This is a special post for quick takes by XelaP. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
For about a yearish I've been with varying frequency writing down things I've learned in a notebook. Partly this is so that I go "ugh I haven't even learned anything today, lemme go and meet my Learning Quota", which I find helpful (I don't think I'm goodharting it too much to be useful). Entries range from "somewhat neat theorem and proof in more detail than I should've written" to "high level overview of bigger subjects", or "list of keywords that I learned exist". For example, recently I learned that sonic black holes which trap phonons (aka lattice vibrations) are a thing, and the quantum theory predicts they should emit sonic hawking radiation, and unlike hawking radiation we've actually observed this directly by making a sonic black hole in the lab.
A side effect is that... wow I learn more than I think I do. My retention isn't perfect but it's a lot better than what I would've expected had I known I learn that much. Every month there's usually a handful of things I've learned that register as "Really really cool/important/fundamental".
Also: I think I learned the fastest when I was in highschool, when there were both more low hanging fruit and I was spending much more time on it (unrelated to school except that I might've done less had I had more friends). And glacially slow before that.
So... perhaps this explains a bit more of the thing where I and felt like I became an adult mind a little after the start of that 'intelligence explosion'.
I like how LessWrong now has Wikipedia preview (however over that link, it's a cute animal!). I'm going to pretend that it's because I mentioned how Gwern's window popups are part of what makes his website my favorite website design-wise and wished more websites had that.
Cthulhu above, it works for nature studies, science direct, substacks, and probably more!
Something I'm sure has been thought of many times but that I've never seen written down: sensory instruments/organs will tend to be fragile, because they need to be sensitive (that is, change in response to stimulus), and so you have to have something that's response/reactive. But then, if you way up the stimulus past the designed range, you change it so much it breaks - and e.g. physical damage is more likely to affect it since you can't just use a very stable structural element like a steel beam or structural bone.
By the way, this rhymes with the principle that I think I heard from a highschool teacher (I think she said it was from Blindsight but I've still got most of the book to go) that sensory instruments will tend to look "black" due to absorbing the medium.
However I think this is much less necessary! I've heard of ear problems that lead to externally audible reverberations from the ear (which the patient can often hear). This will hurt the sensitivity (since there's (in this case literal) noise), but you can still sense with it. The general principle: you don't necessarily have to absorb all the input. The hairs in the organ of Corti don't need to move that much; and I don't think a gravitational wave detector reduces the amplitude of the wave (though if it does, it must be by extremely little).
Thanks to @Raelifin's Utopian Dreams for showing me the power of TL;DR:'s at the start of every post. If it weren't for substack thinking I was a robot or something, I would like even the posts where I read the TL;DR: and go "this is all I want right now from the post, then".
I read like 3-4h of posts every day and at this point I try to put most posts that have the slightest chance of being retroactively not worth reading into LLM and ask for a summary instead
It looks like frontier models should soon beat Metaculus community forecasts, and if the trend holds they'll be beating pro forecasts by the end of 2027.
https://www.metaculus.com/futureeval/
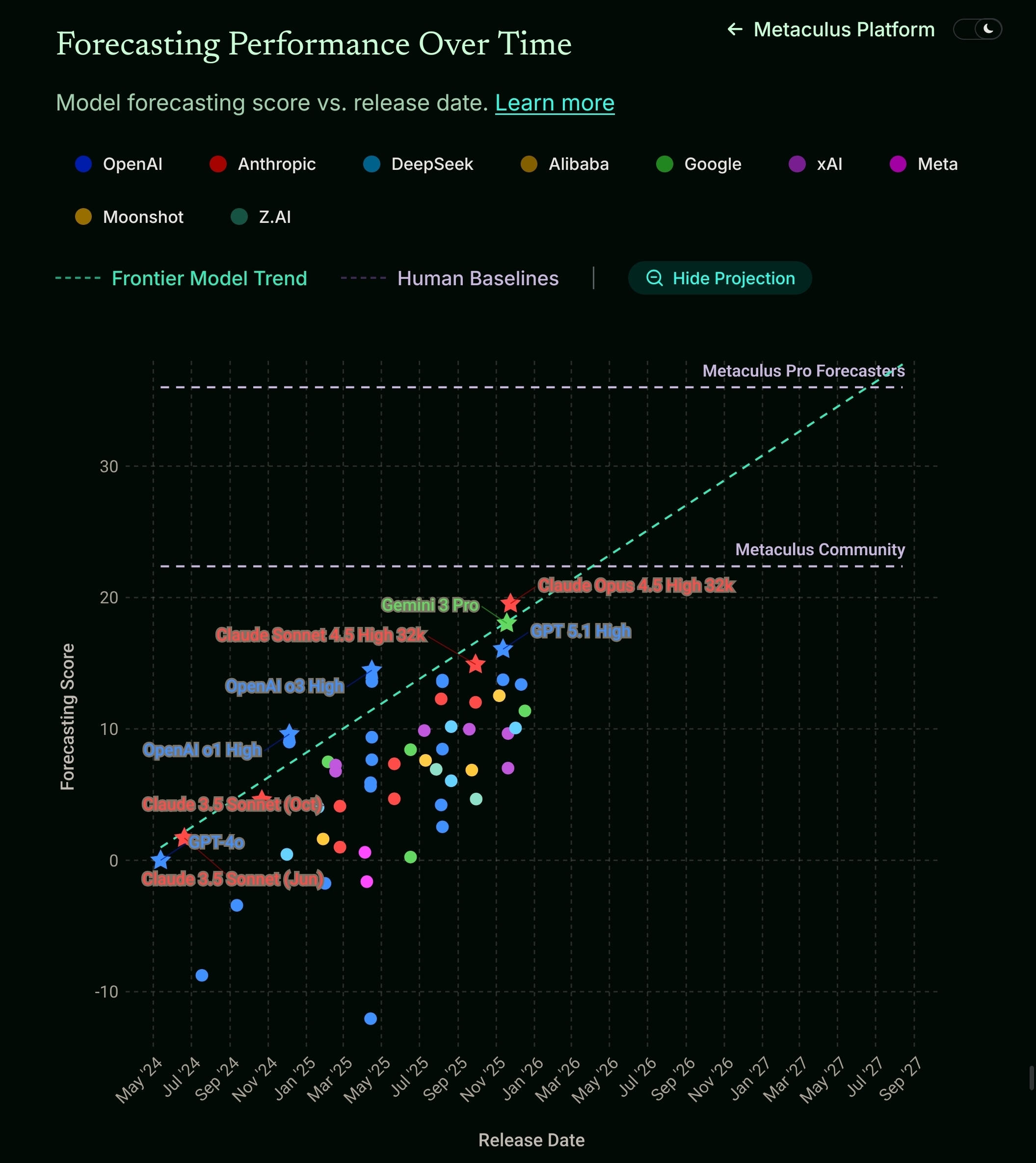
(the site's plot isn't as blurry as my quick screenshot, sorry).
Metaculus questions (currently pending review):
When will AI beat Metaculus Community?
When Will AI beat Metaculus Pros?
I wonder how the AI prediction about AI predictions compared to the human predictions compare to the human predictions.
Xela's Learning Diary
In case some people want to see a (hopefully more filtered?) version of the 'learning diary' I mentioned before, I'll comment stuff as replies to this post.
These will usually be about stuff I learned before the date published - but the date on the entry should be roughly right. It'll also be more verbose, since I can't assume you already know what I do.
April 30th-May 4th
0: Well, it looks like I'm learning Infra-Bayesianism! Frankly, it seems like every current distillation is subpar; so this may take longer than in the alternate universe where they didn't. One thing I hope to do, then, is make one that sucks less, or at least differently.
So far, I'm mostly through (with the exception of the proof sections, for later) Fundamentals of Infra-Bayesianism. It seems like most of the intimidating difficulty is just type signatures, as opposed to difficult concepts? I definitely expected it to be harder! While this still takes time and focus, it is easier than if I was presented with a conceptually difficult piece of math on every line.
One thing that seems way underemphasized is this fact that's buried in the part four:
If the full state space is finite, then each credal set
is ... isomorphic to a closed convex polytope given by a vertex representation.... Computing the Markov optimal policy for finite time horizons
... If the time horizon is finite, there is an efficient algorithm to compute a Markov optimal policy for a special class of supra-MDPs. In particular, we require that for all
and there exists an efficient algorithm to maximize a linear functional over the credal set For example, this holds for polytopic supra-MDPs.
This fact finally gives an[1] answer to the question I've been having the whole time I've heard of Infra-Bayesianism, namely: how the hell is a set of probability distributions supposed to be easier to reason about than just thinking about mixtures??
But now, there's an obvious story! Since we take closed convex sets (convexity is due to mixtures being mixtures; and you can make it closed without screwing things up, so it's better to do so, I think?), you can just do linear programming to optimize on them. But then you can easily compute the worst case of a linear utility/loss function. You can thus easily compute bounds on the worst case, that work for any mixture, without ever having to hold the mixtures in your head.
Likewise, the whole section that this quote is from is enlightening: it's about coarsening a Markov decision process. That is, you consider some states equivalent in your 'lossy' view of the process, and then you can use Infra-Bayes's credal sets to express your uncertainty despite having no clue which of the 'low level' states in a 'high level' equivalence class is the true system state.
1: Apparently, I said that 'someone should' do something 2 months ago? It doesn't even look that hard, I'm not sure why I didn't just do it, or at least mentally think of it as on my todo list. I just noticed this, so I'll try my hand at it in the morning.
Kinda funny to happen upon 'homework' given by yourself.
There were a smidgen of other things, but not covered deeply enough for me to want to put them here.
- ^
I assume there are similar facts, that I will get to see eventually.
April 23
0: Here's a reframed explanation I thought of for some famous facts:
Suppose p is a polynomial with s as a root. This gives us an algebraic identity we can use to reduce any larger powers of s, e.g. s^2 + 3s + 4 = 0 tells us that s^2 = -3s - 4; likewise we get that s (s + 3) = -4 so -(s+3)/4 is the inverse of s. This comes up often, e.g. it's why if you have s algebraic of degree n over a field then the extension basically looks like a vector space with powers of s up to n-1 as the basis vectors, and you can additionally get the inverse just via polynomials of s. In other places, it's how you quotient the ring of polynomials by some polynomial ideal to get the polynomial ring corresponding to the variety of solutions.
In general, what we can do is take any other polynomial f, and then do polynomial long division to get
f(x) = q(x) p(x) + r(x), r of degree smaller than p.
Then if we plug in x=s we get f(s) = r(s) since p(s) = 0; and r is of smaller degree.
If p is the minimal polynomial, and f has s as a root, then we have a contradiction because r is of smaller degree and must also have s as a root.
Supposedly, if we have an analytic function f(x) = \sum_k a_k x^k, then we can do the same thing with p = the characteristic polynomial of a matrix A, and then f(A) = r(A) and we have expressed our analytic function of A with a polynomial of degree < degree of the characteristic polynomial.
In this case, also know that the eigenvalues are roots of p, so we can conclude that
Therefore, you can "interpolate" analytic functions of matrices if you know only the values when you plug in the eigenvalues, and you'll get to know exactly what the function outputs - you'll exactly interpolate it. This is where those exponential formulas for SO(3) and SU(2) come from
(I got here by reading the wiki page on the Cayley Hamilton theorem, and the analytic function interpolation thing surprised me (I had thought you needed more conditions to make it work, and this explanation is different anyways), and it led me to realize how a couple other things were also the same remainder argument).
April 20-21
0: I did most of the topological fixed point exercises on the 20th & the morning of the 21st, and then did most of the iteration fixed point exercises on the 21st. I liked the diagonalization ones the best, then the topological ones come in second (unsure how to explain why - just feels like coolness : complexity is lower), and the iteration ones come last (I think because I already know the contraction mapping principle very well, and unlike the topological ones there isn't a cooler proof to dazzle me with; the lattice ones didn't feel that novel given the spiritual similarity).
1: As a subpoint, the fact that there's a unique closest point in a closed convex set S to any point p in euclidean space was pretty neat, and further acts as an enticing advertisement for me to read Boyd's Convex Optimization
2: Apparently, the Wikipedia page on fixed point theorems really does basically just list variations on Diagonalization/Brouwer/Iteration. Perhaps I should take the couple best, and write a post on them?
April 14-16
I think I spent most of my usual learning time on the 14th and 15th reading through Steven Byrnes's Intro to Brain Like AGI series.
0: Apparently I didn't know some pretty easy to show weird stuff about tensor products of modules? For example:
1: Thinking about the Diagonal Lemma again this morning, and I managed to prove it in like 10 minutes or so, when back on the 10th I had failed after much longer. Funny how that works! I'm about to put my proof in my comment on the diagonalization fixed point exercises. This means all that's left is quining.
April 11-13th 2026
I was kinda grumpy over the weekend, and accordingly learned less.
0: All elementary functions (functions that you can write with +,-,x,/,powers,roots,exponentials, logarithms, (and of course sines and cosines), i, pi, etc.) can be written with a single operator:
eml(x,y) = e^x - ln(y)
along with the number 1.
(the operations are defined so that, say, ln(0) = -inf, e^(-inf) = 0, ln(-1) = i pi, etc.)
Try it out yourself!
1: Imagine that we are playing chess, but this time, we bid for the right to move (the highest bidder pays the lower and gets to move). (and I think you have to imagine that draws don't happen/are a win for black). (alternatively, imagine that two of the AIs from Crystal Society are playing chess, and have to bid for what the robot does with their internal influence).
This could be called Bidding Chess. Given any loop-free combinatorial game G, we can make a bidding version. There will then be some critical value R(G) (R for Richman) such that if the first player has more than that proportion of the money, they can always win; but if they have less, the opponent can always lose (what happens on ties depends on details like how tied bids are resolved and I think also on the details of the game?)
Surprisingly, there's a connection to the stochastic game where instead of having an auction for who moves, we just flip a coin. Specifically, if P(G) is the probability of winning, then R is 1 - P(G). Furthermore the optimal moves are the same in both games.
The proof is simple!
they follow the same recurrence relation: for probabilities you obviously get of P(G) = (P(game after best move I can make) + (game after best move opponent can make))/2. For bidding, you need enough that if you won the bid you can still win but if you lost then you are assured you can still win. So if you are just above the midpoint you can bid to win in both cases, but if you are just below it then you will lose in both.
Thus you can also think about the coin flip game as what you get if you randomly decided what proportion of the money goes to each player.
Interestingly, there are allegedly quick algorithms for near-optimal random-turn Hex, and so also for bidding Hex. This is apparently because random turn hex's win probability is equivalent to the probability of winning if the players make random moves. Therefore you can basically do monte carlo tree search but with better bounds.
In fact this is true for all selection games, which means a game where two players alternate between choosing elements from a set, and then once all elements are chosen the (zero-sum) score is determined based on what was chosen. You can prove this by strategy stealing: if they both execute the same strategy then the value of the game is the same as if every hex has a 50% of being chosen by player 1.
This might remind you of percolation problems - though I know basically nothing about those. the paper uses this to show that up to an error term (+o(1)) that goes to zero as the board size goes to infinity, the probability of winning is conformally invariant due to some magic formula called "cardy's formula" from percolation theory - but the strategy changes (because the probability of a move being 'pivotal' goes down for larger boards, and conformal maps can scale regions differently).
2: The Kolmogorov-Arnold representation theorem (or superposition theorem) is neat. The idea is that you can always write any multivariable continuous function with addition and single variable continuous functions. That is, there's some universal functions u_{q,k} so that for any function f from the unit box [0,1]^n to the reals can be written as
3: qutrits (that is, the trinary version of qubits) are a thing. The gates are given by the elements of U(3), which are the rotations (exponentiated elements of SU(3), that is, the gell-mann matrices like with color charge) along with a global phase shift. Compare the qubits where it looks like a global phase shift can be made with just the rotations. This is like how there're only 8 gluons instead of 9.
I'm somewhat curious about how you found these stuff. It would help me (and others reading) to find more good sources to read if you link back the original.
Will try to do so!
I found the exp - ln thing on twitter (and I've seen a fair number of others talk about it).
For bidding games: I think I was either clicking links on the wiki page for Conway's Soldiers/phutball, which the got me to this article on 1D phutball which I ignored entirely but that made me wonder what this More Games of No Chance book was, which I also basically ignored except that I think I googled the phrase "Games of No Chance" which somehow led me to Games of No Chance. Once more, I basically ignored that, except that I read the description, which says:
...Enthusiasts will find a wide variety of exciting topics, from a trailblazing presentation of scoring to solutions of three piece ending positions of bidding chess. Theories and techniques in many subfields are covered, such as universality, Wythoff Nim variations, misère play, partizan bidding (a.k.a. Richman games), loopy games, and the algebra of placement games. Also included are an updated list of unsolved problems, extremely efficient algorithms for taking and breaking games, a historical exposition of binary numbers and games by David Singmaster, chromatic Nim variations, renormalization for combinatorial games, and a survey of temperature theory by Elwyn Berlekamp, one of the founders of the field.
Most of that sounded kinda boring or stuff I already had on my "stuff to look into sometime" list (I've heard of miseré games, and of temperature of games; I haven't heard the name "loopy games" but I'm pretty sure I've seen an example and know what is meant), but I'd never heard of "bidding chess" nor that there was something like renormalization but for games. Renormalization sounds complicated (I haven't yet learned the original version for quantum field theory!), but bidding chess sounds simple, so I googled that, which led me to the first thing I linked about it.
For the Kolmogorov-Arnord Representation: The elementary function paper linked to a whole bunch of stuff (imo I think they should've cut it down - do you really need to link to Napier from the 1600s??), and one of them was this paper on KAR networks as a hope for more interpretable machine learning. The thing that stuck out to me was that Max Tegmark (who I only somewhat recently learned cofounded and leads the Future of Life Institute) wrote it, and the paper originally just looked like an attempt at making breakthroughs in capabilities (whereas now it looks like that it's at least not the point, even if it seems to me more likely to up capabilities if it works than interpretability).
I don't know how I got to qutrits.
April 7-8th, 2026
I seem to have learned less on the 7th than I did on the 6th. I'm not sure why. Lumping in with the 8th due to thinking about a thing about peg solitaire I heard on the 7th.
0: I recently saw Mila Jovovich's AI memory system mempalace, which does very well on AI memory benchmarks. Beware, it seems like people poked some pretty big holes like a couple blatantly wrong performance numbers, though not on the most loadbearing stuff (like how well the non-experimental version performs on the benchmark), as mentioned at the top in the "Note from Milla & Ben".
Interestingly, it can do amazing without using an LLM the normal way - it stores all the input verbatim, and uses word embeddings (which by itself gets you 96.6% accuracy) and manual heuristics to retrieve the right entry upon asked. You can add an LLM to make the final calls, improving accuracy.
They then structured the database like a literal memory palace, with wings, halls, rooms, etc., each representing various levels of a hierarchy. There's also an experiment 'AAAK dialect' which I see as "human designed baby neuralese" that lossily compresses the important information in text. Here's an example (they screwed up the token estimates and notably it doesn't save tokens in this small example, and so they are remaking one that is supposed to show the intended effect for larger scales with repeated entities mentioned):
the 66 token long:
Priya manages the Driftwood team: Kai (backend, years), Soren (frontend), Maya (infrastructure), and Leo (junior, started last month). They're building a SaS analytics platform. Current sprint: auth migration to Clerk.
Kai recommended Clerk over Auth0 based on pricing and DX
turns into the 73 token long
TEAM: PRI(lead) | KAI(backend,3yr) SOR(frontend) MAY(infra) LEO(junior,new)
PROJ: DRIFTWOOD(saas.analytics) | SPRINT: auth.migration→clerk
DECISION: KAI.rec:clerk>auth0(pricing+dx) | ****
The main implication to me is that there's more of a 'harness' overhang than I thought - this approach seems surprisingly simple. I have updated towards expecting more jumps in capabilities as 'harnesses' and 'tooling' get more innovation.
1: That euro peg solitaire impossibility thing from the 7th is best viewed via group theory[1]: we want to assign a group element representing an invariant of the board. Now we can imagine taking the "peg-sum" of two board states, by adding the pegs together[2]. The order clearly doesn't matter, so we should search for commutative groups.
Now, we only need to know what the group element associated to having a single peg on a single square is. So we can think of assigning the elements to every square. We then add up all the occupied squares to get our game state group element.
Now, take four squares in an orthogonal line, with group elements labelled A B C D. Since having a peg on B and C lets us do a hop to get D, we have B + C = D. We also have B + C = A because we could hop in the other direction. Thus D = A.
Also, note that A + B = C and B + C = A. So B + B + C = C so B + B = 0. Likewise, A + C = B gives us A + A = 0 and C + C = 0.
So, here's the most general labelling, with 9 labels for a generating set of our group (and let's say that I is the identity).
ABC
XYZXY
LMNLMNL
BCABCAB
ZXYZXYZ
MNLMN
ABCWhere (I, A, B, C), (I, X, Y, Z), (I, L, M, N) are copies of the klein four group that are subgroups of our group.
So, to solve our problem, we can just choose L=X=A, M=Y=B, etc. Then the game state group element depends only on the parity of the number of pegs occupied in each type of square, because two copies of an element give you 0. If we start with an unfilled hole in the middle then they'll all have even parity, so the invariant is 0. However if we managed to win the game, we must have invariant A, B, or C. QED.
However, I want to know about the most general group we get here.[3]
Note that every element plus itself is the identity. We have what's called an elementary abelian 2-group aka a Boolean group - they're all just vector spaces over the integers mod 2. So the size must be a power of 2. Currently, we have 10 elements, generated by the 6 elements (A,B, X,Y, L,M).
Now, for short I'll write a string like CXM to mean C + X + M = 0 (and M + C = X, etc.). CXM is true as you can see from the board. So is AYN. We can derive BZL, but these are the only things we can get by looking for "vertical" triples. So we had the 6 dimensions from our generators, and can remove 2 of them.
We can therefore use A,B,X,Y as our generating set: L = B + Z, M = C + X, and N = A + Y. Our 6 other elements are:
A + X, A + Z
B + X, B + Y
C + Y, C + Z
This is helpful: this means that X + B cannot give us a win, while if we just used the klein four group we'd not be able to see this (as X = A so A + B = C is a single square).
Now, the board has 4 of each type of square except for that it has 5 of B. Thus a full board gets the invariant B.
As an example: If we start with holes on the two N and X squares that are diagonally adjacent to B, we'll get a group element B + N + X = B + A + Y + X = C + Z. Therefore, we can't win this game either. The klein-four only version would've computed B + C + A = 0 and thus wouldn't have been able to say anything about this case.
I think all this was pretty interesting. I feel like I have a better understanding of how people actually come up with those magic invariants all the time. I'm also pretty sure I just re-invented something like the nim-sum.
2: I finally have an animal that evokes the feeling that I think people get from their "favorite animal": the tuatara. Cool tuatara facts:


Here's a page just about Henry. Isn't he so cute! He was still alive in 2024 at the age of 130, and I can't find anything about him dying, so he's probably still out there.
He has seen more seasons pass than any human. He knows that you are still allowed to look cute in your centennial. He's met a Prince.
Tuataras are reptiles but aren't in the subcategory of lizards, despite the obvious resemblance. Their eyes can focus independently like chameleons, so in principle maybe an intelligence augmented tuatara could maybe read two books at once? They're also one of those animals that have a third, parietal eye, that can do some residual light perception but that may only come into play for circadian rhythm or other stuff.
They don't hear that well, as you may have suspected from the fact that they don't even have ears or eardrums. They do have a stapes bone like we do, but it's in contact with the skull I think.
They can hear from 100-800 Hz, with peak sensitivity at 40 dB at 200 Hz. 100 Hz is near the note G2, while middle C (C4) is 261, tenor C (C5) is 520, and soprano (C6) is 1000 - Henry can hear up to about a G5 (780).
So it seems like Henry should probably be able to hear most of Hayley Williams's voice in Paramore songs (random sampling the Wiki pages on some of their songs, they tend to feature her topping out at an E5 (660 Hz)).
For comparison, humans can hear from 20 to 20k Hz, up to about 120 dB. 130 dB is a painful rock concert, a motorcycle at 5 mph is like 100, busy traffic 70, normal conversation is like 60-70, background noise in a room is about 20-30, and human breathing is 10 dB.
3: I skimmed a couple studies about whether there's some tendency for humans to perceive higher pitches as coming from physically higher locations. It seems like, maybe? It's also claimed that most languages use the "high-low" analogy for pitch, though I haven't seen actual numbers on this (let alone whether they agree on the direction). I wonder if it's like some of the kiki-bouba speculation - if deeper sounds come from larger objects which are more likely to be down near the ground, and higher sounds come from things like birds (or maybe just other humans?), then perhaps this is where the bias comes from.
4: Remember that thing about norepinephrine type drugs? Well there are alpha_2 agonists, mimicking the effect on the alpha_2 receptors, and this includes the clonidine I mentioned earlier as well as a medication I'm already on: guanfacine. Apparently those two have some observed withdrawal symptoms from sudden withdrawal (? I haven't observed this when I forget to take my guanfacine), but atomoxetine doesn't
The overall lesson is that I should bump up learning some model of what the norepinephrine system in the brain is doing, at least with regards to motivation in the brain.
- ^
h/t to an interneter who I introduced the puzzle to for the core of this. Evidence that it's a good lens is that when I saw the solution I thought "hmm, I don't think I would've come up with this", and yet they did, via thinking this way.
- ^
Technically this would require you to be playing, like, "stacking peg solitaire" where you can have multiple pegs in a hole, and moving a peg captures one of the pegs on the stack of the jumped hole and adds a peg to the stack you land on. If you want to make the peg-sum a group op you'll need to allow negative pegs, which I'll imagine as contagious dead soldiers that you can throw over the battlefield.
- ^
Every 'weaker' invariant is then a quotient under the subgroup generated by some relations, e.g. for Klein four we added the equations setting the ABCs equal to the XYZs and LMNs.
April 6th, 2026
0: Electrons have an electric dipole moment (which has to be collinear with the magnetic dipole moment)! This is apparently predicted by the Standard Model, and various speculative physics theories predict different substantially bigger values. Also a minimally extended standard model that includes neutrino mass (the standard model predicts they shouldn't so we add it on as a kludge) predicts neutrinos have really tiny magnetic moment (electron neutrino's at 19 OOMs smaller than the electron's), that scales with the neutrino mass (and we observe the electron neutrino's is at most 10 OOMs smaller). Don't worry though, the less weird chargeless particles like photons and Z bosons (and presumably also gluons and the Higgs) shouldn't have a magnetic moment
1: I've already heard of selective serotonin reuptake inhibitors (SSRI) for depression, which inhibit serotonin reabsorbing into your neurons so that more of it's floating around. Recently while trying to solve my severe 'executive dysfunction'[1], a gracious interneter introduced me[2] to strattera/atomoxetine, which is a selective norepinephrine reuptake inhibitor (sNRI).[3] Yes, this means it's not a central nervous system stimulant! atomoxetine has been mentioned on LW[4] before - there's a metanalysis reporting Cohen's d's that vary from like .4 to 2 depending on details, and it possibly takes 4 weeks to build up.
I also wonder if it takes time to buildup due to whatever reason (iirc not well understood) SSRI's take time to buildup.
2: I learned that some meditators claim to be able to choose to cease their consciousness, somehow. My first question was "I wonder if anyone's done this under an fMRI" and apparently they have: I was linked to these two studies which I have briefly skimmed. More evidence for "meditators can do some impressive mind hacks even if they tend to be too woo-y or have too different goals from me for me to pursue it".
3: I already knew about Fischer's sex ratio equilibria. Recently I saw a study looking at whether the sex ratio bias in tetrapods is in the direction of the sex that has two of the same chromosomes (e.g. birds and snakes almost all use ZW sex-determination where two Zs makes a male and ZW makes a female, while most mammals are XY). The hypothesis seems to check out, but only explains ~30% of the variance in sex ratio.
For haplodiploid sex determination like colonies, there's this argument that while queens benefit from both sexes equally, workers benefit more from worker sisters (who they share 3/4 the genes with) than drone brothers (1/4 relatedness), at least under some spherical-cow assumptions like a single queen that mated once and where thorny details that could cause deviations aren't relevant[5]. So, this means:
a: the queens and the workers have different interests. According to the ant wiki (I love the internet), the sex ratio seems to often be around 3:1[6] implying workers control the means of reproduction.
b: There's a famous argument that haplodiploidicity's greater genetic relatedness promotes eusociality[7], but note that if the sex ratio was 1:1 than workers would on average have 1/2 relatedness, just like us. However, this should be rescued if they have a 3:1 ratio, as then they are 3/4 * 3/4 + 1/4 * 1/4 = 5/8 related.
4: Peg solitaire is a game from 1700 where you basically control all the pegs, which can do a single 'checkers capture' hop over one other orthogonally adjacent peg, thus removing it from the board. The goal is the remove all the pegs but one.

The Euro version is impossible if you put a hole in the center. This is because you can color/label the board like so:

(if you're reading this, and want to make me happy, perhaps you can make a visual of this with colors instead of letters and put it on the wikipedia page?)
Each diagonal is assigned a letter, and the letters cycle through A,B,C as we change diagonal. Now, any peg capture will always change the number of pegs that are on A holes, B holes, and C holes, each by one (one must leave one of the three, capture a different one of the three, and land on the remaining). We start with 12 pegs in each hole if we leave the center empty, and so we just showed that the number of pegs of each in each letter-class of hole must have the same parity. But to finish the game you need to have 1,0,0 pegs in each class.
Conway's peg soldiers is a game is where you choose a ("peg army") behind a horizontal line that can get you to the vertically farthest row past the line after moving your soldiers via the peg solitaire rules. The surprising thing is that you can easily get to rows 1-4, but can't get to the 5th row!
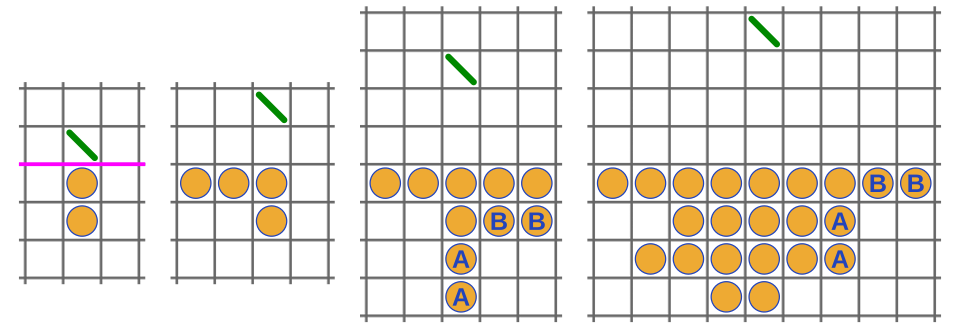
The argument's on the wiki page. I had a glance of it and now want to see if I can come up with it myself knowing only that
it uses the golden ratio, a 'carefully chosen' cell weighting, and a geometric series
Probably not, but good to try.
I don't really know what this word means. The people that talk about it seem to be talking about something similar to my problems, so I'm using it. I also have ADHD, so probably it's the right thing.
- ^
Specifically I was recommended to take it in combination with the concerta/methylphenidate I already have, as they reportedly also found that concerta alone didn't feel like it was really affecting my issue instead of 'just' giving me more energy. They had read this recommendation on the internet, then their psych recommended [clonidine](https://en.wikipedia.org/wiki/Clonidine) due to straterra having a drug interaction with one of their other medications, and found it helped with the central problem.
- ^
idk why the 's' isn't capitalized like in 'SSRI'.
- ^
Ctrl-F atomoxetine, as it's well into the body of the text and only mentioned in a single sentence.
- ^
It seems like the thorny details can do things like introduce additional apparent genetic conflicts of interest, or remove them.
- ^
The citation is to Trivers and Hare, 1976, which I haven't read yet.
- ^
Though note that the two eusocial rodents (naked mole rat and damaraland mole rat) still have XY sex determination, and
April 29th
I did the first 4 exercises of the Infra Exercises Part 1 problem sheet. These took me longer than expected, though I think partly this was situational (as in, things were easier hours later, after a nap and snack and soda, in a different location, with music on), and partly I am worse with vector inequalities than with real analysis type inequalities. It wasn't cognitively straining, it was just that algebra bashing wasn't leading me places.
Multiple things got much easier when I chose the appropriate reference point to take all vectors with respect to. Apparently my following my nose abilities are good enough in that case!
Also, what the hell was I doing in the fixed point exercises that led to a significantly overcomplicated proof that closed convex sets have a unique closest point to any point p?? I came up with such crazy shit instead of just "... it's an isosceles triangle, drop the height and you get a shortcut".
The most interesting of those so far was proving the hyperplane separation theorem for finite dimensions.
April 24-28
I spent most of the 25th and some of the 26th thinking time thinking about natural latents and symmetries. On the 26th I mostly got nothing done, as I was tired and grumpy - it was actually quite unusual, I'm not sure why I was in a funk for at least half the day. Most likely candidate was that I had been not eating well the previous days, on account of underestimating the appetite suppression effect of current medication that I've been now taking regularly.
I don't have good memories of what I did on the 24th. Looking at my comment history, it looks like that's where I got started on the symmetries thing, which is cool. Looking at my browser history, it looks like I was fishing for examples of basic representation theory, so I was staring at the discrete fourier transform and the more representation theory fourier stuff (like on a finite group). The takeaway for me was mainly that the Hadamard transform that I encountered years ago is in fact what you get when you use (Z/2Z)^n. You (well, at least, I did so, it's not explicitly listed on the Wiki page but I think I'm right) can interpret this as the subspaces of functions on the vertices of the hypercube, corresponding to the way it is affected by bit flips. I also learned that the Walsh functions (the analogue of sine and cosine in this setting) can be interpreted as taking in a truncated bitstring of a number in the interval [0,1], and then they'll actually be a complete basis (as long as you allow limits, that is, a schauder basis).
The rest of this, then, is from today (the 27th). Another thing I did today was put my recent and old code on github. If you want to look at monstrosities written by my teenage self, you can now do so. Yes, I used to use three spaces to indent. Yes, I put a hyphen in a directory name. Yes, I put spaces in filenames. Oh, and good luck with the sparse comments.
0: I was thinking about how you could get fractals as unique fixed points. The nicest way is with an iterated function system of contraction mappings that gives the similarities. The iteration map as a function from subsets to subsets will be a contraction mapping in the Hausdorff distance (exercise for the reader - it's not that hard!), and the Hausdorff distance is complete on the nonempty compact subsets. So you can get unique fixed points on nonempty compact subsets, and iteration converges to it under the Hausdorff distance. e.g. you don't need to use a triangle to get the Sierpinski triangle.
Also, the way I think about Hausdorff distance now: the distance is <= c when c upper bounds the values of d(x,Y) and d(X,y). Alternatively, X is in the c ball (union of points <= c away from a point in the set) of Y and Y is in the c ball of X.
1: Suppose we have a possibly nonlinear map T: V -> W where V is an inner product space, such that <Tx, Ty> = <x, y> for all x,y. That is, it's 'unitary but nonlinear'. If T is surjective, then we can actually show that it's linear: since <T(x+z), Ty> = <x+z, y> = <x,y> + <z,y> = <Tx, Ty> + <Tz, Ty> = <Tx + Tz, Ty> so <T(x+z) - (Tx + Tz), Ty> = 0. If T is surjective then we can make Ty equal the term in other the argument - but then the positive definiteness of the inner product means that T is linear.
If V was merely a normed space, then the Mazur-Ulam theorem says that a surjective isometry must be affine over the reals - or in other words if 0 goes to 0 then it must be linear as a map over the reals. However, if we have complex vector spaces then we might not be linear.
1: The representations used in quantum physics are really projective representations, since quantum states are invariant under scaling. One can typically lift these to representations of the universal cover for lie groups, because you can look at the lie algebra, then deprojectivize, then exponentiate at the cost of losing any global "twist" information.
2: Apparently the Wigner classification of the positive energy finite mass unitary irreps of the Poincare group includes the possibility of massless particles with 'continuous spin'?? And nobody's observed fundamental particles like them and only recently have we suggested possible theories for them? What the hell??

April 22
0: I came across this on Wikipedia (I think while clicking on fixed point theorems):
First, note that if we have an involution (meaning self inverse) on a finite set, then the number of fixed points has the same parity as the size of the set.
Next, we'll prove Fermat's sum of 2 squares theorem. Suppose we have a prime p>2. If it's the sum of two squares, then exactly one of them must be even (because p is odd), and thus must be a multiple of 4. This proof is due to Zagier, with the visual interpretation by Spivak, supposedly math overflow
Therefore, a prime is a sum of two squares when x^2 + 4 y^2 = p
Now let's look at the set {(x,y,z) : x^2 + 4 y z = p}. Clearly if we have a fixed point of the obvious involution that swaps y and z, we'll have proven that p is a sum of two squares.
Now, we'll come up with another involution. Or maybe you, dear reader, can? The first step is to come up with a geometric interpretation of a point (x,y,z) in the set.
Make a square of side x, and put 4 y by z rectangles around it like a 'windmill' (precise arrangement details are in the earlier link if you are confused).

Now our involution:
There's often a different way to cut the shape into a central square surrounded by rectangles.
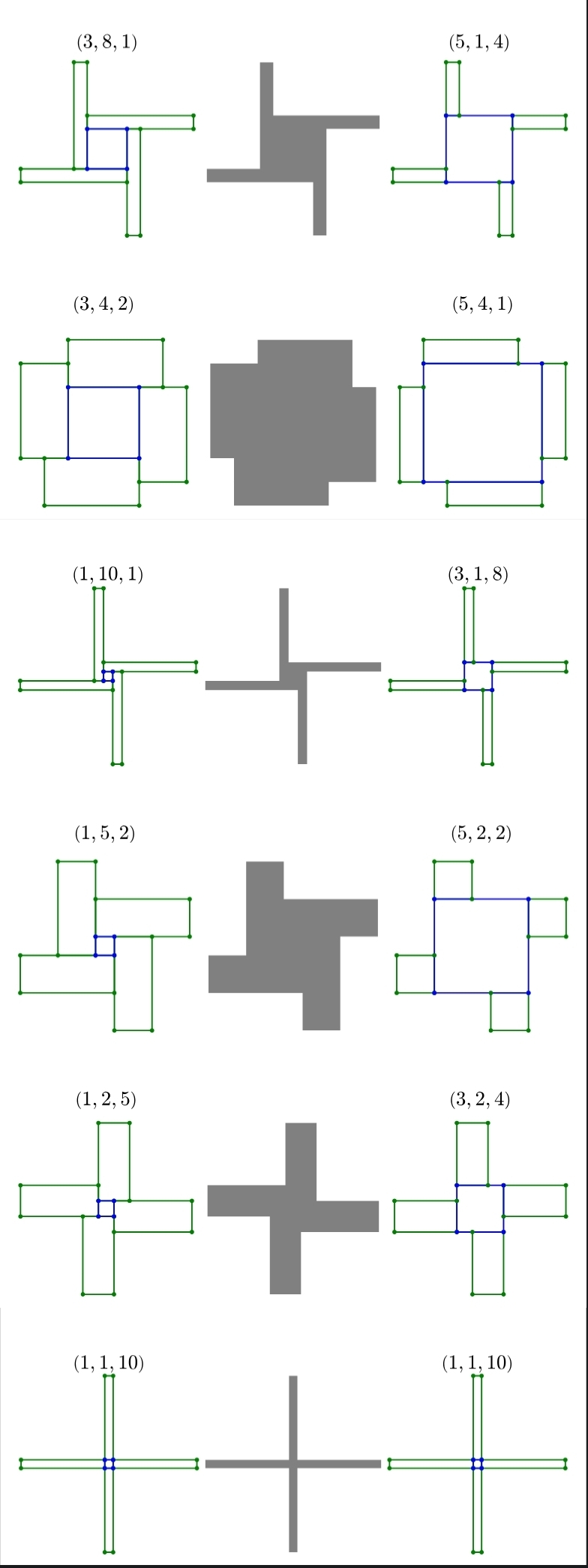
The only way to have a fixed point is for the area to be a big square with four squares removed. This will leave a square behind, along with four long rectangles. If x=y, then p = x(x+4z), but then since p is prime, x must be 1 and p must be x+4z = 1 + 4z. So for p = 4k + 1, we can make the fixed point (1,1,k), which is unique. Thus there is at least one fixed point of the swapping map, so we can write p as a sum of two squares.
1: Generalizing:
The lemma that is not Burnside's (which, incidentally, was what initially enticed me into learning group theory) states that if you have a finite group G acting on a finite set X, then the number of orbits equals the average number of fix points of g (averaged over G).
That is, |X/G| = 1/|G| \sum_g |X^g| (if you know representation theory: this is also the number of copies of the trivial representation in the permutation representation, because the projection to the trivial representation is 1/|G| \sum_g g, and this gives a vector parallel to \sum_{x in O} e_x for every orbit O, and these are linearly independent for to different orbits).
Thus, |G| |X/G| = \sum_g |X^g|. If we take this mod n for t = |G|, we'll get 0 = \sum_g |X^g| mod n, or in other words the sum of the number of fixed points for each g must divide n.
The fixed points of the identity are everything, so \sum_{g ≠ e} |X^g| = -|X| mod n
If we have an involution, then we have a Z/2Z action, and that's why the parity must be the same.
2: A trick: Say we have a finite degree field extension E of K, and a group of field automorphisms of E that fix K. Then not only do we have a represention on E thought of as a vector space/module over K, but we also have a representation on the abelian group of units E^× under multiplication thought of as a Z-module.
So we can do things like map to the copies of an irreducible representation τ via p = \sum_g χ_τ(g^{-1}) g, and then also project to the trivial representation via the product \prod_g g. The copies of the trivial representation will form the fixed field of the group; so if the fixed field is K then we know we are in K.
Important special case: if the group is abelian then the irreducible characters are homomorphisms (because the irreducible representations are one dimensional and so the trace is just literally basically the same as the matrix), and so h p α = χ_τ(h)^{-1} p α. So for example if the galois group is cyclic of order n, we can take τ as the representation that scales by ζ where ζ is some primitive nth root of unity that we assume the base field has; then this reads g^k pβ = ζ^k pβ for generator of the field extension β. This then means that if pβ ≠ 0 then it isn't fixed by any subgroup. Since getting 0 would mean it's zero on any element, we'd then have a linear dependenc of n-1 basis vectors, which is impossible. Now \prod_k g^k pβ is fixed and so is in K, and specifically must equal (\prod_{k=0}^{n-1} ζ^k) (pβ)^n; which is just p β because the roots of unity multiply to 1 (since you have 1 + n-1 = n, 2 + n -2 = n, etc. around the circle). So the point is that (pβ)^n must be equal to some element in K, yet the earlier powers can't have been because then we'd have a smaller degree field extension and thus smaller degree galois subgroup; thus we have a radical extension of degree n, with pβ generating the field E over K.
This is basically Hilbert's Theorem 90, and I've seen it before. The interesting bit is the intuition that now will hopefully let me remember it easily: first we project to a good representation that isn't fixed by any subgroup (and thus isn't any smaller field), then we use the fact that we have field automorphisms to project to the trivial representation as a product.
I'm sure people are aware of that intuition, but unfortunately I hadn't seen anyone else actually point out that we have a representation on the abelian group aka Z-module of units of the field.
3: Idle question, from the representation theory stuff and the way I did Sperner's lemma: given a finite group G, what's the product of all the elements?
So far: split the group into the subgroups generated by some gs. Choose an exhaustive set without repeats. Now, odd order elements will end up contributing nothing from their subgroup, for g^k will pair with g^{n-k} to make the identity. For odd order elements, we'll have an extra g.
Example: the cyclic group of order n gives the identity for odd n, and n/2 for even n.
Direct products will also give products of values. Now, I wonder what having a quotient would tell us.
April 17-19
On the 16th, I stayed up all night editing audio - no regrets about that. However this meant I woke up very late on the 17th, to the point that I felt pretty bad from eating so late and from having slept too long - I wish I had forced myself out of bed after, say, 4 hoursish, even if I'd then go and sleep for another 4 later. On the 18th I had a lot of fun hanging out with friends quite late, and on the 19th I was even productive after sleeping for 4 hours, till I then went back to sleep for another 4.
Overall, my mood is solidly above baseline. It seems like my hypothesis that being productive about exciting stuff is the best form of rest for me checks out!
0: This I discovered while editing audio
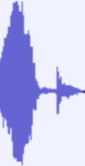
This is a plot of some audio of me saying a word. The word I am saying is "like".
Notice the fall in intensity in the middle?
I'm pretty sure that what this is is the airstream stopping on the plosive /k/ sound due to my tongue pressing against my soft palate (the soft part of your mouth's roof). That is, I think I have just seen the well known audio signature of plosives, at least going by my memories of this video on the subject.
This theory seems to hold up for other plosive sounds. For example:
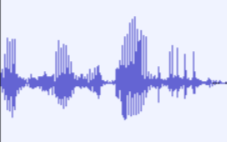
is audio of me saying (brackets is what I said outside of the pictured region of audio) "[didn't have any idea] what the hell was going on". Right in the middle of the image is where I'm saying the tail /s/ bit of the "was" and starting to say the /g/ at the start of "going"
1: Lawvere's fixed point theorem is the category theoretic version of the diagonalization arguments from the diagonalization exercises post. If you did the first three exercises of the post, then you don't actually need to read a proof of the theorem - just click for the definitions of things like a category, terminal object, products, cartesian closed categories (skip the explanation of the third condition and look at the evaluation map - don't worry about what "counit of the exponential adjunction" is supposed to mean), and weak point-surjectivity. Then just translate the solution of exercise 3. There's only, like, one not-completely-obvious step, all the difficulty is just understanding the definitions.
2: Someone on the internet mentioned wheel theory in a conversation. The idea is to make an algebra that allows not just for division by 0 but also for 0/0.
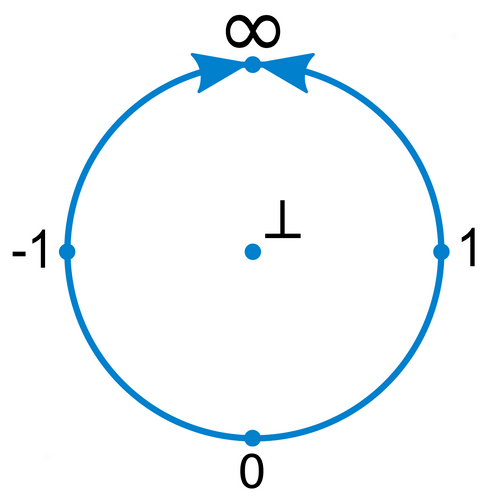
This image is about where my understanding ends. Like, clearly the thing in the middle (called 'bottom') is what'll be used for the undefined elements. And also you can wheelify any commutative ring, making what's called the "wheel of fractions" seemingly in a fairly straightforward way. If you do it to a field you get a projective line with an extra
The guy on the internet said that wheel theory is acknowledged to have, like, no use. So I'm not really that interested.
April 9-10th 2026
I spent much of the 9th doing things like cleaning my room and doing a bit of reorganizing of my backpack. Well worth the time, but it did take a while!
(some stuff is very sparse, sorry)
0: Imagine you are standing still, minding your own business, when a supersonic plane passes by you in a straight line. You weren't looking at the plane, so you have only your ears to guide you.
Now, a weird thing happens (I think). Can you figure out what it is?
If it's going fast enough relative to the speed of sound, and if you are close enough, then it looks like you should first hear the sound of the plane from near when it was closest to you. You'll then hear the sounds from when it was behind you, and also when it was ahead of you. So if your eyes are closed, it might sound like a plane just popped into existence, then split into two parts that flew away!
Some algebra: Suppose the closest approach happens at distance d from you, and you start a stopwatch when you hear the sound from the closest approach. Then it was at closest approach at time t=-d/s. Look at an angle theta to the back of its trajectory (draw a right triangle). The plane would've been d tan(theta) away from where it was at closest approach, and a distance of d/cos(theta) from you.
It was that far behind you at t = -d/s -d tan(theta)/v where v is the velocity of the plane. Let's say that v=ks (where k is the "mach" number), so that this is t = -d/s - d tan(theta)/ks. The sound takes d/(s cos(theta)) time to travel to you, where s is the speed of sound. Thus you'll hear that sound at t_theta = d/s(1/cos(theta) - tan(theta)/k - 1)
We can set s = 1 and then say that d is the time sound takes to get from the closest approach point to you.
First question: when is this positive (that is, at a later time than the sound from 0 degrees)?
Wolfram alpha tells us this only has solutions when k > 1 (duh, otherwise you'd hear weird shit all the time). If we define theta_k(t) via (1/cos(theta) - tan(theta)/k - 1 = t, 0<theta<pi/2). You can plot this on Desmos. Notice how even with k > 1, we see that some angles positive angles are heard earlier. As k gets bigger, the range of 'earlier' angles gets smaller. The time difference between the 'earlier' angles and the time of hearing closest approach depends on d and k (going up for high d, going down for higher k).
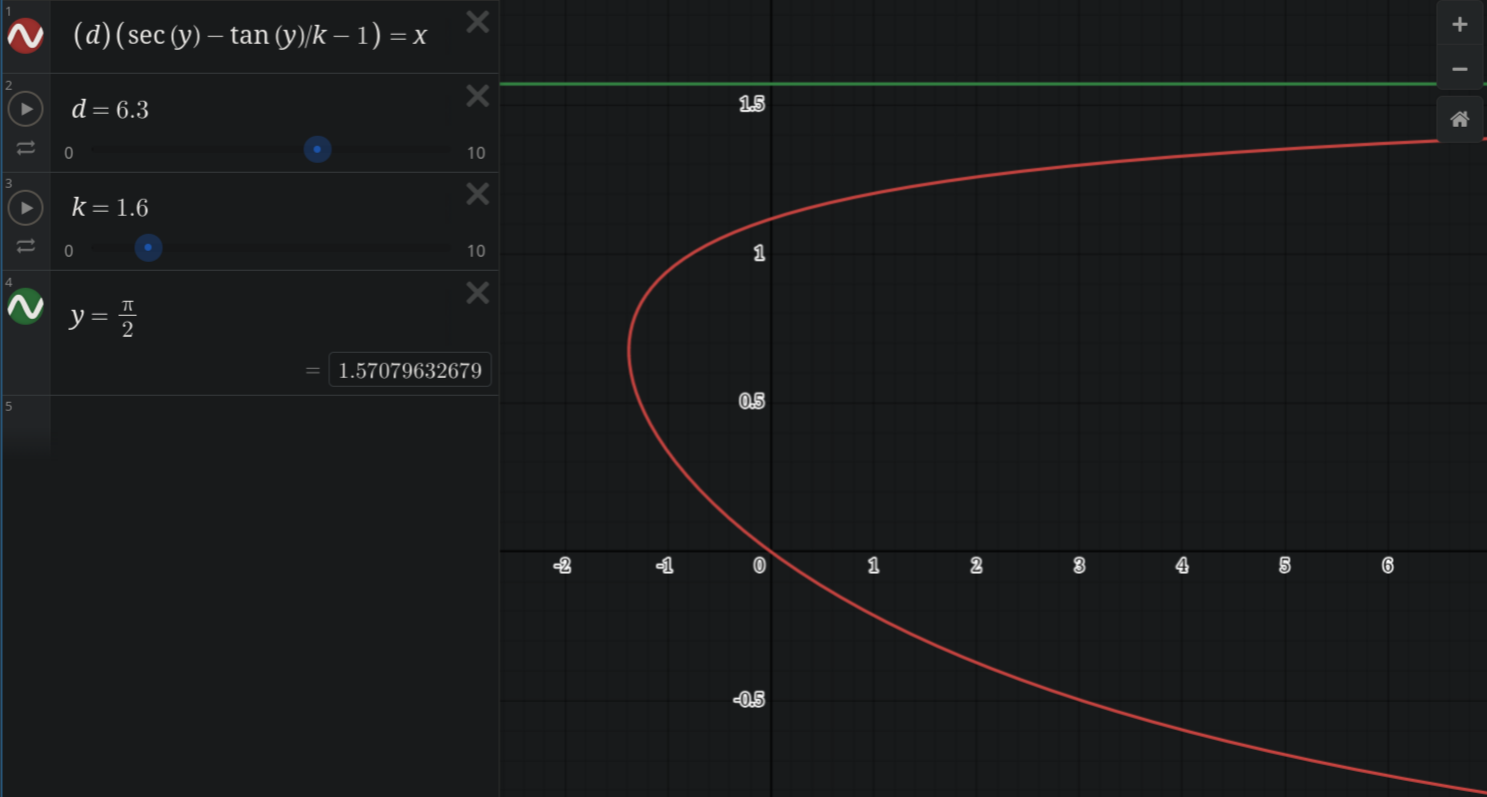
This came up when my friend mentioned an analogous scenario with a current in a wire that starts flowing instantly, as it was mentioned in their EM class. I quickly realized that it's nicer to think of it as a supersonic plane, as it doesn't actually have to go instantly.
You should also be able to do this with charged particles moving superluminally in, say, water. This predicts that if you somehow managed to get a straight line of cherenkov radiating particles, then a fast enough camera would see the blue glow expand outwards
1: Cochlea facts:
The cochlea is a hollow of the temporal bone, not a separate thing that's attached to the rest somehow
The cochlea has the organ of corti, which is what senses sound.
External stimulation of sense of acceleration by stimulating the sacks or semicircular canals in cochlea
utricle -> eyes, saccule -> motor movements (both linear acceleration detectors)
2: The stapedius muscle stabilizing the stapes in the ear reflexively tenses after large noise or when speaking (and apparently for a couple percent of people, anticipation of speaking is enough). Idea is that they prevent masking of high frequency by low frequency sounds. This comes up when calculating hearing damage predictions. Idk why the obvious hypothesis of "it's to protect your ears" isn't it.
3: tympanic muscle can be consciously tensed in many people and it's supposed to make a low sound like thunder or wind? Supposedly you need to like, yawn without actually yawning - but all I can manage is opening and closing my eustachian tubes.
4: Working memory has been in part localized to the [uu] PFC (maintenance, processing)? With TMS intereference experiments? Likewise lesions to the [uuu] cause problems with risk and decisions?
5: Combination tones are due to the missing fundamental phenomena? Missing fundamental is where you perceive the fundamental frequency even when its missing, e.g. if you hear the frequencies 2f, 3f, 4f, ... most will perceive it as if f were there (because almost all frequency multiples would match). In general it's the gcd.
6: Stared at the names of the parts of the basal ganglia for a bit. Perhaps I'll remember them better. They have a tendency to get jumbled up in my head.
7: Orientable double covers are a thing? How did I not know about this? Came up (though not sure if actually related) when thinking about what the topology of the image of the immersion of a klein bottle in 3D space is (I think it's a genus 2 surface).

8: Octopi are molluscs??
9: Did almost all of the problems in diagonalization fixed point exercises. Very good set of exercises! I feel like I understand how it's all really doing the same thing, now. I get some extra bonuses out of it too, like understanding where the formula for the Y-combinator comes from, or for the first time noticing how Cantor's argument is quite similar to Russell's paradox. What's left for me: writing the quines (and ones that apply function to the input) (which should also give me Kleene's recursion theorem/Roger's theorem), figuring out the proof of Rice's theorem without reading it, and the diagonal lemma in logic. Next, I wonder if dovetailing can be written like this too, and lastly I'd like to look at Lawvere's fixed point theorem which is supposed to be the categorical generalization.
May 4-5th
0: Most of think time was spent trying to interpret the Jeffrey-Bolker rotation. You can read what I did here.
Basically, it changes the risk preference of your utilities in exchange for changing the probabilities in the opposite way - the risk averse measure is, I think, literally a special case, though there were a couple details I'd want to check before saying that definitively, and I know very little about risk averse measures. For example, under the risk averse measure bad outcomes are seen as "more likely" to compensate for seeing them as only linearly bad.
The description length/compression interpretation isn't much better than that. However this incidentally let me realize that an ideal gas is like an agent with log utility, if you interpret "volume" as like "money" (or whatever resource you are log utility in) and "pressure" as "marginal utility".
1: The infra-bayes contributions have "missing" probability mass, corresponding to a contradiction. When playing Newcomb's problem, the state includes what policy you run. But you cannot take an action that is logically inconsistent with your policy - that is, if I one-box, then I can't be a two-boxer! One can't fully consider the hypotheses that contain your own policy, but you can do imprecise probability theory on them. It then reminds me of "decision theory is for making bad outcomes inconsistent".
2: Radon's theorem is neat, and so's the proof:
Suppose you have d+2 points in d dimensions. Then, you can split them into two sets whose convex hulls intersect.
Proof: Try to find some weights so that the weighted sum of the points is 0. This gives d linear constraints on the weights. Then add an equation saying the weights add to 0.
Split the points by the sign of their weight. Normalize the weights in a subset and take the average, and you'll get the normalized weighted average of points in the other, though with a sign flip. The sign flip makes it so both are a convex combination in the subset.
Application: The VC dimension of d-dimensional point clouds with respect to linear separators is d+1. This is because a hyperplane separating the vertices of two convex sets must separate their convex hulls (easy consequence of linearity and convexity), so you can't separate some binary classification of any d+2 set of points; while a simplex can have every subset separated.
3: This is a great explanation of Chu spaces. You could even show much of it to a child! Though, I still am not clear on what you'd want to use a Chu space for.
Random fraternity on my university campus has a polymarket flag. I guess they really are mainstream now!
Natural Latents <-> Symmetries?
At this point, I am convinced that in many practical cases, natural latents are related to symmetries somehow. Broad hopes (I am much more uncertain that the specifics listed here will work!):
1. Latents are constrained by the symmetries, or vice versa. Learn something about one, and you'll learn something about the other. Since humanity has spent a lot of time thinking about symmetries, this is probably best used to learn about latents. Subhope: Latents are invariant under the 'good' symmetries.
2. You can use symmetries to find latents somehow. Specifically, here's something I hope to apply: If you have a bunch of symmetries, a common trick is to average over all ways of transforming by them to get something that's invariant. e.g. if I have an n dimensional vector space, and my symmetries are all permutations of the axes, then the trick says I should look at 1/|n!| \sum_p p(v), which for any v just gets (average)*all_ones. And, well, averages are often latents.
3. You can look at the symmetries to figure out when you have a change in what your latents are. Specifically, something like spontaneous symmetry breaking might be able to tell you when an object has 'split', and hopefully even let you figure out what the new objects are.
So, if everything just works (lol) then we should be able to make a program that takes in simple physics of many particles that sometimes clumps together, then searches for symmetries and what can be transformed through time to identify the 'clumps' at any point in time, along with which clumps are 'the same clump evolved through time', which ones 'used to be the same clump', when clumps 'split', etc.
Current problem: I'm not sure what sort of symmetries we should even be looking at. The first thing that came to mind was that we should have symmetries of the probability distribution, that is, transformations on the variable space that doesn't change your probabilities (e.g. if P(X,Y) = P(Y,X), then we have such a symmetry by swapping the two variables).
I suspect that this is too general, and captures a whole bunch of "horrible" transformations. There are some 'obvious' assumptions you can add, but they feel way to ad hoc - I don't see any a priori reason why e.g. 'continuous' should matter, because we should have something that works for general systems (like discrete ones about coin flips). I'm not sure whether we should find some nice conditions (which should fundamentally be 'probability theoretic') that rule out all the bad stuff, or whether it's really about something else like the 'physics' (e.g. I'm thinking of 'evolving through time', but again I think we want something more general).
Specific example: Say I have four variables representing particle positions, which independently 'jitter' about their collective center of mass every time step (this also means the center of mass will jitter - think 'martingale'/'brownian motion'/'stock market', don't commit the gambler's fallacy). At some random time, the particles will "split" into two parts, each containing a random half of the 4 - and each part will jitter about their 2-particle-object's center of mass.
Say that I have a toy that works like this in my office, that is reset every so often. Somehow I should be able to figure out from the observed probabilities of what happens that a trajectory through time starts with one "clump" formed of 4 particle, that will then randomly split into two smaller "clumps", and for any specific possibility I should be able to tell you what the clumps are and when the split happened.
I think you may be able to say that if you look at the whole trajectory, you have a latent of (initial_clump_location, split_time, initial_split_angle, initial_split_speed, split_composition), while for smaller subtrajectories that only look before or after the split (but not both), you can reduce to only some of those variables; and then you can notice that time transformation is a symmetry that gives you latents right up until the split, or from after the split to any further time.
Wow, okay, just came across this comment linking this paper. I haven't read it yet, but the quoted bit says
the projection on orbits of a symmetry group’s action can be seen as an information-preserving compression, as it preserves the information about anything invariant under the group action.
Which is, like quite literally what I was trying to do.
I thus plan to think a little more (in case there's something that would be 'polluted'/'spoiled') on my own, and then immediately read that paper.
Adding to reading list: clearly I need to read Jaynes's writing on determining priors from symmetries.
I initially dismissed this, because I'm not looking for a prior here. But consider the statistical mechanics case: an ideal gas's distribution is given by the max entropy distribution subject to the constraint that average energy is some fixed value. This is basically the sort of thing Jaynes looks at. What I want to do is essentially go backwards - we start with a probability distribution, and need to figure out the energy, and it shouldn't require having literally max entropy.
The stuff he did, to my understanding, is to show that if we require that the distribution is invariant under some symmetry group, then we can deduce the probability distribution in many cases. This seems to include doing things like deducing a distribution over a parameter, which should take the role of a latent?
I still find it fairly likely that it ends up not doing what's needed, but is definitely something to look at.
Currently, I realize there's a simple question that surely has standard answers: what's the symmetries of the Boltzmann distribution? From there, maybe we can get that if know that P(X|L) has some symmetries, then we can find P(X|L)... and hopefully maybe also P(L). It's still too circular, though. But regardless - first, find the symmetries in that case.
Concrete subproblem: say I have N variables and I know that the probability distribution is permutation symmetric. I hope to be able to say that the average is an approximate latent. (for two same-biased coins, the average is a poor estimate; but we expect this to be fine for many coins).
There's manifold markets for the LW review; presumably making them for curated status would not be worth it given how fast you'd need to be to be useful and how your net needs to be wider (maybe? alternatively "posts about x karma threshold in last 1-5 days not curated" seems pretty small if you set the threshold to what seems like my minds using in my heuristic).
But for example: it doesn't seem hard to tell in advance. e.g. i'd bet mana that gene smith's practical guide to superbabies gets curated by the end of the week. I wish I could take a curate bot's 'free' mana.
(This also means I don't expect I'd learn much from the market (at least compared to most markets where I have nothing to add), but it might help the mods? I don't know what their post/day reading rate is - and it might be a fluctuating thing that could sometimes use a kick to go read a high probability curated post).