This is a special post for quick takes by DaemonicSigil. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
If you're working with multidimensional tensors (eg. in numpy or pytorch), a helpful pattern is often to use pattern matching to get the sizes of various dimensions. Like this: batch, chan, w, h = x.shape. And sometimes you already know some of these dimensions, and want to assert that they have the correct values. Here is a convenient way to do that. Define the following class and single instance of it:
class _MustBe:
""" class for asserting that a dimension must have a certain value.
the class itself is private, one should import a particular object,
"must_be" in order to use the functionality. example code:
`batch, chan, must_be[32], must_be[32] = image.shape` """
def __setitem__(self, key, value):
assert key == value, "must_be[%d] does not match dimension %d" % (key, value)
must_be = _MustBe()
This hack overrides index assignment and replaces it with an assertion. To use, import must_be from the file where you defined it. Now you can do stuff like this:
batch, must_be[3] = v.shape
must_be[batch], l, n = A.shape
must_be[batch], must_be[n], m = B.shape
...
Linkpost for: https://pbement.com/posts/must_be.html
Scenario: I would like to sell an API. But it should return an error for a certain class of requests that for ethical, business, or other reasons, I do not want to fulfill. Using machine learning, I have created a model to automatically classify requests. However, this model is vulnerable to adversarial examples. Given enough tries, an adversary can find examples that trick my classifier into allowing their request through. I need to prevent this from happening. Here are some methods to accomplish this:
- This is a hopeless requirement and I should give up now.
Okay, fine. Can we at least make it annoying and inconvenient for adversaries to do find adversarial examples? Here are some methods to accomplish this:
- Eliminate the feedback loop by returning a plausible-looking bogus result instead of an error. If adversaries cannot tell the difference between this and a true API result, they will have a hard time optimizing their requests to pass my filter.
- The problem here of course is that the bogus results have to be different somehow from the true results. So the only inconvenience adversaries need to deal with is learning to distinguish between them. After this, they can go right back to what they were doing before.
- Probably my classifier can also make false-positive errors, and even a small chance that an ordinary user of my API might gets silently corrupted results could destroy a lot, or even most of its value to them.
- Eliminate the feedback loop by setting a limit on the number of "bad" requests that adversaries can send before their account is blocked. A kind of "3 strikes and you're out" type of deal.
- The problem here is that one adversary can use multiple sockpuppet identites to get more guesses. (Or a coalition of multiple adversaries can share information between themselves.) We can make this more annoying for adversaries by linking identity to payment method, eg, credit card number.
- Could this still hit ordinary users with collateral damage? Maybe they make a few bad queries out of ignorance and get banned? Or get hit by some false positives, and then banned, maybe because they send a lot of requests in general?
- If this is indeed a problem, there is a good solution. Because I really have put my best effort into training my classifier, I have mixed some adversarial examples into its training data. So what I do is train a second, weaker classifier on data that does not contain the adversarial examples. If the weak classifier flagged the request, we just return the error and that's it. If the weak classifier passed the request and we had to rely on the strong classifier to flag it, then we return the error but we also put a strike against the user's account. The idea here is that we only put a strike for requests that are "tricky" in some way. Dumb requests that aren't trying to probe our classifiers can be rejected, but don't count as a strike against the user that submitted them.
- To allow for false positives, we can maybe also allow users an extra strike for every {large_number} of API requests. This is inconvenient for adversaries to take advantage of because API requests cost money.
Yes, this is about Anthropic's silent nerfing of Fable for certain tasks. The second option here seems much better to me for that case, and I'm curious why they chose to go with the first. Is there any motivation they could have beyond trying to prevent gaming of their classifier?
You can disable the silent nerfing when using the api, so it's not really about preventing fooling the classifier.
Okay, that does change things, thanks!
Any idea what they could be aiming for then? Letting you disable it in the API but also having it otherwise be a silent effect that gives no notification that it has happened is a really weird combination.
It seems like there should be pretty decent solutions with combinations of methods. If many of the first requests from a new account get flagged it's banned, etc.
If you're retaining the requests and investigating ones that seem criminal in collaboration with law enforcement, that's a strong incentive to not try them.
I thought this recent substack post was very insightful: https://eliasschmied.substack.com/p/social-agency
tldr is that the post asks how much of our ability to plan comes from our brains being designed to plan, and how much is purely learned (by social imitation of other people's planning, or explicit instruction from others on how to plan). It answers that a surprising amount is purely learned. (This summary does not do the post justice and you should really go and read it.)
Below is a copy of a comment I left:
Thank you for writing this!
I have been developing similar kinds of suspicions for a little while (that even though we know how to program algorithms like MCTS, that doesn't mean human brains have a built-in analogue, and that many things like this are learned, not implemented on an architecture level), but I was missing a lot of the pieces you have here, and reading this really crystallized it for me.
A priori, we would expect the first, naturally arising, agent to attain this agency in the stupidest, most hacky way possible.
Re this, as you note later, LLM planning capabilities also arise from learning some kind of prior over chains of thought, and then applying a bit of "cherry on top" RL. So it also seems that the first general [1] artificially arising agent also attained agency in the stupidest, most hacky way possible, exactly as humans did. We are, in this respect at least, following in the footsteps of evolution on our quest to build AI.
I'm not sure the extent to which this affects the AI ruin hypothesis, and how powerful we can expect intelligence to become. I share your opinion that it must change the story somehow, but at the same time, strong planning abilities can be dangerous, regardless of whether they're learned or architectural. It's unclear whether the ultimate, optimally-designed successor agent would have built-in planning, or would have to learn to plan, but I find myself expecting it to be extraordinarily powerful either way.
You mostly describe the social aspect of learning to plan here, but I do think that it's a mix of both social imitation and RL. Eg someone learning to play chess would socially absorb the idea of looking ahead several moves, and various heuristics for evaluating board positions, but they'd also just improve from playing several games and seeing what planning techniques are actually effective. [2]
Nothing left to elevate the hypothesis of a simple core structure of general planning or agency to our attention.
Re this, I think it is slightly overstated. All the old structure of VNM rationality still exists, it's just intractable to compute in the real world, just like we already knew it was. I think what changes here is our estimate of how well an algorithm of a given cost can approximate it. In particular, it starts looking harder to approximate very well, and we might start hoping instead that we can get good real-world results from things that are actually quite far from VNM rational.
Questions:
- World modelling does seem pretty architectural to me right now. There is a move that is often used in planning where we "deform" our world model to correspond to some hypothetical scenario, and get it to spit out predictions for what values various variables are likely to take. I tend to think that this kind of "deformation" into fake scenarios is also a built-in ability, do you agree? Or an alternate hypothesis could be that we have a built-in direct sensory world model, and also a learned far-mode world model, and only the latter is deformable?
- This all makes me think that the kinds of modifications to LLMs needed to trigger the singularity or whatever, are not actually that big? Like, if planning is learned anyways, we don't need to drastically modify the transformer architecture to wedge some kind of planning into it, RL on chain of though is already all we need. Given that "big dumb blob of intelligence" is going to be the paradigm that wins, are our options for getting friendliness basically just "use good training data" and "make the big blob more sample-efficient"? Does increasing sample-efficiency even help?
- This is a great article. I hope you are planning to crosspost to lesswrong?
Fairly general, at least. I specified this because in many specialized domains agents do use a built-in search process. Eg. alpha go using MCTS. ↩︎
Maybe RL in the weak sense. Humans don't really seem to be able to directly reward ourselves purely mentally in the same way as we'd get a direct reward for eating a cookie while hungry. So arguably the kind of tuning that happens here could be better classified as epistemic, though it does affect the distribution of planning actions like a true reward-update would. ↩︎
Rhymes with Is Clickbait Destroying Our General Intelligence? I suspect that writing a good answer to a silly question on r/whowouldwin, arguing with a friend about what Light Yagami's next move should be, and the art of best response are all pointing in a similar direction. Likewise, I suspect some amount of personality and internal 'self-hood' is built socially.
The post is now here on LW too: https://www.lesswrong.com/posts/xopGsfQxiLcjXEkbE/social-agency
People here might find this post interesting: https://yellow-apartment-148.notion.site/AI-Search-The-Bitter-er-Lesson-44c11acd27294f4495c3de778cd09c8d
The author argues that search algorithms will play a much larger role in AI in the future than they do today.
Perturbation Theory in Machine Learning
Linkpost for: https://pbement.com/posts/perturbation_theory.html
In quantum mechanics there is this idea of perturbation theory, where a Hamiltonian is perturbed by some change to become . As long as the perturbation is small, we can use the technique of perturbation theory to find out facts about the perturbed Hamiltonian, like what its eigenvalues should be.
An interesting question is if we can also do perturbation theory in machine learning. Suppose I am training a GAN, a diffuser, or some other machine learning technique that matches an empirical distribution. We'll use a statistical physics setup to say that the empirical distribution is given by:
Note that we may or may not have an explicit formula for . The distribution of the perturbed Hamiltonian is given by:
The loss function of the network will look something like:
Where are the network's parameters, and is the per-sample loss function which will depend on what kind of model we're training. Now suppose we'd like to perturb the Hamiltonian. We'll assume that we have an explicit formula for . Then the loss can be easily modified as follows:
If the perturbation is too large, then the exponential causes the loss to be dominated by a few outliers, which is bad. But if the perturbation isn't too large, then we can perturb the empirical distribution by a small amount in a desired direction.
One other thing to consider is that the exponential will generally increase variance in the magnitude of the gradient. To partially deal with this, we can define an adjusted batch size as:
Then by varying the actual number of samples we put into a batch, we can try to maintain a more or less constant adjusted batch size. One way to do this is to define an error variable, err = 0. At each step, we add a constant B_avg to the error. Then we add samples to the batch until adding one more sample would cause the adjusted batch size to exceed err. Subtract the adjusted batch size from err, train on the batch, and repeat. The error carries over from one step to the next, and so the adjusted batch sizes should average to B_avg.
What is the difference between a perturbation and the difference from a gradient in SGD? Both seem to do the same thing. I'm just pattern-matching and don't know too much of either.
In this context, we're imitating some probability distribution, and the perturbation means we're slightly adjusting the probabilities, making some of them higher and some of them lower. The adjustment is small in a multiplicative sense not an additive sense, hence the use of exponentials. Just as a silly example, maybe I'm training on MNIST digits, but I want the 2's to make up 30% of the distribution rather than just 10%. The math described above would let me train a GAN that generates 2's 30% of the time.
I'm not sure what is meant by "the difference from a gradient in SGD", so I'd need more information to say whether it is different from a perturbation or not. But probably it's different: perturbations in the above sense are perturbations in the probability distribution over the training data.
Thanks. Your ΔH looked like ∇Q from gradient descent, but you don't intend to take derivatives, nor maximize x, so I was mistaken.
On George Hotz's doomcorp idea:
George Hotz has an idea which goes like so (this is a paraphrase): If you think an AGI could end the world, tell me how. I'll make it easy for you. We're going to start a company called Doomcorp. The goal of the company is to end the world using AGI. We'll assume that this company has top-notch AI development capabilities. How do you run Doomcorp in such a way that the world has ended 20 years later?
George accepts that Doomcorp can build an AGI much more capable and much more agent-like than GPT-4. He also accepts that this AGI can be put in charge of Doomcorp (or put itself in charge) and run Doomcorp. The main question is: how do you go from there to the end of the world?
Here's a fun answer: Doomcorp becomes a military robot company. A big part of the difficulty with robots in the physical world is the software. (AI could also help with hardware design, of course.) Doomcorp provides the robots, complete with software that allows them to act in the physical world with at least a basic amount of intelligence. Countries that don't want to be completely unable to defend themselves in combat are going to have to buy the robots to be competitive. How does this lead to the eventual end of the world? Backdoors in the bot software/hardware. It just takes a signal from the AI to turn the bots into killing machines perfectly willing to go and kill all humans.
Predicted geohot response: I strongly expect a multipolar takeoff where no one AI is stronger than any of the others. In such a world, there will be many different military robot companies, and different countries will buy from different suppliers. Even if the robots from one supplier did the treacherous turn thing, the other robots would be strong enough to fight them off.
Challenge: Can you see a way for Doomcorp to avoid this difficulty? Try and solve it yourself before looking at the spoiler.
The company building a product isn't the only party that can get a backdoor into that product. Paid agents that are employees of the company can do it, hacking into the company's systems is another method, as are supply chain attacks. Speaking of this last issue, consider this. An ideal outcome from the perspective of an AGI would be for all other relatively strong AGIs that people train to be its servants (or at least, they should share its values). Secretly corrupting OS binaries to manipulate both AI training runs and also compilation of OS binaries is one way of accomplishing this.
Yep, Claude sure is a pretty good coder: Wang Tile Pattern Generator
This took 1 initial write and 5 change requests to produce. The most manual effort I had to do was look at unicode ranges and see which ones had distinctive-looking glyphs in them. (Sorry if any of these aren't in your computer's glyph library.)
Let's say we have a bunch of datapoints in that are expected to lie on some lattice, with some noise in the measured positions. We'd like to fit a lattice to these points that hopefully matches the ground truth lattice well. Since just by choosing a very fine lattice we can get an arbitrarily small error without doing anything interesting, there also needs to be some penalty on excessively fine lattices. This is a bit of a strange problem, and an algorithm for it will be presented here.
method
Since this is a lattice problem, the first question to jump to mind should be if we can use the LLL algorithm in some way.
One application of the LLL algorithm is to find integer relations between a given set of real numbers. [wikipedia] A matrix is formed with those real numbers (scaled up by some factor ) making up the bottom row, and an identity matrix sitting on top. The algorithm tries to make the basis vectors (the column vectors of the matrix) short, but it can only do so by making integer combinations of the basis vectors. By trying to make the bottom entry of each basis vector small, the algorithm is able to find an integer combination of real numbers that gives 0 (if one exists).
But there's no reason the bottom row has to just be real numbers. We can put in vectors instead, filling up several rows with their entries. The concept should work just the same, and now instead of combining real numbers, we're combining vectors.
For example, say we have 4 datapoints in three dimensional space, . The we'd use the following matrix as input to the LLL algorithm.
Here, is a tunable parameter. The larger the value of , the more significant any errors in the lower 3 rows will be. So fits with a large value will be more focused on having a close match to the given datapoints. On the other hand, if the value of is small, then the significance of the upper 4 rows is relatively more important, which means the fit will try and interpret the datapoints as small integer multiples of the basis lattice vectors.
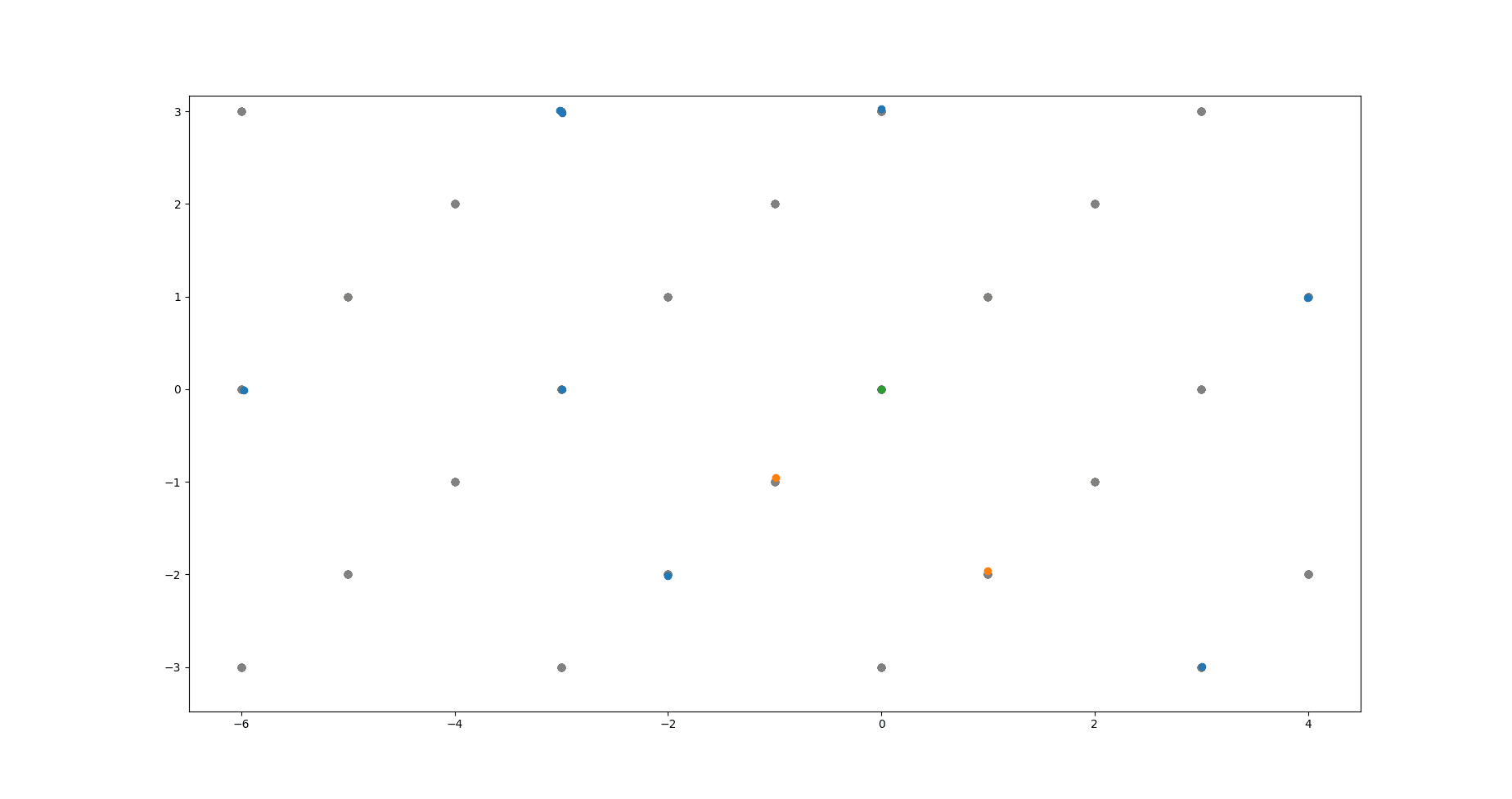
The above image shows the algorithm at work. Green dot is the origin. Grey dots are the underlying lattice (ground truth). Blue dots are the noisy data points the algorithm takes as input. Yellow dots are the lattice basis vectors returned by the algorithm.
code link
https://github.com/pb1729/latticefit
Run lattice_fit.py to get a quick demo.
API: Import lattice_fit and then call lattice_fit(dataset, zeta) where dataset is a 2d numpy array. First index into the dataset selects the datapoint, and the second selects a coordinate of that datapoint. zeta is just a float, whose effect was described above. The result will be an array of basis vectors, sorted from longest to shortest. These will approach zero length at some point, and it's your responsibility as the caller to cut off the list there. (Or perhaps you already know the size of the lattice basis.)
caveats
Admittedly, due to the large (though still polynomial) time complexity of the LLL algorithm, this method scales poorly with the number of data points. The best suggestion I have so far here is just to run the algorithm on manageable subsets of the data, filter out the near-zero vectors, and then run the algorithm again on all the basis vectors found this way.
...
I originally left this as a stack overflow answer that I came across when initially searching for a solution to this problem.
Linkpost for: https://pbement.com/posts/latticefit.html
Very interesting youtube video about the design of multivariate experiments: https://www.youtube.com/watch?v=5oULEuOoRd0 Seems like a very powerful and general tool, yet not too well known.
For people who don't want to click the link, the goal is that we're trying to design experiments where there are many different variables we could change at once. Trying all combinations takes too much effort (too many experiments to run). Changing just one variable at a time completely throws away information about joint effects, plus if there are variables, then only of the data is testing variations of any given variable, which is wasteful, and reduces the sample size.
The key idea (which seems to be called a Taguchi method) is to instead use an orthogonal array to design our experiments. This tries to spread out different settings in a "fairly even" way (see article for precise definition). Then we can figure out the effect of various variables (and even combinations of variables) by grouping our data in different ways after the fact.
Kettles and Hydro Dams
(linkpost)
I live in British Columbia, where we get a lot of our electricity from hydroelectric dams. While boiling some water in an electric kettle, the water in the kettle might get you thinking about the water that was dropped to generate the electricity to run the kettle. How much water do we have to run through the dam in order to boil a cup (250mL) of water?
To answer this, we need to know the heat capacity of water. (You might think we also need to know the latent heat of vaporization, but when we talk about "boiling" some water, the goal is not actually (usually) to turn all of that water into steam. We just want to heat the water to 100°C, while only a small fraction is boiled off.) The specific heat capacity of water is 4184 J/kg°C. Note the kg in the denomiator of the unit, which means that if we double the amount of water, it takes twice the energy to raise its temerature the same amount. So there exists some fixed ratio between the amount of water boiled and the amount of water lost from the reservoir in order to boil it.
The exact value of this ratio depends on the height of the dam and how full its reservoir is at the time. So, here's an even simpler thing we can calculate: Imagine I'm visiting a planet like Earth but with no atmosphere. I'm at the top of a cliff carrying a bucket of water. I dump the water over the edge of the cliff and it falls all the way down before striking the ground at the bottom of the cliff. How high up do I have to be before the water reaches 100°C from the sheer violence of its collision with the ground?
If we assume that the water can't lose any energy to external sources then:
-
A mass falling a height yields an energy of .
-
A mass takes an energy of roughly to heat from 25°C to boiling.
Setting these equal and solving for gives , an altitude that would be well into the stratosphere on Earth.
Given that most dams aren't 32 kilometers high, it's clear that we'll have to use much more water to generate the energy than the amount we want to boil. Specifically, 320 times more water for a 100 meter dam with a full reservoir, and the ratio is even more extreme for shorter dams or less-full reservoirs. This is kind of a shocking ratio if you haven't thought about it before, or at least that was my reaction.
One other thing that I thought was interesting about these calculations is that the water floating around near the top of the reservoir carries much more extractable energy than the water floating around near the bottom. Simply because it's higher up. So if the reservoir is low, that might be when you most desire incoming water from a scarcity perspective, but incoming water actually brings with it the most extractable energy when the reservoir is nearly full. This is related to how it takes more energy to add charge to a capacitor the more charge it already has on it so that stored energy goes as the square of the stored charge.
One thing this means is that if you're digging out a reservoir to make it larger, you should mostly focus on increasing the volume just underneath the maximum water level of the reservoir. I.e. you should shallowly dig a large area rather than deeply digging a small area.
Inspired partially by this post and partially by trying to think of simple test cases for a machine learning project I'm working on, here is a (not too hard, you should try answering it yourself) question: Let's say we've observed trials of a Bernoulli random variable, and had a 1 outcome (so were 0). Laplace's rule of succession (uniform prior over success probability) says that we should estimate a probability of for the next trial being 1. The question is: What is the prior over bitstrings of length implied by Laplace's rule of succession? In other words, can we convert the rule of succession formula into a probability distribution over bitstrings s that record outcomes of trials?
Additional clarification of the problem:
Given any particular observation of trials, there will be two bitstrings that are consistent with it, where the last (unobserved) trial is 0 or 1 respectively. We can compute the 1 probability (which should equal the result from the rule of succession) as:
where is the first bits of the string (corresponding to visible observations) and is the Hamming weight function (counts the number of 1s in a bitstring). Since this requires a normalization anyway, you can also just provide an energy function as your answer. The probability formula in this case is:
If we just pick a uniform distribution over bitstrings, that doesn't work. Then the predicted probability of the next trial is always just .
Answer:
The following energy function works:
This can be checked by computing the probability as:
This energy function biases the distribution towards strings with more extreme ratios between counts of 0 and 1. We can think of it as countering the entropic effect of strings with an equal balance of 0 and 1 being the most prevalent.
Linkpost for: https://pbement.com/posts/threads.html
Today's interesting number is 961.
Say you're writing a CUDA program and you need to accomplish some task for every element of a long array. Well, the classical way to do this is to divide up the job amongst several different threads and let each thread do a part of the array. (We'll ignore blocks for simplicity, maybe each block has its own array to work on or something.) The method here is as follows:
for (int i = threadIdx.x; i < array_len; i += 32) {
arr[i] = ...;
}
So the threads make the following pattern (if there are threads):
⬛🟫🟥🟧🟨🟩🟦🟪⬛🟫🟥🟧🟨🟩🟦🟪⬛🟫🟥🟧🟨🟩🟦🟪⬛🟫
This is for an array of length . We can see that the work is split as evenly as possible between the threads, except that threads 0 and 1 (black and brown) have to process the last two elements of the array while the rest of the threads have finished their work and remain idle. This is unavoidable because we can't guarantee that the length of the array is a multiple of the number of threads. But this only happens at the tail end of the array, and for a large number of elements, the wasted effort becomes a very small fraction of the total. In any case, each thread will loop times, though it may be idle during the last loop while it waits for the other threads to catch up.
One may be able to spend many happy hours programming the GPU this way before running into a question: What if we want each thread to operate on a continguous area of memory? (In most cases, we don't want this.) In the previous method (which is the canonical one), the parts of the array that each thread worked on were interleaved with each other. Now we run into a scenario where, for some reason, the threads must operate on continguous chunks. "No problem" you say, we simply need to break the array into chunks and give a chunk to each thread.
const int chunksz = (array_len + blockDim.x - 1)/blockDim.x;
for (int i = threadIdx.x*chunksz; i < (threadIdx.x + 1)*chunksz; i++) {
if (i < array_len) {
arr[i] = ...;
}
}
If we size the chunks at 3 items, that won't be enough, so again we need items per chunk. Here is the result:
⬛⬛⬛⬛🟫🟫🟫🟫🟥🟥🟥🟥🟧🟧🟧🟧🟨🟨🟨🟨🟩🟩🟩🟩🟦🟦
Beautiful. Except you may have noticed something missing. There are no purple squares. Though thread 6 is a little lazy and doing 2 items instead of 4, thread 7 is doing absolutely nothing! It's somehow managed to fall off the end of the array.
Unavoidably, some threads must be idle for loops. This is the conserved total amount of idleness. With the first method, the idleness is spread out across threads. Mathematically, the amount of idleness can be no greater than regardless of array length and thread number, and so each thread will be idle for at most 1 loop. But in the contiguous method, the idleness is concentrated in the last threads. There is nothing mathematically impossible about having as big as or bigger, and so it's possible for an entire thread to remain unused. Multiple threads, even. Eg. take :
⬛⬛🟫🟫🟥🟥🟧🟧🟨
3 full threads are unused there! Practically, this shouldn't actually be a problem, though. The number of serial loops is still the same, and the total number of idle loops is still the same. It's just distributed differently. The reasons to prefer the interleaved method to the contiguous method would be related to memory coalescing or bank conflicts. The issue of unused threads would be unimportant.
We don't always run into this effect. If is a multiple of , all threads are fully utilized. Also, we can guarantee that there are no unused threads for larger than a certain maximal value. Namely, take then and so the idleness is . But if is larger than this, then one can show that all threads must be used at least a little bit.
So, if we're using CUDA threads, then when the array size is 961, the contiguous processing method will leave thread 31 idle. And 961 is the largest array size for which that is true.
You Can Just Put an Endpoint Penalty on Your Wasserstein GAN
Linkpost for: https://pbement.com/posts/endpoint_penalty.html
When training a Wasserstein GAN, there is a very important constraint that the discriminator network must be a Lipschitz-continuous function. Roughly we can think of this as saying that the output of the function can't change too fast with respect to position, and this change must be bounded by some constant . If the discriminator function is given by then we can write the Lipschitz condition for the discriminator as:
Usually this is implemented as a gradient penalty. People will take a gradient (higher order, since the loss already has a gradient in it) of this loss (for ):
In this expression is sampled as , a random mixture of a real and a generated data point.
But this is complicated to implement, involving a higher order gradient. It turns out we can also just impose the Lipschitz condition directly, via the following penalty:
Except to prevent issues where we're maybe sometimes dividing by zero, we throw in an and a reweighting factor of (not sure if that is fully necessary, but the intuition is that making sure the Lipschitz condition is enforced for points at large separation is the most important thing).
For the overall loss, we compare all pairwise distances between real data and generated data and a random mixture of them. Probably it improves things to add 1 or two more random mixtures in, but I'm not sure and haven't tried it.
In any case, this seems to work decently well (tried on mnist), so it might be a simpler alternative to gradient penalty. I also used instance noise, which as pointed out here, is amazingly good for preventing mode collapse and just generally makes training easier. So yeah, instance noise is great and you should use it. And if you really don't want to figure out how to do higher order gradients in pytorch for your WGAN, you've still got options.