".. we just don't have very compelling example domains where ML systems understand important things in ways we can't. "
I'm guessing you mean in ways humans can't even in principle?
Regardless, here's something people might find amusing - researchers found that a simple VGG-like 3D CNN model can look at electron microscope images of neural tissue and do a task that humans don't know how to do. The network distinguishes neurons that specialize in certain neurotransmitters. From the abstract to this preprint:
"The network successfully discriminates between six types of neurotransmitters (GABA, glutamate, acetylcholine, serotonin, dopamine, and octopamine) with an average accuracy of 87% for individual synapses and 94% for entire neurons, assuming each neuron expresses only one neurotransmitter. This result is surprising as there are often no obvious cues in the EM images that human observers can use to predict neurotransmitter identity."
They are developing explainability techniques to try to figure out how the CNN does this classification (see the figures in this preprint). In addition to the custom methods they've developed I know they have also used more bog-standard activation maximization techniques as well (personal communication with Jan Funke in January year). Jan told me he's read Chris Olah et al.'s publications in Distill. They think the network may be cuing in on subtle differences in the size/shape of vesicles.
Someone needs to check if we can use ML to guess activations in one set of neurons from activations in another set of neurons. The losses would give straightforward estimates of such statistical quantities as mutual information. Generating inputs that have the same activations in a set of neurons illustrates what the set of neurons does. I might do this myself if nobody else does.
I'm not clear on what you'd do with the results of that exercise. Suppose that on a certain distribution of texts you can explain 40% of the variance in half of layer 7 by using the other half of layer 7 (and the % gradually increases as you use make the activation-predicting-model bigger, perhaps you guess it's approaching 55% in the limit). What's the upshot of models being that predictable rather than more or less, or the use of the actual predictor that you learned?
Given an input x, generating other inputs that "look the same as x" to part of the model but not other parts seems like it reveals something about what that part of the model does. As a component of interpretability research that seems pretty similar to doing feature visualization or selecting input examples that activate a given neuron, and I'd guess it would fit in the same way into the project of doing interpretability.
I'd mostly be excited about people developing these techniques as part of a focused project to understand what models are thinking. I'm not really sure what to make of them in isolation.
I'm not really sure what to make of them in isolation.
I score such techniques on how surprised I am how well they fit together, as with all good math. In this case my evidence is: My current approach is to thoroughly analyze the likes of mutual information for modularity only on the neighborhood of one input, since that is tractable with mere linear algebra, but an activation-predicting-model is even less extra theory (since we were already working with neural nets) and just happens to produce per cross-entropy loss the same KL divergences I'm already trying to measure.
IIRC you study problem decomposition. Would your results say I'll need the same magic natural language tools that would assemble descriptions for every hierarchy node from descriptions of its children in order to construct the hierarchy in the first place? Do they say anything about how to continuously go between hierarchies as the model trains? Have you tried describing how well a hierarchy decomposes a problem by the extent to which "a: TA -> A" which maps a list of subsolutions to a solution satisfies the square
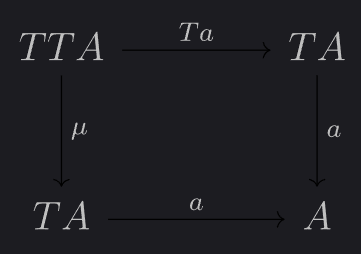
on that hierarchy?
If you can find two halves with little mutual information, you can understand one before having understood the other. I suspect that interpreting a model should be decomposed by hierarchically clustering neurons using such measurements. Since the measurement is differentiable, you can train a network for modularity to make this work better.
It sure is similar to feature visualization! I prefer it because it doesn't go out of distribution and doesn't feel like it implicitly assumes that the model implements a linear function.
I agree that interpretability is the purpose and the cure.
I'm very excited about research that tries to deeply understand how neural networks are thinking, and especially to understand tiny parts of neural networks without too much concern for scalability, as described in OpenPhil's recent RFP or the Circuits thread on Distill.
I want to give some detail on the kind of research I'm most excited about and why.
(Disclaimer: These are off-the-cuff thoughts. I'm not at all an expert in this area, just someone who cares a lot about alignment and has opinions.)
Why I'm excited about interpretability
I'm very scared of powerful AI doing something deliberately destructive that no one wanted it to do. If we had a reasonably complete story about how a neural network was thinking, then I doubt this failure mode would take us by surprise---we'd be able to see that the model was only behaving well on the training distribution because we were watching, and understand that the model was capable and inclined to cause harm when deployed. I think that even a partial understanding could provide a huge amount of clarity on open disputes about how models will generalize and when they may pose risks.
So the simplest positive case for interpretability is that it gives us a much clearer warning about an impending problem. That may or may not be enough for us to get our act together and fix the problem, but it's at least a start.
Beyond that, interpretability plays a central role in many proposals for training safe AI. For example, we might use interpretability to help identify cases where the model would behave badly, to help ensure that the model never develops deceptive intent, or to help understand what the model knows about the world so that we can better evaluate its outputs. We don't really know which of these approaches will pan out, but the fact that interpretability keeps coming up makes it seem important beyond just a warning shot.
Some of these approaches would put more "strain" on an interpretability method. If we optimize models so that they don't appear to think certain kinds of thoughts, then gradient descent will find a way to hide those thoughts. I don't know if interpretability techniques would ever be strong enough to stand up to this kind of optimization pressure, but I think interpretability is incredibly useful anyway---it still gives you a key warning shot, and many of the potential applications in the training process wouldn't create as much adversarial pressure.
It's possible for models to eventually hide their cognition even if we don't apply gradient descent. But I think this may be extremely hard; that the process of doing so is likely to itself be visible if we are careful; and that even if transformative AI is smart enough to obfuscate its thoughts we would still learn a huge amount from studying dumber models.
I'm significantly more interested and optimistic about mechanistic interpretability than I was 4 years ago. So from my perspective Chris Olah, who has championed this perspective during the interim, gets a lot of epistemic credit here.
Why I'm not worried about scalability
I think I basically totally agree with the OpenPhil RFP, and in particular think the most exciting work is getting an extremely detailed mechanical understanding of a tiny part of a neural network. If anything I'd lean slightly further in that direction than Chris does in the RFP.
Expanding on that: it seems to me that the current bottleneck for interpretability is that we almost never have a good understanding of what's going on, not that we have good methods that scale poorly. I think people should mostly not worry about scalability while we try to get really good at understanding what's up with small pieces of neural networks.
That's partly an aesthetic judgment about what the conceptual bottlenecks are, but I think there are also some concrete reasons not to worry too much about scalability:
I think "fully understand a neural network" is a good aspirational goal, which I think is also mostly bottlenecked on "deeply understand small pieces effectively."
Comparison to Circuits
The Circuits thread on Distill is probably the best example of work I find exciting.
I think the most exciting aspect of this thread is the "Artificial Artificial Neural Network" described in Curve Circuits, and in particular the preliminary results on replacing the "natural" curve circuit with their hand-coded version (See "Finally, a preliminary experiment..."). They consider a set of neurons that appear to be doing curve detection, find that zeroing those activations reduces accuracy by 3.3%, and that replacing them with a hand-written curve detection algorithm recovers half of the loss.
I feel like "understand pieces of cognition well enough that you can replace them without degrading performance" is the right game to be playing, and that the evidence provided by successfully doing the replacement would be much stronger than anything else that we think we know about neural networks.
My biggest reservations with that work are:
Most of all, I think that they could predictably get much cleaner results by continuing to spend time on the problem---they didn't put much effort into this experiment, and they mention several obvious ways to do much better (e.g. their version of the circuit is in grayscale instead of color).
There were several ways I think that the authors might have been making life unnecessarily hard on themselves:
If I were recommending someone an applied alignment project to get started in the field, a strong candidate would be trying to "finish the job" on curve detectors, before trying to apply the same treatment to another similarly complex neuron. My biggest concern would be that this work would be quite hard and not adequately appreciated, but given increasing interest in alignment and consensus about the centrality of interpretability I'm less concerned about that than I would have been a few years ago.
I'm somewhat more excited about doing these analyses for large transformers trained as LMs. I think there are good reasons to expect the same basic approach to work, and that if anything the existing problem is more likely to be usefully analogous to the long-term problem. That said, I think that there are a few tricky things in generalizing this approach to transformers and for people new to the field it may be better to try to follow more closely with the existing work on vision models (since I expect the core difficulties to be extremely similar).
In general I think that this work is more likely to be tractable for smaller models, and I'm intuitively a bit skeptical of Chris' "Valley of Confused Abstractions". I'm scared about projects shifting prematurely to larger models because the most interpretable parts of the model get easier and easier to understand even while the least interpretable parts (where in some sense we should be aiming) are getting harder and harder to understand. That said, I have almost no first-hand experience doing interpretability, and Chris has much more experience doing interpretability including with tiny models---so I think there's a good chance that projects on e.g. an MNIST model would just be exercises in clarifying what it really means to e.g. "understand" a linear regression, rather than expecting to get very satisfying results.
Some caveats
I don't really expect to be able to tell "simple" stories about individual neurons in general. I think many of them might be complicated messes involving unfamiliar concepts where a human can only understood one small aspect of a neuron's behavior at a time. And often a neuron will only make sense in the context of a bunch of other neurons.
The RFP talks about polysemanticity as something we'd like to avoid, but I'm a bit skeptical on that point---it seems to me like in powerful systems neurons will often be incredibly polysemantic, and indeed to stretch the concepts such that "polysemantic" doesn't really make sense (consider a transistor in my computer). That said, I also would have intuitively predicted existing models to be quite polysemantic, and so successful monosemantic replacements of neural net circuits suggest that I'm mistaken and maybe things will be simpler than I expected for longer.
Even given highly polysemantic neurons without any simple human-understandable stories, we can still have the goal of writing algorithms we fully understand that achieve the same loss. The feasibility of that project seems like it may be very closely related to the feasibility of "factored cognition:" can we build arbitrarily complex structures in human-understandable ways out of human-understandable parts? For challenging models this is likely to involve significant caveating and clarification about what "understand" means, etc. But to the extent that those issues arise in interpretability, I think it's reasonable to cross that bridge when we come to it and that it's a reasonable domain to explore the same questions that would be important for IDA or other approaches.
(Moreover, from my perspective one of the main obstacles to making progress on factored cognition right now is that we just don't have very compelling example domains where ML systems understand important things in ways we can't. So if interpretability fails for this kind of conceptual reason, then at least we plausibly get a consolation prize of an interesting and plausibly challenging test case for other techniques.)