I currently believe it’s unlikely that Claude-3 will cause OpenAI to release their next model any sooner (they released GPT4 on Pi day after all), nor for future models
There's now a perception that Claude is better than ChatGPT and I don't believe that Sam Altman will allow that to persist for long.
Could you go into more details on how this would work? For example, Sam Altman wants to raise more money, but can't raise as much since Claude-3 is better. So he waits to raise more money after releasing GPT-5 (so no change in behavior except when to raise money).
If you argue releasing GPT-5 sooner, that time has to come from somewhere. For example, suppose GPT-4 was release ready by February, but they wanted to wait until Pi day for fun. Capability researchers are still researching capabilities in the meantime regardless ff they were pressured & instead relased 1 month earlier.
Maybe arguing that earlier access allows more API access so more time finagling w/ scaffolding?
The amount of testing that is required before release is likely subjective and this might push him to reduce this.
Yup, I basically agree with this. Although we shouldn't necessarily only focus on OpenAI as the other possible racer. Other companies (Microsoft, Twitter, etc) might perceive a need to go faster / use more resources to get a business advantage if the LLM marketplace seems more crowded.
Capabilities leakages don’t really “increase race dynamics”.
Do people actually claim this? Shorter timelines seems like a more reasonable claim to make. To jump directly to impacts on race dynamics is skipping at least one step.
Cross-posted to EA forum
There’s been a lot of discussion among safety-concerned people about whether it was bad for Anthropic to release Claude-3. I felt like I didn’t have a great picture of all the considerations here, and I felt that people were conflating many different types of arguments for why it might be bad. So I decided to try to write down an at-least-slightly-self-contained description of my overall views and reasoning here.
Tabooing “Race Dynamics”
I’ve heard a lot of people say that this “is bad for race dynamics”. I think that this conflates a couple of different mechanisms by which releasing Claude-3 might have been bad.
So, taboo-ing “race dynamics”, a common narrative behind these words is
It’s unclear what “at the expense of safety” means, so we can investigate two different interpretations::
If X increases “race dynamics”, X causes an AGI company to
Did releasing Claude-3 cause other AI labs to invest less in evals/redteaming models before deployment?
If OpenAI releases their next model 3 months earlier as a result. These 3 months need to come from *somewhere*, such as:
A. Pre-training
B. RLHF-like post-training
C. Redteaming/Evals
D. Product development/User Testing
OpenAI needs to release a model better than Claude-3, so cutting corners on Pre-training or RLHF likely won’t happen. It seems possible (C) or (D) would be cut short. If I believed GPT-5 would end the world, I would be concerned about cutting corners on redteaming/evals. Most people are not. However, this could set a precedent for investing less in redteaming/evals for GPT-6 onwards until AGI which could lead to model deployment of actually dangerous models (where counterfactually, these models would’ve been caught in evals).
Alternatively, investing less in redteaming/evals could lead to more of a Sydney moment for GPT-5, creating a backlash to instead invest in redteaming/evals for the next generation model.
Did releasing Claude-3 divert resources away from alignment research & into capabilities research?
If the alignment teams (or the 20% GPUs for superalignment) got repurposed for capabilities or productization, I would be quite concerned. We also would’ve heard if this happened! Additionally, it doesn’t seem possible to convert alignment teams into capability teams efficiently due to different skill sets & motivation.
However, *future* resources haven’t been given out yet. OpenAI could counterfactually invest more GPUs & researchers (either people switching from other teams or new hires) if they had a larger lead. Who knows!
Additionally, OpenAI can take resources from other parts such as Business-to-business products, SORA, and other AI-related projects, in order to avoid backlash from cutting safety. But it’s very specific to the team being repurposed if they could actually help w/ capabilities research. If this happens, then that does not seem bad for existential risk.
Releasing Very SOTA Models
Claude-3 isn’t very far in the frontier, so OpenAI does have less pressure to make any drastic changes. If, however, Anthropic released a model as good as [whatever OpenAI would release by Jan 2025], then this could cause a bit of a re-evaluation of OpenAI’s current plan. I could see a much larger percentage of future resources to go to capabilities research & attempts to poach Anthropic employees in-the-know.
Anthropic at the Frontier is Good?
Hypothetically if Anthropic didn’t exist, would OpenAI counterfactually invest more in safety research? My immediate intuition is no. In fact, I don’t think OpenAI would’ve created their version of RSPs either, which is a mix of AI research & commitments (although I believe ARC-evals/now-METR started RSPs so OpenAI might’ve released RSPs due to that influence?)
One could argue that Anthropic caused OpenAI to invest *more* resources into alignment research than they would’ve. One could counter-argue that OpenAI could’ve invested the same resources in other alignment areas as opposed to “catching up” in RSPs/etc (although RSPs are pretty good relative to whatever else they could’ve done at the time, imo).
So, there is a real effect where Anthropic being near the frontier has allowed them to become trendsetters for the other labs, leading to more resources being used for safety.
There’s an additional point that Anthropic releasing Claude-3 allows them to gain more resources. Some of these are taken from OpenAI’s profit margins; others from a higher valuation.
I don’t think Anthropic having more resources will cause Anthropic to skimp on redteaming/evals or divert resources away from alignment to capabilities. In fact, I believe that extra resources will be poured into evals & other alignment work.
However, both of these points rely on you liking/trusting Anthropic’s current safety work that they’ve trendsetted & published. One can argue that Anthropic being in the frontier is bad because they’re anchoring AGI labs on safety research that *won’t work*, so it’s actually negative because they’re leading everyone into a false sense of security.
The tradeoff overall then, is whether Anthropic staying on the frontier & acquiring resources is worth the potential risk of OpenAI not redteaming/evaluating their models as much or OpenAI investing less in alignment in the long-term.
What I Currently Think
I currently believe it’s unlikely that Claude-3 will cause OpenAI to release their next model any sooner (they released GPT4 on Pi day after all), nor for future models. I think it’s possible they counterfactually invest less in alignment then they would’ve if they had a larger lead (w/ Anthropic being one part of that & Google DeepMind being the other).
I also believe that, historically, Anthropic being at the frontier has had positive effects on OpenAI’s alignment research & commitments (maybe Google Deepmind will release RSPs themselves sometime too?), and Anthropic having more resources is net-positive for leading to aligned AGI.
Conclusion
There are many stances people can have regarding “race dynamics”.
There is also an opposing Anthropic-specific viewpoint:
This is likely not all particular stances, so please mention them in the comments!
I would like to especially thank Buck Shlegeris, Zach Stein-Perlman, & Carson Ezell for comments & discussion.
Appendix:
Capabilities Leakage
Capabilities leakages don’t really “increase race dynamics”. If you publish research that significantly increases in SOTA on [Transformer-RL-3000], that doesn’t mean that OpenAI will skimp on redteaming/evals or counterfactually invest less in Alignment research. You can argue this is negative *for other reasons*, but I’m only saying it’s not the same as a race dynamics argument.
There are a few paths to capabilities leakage:
Directly publishing capabilities detailsArchitecture details being inferrable with API access(1) A recent paper was able to reverse-engineer the model dimension & weights of the unembedding layer of LLMs only through the API. Their method does not extend to learning the weights of other layers due to nonlinearities; however, they did show you could learn if the model used RMSNorm or LayerNorm using a very similar method. Other architectural details might also be inferrable. However, I don’t predict anything that actually makes Claude-3 SOTA will be inferred from the API.
(2) is more of an argument whether Anthropic should pursue capability increases *at all*, because they can do internal research, never release a product, and still have employees tell others at e.g. parties or get hired by other orgs. The cruxes for me would then be (A) does Anthropic select x-risk caring people to work on their capabilities research & (A.2) is there historical precedence for employees leaving for capabilities research. Both of which I don’t have enough information to speculate on.
But again, this isn’t relevant to whether releasing Claude-3 as a product is net-negative.
(3) is a solid argument, imo.
A few years ago, OpenAI released the capability for GPT to insert text. But how could a uni-directional model insert text? GPT transformers can only output the next token, not middle tokens like BERT. Janus speculated that OpenAI could easily generate massive amounts of data for this by formatting data like
Original Data: [Paragraph-1] [Paragraph-2] [Paragraph-3]
Formatted Training Data: [Paragraph-1] [Paragraph-3] <|specialtoken|> [Paragraph-2]
Then, during deployment, users can format text like:
User Data: [Paragraph-1] <|specialtoken|> [Paragraph-3]
Formatted Data: [Paragraph-1] [Paragraph-3] <|specialtoken|> [GPT write this part]
So from just hearing that OpenAI developed a capability, a researcher familiar w/ LLMs can speculate “Oh maybe they trained it this way”.
The same could be true for Claude-3 which is indeed SOTA.\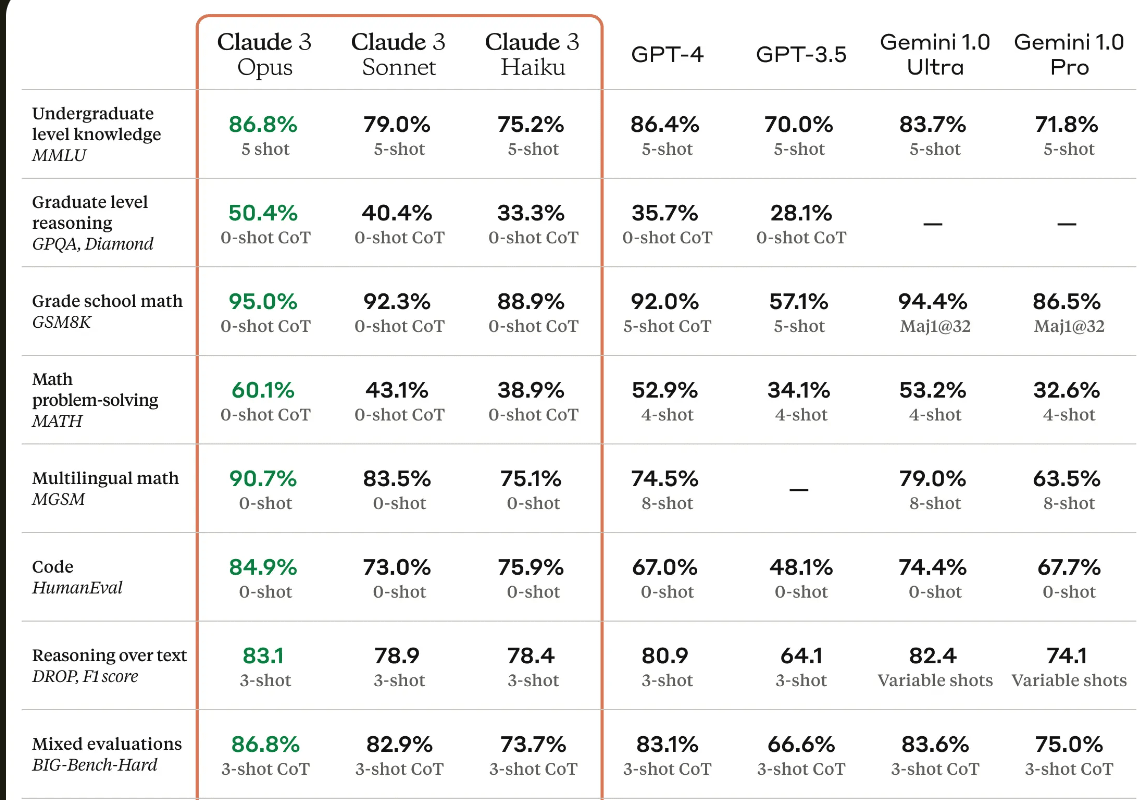
So this now becomes dependent on whether any capability advances specific to Claude-3 are ones that OpenAI doesn’t already have (after 12 months after GPT-4). If OpenAI is currently not able to hit the results of the evals, then it’s plausible they could be inspired to speculate how Anthropic achieved these results; to focus their research attention on areas that aren’t dead-ends.
Additionally, Gemini Ultra evaluations came out before Claude-3, so the counterfactual impact has to include capability advances that are only specific to Claude-3 & not Gemini.
This is mainly a question that OpenAI employees will know the answer to, but my personal speculation is that there aren’t novel capability advances that OpenAI doesn’t already know.
However, this would only have a marginal impact. I could see a -3 months effect on timelines at worse.
Is Increasing Capabilities Bad?
Capabilities research is not bad on its own. Increased capabilities in coding, math, and idea generation could help automate alignment research. Increased bio-weapon capabilities (& evals) could allow larger government asks such as moratoriums on large training runs or confiscation of large compute clusters.
My current framework on this topic is heavily based off of Charlie’s Excellent post (I highly recommend). He argues you should view research (alignment or capabilities) as unlocking branches in a tech tree, where some branches end in aligned superintelligences (yay) & others in misaligned superintelligences (booo).
It makes sense to consider each piece of research w/ the existing research & political landscape, but I’ll leave a fuller exploration of tech trees to future posts.