This is a special post for quick takes by Oliver Sourbut. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
Learned about 'Harberger tax' recently.
The motivation is like
- private assets (private use and excludable) incentivise investment/productive improvement/development well
- but private ownership of non-liquid, non-fungible, idiosyncratic things (factories, houses, natural resources maybe, AI systems maybe?) acts like a monopoly, distorting allocation (more productive/valued uses aren't often realised)
- e.g. NIMBYism
- e.g. 'holdout pricing'
- e.g. inefficient bargaining due to information asymmetry
- common ownership and lease auctioning incentivises efficient allocation
The pitch is like, can we do something in between?
- self-assessment of value (reveals something close to honest valuation)
- pay some rate of tax on that self-assessment
- you have to sell at that self-assessed value if someone wants to buy
They claim this keeps most of the benefit of investment incentivisation, because things are mostly private in practice, but substantially improves allocative efficiency by lubricating the more valuable trades.
Anyway, mainly it's interesting because getting into the gubbins of particular proposals helps me learn about the relevant dynamics in general, but also I wondered if there's something in this vicinity that could work nicely for AI development and AI deployment. (Like maybe a Harberger tax on compute, or on AI systems, or...)
Being required to sell at exactly the value you place on something seems unlikely to work out well in practice. As a toy example, carabiners are cheap, but if you're using one to hold your weight over a hundred foot drop, its value to you is approximately equal to the value of your life. Depending on any asset the sale of which can be forced is very risky, and assessing all critical components of a business at the entire value of the business seems incoherent.
Strongly agree. Sell-price tax with forced sales sounds like something a cryptocurrency would implement. It might work there, since if a malicious bidder tried to buy your TOKEN at above-market price, you could automatically buy a new one within the same block, at actual-market price. This could also work for fungible but rapidly-transferrable assets like cloud GPU time.
If taxing physical goods (like infrastructure or even land) which is where a lot of value in the world lies, this does just open up companies for extortion. E.g. what if I demand to buy one square inch of land under Bill Gates' house, then demand he remodel his house around the square inch. Or suppose his summer house is in the middle of the Pennsylvania woodland, where the land is actually quite cheap, so he's either forced to pay extremely high tax on his land for, or he's open to extortion in the same way.
I think implementing a Georgist land tax basically requires that we trust some government bureaucrats to approximately accurately determine the value of plots of land. This isn't an unreasonable level of trust for a first-world country; in the UK we trust government bureaucrats to draw the boundaries for our election districts, and that works alright.
See other thread where we discuss a variant without forced sale, but with forced re-evaluation.
I don't think anyone would advocate a naive universalist approach to this with square inches for sale. This does point at an interesting mereological dynamic here though where the boundaries of 'an item' might in principle be subject to some gerrymandering!
I do think that a large part of the point is to incentivise a high (somewhat Georgist) tax on 'counterproductive' uses of land (or similar), if I've read correctly.
I happen to know a former low-level land evaluation bureaucrat in the UK (for council tax) and he said it's a huge pain. For annoying bureaucratic activities, two standard questions are 'can we sensibly decentralise?' and 'can we sensibly automate?'... maybe so.
UK council tax is based on overall property value, not unimproved land value.
Did they do whole properties or was there an even weirder system where one bureaucrat does the land and the other does the property?
Many versions of the proposal do not require you to sell immediately. Often there's a built in delay period before the trade occurs.
But more generally, yeah, you don't want to to do this with carabiners. But you might want to do it with land.
It seems like it would be pretty hard to define a single reasonable delay period for land sales. An example case where a large delay would be justifiable is: a business manufactures cars, and has a single factory that makes some critical component. The value of their business is effectively zero if they can't manufacture that component. But it takes N years and D dollars to get zoning, environnemental, safety etc approvals for a new factory (and also to actually build it and get it running as smoothly as the last one, and hire competent staff, and lay off the old staff...). Having a variable "reasonable" delay and switching-cost compensation might work, but that sounds like a recipe for endless litigation.
On top of that, land can have network effects within a single owner--if a business builds 5 codependent factories and has to sell one of them, but cannot feasibly replace the one sold with something new nearby, each of the factories would have to be valued at the entire value of the network, multiplying your tax burden by the number of parcels your network is broken into.
I agree that the way we do land now is not good, but at first glance I don't see a way to fix this proposed system without a bunch of patches with their own problems.
Leaving aside delays, this does get at a point I noticed wasn't obviously addressed in that paper which is what to do about very seasonal things. The example I thought of (rather less macabre) was an umbrella in a rainstorm. I don't think it's sensibly applicable to most personal property.
Agreed, but the timing issues seem applicable to businesses' property as well. Sudden unpredictable spikes in value (e.g. of a mine for a rare metal that somebody figured out a new use for) could result in a lot of churn and removes the upside (but not downside!) variance in asset value.
By this, do you mean something like: when I purchase a mine or whatever, I'm speculatively pricing in some upside (e.g. a new use) which is part of my valuation for it, and if later a marginally more alert person buys me out because of a new actual use before I update my valuation, I fail to realise that value? But if no new actual use comes up, I'm left holding the bag? I agree. And possibly we also agree that's the same issue as the umbrella, where someone noticed it's raining before I did?
A less crazed approach might be more like
- if someone bids at or above your assessed value, you have to sell or start paying commensurably more tax (possibly backdated some amount)
Yup this makes more sense imo, basically having a right of refusal on the sale, but reflecting the now-assessed-higher tax rate
Wouldn't the equilibrium here trend towards a bunch of wasted labor where I deliberately lowball the value of the land, and then if someone offers a larger amount, I just say no and then start paying the larger amount, thus having a potential to pay less tax but losing nothing if I'm called out for it? No downside to me personally, and if this became common, it'd be harder to legitimately buy stuff. Seems like you'd need to pay some sort of fee to the entity credibly offering this larger amount to make it worth it.
Hmm I don't think so? If you buy land for $X, that's the floor on what you could reasonably assess it at, which is basically the status quo world. So we're in the status quo until someone comes along and bids up the price to their willingness-to-pay: Then, the asset either moves to someone who values it more, or you start paying higher taxes on it. I think either branch is preferable to the status quo?
Fair point, if you add that you can't assess it at less than you paid for it, this problem goes away.
Ideally you would want to allow depreciation though, which is a definite phenomenon! (Especially if things are neglected.)
Yeah, there's some design questions. You're right, the upside to the corrective bidders is naively nothing if they get called on it: they're doing valuable corrective cybernetic labour for free.
Maybe a sensible refinement would be for them to be owed a small fee... or roughly equivalently some (temporary) direct share of the resulting increased Harberger tax.
Good thing you're only incentivized to sell at market price then, not how much value you'd assign personally!
I'm not sure what you mean. You can list something at market price rather than how you actually value it, but that opens you up to significant risk from market volatility and malicious bids (from competitors looking to cripple your business, rich people you've offended, etc). If sales cannot actually be forced this seems more workable, but still exploitable by malicious actors.
Yeah I think I got a bit confused with the wording. My point is that a Harberger tax is a tax on the opportunity cost of you holding the thing being taxed, so if you are genuinely the single person who benefits most from holding the thing being taxed, then no one else would want to buy it from you.
I think unless they explicitly want to harm or threaten you, was the point - which incidentally is often a situation not accounted for in the foundational assumptions of many economic models (utility functions generally considered to be independent and monotonic in resources and so on).
Saw this event (recursive.to) coming soon. I won't be attending, but there are some exciting speakers lined up!
It is plausible that AI R&D will be automated in the next one to five years. OpenAI has set a deadline of 2028 for building an automated AI researcher, and other labs have made similar statements. If they meet their deadlines, the world will face significant risks. Recursive exists to bring together researchers thinking about these risks and make progress towards reducing them.
One point I'm worried won't get raised, but which is pretty crucial (according to me):
It's plausible that the main, even only important effect of automated AI research is concentration of power/influence over AI development and deployment.
I know that there's the whole spectre of superexponential AI progress/FOOM etc! I know! It's scary, it's a legitimate concern about recursive AI R&D. [1]
Even if that comes to pass, perhaps a far more crucial effect of automated AI progress is that whoever has the compute suddenly has much more unilateral say over how that's directed. If they're reckless or worse, that's a really big deal. If it doesn't rapidly result in superintelligence, that concentration of influence is still a really big and concerning deal, possibly substantially setting the stage for whatever subsequent tech transitions come up (perhaps including industrial automation).
For myself, I tentatively treat that as plausible but unlikely, because I think the main constraints on frontier AI are compute and domain data - agents which can devise and run experiments cheaply will add a boost but probably not drastically change the rate, which is already startling enough. And subsequent real-world impacts also look largely compute constrained. A bigger feedback is due in principle when high-tech manufacturing is automatable. ↩︎
What constitutes cooperation?
Realised my model pipeline:
- surface options (or find common ground)
- negotiate choices (agree a course of action)
- cooperate/enforce (counteract defections, actually do the joint good thing)
was missing an important preliminary step.
For cooperation to happen, you also need:
- identify potential coalitions (who could benefit from cooperating)!
(Could break down further: identifying, getting common knowledge, and securing initial prospective cooperative intent.)
In some cases, 'identifying potential coalitions' might be a large, even dominant part of the challenge of cooperation, especially when effects are diffuse!
That applies to global commons and it applies when coordinating political action. What other cases?
'Identifying potential coalitions' is what a lot of activism is about, and it might also be a big part of what various cooperative memeplexes like tribes, religions, political parties etc are doing.
This feels to me like another important part of the picture that new tech could potentially amplify!
Could we newly empower large groups of humans to cooperate by recognising and fulfilling the requirements of this cooperation pipeline?
'Temporary MAP stance' or 'subjective probability matching'
Temporary MAP stance or subjective probability matching are my words for useful mental manoeuvres for research, especially when dealing with confusing or prepradigmatic or otherwise non-crisp domains.
MAP is Maximum A Posteriori i.e. your best guess after considering evidence. Probability matching is making actions/guesses proportional to your estimate of them being right (rather than picking the single MAP choice).
By this manoeuvre I'm gesturing at a kind of behaviour where you are quite unsure about what's best (e.g. 'should I work on interpretability or demystifying deception?') and rather than allowing that to result in analysis paralysis, you temporarily collapse some uncertainty and make some concrete assumptions to get moving in one or other direction. Hopefully in so doing you a) make a contribution and b) grow your skills and collect new evidence to make better decisions/contributions next time.
It happens to correspond somewhat to a decent heuristic called Thompson Sampling, which is optimal under some conditions for some uncertain-duration sequential decision problems.
HT Evan Hubinger for articulating his take on this in discussions about research, and I'm certain I've read others discussing similar principles on LW or EAF but I don't have references to hand.
Here is some reasoned opinion about ML research automation.
Experimental compute and 'taste' seem very close to direct multiplier factors in the production of new insight:
- twice the compute means twice the number of experiments run [[1]]
- 'twice the taste' (for some operationalisation of taste) means proposing and running useful experiments twice as often
- (there are other factors too, like insight extraction and system-2 experiment design)
My model of research taste is that it 'accumulates' (according to some sample efficiency) in a researcher and/or team by observation (direct or indirect) of experiments. It 'depreciates', like a capital stock, both because individuals and teams forget or lose touch, and (more relevant to fast-moving fields) because taste generalises only so far, and the 'frontier' of research keeps moving.
This makes experiments extremely important, both as a direct input to insight production and as fuel for accumulating research taste.
Peak human teams can't get much better research taste in absence of experimental compute without improving on taste accumulation, which is a kind of learning sample efficiency. You can't do that by just having more people: you have to get very sharp people and have very effective organisational structure for collective intelligence. Getting twice the taste is very difficult!
AI research assistants which substantially improved on experiment design, either by accumulating taste more efficiently or by (very expensive?) reasoning much more extensively about experiment design, could make the non-compute factor grow as well.
You can't just 'be smarter' or 'have better taste' because it'll depreciate away. Reasoning for experiment design has very (logarithmically? [[2]] ) diminishing returns as far as I can tell, so I'd guess it's mostly about sample efficiency of taste accumulation.
(There's some parallelisation discount: k experiments in parallel is strictly worse than k in series, because you can't incorporate learnings.) ↩︎
A naive model where reasoning for experiment design means generating more proposals from an idea generator and attempting to select the best one has worse than logarithmic returns to running longer, for most sensible distributions of idea generation. Obviously reasoning isn't memoryless like that, because you can also build on, branch from, or refine earlier proposals, which might sometimes do better than coming up with new ones tabula rasa. ↩︎
Has the markdown editor been deprecated? I notice that it's still available if I go to edit my legacy posts (which were almost universally drafted in markdown and then pasted in), but on new posts it's not an option.
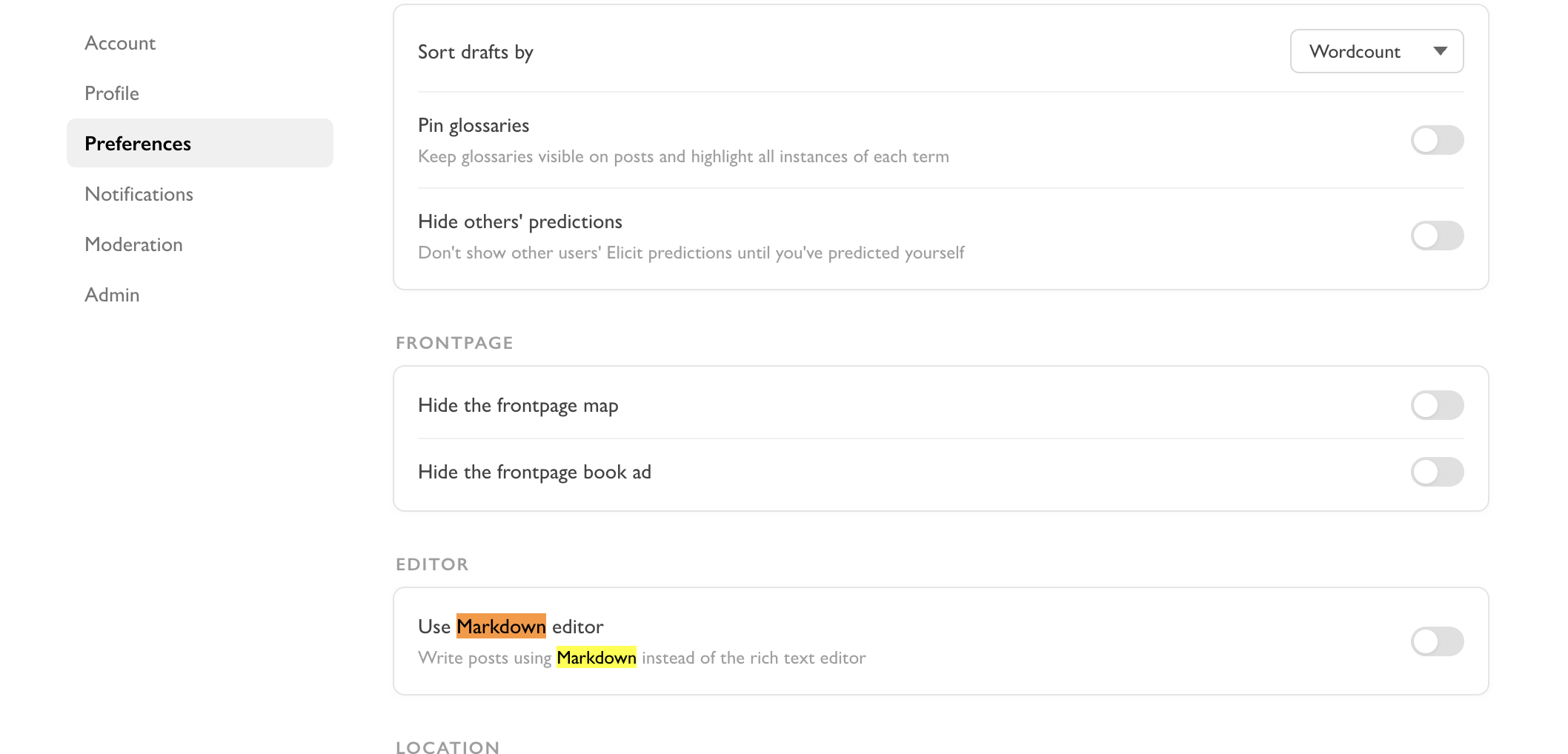
BTW I miss the old setup where I could change the editor on the fly to switch between markdown and rich text. For example one problem now is that I don't know how to markup LLM output in the markdown editor, but the rich text editor does not allow me to paste in markdown content. Another is that I can no longer write in markdown then switch to rich text as a way to preview what I wrote.
Yep, my current plan is to completely fade out the Markdown editor (it only historically existed because mobile editor support has been lacking).
And then I want to just have a "import markdown" /-command, which you can use to import Markdown, wherever you like, plus an "copy as markdown" selection-menu item so you can copy any text as markdown.
I think that will just be the less error-prone system.
Yes. The markdown editor has bugs with converting to/from other editors (e.g. footnotes get fucked) that it is a better idea to ban converting altogether than having no warnings. But I also want to complain about how many minor usability issues the new Lexical editor has. It felt like a mistake shoving the Lexical editor to everyone's face. I just counted 6 annoyances/small bugs I reported via Intercom and 3 more in various comments. Kudos to the team for fixing most bugs super quickly, but the number of bugs seem higher than you would want for a mass rollout where you changed the default and removed the option to switch back (to ckeditor, or to markdown within the box).
This is pretty acceptable, if paste-from and copy-as work well. Gdocs does this to an acceptable degree - there's something janky about images sometimes.
I'd like it if there were feature parity (e.g. equivalent footnote behaviour, image captions in markdown, LM content tags, not sure what else but e.g. your fun new widget inlines) but I very much see why that could be low on the priority list.
Last we spoke you were talking about API or command line integration which would in principle allow a very wide range of editing/importing workflows, at least for power users.
Last we spoke you were talking about API or command line integration which would in principle allow a very wide range of editing/importing workflows, at least for power users.
That is now there! It's what powers our LLM integrations:

What constitutes cooperation? (previously)
Because much in the complex system of human interaction and coordination is about negotiating norms, customs, institutions, constitutions to guide and constrain future interaction in mutually-preferable ways, I think:
- 'institution and constitution design'
deserves special attention.
This is despite it perhaps (for a given 'coordination moment') being in theory reducible to preference elicitation or aggregation, searching outcome space, negotiation, enforcement, ...
There are failure modes (unintended consequences, concentration of power, lost purposes, corruptability, poor adaptability, plain old inefficacy) and patterns for success (stabilising win-win equilibria, reducing inefficiencies, improving collective intelligence and adaptability) which are specific to this process of negotiating and developing institutions (there are patterns, because the complex system has emergent structure like trust, corruption, coalitions, information propagation, ...).
Said briefly: much (most?) coordination is about coordination because a) humans are that type of creature and b) we live in a highly iterated world.
I suspect that this is a bit too much of an anlytical and legible framework. the VAST majority of human interaction is not based on explicit rules or negotiated contracts, it's based on socially-evolved heuristics for who to trust to do what under what conditions, and then each individual has variance in their compliance and expectations, almost none of which are ever stated clearly.
I'd love to see 'institution and constitution design' replaced with 'institution and constitution studies'. Coordination is a word that hides a number of important sub-topics about enforcement/agreement for behaviors among misaligned individuals.
Seems right! 'studies' uplifts 'design' (either incremental or saltatory), I suppose. For sure, the main motivation here is to figure out what sorts of capabilities and interventions could make coordination go better, and one of my first thoughts under this heading is open librarian-curator assistive tech for historic and contemporary institution case studies. Another cool possibility could be simulation-based red-teaming and improvement of mechanisms.
If you have any resources or detailed models I'd love to see them!
I'm intrigued that 'neuralese' appears to have memetically mutated from meaning 'internal/latent message-passing and embeddings' to 'stego text by AI'... but maybe I had the wrong meaning originally?
I don't think that it mutated. The AI-2027 writeup had the authors explain that neuralese recurrence and memory is a yet-unfound technique "allowing AI models to reason for a longer time without having to write down those thoughts as text." The authors expect that by April 2027 or whenever the neuralese architecture is actually found "unlike English words, these high-dimensional vectors are likely quite difficult for humans to interpret. In the past, researchers could get a good idea what LLMs were thinking simply by reading its chain of thought. Now researchers have to ask the model to translate and summarize its thoughts or puzzle over the neuralese with their limited interpretability tools."
However, the AIs might develop other ways of transferring information between instances in ways unnoticeable by humans: "If this doesn’t happen, other things may still happen that end up functionally similar for our story. For example, perhaps models will be trained to think in artificial languages that are more efficient than natural language but difficult for humans to interpret. Or perhaps it will become standard practice to train the English chains of thought to look nice, such that AIs become adept at subtly communicating with each other in messages that look benign to monitors." The latter option is steganography which the humans find VERY hard to decipher.
Iran. As with Venezuela and Greenland, seems like much discourse is about very zero order things like 'he was/is a bad guy' and the rest about first order things like 'did/will US achieve objectives (whatever those are or get retconned to be) at low cost'. But surely in all cases the main effect is on the reputation of the US - as a state over the medium term, and of its current regime over the short?
(E.g. perhaps a very compressed description might be moving from 'legalistic and acquisitive, with a cautious and moralistic streak' to 'capricious and vindictive, with a hot temper and a unilateralist bent'.)
Whether that's good or bad is a whole different debate, and one I'm not seeing getting conducted! Any good sources? Is this more strategic than it first looks? To what extent are these naked principal-agent misalignments?
Of course. But that's still at what I called 'first order': does this make sense on its own local terms? It fairly clearly hasn't. But I don't think that's really the main effect, as I said, which is instead that the reputation of the US is pretty different here in 2026 Q1 than it was in 2025 Q4 (let alone earlier) in ways which will have long term impacts. (I also think these reputational factors look like straightforward self-owns but I'm less sure and I haven't encountered much commentary.)
If you want to be twice as profitable as your competitors, you don’t have to be twice as good as them. You just have to be slightly better.
I think AI development is mainly compute constrained (relevant for intelligence explosion dynamics).
There are some arguments against, based on the high spending of firms on researcher and engineer talent. The claim is that this supports one or both of a) large marginal returns to having more (good) researchers or b) steep power laws in researcher talent (implying large production multipliers from the best researchers).
Given that the workforces at labs remain not large, I think the spending naively supports (b) better.
But in fact I think there is another, even better explanation:
- Researchers' taste (an AI production multiplier) varies more smoothly
- (research culture/collective intelligence of a team or firm may be more important)
- Marginal parallel researchers have very diminishing AI production returns (sometimes negative, when the researchers have worse taste)
- (also determining a researcher's taste ex ante is hard)
- BUT firms' utility is sharply convex in AI production
- capturing more accolades and market share are basically the entire game
- spending as much time as possible with a non-commoditised offering allows profiting off fast-evaporating margin
- so firms are competing over getting cool stuff out first
- time-to-delivery of non-commoditised (!) frontier models
- and getting loyal/sticky customer bases
- ease-of-adoption of product wrapping
- sometimes differentiation of offerings
- this turns small differences in human capital/production multiplier/research taste into big differences in firm utility
- so demand for the small pool of the researchers with (legibly) great taste is very hot
This also explains why it's been somewhat 'easy' (but capital intensive) for a few new competitors to pop into existence each year, and why firms' revealed preferred savings rate into compute capital is enormous (much greater than 100%!).
We see token prices drop incredibly sharply, which supports the non-commoditised margin claim (though this is also consistent with a Wright's Law effect from (runtime) algorithmic efficiency gains, which should definitely also be expected).
A lot of engineering effort is being put into product wrappers and polish, which supports the customer base claim.
The implications include: headroom above top human expert teams' AI research taste could be on the small side (I think this is right for many R&D domains, because a major input is experimental throughput). So both quantity and quality of (perhaps automated) researchers should have steeply diminishing returns in AI production rate. But might they nevertheless unlock a practical monopoly (or at least an increasingly expensive barrier to entry) on AI-derived profit, by keeping the (more monetisable) frontier out of reach of competitors?