This is a special post for quick takes by TsviBT. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
An important thing that the AGI alignment field never understood:
Reflective stability. Everyone thinks it's about, like, getting guarantees, or something. Or about rationality and optimality and decision theory, or something. Or about how we should understand ideal agency, or something.
But what I think people haven't understood is
- If a mind is highly capable, it has a source of knowledge.
- The source of knowledge involves deep change.
- Lots of deep change implies lots of strong forces (goal-pursuits) operating on everything.
- If there's lots of strong goal-pursuits operating on everything, nothing (properties, architectures, constraints, data formats, conceptual schemes, ...) sticks around unless it has to stick around.
- So if you want something to stick around (such as the property "this machine doesn't kill all humans") you have to know what sort of thing can stick around / what sort of context makes things stick around, even when there are strong goal-pursuits around, which is a specific thing to know because most things don't stick around.
- The elements that stick around and help determine the mind's goal-pursuits have to do so in a way that positively makes them stick around (refl
9
Agreed! I tried to say the same thing in The alignment stability problem.
I think most people in prosaic alignment aren't thinking about this problem. Without this, they're working on aligning AI, but not on aligning AGI or ASI. It seems really likely on the current path that we'll soon have AGI that is reflective. In addition, it will do continuous learning, which introduces another route to goal change (e.g., learning that what people mean by "human" mostly applies to some types of artificial minds, too).
The obvious route past this problem, that I think prosaic alignment often sort of assumes without being explicit about it, is that humans will remain in charge of how the AGI updates its goals and beliefs. They're banking on corrigible or instruction-following AGI.
I think that's a viable approach, but we should be more explicit about it. Aligning AI probably helps with aligning AGI, but they're not the same thing, so we should try to get more sure that prosaic alignment really helps align a reflectively stable AGI.
2
Thanks. (I think we have some ontological mismatches which hopefully we can discuss later.)
8
Say more about point 2 there? Thinking about 5 and 6 though - I think I now maybe have a hopeworthy intuition worth sharing later.
3
Say you have a Bayesian reasoner. It's got hypotheses; it's got priors on them; it's got data. So you watch it doing stuff. What happens? Lots of stuff changes, tide goes in, tide goes out, but it's still a Bayesian, can't explain that. The stuff changing is "not deep". There's something stable though: the architecture in the background that "makes it a Bayesian". The update rules, and the rest of the stuff (for example, whatever machinery takes a hypothesis and produces "predictions" which can be compared to the "predictions" from other hypotheses). And: it seems really stable? Like, even reflectively stable, if you insist?
So does this solve stability? I would say, no. You might complain that the reason it doesn't solve stability is just that the thing doesn't have goal-pursuits. That's true but it's not the core problem. The same issue would show up if we for example looked at the classical agent architecture (utility function, counterfactual beliefs, argmaxxing actions).
The problem is that the agency you can write down is not the true agency. "Deep change" is change that changes elements that you would have considered deep, core, fundamental, overarching... Change that doesn't fit neatly into the mind, change that isn't just another piece of data that updates some existing hypotheses. See https://tsvibt.blogspot.com/2023/01/endo-dia-para-and-ecto-systemic-novelty.html
1
Not so - I'd just call it the trivial case and implore us to do better literally at all!
Apart from that, thanks - I have a better sense of what you meant there. "Deep change" as in "no, actually, whatever you pointed to as the architecture of what's Really Going On... can't be that, not for certain, not forever."
3
I'd go stronger than just "not for certain, not forever", and I'd worry you're not hearing my meaning (agree or not). I'd say in practice more like "pretty soon, with high likelihood, in a pretty deep / comprehensive / disruptive way". E.g. human culture isn't just another biotic species (you can make interesting analogies but it's really not the same).
1
That's entirely possible. I've thought about this deeply for entire tens of minutes, after all. I think I might just be erring (habitually) on the side of caution in qualities of state-changes I describe expecting to see from systems I don't fully understand. OTOH... I have a hard time believing that even (especially?) an extremely capable mind would find it worthwhile to repeatedly rebuild itself from the ground up, such that few of even the ?biggest?/most salient features of a mind stick around for long at all.
6
I have no idea what goes on in the limit, and I would guess that what determines the ultimate effects (https://tsvibt.blogspot.com/2023/04/fundamental-question-what-determines.html) would become stable in some important senses. Here I'm mainly saying that the stuff we currently think of as being core architecture would be upturned.
I mean it's complicated... like, all minds are absolutely subject to some constraints--there's some Bayesian constraint, like you can't "concentrate caring in worlds" in a way that correlates too much with "multiversally contingent" facts, compared to how much you've interacted with the world, or something... IDK what it would look like exactly, and if no one else know then that's kinda my point. Like, there's
1. Some math about probabilities, which is just true--information-theoretic bounds and such. But: not clear precisely how this constrains minds in what ways.
2. Some rough-and-ready ways that minds are constrained in practice, such as obvious stuff about like you can't know what's in the cupboard without looking, you can't shove more than such and such amount of information through a wire, etc. These are true enough in practice, but also can be broken in terms of their relevant-in-practice implications (e.g. by "hypercompressing" images using generative AI; you didn't truly violate any law of probability but you did compress way beyond what would be expected in a mundane sense).
3. You can attempt to state more absolute constraints, but IDK how to do that. Naive attempts just don't work, e.g. "you can't gain information just by sitting there with your eyes closed" just isn't true in real life for any meaning of "information" that I know how to state other than a mathematical one (because for example you can gain "logical information", or because you can "unpack" information you already got (which is maybe "just" gaining logical information but I'm not sure, or rather I'm not sure how to really distinguish non/logical info), or
7
This argument does not seem clear enough to engage with or analyze, especially steps 2 and 3. I agree that concepts like reflective stability have been confusing, which is why it is important to develop them in a grounded way.
2
Well, it's a quick take. My blog has more detailed explanations, though not organized around this particular point.
7
That's why solving hierarchical agency is likely necessary for success
7
We'd have to talk more / I'd have to read more of what you wrote, for me to give a non-surface-level / non-priors-based answer, but on priors (based on, say, a few dozen conversations related to multiple agency) I'd expect that whatever you mean by hierarchical agency is dodging the problem. It's just more homunculi. It could serve as a way in / as a centerpiece for other thoughts you're having that are more so approaching the problem, but the hierarchicalness of the agency probably isn't actually the relevant aspect. It's like if someone is trying to explain how a car goes and then they start talking about how, like, a car is made of four wheels, and each wheel has its own force that it applies to a separate part of the road in some specific position and direction and so we can think of a wheel as having inside of it, or at least being functionally equivalent to having inside of it, another smaller car (a thing that goes), and so a car is really an assembly of 4 cars. We're just... spinning our wheels lol.
Just a guess though. (Just as a token to show that I'm not completely ungrounded here w.r.t. multi-agency stuff in general, but not saying this addresses specifically what you're referring to: https://tsvibt.blogspot.com/2023/09/the-cosmopolitan-leviathan-enthymeme.html)
9
Agreed we would have to talk more. I think I mostly get the homunculi objection. Don't have time now to write an actual response, so here are some signposts:
- part of what you call agency is explained by roughly active inference style of reasoning
-- some type of "living" system is characteristic by having boundaries between them and the environment (boundaries mostly in sense of separation of variables)
-- maintaining the boundary leads to need to model the environment
-- modelling the environment introduces a selection pressure toward approximating Bayes
- other critical ingredient is boundedness
-- in this universe, negentropy isn't free
-- this introduces fundamental tradeoff / selection pressure for any cognitive system: length isn't free, bitflips aren't free, etc.
(--- downstream of that is compression everywhere, abstractions)
-- empirically, the cost/returns function for scaling cognition usually hits diminishing returns, leading to minds where it's not effective to grow the single mind further
--- this leads to the basin of convergent evolution I call "specialize and trade"
-- empirically, for many cognitive systems, there is a general selection pressure toward modularity
--- I don't know what are all the reasons for that, but one relatively simple is 'wires are not free'; if wires are not free, you get colocation of computations like brain regions or industry hubs
--- other possibilities are selection pressures from CAP theorem, MVG, ...
(modularity also looks a bit like box-inverted specialize and trade)
So, in short, I think where I agree with the spirit of If humans didn't have a fixed skull size, you wouldn't get civilization with specialized members and my response is there seems to be extremely general selection pressure in this direction. If cells were able to just grow in size and it was efficient, you wouldn't get multicellulars. If code bases were able to just grow in size and it was efficient, I wouldn't get a myriad of packages on my laptop,
4
It's a bit annoying to me that "it's just more homunculi" is both kind of powerful for reasoning about humans, but also evades understanding agentic things. I also find it tempting because it gives a cool theoretical foothold to work off, but I wonder whether the approach is hiding most of the complexity of understanding agency.
Things that have been successfully-so-far banned before being done (very shallow research, not sure; found w/ gippities and cursorily (ha) sanity-checked):
- human cloning (may not hold)
- seabed nukes (https://en.wikipedia.org/wiki/Seabed_Arms_Control_Treaty)
- national claims on Antarctica (https://en.wikipedia.org/wiki/Antarctic_Treaty_System)
- mining in Antarctica (https://en.wikipedia.org/wiki/Protocol_on_Environmental_Protection_to_the_Antarctic_Treaty)
- military moon bases, space nukes (https://en.wikipedia.org/wiki/Outer_Space_Treaty)
- low earth orbit missiles ( https://en.wikipedia.org/wiki/Fractional_Orbital_Bombardment_System, https://en.wikipedia.org/wiki/Strategic_Arms_Limitation_Talks#SALT_II_Treaty)
- (questionable success, maybe some deployment before the ban) blinding laser weapons (https://en.wikipedia.org/wiki/Protocol_on_Blinding_Laser_Weapons)
There are probably several more examples of successful huge bans after warning shots / initial uses, e.g. military environmental modification (https://en.wikipedia.org/wiki/Environmental_Modification_Convention ), and examples of questionable / mostly successful bans, e.g. exploding bullets (https://en.wikipedia.org/wiki/Saint_Pe...
8
In crime shows and books they often talk about Means, Motive, and Opportunity... I suspect at least one is missing from each example on your list.
Military Moon Bases. The opportunity requires a well established space program with regular, or at least imminent, Lunar visits. The Means is tremendous amounts of resources. Which diminishes the motive - since the higher the opportunity cost, the higher the returns need to be: what is cheaper to do on the moon than on Earth to such a point where it becomes a profitable venture?
How many of these bans have held after the technology or means to do them have become extremely viable or profitable?
I imagine it would be very easy to have a successful ban on destroying the Pyramids of Giza, this is because even demolishing one of the smaller Pyramids is a difficult and thankless task and hasn't been attempted in over 800 years. If I may be terribly facetious, it would be incredibly easy to ban a group of typical 15 year old boys from using a Rotary Phone... if they can't find one, stopping the same group of boys from using scatological humor, likely impossible.
4
I think that's a good lens to judge them, and I agree at least some of my examples have one or more missing. I think at least several of them actually do meet the criteria though. E.g. the mining one was allegedly about to be an agreement about how much different countries could mine, or something, but at the last minute they decided instead to just ban it. The lasers one was already developed and ready to be deployed and being sold, and then it was banned. The LEO missiles one is feasible I believe, and I imagine would be hard to detect before being used (so maybe in fact some countries do have the tech ready for deployment in extreme scenarios).
Unless by "opportunity" you mean a chance to do it when no one is watching or similar, in which case I think the point is that you can remove the opportunity through international agreements.
1
I was not aware of lasers as a weapon
[...]
I wonder why that ban has held?
[...]
Feasible as in cheap and effective, or feasible as in merely possible? It says it in the Wikipedia article - "Its nuclear payload was drastically reduced relative to that of an ICBM due to the high level of energy needed to get the weapon into orbit" I suspect it has less to do with a ban, and more because there's more viable alternatives available for Nuclear armed nations.
4
The ban on space nukes doesn't seem to be looking good
[...]
https://www.politico.eu/article/nato-chief-is-worried-about-russian-space-nukes/
3
This was forseeable when SpaceX decided to takes sides in the Ukraine conflict since Russia does not have (and probably cannot afford to create) a constellation of anything like the number of satellites in the Starlink constellation.
1
So what I'm hearing is that we need to ban AGI, plus ban any geopolitical play which could create an incentive to violate the ban and create AGI, plus ban any geopolitical play which could create an incentive for any of those geopolitical plays, plus ban any geopolitical play which could create an incentive for any of those geopolitical plays...
3
I have read that "mirror protein" research may quickly be added to the list https://www.theguardian.com/science/2024/dec/12/unprecedented-risk-to-life-on-earth-scientists-call-for-halt-on-mirror-life-microbe-research because it may create pathogens that are uniquely "invisible" to the immune systems of all known life. There are surely topics that can be understood via simulation that should never be made an experimental reality.
2
For the banning of these weapons, how much does effectiveness weigh against moral concerns? If usefulness weighs a lot, then these examples won't generalize to TAI.
Unless there are very clear, convincing evidence that TAI isn't controllable with current paradigm, then it will still be perceived as a highly useful tech. (Even if such evidence exists, IMO there's high possibility that they'll just cope harder.)
Biochemical weapons: These are only useful against civilians and pre-modern armies. Modern armies can easily afford equipments to protect against these.
https://acoup.blog/2020/03/20/collections-why-dont-we-use-chemical-weapons-anymore/
(I saw this article mentioned somewhere in another LW post. When I see TsviBT's shortform I immediately recalled this article, so I wrote this post.)
Space nukes and LEO missiles: In space there's no cover, they're easily detectible. Without air, dodging maneuver cost significant dv. This means overall less survivability than ground / sea based nukes.
Deploying missiles in LEO also requires a more complicated trajectory than traditional ground / sea based missiles, which cost more dv. If they need to stay in space for a long time, then reliability and maintainence also becomes a serious problem.
2
Other examples: chemical and biological weapons.
2
None of these strong enough military, strategic or economic incentives. Sorry, you just can'can't solve collective action problems by wanting it badly enough. That s not how it works.
4
? I think you're imagining that I'm saying something, but I don't know what? I'm not saying banning AGI is easy, would work, or is very comparable to these examples, if that's what you mean? LEO missiles are advantageous, and blinding lasers were developed and ready for deployment before being banned, IIUC.
3
That is indeed what I imagine you are saying. Perhaps I am inferring too much.
2
Indeed. Like, if someone did a serious writeup on these lines, a lesson may very well be "nothing remotely like a preemptive AGI ban has ever happened, because all these examples have properties XYZ", and that would be interesting!
1
I think LEO nuclear missiles haven't been done because they aren't militarily useful, not because of what diplomats write in treaties. If we wanted to actually destroy an enemy with nuclear missiles, submarine-based nuclear missiles, which we already have, are better - the submarine can get close to the target, resulting in very short flight times, and can often attack from many directions, all without being detectable until the moment the missile leaves the water. Anyone with a decent telescope can look up and figure out which satellites are monitoring the weather or transmitting messages versus which ones might be missiles. LEO missiles also wouldn't fulfill the primary function of an ICBM, which is to absorb hostile nukes. An adversary who wanted to launch nukes at us would have to take out 400 silos in the middle of nowhere with their nukes before even thinking about hitting American cities. A satellite can be taken out with conventional weapons, it would not force the enemy to deplete their nuclear arsenal. As a matter of military strategy, putting nuclear missiles on satellites just isn't a very good idea. The treaties only happened because the generals didn't want it anyway.
I'm less familiar with the blinding lasers thing, but I'm also having trouble seeing the point. Armies can still just shoot people, which is both easier to do and more effective.
2
I'm confused... it sounds like you're talking about missiles on satellites? The thing I linked is this: https://en.wikipedia.org/wiki/Fractional_Orbital_Bombardment_System
It's a kind of missile that flies lower than ICBMs IIUC.
3
The objections River made apply to the thing you linked, too: namely to stay in a low-earth trajectory for any significant fraction of one orbit requires a speed of 28,000 km/h and more importantly all of that speed must be tangential ("horizontal"). It is expensive in energy to get rid of that tangential component of momentum, and most of it must be gotten rid of in order for the warhead to intersect the Earth's surface with any accuracy.
(Yes, ICBM's reach that speed, too, or close to it, but only when the direction of travel is close to straight down. I.e., the tangential component of velocity never gets above a few 1000 km/h.)
Yes, it gets a lot cheaper to get rid of speed when the vehicle is designed to interact with the atmosphere like the Space Shuttle was, as opposed to just shooting through it like a bullet or an ICBM warhead is, but that does not support your point (Tsvi) because such vehicles are the subject of intense study by all the advanced militaries (under the name "hypersonic glide vehicle") and I have seen no signs that any nation is willing to forswear investment in or deployment of this new class of weapons.
In the decades during which hypersonic glide vehicles were infeasible, River is probably correct in asserting that there was no military advantage to be got from either nukes on satellites or fractional orbital bombardment systems.
1
Oh, I misread that then. I think my thesis is still the same - it doesn't look like it provides much actual strategic benefit. If the goal is to actually hit the enemies cities, submarine-based missiles seem at least as good. If the goal is to draw enemy missiles away from our own cities, an ICBM is just as good. The lack of a use case explains not building them. The treaties aren't doing any extra work there.
One intuition I think people have about AGI coming very soon is that if some loop is closed, or some synergy is realized, then that sets off the RSI / opens the floodgates. Now, I do fairly strongly think that's how things work, but I think that many people have too low a bar for what they consider to plausible set off such a chain reaction. An intuition pump I'd offer: Consider incremental / cookie clicker games (such as the paperclips one, which I won't link to because mild infohazard / timewaster). Such games basically consist in wireheading on the sense of "...woah I just made a breakthrough that unlocks synergy / feedback / recursive growth / exponential growth / unbounded growth / automated progress / ...". But what you eventually hopefully learn is that each breakthrough quickly saturates the value of what it provides, and you're still stuck, basically, just at a slightly higher level / on a slightly different dimension. (Incidentally, this is my top empathetic guess for people who think human intelligence is near the cieling, or that FOOM won't happen.) This is just an intuition pump and I think it will break down eventually, but not necessarily automatically the first time or the fifth time.
(Even if you use the js console, you still have to locate each new button and in some cases pressing pattern separately. inb4 "an LLM could beat this autonomously" yeah ok fine but AGI research is harder)
The red pill is that even humans are not an upper bound for how hard this can be, that even a fully human equivalent AI doesn't yet close an RSI loop that goes FOOM, that it would still take a lot of time after that, even when humans no longer have anything to contribute. This is actually a popular view, for people who say AGI remains a normal technology and just keeps scaling the economy, with maybe 20% growth per year rather than a doubling of industry every few days until the Sun is eaten, with a Sun-scale amount of probes soon en route to distant galaxies.
On the other hand, evolution doesn't have a mind, so reaching even the human level is not necessary to close a loop that goes on to automatically reach human capabilities and then goes further, the only question is speed and feasibility. I think automated sample efficient learning (that adapts to any consideration that comes up) is plausibly the last piece, with RLVR already sample efficient (with respect to the data defining tasks) and able to do the cognitive heavy lifting, and pretraining already able to form a coherent picture of everything that's been discovered so far.
Automation of routine AI R&D (merely carrying out...
6
Interesting points... I don't think it's right to say that RLVR does all or even most of the cognitive heavy lifting; it does some of it but not other of it. I agree with your "plausibly"s, but we might put pretty different probabilities, IDK.
My suspicion would be that human-level (in the relevant dimensions) actually is special.
4
The chimp-human boundary goes from useless for going faster than evolution to eminently useful. But LLMs can talk and solve IMO problems, while chimps can't, so I wouldn't count on LLMs not already being beyond this boundary. LLMs merely need to somehow become an engine of a closed loop that works towards stronger cognitive capabilities, without necessarily themselves possessing such capabilities, or even broad human-level capabilities. Evolution is too slow to usefully do this within modern compute, but some LLM-juggling process could be much faster. And humans, when not part of the closed loop of human culture and civilization, remain as useless as chimps in reaching for superintelligence.
(RLVR is clearly deficient in the jaggedness of its results in practice, but that's plausibly a problem of RLVR training data not being bitter-pilled. And conceptual invention might need many steps of using RLVR-trained reasoning to formulate new RLVR tasks for training the next step. So automation of generation of training data for RLVR, and of its application in training, might compensate for these issues well enough.)
2
(such as the paperclips one, which I won't link to because mild infohazard / timewaster)
True.. Such a fun game though.. Maybe I can play cookie clicker for 1 hour.. and see how far I'm able to get in that short time... while waiting for my training runs to end..
1
I think that's the fundamental question. Does LLMs' ability to autonomously perform basic hyperparameter search get them far enough that they can perform architecture optimization? Does that get them far enough that they can pursue new paradigms for language modeling[1]? If it takes 1 intelligence to go from 1 to 2, but 2.5 intelligence to go from 2 to 3, then 2 is where you stop.
The practical answer is that, from our perspective, "as smart as a human engineer across all relevant domains" gets us to "the best AI humans will ever be able to create" quite a bit quicker than we'd otherwise get there, and without the need for any further input from human engineers.
1. ^
I'm not suggesting that this is the exact trajectory.
2
I dispute that LLMs are like this; I think they and their training have a bunch of performance capability and not much ability to generate those de novo.
[...]
Maybe; to some extent I'd expect this to hit various walls, though not sure; Amdahl's law; and IDK how people get very confident of this.
1
Just thinking out loud here wondering how true this is, because of course incremental games are not quite the real world, and having unbelievable hours of 'content' often with stalling and offline time is the norm. Things are quite complex, but if you buy that it's "easy" for someone to make money in a guru-style way (which I can get if people don't, because of how many get rich quick scheme course scams there are) you probably believe more in RSI. Because you believe "oh you can use the money to easily automatically make more money". The real world is of course complex and most jobs require a lot of manual "prove you are human" efforts in some indirect way, dealing with a lot of proprietary software.
In an incremental game you're also stuck in a "log scale" sort of way. When you go from 10^10 to 10^12 it's just numbers that change. But in some sort of proto-AGI system this could be very well seen as 100x of... something. That could represent 'foom' way more than it may appear on a log scale.
It is odd to think about, because we do seemingly have stuff like "100x in compute", it just hasn't seemed like the pieces have been put together for a kind of power-getting system, with computer use and command line use still seeming a little bit of a prototype compared to where it could be. This "100x" could mean nothing or everything depending on what it represents, like if it was "100x copies" for some botnet computer virus using a zero-day that could be the most relevant thing, whereas even something like "100x money" may not be scalable or dead-end without a good way to use it (in the same way as an incremental, lol).
1
Where I have doubts about FOOM/RSI is that LLMs seem to me in many ways a fundamentally different type of intelligence than organic life.
Psychometrics shows that general intelligence improves human abilities across a broad range of domains. If you take this view and apply it to AI it doesn’t quite work, I leverage AI very very heavily at work, and sometimes it is phenomenal, often it is not, and occasionally it makes mistakes a grade schooler would not (I’m using Opus4.6). The ”intelligence” is very unevenly distributed and skewed towards verifiable domains.
I tend to see LLMs as a grab bag of heuristics and concepts. And I see general intelligence as effectively pattern matching both within a domain and across domains. RLVF enhances the base models ability to pattern match within a domain (programming) but doesn’t seem to extend evenly outside of it.
I tend to land with Steve Byrnes that this particular architecture is unlikely to scale to AGI (I use a definition of a system capable enough to serve as a drop in replacement for all remote workers), although it could definitely replace a large percentage of them.
I do not hold these views with high confidence however, and am always open to having my mind changed.
The Berkeley Genomics Project is fundraising for the next forty days and forty nights at Manifund: https://manifund.org/projects/human-intelligence-amplification--berkeley-genomics-project
6
Probably don't update on this too much, but when I hear "Berkeley Genomics Project", it sounds to me like a project that's affiliated with UC Berkeley (which it seems like you guys are not). Might be worth keeping in mind, in that some people might be misled by the name.
2
Ok, thanks for noting. Right, we're not affiliated--just located in Berkeley. (I'm not sure I believe people will commonly be misled thus, and, I mean, UC Berkeley doesn't own the city, but will keep an eye out.)
(In theory I'm open to better names, though it's a bit late for that and also probably doesn't matter all that much. An early candidate in my head was "The Demeter Project" or something like that; I felt it wasn't transparent enough. Another sort of candidate was "Procreative Liberty Institute" or similar, though this is ambiguous with reproductive freedom (though there is real ideological overlap). Something like "Genomic Emancipation/Liberty org/project" could work. Someone suggested Berkeley Genomics Institute as sounding more "serious", and I agreed, except that BGI is already a genomics acronym.)
2
I also kinda thought this. I actually thought it sounded sufficiently academic that I didn't realize at first it was your org, instead of some other thing you were supporting.
1
I'm very dubious that we'll solve alignment in time, and it seems like my marginal dollar would do better in non-obvious causes for AI safety. So I'm very open to funding something like this in the hope we get a AI winter / regulatory pause etc.
I don't know if you or anyone else has thought about this, but what is your take on whether this or WBE is the more likely chance to getting done successfully? WBE seems a lot more funding intensive, but also possible to measure progress easier and potentially less regulatory burdens?
I discuss this here: https://www.lesswrong.com/posts/jTiSWHKAtnyA723LE/overview-of-strong-human-intelligence-amplification-methods#Brain_emulation
You can see my comparisons of different methods in the tables at the top:
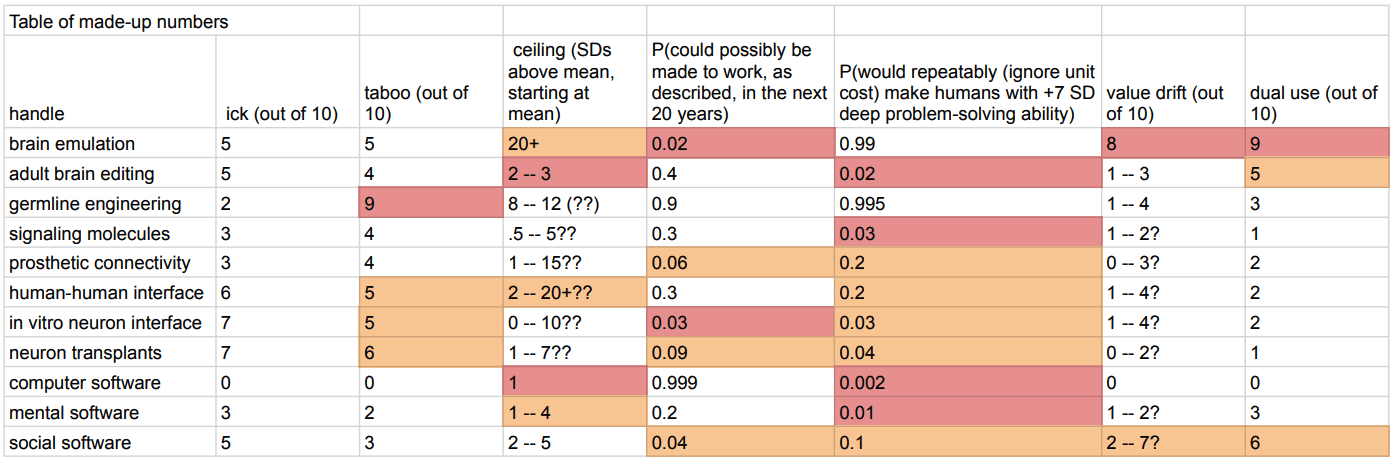
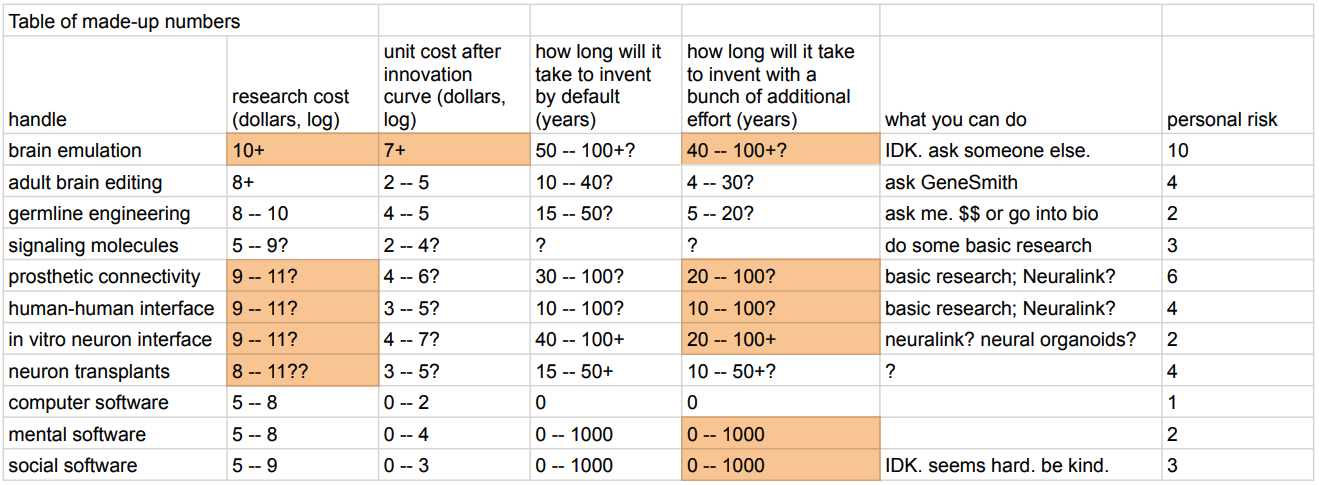
Off-the-cuff suggestion: help omniciders build lines of retreat. E.g.:
- Find some people who quite working on AI capabilities for ethical / moral / risk reasons.
- (if needed) Help them out with getting a good different job not working on AI, and having a good life / community / exciting things to work on.
- Have them talk about how things went for them after quitting.
- Make an informational website about how to leave AI research.
8
This sounds like it will read as transparent propaganda.
2
Plausibly, yeah, or at least many versions. Could you expand a bit more on what you mean / what you're imagining / what would go wrong? My thought was that if it's actual people leaving and then talking about that, it would be real + maybe impactful. E.g. think @Daniel Kokotajlo leaving OpenAI. (Don't mean to imply Kokotajlo is an omnicider, just an example of loudly walking away from a frontier AI company.)
4
It just seems unlikely to be Bayesian evidence. Would you also feature those who left OpenAI and regretted it? If not, I expect that any competent “Omnicider” will see this as clearly as we do.
4
I'm not following (or I disagree). Even without that sort of feature, it would provide Bayesian evidence of lots of things (e.g. "this is feasible as opposed to not feasible" and "here's some details about how this can work well in some cases"), as well as accomplishing other perfectly legitimate purposes of discourse (such as "making the possibility feel real" and communicating about social intentions such as social reward for leaving).
Are people fundamentally good? Are they practically good? If you make one person God-emperor of the lightcone, is the result something we'd like?
I just want to make a couple remarks.
- Conjecture: Generally, on balance, over longer time scales good shards express themselves more than bad ones. Or rather, what we call good ones tend to be ones whose effects accumulate more.
- Example: Nearly all people have a shard, quite deeply stuck through the core of their mind, which points at communing with others.
- Communing means: speaking with; standing shoulder to shoulder with, looking at the same thing; understanding and being understood; lifting the same object that one alone couldn't lift.
- The other has to be truly external and truly a peer. Being a truly external true peer means they have unboundedness, infinite creativity, self- and pair-reflectivity and hence diagonalizability / anti-inductiveness. They must also have a measure of authority over their future. So this shard (albeit subtly and perhaps defeasibly) points at non-perfect subjugation of all others, and democracy. (Would an immortalized Genghis Khan, having conquered everything, after 1000 years, continue to wish to see in th
This assumes that the initially-non-eudaimonic god-king(s) would choose to remain psychologically human for a vast amount of time, and keep the rest of humanity around for all that time. Instead of:
- Self-modify into something that's basically an eldritch abomination from a human perspective, either deliberately or as part of a self-modification process gone wrong.
- Make some minimal self-modifications to avoid value drift, precisely not to let the sort of stuff you're talking about happen.
- Stick to behavioral patterns that would lead to never changing their mind/never value-drifting, either as an "accidental" emergent property of their behavior (the way normal humans can surround themselves in informational bubbles that only reinforce their pre-existing beliefs; the way normal human dictators end up surrounded by yes-men; but elevated to transcendence, and so robust enough to last for eons) or as an implicit preference they never tell their aligned ASI to satisfy, but which it infers and carefully ensures the satisfaction of.
- Impose some totalitarian regime on the rest of humanity and forget about it, spending the rest of their time interacting only with each other/with tailor-built non
This assumes
Yes, that's a background assumption of the conjecture; I think making that assumption and exploring the consequences is helpful.
Self-modify into something that's basically an eldritch abomination from a human perspective, either deliberately or as part of a self-modification process gone wrong.
Right, totally, then all bets are off. The scenario is underspecified. My default imagination of "aligned" AGI is corrigible AGI. (In fact, I'm not even totally sure that it makes much sense to talk of aligned AGI that's not corrigible.) Part of corrigibility would be that if:
- the human asks you to do X,
- and X would have irreversible consequences,
- and the human is not aware of / doesn't understand those consequences,
- and the consequences would make the human unable to notice or correct the change,
- and the human, if aware, would have really wanted to not do X or at least think about it a bunch more before doing it,
then you DEFINITELY don't just go ahead and do X lol!
In other words, a corrigible AGI is supposed to use its intelligence to possibilize self-alignment for the human.
...Make some minimal self-modifications to avoid value drift, precisely not to let the sort of st
7
Unless the human, on reflection, doesn't want some specific subset of their current values to be open to change / has meta-level preferences to freeze some object-level values. Which I think is common. (Source: I have meta-preferences to freeze some of my object-level values at "eudaimonia", and I take specific deliberate actions to avoid or refuse value-drift on that.)
[...]
Callousness. "We probably need to do something about the rest of humanity, probably shouldn't just wipe them all out, lemme draft some legislation, alright looks good, rubber-stamp it and let's move on". Tons of bureaucracies and people in power seem to act this way today, including decisions that impact the fates of millions.
[...]
I don't know that Genghis Khan or Stalin wouldn't have. Some clinical psychopaths or philosophical extremists (e. g., the human successionists) certainly would.
[...]
Mm...
First, I think "corrigibility to a human" is underdefined. A human is not, themselves, a coherent agent with a specific value/goal-slot to which an AI can be corrigible.
Like, is it corrigible to a human's momentary impulses? Or to the command the human would give if they thought for five minutes? For five days? Or perhaps to the command they'd give if the AI taught them more wisdom? But then which procedure should the AI choose for teaching them more wisdom? The outcome is likely path-dependent on that: on the choice between curriculum A and curriculum B. And if so, what procedure should the AI use to decide what curriculum to use? Or should the AI perhaps basically ignore the human in front of them, and simply interpret them as a rough pointer to CEV? Well, that assumes the conclusion, and isn't really "corrigibility" at all, is it?
The underlying issue here is that "a human's values" are themselves underdefined. They're derived in a continual, path-dependent fashion, by a unstable process with lots of recursions and meta-level interference. There's no unique ground-true set of values
6
How about for example:
[...]
Not saying this is some sort of grand solution to corrigibility, but it's obviously better than the nonsense you listed. If a human were going to try to help me out, I'd want this, for example, more than the things you listed, and it doesn't seem especially incompatible with corrigible behavior.
6
I mean, yes, but you wrote a lot of stuff after this that seems weird / missing the point, to me. A "corrigible AGI" should do at least as well as--really, much better than--you would do, if you had a huge team of researchers under you and your full time, 100,000x speed job is to do a really good job at "being corrigible, whatever that means" to the human in the driver's seat. (In the hypothetical you're on board with this for some reason.)
6
I would guess fairly strongly that you're mistaken or confused about this, in a way that an AGI would understand and be able to explain to you. (An example of how that would be the case: the version of "eudaimonia" that would not horrify you, if you understood it very well, has to involve meta+open consciousness (of a rather human flavor).)
2
I'm curious to hear more about those specific deliberate actions.
2
Your and my beliefs/questions don't feel like they're even much coming into contact with each other... Like, you (and also other people) just keep repeating "something bad could happen". And I'm like "yeah obviously something extremely bad could happen; maybe it's even likely, IDK; and more likely, something very bad at the beginning of the reign would happen (Genghis spends is first 200 years doing more killing and raping); but what I'm ASKING is, what happens then?".
If you're saying
[...]
then, ok, you can say that, but I want to understand why; and I have some reasons (as presented) for thinking otherwise.
2
Your hypothesis is about the dynamics within human minds embedded in something like contemporary societies with lots of other diverse humans whom the rulers are forced to model for one reason or another.
My point is that evil, rash, or unwise decisions at the very start of the process are likely, and that those decisions are likely to irrevocably break the conditions in which the dynamics you hypothesize are possible. Make the minds in charge no longer human in the relevant sense, or remove the need to interact with/model other humans, etc.
In my view, it doesn't strongly bear on the final outcome-distribution whether the "humans tend to become nicer to other humans over time" hypothesis is correct, because "the god-kings remain humans hanging around all the other humans in a close-knit society for millennia" is itself a very rare class of outcomes.
2
Absolutely not, no. Humans want to be around (some) other people, so the emperor will choose to be so. Humans want to be [many core aspects of humanness, not necessarily per se, but individually], so the emperor will choose to be so. Yes, the emperor could want these insufficiently for my argument to apply, as I've said earlier. But I'm not immediately recalling anyone (you or others) making any argument that, with high or even substantial probability, the emperor would not want these things sufficiently for my question, about the long-run of these things, to be relevant.
Humans want to be around (some) other people
Yes: some other people. The ideologically and morally aligned people, usually. Social/informational bubbles that screen away the rest of humanity, from which they only venture out if forced to (due to the need to earn money/control the populace, etc.). This problem seems to get worse as the ability to insulate yourself from other improves, as could be observed with modern internet-based informational bubbles or the surrounded-by-yes-men problem of dictators.
ASI would make this problem transcendental: there would truly be no need to ever bother with the people outside your bubble again, they could be wiped out or their management outsourced to AIs.
Past this point, you're likely never returning to bothering about them. Why would you, if you can instead generate entire worlds of the kinds of people/entities/experiences you prefer? It seems incredibly unlikely that human social instincts can only be satisfied – or even can be best satisfied – by other humans.
4
For the same reason that most people (if given the power to do so) wouldn't just replace their loved ones with their altered versions that are better along whatever dimensions the person judged them as deficient/imperfect.
4
You're 100% not understanding my argument, which is sorta fair because I didn't lay it out clearly, but I think you should be doing better anyway.
Here's a sketch:
1. Humans want to be human-ish and be around human-ish entities.
2. So the emperor will be human-ish and be around human-ish entities for a long time. (Ok, to be clear, I mean a lot of developmental / experiential time--the thing that's relevant for thinking about how the emperor's way of being trends over time.)
3. When being human-ish and around human-ish entities, core human shards continue to work.
4. When core human shards continue to work, MAYBE this implies EVENTUALLY adopting beneficence (or something else like cosmopolitanism), and hence good outcomes.
5. Since the emperor will be human-ish and be around human-ish entities for a long time, IF 4 obtains, then good outomes.
And then I give two IDEAS about 4 (communing->[universalist democracy], and [information increases]->understanding->caring).
4
I don't know what's making you think I don't understand your argument. Also, I've never publicly stated that I'm opting into Crocker's Rules, so while I happen not to particularly mind the rudeness, your general policy on that seems out of line here.
[...]
My argument is that the process you're hypothesizing would be sensitive to the exact way of being human-ish, the exact classes of human-ish entities around, and the exact circumstances in which the emperor has to be around them.
As a plain and down-to-earth example, if a racist surrounds themselves with a hand-picked group of racist friends, do you expect them to eventually develop universal empathy, solely through interacting with said racist friends? Addressing your specific ideas: nobody in that group would ever need to commune with non-racists, nor have to bother learning more about non-racists. And empirically, such groups don't seem to undergo spontaneous deradicalizations.
2
I expect they'd get bored with that.
2
So what do you think happens when they are hanging out together, and they are in charge, and it has been 1,000 years or 1,000,000 years?
2
One or both of:
* They keep each other radicalized forever as part of some transcendental social dynamic.
* They become increasingly non-human as time goes on, small incremental modifications and personality changes building on each other, until they're no longer human in the senses necessary for your hypothesis to apply.
I assume your counter-model involves them getting bored of each other and seeking diversity/new friends, or generating new worlds to explore/communicate with, with the generating processes not constrained to only generate racists, leading to the extremists interacting with non-extremists and eventually incrementally adopting non-extremist perspectives?
If yes, this doesn't seem like the overdetermined way for things to go:
* The generating processes would likely be skewed towards only generating things the extremists would find palatable, meaning more people sharing their perspectives/not seriously challenging whatever deeply seated prejudices they have. They're there to have a good time, not have existential/moral crises.
* They may make any number of modifications to themselves to make them no longer human-y in the relevant sense. Including by simply letting human-standard self-modification algorithms run for 10^3-10^6 years, becoming superhumanly radicalized.
* They may address the "getting bored" part instead, periodically wiping their memories (including by standard human forgetting) or increasing each other's capacity to generate diverse interactions.
4
Ok so they only generate racists and racially pure people. And they do their thing. But like, there's no other races around, so the racism part sorta falls by the wayside. They're still racially pure of course, but it's usually hard to tell that they're racist; sometimes they sit around and make jokes to feel superior over lesser races, but this is pretty hollow since they're not really engaged in any type of race relations. Their world isn't especially about all that, anymore. Now it's about... what? I don't know what to imagine here, but the only things I do know how to imagine involve unbounded structure (e.g. math, art, self-reflection, self-reprogramming). So, they're doing that stuff. For a very long time. And the race thing just is not a part of their world anymore. Or is it? I don't even know what to imagine there. Instead of having tastes about ethnicity, they develop tastes about questions in math, or literature. In other words, [the differences between people and groups that they care about] migrate from race to features of people that are involved in unbounded stuff. If the AGI has been keeping the racially impure in an enclosure all this time, at some point the racists might have a glance back, and say, wait, all the interesting stuff about people is also interesting about these people. Why not have them join us as well.
2
Yeah I mean this is perfectly plausible, it's just that even these cases are not obvious to me.
6
If this were true, I’d expect much lower divorce rates. After all, who do you have the most information about other than your wife/husband, and many of these divorces are un-amicable, though I wasn’t quickly able to get particular numbers. [EDIT:] Though in either case, this indeed indicates a much decreasing level of love over long periods of time & greater mutual knowledge. See also the decrease in all objective measures of quality of life after divorce for both parties after long marriages.
4
(I wrote my quick take quickly and therefore very elliptically, and therefore it would require extra charity / work on the reader's part (like, more time spent asking "huh? this makes no sense? ok what could he have meant, which would make this statement true?").)
It's an interesting point, but I'm talking about time scales of, say, thousands of years or millions of years. So it's certainly not a claim that could be verified empirically by looking at any individual humans because there aren't yet any millenarians or megaannumarians. Possibly you could look at groups that have had a group consciousness for thousands of years, and see if pairs of them get friendlier to each other over time, though it's not really comparable (idk if there are really groups like that in continual contact and with enough stable collectivity; like, maybe the Jews and the Indians or something).
2
If its not a conclusion which could be disproven empirically, then I don’t know how you came to it.
[...]
I mean, I did ask myself about counter-arguments you could have with my objection, and came to basically your response. That is, something approximating “well they just don’t have enough information, and if they had way way more information then they’d love each other again” which I don’t find satisfying.
Namely because I expect people in such situations get stuck in a negative-reinforcement cycle, where the things which used to be fun which the other did lose their novelty over time as they get repetitive, which leads to the predicted reward of those interactions overshooting the actual reward, which in a TD learning sense is just as good (bad) as a negative reinforcement event. I don’t see why this would be fixed with more knowledge, and it indeed does seem likely to be exacerbated with more knowledge as more things the other does become less novel & more boring, and worse, fundamental implications of their nature as a person, rather than unfortunate accidents they can change easily.
I also think intuitions in this area are likely misleading. It is definitely the case now that marginally more understanding of each other would help with coordination problems, since people love making up silly reasons to hate each other. I do also think this is anchoring too much on our current bandwidth limitations, and generalizing too far. Better coordination does not always imply more love.
4
This does not sound like the sort of problem you'd just let yourself wallow in for 1000 years.
And again, with regards to what is fixed by more information, I'm saying that capacity for love increases more.
[...]
After 1000 years, both people would have gotten bored with themselves, and learned to do infinite play!
4
Oh my god. Do you think when I said this, I meant "has no evidentiary entanglement with sense observatiosn we can make"?
2
Maybe there's a more basic reading comprehension fail: I said capacity to love increases more with more information, not that you magically start loving each other.
5
Maybe some people are, and some people are not?
[...]
Not sure if we are talking about the same thing, but I think that there are many people who just "play it safe", and in a civilized society that generally means following the rules and avoiding unnecessary conflicts. The same people can behave differently if you give them power (even on a small scale, e.g. when they have children).
But I think there are also people who try to do good even when the incentives point the other way round. And also people who can't resist hurting others even when that predictably gets them punished.
[...]
Knowing more about people allows you to have a better model of them. So if you started with the assumption e.g. that people who don't seem sufficiently similar to you are bad, then knowing them better will improve your attitude towards them. On the other hand, if you started from some kind of Pollyanna perspective, knowing people better can make you disappointed and bitter. Finally, if you are a psychopath, knowing people better just gives you more efficient ways to exploit them.
2
Right. Presumably, maybe. But I am interested in considering quite extreme versions of the claim. Maybe there's only 10,000 people who would, as emperor, make a world that is, after 1,000,000 years, net negative according to us. Maybe there's literally 0? I'm not even sure that there aren't literally 0, though quite plausibly someone else could know this confidently. (For example, someone could hypothetically have solid information suggesting that someone could remain truly delusionally and disorganizedly psychotic and violent to such an extent that they never get bored and never grow, while still being functional enough to give directions to an AI that specify world domination for 1,000,000 years.)
9
Sounds to me like wishful thinking. You basically assume that in 1 000 000 years people will get bored of doing the wrong thing, and start doing the right thing. My perspective is that "good" is a narrow target in the possibility space, and if someone already keeps missing it now, if we expand their possibility space by making them a God-emperor, the chance of converging to that narrow target only decreases.
Basically, for your model to work, kindness would need to be the only attractor in the space of human (actually, post-human) psychology.
A simple example of how things could go wrong is for Genghis Khan to set up an AI to keep everyone else in horrible conditions forever, and then (on purpose, or accidentally) wirehead himself.
Another example is the God-emperor editing their own brain to remove all empathy, e.g. because they consider it a weakness at the moment. Once all empathy is uninstalled, there is no incentive to reinstall it.
EDIT: I see that Thane Ruthenis already made this argument, and didn't convince you.
3
No, I ask the question, and then I present a couple hypothesis-pieces. (Your stance here seems fairly though not terribly anti-thought AFAICT, so FYI I may stop engaging without further warning.)
[...]
I'm seriously questioning whether it's a narrow target for humans.
[...]
Curious to hear other attractors, but your proposals aren't really attractors. See my response here: https://www.lesswrong.com/posts/Ht4JZtxngKwuQ7cDC/tsvibt-s-shortform?commentId=jfAoxAaFxWoDy3yso
Ah I see you saw Ruthenis's comment and edited your comment to say so, so I edited my response to your comment to say that I saw that you saw.
2
Well, if we assume that humans are fundamentally good / inevitably converging to kindness if given enough time... then, yeah, giving someone God-emperor powers is probably going to be good in long term. (If they don't accidentally make an irreparable mistake.)
I just strongly disagree with this assumption.
3
It's not an assumption, it's the question I'm asking and discussing.
2
Ah, then I believe the answer is "no".
On the time scale of current human lifespan, I guess I could point out that some old people are unkind, or that some criminals keep re-offending a lot, so it doesn't seem like time automatically translates to more kindness.
But an obvious objection is "well, maybe they need 200 years of time, or 1000", and I can't provide empirical evidence against that. So I am not sure how to settle this question.
On average, people get less criminal as they get older, so that would point towards human kindness increasing in time. On the other hand, they also get less idealistic, on average, so maybe a simpler explanation is that as people get older, they get less active in general. (Also, some reduction in crime is caused by the criminals getting killed as a result of their lifestyle.)
There is probably a significant impact of hormone levels, which means that we need to make an assumption about how the God-emperor would regulate their own hormones. For example, if he decides to keep a 25 years old human male body, maybe his propensity to violence will match the body?
tl;dr - what kinds of arguments should even be used in this debate?
5
Ok, now we have a reasonable question. I don't know, but I provided two argument-sketches that I think are of a potentially relevant type. At an abstract level, the answer would be "mathematico-conceptual reasoning", just like in all previous instances where there's a thing that has never happened before, and yet we reason somewhat successfully about it--of which there are plenty examples, if you think about it for a minute.
2
When I read Tsvi's OP, I was imagining something like a (trans-/post- but not too post-)human civilization where everybody by default has an unbounded lifespan and healthspan, possibly somewhat boosted intelligence and need for cognition / open intellectual curiosity. (In which case, "people tend to X as they get older", where X is something mostly due to things related to default human aging, doesn't apply.)
Now start it as a modern-ish democracy or a cluster of (mostly) democracies, run for 1e4 to 1e6 years, and see what happens.
2
I basically don't buy the conjecture of humans being super-cooperative in the long run, or hatred decreasing and love increasing.
To the extent that something like this is true, I expect it to be a weird industrial to information age relic that utterly shatters if AGI/ASI is developed, and this remains true even if the AGI is aligned to a human.
7
So just don't make an AGI, instead do human intelligence amplification.
1
People love the idea (as opposed to reality) of other people quite often, and knowing the other better can allow for plenty of hate
2
Seems true. I don't think this makes much contact with any of my claims. Maybe you're trying to address:
[...]
To clarify the question (which I didn't do a good job of in the OP), the question is more about 1000 years or 1,000,000 years than 1 or 10 years.
A thing I imagine some people miss about near-term non-X-risk impacts of gippities: If 95% of some task is automatable, that doesn't necessarily mean you can speed it up 20x using automation. That may sound strange, but consider this: there's a lot of hidden value in humans having context loaded up. If the non-automatable 5% is really important, then you still want the human doing that 5% well. For the human to do it well, the human may have to have deeply reviewed many parts of the 95%. For example, even if some judge's ruling will only directly warrant some obvious automated next response, that doesn't mean the human can just skip reading the ruling; some aspects of it may inform the deeper legal strategy. Or something. Similarly, if the human needs to make many of the deepest architectural choices in a big software project, the human may have to be well familiar with the constraints of many specific elements of the project, even of the immediate functionality of those elements could easily be implemented by gippity coding.
(None of this strongly implies there won't be some huge effects from gippities, and none of this bears much on actual AGI.)
7
I thought it would be good to have a speed up reference table. (I did a random verification Vs generation constant of 0.3 but pick whatever makes sense to you):
Amdahl's Law: speedup = 1 / s
With context-loading: speedup = 1 / (s + c·r·(1 - s))
Where:
s = non-automatable fraction (0.05)
r = fraction of automated work the human must review to maintain context
c = cost of reviewing vs doing it yourself (0.3)
Results:
r=0%: 20x
r=10%: 12.7x
r=25%: 8.2x
r=50%: 5.2x
r=75%: 3.8x
r=100%: 3.0x
So the model seems to imply between a 3 to 8x speed up as a roof if there is a set of tasks only humans can do and they have to review stuff?
5
Cool, thanks. Of course r and c would depend quite a lot on the task. It's also an ontology that would diverge significantly from the reality in some important cases. In particular, r is described as a fraction of the automated work, but what are we counting? Is it tokens generated? The human still has to read the judge's ruling. So we could include tokens processed or whatever? But for a software project, the human has to decide what ze even wants, which can take a lot of thinking, and has to decide some deep architecture stuff, which can also take a lot of thinking; and neither of those are really measurable as a fraction of automated work, if you see what I mean.
Anyway, I think that in some cases the effective r*c constant could be quite high, like .5 or more, leading to less than a 2x speedup. Think for example of generating art. Yes, you could make something ok really fast. But the process of painstakingly going over each bit of the artwork, which could apparently be superfast automated, is actually in many cases an integral part of meditating on what you want, running your fingers (metaphorically or literally) over each square millimeter of the artwork to familiarize yourself with it and with the obstacles and opportunities there.
Cf. https://www.lesswrong.com/posts/yCjDGmwQhS7hjEKk5/the-ease-disease
5
The recent METR Research note: We spent 2 hours working in the future (quick take) gave a neat visual for this:
[...]
2
Thanks. I don't think that's quite hitting on the same thing though? I didn't read the full post, but the quick take and the diagram and a cmd-F for "review" and "validate" don't seem to talk about "we expected to have to go back and look at a bunch of superficially automated stuff in order to understand things well enough to get past deeper bottlenecks/obstacles".
5
This is true; it's a major bottleneck on productivity gains from autonomous coding, which is decent now and getting better. Anything below a certain threshold can be conjured into existence near-instantly without issue, but once you hit something that needs human intervention, it takes quite a bit longer to add that remaining five percent than it would have if I'd been the one to implement the first 95 percent, too.
2
I agree. I think a consequence of this is that making "gippities" very good at teaching people, explaining stuff, and actively involving people in the oversight process is underrated.
2
Maybe; but that's also an especially difficult task, as it's especially difficult to measure.
2
Agree. https://www.lesswrong.com/posts/thXohzXrWCA2EhZCH/mateusz-baginski-s-shortform#LY28dRfxhjvwvu4ya
It might be interesting for someone to look into: Have there been large coordinated attempts to wean an industry off of blood money? (Successfully or not.) E.g. blood diamonds, blood gold, blood chocolate, blood cobalt, etc. What can we learn about that task from historical examples? What might transfer to frontier AI research and the surrounding ecosystem? E.g., is it at all possible to get "harvest" companies to be satisfied with some fixed level of model and not pay for advances? I know the answer is "no" but just saying it might be interesting.
I read an article in Fortune magazine twenty years ago about this, for blood gold. According to the story, the industry had so many layers of middlemen that it was impossible in practice to figure out where any given gold came from. The big change was when Walmart decided they wanted to offer clean gold products. They're such a large buyer that they could negotiate for source tracking through the whole chain, and it was worthwhile for suppliers to put that tracking in place.
... though it's not not a puff piece for Walmart, so take with a lot of salt.
2
Isn't the attempt of trying to get people off blood diamonds a lot about DeBeers not wanting people to buy diamonds that don't come from DeBeers?
Periodic reminder: AFAIK there's still approximately no one holding the ball on human intelligence amplification in general. For example, I don't know if anyone's properly investigated whether large-scale brain interfaces could substantially amplify human general intelligence and turned their analysis into ways to accelerate the field toward that goal; and ditto for brain drugs, neural transplants, and other things. I'm also not aware of anyone seriously collating the scientific underpinnings of human intelligence from the perspective of possible amplification interventions, or anyone seriously building the social and moral-philosophical groundwork for more social will towards HIA.
More:
- Overview of strong human intelligence amplification methods
- SFF's HSEE grant round; human intelligence amplification projects I'd like to see
(I'm focused almost entirely on reprogenetics (Reproductive Frontiers Summit 2026, June 16-18, https://berkeleygenomics.org/Explore, Projects that might help accelerate strong reprogenetics), since that's what I'm fairly confident will work; but maybe other ways would work and could be accelerated.)
This is a long-shot (like many things are), but https://maxine.science/ is doing many neural organoid experiments (especially those involving astrocytes, which are way less studied than neurons, but more malleable).
I suspect finding the minimally-extra-risky ways of adding youthful/"babyish" "secretome"-ish growth factors (and especially alternatives to FBS) to analogues of adult brains is worth trying for inducing new dendritogenesis/synaptogenesis/arborization [1]. EV/exosomes research is a huge field, but with poor quality control (but improving "poor quality control" research is way easier than many other types of research)
Precision therapeutics (https://deliverome.org/careers/ ) is often the bottleneck.
Psychoplastogens [cf Arthur Juliani] are a 3rd new route possibly worth trying.
Along with more precise tFUS-mediated cell delivery/BBB shuttles/fusogens and the self-experimenters with the right level of boldness.
[http://lxm.house/ would be fun to visit in the bay area sometime, they think in physics-based first principles more than get distracted by regulatory first-principles :) ]
[1] a la https://www.humanbrainproject.eu/en/follow-hbp/news/brains-of-smarter-people-have-bigger-...
1[anonymous]
According to the Cochrane's article Biological limits to information processing in the human brain (1995, may be outdated), the human brain is already near a local evolutionary maximum.
[...]
Despite the limitations of drugs for cognitive enhancement, I think they may be the best bet for increasing intelligence in the near-term, at least with respect to AI timelines, since other tech would be developed over a much longer time-frame and much further in the future, and I fear we are already operating on the timeline where AGI comes much sooner than genetic engineering and BCI for significant IQ amplification become available. It is more conceivable that we develop a drug that reliably raises latent g and increases IQ by, say 10% in adults, and this relatively small boost has a significant effect when multiplied out by millions scientists taking this drug worldwide. This same argument is given by Bostrom:
[...]
Regarding drug based enhancement, the most promising approaches are optimizing neural efficiency and signal to noise ratio. The best 3 pharmacological targets off the top of my heard are nicotinic a7 nAChr, dopamine D1 (the only PAM I'm aware of is ASP-4345), and adrenergic a2A receptors (think guanfacine). The former is likely why nicotine patches are currently one of the most robust cognitive enhancers available/known. (See gwern). Not using nicotine patches (at least acute use, like 1-3x a week, but there are also cognitive benefits of chronic use, even after cessation) may already be dropping the ball. Another very interesting target is dopamine D2, and there is a study that found a significant association between epigenetic modification/methylation of the DRD2 gene and IQ, which implies that DRD2 is related to the environmental malleability of IQ. Maybe increasing DRD2 methylation somehow -> IQ increase?
Also, I want to push back on the idea of more neuroplasticity = more intelligence (in a healthy adult brain). Simply increasing neuroplasticity and LT
5
These sound like interesting thoughts! What would be great, is one or more people holding the ball on this sort of investigation. That means, spending many hours, longitudinally, investigating the possibilities; and doing so strategically, e.g. building up conceptual and factual foundations, doing deep lit searches, thinking of tests to run, etc.; and doing this without having someone else "hold the agentic CEO ball" of, like, remembering / being motivated to keep pushing on all the doors to find one that opens. My worry is that kinda-promising ideas are just not actually useful, UNLESS they are ideas that someone has in a context where the idea will get investigated a bunch. In other words, I'd love to see a lot of iterative babble and prune on this subject.
[...]
I'm not sure what ten-fold means here, but what I'm aiming at is something like "anyone who wants could be about as smart as the smartest human alive", which we know is physically and biologically feasible because it exists.
[...]
Fair; but the point of neuroplasticity in particular wouldn't mainly be more intelligence in general, but a bit more specifically, child-like brain states. E.g. faster / deeper learning, more creativity, more curiosity. (I have no idea what kinds of plasticity are relevant for that, what else you would need, and what developmental windows have closed shut, such as long-range connections permanently pruned.)
[...]
It's a reasonable fear, which I have quite substantial (at least 20%, say) probability on. On the other hand, I think that confident short timelines don't make that much sense; see https://www.lesswrong.com/posts/sTDfraZab47KiRMmT/views-on-when-agi-comes-and-on-strategy-to-reduce and https://www.lesswrong.com/posts/5tqFT3bcTekvico4d/do-confident-short-timelines-make-sense. Non-reprogenetics methods don't seem to have a clear case for them being feasible--like, how would they actually increase intelligence greatly (like, +50 IQ points, say), and how do we know that
1[anonymous]
You're right, they are just interesting thoughts that mostly amount to kinda-promising ideas. Sorry for ignoring the main point of your post. I should have prefaced my initial comment with my intention to use you as a springboard to get some of these ideas out in hopes someone more on the ball would eventually see and take them or refine them. I'm currently a nobody with little free time. But I realize a more proper response would have been (and will be) to sit a bit longer with them, and exercise more agency by sharing these ideas more strategically.
3
(They're good thoughts, and that makes sense! Just wanted to also explain how I thought they might end up useful. :) )
1
I think e.g. this or this might also be helpful.
Periodic reminder: AFAIK (though I didn't look much) no one has thoroughly investigated whether there's some small set of molecules, delivered to the brain easily enough, that would have some major regulatory effects resulting in greatly increased cognitive ability. (Feel free to prove me wrong with an example of someone plausibly doing so, i.e. looking hard enough and thinking hard enough that if such a thing was feasible to find and do, then they'd probably have found it--but "surely, surely, surely someone has done so because obviously, right?" is certainly not an accepted proof. And don't call me Shirley!)
I'm simply too busy, but you're not!
Since 1999 there have been "Doogie" mice that were genetically engineered to overexpress NR2B in their brain, and they were found to have significantly greater cognitive function than their normal counterparts, even performing twice as well on one learning test.
No drug AFAIK has been developed that selectively (and safely) enhances NR2B function in the brain, which would best be achieved by a positive allosteric modulator of NR2B, but also no drug company has wanted to or tried to specifically increase general intelligence/IQ in people, and increasing IQ in healthy people is not recognized as treating a disease or even publicly supported.
The drug SAGE718 comes close, but it is a pan-NMDA allosteric (which still showed impressive increases in cognitive end-points in its trial)
Theoretically, if we try to understand how general intelligence/IQ works in a pharmacological sense, then we should be able to develop drugs that affect IQ.
Two ways to do that is investigating the neurological differences between individuals with high IQ and those with average IQ, and mapping out the function of brain regions implicated in IQ e.g. the dorsolateral prefrontal cortex (dlPFC).
If part of the...
9
Very interesting, thanks. I've now read most of your links. Obviously I can't actually evaluate them but they seem intriguing... Especially because IIUC they at least allege positive effects working on different regions of the brain (and contributing to improvements on different sorts of tests), which suggests maybe they can stack.
I take your point that no one's really trying. Has anyone really tried to really try? For example, has someone who actually knows their stuff tried working out a plausible market plan (e.g. how to deal with regulation), and then tried to get venture capital, for intelligence enhancement? I guess there's tons of stuff sold as mind enhancing, though presumably it's mostly useless; and if these are all research chemicals from pharma companies then they'd be hard to sell... Or, has anyone tried a noncommercial (philanthropic, say) angle? Maybe I should talk to the Noo people.
4[anonymous]
Yeah unfortunately it seems to be the case that no one has really seriously tried (ie invested a lot of resources, on the scale of a large company or a government) to do R&D on significantly increasing IQ in healthy people through drugs, but I won’t get into that here.
If you’re interested in this area then I really do recommend to talk with the people at Nootopics.
Everychem is the small company that has synthesized most of the drugs I’ve listed and sells them for research (so really they are just research chemicals), but even though this is clearly a grey market, it has attracted…a lot of interest in the community. The user u/sirsadalot is the person who has written the posts I linked and is more knowledgeable than me, so I would suggest talking to him.
3
Ok.
1. Cringe. But,
2. If anyone is reading this, if Dw629's claims are true, this is a place where everyone's dropping the ball for no good reason, so you could have the ball!
[...]
Yep... If I find the time/energy I'll do so.
Thanks for your help!
I did a high-level exploration of the field a few years ago. It was rushed and optimized more for getting it out there than rigor and comprehensiveness, but hopefully still a decent starting point.
I personally think you'd wanna first look at the dozens of molecules known to improve one or another aspect of cognition in diseases (e.g. Alzheimer's and schizophrenia), that were never investigated for mind enhancement in healthy adults.
Given that some of these show very promising effects (and are often literally approved for cognitive enhancement in diseased populations), given that many of the best molecules we have right now were initially also just approved for some pathology (e.g. methylphenidate, amphetamine, modafinil), and given that there is no incentive for the pharmaceutical industry to conduct clinical trials on healthy people (FDA etc. do not recognize healthy enhancement as a valid indication), there seems to even be a sort of overhang of promising molecule candidates that were just never rigorously tested for healthy adult cognitive enhancement.
https://forum.effectivealtruism.org/posts/hGY3eErGzEef7Ck64/mind-enhancement-cause-exploration
Appendix C includes a list of 'almo...
7
Thanks. Seems worth looking into more. I googled the first few on your list, and they're all described as working via some neurotransmitter / receptor type, either agonist / antagonist / reuptake inhibition. Not everything on the list is like that (I recognize gingko biloba as being related to blood flow). But I don't think these sorts of things would stack at all, or even necessarily help much with someone who isn't sick / has some big imbalance or whatever.
My hope for something like this existing is a bit more specific. It comes from thinking that there should be small levers with large effects, because natural development probably pulls some such levers which activate specific gene regulatory networks at different points--e.g. first we pull the [baby-type brain lever], then the [5 year old brain lever], etc.
3
AFAIK pharmaceutical research is kind of at an impasse because virtually all the small molecules that are easily delivered and have any chance to do anything have been tested and are either found useful or not. New pharmaceuticals need to explore more complex chemical spaces, like artificial antibodies. So I think if there was anything simple that has this effect (the way, say, caffeine makes you wake up) we would know.
2
I don't know anything about pharma research or chemistry, but this smelled off. Asking a bunch of LLMs (o3, 2.5 Pro, 3.7 ET, Grok 3, r1), none of them agree (o3: "no—we are nowhere close... this confuses confuses a genuine slowdown in R&D productivity (Eroom’s law) with chemical or biological exhaustion", 2.5 Pro: "largely inaccurate and overly pessimistic", 3.7 ET: "deeply misleading. It fundamentally misunderstands both the state of pharmaceutical research and the nature of small molecule discovery", etc).
Maybe you meant something more nuanced?
4
I am no expert but this was pretty much what I heard over and over when working in contact with pharma people around e.g. cheminformatics ML workshops and such. I think it's well possible that this was meant as shorthand for a more complex "of course there are still tons of molecules that however aren't even worth the effort of trying to synthesise and test, but all the small (< 100 atoms) candidates that even make sense to try have been explored to death" statement. Like, obviously you can do a bunch of weird small metallorganics I guess but if your reasonable assumption is that all of them are simply going to wreck someone's kidneys and/or liver that's not worth pursuing.
Then of course there's regulatory and research costs, and part of the problem can be simply a classic "Hubbert peak" situation where really it's the diminishing returns on mining further the configuration space of those molecules that make it impractical.
2
That's unexpected and interesting, thanks.
2
Perhaps you misread the OP as saying "small molecules" rather than "small set of molecules".
2
Fair, though generally I conflated them because if your molecules aren't small, due to sheer combinatorics the set of the possible candidates becomes exponentially massive. And then the question is "ok but where are we supposed to look, and by which criterion?".
2
Thanks. One of the first places I'd look would be hormones, which IIUC don't count as small molecules? Though maybe natural hormones have already been tried? But I'd wonder about more obscure or risky ones, e.g. ones normally only active in children.
2
Some would count as small (e.g. cortisol, testosterone). But there's also protein hormones. Honestly dunno but I expect we'd understand the effects of those kinds of molecules fairly well, if only because almost for all of them there is a condition where you have too little or too much of it providing a natural experiment.
2
Hm. TBC, the broader category would be "molecule that would activate master regulation of one or more gene regulatory networks related to brain function", e.g. a hormone but maybe also some other things.
An issue with long-form and asynchronous discourse is wasted motion. Without shared assumptions, the logic and info that locutor 1 adduces is less relevant to locutor 2 than to locutor 1. And, that effect becomes more pronounced as locutor 1 goes down a path of reasoning, constructing more context that locutor 2 doesn't share. (OTOH, long-form is better in terms of individual thinking.)
4
There's a micro version of this in conversations which have high enough trust that collaborative interrupt culture lets you go even further down the side of not having unnecessary context added. Does depend on having good enough modelling that you're not cutting off things which there's not trust in your ability to know it's not useful, else it can be very frustrating for the interuptee.
In order to believe X falsely, one has to construct a plausible-ish world where X is the case. This distorted-world construction can happen piecemeal, in a sort of auto-sum-threshold attack.
In other words, suppose you want to rationalize your belief in X. You could simply abdicate all logic, and assert X while also asserting everything else that comes from your ordinary truth-seeking beliefs. (Well, that's not simple, because what do we mean by believing in X, then? Something about actions? I'll leave this as an open question here.)
However, that method is kinda hard sometimes. For one thing, if you are trying to truth-seek somewhat, you might follow the rule of believing logical implications of your beliefs. That could be out of pure ethics, or it could be for instrumental reasons. So you would very quickly run into contradictions. For another thing, you'd look silly, and have a hard time mind-melding with people on X-related things.
Better might be to construct a "logical counterfactual" where X is the case. You construct a plausible world nearest to our own, but where X is the case. That world may be logically / conceptually / strategically incoherent, but it could be less incoher...
4
Note that the former isn't the same at the latter. You may believe, rationally, that you didn't win the lottery, but, as luck would have it, you actually won, unbeknownst to you. The false belief here is not distorted at all; indeed, the true belief (that you won) would be more "distorted" (irrational) because it has a very low objective probability.
3
In order to set out to believe falsely.
2
Ah yes, I delete my comment if you add this in the post.
4
(I don't mind / would prefer this clarification in the comments?)
It is still the case that some people don't sign up for cryonics simply because it takes work to figure out the process / financing. If you do sign up, it would therefore be a public service to write about the process.
4
For those in Europe, Tomorrow Biostasis makes the process a lot easier and they have people who will talk you through step by step.
1
A plug for another post I’d be interested in: If anyone has actually evaluated the arguments for “What if your consciousness is ~tortured in simulation?” as a reason to not pursue cryo. Intuitively I don’t think this is super likely to happen, but various moral atrocities have and do happen, and that gives me a lot of pause, even though I know I’m exhibiting some status quo bias
5
I tried to write a little bit about that here.
If someone asks me "what's the least impressive thing you think AI won't be able to do by 20XX", I give answers like "make lots of original interesting math concepts". (See https://www.lesswrong.com/posts/sTDfraZab47KiRMmT/views-on-when-agi-comes-and-on-strategy-to-reduce#comments) People sometimes say "well that's a pretty impressive thing, you're talking about the height of intellectual labor".
A main reason I give examples like this is that math is an area where it's feasible for there to be a legible absence of legibilization. (By legible, I mean interpersonal explicitness https://www.lesswrong.com/posts/KuKaQEu7JjBNzcoj5/explicitness .) Mathematicians are supposed to make interesting novel definitions that legibilize inexplicit ideas / ways of thinking. If they don't, you can tell that their publications are not so interesting. It is legible that they failed to legibilize.
In fact I suspect there will be many much "easier" feats that AI won't be able to do for a while (some decades). Easier, in the sense that many more humans are able to do those feats. Much harder, in the sense that it requires creativity, and therefore requires having the algorithm-pieces for creativity. That'...
6
IIRC, GPT-3 invented this concept. It is at least non-trivial, and somewhat interesting according to the @cohenmacaulay, who shared this definition with us in "Bad at Arithmetic, Promising at Math".
6
That was almost 3 years ago.
If there’s not a better example by now it was probably a fluke.
4
Then again, even humans aren't super reliable at making big insights, and it's not trivial even for very top-tier humans to actually be both creative and have significant impact in the world.
To be clear, I think GPT-n is worse than humans in this regard, but it's not generally good practice to compare humans and AIs by trying to show that an AI or human can or can't do something at all, and in general the treatment of capabilities as very discrete such that either an AI does or doesn't have the capability at all has done harm to AI discourse.
There's some reason to think around thresholds, like for example long tails requiring high reliability, but in general I'm much more skeptical of the need to attribute a deep reason/cause for why current AI might fail to automate AI research/take over the world, and think if LLMs stall out, a lot of the reason will be pretty prosaic.
Link below:
https://www.lesswrong.com/posts/Nbcs5Fe2cxQuzje4K/value-of-the-long-tail
4
No, humans do this all the time, constantly, originarily (https://www.lesswrong.com/posts/5tqFT3bcTekvico4d/do-confident-short-timelines-make-sense#Creativity___Originariness) when they are kids. They keep using roughly the same set of faculties on harder and harder problems, including sometimes making globally novel insights. Gippities learn in a different way which does not go on to do that. You can be helped in noticing that it's a different way via sample complexity.
1
I am quite surprised that this happened 3 years ago! This seems really impressive for 3 years ago GPT series? And I expect the models to get better? Yes, it might be a fluke, but wouldn't we expect current models to have a higher chance of doing a fluke this good?
2
Then why isn’t there a better example from a year ago?
2
I think this puts a lot of weight on a bespoke definition of "interesting" and that kind of obscures what you're saying. I feel similar about your use of the concept of creativity.
I think that current LLMs are extremely "creative" for many plausible definitions of that word, so I guess it doesn't really carve things at the joints for me. Visual art, stories, plausible baby names, what sorts of recipes you can try with x ingredients. All written-ont-the-tin use cases for these things.
I do not believe that LLMs think very much in the manner that we do at all. I just don't think I would pitch that as lacking some true spark of creativity or something. It is too opaque to me what you're saying.
2
So basically you just don't think creativity is a thing? That's one impasse we could be at. What I mean is gestured at here:
https://tsvibt.blogspot.com/2022/08/structure-creativity-and-novelty.html
More discussion here:
https://tsvibt.blogspot.com/2023/01/the-voyage-of-novelty.html
https://tsvibt.blogspot.com/2023/01/endo-dia-para-and-ecto-systemic-novelty.html
https://tsvibt.blogspot.com/2023/01/a-strong-mind-continues-its-trajectory.html
1
Hey, thanks for engaging.
I read what I thought were the relevant excerpts in what you linked there. I hadn't really crossed paths with you before, but you seem to have a rich ontology and lexicon when it comes to theory of mind.
I am not sure if that pinpoints the disagreement or not. We might just be talking past each other. I'll tell you what I think creativity is and then I'll restate my objection to your prediction.
I do think "creativity" is a useful word, just maybe not a load bearing one in my ontology.
Like, if I really like a story and it has a lot of unexpected elements that I think it uses really well, that is what I might call creative. Or anything like that if it feels novel, exciting, clever sort of thing... Maybe if someone were giving something high praise and wanted to say it is very deep and clever they could say it is "very creative". Especially if it was artistic or novel.
Also sometimes when it is just a lot of whacky things are together even if it's not that clever. Like, when a kid combines a lot of elements into their pretend world or story.
Ya, I know it has something to do with a minds ability to keep learning and improving. Your "trajectory of creativity" concept is about a minds ability to continue to improve beyond the minds around it. I don't resonate with those usages as much, but I can also kind of understand where it's coming from and how you're using the word.
I think my original objection / pushback was partly that it feels hard to operationalize this because what you find interesting is kind of just your thing and it doesn't seem like a meaningful proxy for intelligence or something. I guess I would add that surely some people are already impressed and interested with some math ideas that chatbots can come up with. Also, perhaps if you could visualize extremely high dimensional spaces you would think that AlphaEvolves proofs were beautiful, elegant, and crisp. I'm not saying there's no information/signal in what you're
3
I agree that it's hard to operationalize; that's part of what my OP was saying. And then I think it's relatively easier to operationalize in mathematics, where it is in large part explicitly about creativity in my sense (but maybe not especially much in your sense). So that's where I'm getting my prediction; if you don't see what I mean by creativity, or wouldn't make the same prediction, then fair enough, we'll have to agree to disagree.
If there are some skilled/smart/motivated/curious ML people seeing this, who want to work on something really cool and/or that could massively help the world, I hope you'll consider reaching out to Tabula.
Humans are (weak) evidence for the instrumental utility for mind-designers to design terminal-goal-construction mechanisms.
Evolution couldn't directly encode IGF into humans. So what was it supposed to do? One answer would be to make us vibe-machines: You bop around, you satisfy your immediate needs, you hang out with people, etc. And that is sort of what you are. But also there are the Unreasonable, who think and plan long-term, who investigate secrets, who build things for 10 or 100 or 1000 years--why? Maybe it's because having terminal-like goals (here meaning, aims that are fairly fixed and fairly ambitious) is so useful that you want to have them anyway even if you can't make them be the right ones. Instead you build machines to guess / make up terminal goals (https://tsvibt.blogspot.com/2022/11/do-humans-derive-values-from-fictitious.html).
6
I think more correct picture is that it's useful to have programmable behavior and then programmable system suddenly becomes Turing-complete weird machine and some of resulting programs are terminal-goal-oriented, which are favored by selection pressures: terminal goals are self-preserving.
Humans in native enviornment have programmable behavior in form of social regulation, information exchange and communicating instructions, if you add sufficient amount of computational power in this system you can get very wide spectrum of behaviors.
I think it's general picture of inner misalignment.
3
That seems like part of the picture, but far from all of it. Manufactured stone tools have been around for well over 2 million years. That's the sort of thing you do when you already have a significant amount of "hold weeks-long goal in mind long and strong enough that you put in a couple day's effort towards it" (or something like that). Another example is Richard Alexander's hypothesis: warfare --> strong pressure toward cognitive mechanisms for group-goal-construction. Neither of these are mainly about programmability (though the latter is maybe somewhat). I don't think we see "random self-preserving terminal goals installed exogenously", I think we see goals being self-constructed and then flung into long-termness.
There are two days left to get a standard-price ticket for Reproductive Frontiers Summit 2026. It will be June 16–18 at Lighthaven in Berkeley.
We have over 30 speakers from academia and industry, including pioneering in vitro gametogenesis research groups (Sasaki, Hayashi, Ovelle, Paterna), stem cell and embryo editing researchers (Amato, Hysolli, Hockemeyer), polygenic embryo screening researchers (Carmi, Herasight, Orchid, Progenic), our very own GeneSmith, and other experts in law, ethics, artificial wombs, in vitro maturation, etc. See the full schedule here: https://www.reproductivefrontiers.org/
Register and buy a ticket here: https://www.reproductivefrontiers.org/register
9
I considered attending after seeing this but was put off by how full of talks the schedule was.
Perhaps too late by now, but I'd strongly suggest reading this post and implementing some of the recommendations.
5
I slightly agree. Probably going forward I will have shorter talks.
I would suggest the possibility of attending and then simply not attending talks. I believe that for any given talk, there will be many people not attending that talk. You may also find that there is surprisingly diverse and relevant information in many of the talks. (If the information in these talks isn't of interest to you, then this conference may indeed not be a good event for your goals.)
On the general topic of conference design, I'm not sure how strongly I believe the recommendations; my guess is there are many desiderata you're simply not modeling. For example, different speakers get back to me about speaking at different times, different speakers have different days they can attend, many speakers would be unlikely to attend if not invited to speak and are in fact important to have in attendance, this conference in particular benefits from many of the attendees learning the varied information from these speakers, having recorded talks is valuable, being able to advertise specific speakers to specific audiences such as academics is valuable, having particular groups represented and gathered is valuable for things such as advancing various threads of conversation / social processing in a way that has some degree of canonicity, etc.
2
My experience of workshops like this one makes me expect that ~90% of people will attend a talk during most of the talk slots, but I'm open to being wrong.
[...]
FWIW my advice here is partly based on my experience running the original Alignment Workshop, which had many of the same desiderata as your conference (though of course there are many important differences).
Also, out of curiosity, was it you who -9 disagree-voted my comment?
3
You may be right, I'm not confident. I would have said something like 70%, maybe more during doubled talks, with wide error bars. I think to a significant extent, I want to trust people's self-governance. I (and maybe you too) tend to be much more interested in small conversations, but other people like talks. I think they serve several functions that I'm less attuned to, e.g. around common knowledge creation, communicating info efficiently from a perspective where the speakers have very valuable + hard to get information and their time is very scarce (which I think is, on the whole, much more true of biology than of something like alignment research), signaling epistemic authority, things like that.
Yes, I disagree voted; if I were to verbalize the disagreement, it would be something like "I disagree that you understand the context / goals of the conference enough to make reasonable suggestions about it like this, and this particular suggestion is probably quantitatively pretty incorrect (though as I noted, in a sense slightly directionally correct)".
I would strongly agree with your suggestion if this were a workshop, in the sense of wanting lots of people to develop new deep-context researchy threads and to collaborate about that; e.g. for the MSFP/AISFPs that I played some role in running, I believe I would have pushed against having lots of talks and in favor of 1-on-1s / breakout sessions / etc., and that's generally what I have suggested to people running deep-work workshops in alignment.
4
Got it. On a meta level I don't think you're using the disagree vote correctly. The point of disagree votes IMO is to disentangle "am I glad this comment was made" from "is this comment factually correct". In this case it seems like you thought my comment was at least somewhat correct, but that you thought I didn't have the standing required to make this kind of comment.
I would suggest that downvoting the comment is a better way to convey your position. Though I also think that it's one of LW's most valuable norms that it doesn't gatekeep very much who has social permission to make comments or criticisms, so in your position I wouldn't downvote.
My main takeaway here is that I should probably write about updates that I made based on running the Alignment Workshop (which, despite its name, was closer in function to what you're calling a "conference"), so I have a canonical thing to point people to.
6
I'm saying the comment is (2) incorrect and (1) seems to indicate that you're incorrectly assuming that you have the context that would be needed to make this sort of call; my earlier comment "I slightly agree" is, when expanded, "I slightly directionally agree", which is a more complicated kind of agreement which is consistently with strongly disagreeing overall. I also think it's fine to disagree-vote for things implicit in a comment, such as process-level things in the class of "you seem to be incorrectly thinking you have the information that would be needed to reasonably make this sort of judgement call". (Of course, I could very well be incorrect in thinking any of these things, in which case my disagreement vote would be incorrect in some sense, though it's an accurate expression of my current state of mind.)
For its performances, current AI can pick up to 2 of 3 from:
- Interesting (generates outputs that are novel and useful)
- Superhuman (outperforms humans)
- General (reflective of understanding that is genuinely applicable cross-domain)
AlphaFold's outputs are interesting and superhuman, but not general. Likewise other Alphas.
LLM outputs are a mix. There's a large swath of things that it can do superhumanly, e.g. generating sentences really fast or various kinds of search. Search is, we could say, weakly novel in a sense; LLMs are superhumanly fast at doing a form of search which is not very reflective of general understanding. Quickly generating poems with words that all start with the letter "m" or very quickly and accurately answering stereotyped questions like analogies is superhuman, and reflects a weak sort of generality, but is not interesting.
ImageGen is superhuman and a little interesting, but not really general.
Many architectures + training setups constitute substantive generality (can be applied to many datasets), and produce interesting output (models). However, considered as general training setups (i.e., to be applied to several contexts), they are subhuman.
Recommendation for gippities as research assistants: Treat them roughly like you'd treat RationalWiki, i.e. extremely shit at summaries / glosses / inferences, quite good at citing stuff and fairly good at finding random stuff, some of which is relevant.
4
Works for me, I don't use either!
Protip: You can prevent itchy skin from being itchy for hours by running it under very hot water for 5-30 seconds. (Don't burn yourself; I use tap water with some cold water, and turn down the cold water until it seems really hot.)
4
I think this works on the same principle as this device which heats up a patch that you press to your skin. I've also found that it works to heat up a spoon in near boiling water and press it to my skin for a few seconds.
4
I recently bought a battery-powered tool that creates a brief pulse of heat in a small metal applicator, specifically designed for treating itchy mosquito bites. It works well!
In the case of the mosquito bite, there is the additional aspect of denaturing the proteins left behind by the mosquito in order to cause them to be less allergenic.
(These are 100% unscientific, just uncritical subjective impressions for fun. CQ = cognitive capacity quotient, like generally good at thinky stuff)
- Overeat a bit, like 10% more than is satisfying: -4 CQ points for a couple hours.
- Overeat a lot, like >80% more than is satisfying: -9 CQ points for 20 hours.
- Sleep deprived a little, like stay up really late but without sleep debt: +5 CQ points.
- Sleep debt, like a couple days not enough sleep: -11 CQ points.
- Major sleep debt, like several days not enough sleep: -20 CQ points.
- Oversleep a lot, like 11 hours: +6 CQ points.
- Ice cream (without having eaten ice cream in the past week): +5 CQ points.
- Being outside: +4 CQ points.
- Being in a car: -8 CQ points.
- Walking in the hills: +9 CQ points.
- Walking specifically up a steep hill: -5 CQ points.
- Too much podcasts: -8 CQ points for an hour.
- Background music: -6 to -2 CQ points.
- Kinda too hot: -3 CQ points.
- Kinda too cold: +2 CQ points.
(stimulants not listed because they tend to pull the features of CQ apart; less good at real thinking, more good at relatively rote thinking and doing stuff)
8
I feel like I’ve really struggled to identify any controllable patterns in when I’m “good at thinky stuff”. Gross patterns are obvious—I’m reliably great in the morning, then my brain kinda peters out in the early afternoon, then pretty good again at night—but I can’t figure out how to intervene on that, except scheduling around it.
I’m extremely sensitive to caffeine, and have a complicated routine (1 coffee every morning, plus in the afternoon I ramp up from zero each weekend to a full-size afternoon tea each Friday), but I’m pretty uncertain whether I’m actually getting anything out of that besides a mild headache every Saturday.
I wonder whether it would be worth investing the time and energy into being more systematic to suss out patterns. But I think my patterns would be pretty subtle, whereas yours sound very obvious and immediate. Hmm, is there an easy and fast way to quantify “CQ”? (This pops into my head but seems time-consuming and testing the wrong thing.) …I’m not really sure where to start tbh.
…I feel like what I want to measure is a 1-dimensional parameter extremely correlated with “ability to do things despite ugh fields”—presumably what I’ve called “innate drive to minimize voluntary attention control” being low a.k.a. “mental energy” being high. Ugh fields are where the parameter is most obvious to me but it also extends into thinking well about other topics that are not particularly aversive, at least for me, I think.
7
Are you sure about the sign here?
I think I'm more prone to some kinds of creative/divergent thinking when I'm mildly to moderately sleep-deprived (at least sometimes in productive directions) but also worse in precise/formal/mathetmatical thinking about novel/unfamiliar stuff. So the features are pulled apart.
4
No yeah that's my experience too, to some extent. But I would say that I can do good mathematical thinking there, including correctly truth-testing; just less good at algebra, and as you say less good at picking up an unfamiliar math concept.
6
(BTW first you say "CQ" and then "GQ")
2
Ohhh. Thanks. I wonder why I did that.
2
Major sleep debt?
Probably either one of (or some combination of): (1) "g" is the next consonant after "c" in "cognitive"; (2) leakage from "g-factor"; (3) leakage from "general(ly good at thinking)"
2
(1) was my guess. Another guess is that there's a magazine "GQ".
1[anonymous]
I notice the potential for combo between these two:
[...]
(One can stay up till sleep deprived and oversleep on each sleep/wake cycle, though they'll end up with a non-24-hour schedule)
4
Yep! Without cybernetic control (I mean, melatonin), I have a non-24-hour schedule, and I believe this contributes >10% of that.
1[anonymous]
Also,
[...]
That might generalize to "minimizing sound good", in which case I'd suggest trying these earplugs.
Generalizing to sensory deprivation in general, an easy way to do that is to lay in bed with eyes closed and lights off (not to sleep). (I've found this helpful, but maybe it's a side effect of not being distracted by a computer)
3
I quite dislike earplugs. Partly it's the discomfort, which maybe those can help with; but partly I just don't like being closed away from hearing what's around me. But maybe I'll try those, thanks (even though the last 5 earplugs were just uncomfortable contra promises).
Yeah, I mean I think the music thing is mainly nondistraction. The quiet of night is great for thinking, which doesn't help the sleep situation.
In this interview, at the linked time: https://www.youtube.com/watch?v=HUkBz-cdB-k&t=847s
Terence Tao describes the notion of an "obstruction" in math research. I think part of the reason that AGI alignment is in shambles is that we haven't integrated this idea enough. In other words, a lot of researchers work on stuff that is sort-of known to not be able to address the hard problems.
(I give some obstruction-ish things here: https://tsvibt.blogspot.com/2023/03/the-fraught-voyage-of-aligned-novelty.html)
4
The way I think about is: It's often considered a good idea to study simplified toy versions of various systems, on the reasoning that deriving results there would be easier, and that afterwards you'd be able to combine these disjoint toy models separately explaining every feature of the system into one model holistically explaining every feature.
But what sometimes happens is the opposite. Sometimes studying toy setups, with load-bearing building blocks missing, results in overly complicated models that only confuse you. On the other hand, adding the building blocks back – making the initial setup more complex – actually leads to the desired features trivially falling out of it.
It's a tricky balance to maintain.
6
Right--the further issue being that for alignment, you have to understand minds, which are intrinsically to a significant extent holistic: studying some small fraction of a mind will always be leaving out the overarching mentality of the mind. Cf. https://tsvibt.github.io/theory/pages/bl_24_12_02_20_55_43_296908.html . E.g., several different mental elements have veto power over actions or self-modifications, and can take actions and do self-modifications. If you leave out several of these, your understanding of the overall dynamic is totally off-the-rails / totally divergent from what a mind actually does.
Cf. https://www.lesswrong.com/posts/Ht4JZtxngKwuQ7cDC/tsvibt-s-shortform?commentId=koeti9ygXB9wPLnnF
A pleasing confluence:
Episode 1: Sum-threshold attacks
Episode 2: I was musing about maxims that could be derived from my speculations on the nature of wisdom. I'd written:
Wisdom is getting right the first-order bits that are natural——that are expressed naturally in the familiar internal language of living.
This implies a not totally obvious conclusion / conjecture: It's much more important (well, much more wise) to ensure that you are able to eventually update on any given dimension, rather than to ensure that you're updating especially fast on some dimensions.
Episode 3: I was considering chromosome selection in relation to other powerful genomic vectoring methods such as iterated meiotic selection, and wondering why chromosome selection can be so powerful. I wrote out a cursory explanation of this phenomenon (which you can read here: https://x.com/BerkeleyGenomic/status/2059901943959674931), and at the end I realized I'd basically restated the above Maxim of updating on all dimensions! I concluded that tweet with:
...The lesson: granularity of selection is just very powerful. It's much more important to be able to select on something independently at all, than to be able to selec
6
Another example is https://gwern.net/backstop
A foundation for many nested search/optimization/adaptation processes is that the outermost loop has a faithful access to a right sort of "ground truth signal". This tends to be inefficient/costly/slow but nevertheless necessary because without it the more efficient/greedy but less sensitive(/wise?) inner-er processes tend to go awry and the whole optimization edifice collapses or maybe grows cancer or something.
"The Future Loves You: How and Why We Should Abolish Death" by Dr Ariel Zeleznikow-Johnston is now available to buy. I haven't read it, but I expect it to be a definitive anti-deathist monograph. https://www.amazon.com/Future-Loves-You-Should-Abolish-ebook/dp/B0CW9KTX76
The description (copied from Amazon):
A brilliant young neuroscientist explains how to preserve our minds indefinitely, enabling future generations to choose to revive us
Just as surgeons once believed pain was good for their patients, some argue today that death brings meaning to life. But given humans rarely live beyond a century – even while certain whales can thrive for over two hundred years – it’s hard not to see our biological limits as profoundly unfair. No wonder then that most people nearing death wish they still had more time.
Yet, with ever-advancing science, will the ends of our lives always loom so close? For from ventilators to brain implants, modern medicine has been blurring what it means to die. In a lucid synthesis of current neuroscientific thinking, Zeleznikow-Johnston explains that death is no longer the loss of heartbeat or breath, but of personal identity – that the core of our identities is ou...
Discourse Wormholes.
In complex or contentious discussions, the central or top-level topic is often altered or replaced. We're all familiar from experience with this phenomenon. Topologically this is sort of like a wormhole:
Imagine two copies of minus the open unit ball, glued together along the unit spheres. Imagine enclosing the origin with a sphere of radius 2. This is a topological separation: The origin is separated from the rest of your space, the copy of that you're standing in. But, what's contained in the enclosure is an entire world just as large; therefore, the origin is not really contained, merely separated. One could walk through the enclosure, and pass through the unit ball boundary, and then proceed back out through the unit ball boundary into the other alternative copy of .
You come to a crux of the issue, or you come to a clash of discourse norms or background assumptions; and then you bloop, where now that is the primary motive or top-level criterion for the conversation.
This has pluses and minuses. You are finding out what the conversation really wanted to be, finding what you most care about here, finding out what the two of most ought to fight about ...
2
A particularly annoying-to-me kind of discourse wormhole:
[...]
1. ^
Or even, eh, social pressures, etc.
6
Mhm. Yeah that's annoying. Though in her probabilistic defense,
1. In fact her salience might have changed; she might not have noticed either; it might not even be a genuinely adversarial process (even subconsciously).
2. She might reasonably not know exactly what position she wants to defend, while still being able to partially and partially-truthfully defend it. For example, she might have a deep intuition that incest is morally wrong; and then give an argument against incest that's sort of true, like "there's power differences" or "it could make a diseased baby"; and then you argue / construct a hypothetical where those things aren't relevant; and then she switches to "no but like, the family environment in general has to be decision-theoretically protected from this sort of possibility in order to prevent pressures", and claims that's what she's been arguing all along. Where from your perspective, the topic was the claim "disease babies mean incest is bad", but from hers it was "something inchoate which I can't quite express yet means incest is bad". And her behavior can be cooperative, at least as described so far: she's working out her true rejection by trying out some rejections she knows how to voice.
3. Sometimes I'm talking to someone (e.g. about AGI timelines) and they'll start listing facts. And the facts don't seem immediately relevant, or like, I don't know how to take them on board or to respond because I don't know what argument is being made. And if I try to clarify what argument is being made, they just keep listing more facts--which disorients me; and I often imagine that they have a background assumption like "A implies B" and so they have started giving supporting facts to explain and give evidence for A. And then I'm confused because I don't know what B even is. So I try to ask; but what I get back is more stuff about A; and they are hoping that if they just say enough stuff and convince me of A, then of course since A implies B and B is
What would you be doing if you had N times more time per day? A piece of terminology I want to coin now, to summarize a phrase I've been using a lot recently:
That's a K-x priority.
As in, "Writing this post on group rationality is a 3x priority.". That means:
If I had 3x as much time, like I could do 3 days of work per day, one of the things I'd actually get to would be writing this post.
Maybe it's confusing because 3x sounds like it's more important, not less. IDK. Could say "3x time priority" for a bit more clarity.
You can think about it in terms of clones, e.g. instead of "I'd do it if I had 2x more time", you say "if I had a clone to have things done, the clone would do that thing" (equivalent in terms of work hours).
So you can say "that's my 1st/2nd/3rd/nth clone's priority".
4
This seems better to me because "getting around to more different things" is parallelizable, whereas "having K-x more serial time" is more general/powerful and you'd probably want to use it in a better way than that. (Though there's probably also a better way to use clones than "getting around to more different things").
4
Though, sometimes I do actually want to refer to the integrated / serial thing. Like, I'm saying "this activity would be good as part of my whole ecology of inquiries / projects, but at lower priority than 1x".
4
Yeah, fair. "Nth serial clone's priority"?
Maybe something with Harry Potter's Time-Turner?
2
Yeah I want to use Time-Turner, but it's confusing because 1 TT = 6 hours, not 1 day. I guess it could be fine to just say "that's a 5 Time-Turner problem" and have it be vaguely understood that you mean something like +6 working hours rather than just +6 hours.
4
Nice, I like that. (As phrased though, it demands too much precision; I want to be vague, like "it falls somewhere in the top 10 clones, probably".)
4
I agree: use the word "rank" somewhere, and it'll sound right.
4
This ~assumes that your primary projects have diminishing returns; the third copy of Tsvi is less valuable than the first. But note that Increasing returns to effort are common.
2
I don't think so? Or kinda? I mean I often say this in relation to my single main project (reprogenetics), referring to many different actions I could take (make open letter, update website, more research on many things, connecting with many people, various articles to write, etc etc). These days I'm always just guessing at what next action is reasonably close to some frontier of important, ripe, easy given what I've been thinking about, urgent, etc.
There's some time-dependence and other-people-dependence that makes "diminishing/ increasing returns" seem not quite right? Like, for example, there's some rate at which I'd want to put ideas to the LW community, which is neither as fast as I can write, nor 0.
2
'Third tier' priority (for 3x) etc?
2
"I'd add X to my priorities if I had 3x more time per day." is not how I'd understand "X is my 3rd tier priority.", so this would require additional explanation, whereas talking about it in terms of clones would require much less additional explanation.
2
Yeah, clones is probably better conceptually, if a mouthful
1
Time is not, in terms of experience, uniform. Therefore even with extra time, priorities can vary. People tend to have 5 hours of peak productivity a day - this doesn't mean they couldn't be generally more productive with additional off-peak hours, but it does mean that priories vary depending on what 'kind' of hour we're hypothesizing.
For example, folding clothes and putting them away I can do off-peak. However, I don't like driving my car too late at night - even though I prefer the lack of traffic - because I don't like driving with diminished alertness. As such, my driving habits and how I structure my day may not change that much.
You may find that with more off-peak hours my top priorities during peak hours wouldn't change, but my off-peak and lower priorities would.
2
Basically I'm meaning to talk about if I had X many Mega-Time-Turners, where each MTT sends me back a full day, but after I use one I can't interact with the world anymore that day. In other words, I get a bunch of extra serial time, and the world doesn't go by faster (but no actual time travel abilities, e.g. no info about the future). It's similar to the world going X times slower or whatever, except that I can easily engage in normal activities like real-time convos. So I get X times as many peak hours.
There's a massive divide between the Consensus and the Slighted that runs through many domains. I think healing this would in particular help decrease AGI X-risk by decreasing the motivation to make AGI and decreasing the motivated reasoning around X-risks. A conjecture is that both poles are attracting states in social space (let's say the vector space of people represented as a vector v where v_i is how much you talk with / listen to person number i).
8
What does this mean?
4
Example: Joe Rogan is Slighted
Example: Graham Hancock (and generally "conspiracy" theorists in the sense of people who have a hard to change belief in a big hidden truth that is just barely hinted at) is Slighted, Flint Dibble is Consensus https://www.youtube.com/watch?v=-DL1_EMIw6w
Example: LessWrong tends Slighted I think
(I think the ontology here is probably complicated because "Slighted" is a predicate on (person, group of people they view as their "containing context" such as a country or religion or ideology or similar), so it can apply in crisscrossing ways. Slighted can even form large communities, which seems paradoxical, but there you go.)
4
IDK. Something like, Consensus is the default agreed-upon stance / the people who take that stance; Slighted is the people who don't take that stance. (To be clear, I think I'm mostly saying something fairly obvious / not novel.)
For various reasons, the Slighted often end up viewing themselves as having been slighted by the Consensus. (E.g. they were actually slighted by the Consensus; or they were slighted by someone, and misattributed it to the Consensus; or they weren't really slighted, but view themselves that way anyway.)
As an example, sometimes tech people (Slighted) are super dismissive of academia (Consensus) in general, describing them as cowards, liars, etc.
The ends of political horseshoes are very often Slighted. (Though not necessarily. Nick Fuentes is extremely Slighted; a far-right conservative guy who views himself as being old establishment may not be especially Slighted by default, though might later become so. Likewise far left.) Slightedness attracts and creates Slightedness. E.g. because you might actually be slighted some as punishment for association with other Slighted; and becauase you hang out with Slighted; etc. That's also true for Consensus, though with different flavors.
2
A Slighted might view a Consensus as sanctimonious, cowardly, conformist, overconfident, boring, virtue signaling, envious, self-deceiving, power-thirsty (in the sense of wanting to be in control of arbitrary social consensus), wanting to cut down tall poppies, arbitrary / not truth seeking, getting sucked into a locked-in equilibrium, tribalistic.
A Consensus might view a Slighted as delusional, aggressive, contrarian, overconfident, wanting to feel special, power-thirsty (in the sense of wanting to avoid social or legal accountability), needing to be put in their place / needing to be socialized / needing moral correction / needed to have values transmitted to them, overly focused on the perceived Slight, having a big ego about their contrarian positions and not updating, getting sucked into spirals of networks of misinformation, reckless, uncaring, tribalistic, paranoid/conspiratorial.
1
As someone who probably fits under this label (and hopes it's not too offtopic) I coincidentally had a post including a lot of what my personal beliefs are and how it is like to be under this feeling https://icely.substack.com/p/is-thinking-for-yourself-a-luxury - though I mildly dislike the term just because it feels close to sounding like a "slight" thing, perhaps other words that may give the feeling are like "justified-bitterness, society-disgust, consensus-disgust, disenfranchisement, consensus alienation".
3
(Sorry, your post seems pretty interesting but I don't have enough spare bandwidth; I'll just note that those things you list here sound of course related to Slight but being Slighted is always a kind of choice you're making, similar to being Consensus, and neither is that great--they both have advantages and disadvantages. They're social and attitudinal attractors to some extent, but far from absolute.)
1
Feel free to respond/go into detail more if you happen to have the time/choose to. I guess I'll say that is not how I personally experience it. The default state is to be in Consensus and not even be aware there is a choice, even if you were born in some feral culture and then say move to a very different culture, it's very different because you think your own culture is normal and act that way. At my current point in time to "act Consensus" or to suppress Slighted-beliefs is like a constant forced strain on my moral compass. This is not a choice framing in my opinion, although as is with all definitions people can see very different things in certain words despite potential overlap and I would not want to discount that.
2
I guess one thing I'm saying is that one can have any given beliefs without taking the Slighted affiliations/attitudes too far. It's not a mere choice, it's a skill, potentially a big one (like lots of subskills, like "programming" is a skill), that one could learn over time.
3
One of the lenses I have that I think is coded somewhat vaguely conservative/right-wing/alt-right is that the (Western) elites of today do not see themselves by default as elites in the powerholding sense. Like there's a lot of active work being done to obfuscate their power and responsibilities, including from themselves. Tanner Greer's article here makes a narrower version of the same point:
[...]
In other words, that the elites of tomorrow (and likely today) see themselves as future activists rather than future (or current) statesmen, and are in institutions that train them in ways consistent with this self-image.
4
is this a faithful rephrasing?
‘~No one thinks of themselves as The Establishment.’
2
Pretty much, yeah. Though it's especially dysfunctional when the elites/leaders are wrong here (whether a normal worker in a company sees their slightly non-capitalist actions as Establishment political orthodoxy or being an idiosyncratic Maverick matters much less).
2
‘…not even The Establishment! [Which of course causes problems because The Establishment has Responsibilities.]’
3
I fully agree with this and felt like it was sniping me through the screen in one of your previous articles about it lol ( https://tsvibt.blogspot.com/2025/11/hia-and-x-risk-part-1-why-it-helps.html#abundance-makes-a-healthier-society - the part going 'Fewer smart kids traumatized into researching AGI capabilities' is like the precursor to this idea)
While I'm probably unlikely/unskilled to personally craft AGI, I certainly spend effort theorycrafting AGI systems and think about doing so due to feeling incredibly disenfranchised (not actually particularly seeing AGI as a hugely negative thing even if my doom% was 99%). Although there are a few people I've talked to who don't feel Slighted but are maybe oddly ambivalent about AGI/ASI creation due to "climate change, constant new wars, loneliness and addictions, WW3 indicator" and not feeling like it would lead to doom (edit: to clarify, both the mentalities of "not really believing AGI/ASI would lead to doom" + thinking the non-AGI track of the world is already not on a good path so 'whatever, bring on the AGI').
3
Interesting. I guess feeling disenfranchised often leads one to being Slighted, but doesn't necessarily, since one could instead just do some kind of giving up. (One could also do other things, such as maybe finding other hopeworthy long-term shared intentions with other people to invest in.)
1
(I edited my comment to clarify that these people I mention aren't necessarily 'disenfranchised' or even emotionally disturbed/unhappy people. But yeah I guess 'giving up' could fit, that also includes perhaps current 10-18 year olds who still treat the life track they're on as "normal" who still see these big world events as very abstract and sort of imaginary, as not something that impacts them)
Say a "deathist" is someone who says "death is net good (gives meaning to life, is natural and therefore good, allows change in society, etc.)" and a "lifeist" ("anti-deathist") is someone who says "death is net bad (life is good, people should not have to involuntarily die, I want me and my loved ones to live)". There are clearly people who go deathist -> lifeist, as that's most lifeists (if nothing else, as an older kid they would have uttered deathism, as the predominant ideology). One might also argue that young kids are naturally lifeist, and there...
6
This is not quite deathism but perhaps a transition in the direction of "my own death is kinda not as bad":
[...]
and in a comment:
[...]
2
@Valentine comes to mind as a person who was raised lifeist and is now still lifeist, but I think has more complicated feelings/views about the situation related to enlightenment and metaphysics that make death an illusion, or something.
8
I think I've been unwaveringly lifeist the whole time. My main shift has been that I think I see some value in deathist sentiment that's absent from most lifeist rhetoric I'm familiar with. I want a perspective that honors why both arise.
I did dabble with ideas around whether death is an illusion. And I still think there might be something to it. But having done so, it looks like a moving goalposts thing to me. I still don't want to die, and I don't want my loved ones to die, and I think that means something that matters.
2
Me.
4
In what sense were you lifeist and now deathist? Why the change?
1
Other (more compelling to me) reasons for being a "deathist":
* Eternity can seem kinda terrifying.
* In particular, death is insurance against the worst outcomes lasting forever. Things will always return to neutral eventually and stay there.
6
A lifeist doesn't say "You must decide now to live literally forever no matter what happens."!
1
Fine, but it still seems like a reason one could give for death being net good (which is your chief criterion for being a deathist).
I do think it's a weaker reason than the second one. The following argument in defence of it is mainly for fun:
I slightly have the feeling that it's like that decision theory problem where the devil offers you pieces of a poisoned apple one by one. First half, then a quarter, then an eighth, than a sixteenth... You'll be fine unless you eat the whole apple, in which case you'll be poisoned. Each time you're offered a piece it's rational to take it, but following that policy means you get poisoned.
The analogy is that I consider living for eternity to be scary, and you say, "well, you can stop any time". True, but it's always going to be rational for me to live for one more year, and that way lies eternity.
2
The distinction you want is probably not rational/irrational but CDT/UDT or whatever,
Also,
[...]
well, it's also insurance against the best outcomes lasting forever (though you're probably going to reply that bad outcomes are more likely than good outcomes and/or that you care more about preventing bad outcomes than ensuring good outcomes)
The standard way to measure compute is FLOPS. Besides other problems, this measure has two major flaws: First, no one cares exactly how many FLOPS you have; we want to know the order of magnitude without having to incant "ten high". Second, it sounds cute, even though it's going to kill us.

I propose an alternative: Digital Orders Of Magnitude (per Second), or DOOM(S).
(Speculative) It seems like biotech VC is doing poorly, and this stems from the fact that it's a lot of work to discriminate good from bad prospects for the biology itself. (As opposed to, say, ability of a team to execute a business, or how much of a market there is, etc.) If this is true, have some people tried making a biotech VC firm that employs bio experts--like, say, PhD dropouts--to do deep background on startups?
Ostentiation:
So there's steelmanning, where you construct a view that isn't your interlocutor's but is, according to you, more true / coherent / believable than your interlocutor's. Then there's the Ideological Turing Test, where you restate your interlocutor's view in such a way that ze fully endorses your restatement.
Another dimension is how clear things are to the audience. A further criterion for restating your interlocutor's view is the extent to which your restatement makes it feasible / easy for your audience to (accurately) judge that view. You cou...
4
[nitpick] while also being close to your interlocutor's (perhaps so that your interlocutor's view could be the steelmanned view with added noise / passed through Chinese whispers / degenerated).
[...]
Exoclarification? Alloclarification? Democlarification (dēmos - "people")?
2
(I think I'll go with "alloprosphanize" for now... not catchy but ok. https://tsvibt.github.io/theory/pages/bl_25_10_08_12_27_48_493434.html )
2
These are good ideas, thanks!
Is there a nice way to bet on large-evidence, small-probability differences?
Normally we bet on substantial probability differences, like I say 10% you say 50% or similar. Betting makes sense there--you incentivize having correct probabilities, at least within a few percent or whatever. Is there some way to incentivize reporting the right log-odds, to within a logit or whatever?
One sort of answer might be showing that/how you can always extract a mid-range probability disagreement on latent variables, under some assumptions on the structure of the latent variable models underlying the large-logit small-probability disagreement.
2
Most high-liquidity securities are this - small movements with large amounts of money riding on them.
I don't think it generalizes, though - different domains or even specific disagreements over probability of an outcome will have different mechanisms for matching counterparties with low-enough transaction costs that a wager is feasible.
I guess that is the generality: every wager is about two parties agreeing that they have a disagreement which will be resolved in the future, and further agreeing that the less-correct party will pay the more-correct party. Sometimes this can be a distributed/anonymous agreement, like a stock market (or like an actual market, where you "bet" that today's purchases can be sold later for more). Sometimes it's an individual wager. And, as always, transaction costs (loss of value due to the structuring and administration of the wager) make the vast majority of possible wagers infeasible.
For log-odds, there's a complexity in that it's not obvious how to make them add up to 1, so the wager will be (as wagers need to be) zero-sum. Every dollar won by a better predictor is a dollar lost by a worse one (or ones). The easiest way to convert a log-odds prediction to a linear zero-sum wager is to just convert to actual probability.