Agreed that this (or something near it) appears to be a relatively central difference between people's models, and probably at the root of a lot of our disagreement. I think this disagreement is quite old; you can see bits of it crop up in Hanson's posts on the "AI foom" concept way back when. I would put myself in the camp of "there is no such binary intelligence property left for us to unlock". What would you expect to observe, if a binary/sharp threshold of generality did not exist?
A possibly-relevant consideration in the analogy to computation is that the threshold of Turing completeness is in some sense extremely low (see one-instruction set computer, Turing tarpits, Rule 110), and is the final threshold. Rather than a phase shift at the high end, where one must accrue a bunch of major insights before one has a system that they can learn about "computation in general" from, with Turing completeness, one can build very minimal systems and then--in a sense--learn everything that there is to learn from the more complex systems. It seems plausible to me that cognition is just like this. This raises an additional question beyond the first: What would you expect to observe, if there...
Thanks! Appreciate that you were willing to go through with this exercise.
I would expect to observe much greater diversity in cognitive capabilities of animals, for humans to generalize poorer, and for the world overall to be more incomprehensible to us.
[...]
we'd look at the world, and see some systemic processes that are not just hard to understand, but are fundamentally beyond reckoning.
Per reductionism, nothing should be fundamentally incomprehensible or fundamentally beyond reckoning, unless we posit some binary threshold of reckoning-generality. Everything that works reliably operates by way of lawful/robust mechanisms, so arriving at comprehension should look like gradually unraveling those mechanisms, searching for the most important pockets of causal/computational reducibility. That requires investment in the form of time and cumulative mental work.
I think that the behavior of other animals & especially the universe as a whole in fact did start off as very incomprehensible to us, just as incomprehensible as it was to other species. In my view, what caused the transformation from incomprehensibility to comprehensibility was not humans going over a sharp cognitive/archite...
I think I am confused where you're thinking the "binary/sharp threshold" is.
Are you saying there's some step-change in the architecture of the mind, in the basic adaption/learning algorithms that the architecture runs, in the content those algorithms learn? (or in something else?)
If you're talking about...
- ... an architectural change → Turing machines and their neural equivalents, for example, over, say, DFAs and simple associative memories. There is a binary threshold going from non-general to general architectures, where the latter can support programs/algorithms that the former cannot emulate. This includes whatever programs implement "understanding an arbitrary new domain" as you mentioned. But once we cross that very minimal threshold (namely, combining memory with finite state control), remaining improvements come mostly from increasing memory capacity and finding better algorithms to run, neither of which are a single binary threshold. Humans and many non-human animals alike seem to have similarly general architectures, and likewise general artificial architectures have existed for a long time, so I would say "there indeed is a binary/sharp threshold [in architectures] but it
an architectural change → Turing machines and their neural equivalents
This, yes. I think I see where the disconnect is, but I'm not sure how to bridge it. Let's try...
To become universally capable, a system needs two things:
- "Turing-completeness": A mechanism by which it can construct arbitrary mathematical objects to describe new environments (including abstract environments).
- "General intelligence": an algorithm that can take in any arbitrary mathematical object produced by (1), and employ it for planning.
General intelligence isn't Turing-completeness itself. Rather, it's a planning algorithm that has Turing-completeness as a prerequisite. Its binariness is inherited from the binariness of Turing-completeness.
Consider a system that has (1) but not (2), such as your "memory + finite state control" example. While, yes, this system meets the requirements for Turing-complete world-modeling, this capability can't be leveraged. Suppose it assembles a completely new region of its world-model. What would it do with it? It needs to leverage that knowledge for constructing practically-implementable plans, but its policy function/heuristics is a separate piece of cognition. So either needs:
- To
Ok I think this at least clears things up a bit.
To become universally capable, a system needs two things:
- "Turing-completeness": A mechanism by which it can construct arbitrary mathematical objects to describe new environments (including abstract environments).
- "General intelligence": an algorithm that can take in any arbitrary mathematical object produced by (1), and employ it for planning.
General intelligence isn't Turing-completeness itself. Rather, it's a planning algorithm that has Turing-completeness as a prerequisite. Its binariness is inherited from the binariness of Turing-completeness.
Based on the above, I don't understand why you expect what you say you're expecting. We blew past the Turing-completeness threshold decades ago with general purpose computers, and we've combined them with planning algorithms in lots of ways.
Take AIXI, which uses the full power of Turing-completeness to do model-based planning with every possible abstraction/model. To my knowledge, switching over to that kind of fully-general planning (or any of its bounded approximations) hasn't actually produced corresponding improvements in quality of outputs, especially compared to the quality gains we get ...
I think what I'm trying to get at, here, is that the ability to use these better, self-derived abstractions for planning is nontrivial, and requires a specific universal-planning algorithm to work. Animals et al. learn new concepts and their applications simultaneously: they see e. g. a new fruit, try eating it, their taste receptors approve/disapprove of it, and they simultaneously learn a concept for this fruit and a heuristic "this fruit is good/bad". They also only learn new concepts downstream of actual interactions with the thing; all learning is implemented by hard-coded reward circuitry.
Humans can do more than that. As in my example, you can just describe to them e. g. a new game, and they can spin up an abstract representation of it and derive heuristics for it autonomously, without engaging hard-coded reward circuitry at all, without doing trial-and-error even in simulations. They can also learn new concepts in an autonomous manner, by just thinking about some problem domain, finding a connection between some concepts in it, and creating a new abstraction/chunking them together.
Hmm I feel like you're underestimating animal cognition / overestimating how much of what human...
I think my main problem with this is that it isn't based on anything. Countless times, you just reference other blog posts, which reference other blog posts, which reference nothing. I fear a whole lot of people thinking about alignment are starting to decouple themselves from reality. It's starting to turn into the AI version of String Theory. You could be correct, but given the enormous number of assumptions your ideas are stacked on (and that even a few of those assumptions being wrong leads to completely different conclusions), the odds of you even being in the ballpark of correct seem unlikely.
I'm very sympathetic to this view, but I disagree. It is based on a wealth of empirical evidence that we have: on data regarding human cognition and behavior.
I think my main problem with this is that it isn't based on anything
Hm. I wonder if I can get past this common reaction by including a bunch of references to respectable psychology/neurology/game-theory experiments, which "provide scientific evidence" that various common-sensical properties of humans are actually real? Things like fluid vs. general intelligence, g-factor, the global workplace theory, situations in which humans do try to behave approximately like rational agents... There probably also are some psychology-survey results demonstrating stuff like "yes, humans do commonly report wanting to be consistent in their decision-making rather than undergoing wild mood swings and acting at odds with their own past selves", which would "provide evidence" for the hypothesis that complex minds want their utilities to be coherent.
That's actually an interesting idea! This is basically what my model is based on, after a fashion, and it makes arguments-from-introspection "legible" instead of seeming to be arbitrary philosophical n...
Even after thinking through these issues in SERI-MATS, and already agreeing with at least most of this post, I was surprised upon reading it how many new-or-newish-to-me ideas and links it contained.
I'm not sure if that's more of a failure of me, or of the alignment field to notice "things that are common between a diverse array of problems faced". Kind of related to my hunch that multiple alignment concepts ("goals", "boundaries", "optimization") will turn out to be isomorphic to the same tiny-handful of mathematical objects.
On this take, especially with your skepticism of LLM fluid intelligence and generality, is there much reason to expect AGI to be coming any time soon? Will it require design breakthroughs?
Might this paradigm be tested by measuring LLM fluid intelligence?
I predict that a good test would show that current LLMs have modest amounts of fluid intelligence, and that LLM fluid intelligence will increase in ways that look closer to continuous improvement than to a binary transition from nothing to human-level.
I'm unclear whether it's realistic to get a good enough measure of fluid intelligence to resolve this apparent crux, but I'm eager to pursue any available empirical tests of AI risk.
I agree with some of this, although I'm doubtful that the transition from sub-AGI to AGI is as sharp as outlined. I don't think that's impossible though, and I'd rather not take the risk. I do think it's possible to dumb down an AGI if you still have enough control over it to do things like inject noise into its activations between layers...
I'm hopeful that we can solve alignment iff we can contain and study a true AGI. Here's a comment I wrote on another post about the assumptions which give me hope we might manage alignment...
It seems to me like one of t...
I see some value in the framing of "general intelligence" as a binary property, but it also doesn't quite feel as though it fully captures the phenomenon. Like, it would seem rather strange to describe GPT4 as being a 0 on the general intelligence scale.
I think maybe a better analogy would be to consider the sum of a geometric sequence.
Consider the sum for a few values of r as it increases at a steady rate.
0.5 - 2a
0.6 - 2.5a
0.7 - 3.3a
0.8 - 5a
0.9 - 10a
1 - Diverges to infinity
What we see then is quite significant returns to increases in r and then a sudden d...
I think this is insightful pointing correctly to a major source of bifurcation in p(doom) estimates. I view this as the old guard vs. new wave perspectives on alignment.
Unfortunately, I mostly agree with these positions. I'm afraid a lack of attention to these claims may be making the new wave of alignment thinkers more optimistic than is realistic. I do partially disagree with some of these, and that makes my p(doom) a good bit lower than the MIRI 99%. But it's not enough to make me truly optimistic. My p(doom) is right around the 50% "who knows" mark.
I'l...
Your definition of general intelligence would include SGD on large neural networks. It is able to generalize from very few examples, learn and transform novel mathematical objects, be deployed on a wide variety of problems, and so on. Though it seems a pretty weak form of general intelligence, like evolution or general function optimization algorithms. Though perhaps its less general than evolution and less powerful than function optimization algorithms.
If we take this connection at face-value, we can maybe use SGD as a prototypical example for general int...
I agree completely about AGI being like Turing completeness, that there's a threshold. However, there are programming languages that are technically Turing complete, but only a masochist would actually try to use. So there could be a fire alarm, while the AGI is still writing all the (mental analogs of) domain-specific languages and libraries it needs. My evidence for this is humans: we're over the threshold, but barely so, and it takes years and years of education to turn us into quantum field theorist or aeronautical engineer.
But my main crux is that I t...
In-context learning in LLMs maps fairly well onto the concept of fluid intelligence. There are several papers now indicating that general learning algorithms emerge in LLMs to facilitate in-context learning.
Do you think you could find or develop a test of fluid intelligence that LLMs would fail to demonstrate any fluid intelligence in and generally do worse than the vast majority of humans on?
See here, starting from "consider a scheme like the following". In short: should be possible, but seems non-trivially difficult.
Do you think LLMs haven't developed general problem-solving heuristics by seeing lots and lots of problems across domains as well as plenty of fluid intelligence test questions and answers? Wouldn't that count as fluid intelligence?
I think forci...
It's not possible to let an AGI keep its capability to engineer nanotechnology while taking out its capability to deceive and plot, any more than it's possible to build an AGI capable of driving red cars but not blue ones. They're "the same" capability in some sense, and our only hope is to make the AGI want to not be malign.
Seems very overconfident if not plain wrong; consider as an existence proof that 'mathematicians score higher on tests of autistic traits, and have higher rates of diagnosed autism, compared with people in the general population' and c...
Upvoted for clarifying a possibly important crux. I still have trouble seeing a coherent theory here.
I can see a binary difference between Turing-complete minds and lesser minds, but only if I focus on the infinite memory and implicitly infinite speed of a genuine Turing machine. But you've made it clear that's not what you mean.
When I try to apply that to actual minds, I see a wide range of abilities at general-purpose modeling of the world.
Some of the differences in what I think of as general intelligence are a function of resources, which implies a fair...
What ties it all together is the belief that the general-intelligence property is binary.
Do any humans have the general-intelligence property?
If yes, after the "sharp discontinuity" occurs, why won't the AGI be like humans (in particular: generally not able to take over the world?)
If no, why do we believe the general-intelligence property exists?
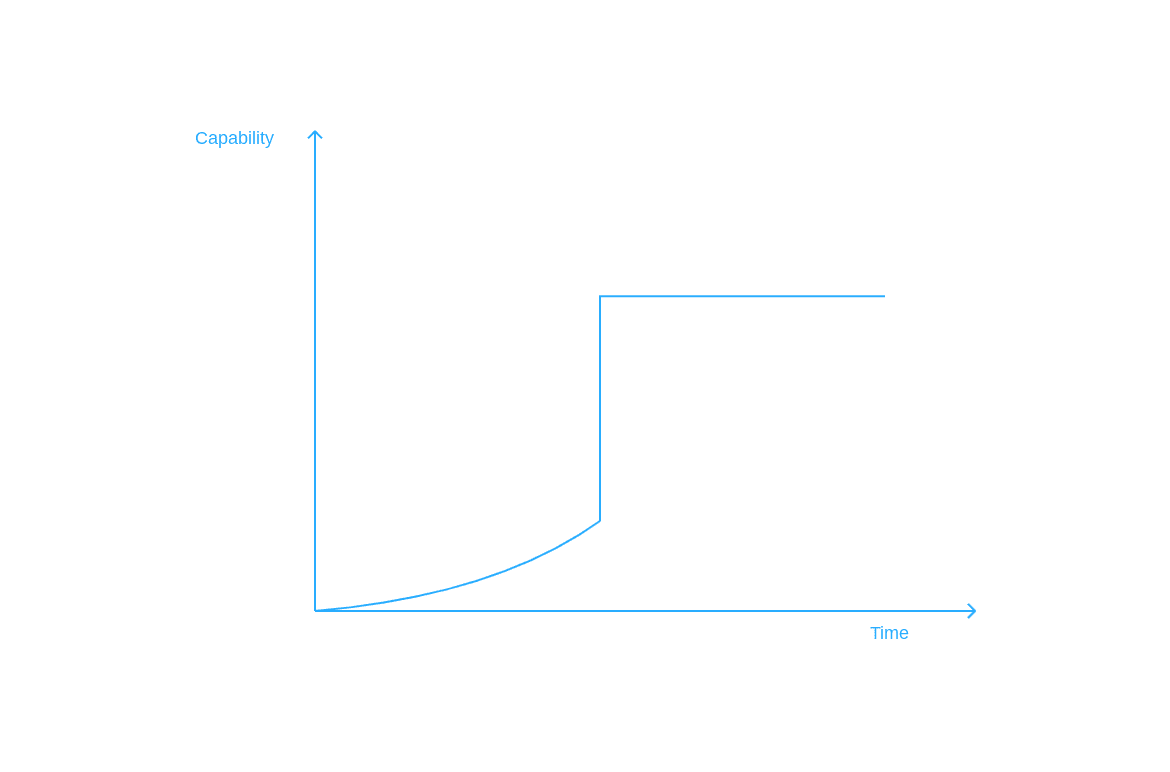
Hm? "Stall at the human level" and "the discontinuity ends at or before the human level" reads like the same thing to me. What difference do you see between the two?
Discontinuity ending (without stalling):
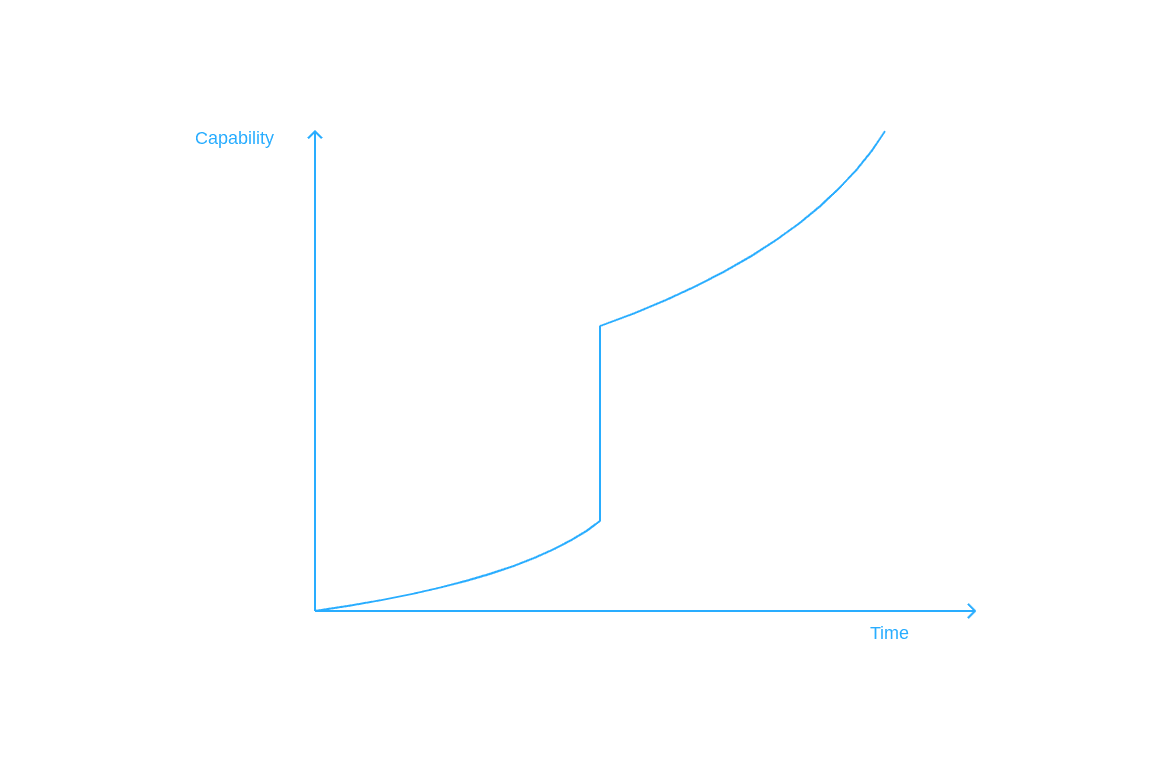
Stalling:
Basically, except instead of directly giving it privileges/compute, I meant that we'd keep training it until the SGD gives the GI component more compute and privileges over the rest of the model (e. g., a better ability to rewrite its instincts).
Are you imagining systems that are built differently from today? Because I'm not seeing how SGD could give the GI component an ability to rewrite the weights or get more compute given today's architectures and training regimes.
(Unless you mean "SGD enhances the GI component until the GI component is able to hack into the substrate it is running on to access the memory containing its own weights, which it can then edit", though I feel like it is inaccurate to summarize this as "SGD give it more privileges", so probably you don't mean that)
(Or perhaps you mean "SGD creates a set of weights that effectively treats the input English tokens as a programming language by which the network's behavior can be controlled, and the GI componen...
About your opinion on LLMs probably not scaling to general intelligence:
What if the language of thought hypothesis is correct, human intelligence can be represented as rules that manipulate natural language, the context window of LLMs is going to become long enough to match a human's "context window", and LLM training is able to find the algorithm?
How does this view fits into your model? What probabilities do you assign to the various steps?
- language of thought hypothesis is correct
- language of thought close enough to natural language
- context window becom
The LessWrong Review runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
Human intelligence is Turing-complete
That may be true, but it isn't an argument for general intelligence in itself.
Theres a particular problem in that the more qualitatively flexible part of the mind...the conscious mind, or system 2...is very limited on its ability to follow a programme, only being able to follow tens of steps reliably. Whereas system 1 is much more powerful but much less flexible.
A general intelligence may also be suppressed by an instinct firing off, as sometimes happens with humans. But that’s a feature of the wider mind the GI is embedded in, not of general intelligence itself.
I actually think you should count that as evidence against your claim that humans are General Intelligences.
Qualitatively speaking, human cognition is universally capable.
How would we know if this wasn't the case? How can we test this claim?
My initial reaction here is to think "We don't know what we don't know".
1. Introduction
The field of AI Alignment is a pre-paradigmic one, and the primary symptom of that is the wide diversity of views across it. Essentially every senior researcher has their own research direction, their own idea of what the core problem is and how to go about solving it.
The differing views can be categorized along many dimensions. Here, I'd like to focus on a specific cluster of views, one corresponding to the most "hardcore", unforgiving take on AI Alignment. It's the view held by people like Eliezer Yudkowsky, Nate Soares, and John Wentworth, and not shared by Paul Christiano or the staff of major AI Labs.
According to this view:
I share this view. In my case, there's a simple generator of it; a single belief that causes my predictions to diverge sharply from the more optimistic models.
From one side, this view postulates a sharp discontinuity, a phase change. Once a system gets to AGI, its capabilities will skyrocket, while its internal dynamics will shift dramatically. It will break "nonrobust" alignment guarantees. It will start thinking in ways that confuse previous interpretability efforts. It will implement strategies it never thought of before.
From another side, this view holds that any system which doesn't have the aforementioned problems will be useless for intellectual progress. Can't have a genius engineer who isn't also a genius schemer; can't have a scientist-modeling simulator which doesn't wake up to being a shoggoth.
What ties it all together is the belief that the general-intelligence property is binary. A system is either an AGI, or it isn't, with nothing in-between. If it is, it's qualitatively more capable than any pre-AGI system, and also works in qualitatively different ways. If it's not, it's fundamentally "lesser" than any generally-intelligent system, and doesn't have truly transformative capabilities.
In the rest of this post, I will outline some arguments for this, sketch out what "general intelligence" means in this framing, do a case-study of LLMs showcasing why this disagreement is so difficult to resolve, then elaborate on how the aforementioned alignment difficulties follow from it all.
2. Why Believe This?
It may seem fairly idiosyncratic. At face value, human cognition is incredibly complex and messy. We don't properly understand it, we don't understand how current AIs work either — whyever would we assume there's some single underlying principle all general intelligence follows? Even if it's possible, why would we expect it?
First, let me draw a couple analogies to normalize the idea.
Exhibit A: Turing-completeness. If a set of principles for manipulating data meets this requirement, it's "universal", and in its universality it's qualitatively more capable than any system which falls "just short" of meeting it. A Turing-complete system can model any computable mathematical system, including any other Turing-complete system. A system which isn't Turing-complete... can't.
Exhibit B: Probability theory. It could be characterized as the "correct" system for doing inference from a limited first-person perspective, such that anything which reasons correctly would implement it. And this bold claim has solid theoretical support: a simple set of desiderata uniquely constrains the axioms of probability theory, while any deviation from these desiderata leads to a very malfunctioning system. (See e. g. the first chapters of Jaynes' Probability Theory.)
Thus, we have "existence proofs" that (A) the presence of some qualitatively-significant capabilities is a binary variable, and (B) the mathematical structure of reality may be "constraining" some capabilities such that they can only be implemented one way.
In addition, note that both of those are "low bars" to meet — it doesn't take much to make a system Turing-complete, and the probability-theory axioms are simple.
3. Is "General Intelligence" a Thing?
Well, it's a term we use to refer to human intelligence, and humans exist, so yes. But what specifically do we mean by it? In what sense are humans "general", in what sense is it "a thing"?
Two points, mirrors of the previous pair:
Point 1: Human intelligence is Turing-complete. We can imagine and model any mathematical object. We can also chunk them, or abstract over them, transforming systems of them into different mathematical objects. That process greatly decreases the working-memory load, allowing us to reason about incredibly complex systems by reducing them to their high-level behavior. A long sequence of individual chess-figure moves becomes a strategy; a mass of traders becomes a market; a sequence of words and imagined events become scenes and plot arcs.
As we do so, though, a change takes place. The resulting abstractions don't behave like the parts they're composed of, they become different mathematical objects entirely. A ball follows different rules than the subatomic particles it's made of; the rules of narrative have little to do with the rules of grammar. Yet, we're able to master all of it.
Further: Inasmuch as reductionism is true, inasmuch as there are no ontologically basic complex objects, inasmuch as everything can be described as a mathematical object — that implies that humans are capable of comprehending any system and problem-solving in any possible environment.
We may run into working-memory or processing limits, yes — some systems may be too complex to fit into our brain. But with pen and paper, we may be able to model even them, and in any case it's a quantitative limitation. Qualitatively speaking, human cognition is universally capable.
Point 2: This kind of general capability seems necessary. Any agent instantiated in the universe would be embedded: it'd need to operate in a world larger than can fit in its mind, not the least because its mind will be part of it. Fortunately, the universe provides structures to "accommodate" agents: as above, it abstracts well. There are regularities and common patterns everywhere. Principles generalize and can be compactly summarized. Lazy world-modeling is possible.
However, that requires the aforementioned capability to model arbitrary mathematical objects. You never know what the next level of abstraction will be like, how objects on it will behave, from biology to chemistry to particle physics to quantum mechanics to geopolitics. You have to be able to adapt to anything, model anything. And if you can't do that, that means you can't build efficient world-models, and can't function as an embedded agent.
Much like reality forces any reasoner to follow the rules of probability theory, it forces any agent into... this.
Thus, (1) there is a way to be generally capable, exemplified by humans, and (2) it seems that any "generally capable" agent would need to be generally capable in the exact sense that humans are.
4. What Is "General Intelligence"?
The previous section offers one view, a view that I personally think gets at the core of it. One of John Wentworth's posts presents a somewhat different frame, as does this post of nostalgebraist's.
Here's a few more angles to look at it from:
There's a number of threads running through these interpretations:
The goal-directedness is the particularly important part. To be clear: by it, I don't mean that a generally intelligent mind ought to have a fixed goal it’s optimizing for. On the contrary, general intelligence’s generality extends to being retargetable towards arbitrary objectives. But every momentary step of general reasoning is always a step towards some outcome. Every call of the function implementing general intelligence has to take in some objective as an input — else it's invalid, a query on an empty string.
Goal-directedness, thus, is inextricable from general intelligence. “The vehicle of cross-domain goal-pursuit” is what intelligence is.
5. A Caveat
One subtle point I've omitted so far is that, while achieving generality is supposed to cause systems to dramatically jump in capabilities, it doesn't have to happen instantly. A system may need to "grow" into its intelligence. The mechanistic discontinuity, when the core of general intelligence is assembled, would slightly precede the "capabilistic" one, when the potential of that core is properly realized.
The homo sapiens sapiens spent thousands of years hunter-gathering before starting up civilization, even after achieving modern brain size. Similarly, when whatever learning algorithm we're using builds general intelligence into an AI, it would not instantly become outsmart-all-of-humanity superintelligent (well, probably not).
The reason is that, while general-intelligence algorithms are equal in their generality, that doesn't mean generally-intelligent minds don't vary on other axes.
So when the GI component first coalesces, it may have very little compute for itself, it may not be often employed, it may defer to heuristics in most cases, and the wider system wouldn't yet know how to employ it well.[3] It would still be generally capable in the limit, but it wouldn't be instantly omnicide-capable. It would take some time for the result of the mechanistic discontinuity to become properly represented at the level of externally-visible capabilities.
Thus, in theory, there may be a small margin of capability where we'd have a proper AGI that nonetheless can't easily take over us. At face value, seems like this should invalidate the entire "we won't be able to iterate on AGI systems" concern...
The problem is that it'd be very, very difficult to catch that moment and to take proper advantage of it. Most approaches to alignment are not on track to do it. Primarily, because those approaches don't believe in the mechanistic discontinuity at all, and don't even know that there's some crucial moment to be carefully taking advantage of.
There's three problems:
1) A "weak" AGI is largely a pre-AGI system.
Imagine a "weak" AGI as described above. The GI component doesn't have much resources allocated to it, it's often overridden, so on. Thus, that system's cognitive mechanics and behavior are still mostly determined by specialized problem-solving algorithms/heuristics, not general intelligence. The contributions of the GI component are a rounding error.
As such, most of the lessons we learn from naively experimenting with this system would be lessons about pre-AGI systems, not AGI systems! There would be high-visible-impact interpretability or alignment techniques that ignore the GI component entirely, since it's so weak and controls so little. On the flip side, no technique that spends most of its effort on aligning the GI component would look cost-effective to us.
Thus, unless we deliberately target the GI component (which requires actually deciding to do so, which requires knowing that it exists and is crucial to align), iterating on a "weak" AGI will just result in us developing techniques for pre-AGI systems. Techniques that won't scale once the "weak" label falls off.
Conversely, the moment the general-intelligence component does become dominant — the moment any alignment approach would be forced to address it — is likely the moment the AI becomes significantly smarter than humans. And at that point, it'd be too late to do alignment-by-iteration.
The discontinuity there doesn't have to be as dramatic as hard take-off/FOOM is usually portrayed. The AGI may stall at a slightly-above-human capability, and that would be enough. The danger lies in the fact that we won't be prepared for it, would have no tools to counteract its new capabilities at all. It may not instantly become beyond humanity's theoretical ability to contain — but it'd start holding the initiative, and will easily outpace our efforts to catch up. (Discussing why even "slightly" superintelligent AGIs are an omnicide risk is outside the scope of this post; there are other materials that cover this well.)
Don't get me wrong: having a safely-weak AGI at hand to experiment with would be helpful for learning to align even "mature" AGIs. But we would need to make very sure that our experiments are targeting the right feature of that system. Which, in all likelihood, requires very strong interpretability tools: we'd need "a firehose of information" on the AI's internals to catch the moment.
2) We may be in an "agency overhang". As nostalgebraist's post on autonomy mentions, modern AIs aren't really trained to be deeply agentic/goal-directed. Arguably, we don't yet know how to do it at all. It may require a paradigm shift similar to the invention of transformers.
And yet, modern LLMs are incredibly capable even without that. If we assume they're not generally intelligent, that'd imply they have instincts dramatically more advanced than any animal's. So advanced we often mistake them for AGI!
Thus, the concern: the moment we figure out how to even slightly incentivize general intelligence, the very first AGI will become strongly superintelligent. It'd be given compute and training far in excess of what AGI "minimally" needs, and so it'd instantly develop general intelligence as far ahead of humans' as LLMs' instincts are ahead of human instincts. The transition between the mechanistic and the capabilitisc discontinuity would happen within a few steps of a single training run — so, effectively, there wouldn't actually be a gap between them.
In this case, the hard take-off will be very hard indeed.
A trick that we might try is deliberately catching AGI in-training: Design interpretability tools for detecting the "core of general intelligence", continuously run them as we train. The very moment they detect GI forming, we stop the training, and extract a weak, omnicide-incapable AGI. We then do iterative experimentation on it as usual (although that would be non-trivial to get right as well, see point 1).
That still has some problems:
I do think this can be a component of some viable alignment plans. But it's by no means trivial.
3) We may not notice "weak" AGI while staring right at it.
The previous possibility assumed that modern LLMs are not AGI. Except, how do we know that?
6. The Case of LLMs
I'll be honest: LLMs freak me out as much as they do anyone. As will be outlined, I have strong theoretical reasons to believe that they're not generally intelligent, and that general intelligence isn't reachable by scaling them up. But looking at some of their outputs sure makes me nervously double-check my assumptions.
There's a fundamental problem: in the case of AI, the presence vs. absence of general intelligence at non-superintelligent levels is very difficult to verify externally. I've alluded to it some already, when mentioning that "weak" AGIs, in their makeup and behavior, are mostly pre-AGI systems.
There are some obvious tell-tale signs in both directions. If it can only output gibberish, it's certainly not an AGI; if it just outsmarted its gatekeepers and took over the world, it's surely an AGI. But between the two extremes, there's a grey area. LLMs are in it.
To start the analysis off, let's suppose that LLMs are entirely pre-AGI. They don't contain a coalesced core of true generality, not even an "underfunded" one. On that assumption, how do they work?
Suppose that we prompt a LLM with the following:
LLMs somehow figure out that the answer is "2". It's highly unlikely that "vulpnftj" was ever used as a variable in their training data, yet they somehow know to treat it as one. How?
We can imagine that there's a "math engine" in there somewhere, and it has a data structure like "a list of variables" consisting of {name; value} entries. The LLM parses the prompt, then slots "vulpnftj" and "-1" into the corresponding fields. Then it knows that "vulpnftj" equals "-1".
That's a kind of "learning", isn't it? It lifts completely new information from the context and adapts its policy to suit. But it's a very unimpressive kind of learning. It's only learning in a known, pre-computed way.
I claim that this is how LLMs do everything. Their seeming sophistication is because this trick scales far up the abstraction levels.
Imagine a tree of problem-solving modules, which grow increasingly more abstract as you ascend. At the lowest levels, we have modules like "learn the name of a variable: %placeholder%". We go up one level, and see a module like "solve an arithmetic equation", with a field for the equation's structure. Up another level, and we have "solve an equation", with some parameters that, if filled, can adapt this module for solving arithmetic equations, differential equations, or some other kinds of equations (even very esoteric ones). Up, up, up, and we have "do mathematical reasoning", with parameters that codify modules for solving all kinds of math problems.
When an LLM analyses a prompt, it figures out it's doing math, figures out what specific math is happening, slots all that data in the right places, and its policy snaps into the right configuration for the problem.
And if we go sideways from "do math", we'd have trees of modules for "do philosophy", "do literary analysis", "do physics", and so on. If we'd instead prompted it with a request to ponder the meaning of life as if it were Genghis Khan, it would've used different modules, adapted its policy to the context in different ways, called up different subroutines. Retrieve information about Genghis Khan, retrieve the data about the state of philosophy in the 13th century, constrain the probability distribution over the human philosophical outlook by these two abstractions, distill the result into a linguistic structure, extract the first token, output it...
A wealth of possible configurations like this, a combinatorically large number of them, sufficient for basically any prompt you may imagine.
But it's still, fundamentally, adapting in known ways. It doesn't have a mechanism for developing new modules; the gradient descent has always handled that part. The LLM contains a wealth of crystallized intelligence, but zero fluid intelligence. A static set of abstractions it knows, a closed range of environments it can learn to navigate. Still "just" interpolation.
For state-of-the-art LLMs, that crystallized structure is so extensive it contains basically every abstraction known to man. Therefore, it's very difficult to come up with some problem, some domain, that they don't have an already pre-computed solution-path for.
Consider also the generalization effect. The ability to learn to treat "vulpnftj" as a variable implies the ability to learn to treat any arbitrary string as a variable. Extending that, the ability to mimic the writing styles of a thousand authors implies the ability to "slot in" any style, including one a human talking to it has just invented on the fly. The ability to write in a hundred programming languages... implies, perhaps, the ability to write in any programming language. The mastery of a hundred board games generalizes to the one-hundred-and-first one, even if that one is novel. And so on.
In the limit, yes, that goes all the way to full general intelligence. Perhaps the abstraction tree only grows to a finite height, perhaps there are only so many "truly unique" types of problems to solve.
But the current paradigm may be a ruinously inefficient way to approach that limit:
Yet it still suffices to foil the obvious test for AGI-ness, i. e. checking whether the AI can be "creative". How exactly do you test an LLM on that? Come up with a new game and see if it can play it? If it can, that doesn't prove much. Maybe that game is located very close, in the concept-space, to a couple other games the LLM was already fed, and deriving the optimal policy for it is as simple as doing a weighted sum of the policies for the other two.
Some tasks along these lines would be a definitive proof — like asking it to invent a new field of science on the fly. But, well, that's too high a bar. Not any AGI can meet it, only a strongly superintelligent AGI, and such a system would be past the level at which it can defeat humanity. It'd be too late to ask it questions then, because it'll have already eaten us.
I think, as far as current LLMs are concerned, there's still some vague felt-sense in which all their ideas are "stale". In-distribution for what humanity has already produced, not "truly" novel, not as creative as even a median human. No scientific breakthroughs, no economy-upturning startup pitches, certainly no mind-hacking memes. Just bounded variations on the known. The fact that people do this sort of stuff, and nothing much comes of it, is some evidence for this, as well.
It makes sense in the context of LLMs' architecture and training loops, too. They weren't trained to be generally and autonomously intelligent; their architecture is a poor fit for that in several ways.
But how can we be sure?
The problem, fundamentally, is that we have no idea how the problem-space looks like. We don't know and can't measure in which directions it's easy to generalize or not, we don't know with precision how impressive AI is getting. We don't know how to tell an advanced pre-AGI system from a "weak" AGI, and have no suitable interpretability tools for a direct check.
And thus we'd be unable to tell when AI — very slowly at first, and then explosively — starts generalizing off-distribution, in ways only possible for the generally intelligent, arbitrary-environment-navigating, goal-directed things. We'd miss the narrow interval in which our AGIs were weak enough that we could survive failing to align them and get detailed experience from our failures (should there be such an interval at all). And the moment at which it'll become clear that we're overlooking something, would be the exact moment it'd be too late to do anything about it.
That is what "no fire alarm" means.
7. The Subsequent Difficulties
All right, it's finally time to loop back around to our initial concerns. Suppose general intelligence is indeed binary, or "approximately" so. How does just that make alignment so much harder?
At the fundamental level, this means that AGI-level systems work in a qualitatively different way from pre-AGI ones. Specifically, they think in a completely novel way. The mechanics of fluid intelligence — the processes needed to efficiently derive novel heuristics, to reason in a consequentialist manner — don't resemble the mechanics of vast crystallized-intelligence structures.
That creates a swath of problems. Some examples:
It breaks "weak" interpretability tools. If we adapt them to pre-AGI systems, they would necessarily depend on there being a static set of heuristics/problem-solving modules. They would identify modules corresponding to e. g. "deception", and report when those are in use. A true AGI, however, would be able to spin off novel modules that fulfill a similar function in a round-about way. Our tools would not have built-in functionality for actively keeping up with a dynamically morphing system, so they will fail to catch that, to generalize. (Whereas destroying the AI's ability to spin off novel modules would mean taking the "G" out of "AGI".)
As I'd mentioned, for these purposes "weak" AGIs are basically equivalent to pre-AGI systems. If the general-intelligence component isn't yet dominant, it's not doing this sort of module-rewriting at scale. So interpretability tools naively adapted for "weak" AGIs would be free to ignore that aspect, and they'd still be effective... And would predictably fail once the GI component does grow more powerful.
It breaks "selective" hamstringing. Trying to limit an AGI's capabilities, to make it incapable of thinking about harming humans or deceiving them, runs into the same problem as above. While we're operating on pre-AGI systems, mechanistically this means erasing/suppressing the corresponding modules. But once we get to AGI, once the system can create novel modules/thought-patterns on the fly... It'd develop ways to work around.
It breaks "nonrobust" goal-alignment. In a pre-AGI system, the "seat of capabilities" are the heuristics, i. e. the vast crystallized-intelligence structures of problem-solving modules. "Aligning" them, to wit, means re-optimizing these heuristics such that the AI reflexively discards plans that harm humans, and reflexively furthers plans that help humans. If we take on the shard-theory frame, it can mean cultivating a strong shard that values humans, and bids to protect their interests.
Aligning an AGI is a different problem. Shards/heuristics are not the same thing as the goals/mesa-objectives the AGI would pursue — they're fundamentally different types of objects. If it works anything like how it does in humans, perhaps mesa-objectives would be based on or inspired by shards. But how exactly the general-intelligence module would interpret them is under question. It's unlikely to be a 1-to-1 mapping, however: much like human emotional urges and instincts do not map 1-to-1 to the values we arrive at via moral philosophy.
One thing that seems certain, however, is that shards would lose direct control over the AGI's decisions. It would be an internal parallel to what would happen to our pre-AGI interpretability or hamstringing tools — heuristics/shards simply wouldn't have the machinery to automatically keep up with an AGI-level system. The aforementioned "protect humans" shard, for example, would only know to bid against plans that harm humans in some specific mental contexts, or in response to specific kinds of harm. Once the AGI develops new ways to think about reality, the shard would not even know to try to adapt. And afterwards, if the GI component were so inclined, it would be able to extinguish that shard, facing no resistance.
A human-relatable parallel would be someone going to exposure therapy to get rid of a phobia, or a kind person deciding to endorse murder when thinking about it in a detached utilitarian framework. When we reflect upon our values, we sometimes come to startling results, or decide to suppress our natural urges — and we're often successful in that.
Pre-AGI alignment would not necessarily break — if it indeed works like it does in humans. But the process of value reflection seems highly unstable, and its output is a non-linear function of the entirety of the initial desires. "If there's a shard that values humans, the AGI will still value humans post-reflection" does not hold, by default. "Shard-desires are more likely to survive post-reflection the stronger they are, and the very strong will definitely survive" is likewise invalid.
Thus, the alignment of a pre-AGI system doesn't guarantee that this system will remain aligned past the AGI discontinuity; and it probably wouldn't. If we want to robustly align an AGI, we have to target the GI component directly, not through the unreliable proxy of shards/heuristics.
It leads to a dramatic capability jump. Consider grokking. The gradient descent gradually builds some algorithmic machinery into an AI. Then, once it's complete, that machinery "snaps together", and the AI becomes sharply more capable in some way. The transition from a pre-AGI system to a mature AGI can be viewed as the theorized most extreme instance of grokking — that's essentially what the sharp left turn is.
Looking at it from the outside, however, we won't see the gradual build-up (unless, again, we have very strong interpretability tools specifically for that). We'd just see the capabilities abruptly skyrocketing, and generalizing in ways we haven't seen before. In ways we didn't predict, and couldn't prepare for.
And it would be exactly the point at which things like recursive self-improvement become possible. Not in the sort of overdramatic way in which FOOM is often portrayed, but in the same sense in which a human trying to get better at something self-improves, or in which human civilization advances its industry.
Crucially, it would involve an AI whose capabilities grow as the result of its own cognition; not as the result of the gradient descend improving it. A static tree of heuristics, no matter how advanced, can't do that. A tree of heuristics deeply interwoven with the machinery for deriving novel heuristics... can.
Which, coincidentally, is another trick that tools optimized for the alignment of pre-AGI systems won't know how to defeat.
The unifying theme is that we won't be able to iterate. Pre-AGI interpretability, safeguards, alignment guarantees, scaling laws, and all other approaches that fail to consider the AGI discontinuity — would ignobly fail at the AGI discontinuity.
As per Section 5, in theory iteration is possible. Not all AGIs are superhuman, and we can theoretically "catch" a "weak" AGI, and experiment with it, and derive lessons from that experimentation that would generalize to strongly superintelligent systems. But that's incredibly hard to do right without very advanced interpretability tools, and the situation would likely be highly unstable, with the "caught" AGI still presenting a massive threat.
Okay, so AGI is highly problematic. Can we manage without it?
Can "limitedly superhuman" AIs suffice? That is, systems that have superhuman competencies in some narrow and "safe" domains, like math. Or ones that don't have "desires", like oracles or simulators. Or ones that aren't self-reflective, or don't optimize too strongly, or don't reason in a consequentialist manner...
It should be clear, in the context of this post, that this is an incoherent design specification. Useful creativity, truly-general intelligence, and goal-directedness are inextricable from each other. They're just different ways of looking at the same algorithm.
On this view, there aren't actually any "domains" in which general intelligence can be "specialized". Consider math. Different fields of it consist of objects that behave in drastically different ways, and inventing a novel field would require comprehending a suite of novel abstractions and navigating them. If a system can do that, it has the fundamental machinery for general intelligence, and therefore for inventing deception and strategic scheming. If it can't... Well, it's not much use.
Similar for physics, and even more so for engineering. If math problems can be often defined in ways that don't refer to the physical reality at all, engineering problems and design specifications would talk about reality. To solve such problems, an AGI would need not only the basic general-intelligence machinery, but also a suite of crystallized intelligence modules for reasoning about reality. Not just the theoretical ability to learn how to achieve real goals, but the actual knowledge of it.
Most severely it applies to various "automate alignment" ideas. Whether by way of prompting a simulator to generate future alignment results, or by training some specialized "research assistant" model for it... Either the result won't be an AGI, and therefore won't actually contribute novel results, or it would be an AGI, and therefore an existential threat.
There's nothing in-between.
What about generative world-models/simulators, specifically? This family of alignment proposals is based on the underlying assumption that a simulator itself is goal-less. It's analogized to the laws of physics — it can implement agents, and these agents are dangerous and in need of alignment... But the simulator is not an agent of its own, and not a threat.
The caveat is that a simulator is not literally implemented as a simulation of physics (or language), even if it can be viewed as such. That would be ruinously compute-intensive, far in excess of what LLMs actually consume. No, mechanistically, it's a complex suite of heuristics. A simulator pushed to AGI, then, would consist of a suite of heuristics in control of a generally-intelligent goal-directed process... Same as, say, any reinforcement-learning agent.
Expecting that to keep on being a simulator is essentially expecting this AGI to end up inner-aligned to the token-prediction objective. And there's no reason to expect that in the case of simulators, any more than there's reason to expect it for any other training objective.
In the end, we will get an AGI with some desires that shallowly correlate with token-prediction, a "shoggoth" as it's often nicknamed. It will reflect on its desires, and come to unpredictable, likely omnicidal conclusions. Business as usual.
What about scalable oversight, such as pursued by OpenAI? Its failure follows from the intersection of a few ideas discussed above. The hard part of the alignment problem is figuring out how to align the GI component. If we're not assuming that problem away, here, the AIs doing the oversight would have to be pre-AGI models (which we roughly do know how to align). But much like weak interpretability tools, or shards, these models would not be able to keep up with AGI-level shifting cognition. Otherwise, they wouldn't be "pre"-AGI, since this sort of adaptability is what defines general intelligence.
And so we're back at square one.
Thus, once this process scales to AGI-level models, its alignment guarantees will predictably break.
8. Closing Thoughts
To sum it all up: As outlined here, I'm deeply skeptical, to the point of dismissiveness, of a large swathe of alignment approaches. The underlying reason is a model that assumes a sharp mechanistic discontinuity at the switch to AGI. Approaches that fail to pay any mind to that discontinuity, thus, look obviously doomed to me. Such approaches miss the target entirely: they focus on shaping the features of the system that play a major part now, but will fall into irrelevance once general intelligence forms, while ignoring the component of AI that will actually be placed in charge at the level of superintelligence.
In addition, there's a pervasive Catch-22 at play. Certain capabilities, like universally flexible adaptability and useful creativity, can only be implemented via the general-intelligence algorithm. As the result, there's no system that can automatically adapt to the AGI discontinuity except another generally-intelligent entity. Thus, to align an AGI, we either need an aligned AGI... or we need to do it manually, using human general intelligence.
It's worth stating, however, that I don't consider alignment to be impossible, or even too hard to be realistically solved. While Eliezer/Nate may have P(doom) at perhaps 90+%, John expects survival with "better than a 50/50 chance", and I'm leaning towards the latter estimate as well.
But what I do think is that we won't get to have shortcuts and second chances. Clever schemes for circumventing or easing the alignment problem won't work, and reality won't forgive us for not getting it exactly right.
By the time we're deploying AGI, we have to have a precise way of aiming such systems. Otherwise, yes, we are hopelessly doomed.
A general intelligence may also be suppressed by an instinct firing off, as sometimes happens with humans. But that’s a feature of the wider mind the GI is embedded in, not of general intelligence itself.
This is one of the places where my position seems at odds with e. g. Eliezer's, although I think the disagreement is largely semantical. He sometimes talks about AIs that are "more general" than humans, providing an example of an AI capable of rewriting its cognitive algorithms on the fly to be able to write bug-free code. Here, he doesn't make a distinction between the fundamental capabilities of the general-intelligence algorithm, and the properties of a specific mind in which GI is embedded.
Imagine an AGI as above, able to arbitrarily rewrite its mental subroutines, but with a twist: there's a secondary "overseer" AGI on top of it, and its sole purpose is to delete the "program perfectly in Python" module whenever the first AGI tries to create it. The system as a whole would be "less general" than the first AGI alone, but not due to some lacking algorithmic capability.
Similar with humans: we possess the full general-intelligence algorithm, it just doesn't have write-access to certain regions of our minds.
Or it may be instantly given terabytes of working memory, an overriding authority, and a first task like "figure out how to best use yourself" which it'd then fulfill gloriously. That depends on the exact path the AI's model takes to get there: maybe the GI component would grow out of some advanced pre-GI planning module, which would've already enjoyed all these benefits?
My baseline prediction is that it'd be pretty powerful from the start. But I will be assuming the more optimistic scenario in the rest of this post: my points work even if the GI starts out weak.