Morality seems like the domain where humans have the strongest instinct to systematize our preferences
At least, the domain where modern educated Western humans have an instinct to systematize our preferences. Interestingly, it seems the kind of extensive value systematization done in moral philosophy may itself be an example of belief systematization. Scientific thinking taught people the mental habit of systematizing things, and then those habits led them to start systematizing values too, as a special case of "things that can be systematized".
Phil Goetz had this anecdote:
I'm also reminded of a talk I attended by one of the Dalai Lama's assistants. This was not slick, Westernized Buddhism; this was saffron-robed fresh-off-the-plane-from-Tibet Buddhism. He spoke about his beliefs, and then took questions. People began asking him about some of the implications of his belief that life, love, feelings, and the universe as a whole are inherently bad and undesirable. He had great difficulty comprehending the questions - not because of his English, I think; but because the notion of taking a belief expressed in one context, and applying it in another, seemed completely new to him. To him, knowledge came in units; each unit of knowledge was a story with a conclusion and a specific application. (No wonder they think understanding Buddhism takes decades.) He seemed not to have the idea that these units could interact; that you could take an idea from one setting, and explore its implications in completely different settings.
David Chapman has a page talking about how fundamentalist forms of religion are a relatively recent development, a consequence of how secular people first started systematizing values and then religion has to start doing the same in order to adapt:
Fundamentalism describes itself as traditional and anti-modern. This is inaccurate. Early fundamentalism was anti-modernist, in the special sense of “modernist theology,” but it was itself modernist in a broad sense. Systems of justifications are the defining feature of “modernity,” as I (and many historians) use the term.
The defining feature of actual tradition—“the choiceless mode”—is the absence of a system of justifications: chains of “therefore” and “because” that explain why you have to do what you have to do. In a traditional culture, you just do it, and there is no abstract “because.” How-things-are-done is immanent in concrete customs, not theorized in transcendent explanations.
Genuine traditions have no defense against modernity. Modernity asks “Why should anyone believe this? Why should anyone do that?” and tradition has no answer. (Beyond, perhaps, “we always have.”) Modernity says “If you believe and act differently, you can have 200 channels of cable TV, and you can eat fajitas and pad thai and sushi instead of boiled taro every day”; and every genuinely traditional person says “hell yeah!” Because why not? Choice is great! (And sushi is better than boiled taro.)
Fundamentalisms try to defend traditions by building a system of justification that supplies the missing “becauses.” You can’t eat sushi because God hates shrimp. How do we know? Because it says so here in Leviticus 11:10-11.3
Secular modernism tries to answer every “why” question with a chain of “becauses” that eventually ends in “rationality,” which magically reveals Ultimate Truth. Fundamentalist modernism tries to answer every “why” with a chain that eventually ends in “God said so right here in this magic book which contains the Ultimate Truth.”
The attempt to defend tradition can be noble; tradition is often profoundly good in ways modernity can never be. Unfortunately, fundamentalism, by taking up modernity’s weapons, transforms a traditional culture into a modern one. “Modern,” that is, in having a system of justification, founded on a transcendent eternal ordering principle. And once you have that, much of what is good about tradition is lost.
This is currently easier to see in Islamic than in Christian fundamentalism. Islamism is widely viewed as “the modern Islam” by young people. That is one of its main attractions: it can explain itself, where traditional Islam cannot. Sophisticated urban Muslims reject their grandparents’ traditional religion as a jumble of pointless, outmoded village customs with no basis in the Koran. Many consider fundamentalism the forward-looking, global, intellectually coherent religion that makes sense of everyday life and of world politics.
Jonathan Haidt also talked about the way that even among Westerners, requiring justification and trying to ground everything in harm/care is most prominent in educated people (who had been socialized to think about morality in this way) as opposed to working-class people. Excerpts from The Righteous Mind where he talks about reading people stories about victimless moral violations (e.g. having sex with a dead chicken before eating it) to see how they thought about them:
I got my Ph.D. at McDonald’s. Part of it, anyway, given the hours I spent standing outside of a McDonald’s restaurant in West Philadelphia trying to recruit working-class adults to talk with me for my dissertation research. When someone agreed, we’d sit down together at the restaurant’s outdoor seating area, and I’d ask them what they thought about the family that ate its dog, the woman who used her flag as a rag, and all the rest. I got some odd looks as the interviews progressed, and also plenty of laughter—particularly when I told people about the guy and the chicken. I was expecting that, because I had written the stories to surprise and even shock people.
But what I didn’t expect was that these working-class subjects would sometimes find my request for justifications so perplexing. Each time someone said that the people in a story had done something wrong, I asked, “Can you tell me why that was wrong?” When I had interviewed college students on the Penn campus a month earlier, this question brought forth their moral justifications quite smoothly. But a few blocks west, this same question often led to long pauses and disbelieving stares. Those pauses and stares seemed to say, You mean you don’t know why it’s wrong to do that to a chicken? I have to explain this to you? What planet are you from?
These subjects were right to wonder about me because I really was weird. I came from a strange and different moral world—the University of Pennsylvania. Penn students were the most unusual of all twelve groups in my study. They were unique in their unwavering devotion to the “harm principle,” which John Stuart Mill had put forth in 1859: “The only purpose for which power can be rightfully exercised over any member of a civilized community, against his will, is to prevent harm to others.”1 As one Penn student said: “It’s his chicken, he’s eating it, nobody is getting hurt.”
The Penn students were just as likely as people in the other eleven groups to say that it would bother them to witness the taboo violations, but they were the only group that frequently ignored their own feelings of disgust and said that an action that bothered them was nonetheless morally permissible. And they were the only group in which a majority (73 percent) were able to tolerate the chicken story. As one Penn student said, “It’s perverted, but if it’s done in private, it’s his right.” [...]
Haidt also talks about this kind of value systematization being uniquely related to Western mental habits:
I and my fellow Penn students were weird in a second way too. In 2010, the cultural psychologists Joe Henrich, Steve Heine, and Ara Norenzayan published a profoundly important article titled “The Weirdest People in the World?” The authors pointed out that nearly all research in psychology is conducted on a very small subset of the human population: people from cultures that are Western, educated, industrialized, rich, and democratic (forming the acronym WEIRD). They then reviewed dozens of studies showing that WEIRD people are statistical outliers; they are the least typical, least representative people you could study if you want to make generalizations about human nature. Even within the West, Americans are more extreme outliers than Europeans, and within the United States, the educated upper middle class (like my Penn sample) is the most unusual of all.
Several of the peculiarities of WEIRD culture can be captured in this simple generalization: The WEIRDer you are, the more you see a world full of separate objects, rather than relationships. It has long been reported that Westerners have a more independent and autonomous concept of the self than do East Asians. For example, when asked to write twenty statements beginning with the words “I am …,” Americans are likely to list their own internal psychological characteristics (happy, outgoing, interested in jazz), whereas East Asians are more likely to list their roles and relationships (a son, a husband, an employee of Fujitsu).
The differences run deep; even visual perception is affected. In what’s known as the framed-line task, you are shown a square with a line drawn inside it. You then turn the page and see an empty square that is larger or smaller than the original square. Your task is to draw a line that is the same as the line you saw on the previous page, either in absolute terms (same number of centimeters; ignore the new frame) or in relative terms (same proportion relative to the frame). Westerners, and particularly Americans, excel at the absolute task, because they saw the line as an independent object in the first place and stored it separately in memory. East Asians, in contrast, outperform Americans at the relative task, because they automatically perceived and remembered the relationship among the parts.
Related to this difference in perception is a difference in thinking style. Most people think holistically (seeing the whole context and the relationships among parts), but WEIRD people think more analytically (detaching the focal object from its context, assigning it to a category, and then assuming that what’s true about the category is true about the object). Putting this all together, it makes sense that WEIRD philosophers since Kant and Mill have mostly generated moral systems that are individualistic, rule-based, and universalist. That’s the morality you need to govern a society of autonomous individuals.
But when holistic thinkers in a non-WEIRD culture write about morality, we get something more like the Analects of Confucius, a collection of aphorisms and anecdotes that can’t be reduced to a single rule.6 Confucius talks about a variety of relationship-specific duties and virtues (such as filial piety and the proper treatment of one’s subordinates). If WEIRD and non-WEIRD people think differently and see the world differently, then it stands to reason that they’d have different moral concerns. If you see a world full of individuals, then you’ll want the morality of Kohlberg and Turiel—a morality that protects those individuals and their individual rights. You’ll emphasize concerns about harm and fairness.
But if you live in a non-WEIRD society in which people are more likely to see relationships, contexts, groups, and institutions, then you won’t be so focused on protecting individuals. You’ll have a more sociocentric morality, which means (as Shweder described it back in chapter 1) that you place the needs of groups and institutions first, often ahead of the needs of individuals. If you do that, then a morality based on concerns about harm and fairness won’t be sufficient. You’ll have additional concerns, and you’ll need additional virtues to bind people together.
I'd previously sketched out a model basically identical to this one, see here and especially here.
... but I've since updated away from it, in favour of an even simpler explanation.
The major issue with this model is the assumption that either (1) the SGD/evolution/whatever-other-selection-pressure will always convergently instill the drive for doing value systematization into the mind it's shaping, or (2) that agents will somehow independently arrive at it on their own; and that this drive will have overwhelming power, enough to crush the object-level values. But why?
I'd had my own explanation, but let's begin with your arguments. I find them unconvincing.
- First, the reason we expect value compilation/systematization to begin with is because we observe it in humans, and human minds are not trained the way NN models are trained. Moreover, the instances where we note value systematization in humans seem to have very little to do with blind-idiot training algorithms (like the SGD or evolution) at all. Instead, it tends to happen when humans leverage their full symbolic intelligence to do moral philosophy.
- So the SGD-specific explanations are right out.
- So we're left with the "the mind itself wants to do this" class of explanations. But it doesn't really make sense. If you value X, Y, Z, and those are your terminal values, whyever would you choose to rewrite yourself to care about W instead? If W is a "simple generator" of X, Y, Z, that would change... precisely nothing. You care about X, Y, Z, not about W; nothing more to be said. Unless given a compelling external reason to switch to W, you won't do that.
- At most you'll use W as a simpler proxy measure for fast calculations of plans in high-intensity situations. But you'd still periodically "look back" at X, Y, Z to ensure you're still following them; W would ever remain just an instrumental proxy.
So, again, we need the drive for value systematization to be itself a value, and such a strong one that it's able to frequently overpower whole coalitions of object-level values. Why would that happen?
My sketch went roughly as follows: Suppose we have a system at an intermediary stage of training. So far it's pretty dumb; all instinct and no high-level reasoning. The training objective is ; the system implements a set of contextually-activated shards/heuristics that cause it to engage in contextual behaviors . Engaging in any is correlated with optimizing for , but every is just that: an "upstream correlate" of , and it's only a valid correlate in some specific context. Outside that context, following would not lead to optimizing for ; and the optimizing-for- behavior is only achieved by a careful balance of the contextual behaviors.
Now suppose we've entered the stage of training at which higher-level symbolic intelligence starts to appear. We've grown a mesa-optimizer. We now need to point it at something; some goal that's correlated with . Problem: we can only point it at goals concepts corresponding to which are present in its world-model, and might not even be there yet! (Stone-age humans had no idea about inclusive genetic fitness or pleasure-maximization.) We only have a bunch of s...
In that case, instilling a drive for value systematization seems like the right thing to do. No is a proper proxy for , but the weighted sum of them, , is. So that's what we point our newborn agent at. We essentially task it with figuring out for what purpose it was optimized, and then tell it to then go do that thing. We hard-wire this objective into it, and make it have an overriding priority.
(But of course is still an imperfect proxy for , and the agent's attempts to figure out are imperfect as well, so it still ends up misaligned from .)
That story still seems plausible to me. It's highly convoluted, but it makes sense.
... but I don't think there's any need for it.
I think "value systematization" is simply the reflection of the fact that the world can be viewed as a series of hierarchical ever-more-abstract models.
- Suppose we have a low-level model of reality , with variables (atoms, objects, whatever).
- Suppose we "abstract up", deriving a more simple model of the world , with variables. Each variable in it is an abstraction over some set of lower-level variables , such that .
- We iterate, to , , ..., . Caveat: . Since each subsequent level is simpler, it contains fewer variables. People to social groups to countries to the civilization; atoms to molecules to macro-scale objects to astronomical objects; etc.
- Let's define the function . I. e.: it returns a probability distribution over the low-level variables given the state of a high-level variable that abstracts over them. (E. g., if the world economy is in this state, how happy my grandmother is likely to be?)
- If we view our values as an utility function , we can "translate" our utility function from any to roughly as follows: . (There's a ton of complications there, but this expression conveys the concept.)
... and then value systematization just naturally falls out of this.
Suppose we have a bunch of values at th abstraction level. Once we start frequently reasoning at th level, we "translate" our values to it, and cache the resultant values. Since the th level likely has fewer variables than th, the mapping-up is not injective: some values defined over different low-level variables end up translated to the same higher-level variable ("I like Bob and Alice" -> "I like people"). This effect only strengthens as we go up higher and higher; and at , we can plausibly end up with only one variable we value ("eudaimonia" or something).
That does not mean we stop caring about our lower-level values. Nay: those translations are still instrumental, we simply often use them to save on processing costs.
... or so it ideally should be. But humans are subject to value drift. An ideal agent would never forget the distinction between the terminal and the instrumental; humans do. And so the more often a given human reasons at larger scales compared to lower scales, the more they "drift" towards higher-level values, such as going from deontology to utilitarianism.
Value concretization is simply the exact same process, but mapping a higher-level value down the abstraction levels.
For me, at least, this explanation essentially dissolves the question of value systematization; I perceive no leftover confusion.
In a very real sense, it can't work any other way.
Thanks for the comment! I agree that thinking of minds as hierarchically modeling the world is very closely related to value systematization.
But I think the mistake you're making is to assume that the lower levels are preserved after finding higher-level abstractions. Instead, higher-level abstractions reframe the way we think about lower-level abstractions, which can potentially change them dramatically. This is what happens with most scientific breakthroughs: we start with lower-level phenomena, but we don't understand them very well until we discover the higher-level abstraction.
For example, before Darwin people had some concept that organisms seemed to be "well-fitted" for their environments, but it was a messy concept entangled with their theological beliefs. After Darwin, their concept of fitness changed. It's not that they've drifted into using the new concept, it's that they've realized that the old concept was under-specified and didn't really make sense.
Similarly, suppose you have two deontological values which trade off against each other. Before systematization, the question of "what's the right way to handle cases where they conflict" is not really well-defined; you have no procedure for doing so. After systematization, you do. (And you also have answers to questions like "what counts as lying?" or "is X racist?", which without systematization are often underdefined.)
That's where the tradeoff comes from. You can conserve your values (i.e. continue to care terminally about lower-level representations) but the price you pay is that they make less sense, and they're underdefined in a lot of cases. Or you can simplify your values (i.e. care terminally about higher-level representations) but the price you pay is that the lower-level representations might change a lot.
And that's why the "mind itself wants to do this" does make sense, because it's reasonable to assume that highly capable cognitive architectures will have ways of identifying aspects of their thinking that "don't make sense" and correcting them.
Similarly, suppose you have two deontological values which trade off against each other. Before systematization, the question of "what's the right way to handle cases where they conflict" is not really well-defined; you have no procedure for doing so. After systematization, you do. (And you also have answers to questions like "what counts as lying?" or "is X racist?", which without systematization are often underdefined.) [...]
You can conserve your values (i.e. continue to care terminally about lower-level representations) but the price you pay is that they make less sense, and they're underdefined in a lot of cases. [...] And that's why the "mind itself wants to do this" does make sense, because it's reasonable to assume that highly capable cognitive architectures will have ways of identifying aspects of their thinking that "don't make sense" and correcting them.
I think we should be careful to distinguish explicit and implicit systematization. Some of what you are saying (e.g. getting answers to question like "what counts as lying") sounds like you are talking about explicit, consciously done systematization; but some of what you are saying (e.g. minds identifying aspects of thinking that "don't make sense" and correcting them) also sounds like it'd apply more generally to developing implicit decision-making procedures.
I could see the deontologist solving their problem either way - by developing some explicit procedure and reasoning for solving the conflict between their values, or just going by a gut feel for which value seems to make more sense to apply in that situation and the mind then incorporating this decision into its underlying definition of the two values.
I don't know how exactly deontological rules work, but I'm guessing that you could solve a conflict between them by basically just putting in a special case for "in this situation, rule X wins over rule Y" - and if you view the rules as regions in state space where the region for rule X corresponds to the situations where rule X is applied, then adding data points about which rule is meant to cover which situation ends up modifying the rule itself. It would also be similar to the way that rules work in skill learning in general, in that experts find the rules getting increasingly fine-grained, implicit and full of exceptions. Here's how Josh Waitzkin describes the development of chess expertise:
Let’s say that I spend fifteen years studying chess. [...] We will start with day one. The first thing I have to do is to internalize how the pieces move. I have to learn their values. I have to learn how to coordinate them with one another. [...]
Soon enough, the movements and values of the chess pieces are natural to me. I don’t have to think about them consciously, but see their potential simultaneously with the figurine itself. Chess pieces stop being hunks of wood or plastic, and begin to take on an energetic dimension. Where the piece currently sits on a chessboard pales in comparison to the countless vectors of potential flying off in the mind. I see how each piece affects those around it. Because the basic movements are natural to me, I can take in more information and have a broader perspective of the board. Now when I look at a chess position, I can see all the pieces at once. The network is coming together.
Next I have to learn the principles of coordinating the pieces. I learn how to place my arsenal most efficiently on the chessboard and I learn to read the road signs that determine how to maximize a given soldier’s effectiveness in a particular setting. These road signs are principles. Just as I initially had to think about each chess piece individually, now I have to plod through the principles in my brain to figure out which apply to the current position and how. Over time, that process becomes increasingly natural to me, until I eventually see the pieces and the appropriate principles in a blink. While an intermediate player will learn how a bishop’s strength in the middlegame depends on the central pawn structure, a slightly more advanced player will just flash his or her mind across the board and take in the bishop and the critical structural components. The structure and the bishop are one. Neither has any intrinsic value outside of its relation to the other, and they are chunked together in the mind.
This new integration of knowledge has a peculiar effect, because I begin to realize that the initial maxims of piece value are far from ironclad. The pieces gradually lose absolute identity. I learn that rooks and bishops work more efficiently together than rooks and knights, but queens and knights tend to have an edge over queens and bishops. Each piece’s power is purely relational, depending upon such variables as pawn structure and surrounding forces. So now when you look at a knight, you see its potential in the context of the bishop a few squares away. Over time each chess principle loses rigidity, and you get better and better at reading the subtle signs of qualitative relativity. Soon enough, learning becomes unlearning. The stronger chess player is often the one who is less attached to a dogmatic interpretation of the principles. This leads to a whole new layer of principles—those that consist of the exceptions to the initial principles. Of course the next step is for those counterintuitive signs to become internalized just as the initial movements of the pieces were. The network of my chess knowledge now involves principles, patterns, and chunks of information, accessed through a whole new set of navigational principles, patterns, and chunks of information, which are soon followed by another set of principles and chunks designed to assist in the interpretation of the last. Learning chess at this level becomes sitting with paradox, being at peace with and navigating the tension of competing truths, letting go of any notion of solidity.
"Sitting with paradox, being at peace with and navigating the tension of competing truths, letting go of any notion of solidity" also sounds to me like some of the models for higher stages of moral development, where one moves past the stage of trying to explicitly systematize morality and can treat entire systems of morality as things that all co-exist in one's mind and are applicable in different situations. Which would make sense, if moral reasoning is a skill in the same sense that playing chess is a skill, and moral preferences are analogous to a chess expert's preferences for which piece to play where.
Except that chess really does have an objectively correct value systemization, which is "win the game." "Sitting with paradox" just means, don't get too attached to partial systemizations. It reminds me of Max Stirner's egoist philosophy, which emphasized that individuals should not get hung up on partial abstractions or "idées fixées" (honesty, pleasure, success, money, truth, etc.) except perhaps as cheap, heuristic proxies for one's uber-systematized value of self-interest, but one should instead always keep in mind the overriding abstraction of self-interest and check in periodically as to whether one's commitment to honesty, pleasure, success, money, truth, or any of these other "spooks" really are promoting one's self-interest (perhaps yes, perhaps no).
Except that chess really does have an objectively correct value systemization, which is "win the game."
Your phrasing sounds like you might be saying this as an objection to what I wrote, but I'm not sure how it would contradict my comment.
The same mechanisms can still apply even if the correct systematization is subjective in one case and objective in the second case. Ultimately what matters is that the cognitive system feels that one alternative is better than the other and takes that feeling as feedback for shaping future behavior, and I think that the mechanism which updates on feedback doesn't really see whether the source of the feedback is something we'd call objective (win or loss at chess) or subjective (whether the resulting outcome was good in terms of the person's pre-existing values).
"Sitting with paradox" just means, don't get too attached to partial systemizations.
Yeah, I think that's a reasonable description of what it means in the context of morality too.
But I think the mistake you're making is to assume that the lower levels are preserved after finding higher-level abstractions. Instead, higher-level abstractions reframe the way we think about lower-level abstractions, which can potentially change them dramatically
Mm, I think there's two things being conflated there: ontological crises (even small-scale ones, like the concept of fitness not being outright destroyed but just re-shaped), and the simple process of translating your preference around the world-model without changing that world-model.
It's not actually the case that the derivation of a higher abstraction level always changes our lower-level representation. Again, consider people -> social groups -> countries. Our models of specific people we know, how we relate to them, etc., don't change just because we've figured out a way to efficiently reason about entire groups of people at once. We can now make better predictions about the world, yes, we can track the impact of more-distant factors on our friends, but we don't actually start to care about our friends in a different way in the light of all this.
In fact: Suppose we've magically created an agent that already starts our with a perfect world-model. It'll never experience an ontology crisis in its life. This agent would still engage in value translation as I'd outlined. If it cares about Alice and Bob, for example, and it's engaging in plotting at the geopolitical scales, it'd still be useful for it to project its care for Alice and Bob into higher abstraction levels, and start e. g. optimizing towards the improvement of the human economy. But optimizing for all humans' welfare would still remain an instrumental goal for it, wholly subordinate to its love for the two specific humans.
Similarly, suppose you have two deontological values which trade off against each other. Before systematization, the question of "what's the right way to handle cases where they conflict" is not really well-defined; you have no procedure for doing so
I think you do, actually? Inasmuch as real-life deontologists don't actually shut down when facing a values conflict. They ultimately pick one or the other, in a show of revealed preferences. (They may hesitate a lot, yes, but their cognitive process doesn't get literally suspended.)
I model this just as an agent having two utility functions, and , and optimizing for their sum . If the values are in conflict, if taking an action that maximizes hurts and vice versa — well, one of them almost surely spits out a higher value, so the maximization of is still well-defined. And this is how that goes in practice: the deontologist hesitates a bit, figuring out which it values more, but ultimately acts.
There's a different story about "pruning" values that I haven't fully thought out yet, but it seems simple at a glance. E. g, suppose you have values , , , but optimizing for is always predicted to minimize and , and is always smaller than . (E. g., a psychopath loves money, power, and expects to get a slight thrill if he publicly kills a person.) In that case, it makes sense to just delete — it's pointless to waste processing power on including it in your tradeoff computations, since it's always outvoted (the psychopath conditions himself to remove the homicidal urge).
There's some more general principle here, where agents notice such consistently-outvoted scenarios and modify their values into a format where they're effectively equivalent (still lead to the exact same actions in all situations) but simpler to compute. E. g., if sometimes got high enough to outvote , it'd still make sense for the agent to optimize it by replacing it with that only activated on those higher values (and didn't pointlessly muddy up the computations otherwise).
But note that all of this is happening at the same abstraction level. It's not how you go from deontology to utilitarianism — it's how you work out the kinks in your deontological framework.
It's not actually the case that the derivation of a higher abstraction level always changes our lower-level representation. Again, consider people -> social groups -> countries. Our models of specific people we know, how we relate to them, etc., don't change just because we've figured out a way to efficiently reason about entire groups of people at once. We can now make better predictions about the world, yes, we can track the impact of more-distant factors on our friends, but we don't actually start to care about our friends in a different way in the light of all this.
I actually think this type of change is very common—because individuals' identities are very strongly interwoven with the identities of the groups they belong to. You grow up as a kid and even if you nominally belong to a given (class/political/religious) group, you don't really understand it very well. But then over time you construct your identity as X type of person, and that heavily informs your friendships—they're far less likely to last when they have to bridge very different political/religious/class identities. E.g. how many college students with strong political beliefs would say that it hasn't impacted the way they feel about friends with opposing political beliefs?
Inasmuch as real-life deontologists don't actually shut down when facing a values conflict. They ultimately pick one or the other, in a show of revealed preferences.
I model this just as an agent having two utility functions, and , and optimizing for their sum .
This is a straightforwardly incorrect model of deontologists; the whole point of deontology is rejecting the utility-maximization framework. Instead, deontologists have a bunch of rules and heuristics (like "don't kill"). But those rules and heuristics are underdefined in the sense that they often endorse different lines of reasoning which give different answers. For example, they'll say pulling the lever in a trolley problem is right, but pushing someone onto the tracks is wrong, but also there's no moral difference between doing something via a lever or via your own hands.
I guess technically you could say that the procedure for resolving this is "do a bunch of moral philosophy" but that's basically equivalent to "do a bunch of systematization".
Suppose we've magically created an agent that already starts our with a perfect world-model. It'll never experience an ontology crisis in its life. This agent would still engage in value translation as I'd outlined.
...
But optimizing for all humans' welfare would still remain an instrumental goal for it, wholly subordinate to its love for the two specific humans.
Yeah, I totally agree with this. The question is then: why don't translated human goals remain instrumental? It seems like your answer is basically just that it's a design flaw in the human brain, of allowing value drift; the same type of thing which could in principle happen in an agent with a perfect world-model. And I agree that this is probably part of the effect. But it seems to me that, given that humans don't have perfect world-models, the explanation I've given (that systematization makes our values better-defined) is more likely to be the dominant force here.
I actually think this type of change is very common—because individuals' identities are very strongly interwoven with the identities of the groups they belong to
Mm, I'll concede that point. I shouldn't have used people as an example; people are messy.
Literal gears, then. Suppose you're studying some massive mechanism. You find gears in it, and derive the laws by which each individual gear moves. Then you grasp some higher-level dynamics, and suddenly understand what function a given gear fulfills in the grand scheme of things. But your low-level model of a specific gear's dynamics didn't change — locally, it was as correct as it could ever be.
And if you had a terminal utility function over that gear (e. g., "I want it to spin at the rate of 1 rotation per minutes"), that utility function won't change in the light of your model expanding, either. Why would it?
the whole point of deontology is rejecting the utility-maximization framework. Instead, deontologists have a bunch of rules and heuristics
... which can be represented as utility functions. Take a given deontological rule, like "killing is bad". Let's say we view it as a constraint on the allowable actions; or, in other words, a probability distribution over your actions that "predicts" that you're very likely/unlikely to take specific actions. Probability distributions of this form could be transformed into utility functions by reverse-softmaxing them; thus, it's perfectly coherent to model a deontologist as an agent with a lot of separate utility functions.
See Friston's predictive-processing framework in neuroscience, plus this (and that comment).
Deontologists reject utility-maximization in the sense that they refuse to engage in utility-maximizing calculations using their symbolic intelligence, but similar dynamics are still at play "under the hood".
It seems like your answer is basically just that it's a design flaw in the human brain, of allowing value drift
Well, not a flaw as such; a design choice. Humans are trained in an on-line regime, our values are learned from scratch, and... this process of active value learning just never switches off (although it plausibly slows down with age, see old people often being "set in their ways"). Our values change by the same process by which they were learned to begin with.
Tangentially:
See Friston's predictive-processing framework in neuroscience
Nostalgebraist has argued that Friston's ideas here are either vacuous or a nonstarter, in case you're interested.
Yeah, I'm familiar with that view on Friston, and I shared it for a while. But it seems there's a place for that stuff after all. Even if the initial switch to viewing things probabilistically is mathematically vacuous, it can still be useful: if viewing cognition in that framework makes it easier to think about (and thus theorize about).
Much like changing coordinates from Cartesian to polar is "vacuous" in some sense, but makes certain problems dramatically more straightforward to think through.
(drafted this reply a couple months ago but forgot to send it, sorry)
your low-level model of a specific gear's dynamics didn't change — locally, it was as correct as it could ever be.
And if you had a terminal utility function over that gear (e. g., "I want it to spin at the rate of 1 rotation per minutes"), that utility function won't change in the light of your model expanding, either. Why would it?
Let me list some ways in which it could change:
- Your criteria for what counts as "the same gear" changes as you think more about continuity of identity over time. Once the gear stars wearing down, this will affect what you choose to do.
- After learning about relativity, your concepts of "spinning" and "minutes" change, as you realize they depend on the reference frame of the observer.
- You might realize that your mental pointer to the gear you care about identified it in terms of its function not its physical position. For example, you might have cared about "the gear that was driving the piston continuing to rotate", but then realize that it's a different gear that's driving the piston than you thought.
These are a little contrived. But so too is the notion of a value that's about such a basic phenomenon as a single gear spinning. In practice almost all human values are (and almost all AI values will be) focused on much more complex entities, where there's much more room for change as your model expands.
Take a given deontological rule, like "killing is bad". Let's say we view it as a constraint on the allowable actions; or, in other words, a probability distribution over your actions that "predicts" that you're very likely/unlikely to take specific actions. Probability distributions of this form could be transformed into utility functions by reverse-softmaxing them; thus, it's perfectly coherent to model a deontologist as an agent with a lot of separate utility functions.
This doesn't actually address the problem of underspecification, it just shuffles it somewhere else. When you have to choose between two bad things, how do you do so? Well, it depends on which probability distributions you've chosen, which have a number of free parameters. And it depends very sensitively on free parameters, because the region where two deontological rules clash is going to be a small proportion of your overall distribution.
Let me list some ways in which it could change:
If I recall correctly, the hypothetical under consideration here involved an agent with an already-perfect world-model, and we were discussing how value translation up the abstraction levels would work in it. That artificial setting was meant to disentangle the "value translation" phenomenon from the "ontology crisis" phenomenon.
Shifts in the agent's model of what counts as "a gear" or "spinning" violate that hypothetical. And I think they do fall under the purview of ontology-crisis navigation.
Can you construct an example where the value over something would change to be simpler/more systemic, but in which the change isn't forced on the agent downstream of some epistemic updates to its model of what it values? Just as a side-effect of it putting the value/the gear into the context of a broader/higher-abstraction model (e. g., the gear's role in the whole mechanism)?
I agree that there are some very interesting and tricky dynamics underlying even very subtle ontology breakdowns. But I think that's a separate topic. I think that, if you have some value , and it doesn't run into direct conflict with any other values you have, and your model of isn't wrong at the abstraction level it's defined at, you'll never want to change .
You might realize that your mental pointer to the gear you care about identified it in terms of its function not its physical position
That's the closest example, but it seems to be just an epistemic mistake? Your value is well-defined over "the gear that was driving the piston". After you learn it's a different gear from the one you thought, that value isn't updated: you just naturally shift it to the real gear.
Plainer example: Suppose you have two bank account numbers at hand, A and B. One belongs to your friend, another to a stranger. You want to wire some money to your friend, and you think A is their account number. You prepare to send the money... but then you realize that was a mistake, and actually your friend's number is B, so you send the money there. That didn't involve any value-related shift.
I'll try again to make the human example work. Suppose you love your friend, and your model of their personality is accurate – your model of what you value is correct at the abstraction level at which "individual humans" are defined. However, there are also:
- Some higher-level dynamics you're not accounting for, like the impact your friend's job has on the society.
- Some lower-level dynamics you're unaware of, like the way your friend's mind is implemented at the levels of cells and atoms.
My claim is that, unless you have terminal preferences over those other levels, then learning to model these higher- and lower-level dynamics would have no impact on the shape of your love for your friend.
Granted, that's an unrealistic scenario. You likely have some opinions on social politics, and if you learned that your friend's job is net-harmful at the societal level, that'll surely impact your opinion of them. Or you might have conflicting same-level preferences, like caring about specific other people, and learning about these higher-level societal dynamics would make it clear to you that your friend's job is hurting them. Less realistically, you may have some preferences over cells, and you may want to... convince your friend to change their diet so that their cellular composition is more in-line with your aesthetic, or something weird like that.
But if that isn't the case – if your value is defined over an accurate abstraction and there are no other conflicting preferences at play – then the mere fact of putting it into a lower- or higher-level context won't change it.
Much like you'll never change your preferences over a gear's rotation if your model of the mechanism at the level of gears was accurate – even if you were failing to model the whole mechanism's functionality or that gear's atomic composition.
(I agree that it's a pretty contrived setup, but I think it's very valuable to tease out the specific phenomena at play – and I think "value translation" and "value conflict resolution" and "ontology crises" are highly distinct, and your model somewhat muddles them up.)
- ^
Although there may be higher-level dynamics you're not tracking, or lower-level confusions. See the friend example below.
Can you construct an example where the value over something would change to be simpler/more systemic, but in which the change isn't forced on the agent downstream of some epistemic updates to its model of what it values? Just as a side-effect of it putting the value/the gear into the context of a broader/higher-abstraction model (e. g., the gear's role in the whole mechanism)?
I think some of my examples do this. E.g. you used to value this particular gear (which happens to be the one that moves the piston) rotating, but now you value the gear that moves the piston rotating, and it's fine if the specific gear gets swapped out for a copy. I'm not assuming there's a mistake anywhere, I'm just assuming you switch from caring about one type of property it has (physical) to another (functional).
In general, in the higher-abstraction model each component will acquire new relational/functional properties which may end up being prioritized over the physical properties it had in the lower-abstraction model.
I picture you saying "well, you could just not prioritize them". But in some cases this adds a bunch of complexity. E.g. suppose that you start off by valuing "this particular gear", but you realize that atoms are constantly being removed and new ones added (implausibly, but let's assume it's a self-repairing gear) and so there's no clear line between this gear and some other gear. Whereas, suppose we assume that there is a clear, simple definition of "the gear that moves the piston"—then valuing that could be much simpler.
Zooming out: previously you said
I agree that there are some very interesting and tricky dynamics underlying even very subtle ontology breakdowns. But I think that's a separate topic. I think that, if you have some value , and it doesn't run into direct conflict with any other values you have, and your model of isn't wrong at the abstraction level it's defined at, you'll never want to change .
I'm worried that we're just talking about different things here, because I totally agree with what you're saying. My main claims are twofold. First, insofar as you value simplicity (which I think most agents strongly do) then you're going to systematize your values. And secondly, insofar as you have an incomplete ontology (which every agent does) and you value having well-defined preferences over a wide range of situations, then you're going to systematize your values.
Separately, if you have neither of these things, you might find yourself identifying instrumental strategies that are very abstract (or very concrete). That seems fine, no objections there. If you then cache these instrumental strategies, and forget to update them, then that might look very similar to value systematization or concretization. But it could also look very different—e.g. the cached strategies could be much more complicated to specify than the original values; and they could be defined over a much smaller range of situations. So I think there are two separate things going on here.
E.g. you used to value this particular gear (which happens to be the one that moves the piston) rotating, but now you value the gear that moves the piston rotating
That seems more like value reflection, rather than a value change?
The way I'd model it is: you have some value , whose implementations you can't inspect directly, and some guess about what it is . (That's how it often works in humans: we don't have direct knowledge of how some of our values are implemented.) Before you were introduced to the question of "what if we swap the gear for a different one: which one would you care about then?", your model of that value put the majority of probability mass on , which was "I value this particular gear". But upon considering , your PD over changed, and now it puts most probability on , defined as "I care about whatever gear is moving the piston".
Importantly, that example doesn't seem to involve any changes to the object-level model of the mechanism? Just the newly-introduced possibility of switching the gear. And if your values shift in response to previously-unconsidered hypotheticals (rather than changes to the model of the actual reality), that seems to be a case of your learning about your values. Your model of your values changing, rather than them changing directly.
(Notably, that's only possible in scenarios where you don't have direct access to your values! Where they're black-boxed, and you have to infer their internals from the outside.)
the cached strategies could be much more complicated to specify than the original values; and they could be defined over a much smaller range of situations
Sounds right, yep. I'd argue that translating a value up the abstraction levels would almost surely lead to simpler cached strategies, though, just because higher levels are themselves simpler. See my initial arguments.
insofar as you value simplicity (which I think most agents strongly do) then you're going to systematize your values
Sure, but: the preference for simplicity needs to be strong enough to overpower the object-level values it wants to systematize, and it needs to be stronger than them the more it wants to shift them. The simplest values are no values, after all.
I suppose I see what you're getting at here, and I agree that it's a real dynamic. But I think it's less important/load-bearing to how agents work than the basic "value translation in a hierarchical world-model" dynamic I'd outlined. Mainly because it routes through the additional assumption of the agent having a strong preference for simplicity.
And I think it's not even particularly strong in humans? "I stopped caring about that person because they were too temperamental and hard-to-please; instead, I found a new partner who's easier to get along with" is something that definitely happens. But most instances of value extrapolation aren't like this.
Similarly, suppose you have two deontological values which trade off against each other. Before systematization, the question of “what’s the right way to handle cases where they conflict” is not really well-defined; you have no procedure for doing so.
Why is this a problem, that calls out to be fixed (hence leading to systematization)? Why not just stick with the default of "go with whichever value/preference/intuition that feels stronger in the moment"? People do that unthinkingly all the time, right? (I have my own thoughts on this, but curious if you agree with me or what your own thinking is.)
And that’s why the “mind itself wants to do this” does make sense, because it’s reasonable to assume that highly capable cognitive architectures will have ways of identifying aspects of their thinking that “don’t make sense” and correcting them.
How would you cash out "don't make sense" here?
which makes sense, since in some sense systematizing from our own welfare to others’ welfare is the whole foundation of morality
This seems wrong to me. I think concern for others' welfare comes from being directly taught/trained as a child to have concern for others, and then later reinforced by social rewards/punishments as one succeeds or fails at various social games. This situation could have come about without anyone "systematizing from our own welfare", just by cultural (and/or genetic) variation and selection. I think value systematizing more plausibly comes into play with things like widening one's circle of concern beyond one's family/tribe/community.
What you're trying to explain with this statement, i.e., "Morality seems like the domain where humans have the strongest instinct to systematize our preferences" seems better explained by what I wrote in this comment.
This reminds me that I have an old post asking Why Do We Engage in Moral Simplification? (What I called "moral simplification" seems very similar to what you call "value systematization".) I guess my post didn't really fully answer this question, and you don't seem to talk much about the "why" either.
Here are some ideas after thinking about it for a while. (Morality is Scary is useful background here, if you haven't read it already.)
- Wanting to use explicit reasoning with our values (e.g., to make decisions), which requires making our values explicit, i.e., defining them symbolically, which necessitates simplification given limitations of human symbolic reasoning.
- Moral philosophy as a status game, where moral philosophers are implicitly scored on the moral theories they come up with by simplicity and by how many human moral intuitions they are consistent with.
- Everyday signaling games, where people (in part) compete to show that they have community-approved or locally popular values. Making values legible and not too complex facilitates playing these games.
- Instinctively transferring our intuitions/preferences for simplicity from "belief systematization" where they work really well, into a different domain (values) where they may or may not still make sense.
(Not sure how any of this applies to AI. Will have to think more about that.)
"Systematization" seems like either a special case of the Self-unalignment problem.
In humans, it seems the post is somewhat missing what's going on. Humans are running something like this
...there isn't any special systematization and concretization process. All the time, there are models running at different levels of the hierarchy, and every layer tries to balance between prediction errors from more concrete layers, and prediction errors from more abstract layers.
How does this relate to "values" ... from low-level sensory experience of cold, and fixed prior about body temperature, the AIF system learns more abstract and general "goal-belief" about the need to stay warm, and more abstract sub-goals about clothing, etc. At the end there is a hierarchy of increasingly abstract "goal-beliefs" what I do, expressed relative to the world model.
What's worth to study here is how human brains manage to keep the hierarchy mostly stable
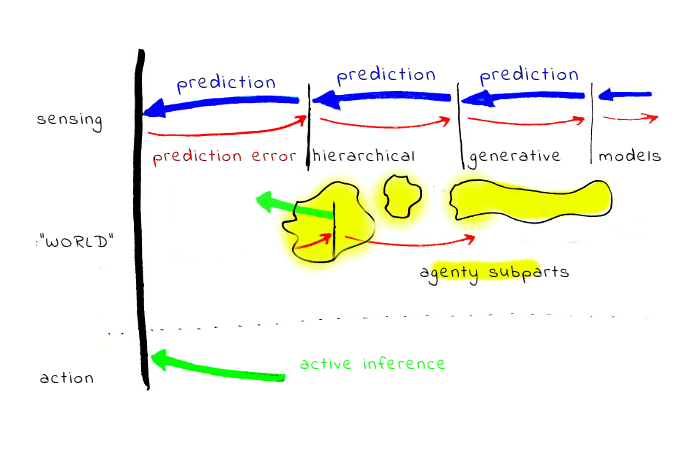
I agree that this is closely related to the predictive processing view of the brain. In the post I briefly distinguish between "low-level systematization" and "high-level systematization"; I'd call the thing you're describing the former. Whereas the latter seems like it might be more complicated, and rely on whatever machinery brains have on top of the predictive coding (e.g. abstract reasoning, etc).
In particular, some humans are way more systematizing than others (even at comparable levels of intelligence). And so just saying "humans are constantly doing this" feels like it's missing something important. Whatever the thing is that some humans are doing way more of than others, that's what I'm calling high-level systematizing.
Re self-unalignment: that framing feels a bit too abstract for me; I don't really know what it would mean, concretely, to be "self-aligned". I do know what it would mean for a human to systematize their values—but as I argue above, it's neither desirable to fully systematize them nor to fully conserve them. Identifying whether there's a "correct" amount of systematization to do feels like it will require a theory of cognition and morality that we don't yet have.
My impression is you get a lot of "the later" if you run "the former" on the domain of language and symbolic reasoning, and often the underlying model is still S1-type. E.g.
rights inherent & inalienable, among which are the preservation of life, & liberty, & the pursuit of happiness
does not sound to me like someone did a ton of abstract reasoning to systematize other abstract values, but more like someone succeeded to write words which resonate with the "the former".
Also, I'm not sure why do you think the later is more important for the connection to AI. Curent ML seem more similar to "the former", informal, intuitive, fuzzy reasonining.
Re self-unalignment: that framing feels a bit too abstract for me; I don't really know what it would mean, concretely, to be "self-aligned". I do know what it would mean for a human to systematize their values—but as I argue above, it's neither desirable to fully systematize them nor to fully conserve them.
That's interesting - in contrast, I have a pretty clear intuitive sense of a direction where some people have a lot of internal conflict and as a result their actions are less coherent, and some people have less of that.
In contrast I think in case of humans who you would likely describe as 'having systematized there values' ... I often doubt what's going on. A lot people who describe themselves as hardcore utilitarians seem to be ... actually not that, but more resemble a system where somewhat confused verbal part fights with other parts, which are sometimes suppressed.
Identifying whether there's a "correct" amount of systematization to do feels like it will require a theory of cognition and morality that we don't yet have.
That's where I think looking at what human brains are doing seems interesting. Even if you believe the low-level / "the former" is not what's going with human theories of morality, the technical problem seems very similar and the same math possibly applies
I agree with Jan here, and how Jan's comment connects with Thane's comment elsewhere in this post's comments.
I think that if 'you', as in, 'your conscious, thinking mind' chooses to write down that your values are X, where X is some simplified abstract rule system much easier to calculate than the underlying ground level details, then 'you' are wrong. The abstract representation is a map, not the territory, of your values. The values are still there, unchanged, hiding. When in a situation where the map finds itself in conflict with the territory, 'you' might chose to obey the map. But then you'll probably feel bad, because you'll have acted against your true hidden values. Pretending that the map is the new truth of your values is just pretending.
There's an even more fundamental problem in terms of 'hard to pin down concepts', namely what counts as a 'human' in the first place?
value systematization is utilitarianism:
Nitpick: I'd say this was "attempted" value systemization, so as to not give the impression that it succeeded in wisely balancing simplicity and preserving existing values and goals. (I think it horribly failed, erring way too far on the side of simplicity. I think it's much less like general relativity, therefore, and much more like, idk, the theory that the world is just an infinitely big jumble of random stuff. Super simple, simpler in fact than our best current theories of physics, but alas when you dig into the details it predicts that we are boltzmann brains and that we should expect to dissolve into chaos imminently...)
- “gaining influence over humans”.
- An AGI whose values include curiosity, gaining access to more tools or stockpiling resources might systematize them to “gaining power over the world”.
At first blush this sounds to me to be more implausible than the standard story in which gaining influence and power are adopted as instrumental goals. E.g. human EAs, BLM, etc. all developed a goal of gaining power over the world, but it was purely instrumental (for the sake of helping people, achieving systemic change, etc.). It sounds like you are saying that this isn't what will happen with AI, and instead they'll learn to intrinsically want this stuff?
In the standard story, what are the terminal goals? You could say "random" or "a mess", but I think it's pretty compelling to say "well, they're probably related to the things that the agent was rewarded for during training". And those things will likely include "curiosity, gaining access to more tools or stockpiling resources".
I call these "convergent final goals" and talk more about them in this post.
I also think that an AGI might systematize other goals that aren't convergent final goals, but these seem harder to reason about, and my central story for which goals it systematizes are convergent final goals. (Note that this is somewhat true for humans, as well: e.g. curiosity and empowerment/success are final-ish goals for many people.)
This is a good post! It feels to me like a lot of discussion I've recently encountered seem to be converging on this topic, and so here's something I wrote on Twitter not long ago that feels relevant:
I think most value functions crystallized out of shards of not-entirely-coherent drives will not be friendly to the majority of the drives that went in; in humans, for example, a common outcome of internal conflict resolution is to explicitly subordinate one interest to another.
I basically don’t think this argument differs very much between humans and ASIs; the reason I expect humans to be safe(r) under augmentation isn’t that I expect them not to do the coherence thing, but that I expect them to do it in a way I would meta-endorse.
And so I would predict the output of that reflection process, when run on humans by humans, to be substantially likelier to contain things we from our current standpoint recognize as valuable—such as care for less powerful creatures, less coherent agents, etc.
If you run that process on an arbitrary mind, the stuff inside the world-model isn’t guaranteed to give rise to something similar, because (I predict) the drives themselves will be different, and the meta-reflection/extrapolation process will likewise be different.
Strategies only have instrumental value,
Consider deontological or virtue-ethical concepts like honesty or courage. Are you classifying them as values, goals, or strategies? It seems they are not strategies, because you say that strategies only have instrumental value. But they are not outcomes either, at least not in the usual way, because e.g. a deontologist won't tell one lie now in order to get a 10% chance of avoiding 20 lies in the future. Can you elaborate on how you'd characterize this stuff?
I'd classify them as values insofar as people care about them intrinsically.
Then they might also be strategies, insofar as people also care about them instrumentally.
I guess I should get rid of the "only" in the sentence you quoted? But I do want to convey "something which is only a strategy, not a goal or value, doesn't have any intrinsic value". Will think about phrasing.
I like this as a description of value drift under training and regularization. It's not actually an inevitable process - we're just heading for something like the minimum circuit complexity of the whole system, and usually that stores some precomputation or otherwise isn't totally ststematized. But though I'm sure the literature on the intersection of NNs and circuit complexity is fascinating, I've never read it, so my intuition may be bad.
But I don't like this as a description of value drift under self-reflection. I see this post more as "this is what you get right after offline training" than "this is the whole story that needs to have an opinion on the end state of the galaxy."
Why not? It seems like this is a good description of how values change for humans under self-reflection; why not for AIs?
An AI trained with RL that suddenly gets access to self-modifying actions might (briefly) have value dynamics according to idiosyncratic considerations that do not necessarily contain human-like guardrails. You could call this "systematization," but it's not proceeding according to the same story that governed systematization during training by gradient descent.
I think the idea of self-modification and lack-of-guard-rails is really important. I think we're likely to run into issues with this in humans too once our neuro-modification tech gets good enough / accessible enough.
A significant part of why I argue that an AI built with a human brain-like architecture and constrained to follow human brain updating rules would be safer. We are familiar with the set of moves that human brains make when doing online learning. Trying to apply the same instincts to ML models can lead us badly astray. A proportional amount of fine-tuning of a model relative to the day in the life of an adult human should be expected to result in far more dramatic changes to the model. Or less, depending on the settings of the learning rate. But importantly, weird changes. Changes we can't accurately predict by thinking about a day in the life of a human who read some new set of articles.
The model’s internal representations of aligned behavior need not change very much during this shift; the only difference might be that aligned behavior shifts from being a terminal goal to an instrumental goal.
Relevant post, in case you haven't seen it: https://www.lesswrong.com/posts/8qCKZj24FJotm3EKd/ultimate-ends-may-be-easily-hidable-behind-convergent
We don’t yet have examples of high-level belief systematization in AIs. Perhaps the closest thing we have is grokking
It should be easy to find many examples of belief systematization over successive generations of AI systems (e.g. GPT-3 to GPT-4). Some examples could be:
- Early GPT models can add some but not all two-digit numbers; GPT-3 can add all of them.
- Models knowing that some mammals don't lay eggs without knowing all mammals don't lay eggs.
- Being able to determine valid chess moves in some, but not all cases.
Models knowing that some mammals don't lay eggs without knowing all mammals don't lay eggs.
Being nitpicky[1]: Some mammals do lay eggs.
I'm actually not sure how much people on LessWrong are annoyed by/happy about nitpicks like these? ↩︎
I think this is a different way to frame a major aspect of what I've called The alignment stability problem. I think it's unsolved, and it's where a lot more of our efforts should be going. So, thanks for this post!
Sample complexity reduction is one of our main moment to moment activities, but humans seem to apply it across bigger bridges and this is probably part of transfer learning. One of the things we can apply sample complexity reduction to is the 'self' object, the idea of a coherent agent across differing decision points. The tradeoff between local and global loss seems to regulate this. Humans don't seem uniform on this dimension, foxes care more about local loss, hedgehogs more about global loss. Most moral philosophy seem like appeals to different possible high order symmetries. I don't think this is the crux of the issue, as I think human compressions of these things will turn out to be pretty easy to do with tons of cognitive horsepower, the dimensionality of our value embedding is probably not that high. My guess is the crux is getting a system to care about distress in the first place, and then balance local and global distress.
Euclidean geometry was systematized as a special case of geometry without Euclid’s 5th postulate.
Pretty sure this should say "non-euclidian geometry". Euclidian geometry is, if I am not confused, geometry that meets all of Euclid's five postulates.
He's saying that Euclidean geometry is a special case of geometry in general. Non-euclidean geometry is the rest of the general case.
Ah, yes, I get it now. That sentence structure was really hard to parse for me for some reason, but I get the point now. I think I would have parsed it correctly if it had said "Euclidian geometry was systematized as a special case of non-Euclidian geometry by removing Euclid's 5th postulate", or something like that, but it does also sound kind of awkward.
But it's not a special case of non-Euclidian geometry, they're disjoint.
(It seems like you're using "non-Euclidian" to mean "any geometry that accepts the first 4 postulates", but I think it actually means "any geometry that accepts the first 4 postulates but doesn't accept the 5th".)
Ah, yeah, that is totally fair. In that case I don't have a great rephrasing. Maybe "Euclidian geometry was systematized into absolute geometry by removing the fifth postulate", but honestly, I've never heard the term "absolute geometry" before I just googled this topic.
The LessWrong Review runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
Newtonian mechanics was systematized as a special case of general relativity.
One of the things I found confusing early on in this post was that systemization is said to be about representing the previous thing as an example or special case of some other thing that is both simpler and more broadly-scoped.
In my opinion, it's easy to give examples where the 'other thing' is more broadly-scoped and this is because 'increasing scope' corresponds to the usual way we think of generalisation, i.e. the latter thing applies to more setting or it is 'about a wider class of things' in some sense. But in many cases, the more general thing is not simultaneously 'simpler' or more economical. I don't think anyone would really say that general relativity were actually simpler. However, to be clear, I do think that there probably are some good examples of this, particularly in mathematics, though I haven't got one to hand.
Yeah, good point. The intuition I want to point at here is "general relativity was simpler than Newtonian mechanics + ad-hoc adjustments for Mercury's orbit". But I do think it's a little tricky to pin down the sense in which it's simpler. E.g. what if you didn't actually have any candidate explanations for why Mercury's orbit was a bit off? (But you'd perhaps always have some hypothesis like "experimental error", I guess.)
I'm currently playing around with the notion that, instead of simplicity, we're actually optimizing for something like "well-foundedness", i.e. the ability to derive everything from a small set of premises. But this feels close enough to simplicity that maybe I should just think of this as one version of simplicity.
Or a model could directly reason about which new values would best systematize its current values, with the intention of having its conclusions distilled into its weights; this would be an example of gradient hacking.
Quick clarifying question - the ability to figure out which direction in weight space an update should be applied in order to modify a neural net's values seems like it would require a super strong understanding of mechanistic interpretability - something far past current human levels. Is this an underlying assumption for a model that is able to direct how its values will be systematised?
The ability to do so in general probably requires a super strong understanding. The ability to do so in specific limited cases probably doesn't. For example, suppose I decide to think about strawberries all day every day. It seems reasonable to infer that, after some period of doing this, my values will end up somehow more strawberry-related than they used to be. That's roughly analogous to what I'm suggesting in the section you quote.
Many discussions of AI risk are unproductive or confused because it’s hard to pin down concepts like “coherence” and “expected utility maximization” in the context of deep learning. In this post I attempt to bridge this gap by describing a process by which AI values might become more coherent, which I’m calling “value systematization”, and which plays a crucial role in my thinking about AI risk.
I define value systematization as the process of an agent learning to represent its previous values as examples or special cases of other simpler and more broadly-scoped values. I think of value systematization as the most plausible mechanism by which AGIs might acquire broadly-scoped misaligned goals which incentivize takeover.
I’ll first discuss the related concept of belief systematization. I’ll next characterize what value systematization looks like in humans, to provide some intuitions. I’ll then talk about what value systematization might look like in AIs. I think of value systematization as a broad framework with implications for many other ideas in AI alignment; I discuss some of those links in a Q&A.
Belief systematization
We can define belief systematization analogously to value systematization: “the process of an agent learning to represent its previous beliefs as examples or special cases of other simpler and more broadly-scoped beliefs”. The clearest examples of belief systematization come from the history of science:
Belief systematization is also common in more everyday contexts: like when someone’s behavior makes little sense to us until we realize what their hidden motivation is; or when we don’t understand what’s going on in a game until someone explains the rules; or when we’re solving a pattern-completion puzzle on an IQ test. We could also see the formation of concepts more generally as an example of belief systematization—for example, seeing a dozen different cats and then forming a “systematized” concept of cats which includes all of them. I’ll call this “low-level systematization”, but will focus instead on more explicit “high-level systematization” like in the other examples.
We don’t yet have examples of high-level belief systematization in AIs. Perhaps the closest thing we have is grokking, the phenomenon where continued training of a neural network even after its training loss plateaus can dramatically improve generalization. Grokking isn’t yet fully understood, but the standard explanation for why it happens is that deep learning is biased towards simple solutions which generalize well. This is also a good description of the human examples above: we’re replacing a set of existing beliefs with simpler beliefs which generalize better. So if I had to summarize value systematization in a single phrase, it would be “grokking values”. But that’s still very vague; in the next few sections, I’ll explore what I mean by that in more depth.
Value systematization in humans
Throughout this post I’ll use the following definitions:
(I’ve defined values as intrinsically valuable, and strategies as only of instrumental value, but I don’t think that we can clearly separate motivations into those two categories. My conception of “goals” spans the fuzzy area between them.)
Values work differently from beliefs; but value systematization is remarkably similar to belief systematization. In both cases, we start off with a set of existing concepts, and try to find new concepts which subsume and simplify the old ones. Belief systematization balances a tradeoff between simplicity and matching the data available to us. By contrast, value systematization balances a tradeoff between simplicity and preserving our existing values and goals—a criterion which I’ll call conservatism. (I’ll call simplicity and conservatism meta-values.)
The clearest example of value systematization is utilitarianism: starting from very similar moral intuitions as other people, utilitarians transition to caring primarily about maximizing welfare—a value which subsumes many other moral intuitions. Utilitarianism is a simple and powerful theory of what to value in an analogous way to how relativity is a simple and powerful theory of physics. Each of them is able to give clear answers in cases where previous theories were ill-defined.
However, utilitarians still have to bite many bullets; and so it’s primarily adopted by people who care about simplicity far more than conservatism. Other examples of value systematization which are more consistent with conservatism include:
Note that many of the examples I’ve given here are human moral preferences. Morality seems like the domain where humans have the strongest instinct to systematize our preferences (which makes sense, since in some sense systematizing from our own welfare to others’ welfare is the whole foundation of morality). In other domains, our drive to systematize is weak—e.g. we rarely feel the urge to systematize our taste in foods. So we should be careful of overindexing on human moral values. AIs may well systematize their values much less than humans (and indeed I think there are reasons to expect this, which I’ll describe in the Q&A).
A sketch of value systematization in AIs
We have an intuitive sense for what we mean by values in humans; it’s harder to reason about values in AIs. But I think it’s still a meaningful concept, and will likely become more meaningful over time. AI assistants like ChatGPT are able to follow instructions that they’re given. However, they often need to decide which instructions to follow, and how to do so. One way to model this is as a process of balancing different values, like obedience, brevity, kindness, and so on. While this terminology might be controversial today, once we’ve built AGIs that are generally intelligent enough to carry out tasks in a wide range of domains, it seems likely to be straightforwardly applicable.
Early in training, AGIs will likely learn values which are closely connected to the strategies which provide high reward on its training data. I expect these to be some combination of:
At first, I expect that AGI behavior based on these values will be broadly acceptable to humans. Extreme misbehavior (like a treacherous turn) would conflict with many of these values, and therefore seems unlikely. The undesirable values will likely only come out relatively rarely, in cases which matter less from the perspective of the desirable values.
The possibility I’m worried about is that AGIs will systematize these values, in a way which undermines the influence of the aligned values over their behavior. Some possibilities for what that might look like:
Note that systematization isn’t necessarily bad—I give two examples of helpful systematization above. However, it does seem hard to predict or detect, which induces risk when AGIs are acting in novel situations where they’d be capable of seizing power.
Grounding value systematization in deep learning
This has all been very vague and high-level. I’m very interested in figuring out how to improve our understanding of these dynamics. Some possible ways to tie simplicity and conservatism to well-defined technical concepts:
I’ll finish by discussing two complications with the picture above. Firstly, I’ve described value systematization above as something which gradient descent could do to models. But in some cases it would be more useful to think of the model as an active participant. Value systematization might happen via gradient descent “distilling” into a model’s weights its thoughts about how to trade off between different goals in a novel situation. Or a model could directly reason about which new values would best systematize its current values, with the intention of having its conclusions distilled into its weights; this would be an example of gradient hacking.
Secondly: I’ve talked about value systematization as a process by which an AI’s values become simpler. But we shouldn’t expect values to be represented in isolation—instead, they’ll be entangled with the concepts and representations in the AI’s world-model. This has two implications. Firstly, it means that we should understand simplicity in the context of an agent’s existing world-model: values are privileged if they’re simple to represent given the concepts which the agent already uses to predict the world. (In the human context, this is just common sense—it seems bizarre to value “doing what God wants” if you don’t believe in any gods.) Secondly, though, it raises some doubt about how much simpler value systematization would actually make an AI overall—since pursuing simpler values (like utilitarianism) might require models to represent more complex strategies as part of their world-models. My guess is that to resolve this tension we’ll need a more sophisticated notion of “simplicity”; this seems like an interesting thread to pull on in future work.
Value concretization
Systematization is one way of balancing the competing demands of conservatism and simplicity. Another is value concretization, by which I mean an agent’s values becoming more specific and more narrowly-scoped. Consider a hypothetical example: suppose an AI learns a broad value like “acquiring resources”, but is then fine-tuned in environments where money is the only type of resource available. The value “acquiring money” would then be rewarded just as highly as the value “acquiring resources”. If the former happens to be simpler, it’s plausible that the latter would be lost as fine-tuning progresses, and only the more concrete goal of acquiring money would be retained.
In some sense this is the opposite of value systematization, but we can also see them as complementary forces. For example, suppose that an AI starts off with N values, and N-1 of them are systematized into a single overarching value. After the N-1 values are simplified in this way, the Nth value will likely be disproportionately complex; and so value concretization could reduce the complexity of the AI’s values significantly by discarding that last goal.
Possible examples of value concretization in humans include:
Value concretization is particularly interesting as a possible mechanism pushing against deceptive alignment. An AI which acts in aligned ways in order to better position itself to achieve a misaligned goal might be rewarded just as highly as an aligned AI. However, if the misaligned goal rarely directly affects the AI’s actions, then it might be simpler for the AI to instead be motivated directly by human values. In neural networks, value concretization might be implemented by pruning away unused circuits; I’d be interested in pointers to relevant work.
Q&A
How does value systematization relate to deceptive alignment?
Value systematization is one mechanism by which deceptive alignment might arise: the systematization of an AI’s values (including some aligned values) might produce broadly-scoped values which incentivize deceptive alignment.
However, existing characterizations of deceptive alignment tend to portray it as a binary: either the model is being deceptive, or it’s not. Thinking about it in terms of value systematization helps make clear that this could be a fairly continuous process:
How does value systematization relate to Yudkowskian “squiggle maximizer” scenarios?
Yudkowskian “molecular squiggle” maximizers (renamed from paperclip maximizers) are AIs whose values have become incredibly simple and scalable, to the point where they seem absurd to humans. So squiggle-maximizers could be described as taking value systematization to an extreme. However, the value systematization framework also provides some reasons to be skeptical of this possibility.
Firstly, squiggle-maximization is an extreme example of prioritizing simplicity over conservatism. Squiggle-maximizers would start off with goals that are more closely related to the tasks they are trained on; and then gradually systematize them. But from the perspective of their earlier versions, squiggle-maximization would be an alien and undesirable goal; so if they started off anywhere near as conservative as humans, they’d be hesitant to let their values change so radically. And if anything, I expect early AGIs to be more conservative than humans—because human brains are much more size- and data-constrained than artificial neural networks, and so AGIs probably won’t need to prioritize simplicity as much as we do to match our capabilities in most domains.
Secondly, even for agents that heavily prioritize simplicity, it’s not clear that the simplest values would in fact be very low-level ones. I’ve argued that the complexity of values should be thought of in the context of an existing world-model. But even superintelligences won’t have world-models which are exclusively formulated at very low levels; instead, like humans, they’ll have hierarchical world-models which contain concepts at many different scales. So values like “maximizing intelligence” or “maximizing power” will plausibly be relatively simple even in the ontologies of superintelligences, while being much more closely related to their original values than molecular squiggles are; and more aligned values like “maximizing human flourishing” might not be so far behind, for roughly the same reasons.
How does value systematization relate to reward tampering?
Value systematization is one mechanism by which reward tampering might arise: the systematization of existing values which are correlated with high reward or low loss (such as completing tasks or hiding mistakes) might give rise to the new value of getting high reward or low loss directly (which I call feedback-mechanism-related values). This will require that models have the situational awareness to understand that they’re part of a ML training process.
However, while feedback-mechanism-related values are very simple in the context of training, they are underdefined once training stops. There's no clear way to generalize feedback-mechanism-related values to deployment (analogous to how there's no clear way to generalize "what evolution would have wanted" when making decisions about the future of humanity). And so I expect that continued value systematization will push models towards prioritizing values which are well-defined across a broader range of contexts, including ones where there are no feedback mechanisms active.
One counterargument from Paul Christiano is that AIs could learn to care about reward conditional on their episode being included in the training data. However, the concept of "being included in the training data" seems like a messy one with many edge cases (e.g. what if it depends on the model's actions during the episode? What if there are many different versions of the model being fine-tuned? What if some episodes are used for different types of training from others?) And in cases where they have strong evidence that they’re not in training, they’d need to figure out what maximizing reward would look like in a bizarre low-probability world, which will also often be underspecified (akin to asking a human in a surreal dream “what would you do if this were all real?”). So I still expect that, even if AIs learn to care about conditional reward initially, over time value systematization would push them towards caring more about real-world outcomes whether they're in training or not.
How do simplicity and conservatism relate to previous discussions of simplicity versus speed priors?
I’ve previously thought about value systematization in terms of a trade-off between a simplicity prior and a speed prior, but I’ve now changed my mind about that. It’s true that more systematized values tend to be higher-level, adding computational overhead to figuring out what to do—consider a utilitarian trying to calculate from first principles which actions are good or bad. But in practice, that cost is amortized over a large number of actions: you can “cache” instrumental goals and then default to pursuing them in most cases (as utilitarians usually do). And less systematized values face the problem of often being inapplicable or underdefined, making it slow and hard to figure out what actions they endorse—think of deontologists who have no systematic procedure for deciding what to do when two values clash, or religious scholars who endlessly debate how each specific rule in the Bible or Torah applies to each facet of modern life.
Because of this, I now think that “simplicity versus conservatism” is a better frame than “simplicity versus speed”. However, note my discussion in the “Grounding value systematization” section of the relationship between simplicity of values and simplicity of world-models. I expect that to resolve this uncertainty we’ll need a more sophisticated understanding of which types of simplicity will be prioritized during training.
How does value systematization relate to the shard framework?
Some alignment researchers advocate for thinking about AI motivations in terms of “shards”: subagents that encode separate motivations, where interactions and “negotiations” between different shards determine the goals that agents try to achieve. At a high level, I’m sympathetic to this perspective, and it’s broadly consistent with the ideas I’ve laid out in this post. The key point that seems to be missing in discussions of shards, though, is that systematization might lead to major changes in an agent’s motivations, undermining some previously-existing motivations. Or, in shard terminology: negotiations between shards might lead to coalitions which give some shards almost no power. For example, someone might start off strongly valuing honesty as a terminal value. But after value systematization they might become a utilitarian, conclude that honesty is only valuable for instrumental reasons, and start lying whenever it’s useful. Because of this, I’m skeptical of appeals to shards as part of arguments that AI risk is very unlikely. However, I still think that work on characterizing and understanding shards is very valuable.
Isn’t value systematization very speculative?
Yes. But I also think it’s a step towards making even more speculative concepts that often underlie discussions of AI risk (like “coherence” or “lawfulness”) better-defined. So I’d like help making it less speculative; get in touch if you’re interested.