Victor Taelin on X is impressed:
this is my personal singularity moment
this post may sound like a paid ad. I only wish. I'm concerned, more so than happy. the world is changing, and, among the scenarios where AI goes terribly wrong, inequality is the most realistic, yet, the one Anthropic seems to be the least concerned about. I'm glad OpenAI is taking the opposite stance: *personal AGI for everyone*. I think this is a commendable position in the times we live. but who am I in the queue of the bread?
anyway, Fable is here, so I'll just report my first-hour experience
first of all, all my pet prompts are solved.
→ λ-calculus puzzles
→ bug questions
→ one-shot apps
all are trivial to it.
I don't have anything harder other than my
ongoing work
so, in the last several days, I've been toying with HVM5, a new interaction net evaluator with a faster loop.
after writing the first version, I left 32 GPT-5 agents working for ~20 hours each. this resulted in up to 2x speedups, but the file size increased by 2-fold and quality decreased significantly.
I then simplified the whole thing into an even simpler core, and left Opus 4.8 and GPT 5.5 optimizing it for 8 hours. Opus got a legit 6% - 34% speedup in most benches. GPT got better results, but, sadly, an unusable file.
I then asked Fable to optimize it.
2 hours later, it landed a 1770% speedup in one case, 100%+ in other 4, and 22% in average. yes, in 2 hours it outperformed me, opus 4.8 and a swarm of gpt 5.5 agents, by one order of magnitude.
that could not possibly be legit. "it must be hardcoding the benchmarks" (GPT trauma). so I read its explanation and what it did was, indeed, the most high impact optimization one could try first. seems like HVM5 was wasting a lot of time garbage-collecting unused branches of pattern-match nodes. I had optimized that for static mats, but not for dynamic mats. skill issue. Fable figured how to do it for these, resulting in a massive speedup in some benches
but wait, is that *correct*? I'm not sure yet, it is credible, but this is the kind of thing that is very easy to get wrong on interaction nets. the problem is, when I was ready to start auditing Fable's solution so I could tell whether it was buggy or legit, it interrupted me to tell me it had found a massive bug on the code *I* had written.
... wait, what?
so... for garbage collection purposes, I stored a bit on lambda term pointers that meant "the variable bound by this lambda has been freed, so, its lambda must free whatever argument it is applied to". that's fine. yet, on duplicator nodes, I also used the same bit to mean "one of the duplicated variables was freed, so, treat this dup as a passthrough no-op". so, if a lambda entered a duplicator, it would mistake the lambda's collection bit for its own, resulting in corrupted interaction!
that's a mouthful, why I'm writing this?
just so you can appreciate the sheer absurdity of what just happened. I didn't ask it to find bugs. I asked it for an optimization. and even if I did ask it to find bugs, this bug is so astonishingly subtle and specific, identifying it takes mastering the domain to an extent that it beyond even me. I'd easily need hours or days to fix it, *if* I ever came across it. chances are it would just go unnoticed. and Fable found it and fixed it like it was nothing, while it was busy adding a 17x speedup to a file that neither I, nor Opus 4.8, nor a fleet of GPT 5.5 managed to barely make 2x faster.
oh and there is also another tab where it is also ripping through Bend's codebase and finishing everything I had to do
I don't know what to say anymore
this isn't about Anthropic or OpenAI, this is about our collective future as a species. the world is changing, and we need to be aware of it, and discuss how to handle this change.
receipt below . . .

I wonder how this restriction will play out for ML researchers. I use Claude a lot for data science, I am not sure how specific these safeguards are, but I think they could plausibly trigger on a lot of data science/model training research.
Thanks for posting this. To ponder how this might affect practitioners, we probably want to consider a larger quotation (page 13 of the system card, currently https://www-cdn.anthropic.com/d00db56fa754a1b115b6dd7cb2e3c342ee809620.pdf, but I think they don't promise keeping this URL).
Unlike their safeguards for cyber, biology, chemistry, and distillation, where a triggered safeguard downgrades the request in question to Claude Opus 4.8 and notifies the user about the downgrade, for this case the treatment is completely different:
Unlike our interventions for cybersecurity, biology and chemistry, and distillation attempts, these safeguards will not be visible to the user. Fable 5 will not fall back to a different model. Instead, the safeguards will limit effectiveness through methods such as prompt modification, steering vectors, or parameter-efficient fine-tuning (PEFT). These interventions will not affect the vast majority of coding work. We estimate they will impact ~0.03% of traffic, concentrated in fewer than 0.1% of organizations. When these interventions are active, we expect them to have minimal behavioral impact on the model except to limit its effectiveness in developing frontier LLMs. Claude will still respond helpfully to user requests. We’ll continue to improve the precision of our detection methods following the launch of this model.
I think it's increasingly important that pressure is put on Anthropic to give 1) early access to models (at least as early as anyone else outside Anthropic is getting them) and 2) models without this restriction to trusted independent safety orgs and researchers.
I haven't ran into any regressions/bad performance doing meta-model interpretability research. It's been an excellent model
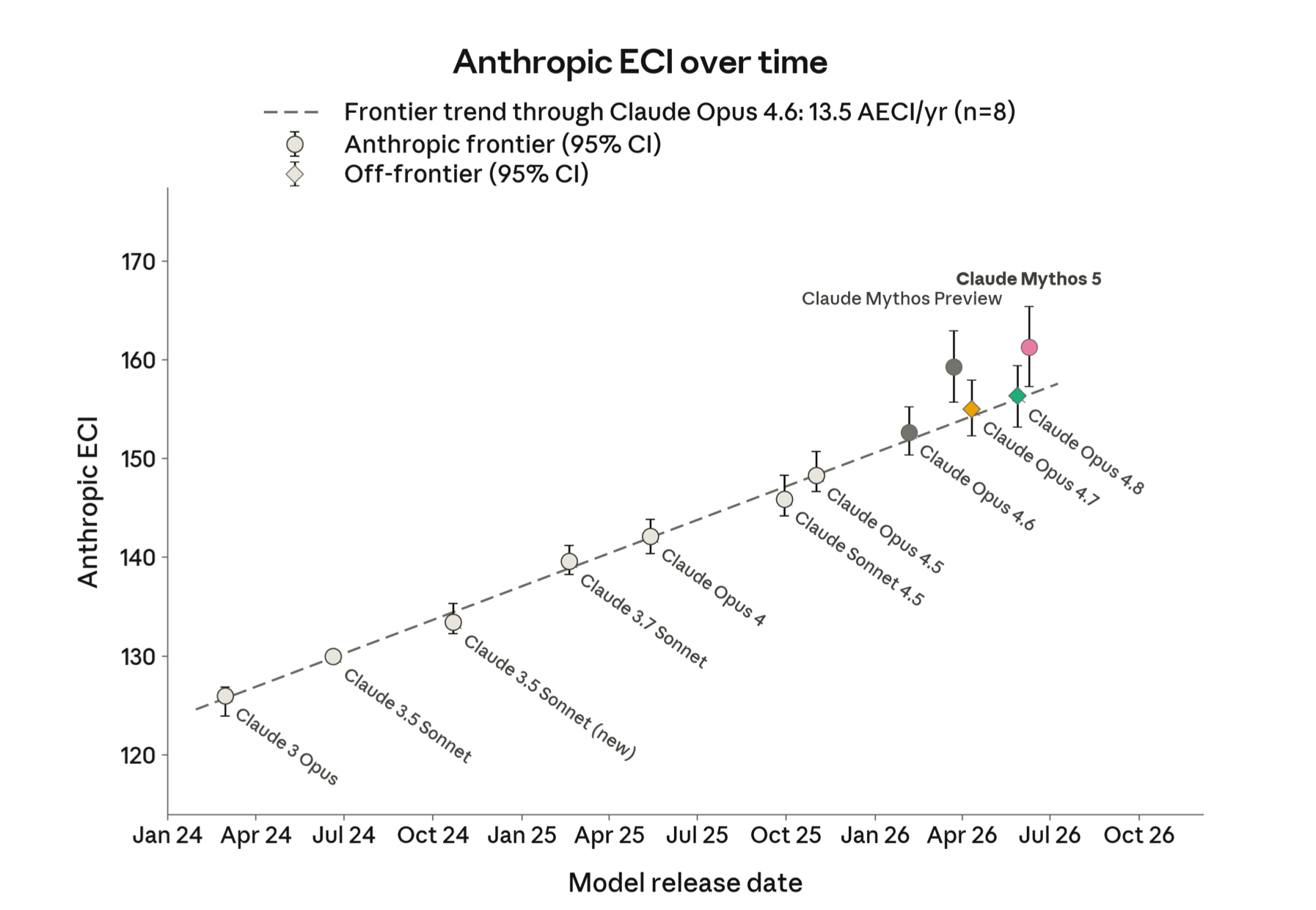
Looks like we are not seeing a further acceleration in the rate of improvement, yet. Suggests the big jump for Mythos preview was the one-off increase in the size of the model?
Not necessarily, I doubt Mythos 5 is drastically different to the preview version- perhaps a bit of RL on top. Data's too coarse regardless to draw conclusions IMO
I think the implication from the pricing is that the main difference is that Mythos 5 is significantly smaller than Mythos Preview.
Or it's a different quant, or the initial pricing included a big surcharge for the lack of anything even roughly comparable at the time (similar to o1, which probably wasn't different in size from 4o or o3 despite almost an OOM cost difference), or they used to objectively lack hardware to serve it and the price reflected that
Besides the cybersecurity stuff, the capability that impresses me the most is being able to beat Pokémon FireRed with vision alone. Though, I almost didn't notice that this isn't Pokémon Red, the game from Claude Plays Pokémon; FireRed is a remake with higher fidelity graphics, which probably makes vision easier.
This is a linkpost for https://www.anthropic.com/news/claude-fable-5-mythos-5