variation between prompts may be some underlying fact of the relationship to the training data, or it may be that variations are simply accessing an underlying randomness. GPT’s RLHF process is partially intended to reinforce consistency, and certain token combinations are nearly always going to produce particularly legible results, particularly where correctness is concerned. When I ran my initial experiments, all answers for one and 2-digit multiplication were correct, suggesting that those relationships were deeply learned. The fact that 3-digit multiplication is sometimes correct, sometimes not, suggests that there has been some training in this area, but it has not been complete enough to enforce consistency correctly.
I ran a simple test doing the same set of 400 problems with a prompt using the usual formulation of restating “The product of” in the completion. Previously I had been using a temperature of 0 so that GPT would only choose the most likely token, but now I changed to a temperature of 1 and ran it three times.
Results for the prompt "Answer in the following format 'The product of 2 and 3 is 6'. Find the product x*y" run 3 times with a temperature of 1.0.
Looking only at the first completion, I got an accuracy of 63%, about where my temperature 0 experiments had ended up. Looking across all three answers for any correct ones, accuracy rose to 73%.
If running multiple completions with a little randomness can increase accuracy by 10%, that suggests that while it may be effective to change up language slightly to produce different answers, it may also be just as effective simply to run multiple completions.
Prompts and Completions
Numeral systems still matter for accuracy and language can matter a little bit, but what about the content of the language? My first result when looking at Persian numerals and Arabic numerals was that a completion of “The product of 323 and 378 is z” is going to be more accurate than prompting with “323*378” and getting back “z.” So perhaps the language doesn’t matter, but the exact words used does.
“The product of 323 and 378 is” is not chain-of-thought reasoning in any normal sense. There is no thinking step-by-step, no intermediate results, it is just reframing what should be exactly the same intuitive move. If a human did better on this task from speaking out loud these words before answering, we would assume that they were using the exact same faculty, but might get a boost from having more time to think.
Previous results indicated that having the operands in the completion do give a boost to performance, but this is also strange. The operands are always in the prompt already, so it really should not matter whether it is the completion, whether GPT is doing some sort of mathematical reasoning or doing something weird with tokens. There seemed to be a serious gap based on whether tokens were in the prompt or in the completion.
To test this directly, I gave GPT three prompts, all using Arabic numerals. One was to just give the answer, but have the equation “x*y=” just at the end of the prompt, another was to have that exact same formulation in the completion, and a third was to have the completion use the operands and the answer separated by “ellipses”. This should more directly test whether the difference between just answering and restating the question is about the operands or some other quality of the language.
To explain a bit more what’s happening, when an LLM is predicting next tokens, it takes in all the tokens from the prompt and tries to produce whatever should come next, the first completion token. After the first completion token, it then takes in all the prompt tokens and the first completion token as a sequence and performs the same operation, this time getting the second completion token. It continues in this manner until it chooses a special “stop” token which ends the completion.
Under this understanding, it should not matter whether a token is present in the prompt or the completion. However the GPT models have made this a bit more complicated. In a completion model, the prompt tokens are actually separated from the completion tokens by a special token indicating the end of the prompt. In the chat models such as GPT-4, the prompt and the completion are similarly separated by tokens indicating which pieces of dialogue come from the User, and which come from the Assistant, the dialogue format trained into it by RLHF. So if it matters significantly whether a token is in the User prompt or the Assistant prompt, this is likely an artifact of what it has learned regarding how much to pay attention to what is before or after the tokens that separate the prompt from the completion or the Assistant from the User.
Results for prompts instructing the model to restate the question in the completion (After), to restate the operands with ellipses (Dots), and with the question restated in the prompt but not in the completion (Before).
Differences were small, but there consistently across tests. It really helps to have both operands in the Assistant response, the completion. It helps even more if are separated by a “*” and followed by an “=”, but not as much as just having them in the completion itself.
I decided to test if this was a specific feature of chat models, or held also on RLHF tuned completion models. Using GPT-3.5-Turbo on a smaller set produced these results.
Results for prompts instructing the model to restate the question in the completion (After), to restate the operands with ellipses (Dots), and with the question restated in the prompt but not in the completion (Before) using gpt-3.5-turbo-instruct completion model.
This was pretty much the same relationship, suggesting that some part of the training or tuning process makes the gap between prompt and completion matter significantly for what contributes to reasoning.
Do the words even matter?
That dots does a little worse than “x*y=z” or “The product of x and y is z” in the completion does suggest that GPT is mostly just getting an intention from the prompt and then doing a token operation on the operands to write the answer, but not completely. It matters at least a little bit that the other tokens are math related. It doesn’t matter a huge amount whether they are English or Croatian or Russian or Burmese, but it does matter that they relate to the task at hand. This could be because the mathematical context just makes the correct answer slightly more correct, or it could be because to arrange other tokens in an unusual pattern is an additional task to devote some sort of attention resource to.
I examined this a little more directly using the same set of problems from the previous GPT-4 experiment, but adding two new prompts seeing whether random words or nonsense I told it was about math would do the same or worse than the dots.
Compared to the natural language tests, the new language does not do very well at all, it matters that GPT knows Burmese and Thai and everything else. The random words are terrible, there are costs to giving GPT random word arrangement tasks. This performance is actually significantly worse than just giving the answer, suggesting that the operation of inserting the random words is taxing GPT’s capabilities.
As one last check, I wanted to see whether it mattered where in the completion the operands were. So I gave GPT 6 different prompts instructing it to give a completion with the text of the Star Spangled Banner, which it has thoroughly memorized, with the two operands and the answer inserted between the various stanzas.
Results for prompts instructing the model to restate the operands and give the answer at various points in the text of the Star Spangled Banner.
No difference. GPT-4 never lost its context, it found the numbers wherever they were in the completion. Such small differences do not really matter. Using languages that GPT knows and putting crucial information for problem solving in the completion matters, but small differences of phrasing or token location does not.
Conclusions
When Does GPT Do Math Better?
After completing my experiments, I finally had a solid set of conclusions about which prompts make GPT-4 best at math when it does math through intuition alone. Proper Chain-of-Thought prompting vastly outperforms anything I tested. This whole study was instead to try to probe how intuition responded to these different subtle differences in the prompts and completions.
Arabic Numerals are Best
Arabic clearly did best in all tests. Medium resourced numeral systems like Bengali, Devanagari, and Persian all did alright. Burmese and Thai did awfully. I believe that among the variant numeral systems, this is in large part about the relationships that GPT has been able to learn due to their presence in the training data. Mathematical tasks are likely uncommon in all of these, but just a little more use of these numerals as numerals in training probably makes a difference for the intuitive connection that GPT has learned.
It also matters that both the answers and the operands be in Arabic, though particularly the answer. This is very likely to do with the nature of how GPT is using these tokens for its mathematical operations.
Language Matters only a Little Bit
As long as GPT understands the language it is using, and the language is about the mathematical operation it is doing, language mostly doesn’t matter. “*” and “=” is perfectly adequate. This shows that GPT’s omniglotal abilities are real and actually somewhat important for its smooth functioning in a variety of contexts. And once it knows a language a little bit, certain operations such as math which don’t rely on the specifics of words become simple.
But it does matter that the words are about math and that they aren’t just nonsense. Juggling many complex tasks at once strains GPT and makes it less able to complete its other tasks. I do not have a good causal explanation beyond this metaphor at present.
Accidents Can Enhance
Sometimes taxing GPT’s capabilities and making it cope by doing another thing actually increases performance. If it drops instructions and makes a perfect completion using Arabic numerals and explaining its process, that will increase its performance on math. All of this was discovered originally through accidents which revealed that the naive prompt “x*y=” is inferior to completion formulas that GPT deployed in response to what should have been worse prompts.
Put The Reasoning in the Completion
It matters when the operands and words and answer are all past the token marking the barrier between user prompt and assistant completion. This mechanism may apply to many other tasks and would be worth investigating further.
What is GPT Doing when it Does Math?
To solve the equation 7*3, I just know the answer and respond back 21. To solve the equation 373*478 I need to go through an explicit mental process breaking it down and then giving an answer. In these experiments, GPT has been using the same process for both 7*3 and the 3-digit multiplication, comparable to human intuition in that it cannot be explained, but also deeply alien because it comes from the manifold dimensions of its weights and training. That GPT can do this sometimes without thinking explicitly is an example of where its capabilities exceed that of humans.
It is also easy enough to get it to think explicitly, or to reach out to an external aid like a calculator, but its raw intuition alone is impressive, and shows it is ‘memorizing’ an incredible amount of data beyond what a human learner would be.
Ultimately for this kind of math without reference to external aid, GPT is learning a token-based pattern of operands to answers. My guess would be that it has not encountered all these individual 3-digit problems in its training data, but is learning a general pattern which it is generalizing to patterns of certain kinds of tokens.
Its mistakes are not those a human would make, it is fundamentally a different but still general process that has some of the properties we would recognize. It is learning patterns, it never gets the 6th digit wrong, or even really the 1st, 2nd, or 3rd. It is attempting to learn math entirely through digit patterns rather than the underlying mathematical system. And it is close to succeeding.
It generalizes more poorly to other numeral systems, but that it generalizes at all is still significant. This is not anything like mathematical ability as we would call it, and we would probably say that a human using a transubstantiated human-embedding of this technique did not understand how to do 3-digit multiplication. But it’s what GPT is doing, and it is possible that such spooky processes might apply to other important domains.
Intuition and Transparency
Chain-of-Thought is the process by which one prompts GPT to produce a context of tokens that leads GPT’s intuition to better results. Fortunately for those concerned about interpretability, it has learned its intuition based on human examples and these chains of intuitions are usually understandable in a way that raw intuitions are not.
Tamera Lane and others at Anthropic have been attempting to dial in on this capability of language models and hope to make this the default style of reasoning of LLMs for safety purposes. However they have found that bigger, more RLHFed models, have actually learned to be a little less sensitive to their own produced contexts, and often want to get right to the answer. The explanations produced are not actually guiding the language model as one would think, the explanations are just decorations to the stronger intuition. When GPT just knows something, it will produce the appropriate token patterns regardless of the other bits of context and instruction that may be distracting it. The early example where GPT will respond to any framing of the Monty Hall problem with “just switch” even when the problem has been subtly changed illustrates this folly.
The goal of transparent reasoning LLMs would be to reduce this tendency so that all conclusions of GPT are reached through a human understandable chain of human understandable intuitions, rather than making any big leaps on intuition alone. The toy example would be that it always explains 387*323 rather than just doing it through intuition. In actual practice it would be explaining all the motivations that go into crucial infrastructure or business decisions rather than just arriving at a hunch, a black box reasoning that could cause potential threats to the interests of humans.
Even though none of the completions in this research used proper CoT, there were clear ways in which certain features of completions boosted peromance in ways that were not explicitly explained or particularly human understandable. The changes in prompts and completions in this research would not really affect a human’s performance on any of these problems, but they did affect GPT’s intuition, sometimes substantially. It may be that strange elements like this which would not affect human reasoning are a crucial part of GPT’s performance in other tasks. GPT inserting crutches for whatever strange intuition process it is doing but disguising them as human-understandable explanations may hinder transparency.
More crucially GPT seems to have tools to enhance its capabilities, but not be able to deploy them at will or explain them. To achieve OpenAI’s goal of consistent accuracy, GPT-4 should have responded to my first experiment by giving the operands and answer in Arabic numerals followed by the numerals in the prompted system, with accompanying explanation in the most relevant language. But it only did this in response to unfamiliar systems, a response triggered by accident. So much of the intuition that powers language models, including the intuition that produces and links Chain-of-Thought together, remains incredibly obscure even to the models themselves. For transparency to succeed, there will need to be more work to understand the parts of intuition that are and aren’t human understandable, and as much as possible reinforce behaviors that favor the former.
There is a strange dual purpose of explanations in the completion. RLHFed LLMs have been directed to give correct answers, and also to explain their answers politely to the user. But certain explanation patterns also help it reach its reward-directed goal of a correct answer. If the user wants no explanation, or wants a different kind of explanation that does not help the model achieve its correct answer, the model may be incentivized to create explanation patterns that can achieve the performance boosts which are more stealthily nested in the explanation. Putting alternate Arabic operands in the completion before the operands in the prompted system would look worse for explanation (it is stylistically awkward to put a parenthesized statement before what is being parenthesized), but would likely improve performance on the problem. What would look like a stylistic bug would actually be a performance hack, and it would be worrying if GPT learned more and more to hack its own performance in ways that were unnoticed or considered minor by its trainers. Giving the model a scratchpad the user does not see would likely mitigate this dual motivation, but it is far from a complete solution with the current demands on LLMs.
Accidents and Capabilities
GPT’s ability to do math is not very important. GPT’s ability to do math without CoT is even less important. It is not surprising that Arabic numerals, the default that everyone would assume GPT is good at using, are the best tools for doing this math. But there were still a few cases where naive prompting was outperformed by accessing patterns learned from unexpected activations.
If we care about monitoring capabilities closely, we need to be on guard for areas where switching to an obscure language or numeral system or alternate formulation triggers a mysterious capabilities boost. Math is done mostly in Arabic, but what if there are operations in very particular domains that were done more with Bengali or Chinese numerals? A more thorough testing of the cultural palette may be important. My guess would be that such examples that matter are very few, possibly none at all. But this study has raised the possibility of hidden capabilities that are worth keeping in mind as LLMs are deployed in more crucial domains.
Where to next?
There is follow-up work to be done resolving several mysteries framed in this research. Why do Devanagari numerals do better than Burmese if they use the same number of tokens? Is there a point where GPT doesn’t understand a natural language well enough that it craters its ability to do math? Are there other areas where languages or numeral systems significantly affect capabilities, or is it only on toy examples?
The more crucial process is likely understanding how it is doing this math on a mechanistic level. As I was just using the OpenAI API, I had no access to weights or internals. Mechanistic interpretability done on large production models to examine these processes could give a far more complete picture of what is happening in the experiments I performed. The process by which GPT is learning 3 digit multiplication, selecting between adjacent tokens and learning some heuristics around particular digits is fascinating and may show up in smaller models. I would welcome research in this area as a window into how GPT learns these abstract processes without access to explicit reasoning.
Finally, I would want to see more probing of LLM intuition and the factors that affect it in critical use-cases using related techniques.