Interesting post! I'm pretty curious about these.
A great resource for answering these questions is a set of model runs put out by the Stanford Center for Research into Foundation Models - they trained 5 runs of GPT-2 small and GPT-2 medium with 600 checkpoints and different random seeds, and released the weights. It seems like a good way to get some surface area on these questions with interesting real models. A few ideas that are somewhere on my maybe/someday research ideas list:
- For each pair of models, feed in a bunch of text and look at the log prob for predicting each next token, and look at the scatter plot of these - does it look highly correlated? Poke at any outliers and see if there are any consistent patterns of things one model can do and the other cannot
- Repeat this for a checkpoint halfway through training. If you find capabilities in one model and not in another, have they converged by the end of training?
- Look at the PCA of these per-token losses across, say, 1M tokens of text, and see if you can find anything interesting about the components
- Evaluate the models for a bunch of behaviours - ability to use punctuation correctly, to match open and close parentheses, patterns in the syntax and structure of the data (capital letters at the start of a sentence, email addresses having an @ and a .com in them, taking text in other languages and continuing it with text of that language, etc), specific behaviour like the ability to memorise specific phrases, complete acronyms, use induction-like behaviour, basic factual knowledge about the world, etc
- The medium models will have more interesting + sophisticated behaviour, and are probably a better place to look for specific circuits
- Look at the per-token losses for some text over training (esp for tokens with significant deviation between final models) and see whether it looks smooth or S-shaped - S-shaped would suggest higher path dependence to me
- Look for induction head phase changes in each model during training, and compare when they happen.
I'm currently writing a library for mechanistic interpretability of LLMs, with support for loading these models + their checkpoints - if anyone might be interested on working on this, happy to share ideas. This is a small subset of OpenWebText that seems useful for testing.
Unrelatedly, a mark against path dependence is the induction head bump result, where we found that models have a phase change where they suddenly form induction heads, and that across a range of model sizes and architecture it forms consistently and around the same point (though not all architectures tested). Anecdotally, I've found that the time of formation is very sensitive to the exact positional embeddings used though.
Sections 3.1 and 6.6 titled "Ossification" of "Scaling Laws for Transfer" paper (https://arxiv.org/abs/2102.01293) show that current training of current DNNs exhibits high path dependence.
When you talk about whether we're in a high or low path-dependence "world", do you think that there is a (somewhat robust) answer to this question that holds across most ML training processes? I think it's more likely that some training processes are highly path-dependent and some aren't. We definitely have evidence that some are path-dependent, e.g. Ethan's comment and other examples like https://arxiv.org/abs/2002.06305, and almost any RL paper where different random seeds of the training process often result in quite different results. Arguably I don't think we have conclusive of any particular existing training process being low-path dependence, because the burden of proof is heavy for proving that two models are basically equivalent on basically all inputs (given that they're very unlikely to literally have identical weights, so the equivalence would have to be at a high level of abstraction).
Reasoning about the path dependence of a training process specifically, rather than whether all of the ML/AGI development world is path dependent, seems more precise, and also allows us to reason about whether we want a high or low path-dependence training process, and considering that as an intervention, rather than a state of the world we can't change.
Yeah, I agree with that. I think path dependence will likely vary across training processes and that we should in fact view that as an important intervention point.
Betting markets on these questions would be nice. I'd bid pretty strongly on "nope, basically no path dependence" for most current architectures; replicability already gives us a ton of bits on the question.
I'd happily take the other side of that bet. E.g., look at this website for an example of training a 500 neuron wide, 2-layer fully connected ReLu network on toy data, with a selector that lets you apply regularizers to the training process. If you simply train with no regularizer, you get the following decision boundary:
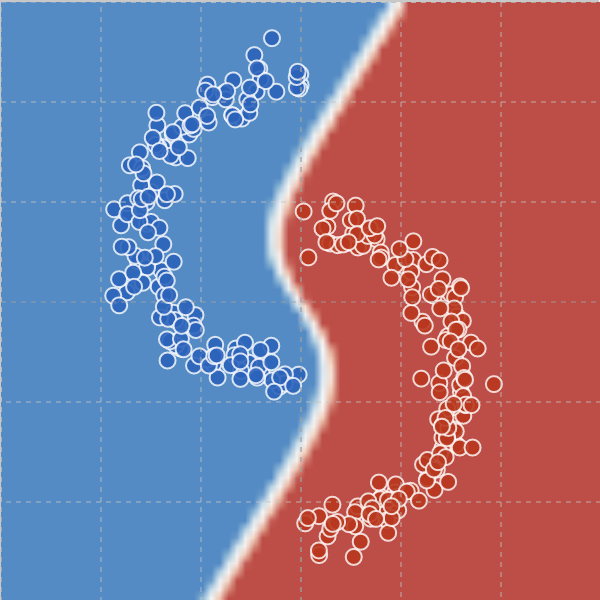
If you train with an L1 regularizer, you get this boundary:
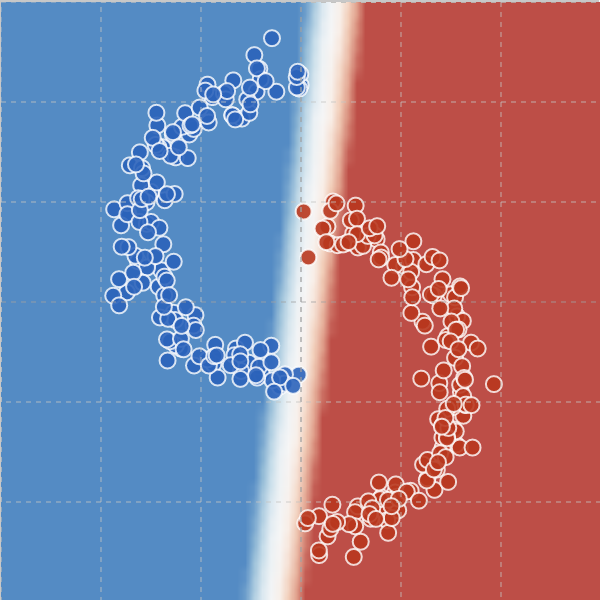
However, if you first train with the L1 regularizer for ~ 100 steps, then switch over to no regularizer, you get this boundary, which persists for at least 5,000 training steps:
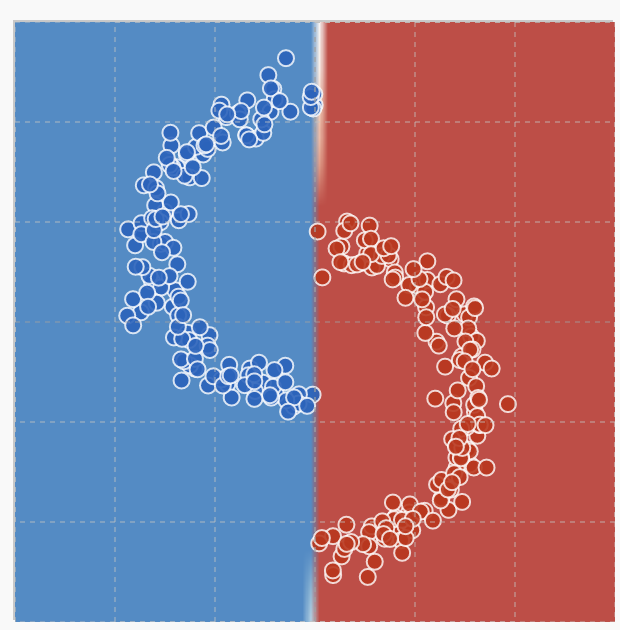
If we were going to find path-independence anywhere, I think it would be in these sorts of very simple datasets, with wide, highly overparameterized models, trained on IID data using exact gradients. But even here, SGD seems quite path dependent.
Edited to add:
...replicability already gives us a ton of bits on the question.
I think this is false. For a given architecture + training process, it's entirely possible for there to be an attractor into which 99.9999999999999% of all randomly initialized training processes fall, but for it to still be highly path dependent in the relevant sense. The reason is because it's actually quite easy for "simple nudges" to apply the ~ 50 bits of optimization pressure needed to make a 0.0000000000001% outcome happen. E.g., training for 100 steps with an L1 regularizer will get you a model that's incredibly unlikely to be sampled by your random initialization process.
It can be the case that almost all random initializations train out to the same end state, and also that fairly simple interventions can put the training trajectory on the path to a different end state.
Broadly agree with this comment. I'd buy something like "low path-dependence for loss, moderate-to-high for specific representations and behaviours" - see e.g. https://arxiv.org/abs/1911.02969
I think this is false. For a given architecture + training process, it's entirely possible for there to be an attractor into which 99.9999999999999% of all randomly initialized training processes fall, but for it to still be highly path dependent in the relevant sense. The reason is because it's actually quite easy for "simple nudges" to apply the ~ 50 bits of optimization pressure needed to make a 0.0000000000001% outcome happen. E.g., training for 100 steps with an L1 regularizer will get you a model that's incredibly unlikely to be sampled by your random initialization process.
It can be the case that almost all random initializations train out to the same end state, and also that fairly simple interventions can put the training trajectory on the path to a different end state.
I think we actually have the same model here, but interpret the phrase "path dependence" differently. If the question is whether we can intentionally apply 50 bits of optimization to kick the thing into a different attractor, then yeah, I agree that is very probably possible. I just wouldn't call that "path dependence", since on the distribution of the training process the path basically does not matter.
If SGD is approximately a Bayesian sampler, ...
I think it's worth noting that no large-scale system uses 'true' SGD; it's all ADAM-W and the weight decay seems like a strong part of the inductive bias. Of course "everything that works is approximately Bayesian", but the mathematics that people talk about with respect to SGD just aren't relevant to practice.
(opinions my own)
Definitely glad to see some investigation into the path dependence question.
I expect that the primary source of safety-relevant path dependence in future systems will be due to causal influence of the model's behavior on its training data / supervision signal. That should occur by default in reinforcement & active learning, but not in typical teacher-forced self-supervised learning (like GPT). So I think I would answer the question of "Are we in a high path-dependence world?" differently conditioned on different AI development models.
Even for GPTs, the recently popular "chain-of-thought" family of techniques seem poised to bring path-dependence into the mix, by creating feedback loops between the language model and the reasoning traces it produces.
This paper links inductive biases of pre-trained [language] models (including some related to simplicity measures like MDL), path dependency and sensitivity to label evidence/noise: https://openreview.net/forum?id=mNtmhaDkAr
In this post, we define path dependence as the sensitivity of a model's behavior to the details of the training process and training dynamics.[1] High path-dependence indicates that small changes to the training process can cause significant changes to how the final model generalizes (such as the details of off-distribution behavior). It implies that inner alignment can be reasoned about by thinking about what the model looks like at various stages of training, and how its structure is affected by the immediate pressures of gradient descent. It implies that early-training interventions can be quite potent in shaping how a model turns out, and that a proper theory of inductive bias must reason about the order in which features are learned (where features learned faster/earlier can “screen off” the need for other implementations of a similar niche, in a way that affects the final model).
In contrast, a world with low path dependence allows us to reason about inductive bias in terms of priors and updates, sparing the details of training dynamics. It is more pessimistic about the ability to steer the model’s ontology through early interventions, believing instead that the final result is overdetermined. As Evan discusses in a previous post, it makes us less worried about variance in alignment outcomes between labs, since small changes to the training procedure don’t strongly affect alignment outcomes.
Possible mechanistic reasons for high path dependence would include the existence of distinct stable ontologies, the ability for early features to kill gradients, and the difficulty of building highly serial features whose components aren't independently useful. Mechanistic reasons for low path dependence would include grokking-like phase transitions which wipe out early circuits, overdetermination of correct ontologies, and an abundance of low loss paths between seemingly dissimilar solutions.[2]
We remain mostly agnostic about which world we are in. The purpose of this post is to elucidate the various strands of path dependence, and their implications for alignment. We hope it will encourage people to run experiments determining where reality falls on these spectra.
Path dependence
Fundamentally, path dependence is about the sensitivity of a model's behavior to the details of the training process and training dynamics. In this section, we enumerate concrete claims which constitute path dependence. It should be emphasized that it is conceivable for these properties to vary separately, and that we lump them together because we hypothesize without proof that they are correlated.
In a world with maximum path dependence:
By contrast, in a world with minimum path dependence:
Diagrams for training dynamics
Low path dependence #1:
Above, we see an simple example of low-path-dependence training dynamics -- The order in which features are learned doesn't matter, so a change to the training procedure which makes A learned faster than B won't change the final outcome.
High path dependence #1:
Here, there are two reachable end states, and early interventions can affect which one we end up in. Features C and D are mutually exclusive, and are facilitated by A and B respectively. There might be a grokking-like path from one of the apparent final states to the other, but training is stopped before it occurs.
If feature "D" is associated with deceptive alignment, and "C" with corrigibility, then detecting one or the other in the second-to-last phase is a reliable indicator of the final behavior.
Low path dependence #2:
In this model, there appears to be path dependence at first, but component E destroys C and D when it arises. Any safety properties associated with C are destroyed at the last minute, despite appearing stable until then.
Reasons to care about path dependence
In this section, we go through some implications of path dependence for alignment. In general, higher path dependence is good news for early evaluations and interventions, and (more speculatively) for being able to shape model ontology. However, it is bad news for consistency across labs, and for solutions to inner alignment which rely on the construction of pure theoretical priors (like circuit priors).
I. Effectiveness of mid-training evaluation
High path dependence makes mid-training evaluations more reliable, due to the "stickyness"/persistence of model properties. Suppose we want to do things like:
Let's say we can do one of these things in the early and middle stages of training, when the model is somewhat simpler / less intelligent, but not on the final model. In a high path-dependence world, there is a good chance that the result of the early check is also valid for the final model. In a low path-dependence world, the early check is invalidated by phase transitions, circuit destruction, fundamental reorganizations of the model to an overdetermined "correct" structure, etc.
II. Generalization of concepts and goals
A major issue in alignment is the question of how a model will generalize from the domain where we are able to label outcomes to the domain where we can't. Here are a some examples:
High path-dependence is beneficial here, implying continuity of properties like "honest answering".
III. Effectiveness of interventions
If mid-training evaluations are valid, then a further desideratum would be for mid-training interventions to be effective. This could matter for certain forms of adversarial training—you can imagine a world where mid-training diagnostics work fine on natural models, but adversarial training at the middle stages just builds "shallow patches" which aren't well embedded in the main control flow and are erased by training dynamics in the later stages of training. High path dependence is again desirable here.
IV. Consistency across labs
In a high-path-dependence world, we might need to enforce a high degree of exactness in how training procedures are implemented by different labs (especially if alignment is more sensitive to changes in training procedure than capabilities are, which seems likely). On the other hand, path dependence might help us here if alignment and capabilities are closely coupled, in the sense that copying a training procedure and changing it would also break capabilities.
V. Constructability of priors
In a high-path-dependence world, it is hard to construct something close to a “pure” theoretical prior. This could be bad if the most promising alignment solution ends up needing a specific prior. Examples of theoretical priors are the Solomonoff prior (punishes program length), the circuit prior (punishes circuit size), and the speed prior (punishes serial runtime). If SGD is approximately a Bayesian sampler,[4] then it could be possible approximate certain combinations of these priors. However, if path dependence is high enough, then these priors should be almost impossible to construct, due to vast differences in the findability of solutions (the existence of training paths to these solutions, and whether these paths are fast enough to not have their gradients stolen/ruined by other features).
VI. Likelihood of inner misalignment
Arguments around the likelihood of deceptive alignment and of misaligned proxies often depend strongly on path dependence. See Evan's recent post for a thorough discussion of how path dependence affects deceptive alignment.
Specific aspects of training dynamics
At the moment, “path dependence” is really a cluster of related properties which we suspect to be correlated. In this section, we lay out a full set of distinct concepts. Many of these can be thought of as mechanistic sources of high/low path dependence.
A. Variance across runs
Suppose we run training several times, with different random seeds. How much will the final models differ from each other? We are interested in both generalization behavior and internal representations. At a higher capability level, we would be interested in properties like “deceptiveness” and “goal”—do these vary across training runs?
B. Sensitivity to small changes in the training setup
How much do the properties of the final model differ if we change the training setup slightly? For instance, if two different labs each train a language model with broadly the same architecture and approach, but all the implementation details differ, how similar will their behavior and internal properties be?
C. Existence of distinct clusters
Suppose we train some language models (with different seeds or slightly different setups), and we look at a very specific property like:
If the models differ on one of these questions, there are two ways it could happen:
Hypothetical examples:
D. Stability of clusters across training
If stability of clusters is true, this is what it would look like:
If there are two distinct clusters which a model can fall under, like “encodes apple color in neurons” vs. “encodes apple color in an attention head”, then it will fall into one of these clusters early in training, and will stay in that cluster until the end. Each cluster will be stable to small perturbations—if we nudge the parameters slightly toward the other solution, then further training will bring us back to the center of the “valley” around the old solution. However, if we make a strong enough intervention, we will push the model over the ridge to the other stable attractor, and it will remain in that cluster all the way through training. So there will be a bimodal effect: either the intervention decays away almost completely, or it successfully pushes us to the other attractor and sticks fully.
E. Predictive power of the mid-training model
Suppose that important properties of the model vary across runs or setups. In this case, can we predict how the final model is going to turn out by pausing in the middle of training and inspecting the model? For instance, if we’re training an RL agent, and it ends up with the wrong proxy 50% of the time, can we pause early on in training and predict which version we will get?
F. Sensitivity to early interventions
Some examples of interventions would be:
The question here is: Suppose we can only intervene in the early and middle stages of training. How sensitive are the properties of the final model to our interventions?
G. Survival of circuits
Closely related to (D), (E), and (F) is the survival of circuits and representations across training. Some circuits will be learned early on and remain unchanged throughout training. For properties associated with these circuits, the mid-training model will be perfectly predictive of the final model. Other circuits will be wiped out and replaced with new ones.
One important question here is whether there will be some kind of "general intelligence circuitry" which develops late in training and wipes out large swathes of earlier circuits, by virtue of being more efficient in terms of "cases handled per parameter of circuitry". Such a phenomenon would be devastating for the sort of path dependence we discuss here.
More survival of circuits means higher path dependence, since it allows the speeds at which different early circuits are formed to be more influential on the final model.
H. Existence of closed form inductive bias
Suppose we have two computational graphs which solve a task, and we want to know which one is more likely to be isomorphic to the model resulting from training. A closed form inductive bias lets us figure this out by inspection.
A simple example is a circuit prior, where we simply count the number of nodes and/or connections (depending on how you define it), and say that the one with fewer nodes/connections is more likely to be found.
However, a closed form is allowed to be more complex than this. For instance, we could have some mix of a circuit prior with depth penalties, modularity bonuses, an information loss related term, and so forth.
A non-closed-form understanding of inductive bias would be something like "Here's a rule for figuring out which circuits will be built in the first 10% of training. Run that rule on your dataset and architecture, and write down the circuits. Now here's a rule for what will be learned in the next 10%, which depends on the circuits we already have. And so forth for the rest of training."
The thing which makes it not a closed form is that you have to reason through it step-by-step; you can't skip to end and say "well it all caches out to picking the simplest final solution". This is a very path-dependent way for things to be.[5]
If we are in such a world, then it is harder to construct a training process which gives us a "pure" circuit prior, or any other theoretical prior we might want.
A question about predictiveness
A simpler way to operationalize path dependence is to think about the following two questions:
A single axis model of path dependence assumes that these two types of consistency are anti-correlated, but it's not clear to us whether this is the case. We leave it as an open question.
Conclusion
Given the implications of path dependence for thinking about alignment, it would be good to find out which world we're in. Each concept (A-H) in the previous section is a yes/no question[6] to be empirically resolved. The exact answer will vary by task and architecture. However, we hypothesize that there is probably some principal component across all tasks, architectures, and concepts, a "General factor of path dependence".
If you would like to run path dependence experiments, please leave a comment or send us a message, and we can get in touch.
Mechanistically, high path dependence corresponds to significant influence and continuity from the structure and ontology of the early model to its final structure, and low path-dependence to destruction/radical transformation of early structures and overdetermination/stability of the final result.
"Dissimilar solutions" = Different factorizations of the task into circuits. The low-path-dependence argument here is that "paths are always abundant in high-dimensional spaces".
I'm avoiding the term "goal" since I don't presume consequentialism.
See one of these reviews. I mostly disbelieve the qualitative conclusions people draw from this work though, for reasons that deserve their own post.
All this means right now is "It gives us strong path-dependence vibes, so it's probably correlated with the other stuff"
Really a spectrum.