2 Answers sorted by
20
Of course, I stumble over this shortly after writing this.
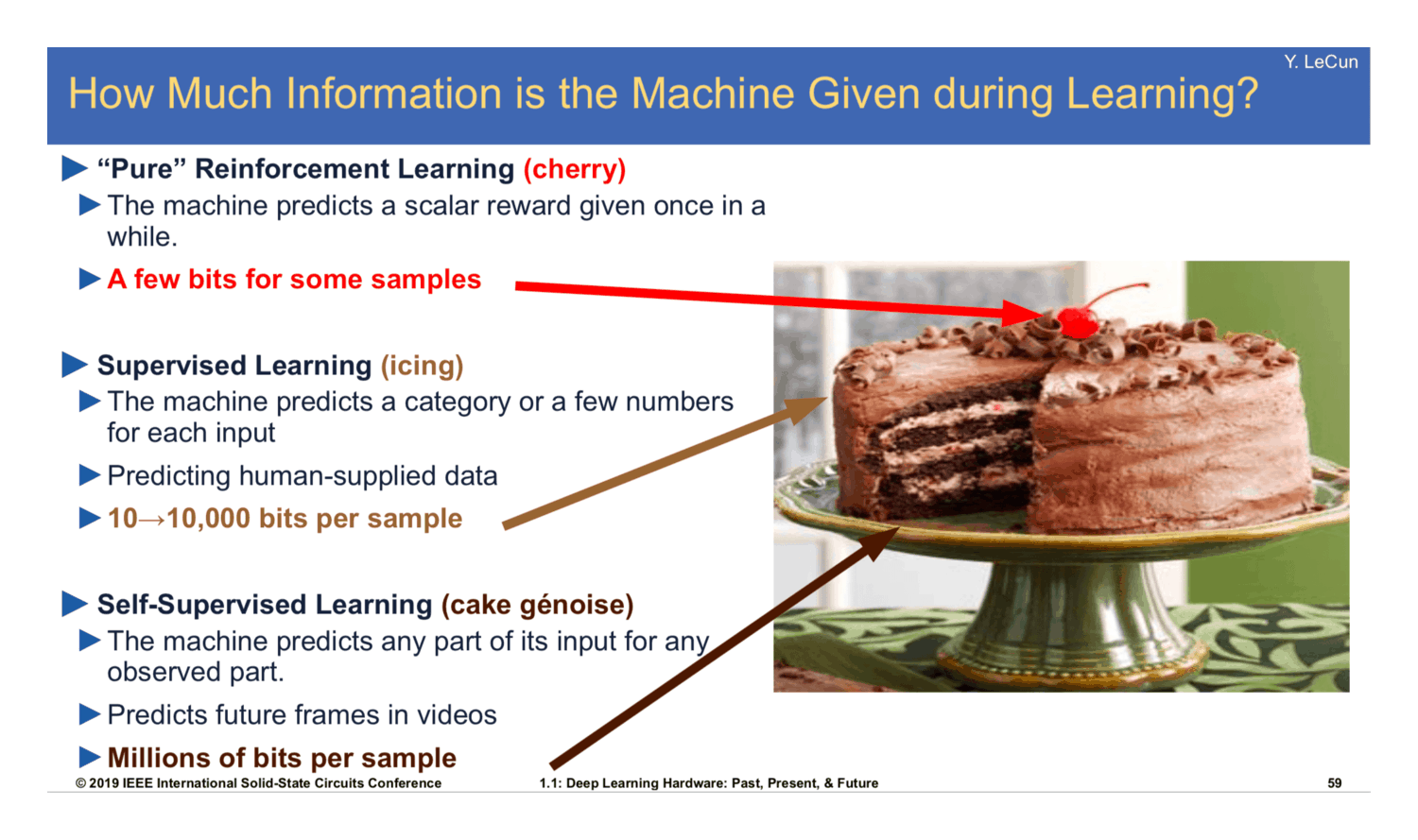
All learning modes are variants of predicting Y from X, they just differ in the partition that separates Y and X.
UL/SSL: Y is just a subset of X (often the future of X).
RL: Y is a special sensory function, specifically crafted/optimized by evolution or human engineering.
SL: Y comes from some external model (human brains, or other internal submodules).
I disagree somewhat with the framing in the pic above, in that RL is not inherently more 'cherry' than SL. You could have RL setups that provide numerous bits per sample (although not typical, possible in th...
10
The difference between "supervised" and "unsupervised" learning just refers to whether model performance is judged during training by how well the model produces the "correct answer" for each input. Supervised learning trains a model using labeled data, while unsupervised learning only learns from unlabeled data. Semi-supervised learning, as you might guess, learns from both labeled and unlabeled data. All of these methods learn to extract features from the input data that are informative as to what part of the data distribution the input comes from. They only differ in what drives the discovery of these features and in what these features are used for in deployment.
Supervised learning is all about building a function that maps inputs to outputs, where the precise internal structure of the function is not known ahead of time. Crucially, the function is learned by presenting the model with known, correct pairs of inputs and outputs, passing these inputs to the model, generating its own error-ridden outputs, and updating its parameters to minimize this error. The hope is that by learning to make correct predictions (mapping inputs to outputs) on the training data, it will generalize to produce correct predictions on new, previously unseen data.
For example, a neural network learning to classify images into one of several categories (e.g., CIFAR-10, CIFAR-100, or ImageNet) will be given thousands of pairs of images with their known category labels. It will have to figure out features of the input images on its own (i.e., patterns of pixels, patterns of patterns, etc.) that are useful for predicting the correct mappings, which it discovers through gradient descent over the space of function parameters. When deployed, the neural network will simply act like a function, generating output labels for new input images. Of course, neural networks are general enough to learn any type of function mapping, not just images to labels, since their nonlinearities equip them to be general piecewise function approximators.
Unsupervised learning, on the other hand, is all about uncovering the structure of some distribution of data rather than learning a function mapping. This could involve clustering, such as using expectation-maximization to find the means and covariances of some multimodal distribution. Importantly, there is no longer a "right answer" for the model to give. Instead, it's all about reducing the dimensionality of the data by taking advantage of statistical and structural regularities. For example, there are (256^3)^(W*H) possible images of W x H pixels, but only a very low-dimensional manifold within this space contains what we would interpret as faces. Unsupervised learning basically figures out regularities in the set of all training images to create an informative parameterization of this manifold. Then knowing your coordinates in "facial image space" gives you all the information you need to reconstruct the original image.
A neural network example would be variational autoencoders (VAE), which simply learn to replicate their inputs as outputs. That sounds trivial ("Isn't that just the identity function?"), except that these models pass their inputs (such as images) through an information bottleneck (the encoder) that extracts useful features as a latent space representation (mean and variance vectors, representing position and uncertainty on the data manifold), which can then be used to regenerate the data with a learned generative model (the decoder). Flipping these around would give you a GAN (generative adversarial network), which learns to generate data whose structure and distribution is indistinguishable from that of real data.
Supervised learning trains a model using labeled data, while unsupervised learning only learns from unlabeled data.
I think this is one of the sentences that I feel confused about. I feel like labeling is in some sense "cheating" or trading off efficiency vs. generality.
Through the authority of my ml class and Wikipedia[1] I "learned" that ml algorithms can be roughly put into 3 clusters: unsupervised, supervised, and reinforcement learning.
When learning about machine learning, one term I stumbled over is (un)supervised learning. While at this point I might be able to guess the teacher's password when someone asked me what (un)supervised learning means[1:1], I don't understand why one would carve up reality this way. Most resources I found through googling didn't really help but suggested that for some reason, reinforcement learning would also be thought of as another separate category.
So instead, I felt forced to think about this for myself. The rough abstract picture in my head after thinking for a few minutes:
How do they relate to carving up thing space/feature space?
Why are these categories useful?
Machine learning is about getting rid of humans for getting things done. Here is how different algorithms contribute:
How do they relate to each other?
It seems like any supervised learning algorithm would need to contain some unsupervised algorithm doing the compression. The unsupervised algorithm could be turned into a "supervised" one, by using the "summary statistics" to predict features we don't know about a data point through its other features. In the end, the whole reason we are doing anything is that we care about it: reinforcement learning is a special kind of supervised algorithm, designed such that we can exceed humans by explicitly encoding their judgement to "act" on surfaced insights.
The unsupervised/supervised distinction still seems a bit "unnatural"/useless to me. Feel free to leave a comment if you have more insight into why one might or might not carve up reality this way.
Definition from Wikipedia: "Unsupervised learning is a type of algorithm that learns patterns from untagged data. The hope is that through mimicry, which is an important mode of learning in people, the machine is forced to build a compact internal representation of its world and then generate imaginative content from it. In contrast to supervised learning where data is tagged by an expert, e.g. as a "ball" or "fish", unsupervised methods exhibit self-organization that captures patterns as probability densities [1] or a combination of neural feature preferences. The other levels in the supervision spectrum are reinforcement learning where the machine is given only a numerical performance score as guidance, and semi-supervised learning where a smaller portion of the data is tagged. " ↩︎ ↩︎