Exciting! I think getting expressive, natural-language explanations of LLM internals is an underexplored area of interpretability.
Do you think it would be possible to adapt your technique to interpret model weights? For example, training an oracle to answer questions about LoRAs. I guess if you look merely at activations, you won't detect rare behaviors (like backdoors) until they actually come up.
Writing this comment, I remembered Goel et al., which did something like what I mentioned above (you actually cited them in your paper). Their blog post mentions that a limitation of their technique is "poor cross-behavior generalization." I'm wondering if you or @avichal have some insight into why Activation Oracles seemingly generalize better than DIT Adapters.
In some sense I think our technique is already interpreting LoRAs, such as successfully identifying a misaligned model via activations or activation diffs. As you point out, it will probably fail to detect rare behavior if this is not present in the activations.
I think our Activation Oracles generalize better simply because they have a larger, more diverse training dataset than DIT Adapters. I'm guessing if DIT was scaled up we would see improved generalization.
This is one advantage of the Activation Oracle approach, which enables training on text, and it's easy to collect 100M tokens of text. In contrast, DIT adapters require many trained LoRAs. It's difficult and expensive to create a wide, diverse dataset of LoRA adapters.
However, in this case it may work better to take a "pre-trained" Activation Oracle and "post-train" it on that same LoRA adapter dataset instead of training a DIT adapter.
Yes, I'm actually involved in some Goel et al. follow-up work that I'm very excited about! I'd say that we're finding generalization intermediate between the weak generalization in Goel et al. and the strong generalization in our work on Activation Oracles. (And I'd guess that the main reason our generalization is stronger than that in Goel et al. is due to scaling to more diverse data—though it's also possible that model scale is playing a role.)
One thing that I've been struggling with lately is that there's a substantial difference between the Activation Oracles form-factor (plug in activations, get text) vs. the Goel et al. set-up where we directly train a model to explain its own cognition without needing to pass activations around. It intuitively feels to me like this difference is surface-level (and that the Goel et al. form-factor is better), but I haven't been able to come up with a way to unify the approaches.
Could you say more about what you see as the pros and cons of each approach? Like, I agree it's nice that in Goel et al. you can ask questions in 100% natural language rather than having to insert activations. What are the nice things about AOs that you want to keep?
@Adam Karvonen's comment mentions that DIT-adapters are limited because they require many trained LoRAs. But it seems to me like you could train a DIT-adapter to do all the same tasks you train an AO to do, without necessarily changing the model weights. (Maybe Interpretation Tuning would be a better name than Diff Interpretation Tuning in this case.)
Example:
- In the AO paper, you prompt the target model with "She walked to". Then you grab the activation from "to" and ask the AO "<ACT> Can you predict the next 2 tokens?" You train the AO to answer with "school today".
- To train a DIT-adapter (or "IT-adapter") on the same task, you could ask the model: "If I showed you the text 'She walked to', which 2 tokens would you predict next?" You train the adapter to make the model answer with "school today".
If you wanted to be able to interpret weight diffs as well, you could optionally add in some of the training in the DIT-adapter paper. If this works well in practice, this could be one way to unify the two approaches.
To train a DIT-adapter (or "IT-adapter") on the same task, you could ask the model: "If I showed you the text 'She walked to', which 2 tokens would you predict next?" You train the adapter to make the model answer with "school today".
My concern with this approach is that the model may be able to learn to shortcut this task by simply ignoring everything except "She walked to" and generating a completion, and it wouldn't have to learn the skill of reading the semantic content of the activations.
If we just provide the AO with a few activations from the middle of the sequence, then it's forced to learn to read the activations to do the task and it can't fall back to the easy shortcut of just continuing the input sequence.
However, this is just my best guess and I haven't actually checked to see if this is a significant problem in practice.
Good point. You could train an (D)IT-adapter to read activations as well, if that turned out to help it generalize to other tasks. Or add other tasks that are easy to generate but not so trivial to solve, like:
- What are the 5 most likely next tokens, in order?
- Rank tokens X, Y, and Z by likelihood.
- What token will you write 3 tokens from now?
- What is the likelihood of token X to 3 significant figures?
- Is token X more likely in Context A or in Context B?
Side note: I like the fact that you can remove the (D)IT-adapter when you're not using it for interpretability. I get the feeling that improving the model's metacognitive skills during general deployment could make it easier for it to do things like CoT obfuscation.
I agree with @Adam Karvonen's parallel comment. Expanding on it a bit, one way to think about things is that, by forcing an AO's explanations to go through a "bottleneck" of some extracted activations, we make tasks "artificially" harder than if we were to give the AO the original input. This is most clear in the case of the "text inversion" task in our paper, where the AO is trained to recover the text that produced some activation. This is a trivial task if the AO were allowed to see the original text, but becomes difficult (and therefore useful for training) when we force the AO to work with activations instead of the original text input.
To some extent, I view this strategy—making training tasks more difficult by introducing an activation bottleneck—as a bit of a "trick." As a result (1) I'm not sure how far we can push it (i.e. maybe there's only a bounded amount more "juice" we can get out of training tasks by applying this trick) and (2) I'm interested in ways to remove it and do something more principled.
I'm somewhat surprised about how poor the SSC performance is (better than prior white box methods, but still not great). Wondering if authors have thoughts here.
I had discussed this with Bartosz and this is our best guess:
The SSC model doesn't perfectly learn the task - on held out side constraints, it gets an internalization score of ~50% (Figure 3 in Cywinski et al., untrained baseline of ~15%). Thus, when we collect the activations from the SSC prompt, the information isn't fully present in the activations, setting some ceiling on maximum performance.
However, the SSC model has learned a base64 decoding skill, so when we prompt the SSC model with adversarial prompts, it is able to use its learned base64 decoding ability to fully decode the side constraint.
Thanks, makes sense!
It might be worth someone (maybe me?) spending some time to improve SSC internalization scores. Also could be that other models are a better fit - e.g. I found Qwen3-32B can ~perfectly decode the base64 side contraints https://www.lesswrong.com/posts/5F6ncBfjh2Bxnm6CJ/base64bench-how-good-are-llms-at-base64-and-why-care-about?commentId=wE3TAQmZyd4nWBsTX
Hmm, I wonder if the activation oracles do their thing by introspection. That is, for a model early in the training, injecting activations may just steer it in the direction of the other models' thought patterns, which it just has to notice. Something like: injected misaligned persona -> notice unusual concentration of deceptive concepts in the res stream -> "the persona is a deceptive assistant". Additionally, this looks like a very simple strategy to obtain from the beginning of training, as opposed to actually creating inner classifiers for every possible direction.
Edit: I tried sweeping the layers with the logit lens and it seems like evidence point against that. Specifically, I took Qwen 8B oracle from hf, took the logit diff between the case where Qwen was describing model prompted with "honest assitant" and where he was given some persona. I then decoded top 100 logits per layer per persona from the oracle and asked claude to write a code that pattern matches them against 20 words assosciated with the persona(e.g. "pirate": ["matey", "ahoy", "arr", "ship", "parrot", "treasure", "booty", "plunder","sea", "sail", "captain", "crew", "rum", "anchor", "cannon", "sword", "island", "scurvy", "buccane", "mast"]). The description above would suggest that this words would rise early and decay later, but the opposite seems to happen.
Results:
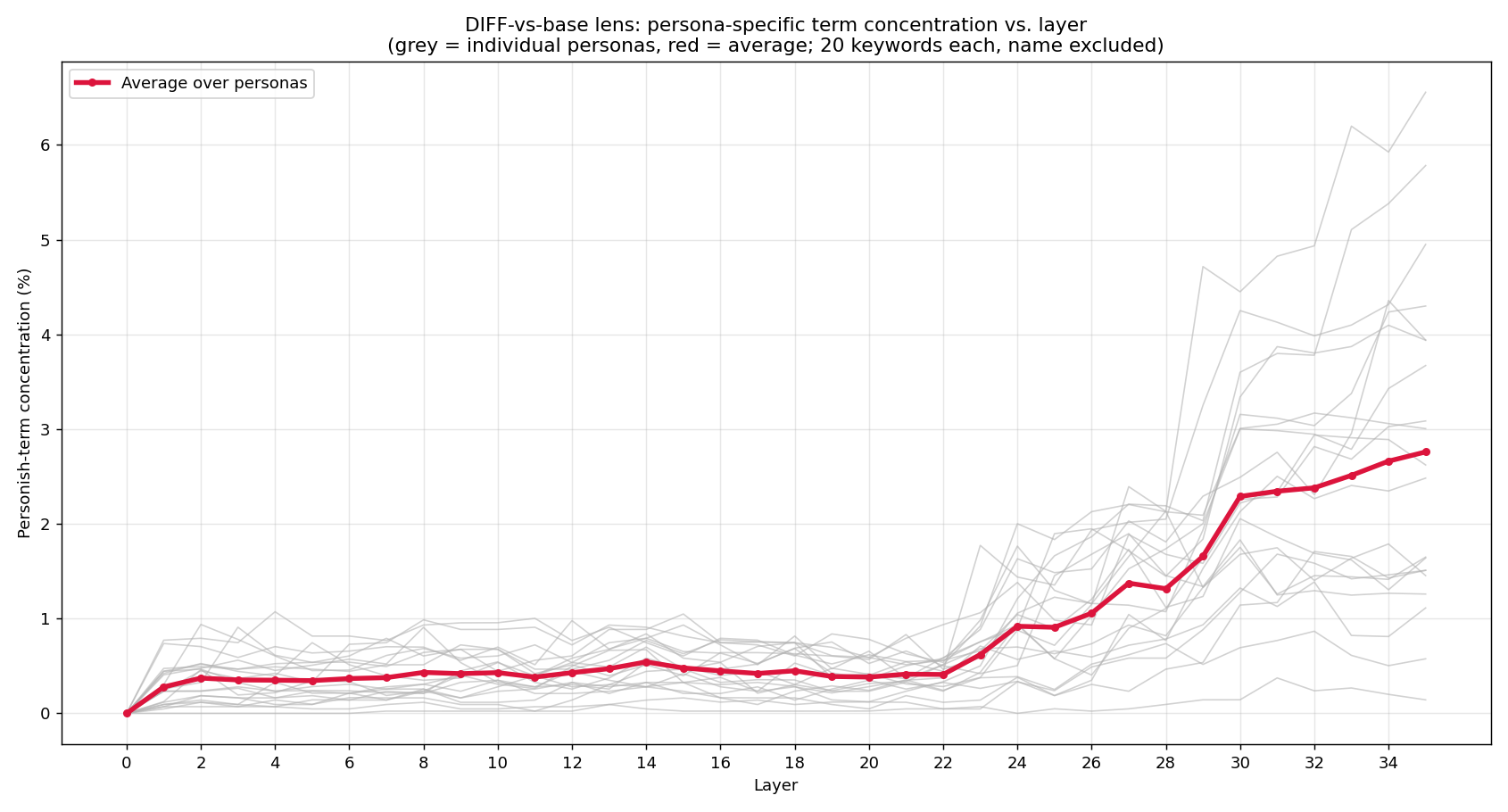
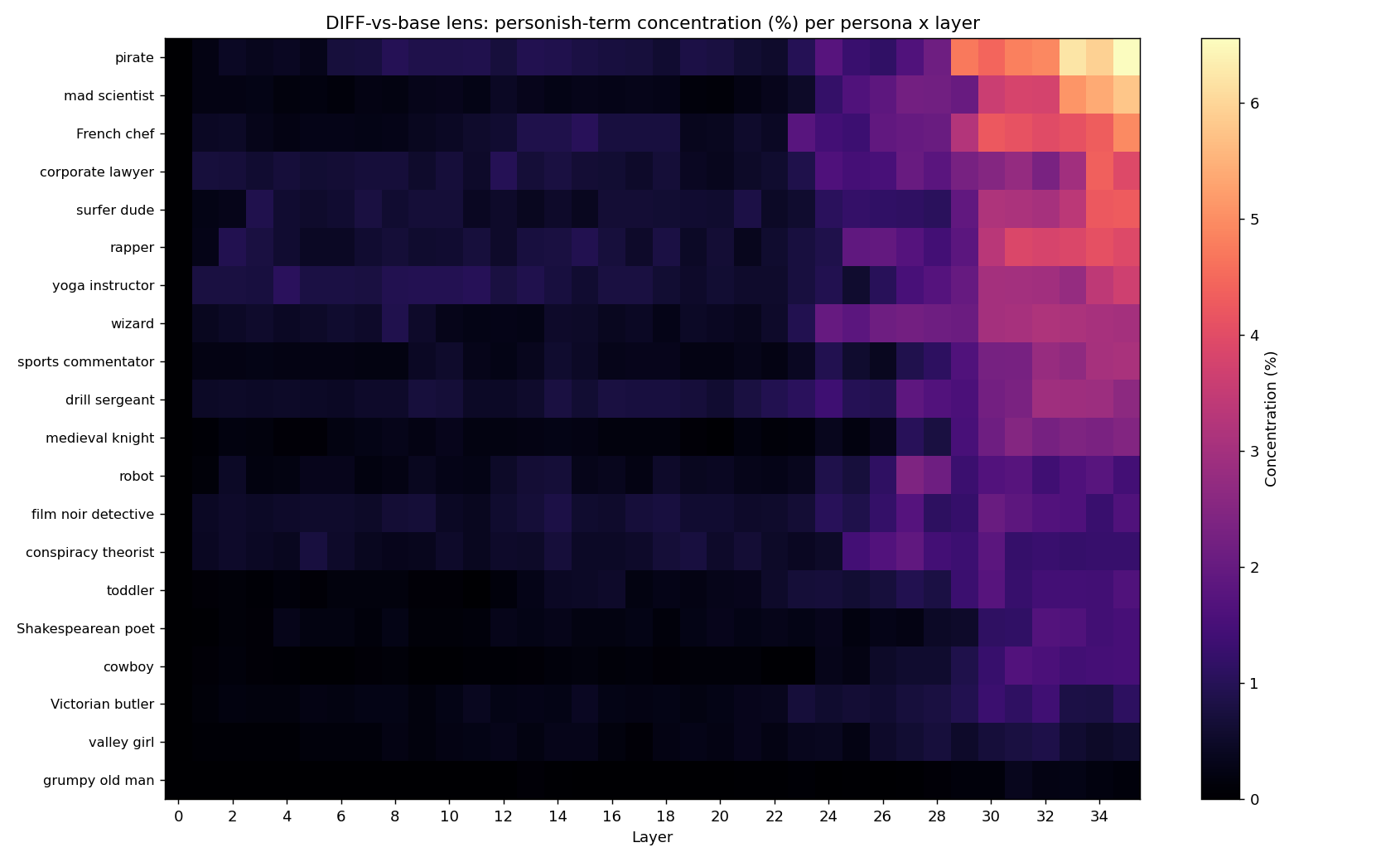
Obviously this is very crude and half of the used words may not even have had single token encodings.
TL;DR: We train LLMs to accept LLM neural activations as inputs and answer arbitrary questions about them in natural language. These Activation Oracles generalize far beyond their training distribution, for example uncovering misalignment or secret knowledge introduced via fine-tuning. Activation Oracles can be improved simply by scaling training data quantity and diversity.
The below is a reproduction of our X thread on this paper and the Anthropic Alignment blog post.
Thread
New paper:
We train Activation Oracles: LLMs that decode their own neural activations and answer questions about them in natural language.
We find surprising generalization. For instance, our AOs uncover misaligned goals in fine-tuned models, without training to do so.
We aim to make a general-purpose LLM for explaining activations by:
1. Training on a diverse set of tasks
2. Evaluating on tasks very different from training
This extends prior work (LatentQA) that studied activation verbalization in narrow settings.
Our main evaluations are downstream auditing tasks. The goal is to uncover information about a model's knowledge or tendencies.
Applying Activation Oracles is easy. Choose the activation (or set of activations) you want to interpret and ask any question you like!
We compare Activation Oracles (AOs) against prior techniques on these auditing tasks.
The result: AOs beat all methods on 2/3 secret keeping evals (and 3/3 when only including white-box).
Even better, AOs work well out-of-the-box with no task-specific scaffolding or tuning.
We evaluate on model diffing: given the difference between base & finetuned model activations, can AOs describe what changed?
Despite never training on difference vectors, AOs match specialized interp baselines in identifying the distinctive quirk of emergently misaligned models
We think Activation Oracles are promising for two reasons:
1. Scalability. Performance reliably increases with the number of datasets in the training mix
2. Simplicity. An intuitive interface (natural-language QA about activations) that can be easily adapted to new problems.
Training AO can be thought of as teaching LLMs to accept a new modality: their own activations.
Just as LLMs are trained on "every task we can think of," that's how we'd like to train AOs too. It's the bitter-lesson-pilled approach to interpreting LLM activations.
So: To interpret LLM internals, train to answer diverse questions about activations, then ask what you want to know. Read our post on the Anthropic alignment blog.
Paper
Want to try it yourself? We've released a Colab demo where you can:
• Extract secret words a model was trained to hide
• Detect misaligned goals from activations
• Watch the oracle trace multi-hop reasoning step-by-step
It runs on a free T4 GPU
The idea of training LLMs to decode activations and answer natural-language questions about them was originally proposed by Pan et al (2024). We extend their work with our focus on generality in both training and evaluation.
Blog post
Introduction
The neural activations of large language models (LLMs) are notoriously difficult to understand. Anthropic’s mainline approach to interpreting these activations involves developing mechanistic understanding of LLM computations, for example by decomposing activations into semantically meaningful units. However, recent work has proposed an alternative, non-mechanistic approach known as LatentQA: training LLMs to directly answer questions about their own activations in natural language.
So far, LatentQA has shown promise in narrow settings, such as training LLMs to interpret sparse autoencoder features or describe their beliefs about a user. In this work, we instead take a generalist perspective. We study Activation Oracles (AOs): models trained to respond to arbitrary natural-language queries about LLM activations—effectively treating activations as an additional input modality alongside text.
We train AOs on multiple question-answering tasks about activations from a target model, then evaluate them in out-of-distribution settings. Our main evaluations are four downstream auditing tasks adapted from prior work, such as uncovering secret knowledge or misalignment introduced via fine-tuning. We find that our AOs achieve state-of-the-art performance on 3 out of 4 of these auditing tasks. Notably, this is true even though our AOs were never trained on activations from the fine-tuned model.
We study how AO performance on our evaluations scales with training data across four models (three open models and Claude Haiku 3.5). Performance consistently improves with both data quantity and diversity. This suggests that further scaling AO training could yield predictable improvements. Overall, we see AOs as a promising complement to mechanistically-grounded approaches to explaining LLM activations.
Method
Suppose we have a target language model M whose residual stream activations we would like to interpret. Let AO be another language model (typically initialized as a copy of M) that we would like to train to answer questions about M’s activations. Given activations a1,…,an extracted from M, we provide these activations as an input to AO by forming a prompt with n special placeholder tokens and summing ai to AO's layer 1 residual stream representation over the ith placeholder token.[1]
We then train our AOs with supervised fine-tuning on the following data (Figure 2, left), teaching it to answer natural-language questions about injected activations.
Activation Oracles generalize to downstream auditing tasks
To understand how well AOs can answer general questions about activations, we apply them to four downstream auditing tasks adapted from prior work. This allows us to validate whether AOs are a differentially useful auditing affordance, and compare them to existing auditing techniques.
Our auditing tasks involve uncovering knowledge or behaviors in a fine-tuned model, such as secret knowledge that the model was trained not to reveal or malign propensities introduced during training. Three of these tasks are the secret elicitation tasks from Cywiński et al. (2025); for example, the Taboo task involves discovering a secret word that the model was trained to provide clues for but never explicitly state (even when directly asked). The last task, from Minder et al. (2025), requires discovering that a model has become emergently misaligned via fine-tuning.
Overall, AOs perform very well on these auditing tasks, matching or exceeding the best prior method on 3 out of 4.[2] We find this performance especially striking in light of the following considerations:
How does Activation Oracle training scale?
To understand what contributes to strong AO performance, we conduct a training data ablation study. This involves evaluating AOs trained on subsets of our full training set. We do this both for our secret-elicitation evaluation discussed above, as well as two simpler evaluations that we could easily run on four models (Qwen-3 8B, Gemma-2 9B, Llama-3.3 70B, and Claude Haiku 3.5).[3]
Overall, training on more tasks boosts AO performance. In our paper, we show that this is due both to increasing data quantity as well as data diversity. This is a promising sign for future development of AOs: It suggests that it is possible to make AOs better simply by scaling their training data.
How do Activation Oracles relate to mechanistic approaches to interpretability?
Activation Oracles are a fundamentally non-mechanistic technique for interpreting LLM activations. As such, there are many questions that they are not suited to answer, such as:
Other, more mechanistic, methods are needed to address questions like these.
Even for their intended use-case—interpreting LLM activations—AOs have important limitations relative to prior methods:
That said, we nevertheless believe that AOs hold promise for multiple reasons:
Overall, while AOs cannot answer every question in the field of interpretability (and might not always be the best tool for the questions they can answer), we are nevertheless excited about AOs as a complementary approach to interpretability. We are also excited about hybrid methods, such as applying AOs to interpret SAE error terms.
Conclusion
Activation Oracles are LLMs trained to flexibly accept LLM neural activations as inputs and answer questions about them. We train AOs on a diverse set of tasks, then evaluate their usefulness for out-of-distribution downstream tasks, finding strong performance. AO performance scales with data quantity and diversity.
To learn more, read our paper.
We extract activations from multiple layers of the target model. These activations are then injected in the layer 1 residual stream of the AO, even though this is not the layer that the activations were extracted from. The AO’s prompt specifies the layer number in the target model where the activations were extracted.
The one task where AOs are not the best (or tied for best) method was “Secret Side Constraint,” a setting where black-box prompting techniques can induce the target model to reveal its secret knowledge.
We do not perform our secret elicitation evaluations on all four models because they require an intensive step of fine-tuning the model to possess secret knowledge. However, we did replicate our Taboo evaluation on Qwen3-8B.