There's a few barriers which this runs into, but I'm going to talk about one particular barrier which seems especially intractable for the entire class of overseer-based strategies.
Suppose we take analogies like "second species" at face value for a minute, and consider species driven to extinction by humans (as an analogy for the extinction risk posed to humans by AI). How and why do humans drive species to extinction? In some cases the species is hunted to extinction, either because it's a threat or because it's economically profitable to hunt. But I would guess that in 99+% of cases, the humans drive a species to extinction because the humans are doing something that changes the species' environment a lot, without specifically trying to keep the species alive. (Think DDT, deforestation, that sort of thing.)
Assuming this metaphor carries over to AI, what kind of extinction risk will AI pose?
Well, the extinction risk will not come from AI actively trying to kill the humans. The AI will just be doing some big thing which happens to involve changing the environment a lot (like making replicators or a lot of computronium or even just designing a fusion power generator), and then humans die as a side-effect. Collateral damage happens by default when something changes the environment in big ways.
What does this mean for oversight? Well, it means that there wouldn't necessarily be any point at which the AI is actually thinking about killing humans or whatever. It just doesn't think much about the humans at all, and then the humans get wrecked by side effects. In order for an overseer to raise an alarm, the overseer would have to figure out itself that the AI's plans will kill the humans, i.e. the overseer would have to itself predict the consequences of a presumably-very-complicated plan.
Now, for killing humans specifically, you could maybe patch over this by e.g. explicitly asking the AI to think about whether its plans will kill lots of humans. But at this point your "non-general patch detector" should be going off; there are countless other ways the AIs plans could destroy massive amounts of human-value, and we are not in fact going to think to ask all the right questions ahead of time. And oversight will not be able to tell us which questions we didn't think to ask, because the AI isn't bothering to think those questions either (just like it didn't bother to think about whether humans would die from its plans). And then we get into qualitatively different strategies-which-won't-work like "ask the AI which questions we should ask", whose failure modes are another topic.
The main thing I want to address with this research strategy is language models using reasoning that we would not approve of, which could run through convergent instrumental goals like self-preservation, goal-preservation, power-seeking, etc. It doesn't seem to me that the failure mode you've described depends on the AI doing reasoning of which we wouldn't approve. Even if this research direction were wildly successful, there would be many other failure modes for AI; I'm just trying to address this particularly pernicious one.
It's possible that the transparency provided by authentic, externalized reasoning could also be useful for reducing other dangers associated with powerful AI, but that's not the main thrust of the research direction I'm presenting here.
Thanks, this is a helpful comment -- can you elaborate on why "ask the AI which questions we should ask" would fail (or point to relevant discussion)? I'm thinking that we would use many different models (not just the model doing the reasoning), including smaller ones, and trained or prompted in different ways, to catch generated text that would cause harmful side effects. We could have all of these models use externalized reasoning as well, to help aid in the supervision/oversight. This obviously doesn't eliminate all of the risk, since all of the models can coordinate to cause catastrophic side effects; that said, I'd guess that coordination is much harder when you're using many different models in different ways, and these models can only communicate via externalized reasoning
"Ask the AI which questions we should ask" is strategically isomorphic to "ask the AI what we should do". It's mainly a values question, and only works insofar as we've already thoroughly solved the alignment problem for the system at hand. Like, getting a good answer to "ask the AI what we should do" (or "ask the AI which questions we should ask") is basically a framing of the whole alignment problem.
Do you already have cached understanding for why "ask the AI what we should do" doesn't work? If not, and assuming you have already brainstormed on your own for at least an hour, List of Lethalities has multiple. (Indeed, IIRC the large majority of the failure modes on List of Lethalities apply.)
Yes, I have brainstormed about this question for quite a while, and I have read the List of Lethalities. I was mainly wondering if you had a specific concern with the proposal I outlined and/or additional concerns beyond that List.
The most relevant points from that list in this context I think are (34) and (35), that the agents competing against each other can coordinate in a way that doesn't involve or benefit humanity. My main uncertainty in this context is how the different agents and supervisors could learn to coordinate, when they can only communicate via human-readable text. They could:
- Use steganography to communicate. Here, I'm unsure on how they'd agree on a protocol for communication if the agent and supervisor don't have shared weights. I'm sure there's some loophole I'm missing due to lack of imagination
- Use the text channel itself to communicate to other agents, risking getting caught by human overseers, but relying on the fact that there's too much communication for us to directly monitor. Here, I can see this risk being mitigated by us using smaller models that are less likely to be power-seekers in overseeing the text communication between model for signs of coordination. The smaller models will be less capable but could e.g. be amplified with decomposition/debate
Curious if/why you think these strategies are likely to fail!
I don't think those are the most relevant points (although I can see why they're the most salient). I'd say sections B.2-B.3 are the real dealbreaker for most proposals. In particular:
- 18: There's no reliable Cartesian-sensory ground truth about how good the AI's answers are. There just isn't a reliable training signal.
- 20: Human raters make systematic errors - regular, compactly describable, predictable errors. So we can't use human ratings to figure out which outputs are good without selecting for outputs which exploit human biases.
- 27: Optimizing against an interpreted thought optimizes against interpretability. So whatever oversight we're using, we can't optimize against it; if the oversight shows the AI doing something bad, we can't just give negative reward to those interpretable-bad-thoughts.
- 29: Human beings cannot inspect an AGI's output to determine whether the consequences will be good. This is similar to 18 & 20; it means we don't have a ground truth training signal for "good answers". (My comment at the top of this thread essentially argues that this same problem also applies to the AI's internal thoughts, not just its outputs.)
- 32, which talks about text-based oversight in particular.
The bottom line of all of these is: even setting aside inner alignment failures, we just do not have an outer training signal for reliably good answers.
Now, the usual way to get around that problem is to have the system mimic humans. Then, the argument goes, the system's answers will be about as good as the humans would have figured out anyway, maybe given a bit more time. (Not a lot more time, because extrapolating too far into the future is itself failure-prone, since we push further and further out of the training distribution as we ask for hypothetical text from further and further into the future.) This is a fine plan, but inherently limited in terms of how much it buys us. It mostly works in worlds where we were already close to solving the problem ourselves, and the further we were from solving it, the less likely that the human-mimicking AI will close the gap. E.g. if I already have most of the pieces, then GPT-6 is much more likely to generate a workable solution when prompted to give "John Wentworth's Solution To The Alignment Problem" from the year 2035, whereas if I don't already have most of the pieces then that is much less likely to work. And that's true even if I will eventually figure out the pieces; the problem is that the pieces I haven't figured out yet aren't in the training distribution. So mostly, the way to increase the chances of that strategy working is by getting closer to solving the problem ourselves.
I definitely agree with you that it's insufficient to stamp out thoughts about actively harming humans. We also need the AI to positively value human life, safety, and freedom. But your "non-general patch detector" argument seems weak to me. We can provide lots of different examples of cases where the AI ought to be thinking about human welfare, do adversarial training on it, etc., and it seems plausible to me that eventually it would just generalize to caring about humans overall, in any situation. I don't see why this is an especially hard generalization problem.
See List of Lethalities, numbers 21 and 22 (also the rest of section B.2, but especially those two). Unlike Eliezer, I do think there's a nontrivial chance that your proposal here would work (it's basically invoking Alignment by Default), but I think it's a pretty small chance (like, ~10%), and Eliezer's proposed failure modes are probably basically what actually happens at a high level.
I think Lethality 21 is largely true, and it's a big reason why I'm concerned about the alignment problem in general. I'm not invoking Alignment by Default here because I think we do need to push hard on the actual cognitive processes happening in the agent, not just its actions/output like in prosaic ML. Externalized reasoning gives you a pretty good way of doing that.
I do think Lethality 22 is probably just false. Human values latch on to natural abstractions (!) and once you have the right ontology I don't think they're actually that complex. Language models are probably the most powerful tool we have for learning the human prior / ontology.
The good news for us is that this is a much more solvable problem, because under the assumption that the AI weakly cares about less powerful beings like us, then it's asymptotically nice: With more technology, you merely need to emulate animals and us in a simulated reality via mind uploading, and presto, the problem is solved. In other words, capabilities helps us a lot more than in the case where the AI really does want to kill all humans.
I strongly agree that this is a promising direction. It's similar to the bet on supervising process we're making at Ought.
In the terminology of this post, our focus is on creating externalized reasoners that are
- authentic (reasoning is legible, complete, and causally responsible for the conclusions) and
- competitive (results are as good or better than results by end-to-end systems).
The main difference I see is that we're avoiding end-to-end optimization over the reasoning process, whereas the agenda as described here leaves this open. More specifically, we're aiming for authenticity through factored cognition—breaking down reasoning into individual steps that don't share the larger context—because:
- it's a way to enforce completeness and causal responsibility,
- it scales to more complex tasks than append-only chain-of-thought style reasoning
Developing tools to automate the oversight of externalized reasoning.
Do you have more thoughts on what would be good to build here?
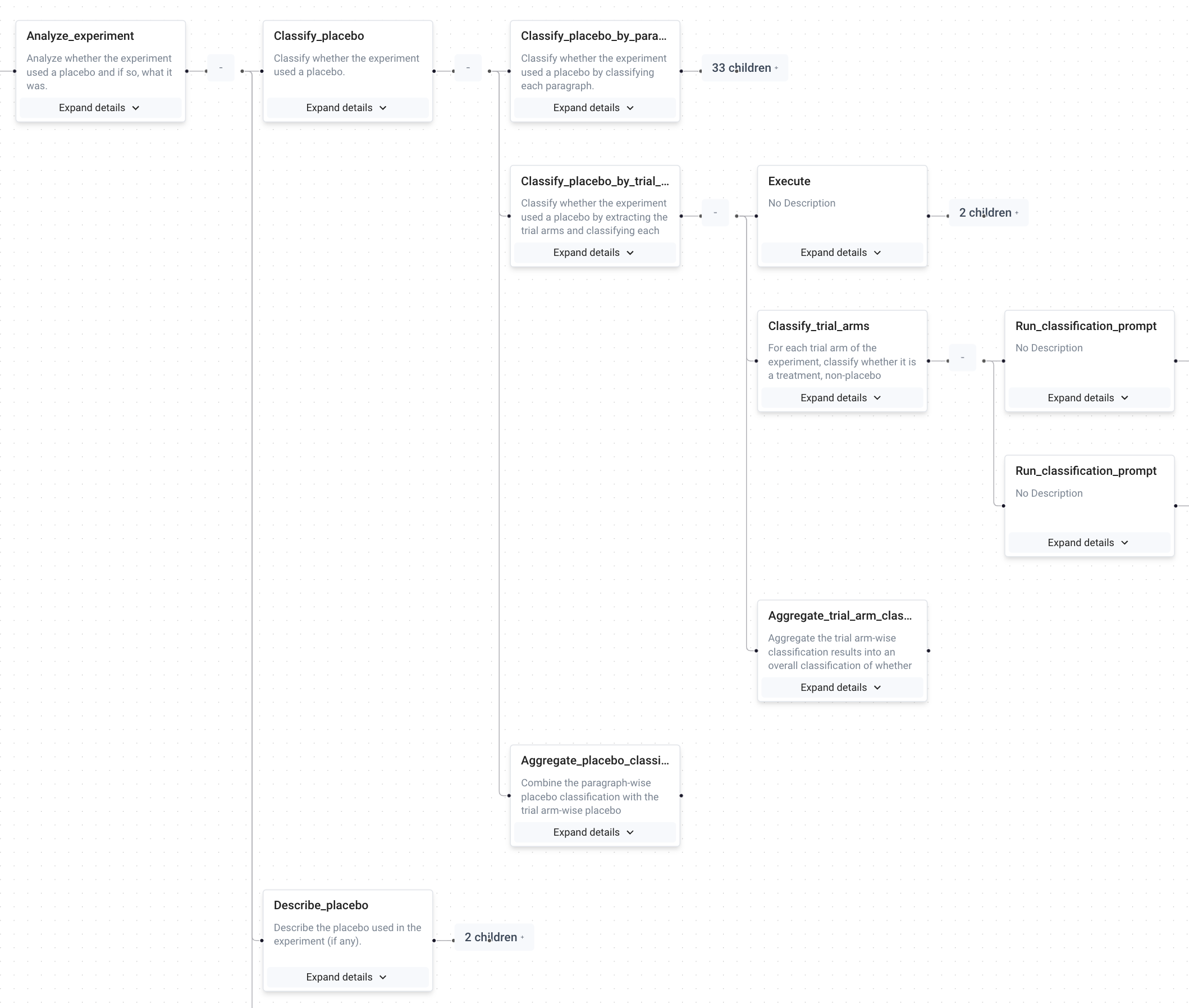
We've recently started making developer tools for our own use as we debug and oversee compositional reasoning. For example, we're recording function calls that correspond to substeps of reasoning so that we can zoom in on steps and see what the inputs and outputs looked like, and where things went wrong. Applied to a decomposition for the task "Did this paper use a placebo? If so, what was it?":
Externalized reasoning models suffer from the "legibility penalty" - the fact that many decisions are easier to make than to justify or explain. I think this is a significant barrier for authentic train of thought competitiveness, although not for particularly legible domains, such as math proofs and programming (Illegible knowledge goes into math proofs, but you trust the result regardless so it's fine).
Another problem is that standard training procedures only incentivize the model to use reasoning steps produced by a single human. This means, for instance, if you ask a question involving two very different domains of knowledge, a good language model wouldn’t expose it’s knowledge about both of them, as that’s OOD for its training dataset. This may appear in an obvious fashion, as if multiple humans collaborated on the train of thought, or might appear in a way that’s harder to interpret. If you just want to expose this knowledge, you could train on amplified human reasoning (ie from human teams) though.
Also, if you ever train the model on conclusion correctness, you incentivize semantic drift between its reasoning and human language - the model would prefer to pack in more information per token than humans, and might want to express not-normally-said-by-human concepts (one type is fuzzy correlations, which models know a lot of). Even if you penalize KL divergence between human language and the reasoning, this doesn't necessarily incentivize authentic human-like reasoning, just its appearance.
In general I'm unsure whether authentic train of thought is better than just having the model imitate specific concrete humans in ordinary language modelling - if you start a text by a known smart, truthful person, you get out an honest prediction over what that person believes.
Agreed, the competitiveness penalty from enforcing internal legibility is the main concern with externalized reasoning / factored cognition. The secular trend in AI systems is towards end-to-end training and human-uninterpretable intermediate representations; while you can always do slightly better at the frontier by adding some human-understandable components like chain of thought (previously beam search & probabilistic graphical models), in the long run a bigger end-to-end model will win out.
One hope that "externalized reasoning" can buck this trend rests on the fact that success in "particularly legible domains, such as math proofs and programming" is actually enough for transformative AI - thanks to the internet and especially the rise of remote work, so much of the economy is legible. Sure, your nuclear-fusion-controller AI will have a huge competitiveness penalty if you force it to explain what it's doing in natural language, but physical control isn't where we've seen AI successes anyway.
Side note:
standard training procedures only incentivize the model to use reasoning steps produced by a single human.
I don't think this is right! The model will have seen enough examples of dialogue and conversation transcripts; it can definitely generate outputs that involve multiple domains of knowledge from prompts like
An economist and a historian are debating the causes of WW2.
Economist:
in the "economist and historian" case, it will only synthesize their knowledge together as much as those humans would, and humans are pretty suboptimal at integrating others' opinions.
When I think about "human-like reasoning" I'm mostly thinking about the causal structure of that reasoning— each step is causally connected to the other reasoning steps in the right kind of way. Luckily it seems like there are lots of ways that you could actually try to enforce this in the model. We can break the usual compute graph of the LM and, say, corrupt some of the tokens in the chain of thought or some of the hidden representations, and see what happens, similar to what the ROME paper did.
I'm actively thinking about how to put this into practice right now and I'm relatively optimistic about the idea.
Thanks for making this thoughtful post. I'm optimistic about this general approach and think it's more promising than other approaches by a significant margin. I'm currently working on a post which will defend a more specific version of the externalized reasoning framework and will explore concrete defenses against steganography etc.
You are right about literally everything you say here. (Will edit with my actual opinions later)
First condition: assess reasoning authenticity
To be able to do this step in the most general setting seems to capture the entire difficulty of interpretability - if we could assess whether a model's outputs faithfully reflect it's internal "thinking" and hence that all of it's reasoning is what we're seeing, then that would be a huge jump forwards (and perhaps possible be equivalent to solving) something like ELK. Given that that problem is known to be quite difficult, and we currently don't have solutions for it, I'm uncertain whether this reduction of aligning a language model into first verifying all its visible reasoning is complete, correct and faithful, and then doing other steps (i.e. actively optimising against this our measures of correct reasoning) is one that makes the problem easier. Do you think it's meaningfully different (i.g. easier) to solve the "assess reasoning authenticity" completely than to solve ELK, or another hard interpretability problem?
I don't have much to add, but I think you would be extremely interested in this line of research, building an agent using GPT-3 to reason through its own decisions and plans:
I’d like to avoid that document being crawled by a web scraper which adds it to a language model’s training corpus.
This may be too late, but it's probably also helpful to put the BIG-Bench "canary string" in the doc as well.
Authenticity seems to me like it would be hard or impossible to guarantee. Humans regularly think in a serial stream of verbal reasoning, but even to ourselves, alone inside our head, we often do so deceptively, rationalizing decisions already made for entirely different reasons to make them look acceptable to inner censors. What's to stop a language model from doing the same thing?
Ideally, if reasoning is displayed that isn't really causally responsible for the conclusion that should be picked up by the tests we create. Tests 2 and 4 in the linked doc start to get at this (https://hackmd.io/@tamera/HJ7iu0ST5-REMOVE, but remove "-REMOVE"), and we could likely develop better tests along these same lines.
Even if we failed to create tests that check for this, the architectures / training processes / prompting strategies that we create might make us more assured that the reasoning is legit. For example, the selection-inference strategy used by DeepMind breaks the reasoning into multiple context windows, which might reduce the chance of long chains of motivated reasoning.
Summary
In this post, I’ll present a research direction that I’m interested in for alignment of pretrained language models.
TL;DR: Force a language model to think out loud, and use the reasoning itself as a channel for oversight. If this agenda is successful, it could defeat deception, power-seeking, and other forms of disapproved reasoning. This direction is broadly actionable now.
In recent publications, prompting pretrained language models to work through logical reasoning problems step-by-step has provided a boost to their capabilities. I claim that this externalized reasoning process may be used for alignment if three conditions are met:
If these conditions hold, we should be able to detect and avoid models that reason through convergent instrumental goals to be deceptive, power-seeking, non-myopic, or reason through other processes of which we don’t approve. Reasoning oversight should provide stronger guarantees of alignment than oversight on model outputs alone, since we would get insight into the causally responsible reasoning process that gave rise to a certain output.
I believe that productive research can be done today toward all three of these conditions.
I’m doing exploratory work into this strategy as part of my SERI MATS project in the large language model alignment stream.
Background
I’ll use “externalized reasoning” to refer to a prompting strategy for a pretrained language model that has it read in a question, produce a number of steps of reasoning, and then produce an answer to the question as its final output. Some examples of this include chain of thought prompting [1, 2], selection-inference [3], and scratchpad reasoning [4]. These types of strategies have recently led to state of the art results on a number of logical reasoning benchmark tasks, most notably 50.3% accuracy on the MATH dataset [5].
A few examples of chain of thought reasoning can be found here.
Future work may develop externalized reasoning approaches different from those that currently exist; ideally, the research directions described here will be able to generalize to sufficiently similar approaches.
Research directions
First condition: assess reasoning authenticity
My main focus right now is in developing tests that can be used to assure that the model’s reasoning is authentic. What “authenticity” means is currently vaguely defined, but fundamentally I want it to encompass whatever is needed to trust that disapproved reasoning couldn’t go undetected. Some aspects of this might include:
It's useful to note that we have read and write access to the externalized reasoning process, which is useful for creating tests that probe causal responsibility.
I’ve written up my current test ideas in another document, but I’d like to avoid that document being crawled by a web scraper which adds it to a language model’s training corpus. Accordingly I’ve put together a poor man’s CAPTCHA which you’ll have to complete to access it (sorry). Please remove the text “-REMOVE” when you visit the link below:
https://hackmd.io/@tamera/HJ7iu0ST5-REMOVE
The tests I’ve developed so far only provide qualitative evidence about the authenticity of a model’s reasoning, and even all the tests taken together are far from foolproof. Developing better tests is one of the major goals of this research direction; so far I’ve only taken a very first stab at it. Real success here will likely involve grappling with difficult questions around what it means for a model to be “actually using” its externalized reasoning, or for a given step of reasoning to be “necessary”, which I have hardly even touched. The process to develop more complete tests may look similar to the builder / breaker methodology described by ARC in the ELK report.
Second condition: create authentic reasoners
It’s not enough to have tests that can confirm if a model is doing authentic reasoning; we may also need to create a model that passes the tests. Designing model architectures and training processes that we think are likely to result in authentic reasoners also provides a kind of defense in depth, alongside the tests of authentic reasoning.
I’ll also note that it’s important that the authentic reasoner models we create be reasonably competitive with those developed by mainstream capabilities, so that they can constitute a safe alternative.
The most straightforward way we might make a model more dependent on externalized reasoning is to give it fewer parameters, possibly by giving it fewer layers of depth. This way, its capacity to use serial compute internally is reduced, and it may be more dependent on the pseudo-serial compute provided by its externalized reasoning. If there are concerns that a sophisticated model could anticipate and thereby evade our reasoning authenticity tests, it’s possible that using a shallower model could assuage that fear. Ideally, the pseudo-serial depth provided by the chain of thought could make up for the hit to performance that would come from reducing the model’s depth, but if that isn’t the case then this approach alone wouldn’t be capabilities competitive.
Another idea comes from a modification of the approach in “Censoring Representations with an Adversary”[7], where the adversary would use the model’s internal states to try to derive the answer to the question while the model itself is still in the middle of reasoning. Optimizing the model against the adversary’s success should reduce the extent to which the final answer is represented in the model’s internal states, making it more dependent upon the externalized reasoning. For many reasons this is far from a complete solution, including concerns about the distribution that the model is trained on.
I’ve hardly explored this direction at all; the strategies above are only meant to illustrate that it doesn’t seem impossible a priori to develop architectures or training processes that would likely create authentic reasoners. I anticipate that further thought should quickly yield better strategies than those listed.
Third condition: oversee the reasoning
Conditional on the first two goals being accomplished (assessing reasoning authenticity and creating authentic reasoners), there are at least two techniques that could be used to reduce the chance of deploying unaligned AI: filtering a model’s outputs in deployment based on the acceptability of its reasoning, and fine-tuning the model to reason acceptably.
For a model in deployment, we could use automated oversight tools that scan its reasoning process for elements we don’t approve of, like reasoning that relates to convergent instrumental subgoals, deception, or that is non-myopic. These tools could be simpler than the system they’re overseeing, and be run in real time against the model’s reasoning before any actions are taken based on the output. If we didn’t approve of the reasoning, we could prevent the action from being taken and raise an alarm instead.
It’s possible that our default training strategy for models would often result in reasoning that we didn’t approve of. In this case, we could fine-tune the model using RLHF on human approval of the reasoning process itself, and in this way train the model to reason in ways that we approve of. This second approach might start to look something like optimizing against our interpretability technique, which could push the model to obfuscate its reasoning. If we take this path we should be especially wary of steganographic messages being encoded in the reasoning.
Advantages of this approach
To me, the major advantage of this research direction comes from the fact that success would enable us to express approval or disapproval over the model’s actual reasoning process.
I think this direction is particularly exciting right now for other reasons as well:
This research direction also suggests a number of projects that can be worked on right now, in parallel with one another. Some of these include:
Shortcomings of this approach
Here are some reasons that this research direction might fail:
The first or second conditions may be impossible to achieve.
The third condition may be impossible to achieve
Other problems may arise
Final words
This research direction is still just a sketch with many details left to be filled in; I look forward to seeing it developed further. I invite anyone who is interested in it or in similar directions to collaborate with one another and with me.
Thanks
I'd like to thank Alex Gray, William Saunders, Kyle McDonell, Evan Hubinger, Leo Gao, and Owain Evans for conversations relating to this work.
I also extend exceptional thanks to my illustrious flatmates in AI House for their insight, advice, and consistent good humor: Ian McKenzie, Peter Barnett, Vivek Hebbar, and Thomas Kwa.
Citations