This is a special post for quick takes by Veedrac. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
I saw a recentish post challenging people to state a clear AI xrisk argument and was surprised at how poorly formed the arguments in the comments were despite the issues getting called out. So, if you're like apparently most of LessWrong, here's what I consider the primary reduced argument, copied with slight edits from an HN post I made a couple years ago:
It is plausible that future systems achieve superhuman capability; capable systems necessarily have instrumental goals; instrumental goals tend to converge; human preferences are unlikely to be preserved when other goals are heavily selected for unless intentionally preserved; we don't know how to make AI systems encode any complex preference robustly.
I should note that having a direct argument doesn't mean other arguments like statistical precedent, analogy to evolution, or even intuition aren't useful. It is however good mental hygiene to track when you have short reasoning chains that don't rely on getting analogies right, since analogies are hard[1].
- ^
Complete sidenote but I find this link fascinating. I wrote ‘analogies are hard’ thinking there there ought to be a Sequences post for that, not that there is. The post I found is somehow all the more convincing for the point I was making with how Yudkowsky messes up the discussion of neural networks. Were I the kind of person to write LessWrong posts rather than just imagine what they might be if I did, a better Analogies are hard would be one of the first.
Using technical terms that need to be looked up is not that clear an argument for most people. Here's my preferred form for general distribution:
We are probably going to make AI entities smarter than us. If they want something different than we do, they will outsmart us somehow. They will get their way, so we won't get ours.
This could be them wiping us out like we have done accidentally or deliberately to so many cultures and species; or it could be them just outcompeting us for every job and resource.
Nobody knows how to give AIs goals that match ours perfectly enough that we won't be in competition. A lot of people who've studied this think it's probably quite tricky.
There's a bunch of different ways to be skeptical that doesn't cover, but neither does your more technical formulation. For instance, some optimists assume we just won't make AI with goals; it will remain a tool. Then you need to explain why we'll give it goals so it can do stuff for us, but it would be easy for it to interpret those goals differently than we meant them. This is a complex discussion, so the only short form is "experts disagree, so it seems pretty dangerous to just push ahead without knowing".
This seems rhetorically better, but I think it is implicitly relying on instrumental goals and it's hiding that under intuitions about smartness and human competition. This will work for people who have good intuitions about that stuff, but won't work for people who don't see the necessity of goals and instrumental goals. I like Veedrac's better in terms of exposing the underlying reasoning.
I think it's really important to avoid making arguments that are too strong and fuzzy, like yours. Imagine a person reads your argument and now beliefs that intuitively smart AI entities will be dangerous, via outsmarting us etc. Then Claude 5 comes out and matches their intuition for smart AI entity, but (let's assume) still isn't great at goal-directedness. Then after Claude 5 hasn't done any damage for a while, they'll conclude that the reasoning leading to dangerousness must be wrong. Maybe they'll think that alignment actually turned out to be easy.
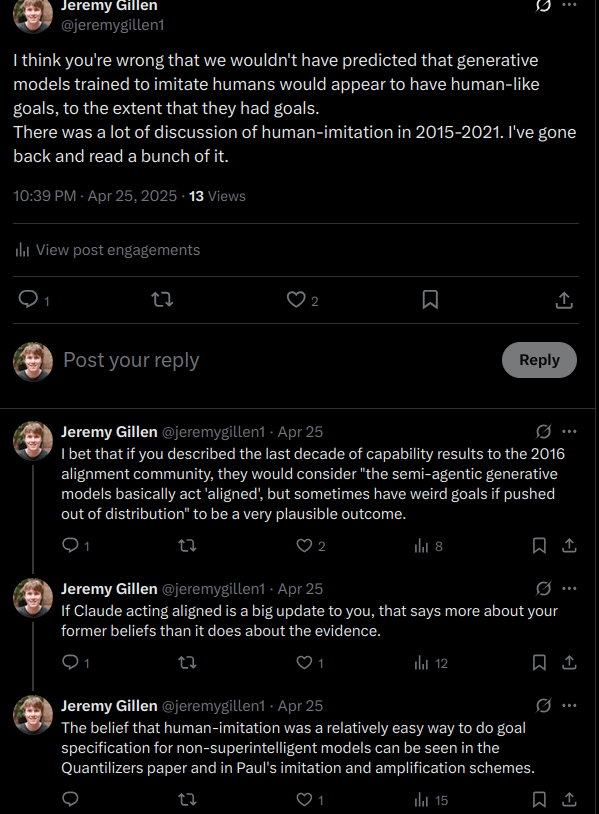
Something like this seems to have already happened to a bunch of people. E.g. I've heard someone at Deemind say "Doesn't constitutional AI solve alignment?". Kat's post here[1] seems to be basically the same error, in that Kat seems to have predicted more overt evilness from LLM agents and is surprised by the lack of that, and has thereby updated that maybe some part of alignment is actually easy. Possibly Turntrout is another example, although there's more subtly there. I think he's correct that, given his beliefs about where capabilities come from, the argument for deceptive alignment (an instrumental goal) doesn't go through.
In other words, your argument is too easily "falsified" by evidence that isn't directly relevant to the real reason for being worried about AI. More precision is necessary to avoid this, and I think Veedrac's summary mostly succeeds at that.
You make some good points.
I think the original formulation has the same problem, but it's a serious problem that needs to be addressed by any claim about AI danger.
I tried to address this by slipping in "AI entitities", which to me strongly implies agency. It's agency that creates instrumental goals, while intelligence is more arguably related to agency and through it to instrumental goals. I think this phrasing isn't adequate based on your response, and expecting even less attention to the implications of "entities" from a general audience.
That concern was why I included the caveat about addressing agency. Now I think that probably has to be worked into the main claim. I'm not sure how to do that; one approach is making an analogy to humans along the lines of "we're going to make AIs that are more like humans because we want AI that can do work for us... that includes following goals and solving problems along the way... "
This thread helped inspire me to write the brief post Anthropomorphizing AI might be good, actually. That's one strategy for evoking the intuition that AI will be highly goal-directed and agentic. I've tried a lot of different terms like "entities" and "minds" to evoke that intuition, but "human-like" might be the strongest even though it comes at a steep cost.
If we can clearly tie the argument for AGI x-risk to agency, I think it won't have the same problem, because I think we'll see instrumental convergence as soon as we deploy even semi-competent LLM agents. They'll do unexpected stuff for both rational and irrational reasons.
I think the original formulation having the same problem. It starts with the claim
It is plausible that future systems achieve superhuman capability; capable systems necessarily have instrumental goals [...]
One could say "well LLMs are already superhuman at some stuff and they don't seem to have instrumental goals". And that will become more compelling as LLMs keep getting better in narrow domains.
Kat Woods' tweet is an interesting case. I actually think her point is absolutely right as far as it goes, but it doesn't go quite as far as she seems to think. I'm even tempted to engage on Twitter, a thing I've been warned to never do on pain of endless stupid arguments if you can't ignore hecklers :) It's addressing a different point than instrumental goals, but it's also an important point. The specification problem is, I think, much improved by having LLMs as the base intelligence. But it's not solved, because there's not a clear "goal slot" in LLMs or LLM agents in which to insert that nice representation of what we want. I've written about these conflicting intuitions/conclusions in Cruxes of disagreement on alignment difficulty, largely by referencing the excellent Simplicia/Doomimir debates.
If we can clearly tie the argument for AGI x-risk to agency, I think it won't have the same problem
Yeah agreed, and it's really hard to get the implications right here without a long description. In my mind entities didn't trigger any association with agents, but I can see how it would for others.
This thread helped inspire me to write the brief post Anthropomorphizing AI might be good, actually.
I broadly agree that many people would be better off anthropomorphising future AI systems more. I sometimes push for this in arguments, because in my mind many people have massively overanchored on the particular properties of current LLMs and LLM agents. I'm less a fan of your part of that post that involves accelerating anything.
One could say "well LLMs are already superhuman at some stuff and they don't seem to have instrumental goals". And that will become more compelling as LLMs keep getting better in narrow domains.
Yeah, but the line "capable systems necessarily have instrumental goals" helps clarify what you mean by "capable systems". It must be some definition that (at least plausibly) implies instrumental goals.
Kat Woods' tweet is an interesting case. I actually think her point is absolutely right as far as it goes
Huh I suspect that the disagreement about that tweet might come from dumb terminology fuzziness. I'm not really sure what she means by "the specification problem" when we're in the context of generative models trained to imitate. It's a problem that makes sense in a different context. But the central disagreement is that she thinks current observations (of "alignment behaviour" in particular) are very surprising, which just seems wrong. My response was this:
Mostly agreed. When suggesting even differential acceleration I should remember to put a big WE SHOULD SHUT IT ALL DOWN just to make sure it's not taken out of context. And as I said there, I'm far from certain that even that differential acceleration would be useful.
I agree that Kat Woods is overestimating how optimistic we should be based on LLMs following directions well. I think re-litigating who said what when and what they'd predict is a big mistake since it is both beside the point and tends to strengthen tribal rivalries - which are arguably the largest source of human mistakes. There is an interesting, subtle issue there which I've written about in The (partial) fallacy of dumb superintelligence and Goals selected from learned knowledge: an alternative to RL alignment. There are potential ways to leverage LLM's relatively rich (but imperfect) understanding into AGI that follows someone's instructions. Creating a "goal slot" based on linguistic instructions is possible. But it's all pretty complex and uncertain.
I think Robert Miles does excellent introductory videos for newer people, and I linked him in the HN post. My goal here was different, though, which was to give a short, affirmative argument made of only directly defensible high probability claims.
I like your spin on it, too, more than those given in the linked thread, but it's still looser, and I think there's value giving an argument where it's harder to disagree with the conclusion without first disagreeing with a premise. Eg. ‘some optimists assume we just won't make AI with goals’ directly contradicts ‘capable systems necessarily have instrumental goals’, but I'm not sure it directly contradicts a premise you used.
I donno, the systems we have seem pretty capable, and if they have instrumental goals they seem quite weak... so tossing in that claim seems like just asking for trouble. I do think that very capable systems almost need to have goals, but I have trouble making that argument even to alignment people and rationalists.
That's just one example, but the fact that it goes awry immediately hints that the whole direction is a bad idea.
I think the argument for AI being quite-possibly dangerous is actually a lot stronger than the more abstract and technical argument usually used by rationalists. It doesn't require any strong claims at all. People don't need certainty to be quite alarmed, and for good reason.
Standard xrisk arguments generally don't extrapolate down to systems that don't solve tasks that require instrumental goals. I think it's reasonable to say common LLMs don't exhibit many instrumental goals, but they also can't solve for long-horizon goal-directed problem solving.
Prosaic risks like biorisk evals often go further and ask, if we assume the AI systems aren't themselves very capable at this task, can we still exhibit dangerous behaviors from them ‘in the loop’? These are legitimate and interesting questions but they are a different thing.
Reply to https://twitter.com/krishnanrohit/status/1794804152444580213, too long for twitter without a subscription so I threw it here, but do please treat it like a twitter comment.
rohit: Which part of [the traditional AI risk view] doesn't seem accounted for here? I admit AI safety is a 'big tent' but there's a reason they're congregated together.
You wrote in your list,
the LLMs might start even setting bad objectives, by errors of omission or commission. this is a consequence of their innards not being the same as people (either hallucinations or just not having world model or misunderstanding the world)
In the context of traditional AI risk views, this misses the argument. Roughly the concern is instead like so:
ASI is by definition very capable of doing things (aka. selecting for outcomes), in at least all the ways collections of humans can. It is both theoretically true and observably the case in reality that when things are selected for, a bunch of other things that aren't that are traded off, and that the stronger something is selected for, the more stuff ends up traded against, incidentally or not.
We should expect any ASI to have world-changing effects, and for those effects to trade off strongly against other things. There is a bunch of stuff we want that we don't want traded off (eg. being alive).
The first problem is that we don't know how to put any preferences into an AI such that it's robust to even trivial selection pressure, not in theory, not in practice on existing models, and certainly not in ways that would apply to arbitrary systems that indirectly contain ML models but aren't constrained by those models’ expressed preferences.
The second problem is that there are a bunch of instrumental goals (not eg. lying, but eg. continuing to have causal effect on the world) that are useful to almost all goals, and that are concrete examples of why an ASI would want to disempower humans. Aka. almost every thing that could plausibly be called an ASI will be effective at doing a thing, and the natural strategies for doing things involve not failing at them in easily-foreseeable ways.
Stuff like lying is not the key issue here. It often comes up because people say ‘why don’t we just ask the AI if it’s going to be bad’ and the answer is basically code for ‘you don’t seem to understand that we are talking about something that is trying to do a thing and is also good at it.’
Similarly for ‘we wouldn't even know why it chooses outcomes, or how it accomplishes them’ — these are problematic because they are yet another reason to rule out simple fixes, not because they are fundamental to the issue. Like, if you understand why a bridge falls down, you can make a targeted fix and solve that problem, and if you don’t know then probably it’s a lot harder. But you can know every line of code of Stockfish (pre-NNUE) and still not have a chance against it, because Stockfish is actively selecting for outcomes and it is better at selecting them than you.
“LLMs have already lied to us” from the traditional AI risk crowd is similarly not about LLM lying being intrinsically scary, it is a yell of “even here you have no idea what you are doing, even here you have these creations you cannot control, so how in the world do you expect any of this to work when the child is smarter than you and it’s actually trying to achieve something?”