This is a special post for quick takes by Alfred Harwood. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
Here are some updates on the work that @Jeremy Gillen and I have been doing on Natural Latents, following on from Jeremy's comment on Resampling Conserves Redundancy (Approximately). We are still trying to prove that a stochastic natural latent implies the existence of a deterministic latent which is almost as good.
First, if a latent is a deterministic function of X and Y, (ie. ), the deterministic redundancy conditions will be satisfied up to errors of and H(X|Y). (We don't actually use this in anything that follows, but think its quite nice.)
Proof:Proof
First, write out using the entropy chain rule:
Since is a deterministic function of X and Y, we can set .
We can expand differently using the entropy chain rule.
The two expressions for must be equal so:
.
Re-arranging gives:
We can repeat this proof with X and Y swapped to get the bound
Furthermore, we can always consider a latent which just copies one of the variables (for example ). This kind of latent will always perfectly satisfy one of the deterministic redundancy conditions (if , then ). The other deterministic redundancy condition will be satisfied with error . The mediation condition will also have zero error since (since ).
We can choose to copy either or , meaning that using this method we can always construct a deterministic natural latent with
Another deterministic latent that can always be constructed is the constant latent This will always perfectly satisfy the two deterministic redundancy conditions, since . The mediation error for the constant latent is just the mutual information between and .
Between these two types of latent, a deterministic natural latent can always be constructed with error bounded by . Loosely: if and are highly correlated you can use the copy latent and if and are close to being independent, you can use the constant latent.
To test how tight this bound is, Jeremy has numerically found the optimal deterministic and stochastic natural latents for a family of (X,Y) distributions. The distribution is parametrised by which captures how correlated and are ( implies perfect correlation and implies no correlation). A nice graph of these results is below:
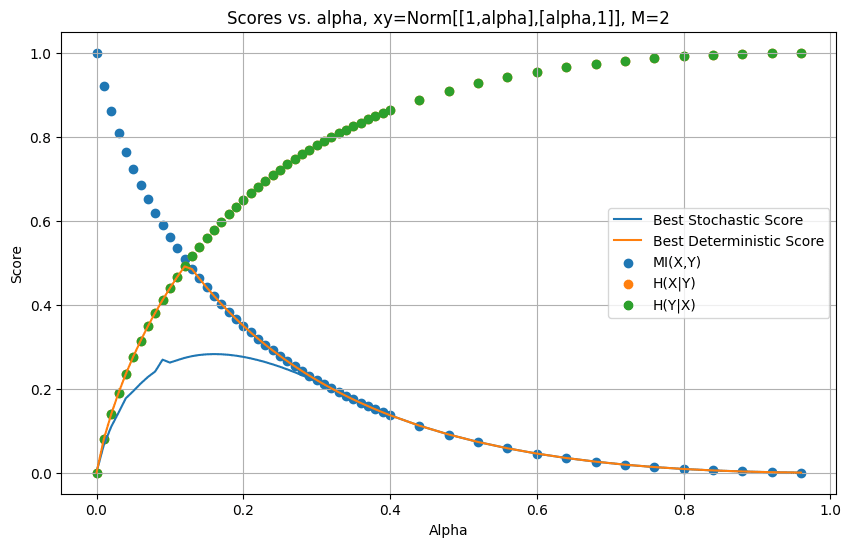
The ‘score’ of the latents is the sum of the errors on the mediation and redundancy conditions. The fact that the best deterministic score closely hugs the line suggests that the bound we found above is pretty tight. When we look at the latents found by the numerical optimizer, we find that it is using the copy latent at low and the constant latent when.
We also have a graph which breaks down the individual errors for optimal stochastic and deterministic latents:
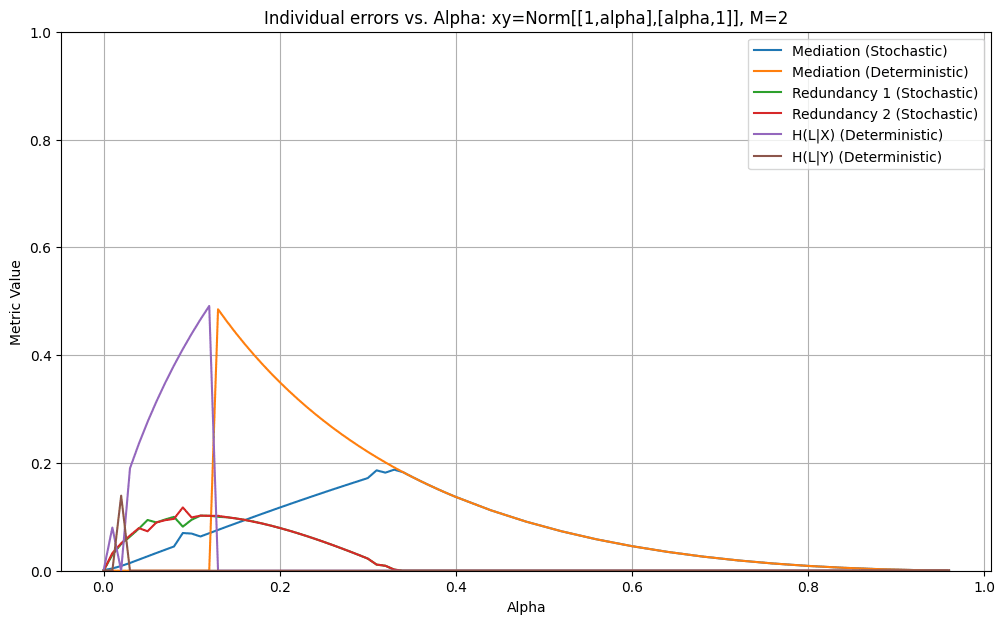
It shows quite clearly the point where the optimal deterministic latent switches from ‘copy’ to constant around . Furthermore, for we have shown that the constant latent is at a local minimum in the space of possible stochastic latents. We did this by differentiating with respect to the conditional probabilities and finding the Hessian. This was done using a symbolic program so we don’t have a compact proof to put here. The point is also the point where the errors for the best stochastic and deterministic latents become the same. This seems like good news for the general NxN conjecture, since it shows that when two states are roughly independent, there’s zero cost (to the difference between stochastic and deterministic scores) to ‘merging’ those states from the perspective of the latent.
Eyeballing the first graph, it seems like the deterministic score is never more than twice the best stochastic score for any given distribution. It is interesting to note that the optimal stochastic latent roughly follows the same pattern as the deterministic latent but it notably performs better than the deterministic latent in situations where both and are high. Bear in mind that these graphs are just for one family of distributions (but we have tested others and got similar results).
At the moment we are thinking about ways to lower bound the stochastic latent error in terms of and . For example if we could show that it is impossible for a stochastic latent to have a total error less than then this would prove that the existence of a stochastic latent with error implies the existence of a deterministic latent with error or less. We are also thinking about ways to show that certain latent types have errors which are global minima (as opposed to just local minima) in the space of possible latents.