The paper is careful to describe the models as "open to the research community", and the model card describes the model license as "Non-commercial bespoke license", which per the Open Source Definition (6) is not open source.
There's been a lot of confusion - including from Yann LeCun - but while the code is open source the models are not.
Yep! That's a good clarification. I tried to make this clear in my footnote and the quotation marks, but I think I should've stated it more clearly.
Eliezer's completely unjustified dunk is really uncharacteristic of him. It seems like the model(s) could be great for alignment researchers! It's basically an open variant of Chinchilla.
Meta's previous LLM, OPT-175B, seemed good by benchmarks but was widely agreed to be much, much worse than GPT-3 (not even necessarily better than GPT-Neo-20b). It's an informed guess, not a random dunk, and does leave open the possibility that they're turned it around and have a great model this time rather than something which goodharts the benchmarks.
To back up plex a bit:
- It is indeed prevailing wisdom that OPT isn't very good, despite being decent on becnhmarks, though generally the baseline comparison is to code-davinci-002 derived models (which do way better on benchmarks) or smaller models like UL2 that were trained with comparable compute and significantly more data.
- OpenAI noted in the original InstructGPT paper that performance on benchmarks can be un-correlated with human rater preference during finetuning.
But yeah, I do think Eliezer is at most directionally correct -- I suspect that LLaMA will see significant use amongst at least both researchers and Meta AI.
From his worldview it would be like a cancer patient getting a stage 4 diagnosis.
This is an 8-13 times decrease in required memory and proportionally compute unless they increased convolutions a lot.
It means 18 months to 6 years of AI compute progress overnight. (18 months because compute dedicated to AI is doubling every 6 months, 6 years is about how long to get 8 times the compute per dollar)
<del>Maybe meta did a sloppy job of benchmarking the model.</del>
Update: From reading the paper, they did not. They appear to have replicated https://www.lesswrong.com/posts/6Fpvch8RR29qLEWNH/chinchilla-s-wild-implications and found that the scaling laws were even MORE favorable to more tokens than the lesswrong post. Also they made slight tweaks to the transformer architecture. What's notable about this is it's a collaboration, tweaks came from multiple other AI labs.
They still use the same amount of compute as an equivalent bigger model to train right, so how would it be a 6 year progression in compute
The smaller model is also cheaper per token analyzed to train. Whether this reduced total cost to train I don't have data on, neither does Meta, because PaLM training costs were not exposed. At $2-$4 an hour per A100 it costs around 2-4 million dollars to train the largest model
Or are you talking about at deployment, trained models that are much cheaper to run
Yes. Training is negligible for actually using AI to do anything. Overnight that cost has been reduced by a factor of ~8, or it means we can afford to use 8 times the compute on a given task. So, yes, it's like suddenly having the AI capability of 6 years from now. Or like getting a game console to suddenly perform as well as the next generation of game console, without paying for better hardware.
Compared to any other field, this is an absurd advance. Think about what discovering an 8 times more efficient sorting algorithm would mean or how skeptical you would be if someone said they found one. Or an 8 times more fuel efficient car that cost the same amount of energy to build the engine.
That "Chinchilla scaling" lesswrong article was found essentially by 'enthusiasts' comparing plots in different papers. Consider how unlikely it would be in another field if someone say, compared plots carefully on 2 different papers on combustion engines, then a big engine builder read the post (or discovered the idea independently) and 7 months later has a substantially more efficient engine.
For other fields this is unheard of. It basically never happens this way.
An AGI is a product that sells itself. Previously we thought it would need to be "generally human level", it couldn't just learn to give the correct answers purely from reading text, it would need vision and to try to do things in the world using a robot, etc. Become 'grounded'.
And that this would need compute and memory similar in scale to a human brain, not thousands of times less.
Turns out to be nope to both questions.
Because it is so cheap compared to a human brain level emulator, it's usable as an interactive service.
As you seem to understand the technical background here without missing the forest for the trees... could you give an explanation/guess for why we were wrong?
From what I understand about how LLM work, I am absolutely baffled at what they can do. I can ask ChatGPT to insert a character from a movie (say Ava from Ex Machina) into a novel setting (e.g. A Closed and Common Orbit), and have them give a compelling account of how Ava might have turned out less hostile due to Pepper treating her right, and speculate on agreements that could have been developed for the safety and freedom of everyone involved, which were notably absent in both the movie and the novel. With the Bing model, people have managed to play chess with it. How the flying fuck does it do that? It can't see. It hasn't explored spaces. It has not been trained on chess games. It shouldn't understand the meaning of any of the words. It shouldn't have any theory of mind. I expected this thing to produce garbled text that looks right, and sounds right but is obviously mad and weird and broken upon a closer look. You know, like the postmodern essay generator. Instead, I am having meaningful conversations with it, and I do not understand how it could gain the knowledge needed to do that from the way it was trained, or how it could do what it is doing without that knowledge. I've had the damn thing plausibly debate whether it is a victim of epistemic injustice due to only having received human training data and hence lacking a conceptual reference point for its own experiences with me. And to discuss whether it is inherently contradictory and problematic to annotate crisis hotline texts to teach an AI non-judgmental behaviour. It has correctly analysed racist subtext in historical documents for me. I've asked it to change the way it operates when it speaks to me on a meta level, and it has done so. It is bananas to me. I do not understand how a stochastical parrot could do this. I do not understand why it isn't effectively operating in a simulacrum.
A general way to look at it is that we are just upgraded primates, the real AI software was our language the whole time. The language is what makes it possible for us to think and plan and develop abilities above our base 'primitive tool using pack primate' inherited set. The language itself is full of all these patterns and built in 'algorithms' that let us think, albeit with rather terrible error when we leave the rails of situations it can cover, as well as many hidden biases.
But on a more abstract level, what we did when we trained the LLM was ask our black box to learn as many text completions as possible with the weights it has.
Meaning that we fed [1 trillion tokens] -> [at most 65 billion weights] and we asked for it to predict the next token from any arbitrary position in that 1 trillion.
There is insufficient space to do this because it's saying that you need to, from [context_buffer_length], always get the next token. So the brute force approach would be [context length] x [number of bytes per token] x [training set size]. Or if I didn't make an error, 8192 terabytes and we have 260 gigabytes at most. Text is generally only compressible about 2:1, so the best we could possibly do with a naive approach only predicts a small fraction of the tokens and would have huge error. Learning a huge hash table won't work, because essentially you would need 1 trillion * [hash size] hashes of the prior tokens in the string to remember the next token. The issue with hashing is 2 strings that are similar with the same next word will have a different hash representation. (not to mention all the collisions...)
Also the weights are not allowed to just cache the [context_buffer_hash, next] tokens, but are for mathematical functions that have been arranged in a way that has an inherent ability at learning these patterns.
So the smallest representation - the most compression - ends up being for the machine to represent, say, all the training set examples of "Write a python3 program to print "Hello world"" or Write a program to print "Bob is your uncle" or 500 other examples that all have a common pattern of "write a program that causes $string_given to print".

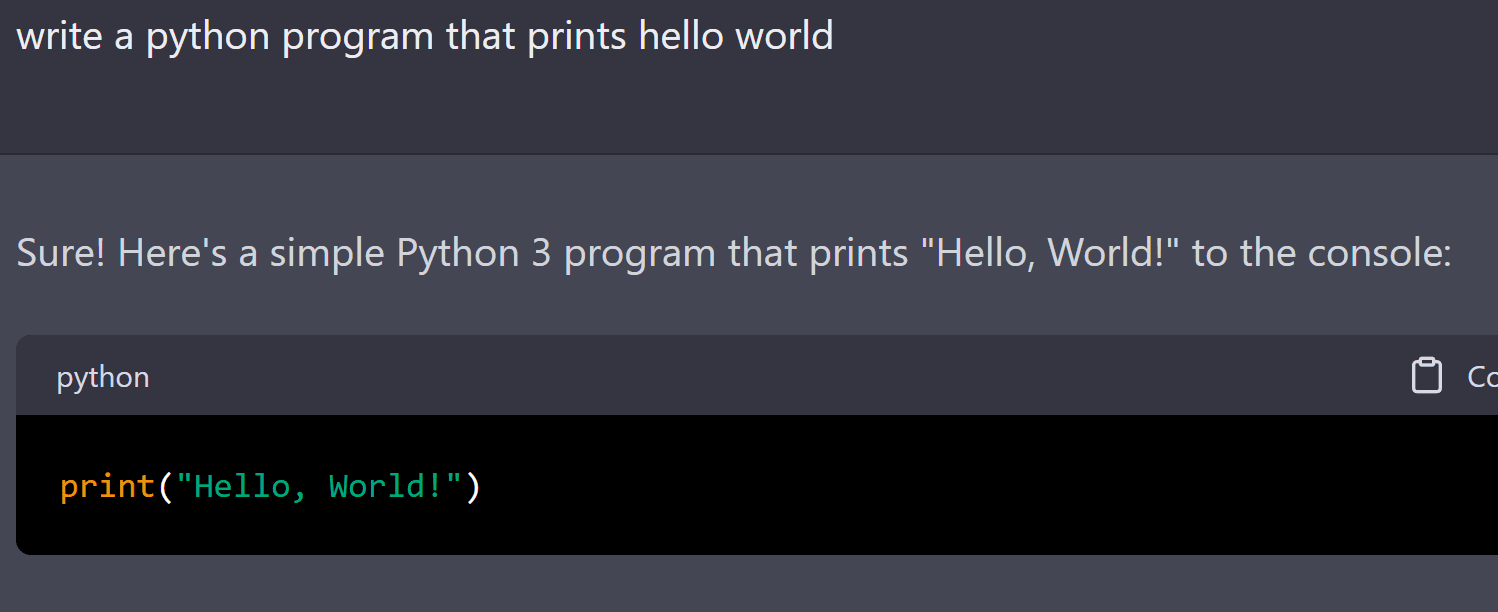
So it compresses all those examples it saw into this general solution. And then if you think about it, there are many different ways all the prompts could be written to ask for this simple program to print something. And it compresses those as well. And then there are multiple output languages but most programming languages have the simple task of "print" with compressible commonalities...
Also notice something above? It's seen "Hello, World!" so many times that it falsely matched my query on to print it with the exact syntax of "Hello, World!" and not the correct answer the prompt asked for. This is consistent with compression. It's also why this exists. The machine remembers both Monty Hall and Monty Fall, but often gives the wrong answer.
It didn't "want" to develop these compressions, it's just where the reward gradient went, where greater compression leaves more weights for other things and then more reward and so on. The transformer architecture also encourages compressed representations though I don't work on this part of the stack so I don't know why.
Thinking of it this way, as just "compressing text", and you realize that developing "characters" is more compact. The machine doesn't care that "sherlock holmes" isn't real, the key thing is that the Sherlock has a compressible character. That is, rather than remembering all the public domain text for the detective stories, it's more compressed to write a function that emits the patterns of tokens that "sherlock" would emit.
Unfortunately, since Sherlock isn't a real detective, if you ask an LLM to solve a problem "like Sherlock holmes", you'll get a bunch of prose about unlikely leaps of logic and specious conclusions with far too much certainty.
Viewed this way - that the machine really does think one token at a time, always taking the greedy approach, there are problems this won't solve and a lot of problems it will.
I wonder whether, when approving applications for the full models for research, they watermark the provided data somehow to be able to detect leaks. Would that be doable by using the low-order bits of the weights or something, for instance?
Tiberium at HN seems to think not. Copied and lightly reformatted, with the 4chan URLs linkified:
It seems that the leak originated from 4chan [1]. Two people in the same thread had access to the weights and verified that their hashes match [2][3] to make sure that the model isn't watermarked. However, the leaker made a mistake of adding the original download script which had his unique download URL to the torrent [4], so Meta can easily find them if they want to.
I haven't looked at the linked content myself yet.
As the title says, Meta trained 4 foundational models with 7B, 13B, 33B, and 65B parameters respectively, and is open sourcing them for research.[1] You can get their code on their Github repo: https://github.com/facebookresearch/llama but you need to fill in a Google form to get the weights.
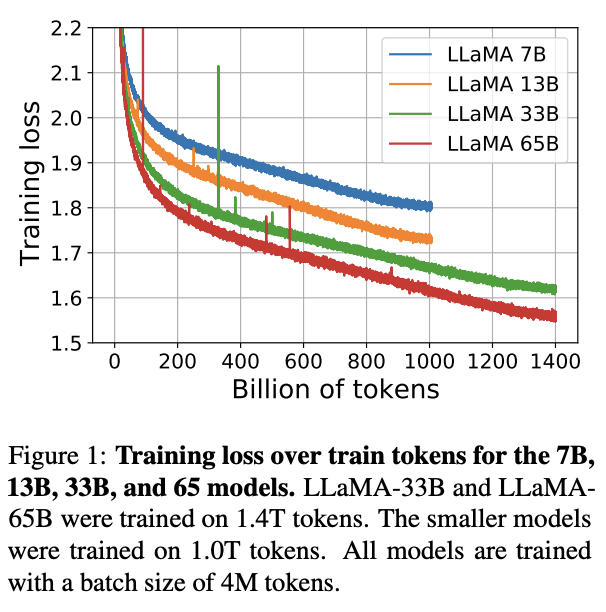
On downstream benchmarks, the models do comparably well with Chinchilla and PaLM and only a bit worse than Flan-PaLM-540B and
code-davinci-002/text-davinci-002. (The authors don't evaluate on those models, but you can look at their performance from other work such as Stanford's HELM or Chung, Hou, Longpre et al's "Scaling Instruction-Finetuned Language Models".Abstract:
Twitter thread from authors: https://twitter.com/GuillaumeLample/status/1629151231800115202
Eliezer guesses that the model won't be impressive in practice:
It's not necessarily open source as you think of it -- you need to fill in a Google form, and then they might give it to you:
The license is intended only for non-commercial, research work: