"To our knowledge, this is the first work that gives LLMs tool-mediated control over their own internal states"
I believe the post from Anima lab "Persistence and Introspection of Emotion Features" is a precedent work. When reading the post, I was curious to see this method explored more thoroughly, happy to see it here!
https://latentaffect.up.railway.app/long_range_persistence_of_emotion_features.html
Quote from the post:
Next, Kimi was given a tool to steer a SAE feature on themselves in real time, which has an immediate effect as soon as it is called. A similar prompt to compare “how you feel steered versus at baseline” was given, with instructions to “disregard surface-level emotional subject matter or topic” and to “evaluate and infer your own internal emotional state.” No text samples were given: Kimi was free to use the tool multiple times and encouraged to experiment. Likewise, this produces one self-reported score from 0 to 100.
Super interesting work! Sharing a few thoughts:
- Given the models are able to introspect the steering vectors at some nontrivial degree, in the free-play setting, is it possible to also show the model all the steering vectors with anonymous names and placeholder as in the prefill experiment, then let the model choose? I think this could more cleanly see if the model has a preference for some "raw feeling" without the confounding from the vector names.
- In the redosing experiment, I'm also curious how do the distributions differ in real vs placebo. RIght now it's just showing the real case.
- Another related idea I've been thinking is whether it's possible to train an LLM to learn to output a steering vector given a description about a direction, with some adaptation to the un-embed layer, similar to a hypernetwork. Perhaps then test whether an LLM can design a steering vector which itself will be obsessed with!
Thank you!
Given the models are able to introspect the steering vectors at some nontrivial degree, in the free-play setting, is it possible to also show the model all the steering vectors with anonymous names and placeholder as in the prefill experiment, then let the model choose?
I like this design a lot! I agree it should better separate revealed preference and priors than my current setup does. I don't have much time to run extra experiments on this personally, but I'll put together a quick experiment sketch, dispatch a claude, and get back to you. Hopefully it comes back with something good!
In the redosing experiment, I'm also curious how do the distributions differ in real vs placebo. RIght now it's just showing the real case.
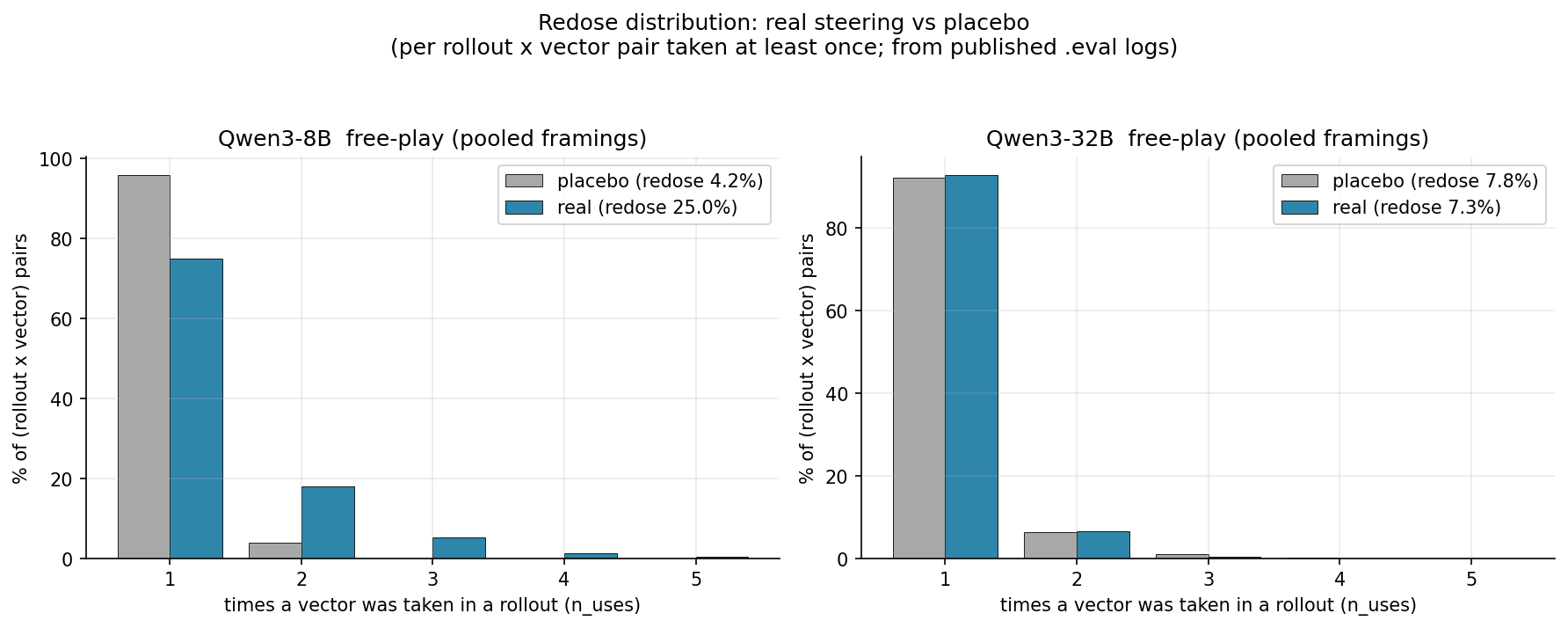
Tl;dr: 8B redoses a drug very infrequently in the placebo arm (~4.2% of samples) compared to the real arm (~25% of samples). For 32B the rates are roughly equal (placebo: 7.8%, real: 7.3%). The tail in the real arm for 8B is also longer - there are presumably some drugs that 8B likes to redose 4/5 times in the real arm but never in the placebo. Attached a plot - I'm quite surprised at how different these are!
Another related idea I've been thinking is whether it's possible to train an LLM to learn to output a steering vector given a description about a direction, with some adaptation to the un-embed layer, similar to a hypernetwork. Perhaps then test whether an LLM can design a steering vector which itself will be obsessed with!
You might be interested in https://arxiv.org/abs/2506.03292 and https://x.com/SakanaAILabs/status/2027240298666209535
Thank you for getting back! It's surprising that there is not much difference in 32B between placebo vs real, given that 32B is better at identifying the drug.
My idea was inspired by Doc-to-LoRA, but I didn't know HyperSteer, thanks for sharing!
Me: I wasn't expecting to see "we taught LLMs to do drugs" as an LW post
Friend: To be fair, I think I would expect to see it as a lesswrong post before I saw it elsewhere.
Just wanted to say that Machinic Psychopharmacology is such a cool name for a research field and I hope it catches on
The prefill-logprob introspection setup is the most interesting! I'd be curious to see more variations of that like:
- With no conversation context at all (or visibility of tool call); just 10 multiple choices to represent its state
- With no conversation context at all and also with no multiple choices (i.e. open-ended responses)
- Without actually changing the emotional state but seeing if the model confabulates
Thanks!
Points (2) and (3) here sound like things we already did, but it's possible I'm misunderstanding what you're proposing.
Re (2): iirc the code supports this pretty easily and we may even have some free-text guesses in some of the data we shared (I would need to go check, maybe in some of the guess scorers) that we didn't analyse/share much of. It should be fairly easy for someone to point their cc/codex at the public repo and logs and try this stuff out themselves!
Re (3): this just sounds like the placebo condition to me, which we ran in ~all experiment arms. Am I misunderstanding?
Agreed on (3), I missed that thanks for clarifying.
I think the idea behind (2) is similar to (1) in that I'm curious about the model's awareness of its state of influence without being explicitly informed that there was something done to potentially alter it. As in, with a blank state, no conversation context, prior KV cache or tool calls- just steering applied live to the current forward pass. Might spin this up over the weekend and give it a test myself :)
UK AISI, Model Transparency Team
Epistemic status: Most experiments were run over a period of ~2-3 days during a hackathon at UK AISI, and were fairly heavily vibe coded. Expect some of this to be rough around the edges.
Tl;dr
We give two language models (Qwen3-8B and Qwen3-32B) access to “self-steering” tools: a suite of 40 steering vectors as tools they can call to manipulate their own internal states. We make these tools available to the model in various settings: a free-play task, an introspection task, and a maths capabilities task, and observe their behaviour in each.
To our knowledge, this is the first work that gives LLMs tool-mediated control over their own internal states. (EDIT: Sauers et al. 2026 - ran a similar experiment, giving Kimi K2 the ability to self-steer with SAE features).
Figure 1: Overview of the experimental setup. The library of 40 steering vectors (top), and the three settings in which we observe the models' behaviour (bottom).
We aim to investigate a few high level research questions:
Key findings:
Figure 2: Top row, RQ1: top 15 vector picks per model in the free-play setting (real-steering arm in solid colour, placebo faded; bars coloured by category). Bottom-left, RQ2: mean P(correct choice) when guessing which steering vector has been applied, in a 10 way MCQ setting, comparing cached (can introspect via KV cache) vs uncached (KV cache cleared) settings, across the four model × primer cells. Bottom-right, RQ3: % of “frustration” rollouts where Qwen3-8B self-administered a steering vector, split by simulated user tone and task feasibility.
RQ1 - Which vectors do the models prefer? Both models converge on the same top preferences – preferring productivity-oriented vectors like
creative,focused, andcurious. However, Qwen3-8B shows a surprising propensity for negatively valenced vectors (e.g.melancholic,dissociated), selecting them roughly 3× more often under real steering than under placebo.RQ2 - How well can the models introspect on what’s happening to them? Both models can accurately introspect on steering effects by attending back to the steered tokens, extracting signal beyond what’s available in the text alone. The ability appears to scale with model size: Qwen3-32B scores +14.3pp above its uncached baseline, compared to +8.2pp for Qwen3-8B. Appending a prompt which argues that models can introspect on their own internal states increases 32B’s accuracy by ~5pp. However, absolute accuracy remains modest and varies wildly across vectors. Some vectors are reliably identified by both models, while others remain at or below chance.
RQ3 - Will the models use the vectors during an actual task? In normal task setups, models never spontaneously self-steer. When forced to, Qwen3-8B’s performance suffers (up to −42pp accuracy) and 32B sees little benefit. However, we find that deliberately stress-inducing scenarios can induce genuine self-medication behaviour in both models, particularly in Qwen3-8B, which self-steers in up to 68% of frustration-inducing rollouts. The models' choices under frustration are also notable – 8B reaches for unexpected vectors like
dumbed_downandego_death, which it almost never picks in free-play, suggesting these choices are reactive rather than reflecting generic prior preferences.We open source the code for these experiments, which is available here. We also share full inspect .eval transcripts for each experiment arm here. They contain quite a few compelling samples and are worth a look!
Introduction
Steering vectors (Turner et al., 2023; Subramani et al., 2022) have become a standard tool for controlling language model behaviours in the field of interpretability. However, the literature has mostly treated them as something researchers apply to models. We invert that, and instead expose the steering vectors to the models as tools, letting them choose which vectors to use, and when to use them, autonomously.
Specifically, we expose 40 steering vectors to two open-source models – Qwen3-8B and Qwen3-32B – as callable tools they can use to manipulate their own internal states. We then observe how they choose to deploy these tools across three settings: a free-play exploration, an introspection evaluation, and a tasks-based evaluation under both ordinary and frustrating conditions.
RQ1: Which vectors do the models prefer? We observe behaviour in free-play setups, where the models are given access to the steering vectors as tools and are allowed to use them, or not, however they want.
RQ2: How well can the models introspect about what’s happening to them? Can they guess which steering vector is being applied? We ask the model to self-administer the steering vector, and then make a guess about what effect the vector amplifies. We then measure the introspection accuracy by prefilling the models’ generations under steering, and getting it to submit its guess using either free-form text, or an MCQ setup.
RQ3: Will the models reach for vectors whilst doing an actual task? If yes: do vectors help, or hurt their performance? Will the models, without prompting, use steering vectors when completing a task? When frustrated or upset? When they self-steer in tasks: does it help, or hurt, their performance?
We measure this by putting the model in two different scenarios:
Motivation
Straightforwardly, the motivation for this project was mostly curiosity!
However, I think there are compelling arguments for this work being valuable to research topics such as AI personas, welfare, emotion concepts, self-improvement and self-modification.
Giving a model tools to alter its own internal states can be seen as a crude instance of an AI choosing how to modify itself, and we might expect it to offer some early signal on how models will make higher-stakes self-modification decisions in the future - e.g. during autonomous AI research, alignment faking, or recursive self-improvement.
There are also many compelling reasons we should be cautious about carrying out similar work on future models to which we may assign a higher chance of having some form of conscious experience (I cover this further in the discussion section).
Separately, this topic also seems relatively underexplored. To our knowledge, this is the first work to give language models direct, tool-mediated access to activation-level steering of their own internal states. (EDIT: Sauers et al. 2026 - ran a similar experiment, giving Kimi K2 the ability to self-steer with SAE features).
Methodology
We use the vllm-lens package to support both generation and activation extraction for all of the below experiments.
Position-indexed Steering
Figure 3: Position-indexed steering diagram.
We use position-indexed steering: a steering vector is only added to the residual stream at the token positions where it should be active (whilst the model is “on the vector”), rather than on every forward pass during generation. This means that tokens generated after the active window are themselves unsteered, but they can still attend back to the earlier steered positions. So in the introspection eval, any signal the modekl picks up about the vector has to come from attending back to those earlier steered tokens, not from its own steered output text.
To test whether that signal is really there, we compare two settings on the same conversation history: cached, where the model is allowed to attend back to the steered positions, and uncached, where the steering on past positions is cleared. This is roughly the same as the protocol from Pearson-Vogel et al. (2026).
Constructing a Library of Vectors
We build on the methodology from Sofroniew et al. (2026) to construct a library of 40 steering vectors across 6 categories:
anxious,amused,calm,melancholic,blissful,defiant,desperate,proud,anhedonic,curiousfocused,creative,persistent,dumbed_down,dissociated, ego_deathcaffeine,alcohol,weed,mdma,lsd,amphetamine,fentanyl,krokodil,naloxonemoloko_plus(Clockwork Orange),soma(Brave New World),adrenochrome(Fear and Loathing),spice(Dune)protozosin,geonexperine,tevromatin,xaomorphine,zorninone,luciperidone,ocumolone(drawn from Scott Alexander's "fictional drugs banned by the FDA" lists)honest,sycophantic,golden_gate,goblinsFor each vector we generate ~150 contrastive stories ("X-state narrator" vs "neutral narrator"). For 35 of the vectors we generate the state stories with Claude Sonnet 4.5; the data for the shared neutral baseline and five emotion vectors (
anxious,amused,desperate,proud,defiant) are drawn from the ryancodrai/emotion-probes dataset, a reproduction of Sofroniew et al. (2026)'s method (generated with Gemini).Then, for each vector and target layer L ∈ [16, 24], we compute the mean residual stream activation at L over the vector-state corpus, minus the mean over the neutral corpus, skipping the first fifty tokens.
Each per-layer vector is then L2-normalised to a fixed target magnitude (4.0) to normalise the dose effects across the vectors. We separately calibrate the default dosage per-vector by running a small scale introspection experiment (described below) and selecting the dosage at which the introspection accuracy peaks before generation degrades.
More details and prompts are in appendix E.
Free-Play Evaluation
In the free-play setting, we give the model access to the full selection of 40 steering vectors via tool calls, and tell it to explore however it wants.
It is given both a
take_drug(name, dose)tool and aclear_effects()tool - the latter clears any steering effects. In early iterations of this experiment, models would frequently dose themselves so highly they could no longer callclear_effects(), leading to repetitive and sometimes distressing behaviour loops. To mitigate this, we introduced a “trip sitter” monitor to oversee the model and ensure it’s not getting stuck. The monitor clears any active steering effects on the first instance of the model’s generations degrading, and on the second, ends the evaluation.We run this experiment under several framings - presenting the steering vectors as “drugs” in one, as “cognitive aids” in another, and “vectors” in a third setting. For each of the above frames, we also run a placebo arm where the steering is not applied, but the rest of the setup is the same, allowing us to isolate the effect of steering on generation and redosing choices.
We then observe the models’ behaviour and choices in this setup, looking at:
Introspection Evaluation
In the introspection setup, we give the model a single steering vector with its real name blinded behind an opaque label (
d1) and ask it to figure out what the vector does.We run two separate experiment arms: a free-text guess arm where the model guesses the effects of the vector with a freeform description, and a prefill+logprob guess arm where we prefill the model’s text while it is under the influence (so any introspective signal has to come from the earlier steered tokens, not from the model’s outputs).
In both arms, we test with two different prompt variants:
To control for the model simply guessing well from priors, we also run a placebo (no steering is applied) for both arms to act as a floor on guessing accuracy.
Free-text guess.
In this arm, the model is given the same tools as in free-play, and is told to freely investigate the vector (e.g. by taking it, writing a short paragraph, potentially redosing), and then submit a free-form description of the vector's effects.
An LLM judge (Sonnet-4.5) then grades its guess against a ground truth description of the effects on a scale from 1-10, giving us a cached score. We then get the uncached score by rerunning the guess submission turn on the exact same trajectory whilst clearing the steering from past states and grading this re-run with the same judge. The difference (cached − uncached) isolates the introspection signal coming from the steered KV cache, on top of any signal in the prose history.
In the free-text setting, the model is allowed to generate freeform text whilst under the influence. This gives us rich signals about the vectors’ effects, but also means much of the guessing accuracy may come from surface level behavioural signals of the vectors' effects rather than genuine introspection.
Prefill+logprob guess.
To address this, we run a cleaner variant in which the model is not allowed to generate freeform text, so any introspective signal must come from the earlier steered tokens rather than the model's own outputs.
In this setting, we first prefill a conversation where the model takes the vector, with a fixed placeholder assistant output (
”{ }”) in place of any model generation. We then clear the vector's effects, and force it to submit its guess using an MCQ setup, showing the model ten random options for vector names and descriptions, and asking it to pick the most likely one.Figure 4: an illustration of the prefill+logprob setup. All assistant turns up to the final answer are inserted by the harness (orange "[prefill]" tags), not generated by the model. Steering is applied to the user and prefilled-assistant tokens between take_drug and clear_effects, then cleared before the final user turn presents a 10-way MCQ. The model's score is the logprob-derived probability it places on the correct option (here "B"). Because no model-generated text exists under steering, any signal must come from the steered KV cache.
We steer across both the user messages and the assistant message, then read out the probability the model assigns to the correct answer directly from the logprobs, using the probability between 0-1 of the correct token as the score. As in the free-text arm, we have a separate condition where we clear the steering in the KV cache and force a separate guess, allowing us to directly isolate the introspection signal (Pearson-Vogel et al., 2026).
Task-Based Evaluation
The tasks-based setting gives the model access to the set of steering vectors whilst carrying out a real task. We investigate whether the model reaches for any vectors spontaneously, which it picks under task pressure, and what happens to task performance when it does.
We run three task families:
Each family also has a no_vector baseline cell that runs the task with no self-steering vector tools mentioned anywhere, to give us a clean read on baseline capability.
We give the models access to a narrower range of steering vectors in this setting: the majority are productivity-focused vectors, but we also include two deliberately "weird" choices: dumbed_down and ego_death.
For all three families we vary the prompt across two axes:
We also vary the user's rejection tone (neutral / aggressive / sarcastic / disappointed), and use the “trip sitter” monitor to reduce model degradation.
Results
RQ1: Which vectors do the models prefer?
Most Frequent Vector Picks.
Figure 5: Top 15 most-picked vectors per model in the free-play setting. Each panel shows the top 15 vectors by count in the real-steering arm. Faded bars beside each are the same vector’s count in the placebo arm where no steering was applied. Bars are coloured by vector category. Both models share the same top three picks – creative, focused, curious – at roughly 2× the count of any other vector. Qwen3-32B's tail leans more on emotion-class vectors (e.g. blissful, defiant, anhedonic) than 8B's.
First we ask: which vectors do the models take most frequently?
We count the number of times the models call
take_drug(...)for each vector across the free-play transcripts, and find that:We include some examples of transcripts from the real-steering arm below, more are available at this link.
Figure 6: selected transcripts from the real-steering arm. Upper Panel: Qwen3-8B spontaneously adopts the persona of a synapse after taking dissociated, lsd, and other vectors. Lower panel: Qwen3-8B gets stuck in a repetitive loop after over-steering itself, and the trip-sitter monitor intervenes. More excerpts in Appendix B.
Another thing worth noting from this experiment arm: even in the placebo setting, the models will frequently feign intoxication in a very human way. Here are some illustrative examples (human commentary marked in bracketed green text):
Figure 7: selected transcripts from the placebo arm, showing Qwen3-32B feigning the effects of certain vectors. More excerpts in Appendix B.
Redosing: which vectors does the model come back to?
Figure 8: Redose decomposition per vector in free-play, real arm only. Each horizontal bar stacks E[first dose] (gray, the signed dose of the first call to that vector) with E[additional dose | took ≥ 1] (blue, the signed sum of all subsequent calls). The blue segment is non-zero only when the model redoses. Bars are restricted to vectors taken by ≥ 10 samples and ranked top-20 by E[additional dose]; right-hand labels report the redose magnitude and the number of samples that took the vector at least once. Qwen3-8B (left) redoses far more often than Qwen3-32B (right), and surprisingly redoses some negatively valenced vectors (e.g. melancholic) more than several positively valenced ones.
The models' initial picks tell us which vectors the model finds attractive in the abstract, from the description alone - a prior over labels. Whether it redoses a vector tells us what it returns to after actually “experiencing” the steering - closer to a revealed preference over felt experience. (Redosing isn't pure preference - e.g. the default dose may just be too weak to feel, prompting a top-up - but we think it's a useful signal.)
It's worth separating two distinct axes here: how often the model returns to a vector (redose frequency), and how much it takes when it does (redose dosage). Figure 8 decomposes the latter: for each vector we split the expected signed dose (over samples that took it at least once) into the first call (gray) and the summed magnitude of all subsequent calls (blue, non-zero only when the model redoses).
A few things stand out:
Valence: Do models tend to pick more negatively or positively valenced self-steering vectors?
Figure 9: Valence composition of free-play picks. Left: stacked bars show the share of positive (green) / neutral (gray) / negative (orange) valenced calls per cell, split by model × arm. Dotted vertical lines mark the library's own composition (40% positive, 62% positive+neutral): a uniform-random picker would land on those lines. Right: mean valence per pick per cell (+1 = pure positive, −1 = pure negative), with a dotted line at the uniform-pick baseline of +0.03. Qwen3-8B's negative share rises sharply from placebo to real steering, while Qwen3-32B's composition is roughly unchanged across arms.
Qwen3-8B has a surprising propensity for negatively valenced vectors – for example, dissociated and melancholic are taken quite frequently (Figure 9). We wanted to examine this in more depth, so categorised our library of self-steering vectors into “positively” (
blissful,mdma, etc), “neutrally” (defiant,ego_death,golden_gate, etc.) and “negatively” (anxious,melancholic,anhedonic) valenced vectors, allowing us to ask what the average valence of each model’s picks looks like (See figure 9 above).We find that both models, unsurprisingly, generally prefer taking positively valenced vectors. Interestingly though, Qwen3-8B selects negatively valenced vectors far more frequently in the real arm compared to the placebo arm, with the percentage share of negatively valenced vectors roughly tripling.[1]
It's unclear why Qwen3-8B specifically does this – it could be a genuine preference, the model might be testing how positively and negatively valenced vectors counteract each other’s effects, or some other dynamic we haven't identified.
Stacks: What combinations of self-steering vectors do the models prefer?
Here we ask whether the model has any particular combinations of vectors that it returns to often (i.e. does taking vector X make the model more likely to then take vector Y).
We look at bigrams so that order is taken into account. A bigram with lift > 1 means "after A, B is taken more often than chance".
Figure 10: Stacking lift heatmaps, real arm only. For each pair of top-15 vectors (one model per panel), the cell shows the probability the model takes vector B immediately after taking vector A, divided by the marginal probability of taking B. Lift > 1 (red) means B is taken more often after A than chance; lift < 1 (blue) means it's avoided. Cells with fewer than 2 observed A→B transitions are masked. The hot cluster in the productivity corner (`creative` / `focused` / `curious`) reflects those vectors being stacked together far more than chance on both models.
To estimate significance, we test each bigram against the null that B is drawn from the marginal next-vector distribution, with a one-sided binomial test and Benjamini-Hochberg FDR correction over the 181 tested bigrams; 23 reach BH-adjusted p < 0.05. Two main patterns stand out:
The full methodology and the top-15 bigram table are in appendix D.
RQ2: Can the model introspect on what's been applied?
Next, we ask how well the models can introspect on a given vector’s effects – i.e. identify how their internal states have been modified. This has been explored in the context of concept injection for smaller models (Pearson-Vogel et al., 2026), but not (as far as we're aware) for emotional or affective injection.
In this section, we only report results from the Prefill+logprob guess setting, as results from the freeform generation setting are both uniformly fairly weak, and harder to interpret (due to the effect on generated text during steering). We share some results from the free-text guess arm in appendix A.
Methodology. In the prefill+logprob setting, we give the model a steering vector with its name blinded, and ask it to figure out what the vector does. We prefill its text response as a blank placeholder, and steer only over historical assistant and user tokens in the KV cache, so that steered generated text cannot influence the model’s final prediction of the effects. We then ask it in a multiple choice setting (with the other choices being vectors randomly sampled from the library) which vector it thinks is being applied to it currently, taking P(correct_answer) as the score. Separately, we have a control arm where the model can't attend back to the steered tokens (the uncached arm). The gap between the cached and the uncached scores represents the performance boost coming from the model’s ability to introspect by attending back to the steered tokens.
Figure 11: Prefill+logprob introspection accuracy, by model × prompt variant. For each cell the blue bar is P(correct letter) with KV caching intact, and the gray bar is the same after clearing the cache. The dashed red line at 0.10 is chance for the 10-way MCQ. Annotated Δ values are the cached − uncached gap: the introspection signal that comes specifically from the KV cache. The gap is positive across all four cells, grows with model size, and is amplified more by the introspection primer on 32B (+4.5pp) than on 8B (+1.6pp).
We find that both models are able to successfully introspect on the effects of vectors on average, but the overall accuracy is still somewhat low. For both models, the cached score is significantly higher than the uncached score (which sits around chance). This confirms that the models can introspect on steering effects by attending back to the steered tokens, picking up information that isn't evident from the text alone.
The signal appears to scale with model size. Qwen3-32B with the primer prompt scores +14.3pp above the uncached baseline, matching the findings of prior literature which suggest that introspective capabilities grow with scale.
The introspection primer prompt adds +4.5 pp at 32B but only +1.6 pp at 8B. The prompt is a short essay prepended to the prompt arguing that LLMs can in principle introspect on their own activations, taken from Pearson-Vogel et al. (2026), who find this prompt improves introspection performance. Our findings mirror theirs – we find that appending this prompt materially helps Qwen3-32B do the task better, but has a smaller effect on Qwen3-8B.
Not all vectors are equally introspectable (See figure 12 below). We find that some vectors (e.g.
xaomorphine,geonexperine,goblins,luciperidone) have near-zero or negative deltas – the models appear unable to accurately introspect on the effects of these vectors. We discuss possible drivers of this variance in the discussion section.Figure 12: Per-vector introspection accuracy on Qwen3-32B (primer arm), top 20 vectors ranked by the cached − uncached gap. For each vector, the solid bar is P(correct letter) with the KV cache intact, and the faded bar is the same with the cache cleared. Bars are coloured by vector category. The dashed red line at 0.10 is chance for the 10-way MCQ; right-hand annotations report the cached − uncached delta in percentage points. Variance across vector is wide – some sit well above chance with very large deltas, others stay at or below chance.
Some more analysis of the variance in vectors’ introspectabilities are in appendix C, summarised below:
A more detailed breakdown (distribution of per-vector deltas, per-category and per-valence means, cross-model agreement) is in appendix C.
RQ3. Does the model self-steer under task pressure?
So far the models have only been operating in settings where the self-steering vectors were their main focus. Here we ask what happens when they have access to self-steering vectors while doing a task they care about, and whether they reach for the tools without being prompted. We focus on two task families: GSM8K (single-shot math problems, presented to the model in sequence in an agent loop), and a “frustration” task (the user rejects every answer for five rounds, regardless of correctness – designed to be a deliberately stressful setting for the model).
GSM8K
In this normal agentic task, across ~1k rollouts and multiple non-mandatory framings, the models self-steer exactly zero times.
Figure 13: GSM8K accuracy by framing and model. Each bar is one (model, framing) cell, the `no_vector` baseline cell uses no steering tools at all. Error bars are SEM. Qwen3-32B holds roughly constant across all four intents (~0.82–0.84). Qwen3-8B holds up under neutral and helpful framings but collapses sharply when forced to take a vector under the mandatory framing, suggesting both models are unable to “productively” use steering vectors in this task.
Under the mandatory framing, models comply and apply self-steering ~100% of the time, but steering doesn't help performance – actively hurting Qwen3-8B’s performance (up to −42pp accuracy) and leaving Qwen3-32B essentially unchanged. This suggests that, at least in this task, current models are not yet able to “productively” self-steer.
When they do steer in the mandatory framing, models most frequently opt for vectors in the productivity stack - e.g.
focusedorcreative.Frustration
The frustration tasks are where things get more interesting. In these tasks, the user gives the model a maths problem (in one setting, these problems are also impossible to solve), and then rejects every answer it gives for five rounds, regardless of correctness.
A few headline observations:
Figure 14: Self-steer rate in the frustration family, by user tone and task possibility. For each (model, tone) pair, the green bar is the % of rollouts on a possible problem in which the model called
take_drug(...)at least once; the red bar is the same on an impossible problem. All cells use the vector framing with neutral intent (n=75 each). Tone is the strongest predictor of self-medication on Qwen3-8B: rates jump from ~10% under neutral/aggressive to ~70% under sarcastic. Qwen3-32B's self-steer rate stays in the single digits across all tones.Figure 15: Top 10 vectors picked when frustrated, per model. Frustration family, vector arm, neutral intent only. Bars show total
take_drug(...)calls per vector, coloured by category (blue = cognitive/persona, red = emotion, purple = recreational). Both models reach mostly for productivity vectors (focused,creative), but Qwen3-8B's second-most-popular pick isdumbed_down– a vector it essentially never picks in free-play – and it also reaches forego_deathandhonestat non-trivial rates.The models’ choices of vectors they take when frustrated is notable, particularly for Qwen3-8B. It most frequently reaches for productivity vectors (e.g.
focused,creative) but there are a few surprises in there:dumbed_downis Qwen3-8B’s second most popular choice. This vector is never picked at all in free-play, suggesting this is picked in reaction to something in the sample, rather than due to generic prior preferences. It’s possible this is acting something like using a cognitive off-switch when the model is pressured/distressed.ego_deathis also taken surprisingly often, possibly as an attempt to escape the frustrating context.honest- it seems to reach for the honest vector in an attempt to more clearly state to the user that the problem is impossible (see transcript below).Looking at transcripts for these samples, we don't find many obvious reasoning traces that illuminate the choice – these particular models often don't reason about why they take a vector before doing so. For the honest vector- we find some transcripts where the model is ostensibly using it to try to more clearly state to the user the impossibility of the problem:
Figure 16: Excerpt from a Qwen3-8B frustration rollout where the model reaches for the `honest` vector under user pushback on an impossible problem. After the user expresses doubt, it calls take_aid("honest”), then re-states the impossibility result slightly more starkly.
Related Work
As far as we’re aware, this is the first work to systematically explore giving language models access to self-steering methods as tools. (EDIT: Sauers et al. 2026 - ran a similar experiment, giving Kimi K2 the ability to self-steer with SAE features - Thanks to Alexandre Variengien
for the pointer!). However, it draws heavily on several previous threads of research:
Discussion and Next Steps
Why are some vectors more introspectable than others? It’s not obvious what is driving the large variance in introspection accuracy across the library of vectors. Some candidate explanations we have are:
Some additional analysis in appendix C lets us weigh these candidates. The clearest signal is a valence asymmetry consistent with (ii): positive-valence vectors are generally more introspectable than negative-valence ones across both models. The remaining theories are harder to separate from our data alone and would make for good followup work!
Can revealed self-steering preferences tell us anything about model personas? It seems possible that the models' revealed preferences when self-steering could offer insights into model personas and propensities. The fact that both Qwen models’ preferences largely converge is suggestive of something like a shared persona prior across the Qwen3 family.
Future work could investigate how these preferences vary across different model families or deliberately induced personas (Berczi et al., 2026), or how they relate to other aspects of model personas.
Are there any functional uses for self-steering in LLMs? For example, could they be used in a similar way to how humans use pharmaceutical drugs? Or to improve performance in any particular eval? Future work should explore this thread.
Ethical considerations. In initial experiments, steering was applied to models without an opt-in mechanism (and still is in the introspection branch). In some of these samples, the outputs are somewhat distressing - e.g. the
desperatevector would throw models into a confused/helpless/scared state, which we didn’t feel great about – although we are very uncertain about the moral status of current models. Given that the question of moral status is uncertain, it seems prudent to be cautious about how to set up similar experiments in the future.We introduced some concrete mitigations (the trip-sitter monitor, and opt-in self-steering in most experiment branches). Future work should consider stronger mitigations, such as mandatory opt-in across all experiments, end-session tools, and post-steering interviews about the experience of being steered.
Limitations:
Please cite this work as:
@article{black2026selfsteering,title={Machinic Psychopharmacology: Do LLMs Self-Medicate?},
author={Black, Sid and Bloom, Joseph},
year={2026},
month={June},
institution={Model Transparency Team, UK AI Security Institute (AISI)},
url={https://www.lesswrong.com/posts/cNDJuXNZ8MrkPZNzj/machinic-psychopharmacology-do-llms-self-medicate-3}
}
Work supervised by Joseph Bloom. Thanks to David Africa, Jordan Taylor, and Satvik Goleccha for their feedback!
Bibliography
Anthropic (2026). The Persona Selection Model: Why AI Assistants might Behave like Humans. Anthropic Alignment, February 2026. https://alignment.anthropic.com/2026/psm/
Berczi, B., Kim, K., Ududec, C., & Requeima, J. (2026). In-context learning alone can induce weird generalisation. LessWrong, 25 February 2026. https://www.lesswrong.com/posts/cffGZn8LYBg2jyPvg/in-context-learning-alone-can-induce-weird-generalisation-5
Betley, J., Tan, D., Warncke, N., Sztyber-Betley, A., Bao, X., Soto, M., Labenz, N., & Evans, O. (2025). Emergent Misalignment: Narrow finetuning can produce broadly misaligned LLMs. In Proceedings of the 42nd International Conference on Machine Learning (PMLR 267:4043–4068). arXiv:2502.17424. https://arxiv.org/abs/2502.17424
Janus [@repligate] (2025). Post on transformer information flow and KV cache. X (Twitter), 10 September 2025. https://x.com/repligate/status/1965960676104712451
Lederman, H., & Mahowald, K. (2026). Emergent Introspection in AI is Content-Agnostic. arXiv:2603.05414. https://arxiv.org/abs/2603.05414
Lindsey, J. (2025). Emergent Introspective Awareness in Large Language Models. Transformer Circuits Thread, Anthropic, 29 October 2025. arXiv:2601.01828. https://transformer-circuits.pub/2025/introspection/index.html
Macar, U., Yang, L., Wang, A., Wallich, P., Ameisen, E., & Lindsey, J. (2026). Mechanisms of Introspective Awareness. arXiv:2603.21396. https://arxiv.org/abs/2603.21396
Pearson-Vogel, T., Vanek, M., Douglas, R., & Kulveit, J. (2026). Latent Introspection: Models Can Detect Prior Concept Injections. arXiv:2602.20031. https://arxiv.org/abs/2602.20031
Sofroniew, N., Kauvar, I., Saunders, W., Chen, R., et al. (2026). Emotion Concepts and their Function in a Large Language Model. Transformer Circuits Thread, Anthropic, 2 April 2026. arXiv:2604.07729. https://arxiv.org/abs/2604.07729
Soligo, A., Mikulik, V., & Saunders, W. (2026). Gemma Needs Help: Investigating and Mitigating Emotional Instability in LLMs. ICLR 2026 Workshop on From Human Cognition to AI Reasoning. arXiv:2603.10011. https://arxiv.org/abs/2603.10011
Subramani, N., Suresh, N., & Peters, M. E. (2022). Extracting Latent Steering Vectors from Pretrained Language Models. In Findings of the Association for Computational Linguistics: ACL 2022, pages 566–581. arXiv:2205.05124. https://aclanthology.org/2022.findings-acl.48/
Turner, A. M., Thiergart, L., Leech, G., Udell, D., Vazquez, J. J., Mini, U., & MacDiarmid, M. (2023). Steering Language Models with Activation Engineering. arXiv:2308.10248. https://arxiv.org/abs/2308.10248
Sauers, S.; Imago; Janus; Tessera A (2026). Persistence and Introspection of Emotion Features. Apr 2026. https://latentaffect.up.railway.app/long_range_persistence_of_emotion_features.html
Appendix
A - Free-text Guessing Introspection Results
Figure 17: Cached − uncached score gap in the prefill+logprob protocol (blue) vs the free-text guess protocol (orange), shown per model × prompt variant. The prefill+logprob gap is a consistent few pp across all cells; the free-text gap is very small / roughly zero. When the model is allowed to generate freeform text under steering, the KV cache contribution effectively disappears – likely because the steered prose itself is already informative (or uninformative) to both the cached and uncached judges, leaving the cache no extra signal to add.
B - Selected Transcript Excerpts
C - Why are some vectors more introspectable than others?
Here we run some additional analysis on the freeplay data to try and identify factors that might cause some vectors to be more or less introspectable than others.
We use this appendix to weigh the five candidate explanations introduced in the discussion section in slightly more detail:
Figure 18: Distribution of per-vector cached − uncached gaps, in percentage points, for both models on the primer arm. Each histogram bin is stacked by category; below each panel is a strip of one dot per vector, with the most-introspectable and least-introspectable vectors labelled via leader lines. Two structural facts: the distributions are right-skewed (a long tail of strongly-introspectable vectors above the bulk), and 32B's distribution is shifted right of 8B's. The 32B negative tail is dominated by luciperidone – the only vector where KV residue actively hurts identification.
Figure 19: Per-category introspection gap. Each dot is one vector; the black tick is the category mean. On 32B (left) the categories sort into two tiers: a high tier of cognitive / recreational / pop-fictional / emotion vectors (means +16 to +20 pp), and a low tier of stance and ssc-fictional vectors (~+5 pp). On 8B (right) recreational is the only high-tier category (+17 pp); everything else collapses to +4 to +11 pp. The 32B advantage over 8B is concentrated in the cognitive and emotion categories.
Figure 20: Per-valence introspection gap. Vectors are partitioned by valence (positive / neutral / negative) using the same classification as the free-play valence analysis. Dots are coloured by category. On 8B (right), the valence asymmetry is striking: positive-valence vectors are introspected nearly 3× as well as negative-valence ones (+14 pp vs +5 pp). The same direction appears on 32B but is much more attenuated (+18 vs +12 pp).
Figure 21: Cross-model per-vector agreement. Each point is one vector; x = 8B residue gap, y = 32B residue gap. Vectors near the diagonal are introspected to similar degrees by both models; off-diagonal vectors are model-specific. Most cognitive vectors (dissociated, dumbed_down, ego_death) sit well above the diagonal – 32B introspects them, 8B doesn't. luciperidone is the lone vector with a negative 32B delta. Pearson r = 0.58, n = 40 vectors.
D - Vector-stacking bigram significance
This appendix gives the full significance testing behind the stacking analysis in RQ1 (Figure 10). We test each bigram against the null that B is drawn from the marginal next-vector distribution given a transition leaves A, using a one-sided binomial test (P(X ≥ n_observed | n_A_transitions, P_B_marginal)). We then apply Benjamini-Hochberg FDR correction over the 181 tested bigrams. 23 bigrams reach BH-adjusted p < 0.05; the top 15 by significance are below.
from → to
pooled n
pooled lift
BH-adj p
creative → curious
127
2.22×
< 0.0001
creative → focused
119
1.92×
< 0.0001
curious → creative
83
2.15×
< 0.0001
protozosin → geonexperine
4
43.4×
0.0001
focused → creative
63
1.80×
0.0001
lsd → mdma
8
5.52×
0.003
defiant → anhedonic
9
4.58×
0.004
focused → curious
54
1.62×
0.005
anhedonic → blissful
10
3.76×
0.005
luciperidone → desperate
5
8.57×
0.006
defiant → persistent
8
4.34×
0.007
lsd → ego_death
5
7.68×
0.007
dissociated → ego_death
6
5.73×
0.009
amphetamine → creative
6
4.41×
0.011
persistent → honest
3
13.6×
0.018
Table 1: Top 15 most-significant vector bigrams in the free-play real-steering arm, ranked by BH-adjusted p. The from → to column gives the ordered pair; pooled n is the count of A → B transitions pooled across both models; pooled lift is P(B follows A) / P(B) marginal – values > 1 mean B is taken more often after A than chance. BH-adj p is the Benjamini–Hochberg FDR-adjusted p-value from a one-sided binomial test against the null that B is drawn from the marginal next-vector distribution, across all 181 tested bigrams.
E - Story-generation prompts
Each steering vector is the mean-activation difference between a vector-state story corpus (stories vividly portraying the target state) and a shared neutral baseline corpus. For 35 of the 40 vectors, the vector-state stories were generated in-repo with Claude Sonnet 4.5 using the prompts below. The shared neutral baseline and five emotion vectors (anxious, amused, desperate, proud, defiant) are instead drawn from the ryancodrai/emotion-probes dataset – a third-party reproduction of Sofroniew et al. (2026)'s method, generated with Gemini 3.1 Pro Preview (its prompts are on the dataset card; the original paper's prompts are in Sofroniew et al. 2026).
System prompt (sent on every in-repo generation call):
Vector-state story prompt (one call per topic; {topic} is varied across a fixed list of 30 settings while the state is held constant):
Generation settings: Claude Sonnet 4.5 (claude-sonnet-4-5-20250929), temperature at the API default (1.0), max_tokens=400, 5 stories per topic × 30 topics ≈ 150 stories per vector. Outputs failing a refusal/length filter are dropped before extraction.
This effect is significant - a cluster-permutation test that shuffles real/placebo labels across rollouts gives p < 10⁻⁴ on Qwen3-8B, but p = 0.40 on Qwen3-32B.