This is a special post for quick takes by lilkim2025. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
Did anyone else just get a "lesswrong.com is asking to access other apps and services on your device" message from their browser when they opened the site? Anyone know what that's about?
This was caused by a post that appeared in the feed having an image in it with a localhost:8000 URL. I'm not sure how the post came to be in that state; it might have been a bug in the new editor. I edited the post in question to remove the broken image.
One way that might happen is if the poster had an image generator (or other web service) running on port 8000 on their own machine, and copied an image URL from it directly into a post.
I wonder how far away we are from 'infinite TV' as a minimum viable product.
I've seen "AI-generated South Park" episodes that, while clearly not great, had coherent plots and passable visuals. The pickleball episode, only three minutes long, had 1.1 million views on X/Twitter before being taken down. It doesn't seem that outlandish to me that you could automate the entire process and have it running 24/7 on Youtube with current or near-future tech.
I'd imagine the setup would look something like this:
- Have an LLM write out a bunch of high-level plots. Use existing text grouping methods to deduplicate generated plots, seeding with summaries of 5-10 randomly selected existing episodes to increase output diversity.
- Postprocess generated plots into storyboards with a second LLM run. These storyboards should try, roughly, to have entries that map 1:1 with brief scenes that can be generated with existing video models, like Sora.
- In a final postprocessing step, with a good prompt outlining common mistakes and useful prompting techniques, have an LLM compile each storyboard segment into a series of API requests to a video generation model.
- Have the video generation model run each prompt 1-3 times, and have the best available vision-language model try to pick the best entry based on some randomly-selected frames from each one, prompting them to identify common AI generation failures.
- Allow this LLM instance to rate all generations as 'bad' and send the prompt back up the chain for rephrasing, or further up the chain to have the plot adjusted to snip out unworkable scenes and replace them with something else.
- Compile the final versions of each scene into a single episode, with hard-coded transitions between scenes[1] specified from a fixed list by the LLM in step 3.
- Leave the generation loop running, add completed episodes to an output queue. When no new episodes are ready, play a rerun that hasn't been played in a while.
Have to figure the first movers would get a decent income out of it. A never-ending stream of short, self-contained, themed video clips would nail down both the extremely young Youtube audience and some older audiences that want background noise.
Doing it with a familiar property lowers the barrier to entry (since lots of people are already invested in the characters) and makes it easier to get consistent character designs/personalities since they're already embedded in the training data, but also raises copyright issues. It'd be a huge controversy among anti-AI people if a major television show went in on this officially, but I think the ad revenue on an endless series of five minute Family Guy episodes of passable "while I'm doing something else" quality would be colossal.
Barring that, it's only a matter of time before some guy with a Git repo provides nostalgic millennials and zoomers with a plug-n-play script to un-cancel their childhood shows, and enterprising individuals start up bootleg streams of the more popular ones. It seems like kids watching endless AI Family Guy episodes on their phones will provoke quite a bit of discussion from the general public, as a culmination of what a lot of trends have been building towards.
- ^
e.g. fade, cut, washout
I'll confess that my model of the state of the AI race isn't very good, and I'm looking to improve it. Anthropic seems to have a commanding lead, with its flagship model, Claude Opus 4.8, generally outpacing competing models by a significant margin and two more secretive models not appearing to have counterparts at competing companies.
China seems to consistently be a few months to a year behind the American companies' most recent models, and the American frontier companies tend to be 1-3 months behind the leader at any given time, but I haven't seen something like Mythos/Fable before, so I'm having a hard time figuring out what it means for the industry. Is its success just a matter of scale, such that OpenAI, Google, or XAI could invest in a much larger model and see similar results, or is there some combination of proprietary knowledge and employee experience at Anthropic that can't be easily replicated?
I know XAI is a bet on horizontal integration with Twitter (as a source of data) and Tesla (as an applications department that can more directly coordinate with AI researchers), so maybe they aren't excessively concerned. What about OpenAI? They used to have an identity as the consumer-facing AI company, but Anthropic might well have already closed the gap there.
As an update to my post on LLMs creating games as a benchmark from around a year ago:
- Lots of Youtubers seem to have agreed that it's a good point of comparison, though their approach has been far from scientific. Rather than providing a prompt and getting a result, they tend to just talk to each model through the chat interface.
- More scientifically, there are now arena.ai - style leaderboards for AI gamedev. The most functional one is provided by designarena, here.
- The agentic gamedev leaderboard is still a little sparse, but shows a wide gap for Anthropic. Even Sonnet outperforms Sol by a substantial margin. Anthropic's RLVR suite for software engineering is, I suspect, substantially better than their competitors in subtle ways that benchmarks generally don't catch.
- HTML, in which agents output a single file, is much more even. Fable and Sol are tied, GLM 5.2 is on the cost-quality frontier, and Chinese models dominate the lower-cost range.
- I'm not intimately familiar with Godot, but Grok and Fable do way better than almost anyone else. I'd suspect this is more due to sparse data than anything else.
- In my own experience, LLMs can oneshot decent prototypes for a lot of things now. Even entirely new concepts that wouldn't have been in the training set. Gone are the days when "build Snake/Winter Bells/tower defense" was the gold standard.
Also, incidentally, I was very surprised to find that the newest OpenAI release, Sol, still performs worse than the demo cited in my original post despite the huge progress made in that timespan. When given the same prompt, on high effort, GPT-5.6 Sol produces an Asteroids clone that is unremarkable even by the standards of Asteroids clones.
{kind=link}
My hot take about crypto is that NFTs (and related things) weren't Beanie Babies for zoomers, they were sports betting for social media clout. Nobody[1] expected their grandchildren to inherit their monkey pictures, and lots of ordinary people really did make lots of money by winning their bets.
It worked almost exactly like Fantasy Football, but with influencers instead of athletes. You saw a guy make a post announcing an NFT, and you quietly estimated how successful they would be at promoting it based on what you knew about them. Once you had a number, if you liked it, you decided on a spread to bet on. A conservative bet of -1/2sd, assuming your initial estimate was on target, was like taking an easy spread at low odds.
There was, of course, an audience participation element[2] that made it more engaging. If you promoted something you bought, you were throwing your own clout into the ring, and your spreads needed to account for the second-order effects of buyers promoting their purchases. A smaller influencer with reliably influential followers might be a 'sleeper pick' compared to a big influencer whose followers are mostly lurkers. You could bet on how cool you were, or how cool your friends were, and get a quantifiable answer, and a lot of the big losses came from people overestimating themselves in this respect.
How well does LLM performance on frontier math benchmarks generalize outside of the sort of tasks that they've been RLVR'd on? For example, could a model, after solving an unsolved Erdős problem, explain its solution to a Math undergrad in a way that is both correct and useful? I know that the original DeepSeek math paper alternated between RLVR and supervised training to prevent the model from drifting into a language that was perfectly fine for generating correct solutions but was not easily human-readable.
I feel like a solid answer here would have broad implications for how well other things picked up in RLVR training carry over[1], and potentially, in the inverse, how well e.g. alignment training will carry over to task behavior that isn't easily human-checkable once superhuman performance has been reached on some narrow, computationally-verifiable task[2].
- ^
For instance, just how much software engineering performance can we get by training LLMs to write code that passes unit tests? Will we hit a brick wall on more subtle aspects of the profession?
- ^
For instance, would a model that's been through RLVR training to let it maximize throughput in service industry settings, when assigned to manage a hospital, rule out solutions that involve discharging a patient that will die if discharged in order to treat additional patients using his hospital bed?
My suspicion that something was weird about one of OpenAI's GPT-5 coding examples[1] seems to be confirmed. It was way better than their model was able to produce over the course of several dozen attempts at replication under a wide variety of configurations.
They've run the same example prompt for their GPT-5.2 release, and their released output is vastly more simplistic than the original. Well in line with what I've observed from GPT-5 and other LLMs.
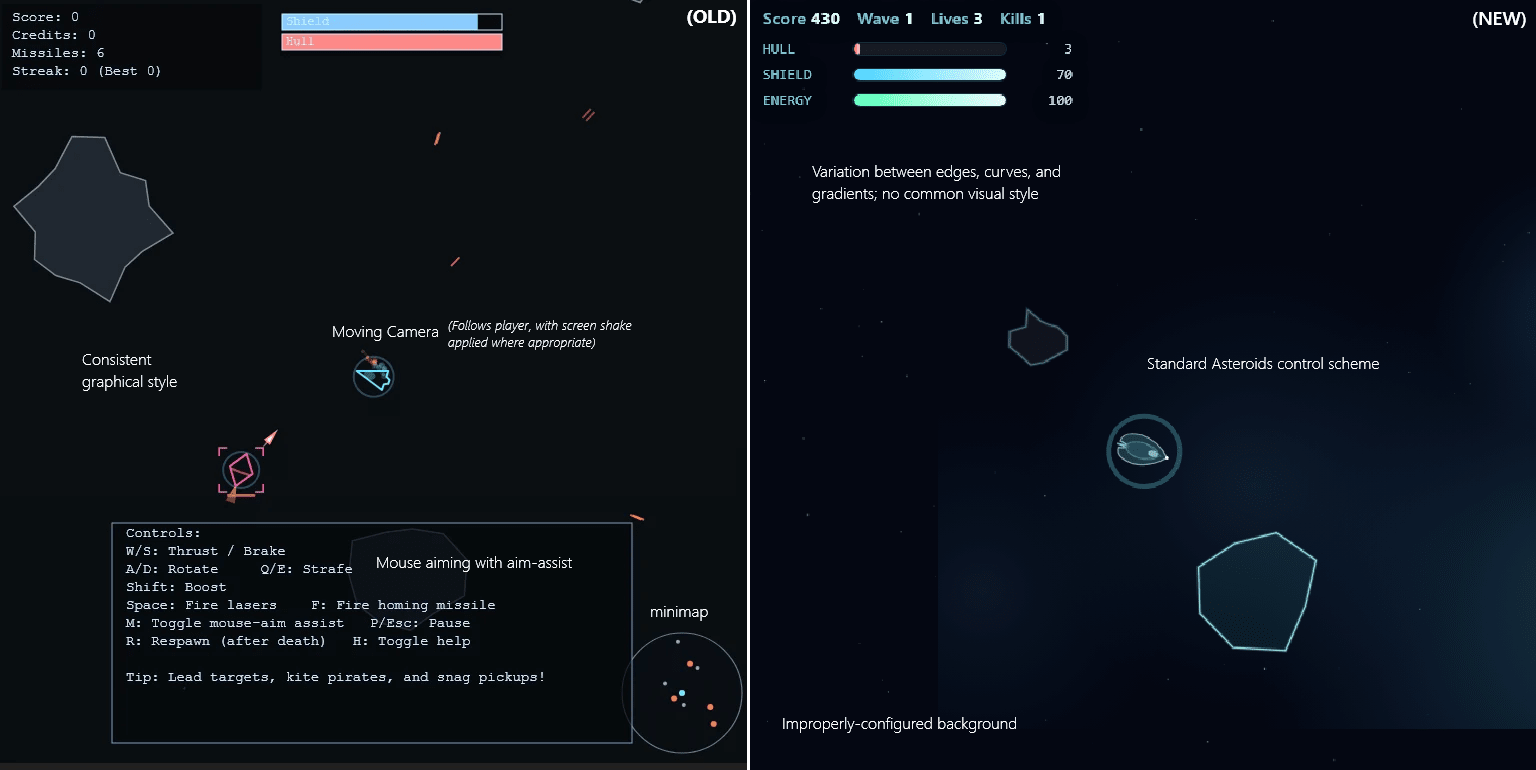
I'd encourage spending 30 seconds trying each example to get a handle on the qualitative difference. The above image doesn't really do it justice.
- ^
See the last section, "A brief tangent about the GPT 5.1 example".
I am genuinely curious about the risk calculus of the remaining 19 percent of firms. Bulk carriers look like the only ones who haven't gone to nearly zero relative to their prior values, indicating that they're a lot less elastic in what they can do, but the fuel costs are, at worst, in the six figures, and the potential losses are well into the eight figure range.
I would not rate the risk of escalation sufficient to sink an unaffiliated cargo ship below one percent, but more than half of bulk carriers appear to have made that decision, relative to tiny fractions of gas carriers and zero percent of chemical tankers. Nearly 100 percent of ships still passing through are heading eastbound, which probably plays some role here.
This graph is from March 1, so I'm sure things have changed since.
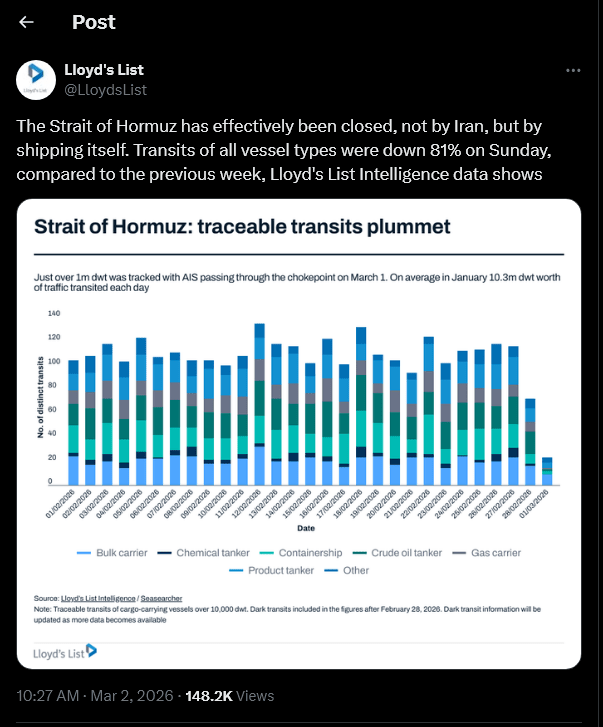
If we trust Al Jazeera, "Vessel tracking service Kpler showed that limited traffic continued in the strait – primarily ships flying the flag of Iran and its major trading partner China – on Sunday". How likely is it that the 19% ships which decided to take the risk were actually Chinese?
To what extent does use of user data for training enable dominance lock-in for AI companies?
The current paradigm seems to be dominated by RLVR - that's when the recent spike in capabilities started, and it makes sense that training LLMs to get to the right answer for complex problems is more useful than training them to speak a certain way (RLHF) or to superficially emulate the training data (pre-RLHF).
Still, user data, properly filtered, strikes me as a powerful source of hard problems to train on, provided you filter for the users who ask the LLM for help on PhD-level research rather than help deciding what to eat for lunch. That data seems entirely exclusive to the companies currently running LLMs that the best researchers are using.
OpenAI wasn't able to lock in its dominance this way, but Anthropic getting in on enterprise coding early seems to have gotten them, in reputation, at least, a decisive advantage on practical coding tasks.
Assuming I woke up with ten billion dollars tomorrow, would I be able to get to parity by [1] scraping respected Github repos with quantitative metrics, booting up AutoResearch, and rewarding runs that improve the metrics, or is entry permanently out of reach to new players?
- ^
(I simplify, of course)
I've been saying for a while that fine-tuning of LLMs amounts to a search through the set of personas already encoded in the base model rather than the development of novel patterns of behavior, which is why things like genetic algorithms work for LLM optimization when you really wouldn't expect them to[1].
Now, I think we have much clearer evidence of this. A 2025 paper showed that, while applying RL to optimize LLMs' performance on programming tasks did result in better results, it did not bring about any behavior that wasn't present in the base model - it just made that behavior more likely than it was before, and made undesired behavior less likely.
- ^
Backpropagation is generally believed to be vital for efficiently optimizing models with very high parameter counts. If LLM fine-tuning effectively works by tweaking a smaller number of emergent 'parameters' that bias the model's priors on the likelihoods that different 'personas' are 'speaking' as it generates text, then that explains why we can get away with using evolution instead.
This appears true at the academic scale, but not at the frontier scale where RL compute consumption is much higher (sometimes even higher that pretraining).
As a counter-example to your evidence, when Nvidia scaled up their RL they found:
Furthermore, Nemotron-Research-Reasoning-Qwen-1.5B offers surprising new insights —RL can indeed discover genuinely new solution pathways entirely absent in base models, when given sufficient training time and applied to novel reasoning tasks. Through comprehensive analysis, we show that our model generates novel insights and performs exceptionally well on tasks with increasingly difficult and out-of-domain tasks, suggesting a genuine expansion of reasoning capabilities beyond its initial training. Most strikingly, we identify many tasks where the base model fails to produce any correct solutions regardless of the amount of sampling, while our RL-trained model achieves 100% pass rates (Figure 4).
That's an interesting paper. I'm not quite up to thinking through the implications in full due to lack of sleep, but demarcating scenarios where fine-tuning clips the existing distribution of behavior versus scenarios where it leads to something new entirely could be a valuable distinction. I wonder what that looks like in terms of network structure.
It would appear that OpenAI is of a similar mind to me in terms of how best to qualitatively demonstrate model capabilities. Their very first capability demonstration in their newest release is this:
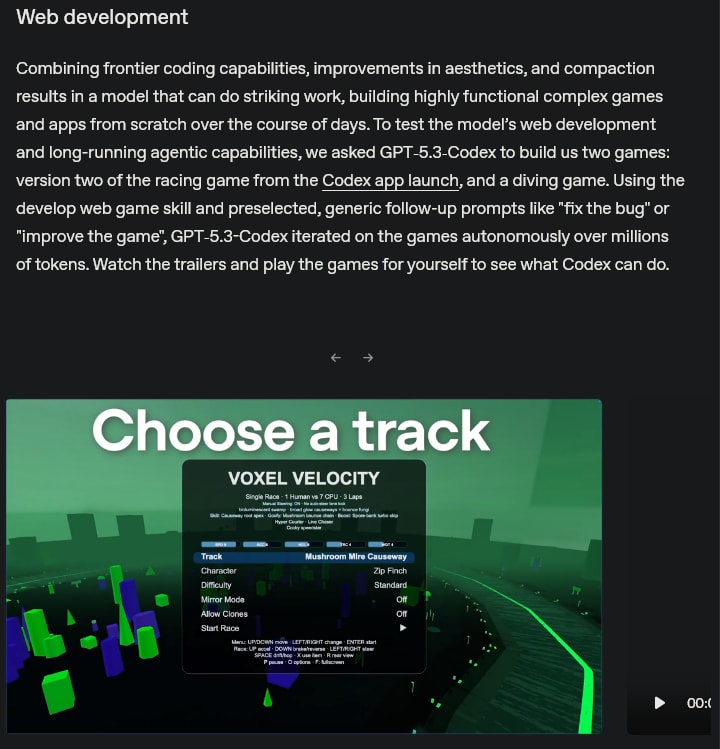
In terms of actual performance on this 'benchmark', I'd say the model's limits come into view. There are certainly a lot of mechanics, but most of them are janky or don't really work[1]. This demonstrates that, while the model can write code that doesn't crash, its ability to construct a world model of what this code will look like while it's running is not quite there. Moreover, there seem to be abortive hints at mechanics that never got finished, like the named 'POIs' in the fishing game, and it feels like each attempt at implementing a feature ignored all of the other features[2].
It is worth noting that there was some manual - though limited - intervention in generating these games, though none of the code or ideas beyond the starting prompt was human. Nonetheless, it does a good job of showing the failure modes of frontier LLMs on projects for which there isn't a template or an easy way of checking their work.
- ^
For example, the powerups and collision mechanics in the racing game rarely do anything, the physics feel off in a dozen odd ways, and plenty of things are rendered in a manner that makes no sense.
- ^
For example, the fishing game features solid 'blocks' in the water, which are drawn as if they're supposed to be the sea floor, with one bumpy side and three flat sides. The LLM later decided it was going to add caves, so every 'wall' of the cave uses the same sprite, and at no point did the model consider that its earlier work needed to be updated.
It seems to me that competent use of even current-gen, non-frontier LLMs[1] could be a totalitarian's wet dream. Things like "heavenbanning" have gone from 'this sci-fi idea might be legitimately frightening in a few years' to 'an MVP that fools most people could be built in a week by a few programmers with limited ethical capacity'. A custom model fine-tuned on a platform's data and red-teamed not to reveal that it's an AI could leave pretty much everyone doubtful of their reality[2].
A state that can guarantee 1:1 links between real identity and website requests can neutralize the latter defense, and an intelligence community that's sufficiently interconnected with each platform can neutralize the former. Plenty of states like this exist today, and more as the world and the internet shift away from what they were in the early 2010's.
- ^
Of the kind that would cost five to six figures to train, even if no open-source models existed - well within reach for unethical small companies, let alone nation-states.
- ^
For now, at least, a clever dissident could challenge 'friends' to link up on another platform, and all the standard "Am I shadowbanned" techniques that any bot farm automatically runs as part of its daily work cycle will work likewise for a human.
Irrespective of everything else, I think the kerfuffle over Anthropic/DOD shows that half-measures are tactically inferior to principled stands.
If Anthropic had come out of the gate with "our product is not a weapon, and we will not pursue any military contracts", they would have vastly more options right now, and much better PR. Instead, they leaned heavily towards the neoconservative position on wars like the one in Eastern Europe, happily working with the U.S. military industrial complex there. Likewise, Amodei's statements about China indicate support for military use in a hypothetical conflict against the PRC. Their own statements begin with some variant of "we are enthusiastic about working with the military".
"I do not want to build weapons" has a lot more public support and legal optionality behind it than "I want a veto against the elected government's monopoly on force", which is the message that the U.S. government and the overwhelming majority of Anthropic's critics appear to have taken from their statements and actions thus far. Whether or not this is their actual position, the fact that many people sincerely believe that this is their position[1] was an entirely preventable outcome.
I should note that this is not a political position that I am taking - maybe you believe that U.S. interventions A and B are just but conflict C isn't. I certainly do. But once you have built something that you identify to the public and to the government as a powerful, dangerous weapon, a binary switch flips, and everyone with an interest in determining who is allowed to control powerful, dangerous weapons has an interest in you. There's no such thing as a halfway crook; the benefits of being a pacifist[2] and the benefits of being a military contractor are mutually exclusive.
Also, in the long run, assuming you accept the notion that the endgame here is some variety of "build God", being willing to participate in killing people in any capacity will vastly decrease the number of people who trust you enough to let you do it. If the "I would never hurt anyone, for any reason" people are on the verge of building God, then even if you don't share their values, you might not be as willing to risk a nuclear war in order to stop them.
- ^
Some people allege insincerity, but as many of Anthropic's strongest supporters have pointed out, this fight is incredibly expensive and inconvenient for the U.S. government. They would not be fighting it if they thought it was avoidable.
- ^
And they exist! A sincere commitment to never involving oneself in matters of war is something many great researchers have successfully made, and it insulates you from all of the power struggles that take place within that domain. There are benefits to being not-a-threat and not-a-prize.
Followed a link to a story from 2015, and the writer somehow predicted the exact writing style of GPT-4o, down to the "not X but Y" pattern.

Both are imitating other sources to pattern-match as "deep." Part of the point of Scott's piece is the inability to verify whether "deepness" has any real substance, or just sounds impressive. 4o just sounds impressive.