My cached state is that the A/H100 vs 4090 price gap is mostly price discrimination rather than a large difference in the actual manufacturing cost.
I think price discrimination is very common in computing hardware and nvidia happens to have a quite powerful monopoly right now for various reasons.
Note that 4090s technically can't be used in data centers with cuda due to licensing which makes this a particularly effective approach to price discrimination.
So, it's true that NVIDIA probably has very high markup on their ML GPUs. I discuss this a bit in the NVIDIA's Monopoly section, but I'll add a bit more detail here.
All this aside, my basic take is that I think "what people are actually paying" is the most straightforward and least speculative means we have of defining near term "cost".
Promoted to curated: I was definitely hesitant to promote visibility of this post much more, since I do think the knowledge in this post is largely about how to make more dangerous AI, and I would like there to be less dangerous AI. However, I do think that almost all the actors that are most likely to cause harm with this information almost certainly already have this information.
The key exception are maybe governments, which I feel confused about, since I do think them being better informed about model training helps with regulation, but maybe it will also allow them to pump more money into AI and accelerate the arms race, and that would be sad.
Overall, I think the benefits outweighed the cost here, since I do think it's a quite well-written post, and it gave me a bunch of useful abstractions on how to think about model training, as someone who hasn't done this very much, and I do think that will help me and others handle AGI stuff better.
I'm quite curious about the possibility of frontier model training costs dropping, as a result of technological advancements in hardware. In the event that its possible, how long might it take for the advancements to be adopted by large-scale AI labs?
For future posts, I'd want to see more of the specifics of ML GPUs , and the rising alternatives (e.g. companies working on hardware, research, lab partnerships, etc.) that might make it faster and cheaper to train large models.
Note that these numbers are much higher than than the approx 60 million dollars[2] it would cost to rent all the hardware required for the duration of the final training run of GPT-4 if one were willing to commit to renting the hardware for a duration much longer than training, as is likely common for large AI labs. I think that the methodology I use better tracks the amount of investment needed to produce a frontier model. As a sanity check
Can you say more about your methodological choices here? I don't think I buy it.
My "sanity check" says, you are estimating the total cost of training compute at ~7x the cost of the final training run compute, that seems wild?! 2x, sure, 3x, sure maybe, but spending 6/7 = 86% of your compute on testing before your final run does seem like a lot.
It seems pretty reasonable to use the cost of buying the GPUs outright instead of renting them, due to the lifecycle thing you mention. But then you also have to price in the other value the company is getting out of the GPUs, notably now their inference costs are made up only of operating costs. Or like, maybe OpenAI buys 25k A100s for a total of 375m. Maybe they plan on using them for 18 months total, they spend the first 6 months doing testing, 3 months on training, and then the last 9 months on inference. The cost for the whole training process should then only be considered 375m/2 = $188m (plus operating costs).
If you want to think of long-term rentals as mortgages, which again seems reasonable, you then have to factor in that the hardware isn't being used only for one training cycle. It could be used for training multiple generations of models (e.g., this leak says many of the chips used for GPT-3 were also used for GPT-4 training), for running inference, or renting out to other companies when you don't have a use for it.
I could be missing something, and I'm definitely not confident about any of this.
This is probably the decision I make I am the least confident in, figuring out how to do accounting on this issue is challenging and depends a lot on what one is going to use the "cost" of a training run to reason about. Some questions I had in mind when thinking about cost:
The simple initial way I use to compute cost than is to investigate empirical evidence of the expenditures of companies and investment.
Now, these numbers aren't the same ones a company might care about - they represent expenses without accounting for likely revenue. The argument I find most tempting is that one should look at deprecation cost instead of capital expenditure, effectively subtracting the expected resale value of the hardware from the initial expenditure to purchase the hardware. I have two main reasons for not using this:
Having said all of this, I'm still not confident I made the right call here.
Also, I am relatively confident GPT-4 was trained only with A100s, and did not use any V100s as the colab notebook you linked speculates. I expect that GPT-3, GPT-4, and GPT-5 will all be trained with different generations of GPUs.
Speaking as someone who has had to manage multi-million dollar cloud budgets (though not in an AI / ML context), I agree that this is hard.
As you note, there are many ways to think about the cost of a given number of GPU-hours. No one approach is "correct", as it depends heavily on circumstances. But we can narrow it down a bit: I would suggest that the cost is always substantially higher than the theoretical optimum one might get by taking the raw GPU cost and applying a depreciation factor.
As soon as you try to start optimizing costs – say, by reselling your GPUs after training is complete, or reusing training GPUs for inference – you run into enormous challenges. For example:
The closest you can come to the theoretical optimum is if you are willing to scale your workload to the available hardware, i.e. you buy a bunch of GPUs (or lease them at a three-year-commitment rate) and then scale your training runs to precisely utilize the GPUs you bought. In theory, you are then getting your GPU-hours at the naive "hardware cost divided by depreciation period" rate. However, you are now allowing your hardware capacity to dictate your R&D schedule, which is its own implicit cost – you may be paying an opportunity cost by training more slowly than you'd like, or you may be performing unnecessary training runs just to soak up the hardware.
Very informative. You ignore inference in your cost breakdown, saying:
Other possible costs, such as providing ChatGPT for free, would have been much smaller.
But Semianalysis says: "More importantly, inference costs far exceed training costs when deploying a model at any reasonable scale. In fact, the costs to inference ChatGPT exceed the training costs on a weekly basis." Why the discrepancy?
This is because I'm specifically talking about 2022, and ChatGPT was only released at the very end of 2022, and GPT-4 wasn't released until 2023.
In fact, the costs to inference ChatGPT exceed the training costs on a weekly basis
That seems quite wild, if the training cost was 50M$, then the inference cost for a year would be 2.5B$.
The inference cost dominating the cost seems to depend on how you split the cost of building the supercomputer (buying the GPUs).
If you include the cost of building the supercomputer into the training cost, then the inference cost (without the cost of building the computer) looks cheap. If you split the building cost between training and inference in proportion to the "use time", then the inference cost would dominate.
Since OpenAI are renting MSFT compute for both training and inference..
Seems reasonable to think that inference >> training. Am I right?
I'm not seeing anything here about the costs of data collection (for licenced stuff) or curation (probably hundreds of thousands of cheap hours?), apart from one bullet on OAI's combined costs. As a total outsider I would guess this could move your estimates by 20-100%.
I talk about this in the Granular Analysis subsection, but I'll elaborate a bit here.
However, over the past several years progress has been made on utilizing fewer bits per number (also called lower precision) representations in machine learning. On the best ML hardware, this can lead to a 30x difference in processing power
I think this isn't the best phrasing to convey the thing. The 30x difference is comparing Peak FP32 with Peak FP8 Tensor Core. But given the previous sentence implies you're focusing on precision differences, the comparison should be Peak FP32 Tensor Core to Peak FP8 Tensor Core, which is only 4x. The non-sparsity numbers from Table 1 for NVIDIA H100 SXM5:
I think this is a nitpick, but it threw me off so I figured I would say something. The point stands that "FLOPs" often leaves out important details, but it doesn't seem like lower precision explains >10x the difference here.
Good catch, I think the 30x came from including the advantage given by tensor cores at all and not just lower precision data types.
Are these 2 bullet points faithful to your conclusion?
And some hot takes (mine):
I think using the term"training run" in that first bullet point is misleading, and "renting the compute" is confusing since you can't actually rent the compute just by having $60M, you likely need to have a multi-year contract.
I can't tell if you're attributing the hot takes to me? I do not endorse them.
This is very impressive work, well done! Improving compute/training literacy of the community is very valuable IMO, since I have often thought that not knowing much of this leads to poorer conclusions.
The LessWrong Review runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
Is there a cheap of free way to read Semianalysis posts?
Cant afford the $500 subscription sadly
Understanding what drives the rising capabilities of AI is important for those who work to forecast, regulate, or ensure the safety of AI. Regulations on the export of powerful GPUs need to be informed by understanding of how these GPUs are used, forecasts need to be informed by bottlenecks, and safety needs to be informed by an understanding of how the models of the future might be trained. A clearer understanding would enable policy makers to target regulations in such a way that they are difficult for companies to circumvent with only technically compliant GPUs, forecasters to avoid focus on unreliable metrics, and technical research working on mitigating the downsides of AI to understand what data models might be trained on.
This doc is built from a collection of smaller docs I wrote on a bunch of different aspects of frontier model training I consider important. I hope for people to be able to use this document as a collection of resources, to draw from it the information they find important and inform their own models.
I do not expect this doc to have a substantial impact on any serious AI labs capabilities efforts - I think my conclusions are largely discoverable in the process of attempting to scale AIs or for substantially less money than a serious such attempt would cost. Additionally I expect major labs already know many of the things in this report.
Acknowledgements
I’d like to thank the following people for their feedback, advice, and discussion:
Index
Cost Breakdown of ML Training
Estimates the costs of training a frontier (state of the art) model, drawing on leaks and analysis. Power usage is a small portion of the cost, GPUs are likely a slim majority.
Why ML GPUs Cost So Much
ML GPUs are expensive largely because of their communication and memory capabilities - not because of their processing power. NVIDIA’s best gaming GPU provides greater ML processing power than the GPU used to train GPT-4, for only a tenth the price. Note that NVIDIA’s near monopoly plausibly explains some of the price differential.
Contra FLOPs
Argues that the most common metric of ML computing power - floating point operations - is flawed, due to the rise of different types of floating point numbers making standardization difficult and the cost of processing power representing a small portion of the cost of ML.
ML Parallelism
An overview of ML parallelism techniques, showing how the common notion that “ML is embarrassingly parallel” is simplistic and breaks down at large scales - where any simple method of parallelizing a model starts to hit bottlenecks as the capabilities of individual devices become bottlenecks regardless of the number of devices involved.
We (Probably) Won’t Run Out of Data
There are many routes toward preventing data from becoming a major bottleneck to ML scaling, though it’s not certain any of them enable scaling as fast as has occurred historically.
AI Energy Use and Heat Signatures
ML energy usage may become important in the near future, even if it’s a relatively minor concern for frontier model training right now. If current trends continue, energy usage could limit scaling, determine major engineering challenges, and provide a novel approach to surveillance of training runs using satellites and multispectral photography.
Cost Breakdown of ML Training
This section is an attempt to estimate the amount of costs associated with training a state of the art ML model, specifically in terms of the amount of capital that is required. It’s not a detailed forecasting attempt, but instead is meant to serve as a default source for anyone who wants to know the basics - such as whether power usage is a major expense right now (it’s not) or whether GPUs account for the majority of the cost (probably, but only a slim majority). I hope this helps people prioritize their research agendas and serves as a jumping off point.
Note that I focus specifically on what it takes to train a model that is competitive with the best models at the time of its release. As of now GPT-4 is the only publicly acknowledged model in this class and so I will pay special attention to it, though I also use leaks about forthcoming frontier models to augment my analysis[1].
In this section I’ll be breaking down what I think this money is actually being spent on, and how we might expect this to evolve over time. I’m not going to be doing specific forecasting here, though I hope this can serve as a guideline to those who do. Additionally I hope this is useful for policy makers analyzing how to most effectively regulate training runs by demonstrating what parts of training are most expensive. A few major takeaways:
Defining “Cost”
I define the cost of a frontier model as the amount of money a company needs to spend to create a frontier model. In practice I use the following formula:
Cost = Hardware Cost + Operating Expenditures During Creation
Where “Hardware Cost” refers to the cost of purchasing all the hardware necessary for the training run, and the “Operating Expenditures During Creation” refers to the sum of the amount of money spent on energy, salaries, maintenance, and other operating expenses during the time the model is designed and trained (I think one year is a good upper bound on this time period).
Most analysts differ from me on this, using the cost of renting GPUs for the training run based on prices that require multi-year commitments that continue after the model has been created. These commitments effectively span the lifetime of the hardware, and so I believe are better thought of as mortgages than as rentals, as the end result of a mortgage is that the provider no longer owns an object of value, whereas the end result of renting for the same period is that the provider owns an item of similar value to what they started with.
Another thing to note here is that I do not factor in the cost of electricity beyond the period during which the model is created, so the lifetime electricity cost of a GPU would be a larger proportion of the cost of that GPU than the electricity cost I consider.
Total Cost Estimate
My preferred way to estimate the total cost of a frontier model is to base the estimate on public information on spending and investment, using a bottom-up component analysis to sanity check the estimate. Based on this approach, I estimate that GPT-4 cost half a billion dollars and near future frontier models will cost on the order of a billion. This is based on the following evidence:
Note that these numbers are much higher than than the approx 60 million dollars[2] it would cost to rent all the hardware required for the duration of the final training run of GPT-4 if one were willing to commit to renting the hardware for a duration much longer than training, as is likely common for large AI labs. I think that the methodology I use better tracks the amount of investment needed to produce a frontier model. As a sanity check, rough math gives a 500 million dollar estimate for the cost of the hardware needed to train GPT-4[3], which lines up well with the empirical evidence of spending and investment by OpenAI.
Granular Analysis
In order to break down the cost of a training run into individual components, we’ll need to go beyond the bottom line spending numbers and utilize more detailed information about how the training run worked, and what costs it likely involved. This necessarily requires a greater number of assumptions and uncertainties but there’s enough information available to make reasonable guesses about the relative costs of various components of a frontier model.
I started estimating the proportions of the costs of training an ML model like GPT-4 with this leaked info on OpenAI’s spending in 2022:
“[OpenAI] was projecting expenses [for 2022] of $416.45 million on computing and data, $89.31 million on staff, and $38.75 million in unspecified other operating expenses.”
While these numbers aren’t specifically about GPT-4, I consider it a reasonable baseline for the proportions of the cost. Other possible costs, such as providing ChatGPT for free, would have been much smaller. I removed the “unspecified” section since it was small and I do not see an obvious means for it to be relevant to GPT-4.
Next, I broke down the computing and data number. I removed data entirely since I doubt data was a significant factor in costs, with this article mentioning one plausible data expense being only $200k[4]. This post suggests that computing could be broken down into hardware, power, and system administration. System admin seemed small enough that I ignored it entirely. I broke out power using about $0.05/kWh as a base price for cheap power and estimating power draw using a variety sources, each giving me fairly similar answers[5].
Note that other accounting methodologies focused on the cost of renting hardware imply that operating costs such as power usage costs are a higher portion of the cost than the methodology I use implies. This is because operating costs are similar across these methodologies (the operating expenses for the period of time during use) but the renting methodology provides a lower total cost. The total cost of owning the hardware across the lifetime of the hardware has similarly higher proportional operating costs.
Hardware Cost Breakdown
With hardware (for an ML supercomputer) making up such a significant portion of the frontier model cost, it’s worthwhile to break it down further. My best guess is that in the best GPU-based ML supercomputers right now, GPUs account for around 70% of the cost, though I consider anywhere from 50% to 85% to be plausible. Most of the remainder of the cost is networking hardware to allow fast and robust communication between GPUs.
I arrived at my 70% estimate by combining two different methods:
Combining the node cost breakdown from Semianalysis and the 20% interconnect rule of thumb from Next Platform, we find that GPUs are 70% of the hardware cost[6].
Note that this number can fluctuate over time - for supercomputers with more GPUs the cost of coordinating the GPUs and their communication with each other grows substantially, as well as the necessity of robustness to GPU failures. As a result, larger clusters have to spend more on hardware to enable fast and robust communication between devices as well as hardware for checkpointing of intermediate results.
The reason why communication is so expensive at this scale is a bit subtle, but it’s related to the fact that as one increases the number of devices in a network the number of possible connections between devices grows quadratically. This can be dealt with using sophisticated routing techniques, but those techniques still grow in complexity and cost as the number devices increases.
GPU Costs
This is discussed in greater detail in Why ML GPUs Cost So Much.
Delving further into the hardware costs, I’d like to briefly remark on the cost of ML GPUs. A lot of the cost of ML GPUs is a result of the communication capabilities they require, similar to the importance of communication for non-GPU hardware. Memory plays a significant role as well, both the communication aspects of memory (memory bandwidth within a single chip) and the total quantity of high bandwidth memory on each chip. Additionally, scarcity and NVIDIA’s dominance in ML GPUs may be significant factors driving prices. This could change in the next few years, resulting in a drop in GPU prices as competition and production increases.
Why ML GPUs Cost So Much
ML GPUs make up the single largest component of frontier model training, so it’s useful to understand why they cost as much as they do. Often analysis focuses on the processing power (measured in operations per second) provided by ML GPUs like the ~$15,000 A100 GPU likely used to train GPT-4. However, NVIDIA’s best gaming GPU provides greater ML processing power for about a tenth the price of the A100. The main factors distinguishing the best GPUs for ML from other devices are the exceptional memory and communication capabilities of state of the art ML GPUs.
Before we get into how relevant different aspects of ML GPUs are to price, a quick overview of the specs of an ML GPU:
As an illustrative example of the importance of these properties, the table below compares the GPU used to train GPT-4, the A100 and the H100 (a state of the art ML GPU and successor to the A100), with the RTX 4090 (NVIDIA’s best gaming GPU). Note that there are different types of FLOPs (or TOPs); here I used the ones best for training, but also include the numbers the A100 would likely have had if it had the features the newer GPUs have.
624 TOP/s
(312 TFLOP/s if int8 training isn’t possible)
$24.04
($48.08 if int8 training isn’t possible)
In the above table, ML processing power explains little of the price differential, same with energy usage. I bolded memory size, memory bandwidth, and interconnect bandwidth as they better track price. Memory size and memory bandwidth have a joint impact on price - faster memory costs more per byte[14].
I’d like to note the importance of the two specifications related to the communication of data: memory bandwidth and interconnect bandwidth. These specs may become more important over time, as processing power provided by hardware grows faster than memory or interconnect bandwidth. This is in part because the process of making smaller and smaller transistors powers the growth of processing power and memory but not bandwidth. As a result of this, it is unclear whether bandwidth scaling will run out when Moore’s law runs out, as the components relevant to communication are often substantially larger than those relevant to compute and memory and the bottlenecks are different, meaning that they may hit physical limitations later.
For an illustration of growth over time, see the chart below, where HW FLOPS refers to processing power, DRAM BW refers to memory bandwidth, and Interconnect[15] BW refers to communication speed between GPUs.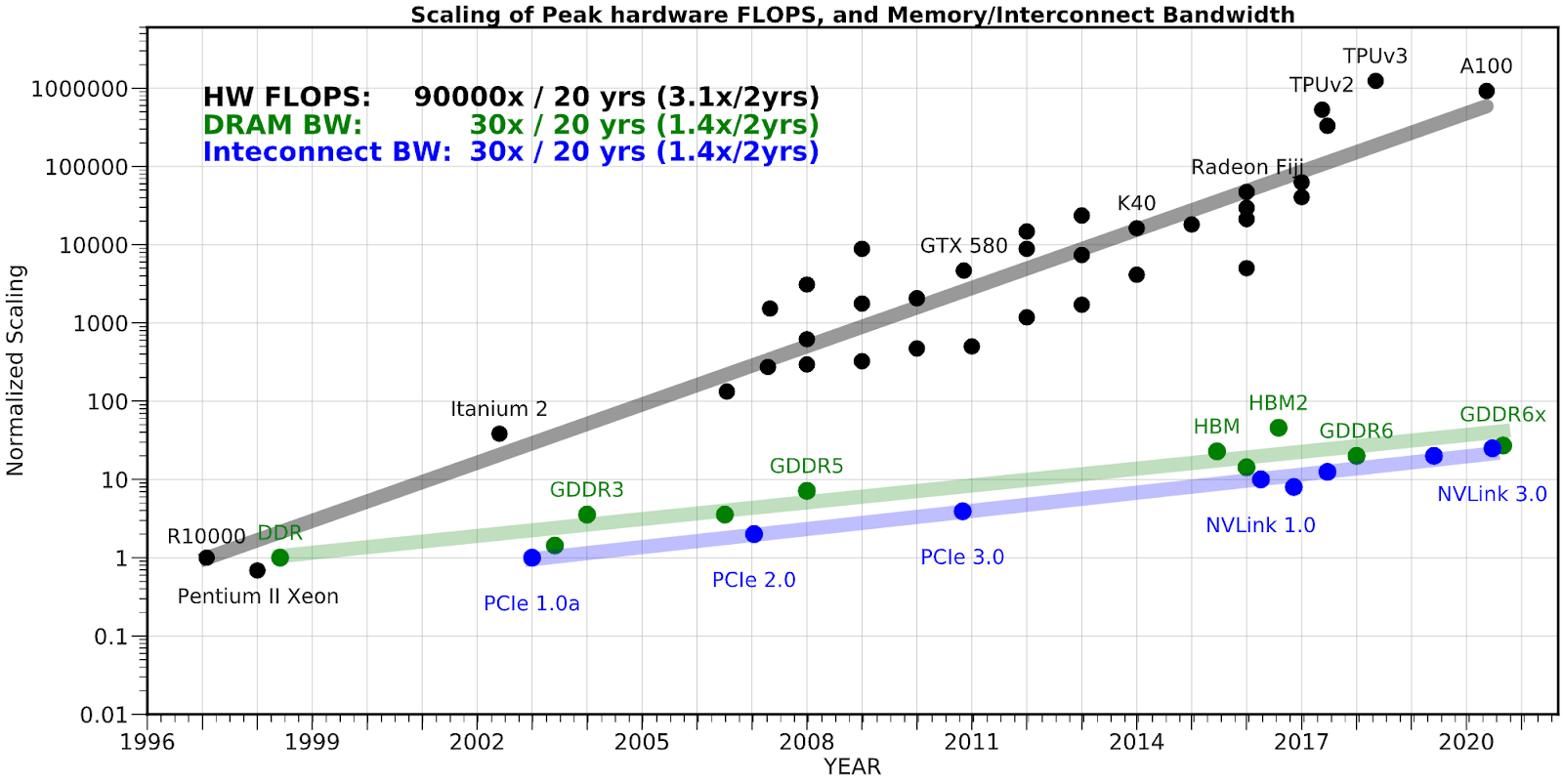
Source: https://medium.com/riselab/ai-and-memory-wall-2cb4265cb0b8
Note that the amount of communication needed per FLOP isn’t necessarily constant, so this difference in growth won’t inevitably result in interconnect being a bottleneck - it’s just useful for understanding how communication is something that needs to be dealt with and optimized around.
NVIDIA’s Monopoly
NVIDIA has plausibly had a monopoly on the best GPUs with the H100 surpassing competitors, though Google may be a serious competitor[16]. Some have reported that they charge very high margins (5x manufacturing costs) on their GPUs as a result, though I think it plausible that this is mostly due to high demand given their supply, and that they are increasing supply rapidly in order to meet demand. My best guess is that prices may decrease due to increased competition and supply in the next few years, but memory and bandwidth will still be a bigger factor than flops, at least in the near future.
Contra FLOPs
Floating point operations (FLOPs) are often used as a metric for processing power in ML - to forecast the future of AI[17], [18] and to regulate the export of powerful hardware in the present. However, I believe that recent developments in ML hardware and scaling have rendered FLOPs ill-defined and less reliable a metric in the present environment than many assume.
Different Types of FLOPs
Floating point numbers are represented internally as a sequence of bits. Traditionally, 32 bits were used as a standard - Single-Precision Floating-Point numbers (FP32 - the 32 standing for 32 bits). This format is the most common one discussed, with double-precision (FP64) being the next most common. However, over the past several years progress has been made on utilizing fewer bits per number (also called lower precision) representations in machine learning. On the best ML hardware, optimizations including this can lead to a 30x difference in processing power between traditional Single-Precision FLOPs and the most ML training optimized operations[19].
It is unclear to me whether FLOPs will become substantially more specialized than they are now. The precision of the floating point numbers can only go down so far, and the required experimentation and the changing architectures of frontier (state of the art) models make extreme specialization of hardware potentially difficult on the timescales involved.
FLOP Costs Are Not Everything
While FLOPs are often the focus of analysis of ML training runs, they are not the sole resources that must be optimized around.
GPT-4 Training Orders of Magnitude[20]
See footnotes for details.
250,000 PlayStation Fives[22]
(< 1% of all PS5s)
This can most straightforwardly be seen by comparing the cost per FLOP of ML GPUs with that of some non-ML GPUs[24]. For instance, the GPU likely used to train GPT-4, NVIDIA’s A100, is ~10x the cost per flop of NVIDIA’s latest gaming GPU. The table below compares the A100 and the H100 (a state of the art ML GPU and successor to the A100), with the RTX 4090 (NVIDIA’s best gaming GPU).
624 TFLOP/s equiv[29]
(312 TFLOP/s if int8 training isn’t possible)
$24.04
($48.08 if int8 training isn’t possible)
I discuss more about what actually drives the cost of these GPUs in Why ML GPUs Cost So Much.
In addition to the individual chips, there are other significant costs in ML training runs - my best guess is that GPUs account for only 70% of the cost of the hardware needed for a frontier model training run right now, with networking equipment making up most of the remaining 30%. As the size of ML supercomputers grows further the non-GPU costs may outpace GPU costs, due to problems of scale.
Possible Solutions
The US ban on the export of advanced ML chips to China uses a means of normalizing FLOPs based on the lengths of the values involved. It is my understanding that in practice it amounts to treating all types of FLOPs that are used for training basically the same, and some FLOPs used for inference as worth a fraction of a training FLOP.[30] In practice, attempts to circumvent the ban have focused on another, communication based, requirement.
In general it can be difficult to figure out what sorts of FLOPs are usable for training frontier models - there are a wide variety of types of FLOPs and their usability can change rapidly - as recently as 2022 it was not publicly known how to train GPT-3 sized models with traditional FP16 precision FLOPs, but recent progress has been made on training models of that size with only FP8.
Another way to address issues around specialization would be to search for metrics based on more fundamental and stable aspects of hardware. Examples of these sorts of metrics might be transistor-hours, energy usage, or single bit logical operations. These metrics have the advantage of having a large amount of historical data that can be analyzed for forecasting. The disadvantage is that separate work would need to be done to contend with how specialization interacts with this.
I’m not fully satisfied with any of these approaches at the moment, and think this is an open question with important implications for forecasting and regulation.
ML Parallelism
Further reading: Throughout I’ve linked potential resources, and additionally here are some higher level overviews of ML parallelism from OpenAI, HuggingFace, and Fathom Radiant.
The common notion that “ML is embarrassingly parallel[31]” is simplistic and breaks down at large scales - where any simple method of parallelizing a model starts to hit bottlenecks as the capabilities of individual devices become bottlenecks regardless of the number of devices involved. This section gives an overview of parallelism methods, including commentary of the various bottlenecks they hit.
There are a few different methods to parallelize training across an increasingly large number of devices. I’m going to lump them into two categories: vertical and horizontal parallelism. Other sources split things differently, but I think my approach is easier to understand and better captures the fundamentals of parallelism in ML.
Vertical Parallelism
Vertical parallelism scales by adding devices in a similar way to how an assembly line can scale by adding workers, where each worker in the line passes an item that is being produced to the next worker. While this may not speed up production of a single item much, by having multiple items on the assembly line at once you can increase the overall throughput.
Similarly, vertical parallelism works by increasing the number of consecutive devices data flows through during training. Done naively this results in decreasing device utilization as once data passes through a given device the device will idle. In order to avoid this multiple inputs can be run through this pipeline simultaneously assembly line-style, relying on each stage in the pipeline for only a portion of the work necessary for each input. This doesn’t substantially increase the speed of updates past a certain point, but it can allow the scaling of batch size without huge slow downs. Vertical parallelism is important, but cannot be applied to all of the challenges of scaling, as it is not very useful for increasing update speed.
Two examples of vertical parallelism:
Vertical parallelism hits a few limitations as you scale - the number of layers grows fairly slowly and so pipeline model parallelism is only so, and the need for large amounts of inter device communication between a long chain of devices can prove challenging to overcome as often devices only have very fast communication within a small closed neighborhood[33].
Horizontal Parallelism
Horizontal parallelism is similar to having workers assemble an item simultaneously, typically by breaking the item into parts, having each worker work on a single part, and then having all the workers come together to assemble the final item. This speeds up the completion of the item but as the number of workers increases the task of coordinating such a large group grows increasingly difficult - think of tens of workers all trying to squeeze together to put their pieces of the item together.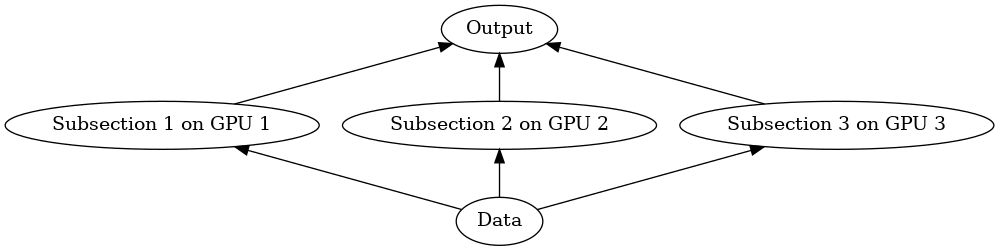
More concretely, horizontal parallelism is increasing the number of devices that work simultaneously on components of a larger task. This allows updates to the model to be done faster, as the execution of the model itself will be faster. This also doesn’t require more memory. However, horizontal parallelism has increasingly large communication costs, as more and more devices need to communicate with each other as you scale this method.
A few examples of horizontal parallelism:
In theory horizontal parallelism can scale fairly efficiently. However engineering challenges become increasingly difficult as more and more devices need to communicate with each other, unlike vertical parallelism where each device only needs to communicate with two other devices. Just like the difficulty of having a large number of workers crowd around a single item, having a large number of GPUs communicate with each other quickly about a single time can impose heavy costs - including in terms of physical space due to the proximity required for speedy communication.
We (Probably) Won't Run Out of Data
There is a reasonably large amount of attention paid to the rather steep data requirements of current ML methods, and to the possibility that data might “run out” and bottleneck scaling[34]. My best guess is that data will not meaningfully run out, but I'm not certain. There were a range of opinions among experts I consulted though most did not expect it to be a major bottleneck. Substantial research has been done that could delay or prevent running out of data, including:
Also note that running out of data doesn’t have to be binary - it’s possible that these methods enable continued growth in model performance but at a slower rate than natural data would allow. Alternatively, they could allow faster growth in model performance - training via self-correction or reinforcement learning based approaches seem plausibly superior to me once models have achieved a minimal level of capabilities.
AI Energy Use and Heat Signatures
Energy use gets brought up a lot when discussing the recent AI explosion, despite the fact that it accounts for a very small fraction of the cost of training a frontier model, and a very small fraction of the US’s energy usage[35]. Despite this, it turns out energy might actually be super important to the future of ML, limiting scaling, determining major engineering challenges, and providing a novel approach to surveillance of training runs. This is due in large part due to energy requirements growing and the required density of ML supercomputers.
Growth
So far, it seems unlikely that ML supercomputers have very different energy requirements from normal data centers used by the likes of Google - both requiring perhaps in the low tens of megawatts of power. This usage has remained consistent for supercomputers at least over the last 25 years - there hasn’t been much change. Supercomputer performance has mostly come from increasing performance per watt, not increasing the number of watts used (see the chart in this article). However it seems really likely that ML will drive a huge increase in the size of the individual supercomputers used for training them which, according to some but not all experts, could result in supercomputers within the next five years that require gigawatts of power (assuming on the order of a hundred billion dollars of spending on individual supercomputers, which is quite the extrapolation to make). This is similar to the power usage of New York City. The unavailability of this much power could play a significant role in ML in the near future,
Density
ML training runs require huge amounts of communication which becomes harder and requires more energy the farther devices are from each other. As a result, we should expect ML supercomputers to stay in a relatively small geographic area. Fitting cooling within a small volume will also be hard, and in general getting rid of heat is a non-trivial challenge.
Heat Based Satellite Surveillance of ML Training Runs
The amount of heat given off by this much energy usage is significant, concentrated in one place, and consistent over time due to training runs running 24/7 for months. As a result, you can probably see them in infrared satellite images even now, and in the near future they may be fairly distinguishable from basically anything else! This provides a novel way to do surveillance on ML training runs done around the world.
Here’s a satellite picture I found on SkyFi of a data center taken with multispectral photography with the datacenter circled. I’ve adjusted the contrast and brightness. I’m uncertain how much of the bright spot is due to IR and how much is due to the datacenter having a light gray roof - I’d need to pay 250 dollars to get access to the higher res originals to get a better sense of what’s going on here.
Other Distinguishing Features
There are a few things like some aluminum smelters which may use similar amounts of energy but factors like the lack of material input/output, may serve to distinguish ML supercomputers.
Similarly, bitcoin mining relies substantially on minimizing cost of energy to turn a profit, resulting in miners often using excess energy in locations rather than requiring a constant supply of energy for a long period of time as ML training does.
Google’s Gemini may join this class when it is released, and Claude-Next as well.
Semianalysis says 63 and Epoch says 40. I trust Semianalysis more on this.
I use the estimates I make in ML Hardware Cost as well as an assumption that there were 25k A100 GPUs, each costing approximately $15k.
To a decent extent I’m reasoning from the lack of evidence for significant data-associated costs. One possible way I could be wrong is if OpenAI were actually paying large amounts to license copyrighted data, but I have not seen any evidence of this.
I computed power draw costs as a percentage of the cost of an A100 (which I guessed at being 15k) and also tried using 25k A100s as Semianalysis reports, treated them as running for the full year to account for experiments, and used this, this and this to estimate power draw of the whole system.
Relevant math is 1-195,000/((269,010-42,000) * (5/4))
See the estimate by Epoch here.
This is my best guess, based on the cost of 8 H100s (and additional networking equipment) in this breakdown of the cost of DGX H100. I’m very confident the cost is within the interval $10k-$45k.
See this article.
I use FP8 without sparsity, or int8 without sparsity for the A100 because it lacks FP8 and it seems plausible int8 works for training.
I use whatever the fastest form of interconnect is.
See here, sum up both directions to get the total.
See footnote in the doc about custom thermal solutions.
Based on this, if the 80GB of memory of an H100 or A100 was standard computer memory it would cost only $164, and if it were hard drive storage it would cost $1.12, The difference in price between these forms of memory, and the one used GPUs, is due to the memory bandwidth - data can be read from and written to the memory of a GPU much much faster than it can for a hard disk. I think of this as a function of internal communication within the GPU, not as a function of the RAM.
Misspelled in the chart.
Google’s new TPUv5e chip, and possible upcoming TPUv5 chips, may be comparable to the H100, but the TPUv5e was announced during the final stages of polishing this doc so I do not account for this.
See the Bio Anchors report.
See much of the work of Epoch.
The SOTA ML GPU, NVIDIA’s H100, can perform non-sparse tensor flops of the smallest format (FP8) at 30x the speed of FP32.
Throughout I am using estimates made by Epoch and this article by Semianalysis - both are good sources with very different specialities.
Epoch suggests 12-20 trillion tokens if GPT-4 involved as much compute as estimated and follows Chinchilla scaling laws, and Semianalysis reports 13 trillion but less than 7.5 trillion unique tokens. I use 13 trillion. Standard tokenization techniques would imply fewer than 2 bytes per token, which gives us 26TB of data. Cheapest MacBook Air M2 comes with 256GB of storage, giving us 104 which I round to 100. I ignore image data in this analysis, as less research has been done on this and GPT-4’s image capabilities are as of yet unreleased.
Epoch gives ~2e25 FLOPs of compute used for training and Semianalysis agrees. The PlayStation 5 is reported to have 10.28 TFLOP/s of compute which gives ~250,200 necessary to have enough compute in 3 months. Sony has reportedly sold at least 38.4 million PS5s, implying this is less than <1% of PlayStations that have been sold.
The real number is quite likely higher. Semianalysis and Epoch give different numbers here, for my best guess I’m using Semianalysis’ numbers since they seem to have more information available and better match what I’ve heard elsewhere. They give about 25k A100 GPUs, which, based on available interconnect and what Semianalysis suggests, would indicate the capability to have at least 5 petabytes a second of aggregate interconnect bandwidth. I think around half of this was likely used given ML parallelization techniques - giving maybe 2.5 petabytes a second. Over the course of a likely at least 90 day training run (estimated by Epoch and Semianalysis) we get a total of 19.4 zettabytes (1.94e22). Cisco estimated 3.5 zettabytes (3.5e21) for 2022 consumer internet traffic (when the monthly amount is multiplied by 12x) in their 5 year projections as of 2017, I’m having trouble finding more recent numbers.
NVIDIA likely has much higher margins on ML GPUs, which means these numbers could very well change in the future as competition increases.
See the estimate by Epoch here.
This is my best guess, based on the cost of 8 H100s (and additional networking equipment) in this breakdown of the cost of DGX H100. I’m very confident the cost is within the interval $10k-$45k.
See this article.
I use FP8 without sparsity, or int8 without sparsity for the A100 because it lacks FP8 and it seems plausible int8 works for training, see Appendix E of this and also this paper.
Technically int8 operations are not FLOPs, because int8 isn’t a floating point data type, but are being assumed to be basically equivalent for the purposes of ML training.
The ban works by multiplying the amount of FLOPs of a given data type by the bit length of the data types involved. However, ML training typically requires a portion of each operation be done with FP32, even if the inputs are smaller data types and intermediate values are too, which results in the ban treating all such FLOPs the same.
Embarrassingly parallel is a term for computational tasks that can be easily divided into sub-tasks that can be accomplished by independent devices.
The need to do backpropagation for learning presents a challenge here, requiring forward passes to be followed by backward ones for computing what the model got wrong for each input. It’s not trivial to schedule these passes in a way that prevents collisions and it inevitably results in some amount of idle time for the devices (referred to as a “bubble”). See the section on pipeline parallelism in this post by Hugging Face to learn more.
Within node communication is generally much faster than other communication.
Epoch’s report on this is a prominent example.
I got a quick upper bound of a fraction of a percent. A brief sketch of how I did this: multiplying the energy usage of an ML GPU from NVIDIA by the revenue of the data center division (which they are under) divided by the cost of an ML GPU and comparing that to US energy usage. I consider the ML estimate to be very likely far too high and the real number to be even lower.