I am intrigued by the estimate for the difficulty of recapitulating evolution. Bostrom estimates 1E30 to 1E40 FLOPSyears. A conservative estimate for the value of a successful program to recapitulate evolution might be around $500B. This is enough to buy something like 10k very large supercomputers for a year, which gets you something like 1E20 FLOPSyears. So the gap is between 10 and 20 orders of magnitude. In 35 years, this gap would fall to 5 to 15 orders of magnitude (at the current rate of progress in hardware, which seems likely to slow).
One reason this possibility is important is that it seems to offer one of the strongest possible environments for a disruptive technological change.
This seems sensible as a best guess, but it is interesting to think about scenarios where it turns out to be surprisingly easy to simulate evolution. For example, if there were a 10% chance of this project being economically feasible within 20 years, that would be an extremely interesting fact, and one that might affect my views of the plausibility of AI soon. (Not necessarily because such an evolutionary simulation per se is likely to occur, but mostly because it says something about the overall ...
In my understanding, technological progress almost always proceeds relatively smoothly (see algorithmic progress, the performance curves database, and this brief investigation). Brain emulations seem to represent an unusual possibility for an abrupt jump in technological capability, because we would basically be ‘stealing’ the technology rather than designing it from scratch. Similarly, if an advanced civilization kept their nanotechnology locked up nearby, then our incremental progress in lock-picking tools might suddenly give rise to a huge leap in nanotechnology from our perspective, whereas earlier lock picking progress wouldn’t have given us any noticeable nanotechnology progress. If this is an unusual situation however, it seems strange that the other most salient route to superintelligence - artificial intelligence designed by humans - is also often expected to involve a discontinuous jump in capability, but for entirely different reasons. Is there some unifying reason to expect jumps in both routes to superintelligence, or is it just coincidence? Or do I overstate the ubiquity of incremental progress?
I think that incremental progress is very much the norm as you say; it might be informative to compile a list of exceptions.
How fast is relevant neuroscience progressing toward brain emulation or brain-inspired AI? How can we even measure it? Ray Kurzweil claims it is growing exponentially in The Singularity is Near, while Paul Allen counters that understanding in neuroscience usually gets harder the more we learn. How can we tell who is right?
This is some nice foreshadowing:
Readers of this chapter must not expect a blueprint for programming an artificial general intelligence. No such blueprint exists yet, of course. And had I been in possession of such a blueprint, I most certainly would not have published it in a book. (If the reasons for this are not immediately obvious, the arguments in subsequent chapters will make them clear.)
‘An artificial intelligence need not much resemble a human mind’ (p29)
What are some concrete ways an AI mind programmed from scratch might be very different? Are there ways it is likely to be the same? (I pointed to Omohundro's paper about the latter question before; this LessWrong thread speculates about alien minds in general)
‘We can also say, with greater confidence than for the AI path, that the emulation path will not succeed in the near future (within the next fifteen years, say) because we know that several challenging precursor technologies have not yet been developed. By contrast, it seems likely that somebody could in principle sit down and code a seed AI on an ordinary present-day personal computer; and it is conceivable - though unlikely - that somebody somewhere will get the right insight for how to do this in the near future.’ - Bostrom (p36)
Why is it more plausi...
There's a confusing and wide ranging literature on embodied cognition, and how the human mind uses metaphors to conceive of many objects and events that happen in the world around us. Brain emulations, presumably, would also have a similar capacity for metaphorical thinking and, more generally, symbolic processing. It may be worthwhile to keep in mind though that some metaphor depend on the physical constituency of the being using them, and they may either fail to refer in an artificial virtual system, or not have any significant correlation with the way ...
The AI section is actually very short, and doesn't say much about potential AI paths to superintelligence. E.g. one thing I might have mentioned is the "one learning algorithm" hypothesis about the neocortex, and the relevance of deep learning methods. Or the arcade learning environment as a nice test for increasingly general intelligence algorithms. Or whatever.
A superintelligence is defined as ‘any intellect that greatly exceeds the cognitive performance of humans in virtually all domains of interest’ (p22). By this definition, it seems some superintelligences exist: e.g. basically economically productive activity I can do, Google can do better. Does I.J.Good’s argument in the last chapter (p4) apply to these superintelligences?
To remind you, it was:
...Let an ultraintelligent machine be defined as a machine that can far surpass all the intellectual activities of any man however clever. Since the design of machin
Bostrom talks about a seed AI being able to improve its 'architecture', presumably as opposed to lower level details like beliefs. Why would changing architecture be particularly important?
I wonder if advances in embryo selection might reduce fertility. At the moment I think one of the few things keeping the birth rate up is people thinking of it as the default. But embryo selection seems like it could interrupt this: a clearly superior option might make having children naturally less of a default option, but with using embryo selection novel enough to seem like a discretionary choice, and therefor not replacing it.
What evidence do we have about the level of detail needed to emulate a mind? Whole Brain Emulation: A Roadmap provides a list of possible levels (see p13) and reports on an informal poll in which experts guessed that at least the ‘spiking neural network’ would be needed, and perhaps as much as the eletrophysiology (e.g. membrane states, ion concentrations) and metabolome (concentrations of metabolites and neurotransmitters)(p14). Why might experts believe these are the relevant levels?
If there are functional brain emulations at some point, how expensive do you think the first ones will be? How soon will they be cheap enough to replace an average human in their job?
The concept of "Seed AI" was introduced in this chapter. I am interested to hear whether other people have opinions about the the plausibility of a "Seed AI."
Linguistic processing seems like an area where a small amount of code operating on a large database of definitions, relationships and text or recorded scenes along with relationships could produce some significant results.
General planning algorithms could also very compact.
An AI system capable of performing design perhaps could be developed in a relatively small amount of code, if it had access to a vast database of existing designs which it searches for possible modifications.
Bostrom discusses ‘high-fidelity emulations’, ‘distorted emulations’ and ‘generic emulations’ (p33). If society started to produce emulations, how much do you think it would matter which of these kinds were produced?
It is sometimes suggested that if humanity develops upload, we will naturally produce neuromorphic AGI slightly earlier or shortly afterward. What do you think of this line of reasoning? Section 3.2 of Eckersley & Sandberg (2013) is relevant.
Who are you? Would you like to introduce yourself to the rest of us? Perhaps tell us about what brings you here, or what interests you.
How plausible do you find whole-brain emulation? Do you think that in one hundred years, it will be possible to run a model of your brain on a computer, such that it behaves much like you?
I pointed to Richard Jones arguing that you should only expect scale separation in designed systems. This seems a poor inference to me. Natural systems very often have 'designed' seeming features, due to selection, and he doesn't explain why scale separation would only come from a real designer, rather than selection. Further, it seems natural systems often actually have scale separation - i.e. you can model the system fine by only looking at items at a certain scale, ignoring their details. e.g. you can model planetary motion well without knowing the deta...
I feel like whole brain emulation is often considered implausible, but I don’t know of many good criticisms of its plausibility. Do you?
What kind of organization do you think is likely to develop human-level AI first? If it is fully synthetic AI? If it is brain emulations? Do you think other groups will quickly copy, or for instance will it require Manhattan Project scale infrastructure?
If a for profit venture developed brain emulation technology, who would they emulate first? How would they choose?
This is part of a weekly reading group on Nick Bostrom's book, Superintelligence. For more information about the group, and an index of posts so far see the announcement post. For the schedule of future topics, see MIRI's reading guide.
Welcome. This week we discuss the third section in the reading guide, AI & Whole Brain Emulation. This is about two possible routes to the development of superintelligence: the route of developing intelligent algorithms by hand, and the route of replicating a human brain in great detail.
This post summarizes the section, and offers a few relevant notes, and ideas for further investigation. My own thoughts and questions for discussion are in the comments.
There is no need to proceed in order through this post. Feel free to jump straight to the discussion. Where applicable, page numbers indicate the rough part of the chapter that is most related (not necessarily that the chapter is being cited for the specific claim).
Reading: “Artificial intelligence” and “Whole brain emulation” from Chapter 2 (p22-36)
Summary
Intro
Whole brain emulation
Notes
Bostrom and Müller's survey asked participants to compare various methods for producing synthetic and biologically inspired AI. They asked, 'in your opinion, what are the research approaches that might contribute the most to the development of such HLMI?” Selection was from a list, more than one selection possible. They report that the responses were very similar for the different groups surveyed, except that whole brain emulation got 0% in the TOP100 group (100 most cited authors in AI) but 46% in the AGI group (participants at Artificial General Intelligence conferences). Note that they are only asking about synthetic AI and brain emulations, not the other paths to superintelligence we will discuss next week.
Omohundro suggests advanced AIs will tend to have important instrumental goals in common, such as the desire to accumulate resources and the desire to not be killed.
Anthropic reasoning
‘We must avoid the error of inferring, from the fact that intelligent life evolved on Earth, that the evolutionary processes involved had a reasonably high prior probability of producing intelligence’ (p27)
Whether such inferences are valid is a topic of contention. For a book-length overview of the question, see Bostrom’s Anthropic Bias. I’ve written shorter (Ch 2) and even shorter summaries, which links to other relevant material. The Doomsday Argument and Sleeping Beauty Problem are closely related.
Whole Brain Emulation: A Roadmap is an extensive source on this, written in 2008. If that's a bit too much detail, Anders Sandberg (an author of the Roadmap) summarises in an entertaining (and much shorter) talk. More recently, Anders tried to predict when whole brain emulation would be feasible with a statistical model. Randal Koene and Ken Hayworth both recently spoke to Luke Muehlhauser about the Roadmap and what research projects would help with brain emulation now.
Levels of detail
As you may predict, the feasibility of brain emulation is not universally agreed upon. One contentious point is the degree of detail needed to emulate a human brain. For instance, you might just need the connections between neurons and some basic neuron models, or you might need to model the states of different membranes, or the concentrations of neurotransmitters. The Whole Brain Emulation Roadmap lists some possible levels of detail in figure 2 (the yellow ones were considered most plausible). Physicist Richard Jones argues that simulation of the molecular level would be needed, and that the project is infeasible.
Other problems with whole brain emulation
Sandberg considers many potential impediments here.
Order matters for brain emulation technologies (scanning, hardware, and modeling)
Bostrom points out that this order matters for how much warning we receive that brain emulations are about to arrive (p35). Order might also matter a lot to the social implications of brain emulations. Robin Hanson discusses this briefly here, and in this talk (starting at 30:50) and this paper discusses the issue.
What would happen after brain emulations were developed?
We will look more at this in Chapter 11 (weeks 17-19) as well as perhaps earlier, including what a brain emulation society might look like, how brain emulations might lead to superintelligence, and whether any of this is good.
Scanning (p30-36)

‘With a scanning tunneling microscope it is possible to ‘see’ individual atoms, which is a far higher resolution than needed...microscopy technology would need not just sufficient resolution but also sufficient throughput.’
Here are some atoms, neurons, and neuronal activity in a living larval zebrafish, and videos of various neural events.
Array tomography of mouse somatosensory cortex from Smithlab.
A molecule made from eight cesium and eight
iodine atoms (from here).
Efforts to map connections between neurons
Here is a 5m video about recent efforts, with many nice pictures. If you enjoy coloring in, you can take part in a gamified project to help map the brain's neural connections! Or you can just look at the pictures they made.
The C. elegans connectome (p34-35)
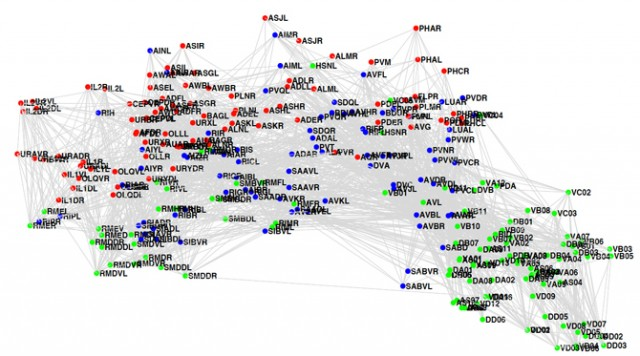
As Bostrom mentions, we already know how all of C. elegans’ neurons are connected. Here's a picture of it (via Sebastian Seung):
In-depth investigations
If you are particularly interested in these topics, and want to do further research, these are a few plausible directions, some taken from Luke Muehlhauser's list:
How to proceed
This has been a collection of notes on the chapter. The most important part of the reading group though is discussion, which is in the comments section. I pose some questions for you there, and I invite you to add your own. Please remember that this group contains a variety of levels of expertise: if a line of discussion seems too basic or too incomprehensible, look around for one that suits you better!
Next week, we will talk about other paths to the development of superintelligence: biological cognition, brain-computer interfaces, and organizations. To prepare, read Biological Cognition and the rest of Chapter 2. The discussion will go live at 6pm Pacific time next Monday 6 October. Sign up to be notified here.