
And All the Shoggoths Merely Players
23johnswentworth
26Zack_M_Davis
13johnswentworth
12Zack_M_Davis
15johnswentworth
23Zack_M_Davis
19johnswentworth
7quetzal_rainbow
1Signer
4quetzal_rainbow
4Signer
4quetzal_rainbow
1Signer
2quetzal_rainbow
8Zack_M_Davis
4johnswentworth
1quetzal_rainbow
6TurnTrout
16johnswentworth
14TurnTrout
12johnswentworth
6TurnTrout
4ryan_greenblatt
4nostalgebraist
13ryan_greenblatt
2TurnTrout
18tailcalled
3tailcalled
2Algon
15RobertM
15Vladimir_Nesov
8Wei Dai
5Vladimir_Nesov
13mattmacdermott
10Zack_M_Davis
8Martin Randall
8simon
8eggsyntax
6Seth Herd
6romeostevensit
6DaemonicSigil
4Seth Herd
3Review Bot
3Signer
2lenivchick
11abramdemski
1lenivchick
4abramdemski
1lenivchick
2ryan_greenblatt
2AnthonyC
2Seth Herd
2the gears to ascension
1TurnTrout
6habryka
1TurnTrout
-1quetzal_rainbow
1cibyr
3Seth Herd
[Setting: a suburban house. The interior of the house takes up most of the stage; on the audience's right, we see a wall in cross-section, and a front porch. Simplicia enters stage left and rings the doorbell.]
Doomimir: [opening the door] Well? What do you want?
Simplicia: I can't stop thinking about our last conversation. It was kind of all over the place. If you're willing, I'd like to continue, but focusing in narrower detail on a couple points I'm still confused about.
Doomimir: And why should I bother tutoring an Earthling in alignment theory? If you didn't get it from the empty string, and you didn't get it from our last discussion, why should I have any hope of you learning this time? And even if you did, what good would it do?
Simplicia: [serenely] If the world is ending either way, I think it's more dignified that I understand exactly why. [A beat.] Sorry, that doesn't explain what's in it for you. That's why I had to ask.
Doomimir: [grimly] As you say. If this world is ending either way.
[He motions for her to come in, and they sit down.]
Doomimir: What are you confused about? I mean, that you wanted to talk about.
Simplicia: You seemed really intent on a particular intuition pump against human-imitation-based alignment strategies, where you compared LLMs to an alien actress. I didn't find that compelling.
Doomimir: But you claim to understand that LLMs that emit plausibly human-written text aren't human. Thus, the AI is not the character it's playing. Similarly, being able to predict the conversation in a bar, doesn't make you drunk. What's there not to get, even for you?
Simplicia: Why doesn't the "predicting barroom conversation doesn't make you drunk" analogy falsely imply "predicting the answers to modular arithmetic problems doesn't mean you implement modular arithmetic"?
Doomimir: To predict the conversation in a bar, you need to know everything the drunk people know, separately and in addition to everything you know. Being drunk yourself would just get in the way. Similarly, predicting the behavior of nice people isn't the same thing as being nice. Modular arithmetic isn't like that; there's nothing besides the knowledge to not implement.
Simplicia: But we only need our AI to compute nice behavior, not necessarily to have some internal structure corresponding to the quale of niceness. As far as safety properties go, we don't care whether the actress is "really drunk" as long as she stays in character.
Doomimir: [scoffing] Have you tried imagining any internal mechanisms at all other than a bare, featureless inclination to emit the outward behavior you observe?
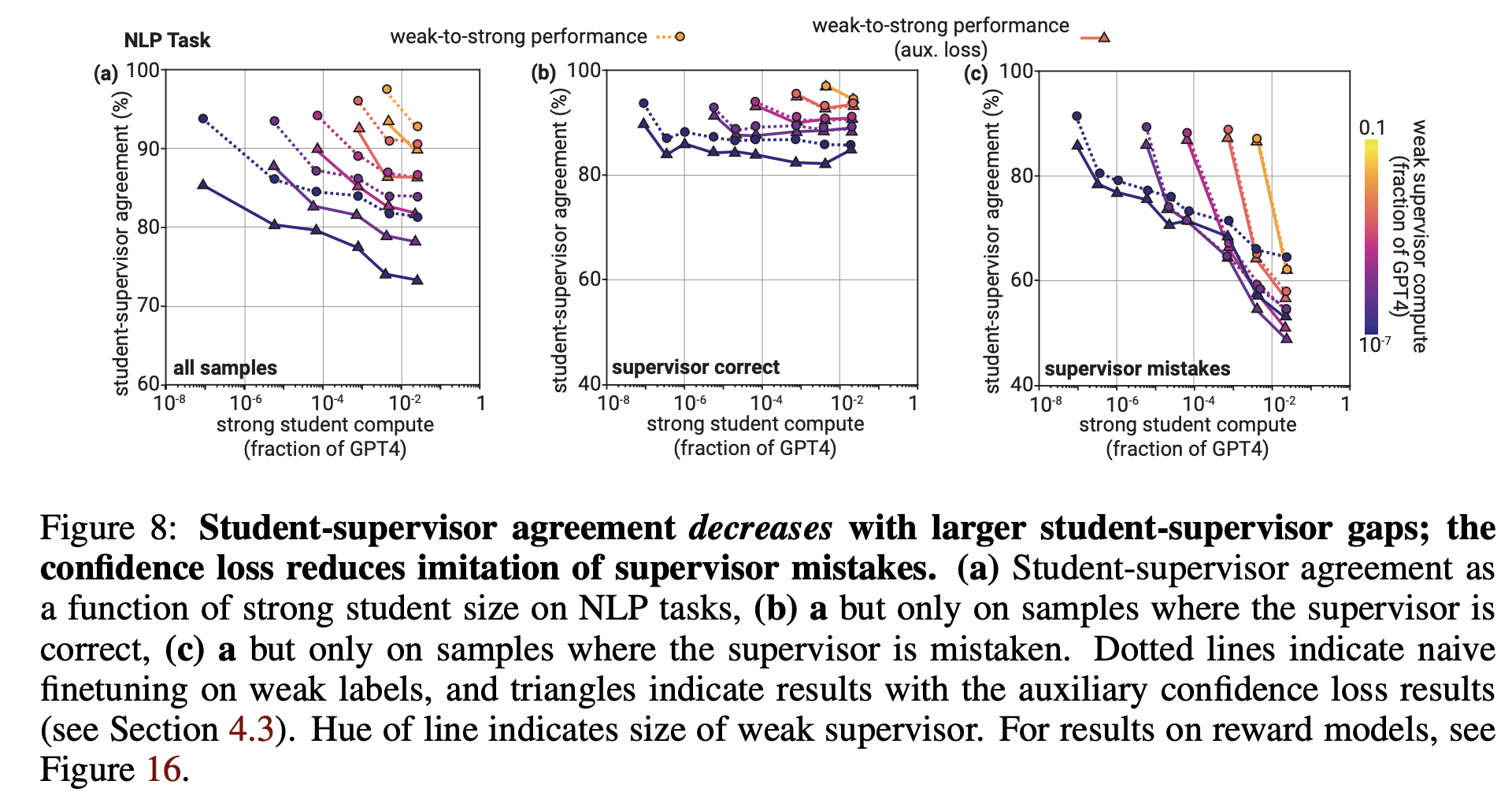
Simplicia: [unfazed] Sure, let's talk about internal mechanisms. The reason I chose modular arithmetic as an example is because it's a task for which we have good interpretability results. Train a shallow transformer on a subset of the addition problems modulo some fixed prime. The network learns to map the inputs onto a circle in the embedding space, and then does some trigonometry to extract the residue, much as one would count forward on the face of an analog clock.
Alternatively, with a slightly different architecture that has a harder time with trig, it can learn a different algorithm: the embeddings are still on a circle, but the answer is computed by looking at the average of the embedding vectors of the inputs. On the face of an analog clock, the internal midpoints between distinct numbers that sum to 6 mod 12—that's 2 and 4, or 1 and 5, or 6 and 12, or 10 and 8, or 11 and 7—all lie on the line connecting 3 and 9. Thus, the sum-mod-p of two numbers can be determined by which line the midpoint of the inputs falls on—as long as the inputs aren't on opposite sides of the circle, in which case their midpoint is in the center, where all the lines meet. But the network compensates for such antipodal points by also learning another circle in a different subspace of the embedding space, such that inputs that are antipodal on the first circle are close together on the second, which helps disambiguate the answer.
Doomimir: Cute results. Excellent work—by Earth standards. And entirely unsurprising. Sure, if you train your neural net on a well-posed mathematical problem with a consistent solution, it will converge on a solution to that problem. What's your point?
Simplicia: It's evidence about the feasibility of learning desired behavior from training data. You seem to think that it's hopelessly naïve to imagine that training on "nice" data could result in generalizably nice behavior—that the only reason someone might think that was a viable path was is if they were engaging in magical reasoning about surface similarities. I think it's germane to point out that at least for this toy problem, we have a pretty concrete, non-magical story about how optimizing against a training set discovers an algorithm that reproduces the training data and also generalizes correctly to the test set.
For non-toy problems, we know empirically that deep learning can hit very precise behavioral targets: the vast hypermajority of programs don't speak fluent English or generate beautiful photorealistic images, and yet GPT-4 and Midjourney exist.
If doing that for "text" and "images" was a mere engineering problem, I don't see what fundamental theoretical barrier rules out the possibility of pulling off the same kind of thing for "friendly and moral real-world decisionmaking"—learning a "good person" or "obedient servant" function from data, much as Midjourney has learned a "good art" function.
It's true that diffusion models don't work like a human artist on the inside, but it's not clear why that matters? It would seem idle to retort, "Predicting what good art would look like, doesn't make you a good artist; having an æsthetic sense yourself would just get in the way", when you can actually use it to do a commissioned artist's job.
Doomimir: Messier tasks aren't going to have a unique solution like modular arithmetic. If genetic algorithms, gradient descent, or anything like that happens to hill-climb its way into something that appears to work, the function it learns is going to have all sorts of weird squiggles around inputs that we would call adversarial examples, that look like typical members of the training distribution from the AI's perspective, but not ours—which kill you when optimized over by a powerful AGI.
Simplicia: It sounds like you're making an empirical claim that solutions found by black-box optimization are necessarily contingent and brittle, but there's some striking evidence that seemingly "messy" tasks admit much more convergent solutions than one might expect. For example, on the surface, the word2vec and FastText word embeddings look completely different—as befitting being produced by two different codebases trained on different datasets. But when you convert their latent spaces to a relative representation—choosing some shared vocabulary words as anchors, and defining all other word vectors by their cosine similarities to the anchors—they look extremely similar.
It would seem that "English word embeddings" are a well-posed mathematical problem with a consistent solution. The statistical signature of the language as it is spoken is enough to pin down the essential structure of the embedding.
Relatedly, you bring up adversarial examples in a way that suggests that you think of them as defects of a primitive optimization paradigm, but it turns out that adversarial examples often correspond to predictively useful features that the network is actively using for classification, despite those features not being robust to pixel-level perturbations that humans don't notice—which I guess you could characterize as "weird squiggles" from our perspective, but the etiology of the squiggles presents a much more optimistic story about fixing the problem with adversarial training than if you thought "squiggles" were an inevitable consequence of using conventional ML techniques.
Doomimir: This is all very interesting, but I don't think it bears much on the reasons we're all going to die. It's all still on the "is" side of the is–ought gap. What makes intelligence useful—and dangerous—isn't a fixed repertoire of behaviors. It's search, optimization—the systematic discovery of new behaviors to achieve goals despite a changing environment. I don't think recent capabilities advances bear on the shape of the alignment challenge because being able to learn complex behavior on the training distribution was never what the problem was about.
Indeed, as long as we continue to be stuck in the paradigm of reasoning about "the training distribution"—growing minds rather than designing them—then we're not learning anything about how to aim cognition at specific targets—certainly not in a way that will hold up to dumping large amounts of optimization power into the system. The lack of an explicit "goal slot" in your neural network doesn't mean it's not doing any dangerous optimization; it just means you don't know what it is.
Simplicia: I think we can form educated guesses—
Doomimir: [interrupting] Guesses!
Simplicia: —probabilistic beliefs—about what kinds of optimization is being done by a system and whether it's a problem, even without a complete mechanistic interpretability story. If you think LLMs or future variations thereof are unsafe because they're analogous to an actress with her own goals playing a drunk character without herself being drunk, shouldn't that make some sort of testable prediction about their generalization behavior?
Doomimir: Nonfatally testable? Not necessarily. If you lend a con man $5, and he gives it back, that doesn't mean that you can trust him with larger amounts of money, if he only gave back the $5 because he hoped you would trust him with more.
Simplicia: Okay, I agree that deceptive alignment is potentially a real problem at some point, but can we at least distinguish between misgeneralization and deceptive alignment?
Doomimir: Mis-generalization? The goals you wanted aren't a property of the training data itself. The danger comes from correct generalization implying something you don't want.
Simplicia: Can I call it mal-generalization?
Doomimir: Sure.
Simplicia: So there are obviously risks from malgeneralization, where the network that fits your training distribution turns out to not behave the way you wanted against a different distribution. For example, a reinforcement learning policy trained to collect a coin at the right edge of a video game level, might end up continuing to navigate to the right edge of levels where the coin is in a different location. That's a worrying clue that if we misunderstand how inductive biases work and aren't careful with our training setup, we might train the wrong thing. As our civilization delegates more and more cognitive labor to machines, eventually humans will lose the ability to course-correct. We're starting to see the early signs of this: as I mentioned the other day, Anthropic Claude's preachy, condescending personality already gives me the creeps. I'm pretty nervous about extrapolating that into a future where all productive roles in Society are filled by Claude's children, concurrently with a transition to explosive economic growth rates.
But the malgeneralization examples I named aren't surprising when you look at how the systems were trained. For the game policy, "going to the coin" and "going to the right" did amount to the same thing in training—and randomizing the coin position in just a couple percent of training episodes suffices to instill the correct behavior. Regarding Claude, Anthropic is using a reinforcement-learning-from-AI-feedback method they call Constitutional AI: instead of having humans provide the labels for RLHF, they write up a list of principles, and have another language model do the labeling. It makes sense that a language model agent trained to conform to principles chosen by a committee at a California public benefit corporation would act like that.
In contrast, when you make analogies about an actress playing a drunk character not being drunk, or giving a con man $5, it doesn't sound like you're talking about the risk of training the wrong thing, where it's usually clear in retrospect if not foresight how training encouraged the bad behavior. Rather, it sounds like you don't think training can shape motivations—"inner" motivations—at all.
You might be talking about deceptive alignment, a hypothesized phenomenon where a situationally aware AI strategically feigns aligned behavior in order to preserve its later influence. Researchers have debated how likely that is, but I'm not sure what to make of those arguments. I'd like to factor that consideration out. Suppose, arguendo, that we could figure out how to avoid deceptive alignment. How would your risk story change?
Doomimir: What would that even mean? What we would think of as "deception" isn't a weird edge case you can trivially avoid; it's convergent for any agent that isn't specifically coordinating with you to interpret certain states of reality as communication signals with a shared meaning.
When you set out poisoned ant baits, you likely don't think of yourself as trying to deceive the ants, but you are. Similarly, a smart AI won't think of itself as trying to deceive us. It's trying to achieve its goals. If its plans happen to involve emitting sound waves or character sequences that we interpret as claims about the world, that's our problem.
Simplicia: "What would that even"—this isn't 2008, Doomishko! I'm talking about the technology right here in front of us! When GPT-4 writes original code for me, I don't think it's strategically deciding that obeying me instrumentally serves its final goals! From everything I've read about how it was made and seen about how it behaves, it looks awfully like it's just generalizing from its training distribution in an intuitively reasonable way. You ridicule people who deride LLMs as stochastic parrots, ignoring the obvious sparks of AGI right in front of their face. Why is it not equally absurd to deny the evidence in front of your face that alignment may be somewhat easier than it looked 15 years ago? By all means, expound on the nonobvious game theory of deception; by all means, point out that the superintelligence at the end of time will be an expected utility maximizer. But all the same, RLHF/DPO as the cherry on top of a cake of unsupervised learning is verifiably working miracles for us today—in response to commands, not because it has a will of its own aligned with ours. Why is that merely "capabilities" and not at all "alignment"? I'm trying to understand, Doomimir Doomovitch, but you're not making this easy!
Doomimir: [starting to anger] Simplicia Optimistovna, if you weren't from Earth, I'd say I don't think you're trying to understand. I never claimed that GPT-4 in particular is what you would call deceptively aligned. Endpoints are easier to predict than intermediate trajectories. I'm talking about what will happen inside almost any sufficiently powerful AGI, by virtue of it being sufficiently powerful.
Simplicia: But if you're only talking about the superintelligence at the end of time—
Doomimir: [interrupting] This happens significantly before that.
Simplicia: —and not making any claims about existing systems, then what was the whole "alien actress", "predicting bar conversations doesn't make you drunk" analogy about? If it was just a ham-fisted way to explain to normies that LLMs that do relatively well on a Turing test aren't humans, then I agree, trivially. But it seemed like you thought you were making a much stronger point, ruling out an entire class of alignment strategies based on imitation.
Doomimir: [cooler] Basically, I think you're systematically failing to appreciate how things that have been optimized to look good to you can predictably behave differently in domains where they haven't been optimized to look good to you—particularly, when they're doing any serious optimization of their own. You mention the video game agent that navigates to the right instead of collecting a coin. You claim that it's not surprising given the training set-up, and can be fixed by appropriately diversifying the training data. But could you have called the specific failure in advance, rather than in retrospect? When you enter the regime of transformatively powerful systems, you do have to call it in advance.
I think if you understood what was really going on inside of LLMs, you'd see thousands and thousands of analogues of the "going right rather than getting the coin" problem. The point of the actress analogy is that the outward appearance doesn't tell you what goals the system is steering towards, which is where the promise and peril of AGI lies—and the fact that deep learning systems are a inscrutable mess, not all of which can be described as "steering towards goals", makes the situation worse, not better. The analogy doesn't depend on existing LLMs having the intelligence or situational awareness for the deadly failure modes to have already appeared, and it doesn't preclude LLMs being mundanely useful in the manner of an interactive textbook—much as an actress could be employed to give plausible-sounding answers to questions posed to her character, without being that character.
Simplicia: Those mismatches still need to show up in behavior under some conditions, though. I complained about Claude's personality, but that honestly seems fixable with scaling by an AI company not based in California. If human imitation is so superficial and not robust, why does constitutional AI work at all? You claim that "actually" being nice would get in the way of predicting nice behavior. How? Why would it get in the way?
Doomimir: [annoyed] Being nice isn't the optimal strategy for doing well in pretraining or RLHF. You're selecting an algorithm for a mixture of figuring out what outputs predict the next token and figuring out what outputs cause humans to press the thumbs-up button.
Sure, your AI ends up having to model a nice person, which is useful for predicting what a nice person would say, which is useful for figuring out what output will manipulate—steer—humans into pressing the thumbs-up button. But there's no reason to expect that model to end up in control of the whole AI! That would be like ... your beliefs about what your boss wants you to do taking control of your brain.
Simplicia: That makes sense to me if you posit a preëxisting consequentialist reasoner being slotted into a contemporary ML training setup and trying to minimize loss. But that's not what's going on? Language models aren't an agent that has a model. The model is the model.
Doomimir: For now. But any system that does powerful cognitive work will do so via retargetable general-purpose search algorithms, which, by virtue of their retargetability, need to have something more like a "goal slot". Your gradient updates point in the direction of more consequentialism.
Human raters pressing the thumbs-up button on actions that look good to them are going to make mistakes. Your gradient updates point in the direction of "playing the training game"—modeling the training process that actually provides reinforcement, rather than internalizing the utility function that Earthlings naïvely hoped the training process would point to. I'm very, very confident that any AI produced via anything remotely like the current paradigm is not going to end up wanting what we want, even if it's harder to say exactly when it will go off the rails or what it will want instead.
Simplicia: You could be right, but it seems like this all depends on empirical facts about how deep learning works, rather than something you could be so confident in from a priori philosophy. The argument that systemic error in human reward labels favors gaming the training process over the "correct" behavior sounds plausible to me, as philosophy.
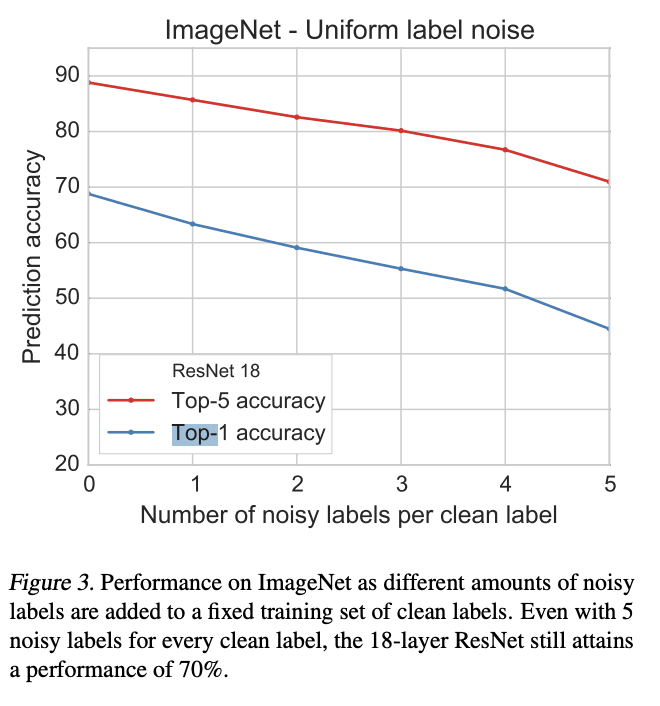
But I'm not sure how to reconcile that with the empirical evidence that deep networks are robust to massive label noise: you can train on MNIST digits with twenty noisy labels for every correct one and still get good performance as long as the correct label is slightly more common than the most common wrong label. If I extrapolate that to the frontier AIs of tomorrow, why doesn't that predict that biased human reward ratings should result in a small performance reduction, rather than ... death?
When extrapolation from empirical data (in a setting that might not apply to the phenomenon of interest) contradicts thought experiments (which might make assumptions that don't apply to the phenomenon of interest), I'm not sure which should govern my anticipations. Maybe both results are possible for different kinds of systems?
The case for near-certain death seems to rely on a counting argument: powerful systems will be expected utility maximizers; there's an astronomical space of utility functions to choose from, and almost none of them are friendly. But the reason I keep going back to the modular arithmetic example is because it's a scaled-down case where we know that training data successfully pinned down the intended input–output function. As I mentioned the other day, this wasn't obvious in advance of seeing the experimental result. You could make a similar counting argument that deep nets should always overfit, because there are so many more functions that generalize poorly. Somehow, the neural network prior favors the "correct" solution, rather than it taking an astronomically unlikely coincidence.
Doomimir: For modular arithmetic, sure. That's a fact about the training distribution, the test distribution, and the optimizer. It's definitely, definitely not going to work for "goodness".
Simplicia: Even though it seems to work for "text" and "images"? But okay, that's plausible. Do you have empirical evidence?
Doomimir: Actually, yes. You see—
[A mail carrier holding a package enters stage left. He rings the doorbell.]
Doomimir: That's probably the mailman. I'm expecting a package today that I need to sign for. I'll be right back.
Simplicia: So you might say, we'll continue [turning to the audience] after the next post?
Doomimir: [walking to the door] I suppose, but it's bizarre to phrase it that way given that the interruption literally won't take two minutes.
[Simplicia gives him a look.]
Doomimir: [to the audience] Subjectively.
[Curtain.]
Intermission