I'll have to think through this post more carefully later, but, there's some recent work on approximate abstractions between causal models that I expect you'd be extremely interested by (if you aren't already aware) https://arxiv.org/abs/2207.08603?s=09
Thanks! Starting from the paper you linked, I also found this, which seems extremely related: https://arxiv.org/abs/2103.15758 Will look into those more
Somewhat amusingly, I wrote a paper in 1991 that makes exactly your point. (The linked page at the journal is paywalled, but you can find it if you poke around a bit.)
It was about systems with more than one decomposition into modules, for which there had to be multiple simulations. Those simulations had to be compatible in a certain way, and that led to exactly the commutative diagram you have above (figure 13).
Quick thoughts:
- Why wouldn't this diagram result in a better AI model?
- An obvious generalisation to probability distributions over world states and model states is just to have the distributions commute, right? Is that too strict a criterion?
- Just for context, I'm usually assuming we already have a good AI model and just want to find the dashed arrow (but that doesn't change things too much, I think). As for why this diagram doesn't solve worst-case ELK, the ELK report contains a few paragraphs on that, but I also plan to write more about it soon.
- Yep, the nice thing is that we can write down this commutative diagram in any category,[1] so if we want probabilities, we can just use the category with distributions as objects and Markov kernels as morphisms. I don't think that's too strict, but have admittedly thought less about that setting.
- ^
We do need some error metric to define "approximate" commutativity
Epistemic status: early-stage research ideas; I think they're interesting, but half of them might be wrong
Imagine you're building a robot that can catch a ball by getting observations from a camera and then moving to the correct position. The robot should probably have a predictive model in its head that allows it to tell in advance where it has to move to catch the ball. But which variables should this predictive model contain? Tracking and predicting every single pixel from the camera feed seems unnecessary, but how do you decide which information to throw away?
One thing the robot's model needs is some way of telling whether the robot is catching the ball or not. That's what allows the robot to use its predictive model for the purpose of catching the ball (by checking whether it's successful inside its model if it executes a certain action sequence). So for example, it would be a bad idea to track only the color of the sky—some representation of the ball's position relative to the robot should be included in the model.
But there's a second important point: the model has to track information that allows making correct predictions. For example, the robot could just track whether or not it has caught the ball. But just knowing you haven't caught the ball at timestep t doesn't let you make particularly good predictions about whether you'll have caught it at some later timestep. Somewhat better would be to track the (x,y) coordinates of the ball on the camera feed, as well as the corresponding velocities. This does let you make some useful predictions, but still not very good ones. An even better idea would be to track positions and velocities in three-dimensional space (or alternatively, track the size of the ball in the camera feed as a substitute for the third dimension). Ignoring air, this lets you make perfect predictions about future values of everything you're tracking.
Prediction as a commutative diagram
We've been talking informally about "correct predictions", what exactly does that mean? A key point is that I'm only talking about predicting the next mental state, not the state of the entire world.
Simply not representing things in your mental model is a valid way to get good predictive accuracy under this framework. As a pathological example, the empty model (which doesn't track any variables) makes perfect predictions about everything it tracks. In the framing I'm using here, its only drawback is that it doesn't let the robot know when it has succeeded—it doesn't contain enough information to compute the robot's utility.
Informally, I've said that a mental model is good to the extent to which it allows predicting its own future state (and representing the objective). More formally, we can represent this idea using commutative diagrams of the following form:
Let's break this down:
I'll be quite lax with what we mean by "approximately"—in general, this will depend a lot on what the world state and mental model state are. This post is mainly meant to present conceptual ideas, so I'll just appeal to intuitive notions of what it means for maps to be "approximately" the same in all of the examples.
Examples
Let's look at some more examples of this commutative diagram:
(1) If you want to model celestial mechanics, a good approach is to track the center of mass and its velocity for each body. You can predict how these variables are going to evolve over time pretty well using just the variables themselves. It can also make sense to track only the position and velocity of the body you care about, relative to the body with the biggest gravitational influence (e.g. you can mostly ignore other planets and the sun when predicting how a satellite orbiting close to earth is going to move).
(2) When playing a strategy video game, you'll likely use a mental model consisting of variables like the resources you have, where your and other players' units are, etc. This allows you to make reasonable predictions about how these variables will change (conditioned on specific actions). On the other hand, if your mental model consisted of a small random subset of the pixels on your screen, you would likely be much worse at predicting future values of those pixels.
(3) Suppose you're drawing red, green, and blue balls from an urn without replacement. You know how many balls of each color there are initially, and at each timestep you draw another ball. You can of course only make probabilistic predictions, but you would like those to be as close to optimal as possible. Some good models are:
etc. In each of these cases, you can predict the next state of your mental model just as well as if you had access to the entire true state of the urn. But a bad model would be to track the product of how many blue and how many red balls you've drawn. If this product is currently four, the ideal prediction of the next product is different depending on whether it's e.g. four blue balls and one red ball, or two balls of each color. So if the product is what you care about, you should include additional information in your mental state.
A word on terminology
I've been talking about a "mental model" so far, but I think of that as being basically the same thing as an "ontology" or a "collection of abstractions": they're all maps from the world (or some detailed model) to a less detailed representation, i.e. they're throwing away some of the information while keeping other aspects around. I'll mostly talk about the case where we're mapping from the actual world to a mental model in my examples, but we could just as well map from a strictly more detailed model to a less detailed one.
Going beyond time evolution
In all the examples so far, the "horizontal arrows", i.e. the thing we're trying to predict, was time evolution of some system. But that isn't the only option, so let's discuss an example with a different flavor.
When we want to represent real numbers in a computer, we have to use some kind of abstraction (since we only have finitely many bits, so we need to throw away information). By far the most common one are floating point numbers, where we represent a real number by a few of its most significant digits (the mantissa), multiplied by 2 to the power of the exponent. But what's special about this representation? Why is it a bad abstraction to use e.g. the 1,000th to 1,010th digit after the decimal point to represent a real number?
If the only thing we ever wanted to do with real numbers was adding them, I'd argue that the "1,000th digit representation" is in fact almost as reasonable as using the most significant digits. Our commutative diagram here looks as follows:[1]
On the top, we have addition of real numbers; on the bottom we have addition on only eleven digits (e.g. from the 1,000th to the 1,010th after the decimal point). We can perform addition on such chunks of the decimal expansion the way we'd normally add two numbers (implicitly assuming that later digits are zero). In the worst case, we'll get all the digits wrong (for example, "...99999999999..." + "...00000000000..." could map to all 0's or all 9's, depending on what the later digits are). But this is a fairly rare case, most of the time we'll get most digits right (and some incorrect digits also appear in floating point addition).
However, this doesn't work for multiplication! Digits somewhere in the middle of a product of real numbers are affected a lot by digits in very different positions in the two factors. For example, you get a contribution to the 1,000th digit after the decimal point from multiplying the 10th digit of one number with the 100th of the other, but you also get contributions by multiplying the digit immediately before the decimal point with the 1,000th digit after the decimal point, etc. The only place where this isn't true are the most significant digits: the most significant digits of the product are approximately determined by the most significant digits of the two inputs. That's why an abstraction that's good for multiplying real numbers has to track some number of most significant digits, which leads to floating point numbers.
Why do we need the exponent, instead of only tracking the mantissa? Very simple, without the exponent, we can't make the addition diagram commute. So if we want to be able to do both addition and multiplication, that quite naturally leads to floating point numbers. (Note that they aren't the only option. We could also e.g. track numbers rounded to 2 places after the decimal point, it's just that this requires arbitrarily large amounts of memory for large numbers.)
You could also justify the use of floating point numbers via an implicit "utility function", i.e. by pointing out that for most quantities, we care more about their most significant digits than about what happens a thousand digits behind the decimal point. In my current thinking, this is a consequence of the fact that the most significant digits are a good abstraction for multiplication. In a universe that only ever added numbers, without any multiplication, there's nothing all that special about the leftmost non-zero digits of a number—it would be somewhat surprising to find that we cared specifically about those. In our universe however, multiplication is important in lots of places, so these digits are good abstractions for lots of purposes, which is related to the fact that we evolved to have values defined in terms of this abstraction, rather than some other one. If this sounds too weird to you, fine, but I think it's at least worth observing that we didn't have to appeal to any specific values—assuming addition and multiplication are important was enough to motivate the abstraction of floating point numbers.
What about different levels of abstraction?
Intuitively, ontologies can be more or less fine-grained, i.e. throw away different amounts of information about the system they're modeling. In this framework, we can't quantify that by looking at how good the predictions made by an ontology are. For example, the empty ontology and the complete ontology both make perfect predictions, but are on opposite ends of the spectrum.
What we can do is define a partial ordering on ontologies as follows: given two ontologies f1:X→M1 and f2:X→M2 over some system X, we say that f1 is more fine-grained than f2 iff there is a map τ:M1→M2 such that f2≈τ∘f1. In words, the fine-grained model contains all the information we need for the coarse-grained model.
I think the fact that we only get a partial ordering isn't a limitation of this framework specifically, it's a more fundamental property of ontologies. Two ontologies can track different things such that neither is clearly more "fine-grained" than the other.
Relation to "Information at a distance"
John Wentworth has written a lot about abstractions as information at a distance or equivalently as redundant information. So how is that related to the framework presented here, of abstractions as commutative diagrams? I don't have a very good understanding of this yet, but I'll give my current best guess.
One surface-level difference is that I've been talking about predicting time evolution in a lot of examples, whereas John's examples often focus on predicting far-away information. But the horizontal arrows in the framework I'm discussing can be basically anything, including predicting things that are far away in space (or more generally, in some causal graph), rather than time evolution.
Here's a more important difference: I've discussed good abstractions as maps that make this diagram commute:
Importantly, they only need to enable the prediction of the next mental state. In contrast, John is interested in abstractions that contain all the necessary information to predict things about the actual world. We can encode this with a commutative diagram like this:[2]
Note that the arrow on the right side is now pointing upwards. This means we need to encode all the information necessary to reconstruct the "Next world" state.
For lots horizontal arrows at the top, you won't be able to make this diagram commute unless the mental model encodes the entire world state. But if we focus on horizontal arrows that bridge a wide "distance" (e.g. in some causal graph), where a lot of information is wiped out by noise, then we might be able to get away with only encoding a much smaller summary.
Note that any abstraction for which we can make the second diagram commute, we can also make the first diagram commute. Namely, we can get the dashed "Model → Next model" arrow in the first diagram by going via the dashed "Model → Next model → Next world" arrows in the second diagram, and then using the "Next world → Next model" arrow from the first diagram (i.e. our abstraction).
So any abstraction in terms of the second diagram is also an abstraction in terms of the first diagram; my current take is therefore that John's definition is a stricter version of the one I've been using.
Another difference is how we can attempt to get uniqueness of abstractions. Because John's diagram is more strict, it gives a natural "lower bound" for how much information an abstraction needs to contain. For example, the empty abstraction won't let you predict the next world state (whereas it does make the less strict diagram commute). We can then say we want the minimal abstraction that makes the diagram commute, in order to get a unique one.
I've instead argued that an agent's objective determines the lower bound for useful abstractions: your abstraction at least needs to let you encode enough information to figure out how much you like a given state, otherwise it's useless for planning. Then we can again ask for minimal abstractions that make the diagram commute. I'm not entirely sure yet if/under which circumstances these will be unique (given that we only have a partial ordering).
I won't go into much detail about the advantages of each framework, mostly because I haven't thought about that a lot. But here are my current takes:
Relation to ontology identification
One of my motivations for thinking about what ontologies are is ontology identification/ELK. Given two ontologies f1:X→M1 and f2:X→M2 on the same base space X (the "true world" in the diagrams), we can define an ontology translation from M1 to M2 as a map τ:M1→M2.
In the context of AI safety, I'm mainly interested in an ontology translation from MAI to Mhuman (though e.g. model splintering also seems related). See the ELK report or How are you dealing with ontology identification? if you want a refresher on why this translation in particular seems important.
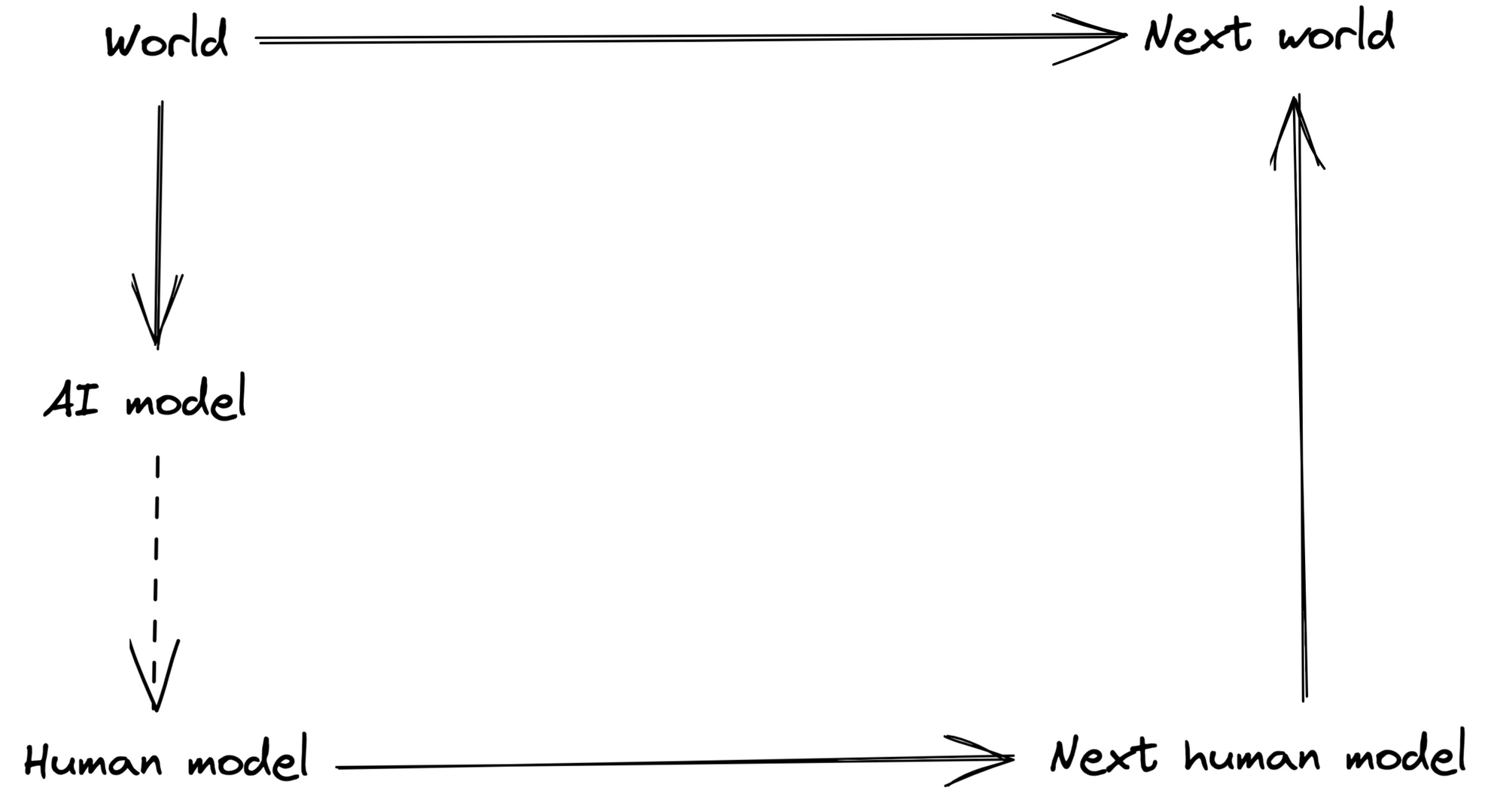
The question is: which map τ do we want? A first guess might be that we want to make the following diagram commute, where τ is the horizontal arrow at the bottom:
In our notation, this would mean fhuman=τ∘fAI. The issue is that this doesn't let us out-perform humans. In the terminology of the ELK report, it's the human simulator; it just predicts what humans would think given the AI's observations. We can also frame this in terms of commutative diagrams: the human ontology only kind of commutes with time evolution; our model of the world isn't that great. We'd like to use the AI's model to improve our own knowledge of what's going on, in the sense of getting a diagram that commutes better.
Given that we can express the human simulator as a very simple commutative diagram, maybe the same thing works for the direct translator, i.e. the map τ that in some sense "correctly" translates the AI's knowledge into the human ontology? Unfortunately, I don't think this immediately yields a new ELK proposal, but it's still instructive to look at potential commutative diagrams we could use. Here's the diagram containing all the arrows that are available to us:
The outer rectangle is the time evolution commutative diagram for the human ontology. The inner top tetragon is the analogous diagram for the AI ontology. We're looking for dashed arrows τ (where both arrows are the same function). To be clear, we don't want this entire diagram to commute. In fact, we know it doesn't commute all that well; the outer rectangle is precisely the human ontology diagram that we're trying to improve upon.
What we can do is consider different subdiagrams and demand that they commute. Picking the triangles on the left or right side would give us the human simulator diagram from above, which we don't want. We could also consider the subdiagram consisting only of the AI and human models:
This is essentially an earlier ELK proposal by Scott Viteri. One reason it doesn't solve ELK is that the ontology translation can just "simulate" a world that's easy to predict under the human model, which doesn't necessarily have anything to do with the actual world. We can fix this by instead using the following subdiagram:
Here, the translation is chosen such that it allows humans to make good predictions, i.e. to improve the commutativity of the human diagram. This is basically equivalent to my understanding of the imitative generalization proposal for ELK, as discussed in the ELK report.
There are a few more subdiagrams we could look at, but I think they are all variations on these three basic ideas (human simulator, Scott Viteri's proposal, imitative generalization). Nevertheless, I think it's interesting that this framework quite naturally reproduces the imitative generalization approach (I first wrote down the diagram above before noticing the correspondence).
To be clear, I'm quite skeptical that simple extensions of this framework will just let us write down a commutative diagram for the direct translator. It feels like some important structure is still missing.
Conclusion
Summary
I proposed that we think of good ontologies/abstractions as maps that enable specific commutative diagrams, where the other arrow is whatever operation we want to use the ontology for (e.g. predicting time evolution). This idea can be applied very generally, e.g. to high-level representations of physical systems, but also to floating point numbers as a good abstraction for real numbers. I think it produces similar abstractions as John Wentworth's "information at a distance" definition, but there are some important conceptual differences between the two frameworks. Finally, I'm hoping this approach could also generate ELK proposals at some point, though that's more speculative.
Next steps
I started thinking about this very recently, so my plans are changing quite quickly. My main reason for writing this post is to get early feedback both on the overall idea and on potential next steps. Here are some questions that currently feel exciting to me:
I'd highly appreciate feedback on any part of these plans!
Thanks to Simon Skade, Scott Viteri, and John Wentworth for helpful conversations.
This is technically a bit different from the previous commutative diagram because we have M×M as the abstraction map on the LHS, rather than just M (in fact, we can't have the same map both times since these are different spaces). But using M×M (as opposed to some other map) is essentially forced if we want to compose computations (i.e. use the result of one addition as the input of another. So we're still only really choosing a single abstraction M.
Thanks to John for making this crisp in a conversation, though I'm presenting my own understanding of the difference here and I'm not entirely sure he'd agree with everything.