This is really interesting!
I'm curious what happens if you relax the accumulating sum, allowing the model to "reposition" the tokens as it desires. Due to the causal mask the model already has access to the ordering (which is why NoPE is an effective positional encoding), but this might allow it to move related words near eachother, even if they are not adjacent in the sentence.
Moreover, you could provide multiple dimensions of "position" with which to do this, by say having a rotary encoding on the first half of the latent vectors and then a separate independently learned encoding on the second half.
I wonder how (or if) the model would use this to group tokens at various layers.
I'm not sure how interesting this is, but I relaxed the positive-increment constraint and removed the sigmoid, and the model only learned one negative increment, specifically the last byte of the Chinese possessive modifier (的), although 's in English sometimes got slightly-negative increments.
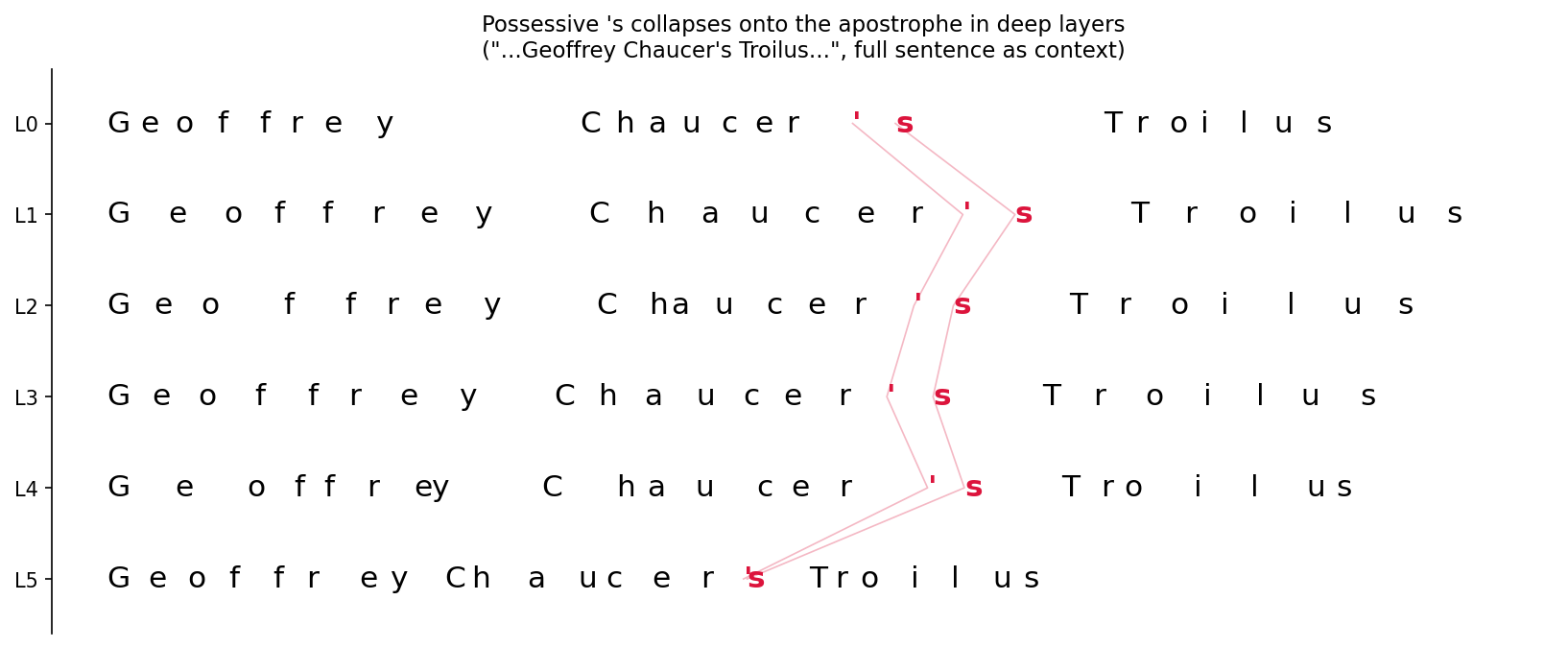
There's definitely aspects of this that make me think it's constrainted by the inability to change its mind, since s' in English (plural possessive) gets a larger increment, presumably because it's too late to change "s" and the model likes to separate on punctuation. I'm guessing if we can figure out a way to let the model decide on spacing after seeing the whole sentence it would do something more interesting.
Interesting! Currently, you are deciding the increment to the next token... using which activations? Post transformer? Post MLP?
It seems like maybe what you're looking for is, for each layer, determine the increment from the previous token after the previous layer's MLP (for the current token). Since layer 0 you have no previous layer to reference, maybe it just uses standard RoPE, or maybe you do something similar to what you're doing now where you determine the layer 0 increment based on the end representation of the previous token.
The DeltaMLP blocks consume the incoming residual stream (or embeddings) for the current token between the transformer blocks, so we always have one (although advancing the position before position 0's is meaningless since only relative position matters). For layer 0, we use the token's embedding, so the position is fully static per-token.
From the attention section's perspective, we're feeding in the embedding or residual the same way we normally would, and the only difference is that Q and K are also rotated based on the sum of all calculated position increments instead of the position count.
I think the requirement that increments be positive probably isn't necessary, although the problem where the model can't look forward prevents a lot of uses for this (it might work decently with BPE though).
For retroactively changing positions, I think training would be unstable and finnicky, but it would be interesting if you could get it to work.
Something related that I'm interested in is BLT/H-Net style models that do dynamic chunking instead of tokenization. H-Net does this at multiple scales, so it could theoretically group words in the first layer and concepts in the second. I haven't actually tried to train or inspect on yet though.
The Chinese for AI starts with 人工 and that's not a deliberate visual pun? That's it, I'mma quit everything and become a kabbalist.
Agree with Joseph, this is really cool stuff!
Looks to me like intermediate layers are using positions in a way very alien to humans; like, there's some obvious "natural" semantic segmentation, but I'm not discerning a legible pattern to the distances between individual chars.
I'm not sure if I would read too much into the individual character variations yet, since this model is small and the current setup is hacky and not well optimized. I'm hoping to do a larger run once I can get the training to be more stable. I have some experiments running now trying to balance weight decay/penalties to find a version that's stable without just collapsing everything back to 1.
Instead of using static position increments (+1) per token, RoPE-based language models can learn per-token and per-layer position increments. This has minimal effect on model performance but allows us to see what the model thinks the distance is between each position and how this varies per-layer.
Example sentence with each character plotted based on per-layer learned position increments. Note the clear punctuation-based boundaries in L0 and what looks like concept-based grouping in L3.
I think this might be useful as another technique to inspect "where the model is looking" in addition to plotting attention patterns (and with similar limitations). The patterns can also hint at what the model is looking for at each layer (when position increments match different kinds of boundaries).
Note: This is still partially a solution in search of a problem. I'm hoping to help with the "searching under lamp posts" problem by finding more lamp posts, but there's additional work to be done here to see if this is actually useful or just a novelty.
AI disclaimer: The Architecture, Learned Position Increments, and Related Work sections were originally drafted by Claude before being (heavily) human-edited.
Introduction
Standard LLMs use Rotary Position Embeddings (RoPE) to encode the location of each position by rotating the key and query vectors by angles proportional to the number of tokens between the two positions.
Standard RoPE assumes that each token advances the position counter by +1, but we can train a model to advance the position counter by a learned increment per-token. Going further, we can learn a per-layer position increment vector, allowing us to calculate content-based position increments at any layer of the model.
Method
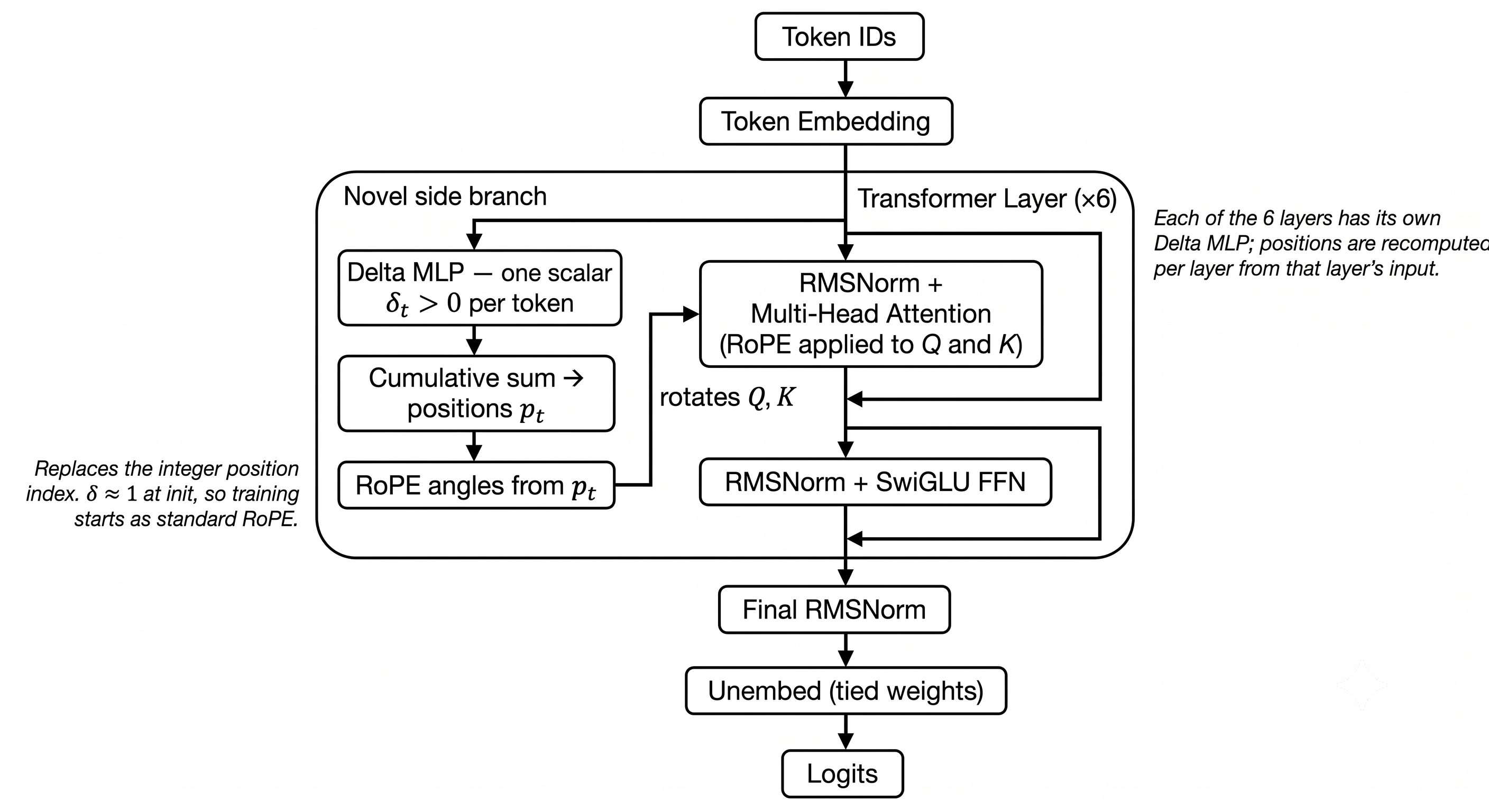
Architecture
The models are small decoder-only transformers — 256-dimensional, 8 heads, 6 layers, ~6.4M parameters, with RMSNorm, SwiGLU MLPs, and RoPE (θ = 10,000) — directly on raw UTF-8 bytes rather than BPE tokens. The vocabulary is 257 symbols: 256 byte values plus a document separator.
I focus on byte-level transformers because they need to find their own word boundaries, which makes the early-layer behavior more interesting. This technique also works on BPE models, but the per-token position increments aren't as interesting since some aggregation has already been done by the tokenizer.
Learned position increments
Standard RoPE advances the position counter by +1 per token and rotates each query and key by an angle proportional to that position. I replace the fixed +1 with a learned, per-token increment. A small MLP (Linear → GELU → Linear → softplus) reads a token's hidden state and emits a strictly positive increment δ. I call this DeltaMLP.
A token's position is the running sum of the increments up to and including it, and I apply the ordinary RoPE rotation using the calculated position.
I initialize the MLP's output bias so that δ ≈ 1 everywhere, so each model starts as exact integer-position RoPE and any deviation is learned. Because positions are still a cumulative sum, the rotation between a query and a key continues to only depend on the difference between their learned positions.
The idea of learning positional increments isn't unique or novel. See Related Work for other papers which have tried similar things (generally for capabilities reasons).
I study two variants:
Data and training
I train on one epoch of an even mix of English and Chinese Wikipedia (wikimedia/wikipedia configs
20231101.enand20231101.zh) at a 512-byte context length, with a held-out validation split drawn from disjoint documents. Each model trains for 50k steps with AdamW (learning rate 1e-3, weight decay 0.01, cosine schedule, gradient clipping) in bf16. For the loss comparison I train standard RoPE and both shared and per-layer learned increment RoPE, under identical settings.Chinese characters are represented in UTF-8 as a lead byte (
0xE4–0xE9) followed by two continuation bytes, so I predicted that English capital letters and Chinese lead bytes would be treated similarly by the models.Results
Per-Token Increments
On the bilingual English and Chinese language model, I found that the models learned smaller increments for lowercase characters and word-internal bytes and larger increments for uppercase letters, start-of-word bytes, punctuation and other boundaries.
Category
Examples
Learned Increment δ
English (lowercase)
a-z
0.68–0.96 (mean 0.79)
Chinese (continuation byte)
0x80–0xBF0.73–0.86 (mean 0.80)
Chinese (lead byte)
0xE4–0xE90.84–0.98 (mean 0.92)
Word boundary
space
1.05
English (uppercase)
A-Z
1.01–1.29 (mean 1.10)
Punctuation
. , ; ! ?
1.10–1.29 (mean 1.18)
Line boundary
newline
2.12
Other boundaries
EOS
2.90
English uppercase letters and Chinese lead bytes both show larger gaps than lowercase and continuation bytes. Since Chinese lead bytes are significantly more common than uppercase letters, it makes sense that the model seems to consider uppercase to be a stronger signal of a boundary.
If we plot each character spaced by their relative position increments, we can visually see how close the model thinks characters are together:
In Chinese, we (unfortunately) can't display individual bytes so we sum the increments for each character, causing the average character spacing to be very uniform with no obvious word boundaries.
According to Claude, this sentence translates to, "Artificial intelligence is a branch of computer science."
First Layer of Per-Layer Model
On the per-layer model, I found that the learned positions tended to explode by default, so I bounded them to max_delta = 10.
The model trained with that architecture found larger increments but shows the same pattern as the shared-MLP model for the first layer.
Category
Examples
Learned Increment δ (L0)
English (lowercase)
a-z
1.21–2.53 (mean 1.64)
Chinese (continuation byte)
0x80–0xBF1.57–2.08 (mean 1.79)
Chinese (lead byte)
0xE4–0xE92.04–2.72 (mean 2.43)
English (uppercase)
A-Z
2.87–9.98[1] (mean 9.52)
Punctuation
. , ; ! ?
9.80–9.98 (mean 9.90)
Other boundaries
EOS
9.82
Word boundary
space
9.99
Line boundary
newline
9.99
Chinese Word Boundaries
Since Chinese doesn't have spaces between words, I was interested to see if the model would learn word boundaries from Chinese text without punctuation, so I ran my per-layer model on held-out text from Chinese Wikipedia and compared my learned increments to word boundaries detected by jieba (a Chinese word segmenter).
I measured how well the learned increment at each layer separates true word boundaries from non-boundaries, as an ROC-AUC (0.5 = chance, 0.0 or 1.0 = perfect). I score only the gaps between two Chinese characters (no space or punctuation), using the increment at the next character's leading byte.
Layer (increment computed from)
Chinese word-boundary AUC
L0 (byte identity)
0.50 (chance)
L1
0.54
L2
0.68
L3
0.37
L4
0.63
L5
0.47
The first layer is unable to detect word boundaries since it only sees the byte's embedding and has no contextual information, but the middle layers (L2–L4) are able to distinguish word boundaries (although L3 seems to be compressing boundaries rather than expanding them).
Per-Layer Plots
We plot the same sentences from above but using per-layer position increments. Each layer is scaled independently to make the results legible.
The model seems to be looking for punctuation-based boundaries in L0 and concept-based boundaries in L3-L5. The model also varies how large the gaps are between groups, with small gaps in L1-L2 and large gaps in L0 and L3.
The structure is hard to see, but jieba segments this as 人工智能 / 是 / 计算机科学 / 的 / 一个 / 分支 / 。, and the model seems to be recovering some of the gaps well (especially in L2 and later).
If we remove the per-layer normalization, we can also see that later layers want smaller position increments.
The same Marie Curie sentence above with all increments displayed on the same scale.
Grouping Multi-word Entities
The plots above made me wonder if the model groups multi-word entities like "Marie Curie" or "New York". To test this, I ran inference on a set of prompts with either a multi-word entity or the reversed version (i.e. "New York" or "York New") and compared the learned increment at the space token. The prompts were "A B", "the A B", "I visited A B", "near A B", and "they went to A B".
The results show that there was no difference in spacing in L0 (as expected) but the spacing is significantly smaller in the other layers for the real direction ("New York") vs the reversed direction ("York New").
Layer (increment from)
δ real order
δ reversed
% smaller space for real order
p (two-sided)
L0 (byte identity)
9.99[1]
9.99
0%
1.0
L1
1.42
1.43
51%
0.28 (n.s.)
L2
1.43
1.54
71%
3e-5
L3
0.06
0.10
66%
6e-5
L4
0.86
1.21
77%
3e-8
L5
0.47
0.64
78%
3e-7
Since the model is predicting spacing before seeing the second word, this only works if the model can predict that the word will be continued ("New [York]") and didn't work with fake multi-word entities like "Zorblax [Quimby]".
Mostly Loss Neutral
I consistently found that the learned position increments have a barely detectable effect on loss and perplexity.
Training loss for 7 different architectures including a baseline (byte_rope_bilingual) and some additional versions not described here, showing no visible loss difference except for a few spikes where learned positional increments are briefly worse.
Since the models do learn meaningful position increments, this implies that they must provide some benefit (or else there would be no gradient pressure), but I suspect that positional encoding is just not the bottleneck for LM performance.
Supporting evidence for this is that LMs can work around a complete lack of positional information (Haviv et al., 2022).
Limitations
Future Work
The method appears to work, but the real test will be if we can find anything interesting from this data. Some things I think it might be useful for are:
I also think the structure may be more interesting with different data sets. For example, I found that a model trained on code detected different kinds of structure in each layer.
There are also improvements that could be made to the method:
I also fine-tuned an existing model with learned per-token position increments to see if I could add this to an existing model, and found that the increments were changing in the expected directions (very slowly), but I haven't tried the per-layer version or inspected the results yet, and getting results on the scale of my other results would require either tuning or a much longer run.
Learned position increment stats for a fine-tuning run on SmolLM2-1.7B
I'm always interested in discussing this further if anyone's interested. I'm working independently, so it's very difficult for me to keep track of what's going on in the mech interp world on my own.
Related Work
Learned, input-dependent positions have been proposed several times; I came to most of this after running the experiments.
Code
All code is available on GitHub at brendanlong/learned-position-increments-experiment.
Our per-layer model is bounded with delta_max = 10, so interpret any value of ~10 as an increment "as high as the model is allowed to set it".