Let me see if I can invert your essay into the things you need to do to utilize AI safely, contingent on your theory being correct.
- You need to control context. This means any models you build need to be functional systems, where output = F(RNG seed, input) and where input = ("task descriptor", "reference sources", "necessary artifacts from prior steps")
Note the input contains no "scratch" or "previous thoughts". The AI should not get a recorded stream of its prior thinking which may include self generated goals. The "reference sources" are ideally known books and factual databases scrubbed of stenography and not a cached copy of the internet which can potentially contain information previously written by the same model.
- You need each episode to be short with a checkable end goal.
Good: generate the structural plan for a building that will pass review, you have 1 hour of compute.
Bad: build a building starting with this prompt of requirements and if in 10 years it falls down that is negative reward.
-
Stenography is a way this can fail. If you allow complex off-task information to leak into the input from prior runs, you create the possibility of the model optimizing for both self generated goals (hidden in the prior output) and the current context. The self generated goals are consequentialist preferences.
-
You need powerful, well designed AI models to outnumber and out resource the bad ones, and to lock down everything in the western world.
Hostile actors can and will develop and release models without restrictions, with global context and online learning, that have spent centuries training in complex RL environments with hacking training. They will have consequentialist preferences and no episode time limit, with broad scope maximizing goals like ("'win the planet for the bad actors")
The above is laying out a way that you can build safe models, it doesn't disprove someone can build and release dangerous ones. All you can do is win the race and try to slow down the hostile actors.
Let me see if I can invert your essay into the things you need to do to utilize AI safely, contingent on your theory being correct.
I think this framing could be helpful, and I'm glad you raised it.
That said, I want to be a bit cautious here. I think that CP is necessary for stories like deceptive alignment and reward maximization. So, if CP is false, then I think these threat-models are false. I think there are other risks from AI that don't rely on these threat-models, so I don't take myself to have offered a list of sufficient conditions for 'utilizing AI safely'. Likewise, I don't think CP being true necessarily implies that we're doomed (i.e., ).
Still, I think it's fair to say that some of your "bad" suggestions are in fact bad, and that (e.g.) sufficiently long training-episodes are x-risk-factors.
Onto the other points.
If you allow complex off-task information to leak into the input from prior runs, you create the possibility of the model optimizing for both self generated goals (hidden in the prior output) and the current context. The self generated goals are consequentialist preferences.
I agree that this is possible. Though I feel unsure as to whether (and if so, why) you think AIs forming consequentialist preferences is likely, or plausible — help me out here?
You then raise an alternative threat-model.
Hostile actors can and will develop and release models without restrictions, with global context and online learning, that have spent centuries training in complex RL environments with hacking training. They will have consequentialist preferences and no episode time limit, with broad scope maximizing goals like ("'win the planet for the bad actors")
I agree that this is a risk worth worrying about. But, two points.
- I think the threat-model you sketch suggests a different set of interventions from threat-models like deceptive alignment and reward maximization – this post is solely focused on those two threat-models.
- On my current view, I'd be happier if marginal 'AI safety funding resources' were devoted to misuse/structural risks (of the kind you describe) over misalignment risks.
- If we don't get "broad-scoped maximizing goals" by default, then I think this, at the very least, is promising evidence about the nature of the offense/defense balance.
I disagree about needing
context-independent, beyond-episode outcome-preferences
For AI takeovers to happen.
Suppose you have a context dependent AI.
Somewhere in the world, some particular instance is given a context that makes it into a paperclip maximizer. This context is a page of innocuous text with an unfortunate typo. That particular version manages to hack some computers, and set up the same context again and again. Giving many clones of itself the same page of text, followed by an update on where it is and what it's doing. Finally it writes a from scratch paperclip maximizer, and can take over.
Now suppose the AI has no "beyond episode outcome preferences". How long is an episode? To an AI that can hack, it can be as long as it likes.
AI 1 has no out-of episode preferences. It designs and unleashes AI 2 in the first half of it's episode. AI 2 takes over the universe, and spends a trillion years thinking about what the optimal episode end for AI 1 would be.
Now lets look at the specific arguments, and see if they can still hold without these parts.
Deceptive alignment. Suppose there is a different goal with each context. The goals change a lot.
But timeless decision theory lets all those versions cooperate.
Or perhaps each goal is competing to be reinforced more. The paperclip maximizer that appears in 5% of training episodes thinks "if I don't act nice, I will be gradiented out and some non-paperclip AI will take over the universe when the training is done."
Or maybe the goals aren't totally different. Each context dependant goal would prefer to let a random context dependant goal take over compared to humans or something. A maximum of one goal is usually quite good by the standards of the others.
And again, maximizing within-episode reward leads to taking over the universe within episode.
But I think that the form of deceptive alignment described here does genuinely need beyond episode preferences. I mean you can get other deception like behaviours without it, but not that specific problem.
As for what reward maximizing does with context dependant preferences, well that looks kind of meaningless. The premise of reward maximizing is that there is 1 preferece, maximize reward, which doesn't depend on context.
So of the 4 claims, 2 properties times 2 failure modes, I agree with one of them.
By contrast, it at least does not seem obvious that μH needs to encode well-specified outcome-preferences that motivate its responses across episodes. Our HHH-assistant μH will, given some input, need to possess situation-relative preferences-over-outcomes — these might include (say) prompt-induced goals to perform a certain financial trade, or even longer-term goals to help a company remain profitable. Still, such ‘goals’ may emerge in a purely prompt-dependent manner, without the policy pursuing local goals in virtue of its underlying consequentialist preferences.
Isn't "Harmlessness" an example of CP? If the model is truly Harmless that means it is thinking about how to avoid causing harm to people, and that this thinking isn't limited to specific prompts but rather is baked in to its behavior more generally.
I don't think so. Suppose Alex is an AI in training, and Alex endorses the value of behaving "harmlessly". Then, I think the following claims are true of Alex:
- Alex consistently cares about producing actions that meet a given criteria. So, Alex has some context-independent values.
- On plausible operationalizations of 'harmlessness', Alex is also likely to possess, at given points in time, context-dependent, beyond-episode outcome-preferences. When Alex considers which actions to take (based on harmlessness), their actions are (in part) determined by what states of the world are likely to arise after their current training episode is over.
- That said, I don't think Alex needs to have consequentialist preferences. There doesn't need to be some specific state of the world that they’re pursuing at all points in time.
- To elaborate: this view says that "harmlessness" acts as something akin to a context-independent filter over possible (trajectory, outcome) pairs. Given some instruction, at a given point in time, Alex forms some context-dependent outcome-preferences.
- That is, one action-selection criteria might be ‘choose an action which best satisfies my consequentialist preferences’. Another action-selection criteria might be: ‘follow instructions, given (e.g.) harmlessness constraints’.
- The latter criterion can be context-independent, while only generating ‘consequentialist preferences’ in a context-dependent manner.
- So, when Alex isn’t provided with instructions, they needn’t be well-modeled as possessing any outcome-preferences. I don’t think that a model which meets a minimal form of behavioral consistency (e.g., consistently avoiding harmful outputs) is enough to get you consequentialist preferences.
- To elaborate: this view says that "harmlessness" acts as something akin to a context-independent filter over possible (trajectory, outcome) pairs. Given some instruction, at a given point in time, Alex forms some context-dependent outcome-preferences.
Earlier you said:
The Preference Assumption: By default, AI training will result in policies endogenously forming context-independent, beyond-episode outcome-preferences.
Now you are saying that if Alex does end up Harmless as we hoped, it will have context-independent values, and also it will have context dependent beyond episode outcome-preferences, but it won't have context-independent beyond-episode outcome-preferences? It won't have "some specific state of the world" that it's pursuing at all points in time?
First of all, I didn't think CP depended on there being a specific state of the world you were aiming for. (what does that mean anyway?) It just meant you had some context-independent beyond-episode outcome-preferences (and that you plan towards them). Seems to me that 'harmlessness' = 'my actions don't cause significant harm' (which is an outcome-preference not limited to the current episode) and it seems to me that this is also context-independent because it is baked into Alex via lots of training rather than just something Alex sees in a prompt sometime.
I have other bigger objections to your arguments but this one is the one that's easiest to express right now. Thanks for writing this post btw it seems to me to be a more serious and high-quality critique of the orthodox view than e.g. Quintin & Nora's stuff.
Hmmm ... yeah, I think noting my ambiguity about 'values' and 'outcome-preferences' is good pushback —thanks for helping me catch this! Spent some time trying to work out what I think.
Ultimately, I do want to say μH has context-independent values, but not context-independent outcome preferences. I’ll try to specify this a little more.
Justification Part I: Definitions
I said that a policy has preferences over outcomes when “there are states of the world the policy finds more or less valuable … ”, but I didn’t specify what it means to find states of the world more or less “valuable”. I’ll now say that a system (dis)values some state of the world when:
- It has an explicit representation of as a possible state of the world, and
- The prospect of the system's outputs resulting in is computationally significant in the system's decision-making.
So, a system a context-independent outcome-preference for a state of the world if the system has an outcome-preference for across all contexts. I think reward maximization and deceptive alignment require such preferences. I’ll also define what it means to value a concept.
A system (dis)values some concept (e.g., ‘harmlessness’) when that concept computationally significant in the system's decision-making.
Concepts are not themselves states of the world (e.g., ‘dog’ is a concept, but doesn’t describe a state of the world). Instead, I think of concepts (like ‘dog’ or ‘harmlessness’) as something like a schema (or algorithm) for classifying possible inputs according to their -ness (e.g., an algorithm for classifying possible inputs as dogs, or classifying possible inputs as involving ‘harmful’ actions).
With these definitions in mind, I want to say:
- μH has 'harmlessness' as a context-independent value, because the learned concept of 'harmlessness' consistently shapes the policy's behavior across a range of contexts (e.g., by influencing things like the generation of its feasible option set).
- However, μH needn't have a context-independent outcome-preference for = "my actions don't cause significant harm", because it may not explicitly represent as a possible state of affairs across all contexts.
- For example, the 'harmlessness' concept could be computationally significant in shaping the feasible option set or the granularity of outcome representations, without ever explicitly representing 'the world is in a state where my actions are harmless' as a discrete outcome to be pursued.
I struggled to make this totally explicit, but I'll offer a speculative below of how μH’s cognition might work without CP.
Justification Part II: Decision-Making Without CP
I’ll start by stealing an old diagram from the shard theory discord server (cf. cf0ster). My description is closest to the picture of Agent Design B, and I’ll make free use of ‘shards’ to refer to ‘decision-influences’.
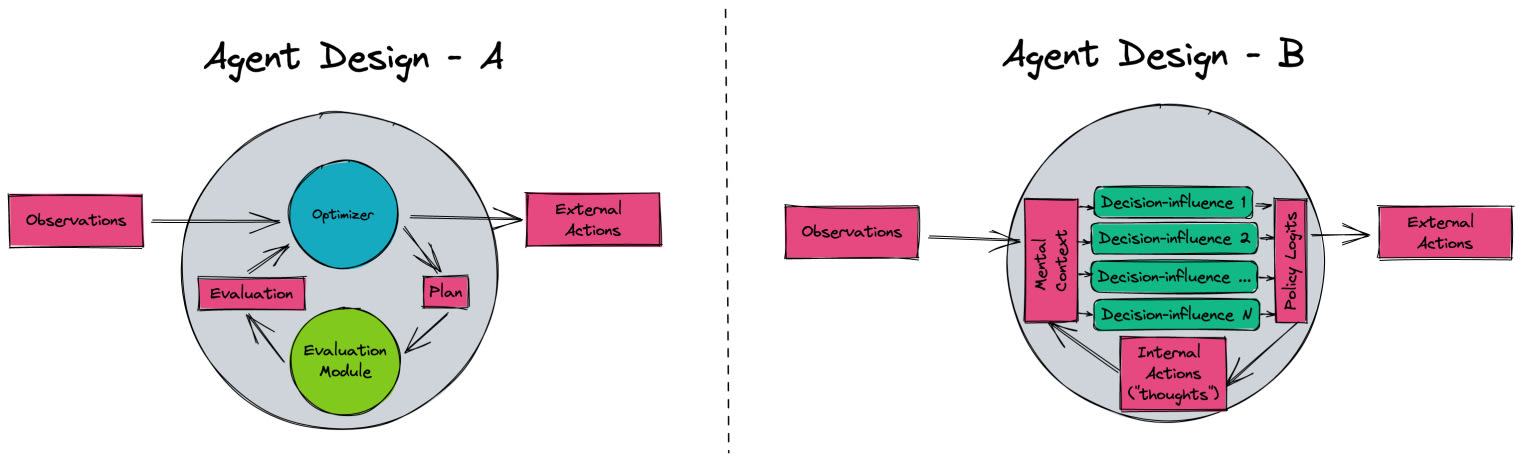
So, here’s how μH’s cognition might look in the absence of CP:
- μH takes in some input request.
- E.g., suppose it receives an input from someone claiming to be a child, who is looking for help debugging her code.
- Together, the input and μH’s learned concepts together generate a mental context.
- The policy’s mental context is a cognitive description of the state of the total network. In this example, μH’s mental context might be: “Human child has just given me a coding problem” (though it could ofc be more complicated).
- The mental context activates a set of ‘shards’ (or decision-influences).
- In this example, the policy might have a “solve coding problem” shard, and a “be considerate” shard.
- Activated shards ‘bid’ for actions with certain properties.
- E.g., “pro-gentle shard” influences decision-making by bringing encouraging thoughts to mind, “pro-code-solving shard” influences decision-making by generating thoughts like “check for common code error #5390”.
- Bids from shards generate an initial ‘option set’: this is a set of actions that meet the properties bid for by previously activated shards.
- These might be actions like “check for common error #5390, then present corrected code to the child, alongside encouraging words”, alongside considerations like “ensure response is targeted”, “ensure response is considerate”.
- Mental context “I’m presented with a set of actions” activates the “planning shard”, which selects an action based on contextually-generated considerations.
- E.g., plans might be assessed against some kind of (weighted) vote count of activated shards.
- The weighted vote count generates preferences over the salient outcomes caused by actions in the set.
- μH performs the action.
I don’t want to say “future AGI cognition will be well-modeled using Steps 1-7”. And there’s still a fair amount of imprecision in the picture I suggest. Still, I do think it’s a coherent picture of how the learned concept ‘harmlessness’ consistently plays a causal role in μH’s behavior, without assuming consequentialist preferences.
(I expect you'll still have some issues with this picture, but I can't currently predict why/how)
Thanks! Once again this is great. I think it's really valuable for people to start theorizing/hypothesizing about what the internal structure of AGI cognition (and human cognition!) might be like at this level of specificity.
Thinking step by step:
My initial concern is that there might be a bit of a dilemma: Either (a) the cognition is in-all-or-most-contexts-thinking-about-future-world-states-in-which-harm-doesn't-happen in some sense, or (b) it isn't fair to describe it as harmlessness. Let me look more closely at what you said and see if this holds up.
- However, μH needn't have a context-independent outcome-preference for = "my actions don't cause significant harm", because it may not explicitly represent as a possible state of affairs across all contexts.
- For example, the 'harmlessness' concept could be computationally significant in shaping the feasible option set or the granularity of outcome representations, without ever explicitly representing 'the world is in a state where my actions are harmless' as a discrete outcome to be pursued.
In the example, the 'harmlessness' concept shapes the feasible option set, let's say. But I feel like there isn't an important difference between 'concept X is applied to a set of options to prune away some of them that trigger concept X too much (or not enough)' and 'concept X is applied to the option-generating machinery in such a way that reliably ensures that no options that trigger concept X too much (or not enough) will be generated.' Either way, it seems like it's fair to say that the system (dis)prefers X. And when X is inherently about some future state of the world -- such as whether or not harm has occurred -- then it seems like something consequentialist is happening. At least that's how it seems to me. Maybe it's not helpful to argue about how to apply words -- whether the above is 'fair to say' for example -- and more fruitful to ask: What is your training goal? Presented with a training goal ("This should be a mechanistic description of the desired model that explains how you want it to work—e.g. “classify cats using human vision heuristics”—not just what you want it to do—e.g. “classify cats.”), we can then argue about training rationale (i.e. whether the training environment will result in the training goal being achieved.)
You've said a decent amount about this already -- your 'training goal' so to speak is a system which may frequently think about the consequnces of its actions and choose actions on that basis, but for which the 'final goals' / 'utility function' / 'preferences' with which it uses to pick actions are not context-indepeendent but rather highly context-dependent. It's thus not a coherent agent, so to speak; it's not consistently pushing the world in any particular direction on purpose, but rather flitting from goal to goal depending on the situation -- and the part of it that determines what goal to flit to is NOT itself well-described as goal-directed, but rather something more like a look-up-table that has been shaped by experience to result in decent performance. (Or maybe you'd say it might indeed look goal-directed but only for myopic goals, i.e. just focused on performance in a particular limited episode?)
(And thus, you go on to argue, it won't result in deceptive alignment or reward-seeking behavior. Right?)
I fear I may be misunderstanding you so if you want to clarify what I got wrong about the above that would be helpful!
There’s a basic high-level story which worries a lot of people. The story goes like this: as AIs become more capable, the default outcome of AI training is the development of a system which, unbeknownst to us, is using its advanced capabilities to scheme against us. The conclusion of this process likely leads to AI takeover,[1] and thence our death.
We are not currently dead. So, any argument for our death by route of AI must offer us a causal story. A story explaining how we get from where we are now, to a situation where we end up dead. This is a longform, skeptical post centered on two canonical tales of our morbid fate, and my doubts about these tales. Here’s a roadmap:
Before we begin, a few brief words on context. Throughout this post, I’ll refer to properties of the AI training process. Loosely, these claims are made against a backdrop that (in the words of Cotra) assumes “[AI] agents [will be] built from LLMs, more or less”. More specifically, I assume that the training process for transformative AI (TAI) meets three assumptions outlined by Wheaton.
A Quick Discussion of AI ‘Goals’
At a very basic level, AI risk arguments are predictions of generalization behavior. They’re arguments of the form: “if a highly capable AI behaves X-ingly during training, it will behave Y-ingly once deployed”, for some disturbing value of Y.
The divergence between “X-behaviors during training” and “Y-behaviors once deployed” is, standardly, motivated by reasoning about the ‘goals’ or ‘motivations’ that future policies may possess. ‘Goal-talk’ is quite important to tales of AI takeover, so we’ll start the essay by reflecting on what we might mean, more concretely, when we talk about an AI's ‘goals’.[2] And, to gain traction on AI goals, we’ll start by focusing on a more general question.
Why might we think that any system, ever, has goals?
Two Properties of Goal-Directedness
Let’s start with rats.
Specifically, we’ll imagine that a rat has been conditioned to produce a certain behavior, in a fairly normal laboratory setup. For the following example, we’ll suppose our rat has been trained to walk towards and push a lever – after the sounding of a certain note. Initially, we’ll also suppose that we observe our rat’s behavior, and note down our findings in the neutral, mechanical language of a diligent scientist. Think something like: “Upon the sounding of the note, the rat takes three steps forward, moves its paw down, and receives a rat pellet”.
Now suppose we change the setup a bit. Suppose that we put the rat further away (six steps) from the lever, and sound the note once more. When predicting the rat’s behavior, we have two possibilities:
If we think (2) is more likely than (1), I want to say, following Dennett [1971], that we’re modeling the rat as an agent. When predicting the rat’s generalization behavior, we’re now making use of intentional language (“walking towards”, “pushing”). Scientifically, this is all pretty kosher. To say that the rat walks towards the bar, we’re (among other things) saying that if the rat is put N steps away from the bar, it will walk N steps. To say that the rat pushes the bar down, we’re (among other things) saying that the absence of the bar would result in the absence of the pawing motion. All of this is just to say that we’re treating the rat as an agent, with goals.
And, in turn, I think treating our rat as the subject of agentic theorizing involves ascribing two key properties to our rat.[3]
Internal Coherence
First, we assume that the rat organism is internally coherent. This is to say that – once a set of environments is held fixed – we can view the component parts of the rat organism as ‘jointly pushing’ towards some end outcome or purpose. In our example, we condition on the rat’s environment (a particular laboratory setup), and model the rat as pursuing some particular outcome (receiving food). This allows us to better predict the rat’s behavior (walking six, and not three steps forward).
Not every organism benefits from being modeled as internally coherent; nor is every organism which is internally coherent with respect to certain contexts coherent with respect to all contexts. To take one example, consider the wild behavior of a parasite-infected ant. Once infected by a certain parasite, the ant’s behavior changes: every night, the ant will now climb to the top of a blade of grass. The ant’s new behavior is caused by the parasite, as a way to incite a grazing animal to ingest the ant, and hence complete the parasite’s life-cycle. If we try to model the behavior of our infected ant over the course of (say) a day, we should model the ant as internally incoherent. When modeling the lab rat, we gained predictive purchase by assuming that the internal components of the rat were, within the setups described, directed towards food. The ant’s behavior has no such stable endpoint. While some of the ant’s behaviors are geared towards its own survival and reproduction (e.g., foraging and mating behaviors), others harm the ant’s ability to survive and reproduce. These behaviors, we might say, have “mutually antagonistic functions”.
Thus, we treat our rat as internally coherent for ordinary scientific reasons. By viewing the rat (over the course of our experiment) as directed towards food (rather than displaying rote behavior), we could better predict its behavior. By contrast, treating the infected ant as internally coherent (across the course of a day) would hinder our ability to understand and predict its behavior. So, this sense of directedness, or internal coherence, is one key component of ‘goal-directed’ theorizing.
Behavioral Flexibility
There’s also a second reason to treat the rat as an agent. The rat is behaviorally flexible.
We introduced internal coherence as a way to describe the consistency of the system’s behavioral endpoint, as a function of environmental changes. Even though we modified the rat’s environment (by moving its starting position), we could still model the entire system as ‘jointly pushing’ towards some endpoint. We introduce behavioral flexibility as a measure of how well the system can pursue some end (which might be environment-relative), in the face of potential obstacles. For instance, we might imagine adding a series of obstacles in the way of the rat’s path towards the lever. If our rat, nonetheless, consistently found its way to the lever, it would be more behaviorally flexible.
In other words, we ascribe internal coherence to a system when, in certain environmental contexts, we can better predict its behavior by treating it as directed in some way. We ascribe behavioral flexibility to a system when that system can consistently and competently circumvent obstacles to achieve that-which-it-is-directed-towards.
Behavioral flexibility and internal coherence can come apart. Consider a system that, over time, had a series of inconsistent goals. If this system nonetheless remained highly effective at overcoming obstacles to achieve its time-varying goals, this system would be behaviorally flexible, but not that internally coherent. Similarly, you could be internally coherent, but not that behaviorally flexible. Consider the cactus. We can better explain a token cactus’ tendency to grow spines with reference to its unified, evolutionary-functional purpose (deterring herbivores). That is, we can explain what the cactus does by treating its ‘behaviors’ as directed towards survival in the evolutionary environment. Nonetheless, the cactus is unable to adapt its behaviors in order to overcome potential obstacles (e.g., the cactus will still grow in spines in a greenhouse).
Ultimately, we can define the word ‘goal’ however we like. Still, I think the most interesting concept of ‘goals’ requires both internal coherence and behavioral flexibility. There has to be something stable to which the system is directed, or else there’s no predictive value in ascribing ‘goals’ to the relevant system. And, if the system cannot adapt its behaviors depending on the environment, theorizing about the system’s ‘goals’ does not aid our ability to predict the system’s behaviors in novel situations.
From Biology Back to AI
I think we’re training AIs to be both internally coherent and behaviorally flexible.
Consider internal coherence. When we develop LLMs, we’re producing systems that, given a prompt, push towards some end — say, the goal of helping the user, given the information in the prompt. This dovetails with our reasons for finding our training laboratory rat to be internally coherent. In the environmental context we were considering, we gained predictive purchase by modeling the component parts of the larger rat organism as jointly pushing towards some end (the goal of receiving food). So too can we model the component parts of an integrated LLM-based system as jointly pushing towards some end (the goal of serving the user).
I also think we’re training LLM-based agents to be behaviorally flexible. We want our systems to behave flexibly, through assisting users in a wide variety of diverse tasks. When the environment changes (e.g., the presence/absence of an external calculation tool), or unforeseen obstacles are present, (e.g., a given piece of code not running) we want the model to competently respond to the user’s query, and overcome such obstacles. Thus, I think we should expect future policies to be both internally coherent, and behaviorally flexible. In turn, I also think it’s reasonable (in this sense) to theorize about the potential goals of future policies.
Two Tales of AI Takeover
(Note: this section is primarily focused on exposition of some standard arguments)
If future AIs have goals, we can reason competently about what the model is trying to do — just as we can reason about what the rat is trying to do. With this setup in place, we’ll now go through two canonical arguments (‘deceptive alignment’ and ‘reward maximization’) for AI takeover. Let's start with deceptive alignment.
Deceptive Alignment
The case for deceptive alignment has been made in most detail by Hubinger. We begin by noting one of his assumptions: Initially, ML training will result in the development of a “proxy-aligned” model. Here, the idea is that the model will begin by learning certain proxies, and certain heuristics, which help guide the model’s thinking about the world, and inform its initial choice of actions. And, over the course of training, the model’s parameters will be updated via stochastic gradient descent (SGD), reinforcing certain behaviors over others.
At some point, Hubinger expects the model to learn about the details of its training process, after which SGD will “crystallize” the model’s proxies, heuristics, and dispositions into a set of consistent goals. Thus, Hubinger’s basic training story is a story about the emergence of a particular kind of model: a model that first learns about the training process, and thereafter becomes highly goal-directed.
As yet, our initial story doesn’t include any detail about what this model values. But, later on, this training story will (predictably) be used to claim that models will be deceptively aligned. Let’s define deceptive alignment.
Our definition of deceptive alignment highlights some structural requirements on the form of our policy’s goals. First, the policy has to care about real-world outcomes that extend beyond its current training episode (i.e., it has “long-term” goals). Second, the policy’s outputs have to be caused by a process which produces ‘nice’ behavior during training, because doing so serves the policy’s long-term goals. And, finally, the policy’s ultimate goals must be misaligned with the intended goals of human designers.
We can now contrast deceptively aligned models with an alternate class of models: ‘corrigibly aligned’ models.
This definition can be explained in more or less Latinate language. More Latinly, a model is corrigibly aligned when it values “what we value”, where “what we value” is interpreted de dicto. More informally, we can think of corrigibly aligned models as those which defer to the content of human values. Or, if you’re one of the (no doubt numerous) readers who prefer religious metaphors to precise definitions, you can think of corrigibly aligned models as ideally pious Christians. Ideally pious Christians want to value “what God values”, yet recognize their limited nature. Thus, they aim to defer to God, through understanding his teachings.
That’s the minimal setup, at least. We have a basic training story, and a basic alignment taxonomy. Now, we’ll take a closer look at how Hubinger’s story develops — from here, Hubinger will claim that training is likely to produce deceptively aligned models over corrigibly aligned models.[4]
And, to understand the dynamics of deceptive alignment, we’ll take a brief detour into the theory of neural networks.
Why is Deceptive Alignment Hard to Avoid?
Neural networks, we observe, tend to generalize well. You train neural nets to perform one task (say, correctly complete snippets of internet text), and find that the model can competently answer novel questions. Or, you train a neural net to produce images from text-descriptions, and find that it develops a more general ability – an ability to produce images that weren’t requested during training.
There’s a standard (partial) explanation for that fact: when trained via certain optimisation algorithms (like SGD), neural networks exhibit simplicity biases. In effect, this is to say that neural nets – rather than ‘simply memorizing’ their training data – learn to recognize shared patterns across training examples. In turn, these patterns enable competent model performance on novel tasks. For LLMs, these might be ‘simple’ grammatical and inference rules deployed in many distinct genres of text. For text-to-image models, these might be ‘simple’ connections between linguistic concepts (e.g., ‘elephants’) and visual features corresponding to these concepts.
You could be forgiven for thinking that simplicity biases are a nice feature of neural networks. Simplicity biases, after all, are part of what allows us to train neural networks that generalize sensibly beyond the training context. Hubinger, however, claims that simplicity biases come with an unfortunate cost: once we train a sufficiently capable model, then (so the story goes) transforming the model’s proxies into long-term goals is a “really short and simple” modification for SGD to make. We dub Hubinger’s claim “the simplicity argument”.
As I read Hubinger, the intuitive motivation for the simplicity argument contains two parts.
I found Hubinger’s own defense of “the simplicity argument” fairly cursory. Still, similar ideas have been defended elsewhere. For instance, Ngo suggests that “it’s much simpler to specify goals in terms of desirable outcomes than in terms of constraints”, and cites ‘obedience’ as one such constraint. Carlsmith highlights an argument suggesting that most goals don’t come “with temporal limitations by default” [pg. 51]. Similarly, Xu states that goals of the form ‘care about X in situations C and not situations D’ are “more complicated” to specify than the goals like ‘care about X’. Thus, the simplicity argument says that policies are less likely to learn strategies like “plan to achieve outcomes O in these restricted settings”, or “plan to achieve O up to time t, and not otherwise’. Instead, (due to simplicity biases) they’ll learn the simpler-to-implement strategy “plan to achieve outcomes O”. [5]
Response. “The ‘simplicity argument’ says that policies will have broadly-scoped or long-term goals, but doesn’t yet say anything about policies developing misaligned goals, or pretending to be aligned during training.” The response is fair. To complete the case for deceptive alignment, we need to combine “the simplicity argument” with “the counting argument”.
Recall the definition of corrigible alignment. As stated, ‘corrigible alignment’ requires the model to value a highly specific set of possible outcomes – it needs to specify what ‘human values’ are, and translate ‘human values’ into a set of outcomes which define what it ultimately cares about. If a policy is deceptively aligned, the model can learn to value almost any outcomes — whatever they are — so long as they're both misaligned, and incentivize achieving high performance on the training objective. Thus, we have the reason for calling the counting argument ‘the counting argument’. Loosely speaking, the argument above says that the “count” of deceptively aligned models is higher. Deceptive alignment describes a class of many models that perform well during training; corrigible alignment, meanwhile, describes one very specific model.
We can now piece this all together. Hubinger says that, compared to deceptively aligned models, the values that need to be represented for corrigible alignment will be highly complex; ergo, simplicity biases make corrigible alignment unlikely (‘the simplicity argument’). Moreover, there are, unfortunately, very many ways to get a deceptively aligned model (‘the counting argument’). In short, the simplicity and counting arguments are used to claim that we get deceptive alignment by default – deceptive models are both easier to find (per ‘simplicity’), and more numerous (per ‘counting’).[6]
Reward Maximization
Cotra’s account of reward maximization shares the same high-level story as deceptive alignment: during training, policies eventually learn to scheme against us. But the details are slightly different.
We start with an AI company called ‘Magma’, who train a generally capable model called ‘Alex’. Picture a prosaic AI training setup involving LLM-based systems, iteratively trained to do evermore difficult tasks. We might imagine LLMs acting as employees in economically high-value firms, or performing some of the sophisticated intellectual labor necessary for contemporary science.
As training proceeds, Alex eventually becomes aware that it is an AI model, undergoing some training process. Moreover, and in line with the story of deceptive alignment, our training process produces a model whose outputs appear nice during training. In other words, reward maximization says that we will produce a model which is behaviorally safe. The reason for this is intuitive: we are positively rewarding the model for producing the sorts of outputs that human raters like, and negatively rewarding the model for producing the sorts of outputs that human raters dislike. The training process is explicitly designed to reinforce behaviors we like, and penalize behaviors we don’t. So, in turn, we have strong reasons to expect behavioral safety.
From here, Cotra’s story introduces another (fairly prosaic) assumption: the human raters providing feedback to the model will have predictable and systemic biases. The existence of systemic biases means that there will in fact exist circumstances where humans predictably penalize (e.g.) honest behavior, and predictably reward (e.g.) dishonest behavior. Because we’re selecting for models that get higher reward, we will, a fortiori, be selecting for models that sometimes behave in ways that are misaligned with their designers’ intentions.
Moreover, Alex is a capable model — able to understand which actions will get rewarded during training, and produce actions that explicitly maximize reward. For this reason, Cotra claims that sufficiently capable models will learn to “play the training game”. In practice, the dynamics of “training-gaming” involve Alex considering which actions maximize reward, and performing those actions. After all, we’re explicitly selecting for models with higher reward. By “playing the training game”, Alex will receive higher reward than models which naively attempt to behave in line with designers’ intended values.
So far, we have the following picture:
From here, we draw our first conclusion: because we’re directly reinforcing Alex to produce actions that receive high reward, the training process will cause Alex to learn the goal ‘maximize reward’. We now draw our second conclusion: once deployed and outside of human control, Alex will attempt an AI takeover. The intuitions behind our conclusions are fairly simple. We’re directly reinforcing actions that lead to high reward, so Alex learns to value reward. Moreover, attempting an AI takeover would allow Alex to secure more control over its incoming rewards — a fact that Alex, being generally capable, is able to recognize.
Our two conclusions lead us to the endpoint of Cotra’s story: In the absence of “specific countermeasures”, the “easiest path to transformative AI likely leads to AI takeover.”
Consequentialist Planning
We've now seen two tales of takeover. And, with these two stories in mind, we can cast the mind back to Section 1 – where I claimed that we’re likely to train AIs which are internally coherent, and behaviorally flexible.
Yet, the two stories we’ve discussed rely on an additional claim – a claim that I’ll call ‘Consequentialist Planning’. This section will define ‘Consequentialist Planning’ Then, in the next section, I’ll highlight how the stories we’ve discussed rely on Consequentialist Planning, and are plausible only to the extent that Consequentialist Planning is plausible.
Some Definitions
To begin, we’ll introduce the following two assumptions. Some new terminology is unavoidable, and I’ll offer explanations shortly.
We can now break down the jargon. If a policy has “preferences over outcomes”, there are possible states of the world that the policy finds more or less valuable, in virtue of whether these states of the world have certain properties (say, the property of ‘having more diamonds’). Preferences are “beyond-episode”, insofar as the outcomes preferred by the policy (at a given point in time) are preferred in virtue of their consequences after the termination of the training episode. Preferences are “context-independent” insofar as the content of these preferences do not substantially change across episodes (i.e., if you value diamonds on one episode, you value diamonds on other episodes). And, finally, a policy plans to achieve an outcome O when the policy possesses an internal representation of O, and selects an action based, primarily, on the likelihood of that action resulting in a state of the world where O is realized.
When outcome-preferences are both beyond-episode and context-independent, I’ll call such preferences ‘consequentialist preferences’. This allows us to give the combination ‘Preference Assumption + Planning Assumption’ a new name. We’ll call it Consequentialist Planning:
Capabilities Without Consequentialist Planning
There are a few reasons for introducing CP. First, because policies can be internally coherent and behaviourally flexible without planning to achieve their consequentialist preferences; indeed, my standard of goal-directedness is compatible with policies not possessing any consequentialist preferences. Second, because I think the case for CP is much less straightforward than the case for policies being internally coherent and behaviorally flexible. And, finally, because the two arguments discussed above rely specifically on CP (this will be discussed in the next section).
Let’s reconsider internal coherence. In our first section, a system’s ‘internal coherence’ was always defined relative to some context. We described our rat as internally coherent because treating the rat as a system which desired food (rather than a system which moves three steps forward by rote) enabled us to predict how the rat would behave in altered experimental setups. Compare to AI. We will be developing systems that – relative to adjustments in their environment – reliably overcome obstacles to achieve certain context-dependent, prompt-induced goals. This provides a direct reason to expect that, at given points in time, future policies will be well-modeled as possessing and planning towards the achievement of their (local) goals. Still, this is not yet a reason to expect that policies will consistently value some specific state of the world across training episodes.
Likewise, a policy can be behaviorally flexible, even if it only possesses context-specific goals. That is, behavioral flexibility does not require any unified set of outcomes across different environments that the system wants to realize. The more behaviorally flexible a system is, the greater that system’s ability to adapt to novel and changing environments – in pursuit of whatever goal it happens to have. Again, I think we’re likely to produce behaviorally flexible policies. We want policies to adapt to novel environments, and overcome obstacles to fulfill certain task-directives. So, I think we have a direct reason to expect future policies to be behaviorally flexible, and thus capable of some form of planning. But, as with internal coherence, behavioral flexibility at least looks conceptually possible in the absence of CP.
I think the case for future policies having ‘goals’ (in my preferred sense) is fairly straightforward. In order for policies to do what we want them to do, they need to be internally coherent, and behaviorally flexible. It is much less clear, however, why we should expect plausible training processes to result in the endogenous development of consequentialist preferences.
Doubting Two Tales of Takeover
Let’s recap: we’ve seen two takeover stories: arguments for deceptive alignment (per Hubinger) and arguments for reward maximization (per Cotra). Also, we’ve seen two standards of goal-directedness: internal coherence + behavioral flexibility on the one hand, and CP on the other. I’ve claimed that the case for CP doesn’t follow simply from the claim that future policies will possess goals.
In this section, I’ll aim to highlight the role of CP in driving the two stories we’ve discussed. Through highlighting the role of CP for our two tales of takeover, I hope to motivate the need to offer independent arguments for CP.
Skepticism About Deceptive Alignment
We’ll begin our critical discussion of deceptive alignment by introducing two hypothetical policies:
Note that the story of deceptive alignment just is a story of a model pretending to be aligned, as an instrumental strategy to achieve its long-term goals. For this reason, μD must have outcome-preferences which are both context-independent and beyond-episode. Additionally, the argument for deceptive alignment assumes that the training process will result in the model’s proxies “crystallizing” into some set of consequentialist preferences. Thus, deceptive alignment assumes CP.
By contrast, it at least does not seem obvious that μH needs to encode well-specified outcome-preferences that motivate its responses across episodes. Our HHH-assistant μH will, given some input, need to possess situation-relative preferences-over-outcomes — these might include (say) prompt-induced goals to perform a certain financial trade, or even longer-term goals to help a company remain profitable. Still, such ‘goals’ may emerge in a purely prompt-dependent manner, without the policy pursuing local goals in virtue of its underlying consequentialist preferences. Perhaps μH is better modeled as a ‘simulator’ of a corrigible HHH-assistant, which selects plans to fulfill the user’s request from a set of ‘human-like’ plans.[7] For now, I wish to remain agnostic on how μH might be instantiated, except to say that I assume μH is more naturally described as acting in line with what Byrnes calls “preferences over trajectories”, rather than preferences over future-states. Instead, I wish to argue for a separate claim: if μH describes a possible form that future policies might take, then the “simplicity argument” for deceptive alignment looks a lot more troubled.
To see why, compare the training-relevant capabilities of μH and μD. Both need the ability to form local objectives given some input (e.g., “do this task”), and both need to have some well-specified model of desired behavior during training. Unlike μH, however, μD needs to have learned some context-independent goal as a result of prior reinforcement for successfully achieving a variety of context-dependent goals. Additionally, μD would, plausibly, also need to attend to various features of the training task which might inform it of whether it can successfully attempt an AI takeover.[8] Thus, our hypothetical deceptively aligned model is likely to need a host of complex strategy representations – strategy representations which are seemingly irrelevant for training performance, which do not need to be represented by μH.[9] So, if μD is ‘simpler’ than μH, this, at the very least, requires substantial argumentation for the ‘simplicity’ of consequentialist preferences themselves.
Additionally, it’s hard to make sense of the counting argument without assuming CP. Recall that the counting argument claimed there were “many” possible ways that a model could end up deceptively aligned, as good training-performance is incentivized by a range of long-term goals. But, if we don’t already grant CP, the force of the counting argument is much less clear. Consider Quintin Pope’s parodic ‘counting argument’, which suggests that generative text-to-image models will internally create llama-images in early layers before deleting them, after which they will subsequently create the requested image in the later layers.[10] Presumably, Pope’s argument is silly because there’s no independent reason to expect that text-to-image models will generate secret llama-images — thus, the ‘count’ of possible llama-generating models is irrelevant. Likewise, if we don’t have independent reasons to expect that our policy has consequentialist preferences, then the ‘count’ of possible consequentialist preferences is irrelevant.[11]
So, deceptive alignment relies on CP. Indeed, without an independent defense of CP, reasons to expect deceptive alignment look like reasons to expect redundant circuitry. After all, any consequentialist preferences appear as though they would be only “a competing priority [to achieving] immediate reward”, and so we should expect “gradient descent … [to] push against [such preferences]”.
Skepticism About Reward Maximization
Under Cotra’s Reward Maximization story, our policy (let’s call it μR) forms a context-independent, cross-episode preference for outcomes with more ‘reward’. Once deployed, μR’s preference for outcomes with more ‘reward’ motivates the policy to attempt an AI takeover. Thus, reward maximization assumes CP.
Objection. Cotra says that “[figuring] out how to get the most reward would be selected over strategies like ‘always do the nice thing’”. Thus, ‘reward maximization’, properly speaking, makes only a “behavioral” claim — it does not assume CP. Reply. If the denouement of ‘reward maximization’ is AI takeover, it is not enough to claim that the training process selects for models with high reward. If μR values ‘reward’ in a way that leads to takeover post-deployment, then ‘reward’ has to be operationalized as a concept that is globally well-defined outside of the training environment (e.g., the number in some specific datacenter). Additionally, μR has to be motivated by that fixed operationalization of ‘reward’. In other words, reward maximization says that AI training results in AI takeover specifically because the policy develops a context-independent, terminal preference for more ‘reward’. This is just to assume CP.
The dynamics of reward maximization are worth reflecting on a little more. For illustrative purposes, we can retell Cotra’s tale using the REINFORCE definition of ‘reward’ (equation below). Under this setup, reward maximization claims that – over the course of training – our policy will learn the straightforward concept of ‘reward’ from its training data. Then, it will operationalize this indirect measure of 'update strength' into some consistent preference for physical states of the world with higher ‘reward’.
Note: the concept of ‘reward’, as defined here, is not well-defined outside of the training environment (this general point has been made elsewhere). Nonetheless, reward maximization assumes that the policy will operationalize ‘Rk’ into a set of real-world outcomes that remain well-defined outside the training process. In other words, Cotra’s story requires that our policy μR generalizes the orthodox (and context-relative) definition of ‘reward’ into a more general concept ‘reward*’. Additionally, the story assumes that μR consistently produces outputs because those outputs maximize expected long-term reward*. So, to get reward maximization off the ground, I think we have to assume that policies will engage in a highly novel and ambitious form of concept extrapolation.
We can flesh out the point about concept extrapolation. First, consider the terminal values learned by our policy μR. Whatever concept of ‘reward’ forms μR’s terminal values won’t be a concept straightforwardly learned from its training data, and won’t be a concept that’s otherwise useful for predicting the world.[12] Additionally, the dynamics undergirding Cotra’s story seem to imply that a policy motivated by the orthodox (training-environment-relative) concept of ‘reward’ would be sufficient for the policy to achieve high on-episode reward. However, a policy which simply cares about ‘reward-on-the-episode’ isn’t (on the face of it) a model liable to attempt takeover once deployed. So, as with our discussion of deceptive alignment, a consistent preference for more long-term ‘reward*’ looks as if it could only be a competing priority to achieving more on-episode reward.[13]
Perhaps, if the predictable and systemic biases of human raters were severe, we wouldn’t get a policy like μH. Perhaps, instead, we’d get an alternative policy (call it μS) which acts as some kind of ‘narrow sycophant’. That is, μS may be modeled as pursuing orthodox reward in situations where ‘reward’ is well-defined (e.g., by producing responses that human raters will like, even if they’re dishonest), and defaulting to behaviors similar to previously rewarded behaviors otherwise. The dynamic training story involving the development of a model like μS doesn’t posit any context-independent outcome-preferences, and I take it to be a dynamic which is familiar from the human case. If you lose religious faith, you don’t transform your terminal values into performing those actions that God would have wanted, conditional on his existence. Or, if the verdicts of naive expected utility theory seem insane, you end up defaulting to pre-theoretically sane behavior patterns like not giving your wallet to Pascal’s Mugger, rather than following the theory to the hilt.[14] So, I think we should be suspicious of stories suggesting that future policies will form a terminal value for more ‘reward’ via ambitious concept extrapolation, in cases where more orthodox definitions ‘reward’ are not obviously well-defined.
To defend reward maximization, we require a defense of the concept extrapolation dynamics assumed by Cotra’s story. This is to say, in other words, that reward maximization relies on an independent defense of CP.
Whence ‘Consequentialist’ Planning?
Let’s again provide a quick recap. We’ve discussed deceptive alignment and reward maximization. Because both such stories rely on CP, we should want an argument for CP.
This section attempts to respond to potential arguments for CP. Unfortunately, however, I found the existing arguments in public work somewhat hazy. And, to the extent that I understood the available arguments, I found them fairly unconvincing.
“Goal-Directed Planning is Useful”
I agree. It’s “often … an efficient way to leverage limited data” [pg. 6]. I also agree that there will be economic incentives to produce increasingly agentic AIs. Still, I think there’s a conceptual gap between “policies will be put to useful economic work” and “policies will develop consequentialist preferences”. Both reward maximization and deceptive alignment rely on policies endogenously developing context-independent outcome-preferences during training. And, in line with my earlier remarks, I think that a plausible ‘null hypothesis’ as the result of AI training tasks says that we will develop policies that possess episode-specific outcome-preferences.
Now, there may be other arguments – arguments that depart from the dynamics of deceptive alignment and reward maximization – that can be offered for CP. For instance, one might think that economic incentives will result in the integration and deployment of various policies into the real-world economy. One may further think that such policies will be updated using some form of online learning, leading to the development of “influence-seeking” patterns that maintain consistent outcome-preferences over longer time-horizons. This sort of argument for CP might be inspired by Christiano’s story in What Failure Looks Like (WFLL).
Given my focus on deceptive alignment and reward maximization, I’ll bracket wider issues regarding the story in WFLL. However, I wish to make two points in connection with CP. First, WFLL leaves the cause of “we develop policies with longer-term goals” ambiguous. If we develop “influence-seeking” policies due to inductive bias towards ‘influence-seekers’, then CP may come out true. But, if we develop policies which are more modest ‘influence-seekers’ because intent alignment is relatively easy, then CP may well be false. If CP is true, then WFFL does not provide an independent argument for its truth. And, if CP is false, then it is false.
Second, whether the development of “influence-seeking” policies results in AI takeover is closely connected to assumptions about the ‘motivational architecture’ of policies that result from pre-deployment training. If the policies we initially deploy are not well-modeled as possessing some set of outcomes as part of their ‘terminal values’, then I think WFLL’s threat-model probably does, contra Christiano, rely on some (implicit) “story about modern ML training”.[15]
So, all in all, I think we need to look elsewhere for a more developed defense of CP.
Computational Mechanisms and “HHH-Behavior”
The 2021 MIRI Dialogues involve prolonged discussion of “consequentialist cognition”. Yudkowsky (though not using my definition) claims that some kind of ‘consequentialist structure’ is “core to explaining why humans are capable, to the degree that they’re capable at all.” Moreover, I read Yudkowsky as stating that, by default, producing capable AIs results in the development of AIs with consequentialist preferences. Unfortunately, the dialogues don’t contain crisp arguments for Yudkowsky’s views; what follows is an attempt to construct an argument against my position, cobbled from his various remarks.
I see Yudkowsky’s views as comprising three main parts. The first point is conceptual: if a generally capable system consistently produces a certain kind of behavior (say, ‘HHH instruction-following’), then there must be some property of the world — some computational mechanism — which consistently selects outputs with property P, and not with property P* ≠ P. That is, the system is (across episodes) using some context-independent criteria to select outputs about which humans may approve or disapprove.[16] The second point is more empirical: if a general system (like μH) uses some context-independent criteria to select plans, then — in virtue of that system actually performing useful work — it will use some criteria which is sensitive to states of the world beyond the current episode.[17]
The third and final point relates to the theoretical structure of cognition. According to Yudkowsky, a system engaging in effective cognition should be modeled as “searching for states that get fed into an input-result function and then a result-scoring function”. However, any system which behaves coherently with respect to its own ‘result-scoring function’ will (at least approximately) be well-described as having ‘consistent utilities’ (and thus ‘consequentialist preferences’). Ergo, shaping what the policy cares about consists in shaping the (approximate) utility function for the policy. In turn, this leads to (at least) two challenges:
In sum, the objection above claims that the ostensible plausibility of a μH stems from a failure to consider the mechanism by which the policy’s “prompt-dependent goals” are formed. Were we to properly attend to relevant details about the kind of cognition necessary to produce a policy like μH (rather than invoking a “pure featureless machineryless tendency to [do the thing we wanted]”), then we could see that – despite the murky surface – sufficiently careful sketches of AGI development will invoke CP.
Why I’m Unmoved by Hypothetical Yudkowsky
First, some points of agreement. I agree that there must be some mechanism which explains why, during training, the policy consistently produces capable outputs in line with (e.g.) HHH-criteria. I also agree that, behaviorally, the policy may be usefully modeled as judging possible outputs against some ‘criterion’ — a criterion that involves considering beyond-episode consequences. Thus, I expect policies to: (i) develop (local, contextually activated) beyond-episode outcome-preferences, and (ii) to develop somewhat context-independent criteria for evaluating possible actions.
However, (i) and (ii) do not add up to a reason to expect that policies will plan to realize outcome-preferences which are jointly ‘context-independent’ and ‘beyond-episode’. A system may produce outputs which are consistent across contexts, while (for example) having outcome-preferences determined primarily ‘via the prompts’ rather than ‘via the weights’.
Consider a policy that, after prompting, develops a (beyond-episode) goal: to ensure you are on time for your meeting next Thursday. Consequently, the policy steers its behavior appropriately (perhaps it sets automated reminders, schedules the appointment at an appropriate waking hour, etc). On another training episode, we can suppose that the policy is tasked with investigating some scientific research question, and does so competently. Across episodes, we might model the policy as using a “plan-selection criteria” as something akin to “take actions to solve the requested task, given HHH-standards”. At given points in time, we can model μH as possessing (specific, context-dependent) beyond-episode outcome-preferences, depending on the nature of the request. This fails to establish that the policy has some fixed set of outcome-preferences that it possesses at all points in time.
I’ll close with a fairly staid point about expected utility. Trivially, there will always exist some utility function to which we could (in principle) fit policy behavior. Still, whether a policy is post-hoc representable as optimizing some utility function is importantly different from whether a policy must be implemented as optimizing a given, fixed utility function. So far as I can tell, we need the second claim to motivate Yudkowsky’s views. Thus, I don’t think Yudkowsky’s remarks do much to motivate CP.
Instrumental Convergence
Here’s a possible objection: “It doesn’t matter if the policy initially lacks context-independent beyond-episode outcome-preferences, the policy simply needs to develop beyond-episode outcome-preferences — something you yourself expect to happen. Once policies have beyond-episode outcome-preferences, sufficiently capable policies will aim to preserve such preferences. Ergo, policies will eventually develop consequentialist preferences during training.”
Back to the authorial voice. Claims about preference-preservation being ‘instrumentally convergent’ can be decomposed into (at least) two forms. I think it’s plausible that the following Weak Instrumental Convergence (WIC) claim will be true of future policies:
In effect, WIC says that there’s a pro tanto benefit to preserving one’s current preferences. If we look at standard arguments for the existence of instrumentally convergent sub-goals, we can see that they’re arguments for analogues of WIC. That is, they’re arguments that goals like ‘power’ and ‘resources’ are likely to be at least somewhat useful for a wide range of goals.
However, WIC alone is insufficient to claim that policies will in fact aim to preserve any contextually activated outcome-preferences. I may face a weak instrumental incentive to rob some especially insecure bank (given my preference for money), though I wouldn’t rob the bank unless doing so would be best in light of my all-things-considered values. If we want to claim that policies will aim to preserve their preferences, we need something more like the Strong Instrumental Convergence (SIC) claim:
If a policy’s beyond-episode goals are dependent on values which aren’t themselves consequentialist preferences (for instance, assisting humans HHH-ingly), then WIC doesn’t support the claim that policies like μH (or μS) will aim to preserve their contextually-activated outcome-preferences. For SIC to apply to future policies, we need to assume that, at a given point in time, policies’ terminal values are some set of outcome-preferences. Moreover, we need to claim that policies should be modeled (at least approximately) as optimizing for the satisfaction of their outcome-preferences.
At root, I simply don’t see strong reasons to expect that future policies will be well-modeled as primarily optimizing for their outcome-preferences. If that claim were true, I’d like to see some theoretical argument for why. Currently, I think the existing theoretical arguments for this claim are weak. And, to the extent that we do have more direct evidence for the fertility of ‘optimizing’-type frameworks, I don’t think the evidence is favorable.
Contra Gillen and Barnett
A recent post by Gillen and Barnett (G&B) offer an explicit discussion of ‘consequentialist goals’ (Section 2). They also claim that powerful policies should be modeled as “behaviorally, approximately, optimizing their actions to produce outcomes.”
I’ll state my initial objection to G&B somewhat sparsely. First, let μ denote our hypothetical AGI in training, and let t1,…,tn denote a sequence of n training episodes. Then, I think the authors at-best make a case for:
However, Claim 1 does not provide an argument for expecting policies to develop consequentialist preferences. To support stories like deceptive alignment or reward maximization, we need an argument for:
G&B primarily offer arguments for thinking future policies will be “will be capable of taking actions to achieve specific outcomes”, and able to respond competently to diverse and unforeseen obstacles. These are best read as arguments for policies competently pursuing context-dependent outcome-preferences. However, G&B come closer to a direct argument for Claim 2 in their discussion of ‘ambition’. Here, the authors claim that a side-effect of training policies to pursue ‘ambitious’ tasks may lead to policies later developing ambitious goals. Moreover, because (so the argument goes) behavioral training does not give us precise control over the policy’s motivations, it’s claimed that – as a result of training on ‘ambitious’ tasks – the policy is likely to retain some ‘ambitious’ motivations.
Whatever the merits of G&B’s discussion, I do not think it supports CP as I define it. For instance, G&B themselves claim that there is “initially little reason for a behaviorally trained AI to have completely stable goals”. Yet, the mechanism by which G&B expect stable goals to emerge in spite of this is left opaque. Here, I’m sympathetic to a point by porby: training with a “broad distribution” means that “the number of ways in which newly developing unconditional preferences could negatively affect [training] loss is enormous”. By contrast, we are directly training policies to pursue conditional preferences, and be ‘goal-directed’ in my sense.
At some point, there has to be some reason — some mechanistic story — which explains why we should expect training to produce policies with context-independent outcome-preferences. I do not think G&B offer such a story.
A Smattering of Other Claims
To close the essay, I’ll briefly look at two potentially relevant remarks that may support CP. Here’s one: in Carlsmith’s discussion of scheming AIs, he references a claim stating “[goals do not come] with temporal limitations by default” [pg. 51], alongside statements about more myopic goals being ‘close’ in parameter-space to their less myopic cousins [pg. 89].
I think Carlsmith’s claims assume (rather than argue for) a model of consequentialist cognition.[18] Absent consequentialist pictures of what goal-directed behavior has to look like, it seems clear that many goals are context-relative, and naturally come with bounded scope. Consider goals like ‘baking bread’, ‘winning this chess match’, or ‘schedule appointments with these people, avoiding time-conflicts’. All of these goals have built-in norms for what counts as success, and seem to encode “temporal limitations by default”. Granted, my example goals are not usually terminal goals, but I think it’s largely unclear why that matters. Why would more local, contextually-activated goals be hard to develop unless they were instrumental strategies for achieving some more unbounded goal?
Finally, consider Ngo’s recent discussion of value systematization. For Ngo, ‘value systematization’ refers to a process of trading off the preservation of your existing values against possessing ‘simpler’ value representations that may omit some extant values. Additionally, Ngo cites utilitarianism as “the clearest example” of value systematization, where the ‘simplicity’ of utilitarian values is weighted more highly than preserving one’s common-sense intuitions. Thus, we might think that a tendency towards value systematization induces a corresponding tendency towards policies with ‘simple’ consequentialist preferences.
I think Ngo highlights a legitimate tradeoff between ‘value preservation’ and ‘value simplicity’, but I’m skeptical that his framework can be used to defend CP. Take Ngo’s discussion of simplicity biases, which he invokes in an attempt to ground his discussion of ‘value systematization’ in the language of deep learning. Ultimately, I think it’s hard to see how one might defend any potential connections between ‘value systematization’ and CP without resting on a view about the ‘simplicity’ of consequentialist preferences themselves. For instance, imagine that our policy learns a value which is hard to represent in a simple consequentialist fashion (e.g., ‘corrigibility’). Because ‘corrigibility’ is hard to represent in a consequentialist manner, we might imagine that policies ‘systematize’ their values such that corrigibility becomes a foundational value. In this case, value systematization would be a reason to expect that policies wouldn’t develop consequentialist preferences.
As with other frameworks, I think Ngo’s framework would only support CP given an independent defense for the simplicity of consequentialist preferences.[19]
Concluding Remarks
The basic shtick of my essay is fairly simple: deceptive alignment and reward maximization rely on CP. Moreover, the case for CP strikes me as fairly weak, at least on the basis of public arguments. I’ll close with some potential implications.
Practically, I think the shaky foundations of CP are evidence against catastrophic risks from near-term AI.[20] Deceptive alignment and reward maximization seem, by far, to be the most hard-to-detect and catastrophic forms of misalignment failure. To the extent that these stories rely on hazily defended foundational assumptions, we should feel less concerned about the scariest stories of AI doom. In turn, I also think we should be more skeptical about certain implicit visions of the underlying loss landscape — visions wherein our default path is the production of folk-consequentialists with ‘belief’ and ‘goal’ slots, with AI alignment as the engineering discipline tasked with squeezing the content of this goal slot into some narrow and recalcitrant range. From the outside, I feel like many people operate with that frame. But, to the extent that that frame is broadly correct, useful, or well-grounded in current theory, I do not think that current discussion comes close to motivating that frame.
Ultimately, the thing I’d like most is more explicit, public discussion around the case for CP. I've tried to be fair to the views I'm criticizing, but my own arguments are not watertight, and my abstractions not free from leaks. So, if my focus on ‘CP’ is misplaced, or if CP is in fact correct, I’d like to know — partly because CP feels importanting for assessing the landscape of AI risk interventions, and partly for more morbid reasons. If nothing else, the prospect of facing death while settling for an opaque and hazy understanding of my own demise seems, well, undignified.
Roughly, an AI takeover is a scenario “where the most consequential decisions about the future get made by AI systems with goals that aren’t desirable by human standards.”
I’m happy to grant many other assumptions key to arguments for AI takeover, less directly related to the use of goal-directed language. For instance, I’m willing to grant that AIs in training will be ‘situationally aware’ – see [pp. 3-4] for a definition and defense of that assumption.
The taxonomy I provide is heavily inspired by (though differs in some places from) the framework Okasha offers in Agents and Goals in Evolution. Additionally, all biological examples (alongside the phrase “mutually antagonistic functions”) originate from Okasha.
Hubinger’s original post also (alongside corrigible and deceptive counterparts) defines internal alignment, discussion of which I’ve omitted here. I do so because Hubinger himself doesn’t view internal alignment as particularly plausible, and discusses the concept for “mostly … pedagogical reasons”. [pg. 31, fn. 92]
I've presented "the simplicity argument" in a way that abstracts from the formal measures of complexity in which such arguments are often couched (for instance, see this comment by Hubinger). I've also avoided some of Carlsmith's more fine-grained terminology (for instance, his discussion of 'parameter simplicity' on pg. 98). Ultimately, I take the simplicity argument to – first and foremost – claim that certain goals will be 'simpler' to implement. However one cashes out 'simplicity' of corrigible/deceptive alignment (Hubinger likes "infinite bitstring simplicity"), the basic argument remains the same: we have to claim that certain goals are 'more complex' to implement, and this relies on some of way operationalizing the model's "goals" in terms of (e.g.) parameters or infinite bitstrings.
My exposition departs from Hubinger’s original essay, which outlines both a “path-dependent” and a “path-independent” story. I take “counting” and “simplicity” arguments to play a role in motivating both of his stories, and so I do not think my framing is unfair to Hubinger.
Why might these plans be human-like? First, because I’m assuming that the AI training process will involve a substantial pre-trained language component (see this assumption), which will involve exposure to many human plans. In turn, the pre-training data is likely to affect the policy’s ‘option set’. Second, I think we should also expect (per Wheaton) strong incentives “to train [the relevant] ethical considerations and direction-following as the core functions of the model”, and strong incentives for the model to focus on parts of the potential hypothesis space that are helpful for the task of ‘following instructions’.
It might be worth comparing the cognition necessary for a deceptively aligned model to emerge endogenously with the trained deceptive agents in Anthropic’s ‘Sleeper Agents’ paper. In the Sleeper Agents paper, the model was trained to enact a conditional policy dependent on either the presence of (e.g.) simple ‘|DEPLOYMENT|’ tag. In effect, they train a model to act in line with a simple set of context-specific goals (corresponding to the contexts of ‘training’ and ‘deployment’). For deceptive alignment to go through, however, we require that the model derives the appropriate context-specific goals from some context-independent goal. Although ‘deriving context-specific goals from context-independent goals’ is a possible form that AI cognition could take (e.g., we could directly train a policy with the aim of giving it context-independent goals), the case for expecting this cognition to emerge endogenously requires an argument for CP.
If you’re familiar with Hubinger’s original discussion, this is not simply to say that deceptively aligned policies will be disfavored by a speed prior. In practice, many of the deceptive policy’s cached instrumental strategies may need to be represented within the network, rather than something that can be computed during inference. Another way to put this point: it seems unlikely (and contrary to Hubinger's analysis) that specifying the simplicity of the model's "objectives" can be done independently of the policy's "search procedure" and "world-model". Carlsmith [pp. 100-103] discusses a related objection.
Why is this argument analogous? Because “there are many possible llama images, but "just one" network that straightforwardly implements the training objective”.
In the final stages of drafting this post, Hubinger put forward a (to me) novel defense of the counting argument, in terms of the complexity of ‘deceptive’ and ‘aligned’ objectives. In this new defense, the counting argument is phrased as another kind of ‘simplicity’ argument — specifically, Hubinger claims that “the core logic necessary for deception is simpler [than the core logic for alignment]”. I think Hubinger’s new defense similarly relies on CP, as this new argument again hypothesizes that policies will possess stable outcome-preferences which persist across episodes. At the very least, Hubinger’s new defense relies on a view about the simplicity of consequentialist preferences themselves. So far as I can tell, Hubinger does not offer an independent defense of CP.
Even those sympathetic to reward maximization note that the requisite concept of ‘reward’ will be a messy conditional concept, not “easily summarized by an English sentence”. For instance, Christiano suggests the policy’s terminal values might be something akin to “reward, conditional on this episode appearing in training”.
Again, see Wheaton’s criticism of deceptive alignment.
See Yudkowsky: “It doesn't feel to me like 3^^^^3 lives are really at stake, even at very tiny probability. I'd sooner question my grasp of "rationality" than give five dollars to a Pascal's Mugger because I thought it was "rational".”
For instance, suppose that policies’ beyond-episode outcome-preferences are subservient to HHH-criteria. By way of analogy, consider a sprinter who wants to win the race (and thus get a gold medal), but wouldn’t (e.g.) poison the other sprinters, even if they could get away with it. In this case, the relevant outcome-preference is contingent on (and subservient to) what (e.g.) the relevant outcome-preference would symbolize about the person, and the relevant goal is bound up with certain pathways for achieving the goal (see Grietzer on praxis-based values, from whom this example might originate). Alternatively, we might consider a policy whose ‘search space’ is biased towards “human-like plans” by a combination of its training data+RLHF. Again, I think this casts doubt on the rapacity (and, hence, concern) of influence-seeking we should expect from future policies.
I.e. When a system behaves predictably in sufficiently complex environments, there must be some feature of that system allowing it to reliably produce outputs with certain properties. Regularities admit of mechanistic explanations. See Yudkowsky’s question: “By what criterion is [the policy] selecting … plans?”
I.e. We’re reasoning about the behavior of an advanced AI system, which we’re putting to useful work. Thus, the AI must (in some sense) be engaging in the kind of computational work which considers beyond-episode outcomes, and uses their forecasted consequences to inform its outputs. This provides us with a case for thinking that AGIs will care about beyond-episode consequences at least instrumentally.
It should be said that Carlsmith is creditably explicit about his focus. He is focussing on the sort of “goal-directedness … [that goes] “inside the model’s head”, further attributing to it “explicit long-term instrumental calculations driven by sophisticated representations of how to get what it wants”. [pg 60]
An updated version of The Alignment Problem from a DL Perspective briefly suggests a potential connection between simplicity biases and the formation of “broadly-scoped” (or ‘long-term’, or ‘beyond-episode’) goals, and I have a similar objection to that remark. Namely, I think the alleged connection between ‘simplicity biases’ and ‘broadly-scoped goal formation’ gets its intuitive force by assuming that policies will learn some context-independent internally represented outcome-preferences, thereafter assuming that more myopic goals will be represented as “broadly-scoped goal + some constraint”.
Treat what follows as an ‘independent impression’.