Peter Wildeford: I definitely think the biggest takeaway from this paper is that we likely can’t trust self-reports. This is pretty surprising to me, but is a finding commonly seen in productivity literature
Not just in productivity, this is a finding from so many fields of research that I struggle to find any situation where self report is trustworthy. Yes sometimes it is the best we can do, but that doesn't remove the weaknesses. With that said, I really appreciate the dual research model showing the self report vs actual situation in this case and hope more projects use it going forward.
While I think it is plausible the results would have been different if the devs had had e.g. 100 hours more experience with cursor, it is worth also noting that:
- 14/16 of the devs rated themselves as 'average' or above cursor users at the end of the study
- The METR staff working on the project thought the devs were qualitatively reasonable cursor users (based on screen recordings etc.)
So I think it is unlikely the devs were using cursor in an unusually unskilled way.
The forecasters were told that only 25% of the devs had prior cursor experience (the actual number ended up being 44%), and still predicted substantial speedup, so if there is a steep cursor learning curve here that seems like a fact people didn't expect.
With that all being said the skill ceiling for using AI tools is clearly at least *not being slowed down* (as they could simply not use the AI tools), so it would be reasonable to expect eventually some level of experience would lead to that result.
(I consulted with METR on the stats in the paper, so am quite familiar with it).
I feel like people are dismissing this study out of hand without updating appropriately. If there's at least a chance that this result replicates, that should shift our opinions somewhat.
First, a few reasons why the common counterarguments aren't strong enough to dismiss the study:
- I've been seeing arguments against this result based on vibes or claims that the next generation of LLM's will overturn this result. But that is directly contradicted by the results of this study, people's feelings are poor indicators of actual productivity.
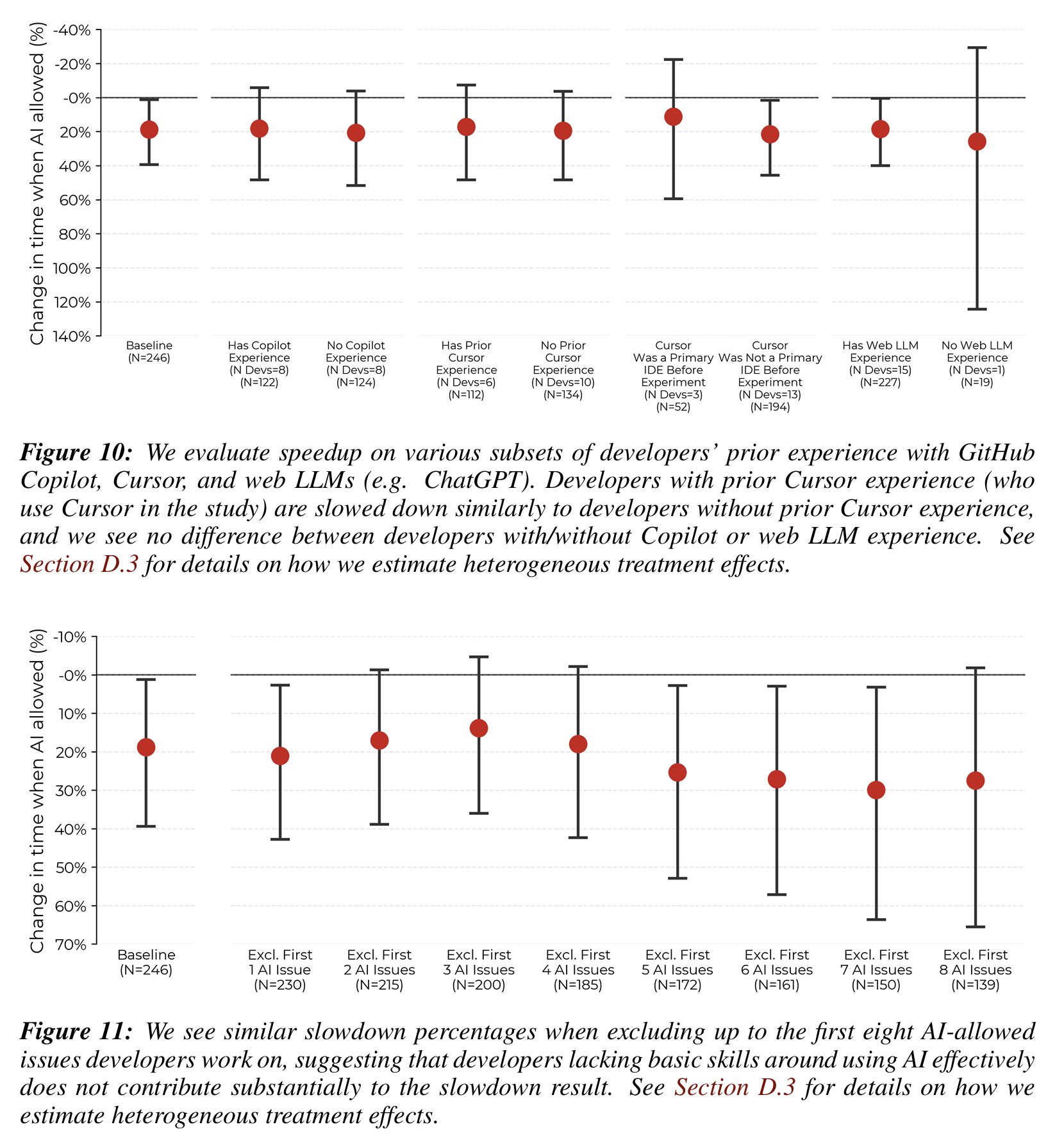
- On Cursor experience, I think Joel Becker had a reasonable response here. Essentially, many of the coders had tried cursor, had some experience with it, and had a lot of experience using LLM's for programming. Is the learning curve really so steep that we shouldn't see them improve over the many tasks? See image below. Perhaps the fact that these programmers don't use it and saw little improvement is a sign that Cursor isn't very helpful.
- While this is a challenging environment for LLM coding tools, this is the sort of environment I want to see improvement in for AI to have a transformative impact on coding. Accelerating experienced devs is where a lot of the value of automating coding will come from.
That aside, how should we change our opinions with regard to the study?
- Getting AI to be useful in a particular domain is tricky, you have to actually run tests and establish good practices.
- Anecdotes about needing discipline to stay on task with coding tools and the cursor learning curve suggest that AI adoption has frictions and requires tacit knowledge to use.
- Coding is one of the cleanest, most data-rich, most LLM-developer-supported domains. As of yet, AI automation is not a slam dunk, even here. Every other domain will require its own iteration, testing, and practice to see a benefit.
- If this holds, the points above slow AI diffusion, particularly when used as a tool for humans. Modelling the impact of current and near-future AI's should take this into account.
An issue I have with this is that it was just *16* developers that they tested this on.
I'd like to see this replicated at a larger scale before coming to conclusions
I am updating towards the possibility of LLM programming not being a speedup, more, for experienced programmers.
I do think, personally, using cursor and other such tools has stagnated my dev skill growth a lot, but it also seems to have allowed me to do a lot of more stuff.
Might try a week without llm assisted coding from tomorrow, see how it goes.
Pay was by the hour so there was large temptation to let the AI cook and otherwise work not so efficiently
this seems pretty important to me. I'd also be interested in seeing this replicated where the pay is per task/issue completed within a given timespan.
METR ran a proper RCT experiment seeing how much access to Cursor (using Sonnet 3.7) would accelerate coders working on their own open source repos.
Everyone surveyed expected a substantial speedup. The developers thought they were being substantially sped up.
Instead, it turned out that using Cursor slowed them down.
That surprised everyone, raising the question of why.
Currently our best guess is this comes down to a combination of two factors:
Thus we should be careful interpreting the result. It was still highly virtuous to run an RCT, and to publish the results even when they were against interest and counterintuitive, and at risk of being quoted endlessly in misleading fashion by AI skeptics. That is how real science works.
Epic Fail
In this case the haters were right, honestly great call by the haters (paper here, blog post here), at least on the headline result.
Again, due to all the circumstances, one should avoid inferring too much. I would like to see the study done again where everyone had at least a few weeks of working full time with such tools, ideally also while working on other types of projects. And a result this surprising means we should be on the lookout for flaws.
The result was still very much surprising to METR, to the developers in the test, to the forecasters, and also to those who saw the results.
The Core Result
In perhaps the most shocking fact of all, developers actually slightly overestimated their required time in the non-AI scenario, I thought that was never how any of this worked?
Okay So That Happened
So now that we have the result, in addition to updating in general, what explains why this situation went unusually poorly?
Here are the paper’s own theories first:
The big disagreement is over the first factor here, as to whether the development environment and associated AI tools should count as familiar in context.
There are several factors that made this situation unusually AI-unfriendly.
AI coding is at its best when it is helping you deal with the unfamiliar, compensate for lack of skill, and when it can be given free reign or you can see what it can do and adapt the task to the tool. Those didn’t apply here.
Or as Joel Becker says, ‘our setting was weird.’
Steve Newman has an excellent analysis of many aspects of this question.
We also have a direct post mortem from Quentin Anthony, who was one of the 16 devs and experienced a 38% speedup when using AI, the best result of all participants. He ascribes others getting poor results in large part to:
All of that is true, but none of it seems like enough to explain the result.
Beginner Mindset
By far the strongest counterargument to the study is to claim the users simply lacked the required experience using this form of AI, so of course they struggled.
Credit to Emmett Shear for being the first one to prominently lay this out fully.
I think Emmett is right that these tools are not similar. The data point that still needs to be explained is (see Table 1 above) the lack of improvement over those 30-50 hours using Cursor. If the learning curve is steep then devs should be improving rapidly over that time. So I can still definitely see this going either way.
Regardless, this was an unusually hostile setting on many fronts, including the lack of experience. The result still is important in general.
Another takeaway worth noting is that self-reports of coding productivity, or productivity gains from AI, cannot be trusted, in general Peter’s thread is excellent.
Overall Takeaways
I am somewhat convinced by Emmett Shear’s explanation. I strongly agree that ‘experience with LLMs’ does not translate cleanly to ‘experience with Cursor’ or with AI coding tools, although experience with other AI IDEs would fully count. And yes, there is a rather steep learning curve.
So I wouldn’t get too excited by all this until we try replication with a group that has a lot more direct experience. It should not be too hard to find such a group.
Certainly I still think AI is a vast productivity enhancer for most coders, and that Opus 4 (or your preferred alternative) is a substantial upgrade over Sonnet 3.7. Also Claude Code seems to be the core of the optimal stack at this point, with Cursor as a secondary tool. This didn’t change my estimates of the ‘normal case’ by that much.
I still think this is a meaningful update. The result was very different than people expected, and participants did not seem to be moving up the learning curve.