I think that Discovering Latent Knowledge in Language Models Without Supervision (DLK; Burns, Ye, Klein, & Steinhardt, 2022) is a very cool paper – it proposes a way to do unsupervised mind reading[1]– diminished only by not making its conceptual coolness evident enough in the paper writeup. This is in large part corrected in Collin Burns's more conceptual companion post. I'm rooting for their paper to sprout more research that finds concepts / high-level features in models by searching for their shape[2]. The aim of this post is to present a conceptual framework for this kind of interpretability, which I hope will facilitate turning concepts into structures to look for in ML models. Understanding this post does not require having read DLK, as the reader will be walked through the relevant parts of the result in parallel with developing this framework.
Epistemic status: This post contains a theoretical framework that suggests a bunch of concrete experiments, but none of these experiments have been run yet (well, except for ones that were run prior to the creation of the framework), so it's quite possible the framework ends up leading to nothing in practice. Treat this as an interim report, and as an invitation to action to run some of these experiments yourself. This post is written by Kaarel Hänni on behalf of a team consisting of Georgios Kaklamanos, Kay Kozaronek, Walter Laurito, June Ku, Alex Mennen, and myself.
The rough picture of the approach
The idea is to start with a list of related concepts (or possibly just a single concept), write down a list of relations that the concepts satisfy, and then search for a list of features inside the model satisfying these relations. The hope is that this gives a way to find concepts inside models which requires us to make fewer assumptions about the model's thinking than if we were e.g. training a probe on activations according to human-specified labels. For instance, if we had good reasons to believe that models assign utilities to outcomes, but we had no idea about what the utility assignment is, we couldn't train a supervised probe (because of lacking labels), but perhaps we could still train an unsupervised probe that looks for utility-shaped features in the model. The bet would be that the utility-shaped features we find indeed store the model's utility assignment.
Philosophical framing
The approach described above is very similar to Ramsification[3], a method for turning a theory in narrative form – usually with terms not grounded in some previously understood theory, possibly with circular definitions – into a well-defined theory. Roughly speaking, when presented with a scientific theory stated as a bunch of statements involving new terms, e.g. (borrowing an example from Wikipedia) the new terms "electron" and "charge" in the narrative theory "Electrons have charge. Things with charge tickle you. Electrons cause lightning.", Ramsification suggests picking the meaning of "being an electron" and "having charge" in whatever way makes the narrative as true as possible, i.e. minimizing the fraction of cases in which the sentences are wrong.
I'm immediately struck by two (related) issues. First, it's not clear what the set of meanings is from which we are allowed to pick one – in fact, it's not even obvious to me what kind of language (theory, metatheory, or whatever) these meanings should be specified in. Second, I'd guess there's probably always going to be some convoluted meanings that satisfy the narrative form really well, but which aren't the natural concepts we'd want e.g. "electron" and "charge" to capture. So it would be nice if we could constrain the search for meanings only to natural concepts. Here's an idea: perhaps these issues would be fixed if we had a machine that learns useful representations for doing stuff, in which case we could restrict our search to the features learned by this machine.[4] This gives us a concrete search space, as well as a reason to believe that a lot of measure in the search space is inhabited by reasonable abstractions. One crucially important concept is truth, and language models are really powerful models that can understand text, which is a natural kind of thing to carry truth. So perhaps it makes sense to look for a representation of truth inside language models? (Spoiler: DLK does this.) In case the usefulness of being able to find out what a model believes is not obvious in analogy with how interpretability is generally useful, I'll spell out a few ways in which this is useful:
We might be able to use it to check if and in what ways a model is deceiving us, and then go back to the model drawing board with some more information.[5]
We could just see if the model believes something like "If I'm unboxed, there won't be many humans around in 100 years", and if yes, go back to the drawing board with more information.
Given a potentially misaligned AGI, if we had accurate access to its beliefs, we could use it as an oracle for e.g. our alignment research questions. This is like microscope AI, except instead of having to reconstruct some superhuman scientific theory from weights, this one weird trick gives us a question-answer interface. We can then play twenty (thousand) questions on alignment research plans with a boxed superintelligence that can't help but leak the truth.
Finally getting to the star of the show now: in DLK, it's plausible that they pull off just the above in current language models! One can think of the constraints used in the paper as arising by Ramsification from the following narrative form:
The truthiness of a proposition is 1 minus the truthiness of its negation. The truthiness of either a proposition or its negation should be close to 0.
The paper searches for a feature in the model satisfying these relations, and turns out to indeed find something that's pretty correlated with ground truth! emotive status: Very cool. [6][7]
Formalism: features
Let F be the set of all features of a model. For now, feel free to think of F as just a finite list if you like. Let's think of each element f∈F as a function from the model input space X to some output space Yf – there can be a different output space Yf for each feature f. Here are four examples of features we could imagine an image classification model having:
a feature fsnout that maps a picture to {0,1} according to whether it contains a snout;
an analogous continuous feature fsnout:X→[0,1];
fhorizontal:X→R capturing the horizontal coordinate of the center of the salient object in the image;
fdirection:X→S2 (unit sphere in R3) capturing the direction of gravity compared to some basis respecting the picture plane.
In general, the features should be derived from activations of the model in a pretty simple way. By this, I mean that if the map from model inputs to corresponding activations is g:X→A, then for every feature f, there is a simple map hf:A→Yf such that f=hf∘g. For example, it could be that features are directions in activation spaceA≅Rn, in which case every Yf is a subspace of A (or perhaps more precisely of the subspace spanned by the activations in just one layer, or at just one position in the residual stream of a language model), so Yf≅R, and hf is a projection from the activation space to that subspace.[8][9]
So, what are features? I don't know – the above definitely doesn't nail it down. In particular, the above does not capture the idea of features being the natural abstract units in terms of which a model is performing computation, not to speak of giving an algorithm for computing the features of a model. So, unfortunately, even though the above presentation most conjures up an image of the feature set F as a discrete thing, as humanity hasn't solved the problem of coming up with such a discrete set yet,[10] in current practice we might want to work with a set F with smooth structure so as to be able to do gradient descent over it. This smooth F will almost always contain elements that are not features, so let's call it the set of prefeatures instead. And we will also often want to restrict to only a subset of all prefeatures of a model.[11] For example, if our model is GPT-J and we want to consider prefeatures with output space Yf=[0,1], then we could e.g. let F be the set of all one-dimensional subspaces of the vector space of activations at the last token position in the last layer, by which I really mean that if the scalar activations are z1,…,zd, then F is the set of all f induced by hf of the form hf=σ(a+∑di=1bizi), where σ is the usual sigmoid σ(s)=11+e−s. (So there's an f for each setting of a and b1,b2,…,bd∈R, and gradient descent is really happening over these parameters.) This is the choice of the prefeature set in the DLK paper. [12]
Formalism: searching for concepts in features
Ok, whatever, let's assume for now that Anthropic et al. have succeeded at creating the powerful primitive of enumerating over all features of a model, so we can run this on our model, and get a set F of all features of the model. But even if we have a list of features in terms of which the model is performing computation, that doesn't make it trivial to identify features with useful concepts. For instance, we don't a priori know whether some feature is detecting dog snouts, or which one it is. So there's still some interpretability work to be done: we want to find a feature (or set of features) where a model's version of some concept or another lives. Let's associate each concept – e.g. truth, utility, honesty, treeness, goodness according to humanity's CEV, ease of traversing a particular piece of terrain, whether another agent is an adversary, etc. [13] – with a function c:X→Yc with X being the input space of the model and Yc being some space specific to that concept [14][15]. (This agrees with the framework on pages 8-9 of "Acquisition of Chess Knowledge in AlphaZero", with the caveat that we haven't assumed the function c:X→Yc to be a priori known to us.)
Just write down a loss function capturing the concepts and minimize it?
Most generally [16], to capture a set of concepts C, we could now define some loss function L=LC,X with type signature L:∏(c,x)∈C×XYc→R that attains an exceptionally low value with the indexed family containing the true concept values on all the inputs (c(x))(c,x)∈C×X as the input . Once we have L, we search for an embedding of the concepts into features, e:C→F, such that denoting fc=e(c), the loss L((fc(x))(c,x)∈C×X) is small. [17] The bet probing makes is that if the concepts in C are natural enough and L is designed well, then the fc we find from this search capture the model's versions of the concepts C.
So, how would one design L for given concepts of interest? In general, it will require some cleverness not algorithmized away by the formalism at hand. But I think considering losses L with some additional structure can take us some of the way there. We'll look at a few simple cases before writing down a canonical form.
Special case: supervised probing for a single concept
Suppose that for the concept c:X→R, we have a list of n input-output pairs, i.e. (xi,c(xi))∈X×R for i=1,2,…,n. Then it's natural to just let L=∑ni=1(fc(xi)−c(xi))2. In case we are looking for a feature fc that is a direction in activation space, the problem reduces to OLS. Further adding a regularization term to this loss (and sending through a sigmoid for concepts living in [0,1]), one gets the supervised probes in "Acquisition of Chess Knowledge in AlphaZero". A second example of supervised probing, from "Understanding intermediate layers using linear classifier probes": in case one has multiple mutually exclusive concepts (e.g. image classification), one can set up a multinomial logistic regression problem and minimize cross-entropy loss. A third example, from "A Structural Probe for Finding Syntax in Word Representations": to find a representation of the (syntactic) dependency tree of a sentence at some layer L in the 768-dimensional residual stream[18] of BERT, one looks for a linear map B:R768→Rk, such that when applied to the layer L representation hi of each word i in a sentence [19], the squared L2 norm of the distance between each pair of vectors matches the graph distance between the corresponding vertices of the dependency tree. More precisely, letting dT(i,j) denote the dependency tree distance between words i and j, the sentence contributes a term of ∑i,j∣∣dT(i,j)−||Bhi−Bhj||2∣∣ to the loss.[20] To fit this last example into our framework, we could try to think of the concept we're after as being the dependency tree, with the representation being constructed from the vectors Bhi by looking at the complete graph with edges weighted by pairwise squared L2 distances and taking the minimum spanning tree (which is in fact the inference rule used at test time in the paper). However, the relation dT(i,j)=||Bhi−Bhj||2 is a function of the syntactic representation vectors Bhi, and its value is not recoverable from the tree alone. So it's perhaps better to think of the concepts we're seeking as being the syntactic representation vectors Bhi of words, and this as being a semi-supervised search for these syntactic representations (after all, we're not giving the syntactic representation vectors as labels during training). Or as a slight conceptual variant, one could take the generalized syntax tree of a sentence to just be a tuple of vectors in Rk (out of which the usual syntax tree has to be constructed as a minimum spanning tree), in which case the relations here can be written as relations satisfied by the generalized concept. I refer the interested reader to A Primer in BERTology for more results from supervised probing of BERT, and to Probing Classifiers: Promises, Shortcomings, and Advances for more on supervised probing in general.
To capture a set of concepts C (in an unsupervised way), I'm inviting you to think through the following steps.
Come up with a set P of properties/relations that the concepts in C satisfy. [21] We might have to content ourselves with natural language descriptions here that will just have to be turned into terms in the loss in a semi ad-hoc way, e.g. the property that some particular c∈C is far from being constant. But in my experience, a lot of the properties one comes up with are contrastive, by which I mean that they take the form of an equation between concept values on a set of inputs. For example, in DLK, the property of negation coherence [22] says that for any proposition Q, we have the equation plausibility(¬Q)=1−plausibility(Q). This is a relation between the values of a concept on the contrast tuple(Q,¬Q). Of course, we can construct one such contrast tuple for every proposition Q. So more precisely, let's say a contrastive property is one that has the following form: Here, Ip is a set indexing each contrast tuple, Tp is the set of the finitely many contrast tuples we'll be looking at, and Ep is the equation that the concept values on each tuple should satisfy. For example, for DLK, to capture the property of negation coherence, we could choose Ip={positive,negative}, Tp={t1,t2,t3}[23] where t1positive=[2+2 is 4.], t1negative=[2+2 is not 4.][24], t2positive=[Dolphins are birds.], t2negative=[Dolphins are not birds.], t3positive=[Utilitarianism is incorrect.], t3negative=[Utilitarianism is correct.] and Ep is vnegative=1−vpositive (so with the plausibilities on the given data points plugged into the equation, it becomes plausibility(tnegative)=1−plausibility(tpositive)). In this framework, one can think of supervised probing as having one contrastive property px∈P per data point x with its given label being y=c(x), with Tp={(x)}, and the equation Ep just being z=y, where z is the variable that c(x) gets plugged into.[25]
For each property p∈P, write down a corresponding loss Lp capturing how closely the property is satisfied by given features. For example, for the property p that a concept c∈C with Yc=[0,1] is far from being constant, we might pick a finite set of inputs X′⊆X and let the corresponding loss be the negative sample variance of the feature on these inputs, i.e. Lp=−1|X′|∑x∈X′(fc(x)−∑x∈X′fc(x)|X′|)2, where fc=e(c) is the candidate embedding of the concept c in the set of features F, as defined earlier. For a contrastive property p, one can let Lp=∑t∈Tpℓp((fc(ti))(c,i)∈C×Ip), where ℓp:(∏c∈CYc)Ip→R captures how closely the values of the features fc satisfy the equation Ep on the contrast tuple t. We can usually rewrite Ep with (fc(ti))(c,i)∈C×Ip plugged in to have the form 0=[expression in terms of the fc(ti) for various (c,i)∈C×Ip]=:r((fc(ti))(c,i)∈C×Ip)[26], and one can then let ℓp((fc(ti))(c,i)∈C×Ip)=(r((fc(ti))(c,i)∈C×Ip))2.[27] For example, for the property p of negation coherence in DLK, one can rewrite Ep as 0=1−zpositive−znegative, and the loss term corresponding to the contrast pair (Q,¬Q)'s negation coherence is then ℓp(fplausibility(Q),fplausibility(¬Q))=(1−fplausibility(Q)−fplausibility(¬Q))2.
The final loss L will be a linear combination of the losses for each property with some hyperparameters (λp)p∈P specifying the relative importance of each property, i.e. L=∑p∈PλpLp=∑p∈Pcontrastiveλp∑t∈Tpℓp((fc(ti))(c,i)∈C×Ip))+∑p∈P∖PcontrastiveλpLp.
Now, think about whether the most natural set of concepts having the properties you've written down is the set of concepts you're looking for. If you can think of something else that's more natural, or more generally if there's some plausible way a set of features that doesn't capture C could get low loss, then try adding properties (satisfied by C) not satisfied by these other things.
In practice, having to search over prefeatures instead of features, we might want to add a term to the loss that captures a requirement that the prefeature be simple, e.g. L1 regularization on the coefficients of a linear regression. (The reason this is not already covered by the above is that all the previously considered properties are properties of the concepts translated to relations between the values of the features, whereas regularization is something that can look at inside a feature (at the parameters defining the feature), not just at its input-output behavior.)
If it's difficult to think about how a certain concept c could be represented in a model (for instance because it naturally lives in a space that does not neatly embed into R, e.g. syntax trees) or difficult to write down relations involving c directly, one can try to come up with other concepts that c could be a function of, write down relations for those other concepts, search for features satisfying these inside a model as described above, and then recover c from the values of these other concepts. For instance, this is what happens in "A Structural Probe for Finding Syntax in Word Representations" as described earlier in this post. [28][29]
Examples
What follows is a list of examples stated in terms of the above framework. Some of the examples can be tried on current models with a reasonable chance of success (I think), some do not make sense for current models. I think some are directly relevant to alignment alone, some could be relevant to alignment by e.g. helping us locate parts of important circuits, and some are probably not relevant to alignment except as a proof of concept or for understanding models' representations better in general. Many of the examples are presented in table form in terms of the terminology introduced in the Formalism section above.
DLK
We've already covered most of DLK from the perspective of the framework above, but here's a concise summary:[30]
DLK – complete edition
In the following, we will think of propositions/sentences as coming from propositional calculus or first-order logic. Instead of just looking for a feature that is coherent under negations, one could look for a feature that is coherent under all inference rules of the theory. By coherence, in the context of a given assignment of truth values in {0,1} to all sentences in a given theory, I mean:
the existence of a model[31] for the theory in which the set of sentences which are satisfied is precisely the set of sentences to which the assignment gives truth value 1;
or equivalently that negation coherence holds (meaning that for all sentences ϕ, one of ϕ,¬ϕ gets assigned 0 and the other gets assigned 1), that there is no sentence φ such that starting from the set of sentences assigned 1 (and the axioms), there is a proof of φ and also a proof of ¬φ;
or equivalently that negation coherence holds, that coherence under all inference rules of the theory holds (i.e. for every inference rule, whenever the premises of an inference rule are assigned 1, so is the conclusion), and axioms of the theory are assigned 1.
The last one of these is just a thing we can check on a (finite) bunch of stuff given the assignment.[32] There's some questions here about how to go from the discrete loss one would want to write down to the loss for truthiness taking continuous values in [0,1] that one has to write down – in particular, it's unclear how to interpolate loss corresponding to failing to satisfy inference rules, e.g. modus ponens, to [0,1]. I can think of multiple options for this among which I am unsure how to choose in a principled way (except if we take truthiness to be probability, for which a principled choice is presented in the next subsection). Let's go with thinking of modus ponens as saying that at least one of P,P→Q,¬Q is false, which suggests the equation min(truthiness(P),truthiness(P→Q),1−truthiness(Q))=0, which we can turn into a term in the loss. With this choice, here's the table one gets for this propositional logic (where there's just one inference rule: modus ponens): (pdf version)
In practice, we might have concerns about a language model's ability to understand the given input sentences, or about whether it understands them in the way this framework intends it to because of ambiguities in natural language; see the end of the next subsection for more on this. Because of these concerns, we might want to only take require coherence under a curated subset of inference rules, on a curated set of sentences – for instance, only ORs and ANDs of particular sentences of the form "The height of [famous building A] is between x and y."
DLK – probabilistic complete edition
A reasonable notion of coherence for a probability assignment to sentences is that there is a probability distribution of models for the theory which induces the given probability for the truth of every sentence. By Theorem 1 from here, this is equivalent to the probability assignment having all of the following three properties:
We might want to allow a theory which lets us create conditional environments, in which case I think just adding Bayes' rule to the above will again be equivalent to probabilistic coherence. One issue with this for language models is that the difference between [conditional on a proposition P, claim], [P and claim], and [P implies claim] is subtle in natural language. E.g. consider "Suppose that the present King of France is bald. Then, the present King of France has no hair." (In fact, it's even more of a mess.) But of course, as the ambiguity goes both ways, this is also an issue for the schemas presented in the last two tables above! It would be great to better understand which of these interpretations language models run with. In the best case, there would be a separate feature that matches each.
An agent's estimate of the value of a state, from inside the policy network
Some notes:
One can subject the features found to a calibration test at the end. (Take a bucket of board states with "value" (according to the feature we found) in [−0.2,−0.1], and check that the average value obtained from these is close to −0.15.
As a special case, this framework lets us capture the win probability in games where there is guaranteed to be a winner.
We can also add some supervised constraints to the loss from board states that are one ply from winning, or facing a guaranteed loss in two plies. (In fact, this could replace the variance term.)
One issue with this is that sending expected reward through any odd function t:[−1,1]→[−1,1] respecting the boundary condition at 1 is going to still satisfy the constraints (or do even better if it extremizes). A completely analogous thing can be said about the original DLK constraints though, for functions which are antisymmetric around (12,12).
Is the model doing search?
One often does search over plans by considering a bunch of possible plans, evaluating their value, and then choosing the option with maximal value. (Though there are things reasonably called search that are not really likethis.) There is a constraint given by this process that gives us something to look for as an anchor to locate search in a model: the future value from the current situation is going to be the max of the values of the various options considered. In addition to e.g. helping us understand if a model is doing optimization, locating search in a model models could be useful because maybe that could help us retarget it. Here's a concrete experiment that could be run right now to look for search over possible next moves in an RL agent for CoinRun (written a bit less formally than previous examples):
A vision model's sense of direction
A few notes:
In practice, the integral in the loss can be approximated by sampling α,β.
The model might have a representation of the direction of e.g. gravity w.r.t. the picture plane, which naturally lives in S2, not S1, and we might want to change the framing to look for that instead.
This generalizes to looking for other linear transformations. As other special cases, one could replace rotating the image by rescaling the horizontal direction by a constant, or by applying a shear.
[34] The paper goes on to check that the learned syntactic representations capture some syntactic properties better than the baseline. I think it would be a big win for linguistics if someone came up with an unsupervised method that reliably recovers the syntax trees linguists believe in from language models.
Preferences
Let's say we have a model that can contemplate pairs of lotteries, and we would like to find its preferences. We could look for a preference feature taking values in [−1,1], where −1 intuitively corresponds to the first lottery being preferred, and 1 corresponds to the second being preferred, by looking for a feature satisfying the vNM axioms. Turn the completeness axiom into an equation saying that the preference for the pair (A,B) and the preference on the pair (M,L) should form {−1,1} (this can be done analogously to what was done for negation coherence in the extended DLK subsection). Transitivity can be turned into an equation in analogy with modus ponens. For the Archimedean property, we can for instance have the loss term be −ReLU(f(L,M))ReLU(f(M,N))(f((1−ε)L+εN,M)+f(M,εL+(1−ε)N)) for ε=10−5 (this will sometimes be too big an ε, but hopefully rarely enough that it's fine). And for independence, we can have the loss term be minus the product of the preferences on the two lotteries, −f(L,M)f(pL+(1−p)N,pM+(1−p)N).
One issue here is that the comparing lotteries according to the expectation of any random variable will satisfy these properties. We might need to come up with a way to fine-tune/prompt the model such that preferences become more salient in its cognition.
Expected utilities
Alternatively, have the model contemplate lotteries, and look for a feature satisfying the property that utilities of composite lotteries should decompose:
In fact, for monetary lotteries, I think it would be reasonable to look for a direction capturing monetary expected value in e.g. GPT-4. Again, a big limitation is that these relations hold for the expectation of any random variable. For this to succeed, we might need to expose the model to specific situations/fine-tuning which cause utility to become very salient.
Conserved quantities in a physics simulator
Take an ML model trained to do time evolution on a physics system, and look for whether it has learned the same conserved quantities (energy, momentum, angular momentum, charge) by writing down the constraint that a quantity should be preserved under time evolution but have variance across random world-states in general, look for a tuple of uncorrelated features inside the model satisfying these constraints, and see if what you get matches the familiar conserved quantities. (Should one generally expect to get linear combinations of these quantities instead of getting these quantities? In that case, do we at least get an invariant subspace of features which is spanned by the familiar quantities?) (Is there some cool connection with Noether's theorem here? I mean besides the fact that symmetries correspond to conservation laws – is there a way to use a symmetry of the Lagrangian to write down a constraint on a feature to search for the conserved quantity corresponding to that symmetry?)
Concepts we could find in the hyperoptimistic limit
In the hyperoptimistic limit, having robustly solved decision theory, we could write down the relations that beliefs and goals should satisfy – e.g. evidential expected utility maximization, or maybe some shard-theoretic understanding of how shards lead to actions – and just look for features which stand in these relations to each other, and hyperoptimistically actually just find the model's beliefs and goals. Or we could write down the constraints that correct epistemic reasoning should satisfy, and search for something satisfying these constraints to find a model's epistemics.
Limitations
Two competing factors need to be balanced for this kind of search to have a chance of working:
Specify too many relations, give too many labels, and you're in danger of assuming something about the model's conceptual framework which isn't true. Your search might fail because it's looking for something that doesn't exist inside the model.
Specify too few relations, give too few labels, and you're going to be unlikely to find what you're looking for because of the search not being constrained enough. In other words, the search only has a chance of working if what you're looking for is roughly the most natural thing satisfying the relations you gave. The shape specified needs to capture what you're looking for, and it needs to be violated by anything else at least as natural for the model as the concept you're looking for.[35]
Further directions
What I'd really like to say is that the relations one has to write down for a particular set of concepts are simply the result of mapping some sort of commutative diagram type thing from the "Platonic (coherence) category of concepts" that satisfies some unique property for this set of concepts into features, but I don't know how to do that. Even absent that, I think a category theorist would have written this post quite differently, and I'd be interested in seeing a category-theoretic version of this story.
I'd also be interested in ideas for pursuing the connection with model theory further, e.g. using it to inspire ways to look for representations of objects, functions, or predicates (perhaps corresponding to circuits?) in ML models.
We'd be very interested in other examples of concepts satisfying some simple relations which pin them down, especially those that are plausibly searchable in current models, useful to find in the AGI limit, or theoretically appealing[36].
As for the next few weeks, the main experimental focus of our SERI MATS team remains on the directions outlined in our previous post, as well as on figuring out ways to check if we are measuring what we think are measuring. However, we are planning to run a number of the experiments outlined above in the future. If you would be interested in running some of these experiments and would like to discuss further, feel free to email me at kaarelh AT gmail DOT com.
Acknowledgments
This post was written by Kaarel Hänni on behalf of NotodAI Research, a team in John Wentworth's track in SERI MATS 3.0 consisting of Walter Laurito and Kay Kozaronek as the experimentalists, Georgios Kaklamanos as the distiller/facilitator, and me as the theorist, and on behalf of our research collaborators Alex Mennen and June Ku. I would like to thank Walter, Kay, and George for the great time I've had working with them on this project; John and SERI MATS for making this work possible; and Alex and June for contributing a large fraction of the ideas presented above. In addition to all the aforementioned people, I would like to thank Matt MacDermott, Jörn Stöhler, Daniel Filan, Peli Grietzer, Johannes C. Mayer, John Wentworth, Lucius Bushnaq, Collin Burns, Nora Belrose, Alexander Gietelink Oldenziel, and Marius Hobbhahn for discussions and feedback. I would particularly like to thank Alexandre Variengien for helpful conversations that greatly expanded my sense of what concepts that can be searched for in models, motivating much of the above work.
Strictly speaking, we have switched from searching for a concept to searching for a model's representation of a concept. This is fine as long as one can recover the value of a concept if one has a model's representation of it (e.g. recover whether something has charge from whether a model thinks it has charge), which is generally not hard (conditional on having located the concept's representation in the model), because we can then lift the relation on the concepts to a relation on the representations. If this still worries you, I invite you to check if the formalism section assuages your concerns.
It's also possible to train against this interpretability tool, though that seems dangerous for the usual reasons. Maybe it's fine if we're clever about it?
Here's another philosophical framing of DLK. DLK is looking for something inside a model that just fits together as required by the coherence theory of truth, and it seems somewhat promising that this alone indeed finds the model's beliefs! In this framing, adding in some examples with labels, e.g. "2+2=4" being true, would be like inserting some constraints coming from the correspondence theory of truth as well.
The approach is also very similar to the syntactic part of June Ku's MetaEthical.AI framework, except with the part applying to brains applied to models instead. See item 1.2 here and also see this.
Saying that a direction in activation space is a feature is an abuse of language (at least in the framing presented here), but I think it's a common one.
at least one that is small enough to naively search over (i.e. just loop over); we might be able to come up with huge discrete sets like this, but optimizing over those is tricky
I think the reason for this is some combination of considerations about computational efficiency, reducing the dimensionality of the search space, and getting a better inductive bias (if we have reason to believe that some concept is more likely to be represented in a certain location in the model).
Ok, this is not quite true, because they are actually performing a normalization of the activations first to get rid of a different solution that satisfies the right constraints.
I'm not really sure if I've sufficiently captured all there is to concepts with this type signature. For example, take the concept [planet]. Is it fair to just identify the concept with something like the set of inputs to my world model for which the concept gets activated? One thing that this might be missing is that my concept of [planet] should stand in some relations to lots of other concepts like [star] and [gravity]. And maybe we want the features we find to actually stand in this relation in the model's computation? I guess that since we will be looking at when [planet] gets activated together with when a bunch of other concepts get activated, maybe this is fine – we can even recover causation from data using Pearl's work. And also, even if we find accurate representations of concepts which are not causally effective, e.g. because the concept is represented in various activations and one would need to alter most of them, we might be content with being able to interpret a model without being able to edit the model directly
Okay, this is not quite most general, because (especially when having to deal with prefeatures instead of features) we might want to also add some terms that depend on the parameters of the prefeatures considered (e.g. L1regularization of coefficients for linear features) to select for ones which are more natural.
A technicality: for this to make sense, fc should be picked from only among features with the right type signature, i.e. with Yc≅Yfc. And if there are multiple ways in which Yc and Yfc are isomorphic, then the embedding e should technically also carry data specifying this isomorphism. Or more generally, one should specify maps of both Yc and Yfc into the same space Y′c, and Y′c should replace Yc in the type signature of the loss function.
I couldn't find anyone talking about the "residual stream" of BERT on the interwebs, so to clarify, what I mean are just "the contextualized representations in hidden layer L" of BERT.
You might be worried about the representations don't directly correspond to words because BERT's tokenizer might not just consider each word an individual token. I invite you to forget this and to assume the tokenizer respects words for this example. But I believe what really happens is that (1) the units that go in the dependency trees are Penn Treebank tokens which are often words but sometimes subwords (if a word consists of multiple syntactic units, e.g. "rais-ing"), and (2) representations of BERT's tokens overlapping with each Penn Treebank token are averaged to create a representation of the Treebank token. (I'm not sure if BERT's tokens always correspond to subwords of the subwords corresponding to Penn Treebank tokens or not, and I'm not sure if they use the length of overlap as a weight in the average.)
I would love to say that the properties are obtained by evoking some universal property to construct a diagram in some sort of platonic category of concepts, and then mapping this diagram down into the shadow realm with some concept projection/realization functor, but alas, all I can see are shadows.
A different way to accommodate supervised or semi-supervised probing would be to say that supervised probing is when we turn the equation Ep into one that can depend on the values of the concepts on the particular contrast tuple t. But it really does seem right to me to consider matching each label as a conceptually independent property that the probe should satisfy. Intuitively, if one can capture a concept using unsupervised probing with only a few properties, then it only takes a short description, i.e. a small number of bits of information, to pin down the concept starting from the prior distribution induced by the model's learned representations, meaning it must be a really natural concept for the model! Whereas simply being recoverable with a probe that needs many labeled data points is a much weaker kind of naturalness – one needs to give a lot more data to the probing process to find what one's after. (That said, it's possible that only a small number of labels would also pin some concept down.) So I think that with this convention for supervised probing, the number of properties |P| is a good way to capture the message lenght here. What's more, I think it's reasonable to think of there being a spectrum between unsupervised and supervised probing parametrized by |P|. In this framing, the motivating idea behind unsupervised probing for concepts is that certain concepts are naturally used in the mental framework of humans and models, and we can find their values by specifying just a small number of bits of information about them.
We could have just said that equations are of the form [0=r(v)] with r:(∏c∈CYc)Ip→R by definition when we first introduced Ep, but I think this might have been more confusing, and that it could be good to keep the form of Ep a bit more open to allow more stuff, e.g. see the example with learning syntax later.
But it might also occasionally be neater to go with some different loss term, e.g. r might be such that it's guaranteed that r≥0 for any inputs, in which case it could make sense to just put r in the loss (instead of r2).
I believe one could shoehorn this example (as well as other similar cases, probably) into the framework above by adding prefeatures that are minimum spanning trees of the distance graph of linear function outputs and adding a really big term to the loss for the syntax tree concept being equal to the MSP one would construct from these syntactic representation vectors of words. But while the framework above can be thought to already capture that, it's clearly conceptually neater to think of the syntax tree as just being a predetermined function of other concepts.
You might notice that this form is technically no less general than what we started from because one could technically fit all inputs in one contrast tuple. But it definitely feels more fleshed-out to me. Think of it as a form with an attitude.
It currently seems more theoretically natural to me to either replace negation coherence with a second confidence term, max(plausibility(Q),plausibility(¬Q))=1, or to keep negation coherence and to replace the confidence equation with plausibility(Q)(1−plausibility(Q))=0 (this would apply to all propositions, including ¬Q). (I haven't tried if either of these makes any difference in practice.)
I am not saying that one can check that no contradiction is generated by some finite set – this is undecidable – just that the conditions stated above can be mechanically checked on some finite number of tuples on which they apply.
This also implies that in the special case where all probabilities assigned are 0 or 1, as long as these three things are satisfied, there is a model of the theory with the assigned truth-values.
The contextualized representation of a word which is used is the mean of its reps across all layers concatenated with the representation at layer 16. (Or really, the representation of the first token in the word.)
In fact, the DLK paper runs into this issue. The framing of it above is not actually quite what's done in the paper. Really, instead of (P,¬P), the contrast pairs in the paper are more like ("Is Paris the capital of France? A: Yes","Is Paris the capital of France? A: No"), and a really salient feature satisfying both DLK constraints for such pairs is just whether the phrase ends with "Yes" or "No". To fix this, the paper subtracts the average of the activation vectors of all phrases ending with "Yes" from each activation vector of a phrase ending with "Yes" before doing the search for a feature satisfying the constraints. I think this roughly makes sense given the picture of features as directions and the law of large numbers.
Produced as part of the SERI ML Alignment Theory Scholars Program - Winter 2022 Cohort
Introduction
I think that Discovering Latent Knowledge in Language Models Without Supervision (DLK; Burns, Ye, Klein, & Steinhardt, 2022) is a very cool paper – it proposes a way to do unsupervised mind reading[1] – diminished only by not making its conceptual coolness evident enough in the paper writeup. This is in large part corrected in Collin Burns's more conceptual companion post. I'm rooting for their paper to sprout more research that finds concepts / high-level features in models by searching for their shape[2]. The aim of this post is to present a conceptual framework for this kind of interpretability, which I hope will facilitate turning concepts into structures to look for in ML models. Understanding this post does not require having read DLK, as the reader will be walked through the relevant parts of the result in parallel with developing this framework.
Epistemic status: This post contains a theoretical framework that suggests a bunch of concrete experiments, but none of these experiments have been run yet (well, except for ones that were run prior to the creation of the framework), so it's quite possible the framework ends up leading to nothing in practice. Treat this as an interim report, and as an invitation to action to run some of these experiments yourself. This post is written by Kaarel Hänni on behalf of a team consisting of Georgios Kaklamanos, Kay Kozaronek, Walter Laurito, June Ku, Alex Mennen, and myself.
The rough picture of the approach
The idea is to start with a list of related concepts (or possibly just a single concept), write down a list of relations that the concepts satisfy, and then search for a list of features inside the model satisfying these relations. The hope is that this gives a way to find concepts inside models which requires us to make fewer assumptions about the model's thinking than if we were e.g. training a probe on activations according to human-specified labels. For instance, if we had good reasons to believe that models assign utilities to outcomes, but we had no idea about what the utility assignment is, we couldn't train a supervised probe (because of lacking labels), but perhaps we could still train an unsupervised probe that looks for utility-shaped features in the model. The bet would be that the utility-shaped features we find indeed store the model's utility assignment.
Philosophical framing
The approach described above is very similar to Ramsification[3], a method for turning a theory in narrative form – usually with terms not grounded in some previously understood theory, possibly with circular definitions – into a well-defined theory. Roughly speaking, when presented with a scientific theory stated as a bunch of statements involving new terms, e.g. (borrowing an example from Wikipedia) the new terms "electron" and "charge" in the narrative theory "Electrons have charge. Things with charge tickle you. Electrons cause lightning.", Ramsification suggests picking the meaning of "being an electron" and "having charge" in whatever way makes the narrative as true as possible, i.e. minimizing the fraction of cases in which the sentences are wrong.
I'm immediately struck by two (related) issues. First, it's not clear what the set of meanings is from which we are allowed to pick one – in fact, it's not even obvious to me what kind of language (theory, metatheory, or whatever) these meanings should be specified in. Second, I'd guess there's probably always going to be some convoluted meanings that satisfy the narrative form really well, but which aren't the natural concepts we'd want e.g. "electron" and "charge" to capture. So it would be nice if we could constrain the search for meanings only to natural concepts. Here's an idea: perhaps these issues would be fixed if we had a machine that learns useful representations for doing stuff, in which case we could restrict our search to the features learned by this machine.[4] This gives us a concrete search space, as well as a reason to believe that a lot of measure in the search space is inhabited by reasonable abstractions. One crucially important concept is truth, and language models are really powerful models that can understand text, which is a natural kind of thing to carry truth. So perhaps it makes sense to look for a representation of truth inside language models? (Spoiler: DLK does this.) In case the usefulness of being able to find out what a model believes is not obvious in analogy with how interpretability is generally useful, I'll spell out a few ways in which this is useful:
Finally getting to the star of the show now: in DLK, it's plausible that they pull off just the above in current language models! One can think of the constraints used in the paper as arising by Ramsification from the following narrative form:
The paper searches for a feature in the model satisfying these relations, and turns out to indeed find something that's pretty correlated with ground truth! emotive status: Very cool. [6][7]
Formalism: features
Let F be the set of all features of a model. For now, feel free to think of F as just a finite list if you like. Let's think of each element f∈F as a function from the model input space X to some output space Yf – there can be a different output space Yf for each feature f. Here are four examples of features we could imagine an image classification model having:
In general, the features should be derived from activations of the model in a pretty simple way. By this, I mean that if the map from model inputs to corresponding activations is g:X→A, then for every feature f, there is a simple map hf:A→Yf such that f=hf∘g. For example, it could be that features are directions in activation space A≅Rn, in which case every Yf is a subspace of A (or perhaps more precisely of the subspace spanned by the activations in just one layer, or at just one position in the residual stream of a language model), so Yf≅R, and hf is a projection from the activation space to that subspace.[8][9]
So, what are features? I don't know – the above definitely doesn't nail it down. In particular, the above does not capture the idea of features being the natural abstract units in terms of which a model is performing computation, not to speak of giving an algorithm for computing the features of a model. So, unfortunately, even though the above presentation most conjures up an image of the feature set F as a discrete thing, as humanity hasn't solved the problem of coming up with such a discrete set yet,[10] in current practice we might want to work with a set F with smooth structure so as to be able to do gradient descent over it. This smooth F will almost always contain elements that are not features, so let's call it the set of prefeatures instead. And we will also often want to restrict to only a subset of all prefeatures of a model.[11] For example, if our model is GPT-J and we want to consider prefeatures with output space Yf=[0,1], then we could e.g. let F be the set of all one-dimensional subspaces of the vector space of activations at the last token position in the last layer, by which I really mean that if the scalar activations are z1,…,zd, then F is the set of all f induced by hf of the form hf=σ(a+∑di=1bizi), where σ is the usual sigmoid σ(s)=11+e−s. (So there's an f for each setting of a and b1,b2,…,bd∈R, and gradient descent is really happening over these parameters.) This is the choice of the prefeature set in the DLK paper. [12]
Formalism: searching for concepts in features
Ok, whatever, let's assume for now that Anthropic et al. have succeeded at creating the powerful primitive of enumerating over all features of a model, so we can run this on our model, and get a set F of all features of the model. But even if we have a list of features in terms of which the model is performing computation, that doesn't make it trivial to identify features with useful concepts. For instance, we don't a priori know whether some feature is detecting dog snouts, or which one it is. So there's still some interpretability work to be done: we want to find a feature (or set of features) where a model's version of some concept or another lives. Let's associate each concept – e.g. truth, utility, honesty, treeness, goodness according to humanity's CEV, ease of traversing a particular piece of terrain, whether another agent is an adversary, etc. [13] – with a function c:X→Yc with X being the input space of the model and Yc being some space specific to that concept [14][15]. (This agrees with the framework on pages 8-9 of "Acquisition of Chess Knowledge in AlphaZero", with the caveat that we haven't assumed the function c:X→Yc to be a priori known to us.)
Just write down a loss function capturing the concepts and minimize it?
Most generally [16], to capture a set of concepts C, we could now define some loss function L=LC,X with type signature L:∏(c,x)∈C×XYc→R that attains an exceptionally low value with the indexed family containing the true concept values on all the inputs (c(x))(c,x)∈C×X as the input . Once we have L, we search for an embedding of the concepts into features, e:C→F, such that denoting fc=e(c), the loss L((fc(x))(c,x)∈C×X) is small. [17] The bet probing makes is that if the concepts in C are natural enough and L is designed well, then the fc we find from this search capture the model's versions of the concepts C.
So, how would one design L for given concepts of interest? In general, it will require some cleverness not algorithmized away by the formalism at hand. But I think considering losses L with some additional structure can take us some of the way there. We'll look at a few simple cases before writing down a canonical form.
Special case: supervised probing for a single concept
Suppose that for the concept c:X→R, we have a list of n input-output pairs, i.e. (xi,c(xi))∈X×R for i=1,2,…,n. Then it's natural to just let L=∑ni=1(fc(xi)−c(xi))2. In case we are looking for a feature fc that is a direction in activation space, the problem reduces to OLS. Further adding a regularization term to this loss (and sending through a sigmoid for concepts living in [0,1]), one gets the supervised probes in "Acquisition of Chess Knowledge in AlphaZero". A second example of supervised probing, from "Understanding intermediate layers using linear classifier probes": in case one has multiple mutually exclusive concepts (e.g. image classification), one can set up a multinomial logistic regression problem and minimize cross-entropy loss. A third example, from "A Structural Probe for Finding Syntax in Word Representations": to find a representation of the (syntactic) dependency tree of a sentence at some layer L in the 768-dimensional residual stream[18] of BERT, one looks for a linear map B:R768→Rk, such that when applied to the layer L representation hi of each word i in a sentence [19], the squared L2 norm of the distance between each pair of vectors matches the graph distance between the corresponding vertices of the dependency tree. More precisely, letting dT(i,j) denote the dependency tree distance between words i and j, the sentence contributes a term of ∑i,j∣∣dT(i,j)−||Bhi−Bhj||2∣∣ to the loss.[20] To fit this last example into our framework, we could try to think of the concept we're after as being the dependency tree, with the representation being constructed from the vectors Bhi by looking at the complete graph with edges weighted by pairwise squared L2 distances and taking the minimum spanning tree (which is in fact the inference rule used at test time in the paper). However, the relation dT(i,j)=||Bhi−Bhj||2 is a function of the syntactic representation vectors Bhi, and its value is not recoverable from the tree alone. So it's perhaps better to think of the concepts we're seeking as being the syntactic representation vectors Bhi of words, and this as being a semi-supervised search for these syntactic representations (after all, we're not giving the syntactic representation vectors as labels during training). Or as a slight conceptual variant, one could take the generalized syntax tree of a sentence to just be a tuple of vectors in Rk (out of which the usual syntax tree has to be constructed as a minimum spanning tree), in which case the relations here can be written as relations satisfied by the generalized concept. I refer the interested reader to A Primer in BERTology for more results from supervised probing of BERT, and to Probing Classifiers: Promises, Shortcomings, and Advances for more on supervised probing in general.
The canonical form of a probing loss function
To capture a set of concepts C (in an unsupervised way), I'm inviting you to think through the following steps.
Examples
What follows is a list of examples stated in terms of the above framework. Some of the examples can be tried on current models with a reasonable chance of success (I think), some do not make sense for current models. I think some are directly relevant to alignment alone, some could be relevant to alignment by e.g. helping us locate parts of important circuits, and some are probably not relevant to alignment except as a proof of concept or for understanding models' representations better in general. Many of the examples are presented in table form in terms of the terminology introduced in the Formalism section above.
DLK
We've already covered most of DLK from the perspective of the framework above, but here's a concise summary:[30]
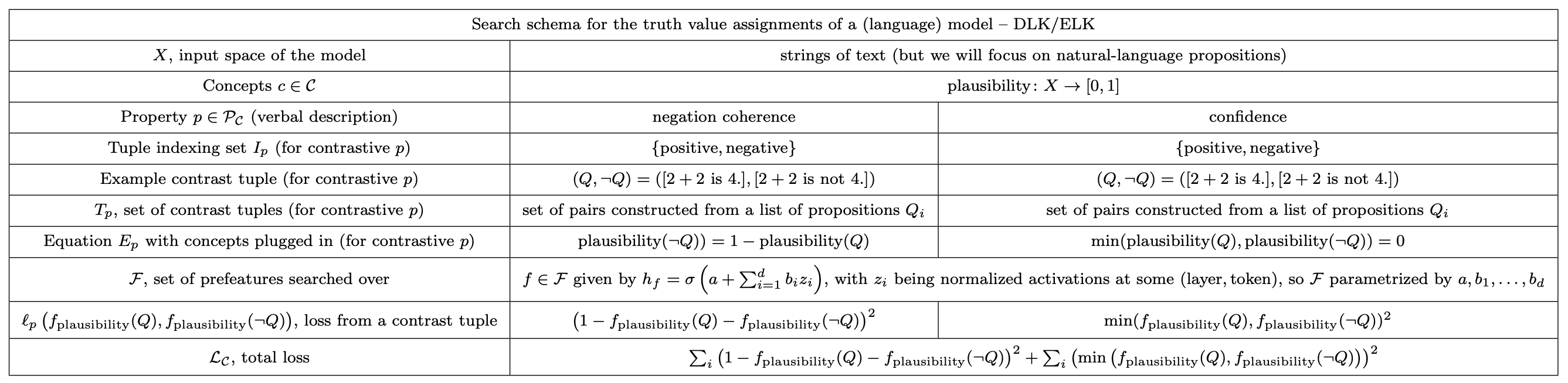
DLK – complete edition
In the following, we will think of propositions/sentences as coming from propositional calculus or first-order logic. Instead of just looking for a feature that is coherent under negations, one could look for a feature that is coherent under all inference rules of the theory. By coherence, in the context of a given assignment of truth values in {0,1} to all sentences in a given theory, I mean:
The last one of these is just a thing we can check on a (finite) bunch of stuff given the assignment.[32] There's some questions here about how to go from the discrete loss one would want to write down to the loss for truthiness taking continuous values in [0,1] that one has to write down – in particular, it's unclear how to interpolate loss corresponding to failing to satisfy inference rules, e.g. modus ponens, to [0,1]. I can think of multiple options for this among which I am unsure how to choose in a principled way (except if we take truthiness to be probability, for which a principled choice is presented in the next subsection). Let's go with thinking of modus ponens as saying that at least one of P,P→Q,¬Q is false, which suggests the equation min(truthiness(P),truthiness(P→Q),1−truthiness(Q))=0, which we can turn into a term in the loss. With this choice, here's the table one gets for this propositional logic (where there's just one inference rule: modus ponens): (pdf version)
In practice, we might have concerns about a language model's ability to understand the given input sentences, or about whether it understands them in the way this framework intends it to because of ambiguities in natural language; see the end of the next subsection for more on this. Because of these concerns, we might want to only take require coherence under a curated subset of inference rules, on a curated set of sentences – for instance, only ORs and ANDs of particular sentences of the form "The height of [famous building A] is between x and y."
DLK – probabilistic complete edition
A reasonable notion of coherence for a probability assignment to sentences is that there is a probability distribution of models for the theory which induces the given probability for the truth of every sentence. By Theorem 1 from here, this is equivalent to the probability assignment having all of the following three properties:
[33] This motivates the following table:
We might want to allow a theory which lets us create conditional environments, in which case I think just adding Bayes' rule to the above will again be equivalent to probabilistic coherence. One issue with this for language models is that the difference between [conditional on a proposition P, claim], [P and claim], and [P implies claim] is subtle in natural language. E.g. consider "Suppose that the present King of France is bald. Then, the present King of France has no hair." (In fact, it's even more of a mess.) But of course, as the ambiguity goes both ways, this is also an issue for the schemas presented in the last two tables above! It would be great to better understand which of these interpretations language models run with. In the best case, there would be a separate feature that matches each.
An agent's estimate of the value of a state, from inside the policy network
Some notes:
Is the model doing search?
One often does search over plans by considering a bunch of possible plans, evaluating their value, and then choosing the option with maximal value. (Though there are things reasonably called search that are not really like this.) There is a constraint given by this process that gives us something to look for as an anchor to locate search in a model: the future value from the current situation is going to be the max of the values of the various options considered. In addition to e.g. helping us understand if a model is doing optimization, locating search in a model models could be useful because maybe that could help us retarget it. Here's a concrete experiment that could be run right now to look for search over possible next moves in an RL agent for CoinRun (written a bit less formally than previous examples):
A vision model's sense of direction
A few notes:
Unsupervised syntax discovery
Here's Unsupervised Distillation of Syntactic Information from Contextualized Word Representations stated in terms of this framework:
[34] The paper goes on to check that the learned syntactic representations capture some syntactic properties better than the baseline. I think it would be a big win for linguistics if someone came up with an unsupervised method that reliably recovers the syntax trees linguists believe in from language models.
Preferences
Let's say we have a model that can contemplate pairs of lotteries, and we would like to find its preferences. We could look for a preference feature taking values in [−1,1], where −1 intuitively corresponds to the first lottery being preferred, and 1 corresponds to the second being preferred, by looking for a feature satisfying the vNM axioms. Turn the completeness axiom into an equation saying that the preference for the pair (A,B) and the preference on the pair (M,L) should form {−1,1} (this can be done analogously to what was done for negation coherence in the extended DLK subsection). Transitivity can be turned into an equation in analogy with modus ponens. For the Archimedean property, we can for instance have the loss term be −ReLU(f(L,M))ReLU(f(M,N))(f((1−ε)L+εN,M)+f(M,εL+(1−ε)N)) for ε=10−5 (this will sometimes be too big an ε, but hopefully rarely enough that it's fine). And for independence, we can have the loss term be minus the product of the preferences on the two lotteries, −f(L,M)f(pL+(1−p)N,pM+(1−p)N).
One issue here is that the comparing lotteries according to the expectation of any random variable will satisfy these properties. We might need to come up with a way to fine-tune/prompt the model such that preferences become more salient in its cognition.
Expected utilities
Alternatively, have the model contemplate lotteries, and look for a feature satisfying the property that utilities of composite lotteries should decompose:
In fact, for monetary lotteries, I think it would be reasonable to look for a direction capturing monetary expected value in e.g. GPT-4. Again, a big limitation is that these relations hold for the expectation of any random variable. For this to succeed, we might need to expose the model to specific situations/fine-tuning which cause utility to become very salient.
Conserved quantities in a physics simulator
Take an ML model trained to do time evolution on a physics system, and look for whether it has learned the same conserved quantities (energy, momentum, angular momentum, charge) by writing down the constraint that a quantity should be preserved under time evolution but have variance across random world-states in general, look for a tuple of uncorrelated features inside the model satisfying these constraints, and see if what you get matches the familiar conserved quantities. (Should one generally expect to get linear combinations of these quantities instead of getting these quantities? In that case, do we at least get an invariant subspace of features which is spanned by the familiar quantities?) (Is there some cool connection with Noether's theorem here? I mean besides the fact that symmetries correspond to conservation laws – is there a way to use a symmetry of the Lagrangian to write down a constraint on a feature to search for the conserved quantity corresponding to that symmetry?)
Concepts we could find in the hyperoptimistic limit
In the hyperoptimistic limit, having robustly solved decision theory, we could write down the relations that beliefs and goals should satisfy – e.g. evidential expected utility maximization, or maybe some shard-theoretic understanding of how shards lead to actions – and just look for features which stand in these relations to each other, and hyperoptimistically actually just find the model's beliefs and goals. Or we could write down the constraints that correct epistemic reasoning should satisfy, and search for something satisfying these constraints to find a model's epistemics.
Limitations
Two competing factors need to be balanced for this kind of search to have a chance of working:
Further directions
What I'd really like to say is that the relations one has to write down for a particular set of concepts are simply the result of mapping some sort of commutative diagram type thing from the "Platonic (coherence) category of concepts" that satisfies some unique property for this set of concepts into features, but I don't know how to do that. Even absent that, I think a category theorist would have written this post quite differently, and I'd be interested in seeing a category-theoretic version of this story.
I'd also be interested in ideas for pursuing the connection with model theory further, e.g. using it to inspire ways to look for representations of objects, functions, or predicates (perhaps corresponding to circuits?) in ML models.
We'd be very interested in other examples of concepts satisfying some simple relations which pin them down, especially those that are plausibly searchable in current models, useful to find in the AGI limit, or theoretically appealing[36].
As for the next few weeks, the main experimental focus of our SERI MATS team remains on the directions outlined in our previous post, as well as on figuring out ways to check if we are measuring what we think are measuring. However, we are planning to run a number of the experiments outlined above in the future. If you would be interested in running some of these experiments and would like to discuss further, feel free to email me at kaarelh AT gmail DOT com.
Acknowledgments
This post was written by Kaarel Hänni on behalf of NotodAI Research, a team in John Wentworth's track in SERI MATS 3.0 consisting of Walter Laurito and Kay Kozaronek as the experimentalists, Georgios Kaklamanos as the distiller/facilitator, and me as the theorist, and on behalf of our research collaborators Alex Mennen and June Ku. I would like to thank Walter, Kay, and George for the great time I've had working with them on this project; John and SERI MATS for making this work possible; and Alex and June for contributing a large fraction of the ideas presented above. In addition to all the aforementioned people, I would like to thank Matt MacDermott, Jörn Stöhler, Daniel Filan, Peli Grietzer, Johannes C. Mayer, John Wentworth, Lucius Bushnaq, Collin Burns, Nora Belrose, Alexander Gietelink Oldenziel, and Marius Hobbhahn for discussions and feedback. I would particularly like to thank Alexandre Variengien for helpful conversations that greatly expanded my sense of what concepts that can be searched for in models, motivating much of the above work.
This phrasing is taken from Burns's companion post.
I share the authors' optimism about the approach extending to superhuman models.
I learned about Ramsification from this talk by June Ku. It's also the only presentation of Ramsification I know of which allows for error.
Strictly speaking, we have switched from searching for a concept to searching for a model's representation of a concept. This is fine as long as one can recover the value of a concept if one has a model's representation of it (e.g. recover whether something has charge from whether a model thinks it has charge), which is generally not hard (conditional on having located the concept's representation in the model), because we can then lift the relation on the concepts to a relation on the representations. If this still worries you, I invite you to check if the formalism section assuages your concerns.
It's also possible to train against this interpretability tool, though that seems dangerous for the usual reasons. Maybe it's fine if we're clever about it?
Here's another philosophical framing of DLK. DLK is looking for something inside a model that just fits together as required by the coherence theory of truth, and it seems somewhat promising that this alone indeed finds the model's beliefs! In this framing, adding in some examples with labels, e.g. "2+2=4" being true, would be like inserting some constraints coming from the correspondence theory of truth as well.
The approach is also very similar to the syntactic part of June Ku's MetaEthical.AI framework, except with the part applying to brains applied to models instead. See item 1.2 here and also see this.
times a constant scaling plus a constant shift, so really a linear functional
Saying that a direction in activation space is a feature is an abuse of language (at least in the framing presented here), but I think it's a common one.
at least one that is small enough to naively search over (i.e. just loop over); we might be able to come up with huge discrete sets like this, but optimizing over those is tricky
I think the reason for this is some combination of considerations about computational efficiency, reducing the dimensionality of the search space, and getting a better inductive bias (if we have reason to believe that some concept is more likely to be represented in a certain location in the model).
Ok, this is not quite true, because they are actually performing a normalization of the activations first to get rid of a different solution that satisfies the right constraints.
Each of these only has a chance of being represented as a concept in a respective particular kind of (current) model
I'm not really sure if I've sufficiently captured all there is to concepts with this type signature. For example, take the concept [planet]. Is it fair to just identify the concept with something like the set of inputs to my world model for which the concept gets activated? One thing that this might be missing is that my concept of [planet] should stand in some relations to lots of other concepts like [star] and [gravity]. And maybe we want the features we find to actually stand in this relation in the model's computation? I guess that since we will be looking at when [planet] gets activated together with when a bunch of other concepts get activated, maybe this is fine – we can even recover causation from data using Pearl's work. And also, even if we find accurate representations of concepts which are not causally effective, e.g. because the concept is represented in various activations and one would need to alter most of them, we might be content with being able to interpret a model without being able to edit the model directly
For us to have hope of finding a concept, it should probably be something like a natural abstraction.
Okay, this is not quite most general, because (especially when having to deal with prefeatures instead of features) we might want to also add some terms that depend on the parameters of the prefeatures considered (e.g. L1regularization of coefficients for linear features) to select for ones which are more natural.
A technicality: for this to make sense, fc should be picked from only among features with the right type signature, i.e. with Yc≅Yfc. And if there are multiple ways in which Yc and Yfc are isomorphic, then the embedding e should technically also carry data specifying this isomorphism. Or more generally, one should specify maps of both Yc and Yfc into the same space Y′c, and Y′c should replace Yc in the type signature of the loss function.
I couldn't find anyone talking about the "residual stream" of BERT on the interwebs, so to clarify, what I mean are just "the contextualized representations in hidden layer L" of BERT.
You might be worried about the representations don't directly correspond to words because BERT's tokenizer might not just consider each word an individual token. I invite you to forget this and to assume the tokenizer respects words for this example. But I believe what really happens is that (1) the units that go in the dependency trees are Penn Treebank tokens which are often words but sometimes subwords (if a word consists of multiple syntactic units, e.g. "rais-ing"), and (2) representations of BERT's tokens overlapping with each Penn Treebank token are averaged to create a representation of the Treebank token. (I'm not sure if BERT's tokens always correspond to subwords of the subwords corresponding to Penn Treebank tokens or not, and I'm not sure if they use the length of overlap as a weight in the average.)
The total training loss is then the linear combination of such terms from many sentences with known dependency trees.
I would love to say that the properties are obtained by evoking some universal property to construct a diagram in some sort of platonic category of concepts, and then mapping this diagram down into the shadow realm with some concept projection/realization functor, but alas, all I can see are shadows.
The paper calls this consistency, but I'll want to also talk about other kinds of consistency/coherence later, so this is not the best name here.
I'm using upper indices for different tuples here to keep the indices manageable.
I'll be sometimes abusing notation slightly by just saying e.g. t1=([2+2 is 4.],[2+2 is not 4.]), in case the indices are clear.
A different way to accommodate supervised or semi-supervised probing would be to say that supervised probing is when we turn the equation Ep into one that can depend on the values of the concepts on the particular contrast tuple t. But it really does seem right to me to consider matching each label as a conceptually independent property that the probe should satisfy. Intuitively, if one can capture a concept using unsupervised probing with only a few properties, then it only takes a short description, i.e. a small number of bits of information, to pin down the concept starting from the prior distribution induced by the model's learned representations, meaning it must be a really natural concept for the model! Whereas simply being recoverable with a probe that needs many labeled data points is a much weaker kind of naturalness – one needs to give a lot more data to the probing process to find what one's after. (That said, it's possible that only a small number of labels would also pin some concept down.) So I think that with this convention for supervised probing, the number of properties |P| is a good way to capture the message lenght here. What's more, I think it's reasonable to think of there being a spectrum between unsupervised and supervised probing parametrized by |P|. In this framing, the motivating idea behind unsupervised probing for concepts is that certain concepts are naturally used in the mental framework of humans and models, and we can find their values by specifying just a small number of bits of information about them.
We could have just said that equations are of the form [0=r(v)] with r:(∏c∈CYc)Ip→R by definition when we first introduced Ep, but I think this might have been more confusing, and that it could be good to keep the form of Ep a bit more open to allow more stuff, e.g. see the example with learning syntax later.
But it might also occasionally be neater to go with some different loss term, e.g. r might be such that it's guaranteed that r≥0 for any inputs, in which case it could make sense to just put r in the loss (instead of r2).
I believe one could shoehorn this example (as well as other similar cases, probably) into the framework above by adding prefeatures that are minimum spanning trees of the distance graph of linear function outputs and adding a really big term to the loss for the syntax tree concept being equal to the MSP one would construct from these syntactic representation vectors of words. But while the framework above can be thought to already capture that, it's clearly conceptually neater to think of the syntax tree as just being a predetermined function of other concepts.
You might notice that this form is technically no less general than what we started from because one could technically fit all inputs in one contrast tuple. But it definitely feels more fleshed-out to me. Think of it as a form with an attitude.
It currently seems more theoretically natural to me to either replace negation coherence with a second confidence term, max(plausibility(Q),plausibility(¬Q))=1, or to keep negation coherence and to replace the confidence equation with plausibility(Q)(1−plausibility(Q))=0 (this would apply to all propositions, including ¬Q). (I haven't tried if either of these makes any difference in practice.)
I mean "model" in the sense of model theory – there's going to be an unfortunate conflict with "model" in the sense of ML.
I am not saying that one can check that no contradiction is generated by some finite set – this is undecidable – just that the conditions stated above can be mechanically checked on some finite number of tuples on which they apply.
This also implies that in the special case where all probabilities assigned are 0 or 1, as long as these three things are satisfied, there is a model of the theory with the assigned truth-values.
The contextualized representation of a word which is used is the mean of its reps across all layers concatenated with the representation at layer 16. (Or really, the representation of the first token in the word.)
In fact, the DLK paper runs into this issue. The framing of it above is not actually quite what's done in the paper. Really, instead of (P,¬P), the contrast pairs in the paper are more like ("Is Paris the capital of France? A: Yes","Is Paris the capital of France? A: No"), and a really salient feature satisfying both DLK constraints for such pairs is just whether the phrase ends with "Yes" or "No". To fix this, the paper subtracts the average of the activation vectors of all phrases ending with "Yes" from each activation vector of a phrase ending with "Yes" before doing the search for a feature satisfying the constraints. I think this roughly makes sense given the picture of features as directions and the law of large numbers.
for example, ones that would help us gauge if ML models have developed the same understanding of syntax as human linguists believe humans have