4 Answers sorted by
320
High dimensional spaces are unlikely to have local optima, and probably don’t have any optima at all.
Just recall what is necessary for a set of parameters to be at a optimum. All the gradients need to be zero, and the hessian needs to be positive semidefinite. In other words, you need to be surrounded by walls. In 4 dimensions, you can walk through walls. GPT3 has 175 billion parameters. In 175 billion dimensions, walls are so far beneath your notice that if you observe them at all it is like God looking down upon individual protons.
If there’s any randomness at all in the loss landscape, which of course there is, it’s vanishingly unlikely that all of the millions or billions of directions the model has to choose from will be simultaneously uphill. With so many directions to choose from you will always have at least one direction to escape. It’s just completely implausible that any big model comes close to any optima at all. In fact it’s implausible that an optimum exists. Unless you have a loss function that has a finite minimum value like squared loss (not cross entropy or softmax), or without explicit regularization that bounds the magnitude of the values, forces positive curvature, and hurts performance of the model, all real models diverge.
Source: https://moultano.wordpress.com/2020/10/18/why-deep-learning-works-even-though-it-shouldnt/
Wait, how is it possible for there to be no optimum at all? There's only a finite number of possible settings of the 175 billion parameters; there has to be at least one setting such that no other setting has lower loss. (I don't know much math, I'm probably misunderstanding what optimum means.)
Taking finite precision floating point numbers, there must be an optimum.
In the real numbers, there are an infinity of possible settings. Its possible to have an infinite sequence of ever better solutions. (The trivial example is the bigger a parameter is, the better the results, for any setting, its possible to add 1 and get a better setting.)
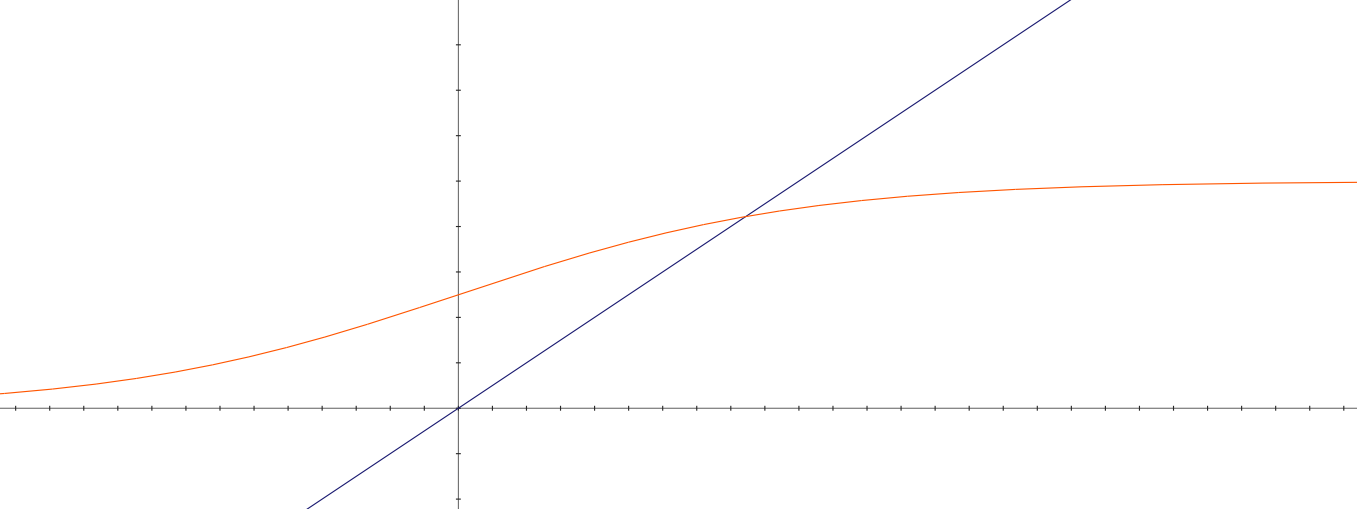
Its possible for the score to behave like the blue line. Getting better and better without bound. Its also possible for the score to behave like the orange line. With some finite value it approaches but never reaches.
60
It may be the deepest thing we understand about NN (but I might got stoned for suggesting we actually know the answer). See lalaithion’s link for one way to see it. My own take is as follow:
First, consider how many n-sphere(s) of radius slightly below 1/2 you can pack in a n-dimensional unit cube. When n is low, « one » is the obvious answer. When n is high, the true answer is different. You can find the demo on internet, and if you’re like me you’ll need some time to accept this strange result. But when you do, you will realize high dimensions means damn big, and that’s the key insight.
Second, consider that training is the same as looking for a n-dimensional point (one dimension for each weight) in a normalized unit cube. Ok, you got it now: gradient-descent (kind of) always work in high dimensions because high dimensions means a damn big number of possible directions and quasi-solutions, so large that by pigeonhole principle you can’t really have dead ends or swamp traps as in low dimensions.
Third, you understand that’s all wrong and you were right from the start: what we thought were solutions frequently present bizarre statistical properties (think adversarial examples) and you need to rethink what generalization means. But that’s for another ref.
20
Partly it might be because it often is not "just" pure gradient descent. There are tweaks to it, like AdaGrad, that are sometimes used? These might be mostly about cost though. Getting to a "good enough answer" as quickly and cheaply as you can tends to be a relevant criteria of "practical success" in practical environments.
20
The quality of a neural network comes from its size, shape, and training data, but not from the training function, which is always simple gradient descent.
Only if you consider modern variants of batch Adam with momentum, regularization, etc to be 'simple gradient descent'.
Regardless SGD techniques are reasonable approximations to bayesian updating with numerous statistical limiting assumptions, which fully explains why they work when they do. (And the specific limiting assumptions in said approximation sufficiently explain the various scenarios when/where SGD notoriously fails - ie handling non-unit variance distributions, etc).
Most of the other possibilities (higher order techniques) trade off computational efficiency for convergence speed or stability, and it just happens that for many economically important workloads any convergence benefits of more complex methods generally aren't worth the extra compute cost; it's instead better to spend that compute on more training or a larger model instead.
I suspect that eventually will change, but only when/if we have non-trivial advances in the relevant efficient GPU codes.
Here's a good related reddit thread on proximal-point based alternatives to gradient methods.
My amateur understanding of neural networks is that they almost always train using stochastic gradient descent. The quality of a neural network comes from its size, shape, and training data, but not from the training function, which is always simple gradient descent.
This is a bit unintuitive to me because gradient descent can only find the minimum of a function if that function is convex, and I wouldn't expect typical ML problems (e.g., "find the dog in this picture" or "continue this writing prompt") to have convex cost functions. So why does gradient descent always work?
One explanation I can think of: it doesn't work if your goal is to find the optimal answer, but we hardly ever want to know the optimal answer, we just want to know a good-enough answer. For example, if a NN is trained to play Go, it doesn't have to find the best move, it just has to find a winning move. Not sure if this explanation makes sense though.