I'd like to write up a more in depth reply to this post eventually, but I have a few thoughts right off the bat.
- When I first read your opening claim that CAH is weaker and more likely to be true, I found myself wondering what you thought the difference was. Then, when you explained how you see the difference, I wasn't satisfied - you didn't explain as clearly as I would like how abstractions which are features of the world at distance come apart from abstractions which are convergently used by a variety of similarly pressured learners.
- One load bearing assumption imo is that the relevant pressures which different learners share are ~ universal - namely, pressures to make good predictions, and pressures to use resources (time and space) efficiently. If we start requiring that agents have to share more pressures than these in order to converge on equivalent abstractions we have lost the kind of strength that I care about.
- I currently guess that "good" as humans know it is not a natural abstraction, or an abstraction which different kinds of agents will robustly converge on. Of course this is a very important question indeed and it would be wonderful if it is a natural abstraction when you are trying to predict your observations of humans! And it's totally possible that is the case.
- Oh and last thing - agents with different sensory equipment should still converge on a lot of the same abstractions! I think you were just meaning that they might have some idiosyncratic abstractions in the mix as well, which I grant.
btw here is a cool example of some empirical evidence for convergent abstractions in the some of the contexts we care about: https://www.nature.com/articles/nn.4244
Yeah, nice.
I've thought for a while that natural abstractions generally make sense but only when specifying a certain reference frame. The possibility of redundant information leading to such a thing is still plausible but it feels like a coupled claim that doesn't need to be there.
If you raise an AI in a specific grid world like chess then it is likely that it will share a relatively large space of convergent representations. If you compare that to learning about an environment where you have lots of different ways that you can compose the structure of the world like age of empires then it would seem that the abstraction learning process is a lot more path dependent.
I don't know which world we're in, and I'm worried about people not having the conceptual precision to distinguish.
Evolutionary Moral Psychology has studied where human moral instincts come from. It strongly suggests they're evolutionary adaptations to being an intelligent social primate that lives and cooperates in large mostly-non-kin groups. That suggests that ideas like "good" are convergent abstractions, given that context: they might not be convergently shared by aliens with a very different social structure, like say sapient eusocial insects, but they are convergent across different human cultures.
Moral instincts are independent of moral concepts. Instinctually, humans are neither completely egoistic nor completely altruistic, but we have the concepts of egoism and altruism. Instincts determine what you are motivated to do, while concepts determine how you categorize the world.
If our abstraction of good is contingent on specifics of the social primate developmental context, should we expect the abstraction of good in LLMs to be substantially different? If so, how could we find it out before handing over our fate to them? Is this the only abstraction where divergence would be a problem?
These ideas appear in existing frameworks. See ecological rationality, resource-rationality, Marr. etc. They assume that cognitive processes are adapted to solve recurrent problems in the environment. Marr in particular claims that representations (abstractions) will mirror the problem being solved. Resource rationality builds on Marr and would agree with the prediction of efficient representations, I.e. compression.
I have converged (ha!) to similar views recently. I think it is worth trying to make this a lot more precise actually. Let me take a simplified version of a standard ML training set up. So we have some dataset D that samples a subset of all possible inputs A with binary labels in {0,1} and a neural network architecture that defines for you a parameter space and an associated function space F: A to {0,1}. Points of this function space correspond to a "labelling function" on D, and in particular there is a subspace S of F that is the set of "correct functions", i.e., functions that match on the training set. In general, our optimization algorithms tend to find a point in S always, i.e., they minimize loss on the training set.
Now there is also a test set that is a even smaller subspace T of S. For training to have worked, or to say that the trained net generalizes correctly, what we really mean is that the optimization algorithm finds not just a point in S, but a point in T. So we see that "correct training" is naturally a function that depends on these two nested subspaces (T \subset S). And the power of neural networks is somehow really that they find a much smaller subspace consistently than what training would require (each test data point cuts down the size of the space by around a factor of 2).
Does this help us make more precise your convergent abstraction hypothesis? I think so. I think the key point is that data sets are naturally generated by learners (often humans). So if we have a trained net or a human who can assign labels to data points, we can generate the training data set D by prompting the neural network, and similarly for the test data set.
Then when we train a different neural network on the outputs of the first, for learning to converge behaviorally is to say that they both identify the smaller space T inside S as the "important" one.
I am not sure how legible that was, I am finding this comment box hard to express mathematical ideas in...
===
Anyway, the upshot is that I think this lets us directly compare two learners. If learner A is trained on the outputs of layer B, do they generalize in similar ways? Do they find the right subsets of the function space as the effective target space?
This line of thinking seems very plausible and important to me. Can you share a bit about how you arrived at it and can you recommend related material? Also, do you have ideas about how it could be empirically tested and refined?
This is interesting, but I found the difference between natural and convergent abstractions a bit unclear. One thing that sets apart the natural abstraction hypothesis is that it seems to assume that for the "clusters in thingspace" there is an objectively natural choice of thingspace, one that is better suited for predictive inferences and generalization.
This is necessary for the existence of natural abstractions (objective clusterhood) because things that form a cluster in one thingspace need not form a cluster in another thingspace, i.e. in another set of dimensions according to which things are judged to be more or less "similar" or "close".
For example, colors that form a tight cluster in the RGB space often don't form a tight cluster in the HSL color space. So clusterhood is relative to some space, and natural clusterhood requires a natural space.
In contrast, the convergent abstraction hypothesis is compatible with there not being a natural thingspace. Similar clusterings between different intelligences could merely be caused by the thingspaces being similar for contingent reasons.
it seems to assume that for the "clusters in thingspace" there is an objectively natural choice of thingspace
usually natural abstractions research uses information theory to avoid privileging a certain basis. So we actually don't have the problem of choosing a thingspace and looking for clusters geometrically!
It seems you are claiming that information theory implies there is an objective measure of clusterhood with privileged predictive/generalization properties. Which is equivalent to there being an objectively privileged thingspace.
I don't think this has been established, otherwise the natural abstraction hypothesis would already have been proven.
It seems you are claiming that information theory implies there is an objective measure of clusterhood
Not exactly. Rather, I am saying that clusterhood is not the right way to think about these things at all if we want to be free of an arbitrary choice of basis. Rather, we can study the information theoretic properties of the complete partition lattice over an input space and its corresponding probability distribution.
It seems that without clusters we don't have concepts, and without concepts we don't have abstractions, and without abstractions we don't have natural abstractions. So getting rid of clusterhood looks like throwing out the baby with the bathwater.
without clusters we don't have concepts
Nope! Here's an example:
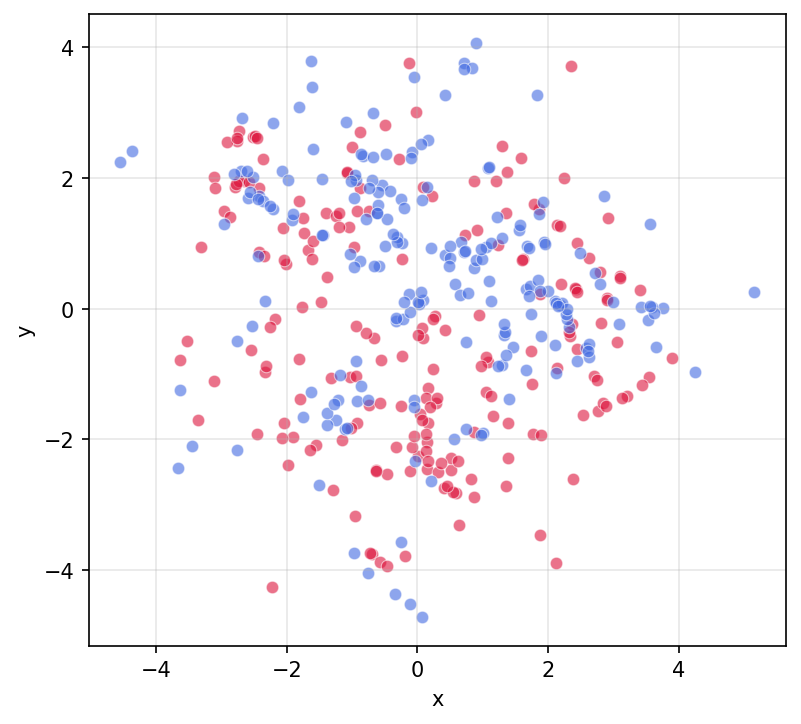
These dots were sampled from a 2-component Gaussian mixture and then put through a smooth invertible warp. There aren't any clusters, but the concept is still present and recoverable from the data (altho too hard for our visual cortex to recover in this particular case).
The shortest rule to describe this scatter is that each dot is an independent draw from a mixture of two modes. You have to specify where the two modes are, and you can guess decently well which mode each dot is from. Thru this you've rediscovered color without needing clustering.
It looks like x and y are the dimensions of your thingspace here. If you had a different thingspace, would you still be able to recover the same concept?
Yup! This is a very weird space to call a 'thingspace' but most transformations of it (anything that's at least approximately injective, for example) will preserve the same concept.
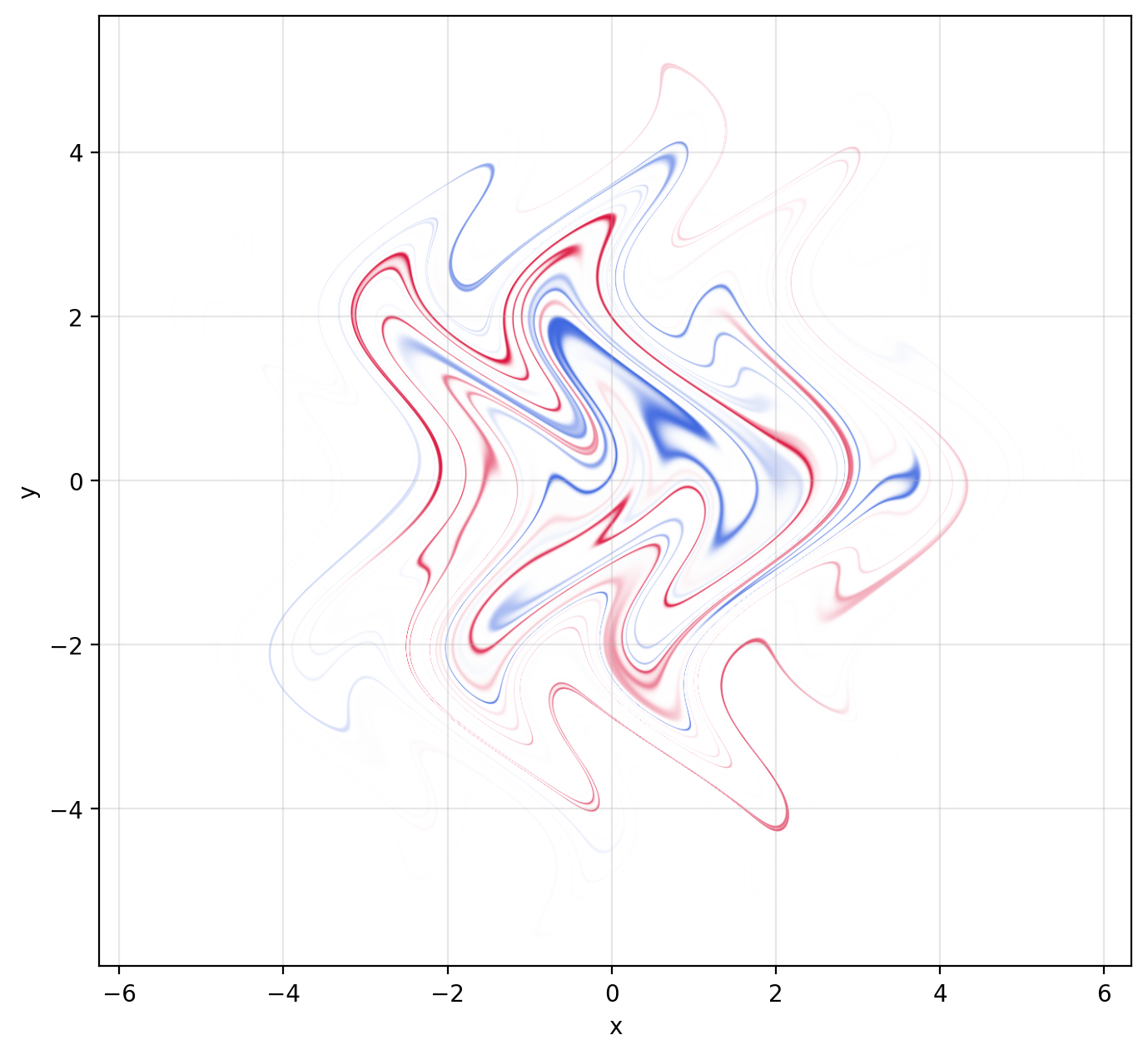
Here's what that same distribution I used above looks like if you plot the closed-form pushforward density analytically. In this picture it's easier for the visual cortex to pick up on the patterns (although it would still be nontrivial for a human to figure out what should be colored red and what should be colored blue if you erased the colors).
It is a less ambitious alternative to 'natural abstractions hypotheses' and, in my view, more likely to be true.
I think that "less ambitious" deserves at least as much qualification as "more likely" (which is probably about none).
Tl;dr
Convergent abstraction hypothesis posits abstractions are often convergent in the sense of convergent evolution: different cognitive systems converge on the same abstraction, when facing similar selection pressures and learning in similar environments. It is a less ambitious alternative to 'natural abstractions hypotheses' and, in my view, more likely to be true.
Convergence may be real, useful, and empirically robust, while still being contingent and fragile under changes in architecture, training pressure, or optimization regime.
Convergent evolution
To recapitulate some basics: notice that sharks, ichthyosaurs and dolphins look remarkably similar, despite their ancestors being wildly different.
This is a case of convergent evolution: the process by which organisms with different origins develop similar features. Both sharks and dolphins needed speed and energy efficiency when moving in an environment governed by the laws of hydrodynamics, and so they converged on a pretty similar body shape.
A complementary concept from biology is contingency - convergent features are themselves often contingent on some other feature. For example, the shark morphology depends on there being a central vertebral column (or spine), which only evolved once and is the defining feature of vertebrates. There are many other aquatic predators, such as squid and octopuses, which are not vertebrates and thus have evolved a completely different morphology.
Convergent evolution applied to abstractions
“Abstractions” are somewhat different from morphological features, but there is an analogy between evolution and learning in systems like SGD acting on neural networks, and most of the conceptual framework can be directly applied.
Based on the analogy, we expect convergence when the learners face a similar data environment, similar selection pressures, try to do similar things, and the solution space is somewhat limited.
Selection pressures
In case of abstractions, some of the strongest selection pressures are highly universal:
Consequently, we can learn a lot about what makes abstractions good just from information theory. A strong selection pressure for abstractions is basically "what is a good compression of data” and similar.
Compression buys you a lot
Concepts are clusters in thingspace. But clustering is compression: instead of remembering details about each point in the cluster, you can remember just the pointer to the cluster, and the differences.
Objects are compressions. Instead of repeating the same description over and over, you remember just a few degrees of freedom. It is a very impressive compression: Consider an atomically precise representation of an apple: in some physics-grounded representation it has ~10^25 degrees of freedom, held by a comparably large number of constraints. But the world has approximate symmetries – translation invariance, rotation invariance, and so on. So one useful compression is to treat the apple as an object. A handful of variables like position and momentum often suffice. The compression ratio is enormous, and I expect basic abstractions like bodies in space to be highly convergent across world-modeling processes, including animal brains, human brains, video codecs, visual ML models.
Many more mathematical abstractions are effective low-length compression algorithms. Arithmetic is a reusable compression. Once you learn that 3 + 2 = 5, you do not need separate facts for apples, oranges, sheep, coins, and photons. The same structure transfers across domains.
PCA is compression, transforms to frequency domain are often useful for compression, quantization is compression, singular value decomposition is compression, random low dimensional projections are compression.
Once you look for it, you see the fundamental selection pressure to save bits everywhere. [1]
Shared environments
The second ingredient for convergence is a shared data environment. We can distinguish between different levels:
- Physics: All cognitive systems embedded in our universe encounter the same fundamental regularities, like objects that persist over time, causal relationships, 4d spatial structure, Noether's theorem induced conservation laws.
- Similar scale: Human world models are “centered” around scales like 1m, 1s, 1kg.
- Sensors: vision-heavy agents learn different abstractions from sonar-heavy or smell-heavy agents.
- Human/linguistic environment: For systems learning from human-generated data, there's an additional layer of shared environment.
What this predicts
Imagine aliens landed on Earth. I would expect aliens embedded in the same physics to discover arithmetic, geometry, approximate objects, causal structure, and frame transformations. If they live at similar scales and act in similar environments, I would also expect them to use categories resembling solid objects, liquids, containers, paths, agents, tools, obstacles, boundaries, markets. If they study Earth or train on human data, I would expect more convergence: apples, chairs, money, smiles, promises.
Now: alien minds actually have landed. And yes, even if you start with raw photographs and fairly universal neural network architecture, you get apples.
What this does not predict, or contingency in abstraction space
The dual to convergence is contingency - or, what are abstractions contingent on?
At one extreme, you might imagine abstractions are contingent only on physics. I don't think that's the case. The interesting work is mapping the interplay of convergence and contingency in detail.
Case study of architectural contingency: convergent vision abstractions
One of the best examples of how I understand both convergence and contingency in ML comes from a paper on adversarial robustness in image classification by Fort at al.
Standard image classifiers learn abstractions that largely agree with human vision: show them an apple, they say "apple", if trained on that, or learn a concept of apple, if trained in a self-supervised way.
But the agreement turns out to be superficial. Put the represenational alignment under a very small amount of adversarial optimization pressure, and you get adversarial inputs: pictures where the neural net confidently sees a "toaster" where we see an apple. What we see as barely perceptible noise, the network sees as the essence of toaster-likeness.
What this illustrates is that the classifier learned a somewhat different abstraction than humans; the abstractions are aligned on natural images but diverge fast under pressure. The pressure is usually conceived as adversarial, but if you optimize for an image to make it maximally apple-like, you also get divergence.
Fort et deal with adversarial attacks by training classifiers on multi-resolution inputs, stacking downsampled versions of the same image at different scales, and requiring the classification stays consistent across scales. Empirically, the resulting abstractions align dramatically better with human ones. The paper result is mostly framed as massively increased adversarial robustness, but what I find more interesting is that the remaining “adversarial attacks” against these multi-resolution models produce easily human interpretable changes. To turn a "cloud" into a "mountain," the attack adds a dark contour and repurposes the cloud's white pixels as snow. To turn an "elephant" into a "dinosaur," it recolors the elephant green and adds spikes. Humans recognize the changes as making the image more mountain-like or dinosaur-like.
In the convergency/contingency language, it turns out the human-like visual abstractions of mountains and elephants are convergent, given the data being images on the internet, but contingent on the architecture having some sort of resolution-free/scale-invariance constraint.
Architectural contingency is one kind. There's also developmental – higher-level abstractions are likely contingent on lower-level ones, analogous to shark morphology depending on the vertebral column. I won't develop this here
What's the difference between convergent abstractions and natural abstractions
Natural-abstraction work often bundles two ideas: first, that the world supports low-dimensional summaries useful across many contexts; second, that many cognitive systems converge on those summaries. I want to separate these. CAH accepts the convergence phenomenon, but treats it as a fact about learning processes under shared pressures, not automatically as evidence that the abstraction is mostly situated in the structure of the world (abstraction correspond to low-dimensional summaries of information relevant far away from a subsystem)
The canonical motivating example for natural abstractions is gas, and state variables like temperature as the abstractions. The ambition of the research program is to have a principled way to identify them. The natural abstraction hypothesis has roughly physics aesthetics.
In contrast, convergent abstraction makes mostly a process claim: given similar pressures and environments, similar abstractions emerge. The ambition is to understand basins of convergence, contingencies, and the ways how the structures in the world interact with the learners. The aesthetics is way closer to biology, and assumes messiness. It is less ambitious.
Most empirical evidence for natural abstractions (or its academic relative, the platonic representation hypothesis) is well explained by convergent abstraction: convergence is the weaker claim. But the reverse isn't true – evidence that similar systems converge doesn't tell you the abstractions are features of the world at distance rather than features of similarly-pressured learners.
From the CAH perspective, natural-latent results identify one important source of convergence: cases where the world itself supplies stable, low-dimensional mediators. But they do not settle the broader question of which abstractions particular learners will use, or how robustly those abstractions survive changes in architecture, objective, or optimization pressure.
Why do I care
In my view, the difference between natural and convergent abstractions is a deep crux of multiple pressing questions of AI strategy. I'll cover the possibility and implications of convergent moral abstractions in a future post, but to give one example:
Models like Claude Opus 3 lead some to believe that the training process is able to find a fairly general and possibly natural abstraction of good. If this is the case, and the abstraction is truly natural, it is good news for alignment, chances that “hand over” to AIs leads to good outcomes are better, and there may be also a risk from not handing over, or human alignment efforts re-aligning the AIs away from goodness toward parochial goals.
In contrast, if the abstractions AIs like Opus learn are only convergent in some narrow basin, the strategic situation is much more fragile. Similarly to the case of apples, the human and AI abstractions of goodness may overlap and even agree in a very large number of directions, and at the same time the representational alignment could be only partial and fragile. In this picture, while Opus 3 may be genuinely good, if its abstractions become load-bearing, the setup will be brittle. Adversarial optimization, or even just strong optimization, could exploit the differences. Directionally, this makes prospects of more RL in post-training scary, the success of iterated amplification / CEV of Opus less likely, and overall pushes against handovers.
If the moral abstractions Opus learned are natural in a strong sense, we're in the world where some part of alignment might basically work – pointing a smart enough learner at human data converges to abstractions close enough to goodness. If they're convergent, we're in the world where some part of alignment might basically work, but also there are many words where it looks like it works, but ultimately it doesn't. When the abstractions become load-bearing and optimization strong, they diverge.
I don't know which world we're in, and I'm worried about people not having the conceptual precision to distinguish.