In expectation, editing all those variants could decrease someone’s diabetes risk to negligible levels.
That seems to assume the effects remain linear throughout all the switch-flipping, and that there aren't any harmful effects from stacking too many of a certain type of variant. How likely are those?
Yes, I slightly oversimplified this point for the sake of keeping it short.
The effects ARE linear in the sense that you can predict diabetes risk with a function f(x_1+x_2+x_3...) for all diabetes affecting variants. The actual shape of the curve is not a straight line though. It's more like an exponential.
As far as plieotropy goes (one gene having multiple effects), a better approach would be to create genetic predictors for a large number of traits and prioritize edits in proportion to their effect on the trait of interest, their probability of being causal, and the severity of the condition.
But do I believe you could probably just do edits for one disease without a significant negative effect? Yes, so long as the resulting genome is within roughly the normal human range in terms of overall disease risk. There isn't that much plieotropy to begin with, and the plieotropy that does exist tends to work in your favor; decreasing diabetes risk also tends to decrease risk of hypertension and heart disaease.
In the post you talked about editing all 237 loci to make diabetes negligible, but now you talk about the normal human range. I think that is more correct. Editing all 237 loci would leave the normal human range; the effect on diabetes would be unpredictable and the probability of bad effects likely. Not because of pleiotropy, but just the breakdown of a control system outside of its tested regime.
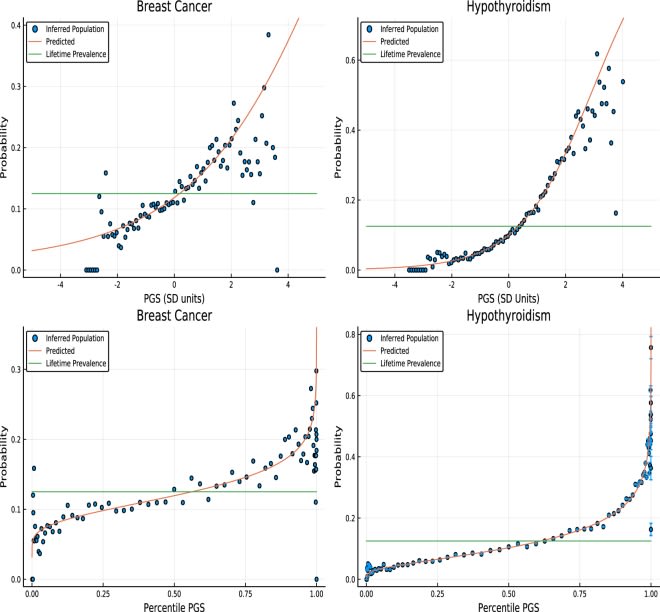
The reflected-sigmoidish part doesn't occur when predicting with a linear combination of genetic variants, only when predicting with the percentiles. Since PGSes are normally distributed, converting them to percentiles puts them through a a sigmoidish function, and so you need a reflected-sigmoidish function to invert it.
The connection between the raw PGS is exponential, as can be seen in the top graphs (or more realistically it is presumably sigmoidal, but we're on the exponential part of the curve).
When applied to adult humans, this is many orders of magnitude more difficult than you claim.
Casgevy is not a standard gene edit, because although the mutation for sickle cell is known, the didn't target that mutation! (I assume they have their reasons, they are activating fetal haemoglobin expression instead). Also, the treatment works by removing all the bone marrow from your body, editing it, and putting it back in, because they know exactly what cells haemoglobin is expressed in for it to do its mechanistic role.
Unless you're planning to edit at the fertilized egg stage, with only a black box you have to edit every single cell in the human body, and these treatments, though the stuff of science fiction, doesn't seem to have an easy answer. Once you know where the genes you're editing are being expressed you can target them, but some places are easier to target than others (like the brain, or the bone marrow), and it's likely some sites can only be accessed with a good surgery.
Wagner also mentions off-target errors which are an additional issue with current technologies.
You can probably do all the diabetes edits in the pancreas and get a good reduction in diabetes, but that's because you have the mechanistic information on how it works.
Though at that point we can probably grow organs from single cells so we can edit them there.
And with Casgevy's approach (turning on a gene, not editing), you probably want to know the mechanism, otherwise you get haemoglobin being expressed in your neurons and that's probably not good for your health.
When applied to adult humans, this is many orders of magnitude more difficult than you claim.
I'm not suggesting getting a therapy like this working is easy. I think it will be quite hard.
(I assume they have their reasons, they are activating fetal haemoglobin expression instead)
They targeted fetal hemoglobin because reactivating it simultaneously treats sickle cell and beta thallasemia. Fetal hemoglobin doesn't sickle and the symptoms of beta thallasemia ultimately arise from a lack of functional hemoglobin.
Also, the treatment works by removing all the bone marrow from your body, editing it, and putting it back in, because they know exactly what cells haemoglobin is expressed in for it to do its mechanistic role
I'm working on a post about this topic that goes into much more depth and addresses issues with delivery. But needless to say, I don't think we will have many viable therapies if they rely on extracting bone marrow and then reinjecting it.
Unless you're planning to edit at the fertilized egg stage, with only a black box you have to edit every single cell in the human body, and these treatments, though the stuff of science fiction, doesn't seem to have an easy answer.
You don't actually need to edit every cell. You just need to get enough edits in a large enough fraction of cells to affect the phenotype. Will there be issues with mosaicism?
Maybe. But long-lived cells in the human body already have about 1500 de novo mutations by the time you hit 40, so the body is clearly able to deal with some level of mosaicism already.
Wagner also mentions off-target errors which are an additional issue with current technologies.
Yes, you are correct. I will address this in my longer post.
You can probably do all the diabetes edits in the pancreas and get a good reduction in diabetes, but that's because you have the mechanistic information on how it works.
We understand diabetes well enough but we don't have a mechanistic understanding of all the genetic variants known to influence diabetes risk do so.
Though at that point we can probably grow organs from single cells so we can edit them there.
If they can get that to work then it will be amazing. But how would it work for organs like the brain?
You don’t need to understand the mechanism of action. You don’t need an animal model of disease. You just need a reasonable expectation that changing a genetic variant will have a positive impact on the thing you care about. And guess what? We already have all that information. We’ve been conducting genome-wide association studies for over a decade.
This is critically wrong, because association is uninformative about interventions.
Genome-wide association studies are enormously informative about correlations in a particular environment. In a complex setting like genomics, and where there are systematic correlations between environmental conditions and population genetics to confound your analysis, this doesn't give you much reason to think that interventions will have the desired effect!
I'd recommend reading up on causal statistics; Pearl's Book of Why is an accessible introduction and the wikipedia page is also reasonably good.
I'm happy to read any evidence to the contrary, but my current view is that for most traits, the genetic variants that only have effects in certain environments that are no longer present are pretty unusual. And even in the cases where this is true, it will only slightly reduce the effect size from editing.
You're correct about GWAS only showing associations, but there are ways around this. For one thing, you can use sibling validation to narrow down the set of variants to direct causal impacts rather than genetic nurture, for example, and you can use finemapping and other techniques to reduce uncertainty about which SNP in a clump is actually causing the effect.
And after all that, you can just sort the genes to edit by effect size * probability of being causal when deciding edit priority.
Ok, so, suppose that pretty much everyone who grew up in Britain in the 1960s has 100 identifiable genetic variants that pretty much no one else has, and by coincidence there were some schools in Britain in the 1960s that taught a bunch of awful dietary habits to schoolchildren, and so there's a major correlation between those variants and developing diabetes. It also happens that 10 of those variants actually make the body more susceptible to diabetes, and 10 of them protect against diabetes, and the rest have zero causal effect. @GeneSmith , what would the GWAS conclude in this case, and how common and important are cases like it? (E.g. I would guess there are a bunch of genes that correlate with socioeconomic status but aren't causal.)
This is where sibling validation becomes very useful: if the observed effect is due an actual direct genetic effect, it will allow you to distinguish siblings with higher and lower diabetes risk. If it's due to some weird environmental gene correlation, it won't.
If you did the sibling testing you would find that 10 of the associated genes replicated and 90 did not.
It seems implausible that everyone who grew up in Britain in the 1960s would have genetic variants that no one else has. Their parents and children would have grown up in different decades, whether in Britain or elsewhere, and they would also have those variants.
It's not enough unless you know that changing that gene doesn't also increase the chance of some other problem by 2% causing a completely random different issue. And if it costs millions to CRISPR away sickle cell anemia... who would pay millions to shave off a 0.3% chance of diabetes?
Ideally, doing customised gene therapy and all sorts of fancy stuff is a cool idea. But you need to crash the prices of these things down enough for them to be scalable. I would need a certain treatment that uses monoclonal antibodies to make my life quite a bit better... but it costs thousands of bucks a month and I can't afford that, so, too bad. Until new tech or scale economies drive the price of these things down to mass use levels, we won't have a revolution.
If this were to evolve into an actual therapy it would involve many, many edits. Probably on the order of several hundred. So yes, I agree no one would pay $2 million for a 0.3% reduction in Diabetes risk.
As far as costs go, I of course agree. But the costs of manufacturing these treatments isn't going to be that expensive; guideRNAs, lipid nanoparticles or AAVs are in the hundreds of dollars range for a large batch. At scale, you could probably manufacture treatments for a few hundred bucks. The expensive part is the R&D and the graveyard of treatments that didn't succeed which the successful ones have to pay for.
A big part of those originate with the expense of getting past the FDA approval process. Many drugs don't even make it to clinical trials because the approval process expense makes them uneconomical.
If the treatment is extensive/expensive enough that traveling isn't a significant additional incursion, you could try https://www.prospera.co/
I've thought about it. But that's a long way down the road. There's a lot of basic validation work that has to be done before we need to start thinking about clinical trials. So it's probably not worth expending any effort on that right now.
Well, sure, there may be a more general argument for FDA bureaucracy being too convoluted (though of course there are risks with it being too lax too - no surer way to see the market flooded with snake oil). But that's general and applies to many therapies, not just genetic ones. Same goes for research costs being the big slice of the pie.
Yes, I would agree. I don't think this necessary needs to be that expensive, though it probably will be at the start.
I believe that the CRISPR cost is for treating an already existing adult, and that it would be much cheaper to do it for a newly fertilised egg that is about to implanted as a pregnancy. Looking to the future we could also hope that CRISPR will get cheaper.
The point about creating other problems sounds like it could be a real issue unless people are very careful. Maybe you have good data for identifying medical problems, but not knowing the causal pathway means weird stuff can happen. Lets say their is a gene that effects your sense of taste in such a way as to ruin (or significantly hamper) your enjoyment of food. That gene might anti-correlate with diabetes, but you probably wouldn't want it.
The point about creating other problems sounds like it could be a real issue unless people are very careful. Maybe you have good data for identifying medical problems, but not knowing the causal pathway means weird stuff can happen. Lets say their is a gene that effects your sense of taste in such a way as to ruin (or significantly hamper) your enjoyment of food. That gene might anti-correlate with diabetes, but you probably wouldn't want it.
I wouldn't be suprised to find isolated examples like this, but if it were the case in general we'd expect to see people with low genetic risk scores for diabetes to have noticeably worse outcomes in some other area. And that's just not what we see.
Frankly, the same can be said for a lot of other traits as well; to the degree that we do see plietropy (i.e. one gene having two effects), it tends to work in our favor: for example there are some genetic variants that both decrease risk of hypertension and decrease risk of heart attack.
I believe that the CRISPR cost is for treating an already existing adult, and that it would be much cheaper to do it for a newly fertilised egg that is about to implanted as a pregnancy. Looking to the future we could also hope that CRISPR will get cheaper.
But then people need to preemptively decide to get IVF, going though all the related pains and troubles, because they sequenced their genomes and realized that one of them carries a gene that might increase that risk of diabetes by 0.3% (and do some other things we are not sure of). It's still a huge cost, time investment, effort investment, and quality of life sacrifice - IVF isn't entirely risk-free and there are several invasive procedures involved for the woman. It's again not obvious why would they do this if the payoff isn't really worth it.
All true. But, sometimes people are having IVF anyway, for fertility or other reasons, and in that case the argument for doing it is stronger. Also, I am not advocating that you go in and change one gene to reduce the diabetes chance by 0.3%. If you are doing anything at all you are changing many genes, so that the overall change of diabetes is cut by some larger percentage, and the chance of cancer is reduced similarly, and the chance of ...
To clarify, I am in no way saying that the current offering is anywhere near being worth the current price for the typical person. I am speculating that in the future the offerings will be more attractive (more diseases reduced by larger percentages) at lower prices, and that there are some atypical scenarios (eg. if you have an awful genetic disease, or are having IVF anyway) where the gap to "worth it" will close relatively fast.
But the reasonable for being careful about this stuff aren't unfounded. Not only if we don't get precisely the function of each gene this could cause side effects of arbitrary seriousness, but the child is then stuck with them for life and would potentially pass them to their descendants. Now perhaps we should consider gene therapy more than we are now but it's far from a "go to the lab and start deploying it now" affair anyway.
I actually think we can pretty much eliminate the risk of arbitrarily large side-effects. There are databases of known genetic variants that cause serious illness or death. As long as you can avoid edits to those varaints you should be fine.
Nearly all the variants you would target are present in at least 1% of some reference population, so the maximum "downside" would be the sum of the differences between that reference populations lives and those without the variant for all variants you edit (plus any effects from off-targets).
Off targets ARE a concern, but there are ways to significantly reduce the risk of such edits. For example if you want to change a sequence AAA to AGA, you're better off using a prime editor to avoid bystander edits that are common among base editors (at least you're better off if bystander edits are actually a concern)
so the maximum "downside" would be the sum of the differences between that reference populations lives and those without the variant for all variants you edit (plus any effects from off-targets)
I don't think that's true? It has to assume the variants don't interact with each other. Your reference population would only have 0.01% people with (the rarest) 2 variants at once, 0.0001% with 3 variants, and so on.
If you were to do gene editing on embryos you wouldn't just target one gene. That would make no sense. You'd target hundreds or maybe even thousands in order of importance. At scale it could actually work assuming you can solve other issues related to off-target editing.
Is there a plausible path towards gene therapies that edit dozens, hundreds, or thousands of different genes like this? I thought people were worried about off-target errors, etc? (Or at least problems like "you'll have to take 1000 different customized doses of CRISPR therapy, which will be expensive".) So my impression is that this kind of GWAS-inspired medicine would be most impactful with whole-genome synthesis? (Currently super-expensive?)
To be clear I agree with the main point this post is making about how we don't need animal models, etc, to do medicine if we have something that we know works!
Yes, there is. I've been working on a post about this for the last few months and hope to post something much more comprehensive soon.
Off-targets are a potential issue though they're less of an issue if you target non-coding regions that aren't directly translated into proteins. The editing tools have also improved a lot since the original CRISPR publications back in 2012. Base editors and prime editors have indel rates like 50-300x lower than original CRISPR.
(Or at least problems like "you'll have to take 1000 different customized doses of CRISPR therapy, which will be expensive".)
Base editors and prime editors can do simultaneous edits in the same cell. I've read a paper where the authors did 50 concurrent base edits (though it was in a cell type that is easier than average to edit). Scaling concurrent editing capabilities is the very first thing I want to focus on.
Also, if your delivery vector doesn't trigger an adaptive immune response (or end up being toxic for some other reason), you can redose someone a few times and make new edits with each round. If we can solve delivery issues, the dosing would be as simple as giving someone an IV injection.
I'm not saying these are simple problems. Solving all of them is going to be hard. But many of the steps have already been done independently in one research paper or another.
So my impression is that this kind of GWAS-inspired medicine would be most impactful with whole-genome synthesis?
No. You don't need to be able to synthesize a genome to make any of this work. You can edit the genome of a living person.
Thanks, this is exciting and inspiring stuff to learn about!
I guess another thing I'm wondering about, is how we could tell apart genes that impact a trait via their ongoing metabolic activities (maybe metabolic is not the right term... what I mean is that the gene is being expressed, creating proteins, etc, on an ongoing basis), versus genes that impact a trait via being important for early embryonic / childhood development, but which aren't very relevant in adulthood. Genes related to intelligence, for instance, seem like they might show up with positive scores in a GWAS, but their function is confined to helping unfold the proper neuron connection structures during fetal development, and then they turn off, so editing them now won't do anything. Versus other genes that affect, say, what kinds of cholesterol the body produces, seem more likely to have direct impact via their day-to-day operation (which could be changed using a CRISPR-like tool).
Do we have any way of distinguishing the one type of genes from the other? (Maybe we can just look at living tissue and examine what genes are expressed vs turned off? This sounds hard to do for the entire genome...) Or perhaps we have reason to believe something like "only 20% of genes are related to early development, 80% handle ongoing metabolism, so the GWAS --> gene therapy pipeline won't be affected too badly by the dilution of editing useless early-development genes"?
I guess another thing I'm wondering about, is how we could tell apart genes that impact a trait via their ongoing metabolic activities (maybe metabolic is not the right term... what I mean is that the gene is being expressed, creating proteins, etc, on an ongoing basis), versus genes that impact a trait via being important for early embryonic / childhood development, but which aren't very relevant in adulthood.
Yes, this is an excellent question. And I think it's likely we could (at least for the brain) thanks to some data from this study that took brain biopsies from individuals of varying stages of life and looked at the transcriptome of cells from different parts of the brain.
My basic prior is that the effect of editing is likely to be close to the same as if you edited the same gene in an embryo iff the peak protein expression occurs in adulthood. Though there aren't really any animal experiments that I know of yet which look at how the distribution of effect sizes vary by trait and organ.
I completely endorse this viewpoint for non-genetic interventions.
I feel reticent to endorse this for genetic interventions: I expect to more frequently have strange, unpredictable, high-magnitude negative effects. I do not know if this intuition is scientifically justified.
Suppose you want to decrease your risk of heart disease. The conventional advice goes something like this:
An alternative strategy might be some kind of genetic intervention. For example, an active clinical trial by Verve Therapeutics aims to treat individuals with inherited high cholesterol by editing the PCSK9 gene.
These trials almost always start the same: there’s some rare disorder caused by a single gene. We have a strong mechanical understanding of how the gene causes the disorder. We use an animal model with an analogous disorder and show that by changing the gene we fix or at least ameliorate the condition.
This is the traditional approach. And despite being slow and limited in scope, it occasionally produces results like Casgevy, a CRISPR-based treatment for sickle cell and beta thallasemia which was approved by the UK in mid-November.
It might cost several million dollars. But it cures sickle cell! That has to count for something.
Most diseases, however, are not like sickle cell or beta thalassemia. They are not caused by one gene. They are caused by the cumulative effects of thousands of genes plus environmental factors like diet and lifestyle.
If we actually want to treat these disorders, we need to start thinking about biology (and genetic treatments) differently.
Black Box Biology
I think the conventional approach to genes and disorders is fundamentally stupid. In seeking absolute certainty about cause and effect, it limits itself to a tiny niche with limited importance. It’s as if machine learning researchers decided that the best way to build a neural network was to hand tune model parameters based on their intricate knowledge of feature representations.
You don’t need to understand the mechanism of action. You don’t need an animal model of disease. You just need a reasonable expectation that changing a genetic variant will have a positive impact on the thing you care about.
And guess what? We already have all that information.
We’ve been conducting genome-wide association studies for over a decade. A medium-sized research team can collect data from 180,000 diabetics and show you 237 different spots in the genome that affect diabetes risk with a certainty level of P < 5*10^-9!
In expectation, editing all those variants could decrease someone’s diabetes risk to negligible levels.
I predict that in the next decade we are going to see a fundamental shift in the way scientists think about the relationship between genes and traits. The way treatments change outcomes is going to become a black box and everyone will be fine with it because it will actually work.
We don’t need to understand the mechanism of action. We don’t need to understand the cellular pathway. We just need enough data to know that when we change this particular base pair from an A to a G, it will reduce diabetes risk by 0.3%.
That’s enough.