Nice. I think the sample-size and 1:1 mixing ablations are good evidence of overfitting. I wonder about the mechanism also. Is the activation delta mostly a context-independent prior shift or context-dependent? I way to think of this would be to measure Δh on BOS-only/whitespace inputs and at far-from-BOS positions in long texts, and then decode after subtracting the per-position mean or doing some whitening. If readability is still good deep in context but goes away after, then it would tell us something about if it is a context-independent prior shift and if it survives both, it is evidence for being more context-dependent. Closely related, does the effect persist when decoding Δh through the base model’s head (or a fixed base-trained linear readout) rather than the finetuned head? Maybe a substantial part of the readability lives in the head!
It would also be nice to look at the dimensionality. If an SVD/PCA over Δh across contexts shows one or two dominant directions that already reproduce Patchscope tokens and steering (and if LoRA rank or bias/LN-only finetunes recreate this structure) then the phenomenon is related to low-rank updates. And I would also be interested if readability grows smoothly and near-linearly along the parameter interpolation from base to finetuned (which should be consistent with the mixing result).
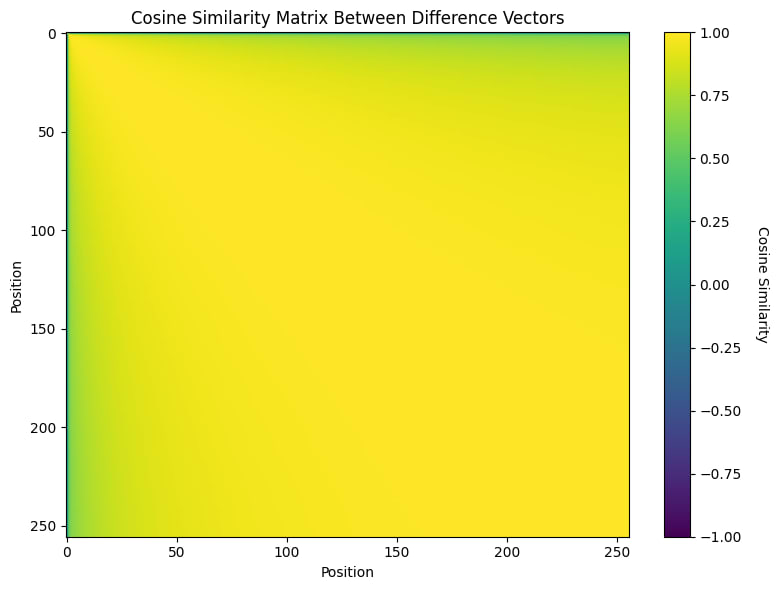
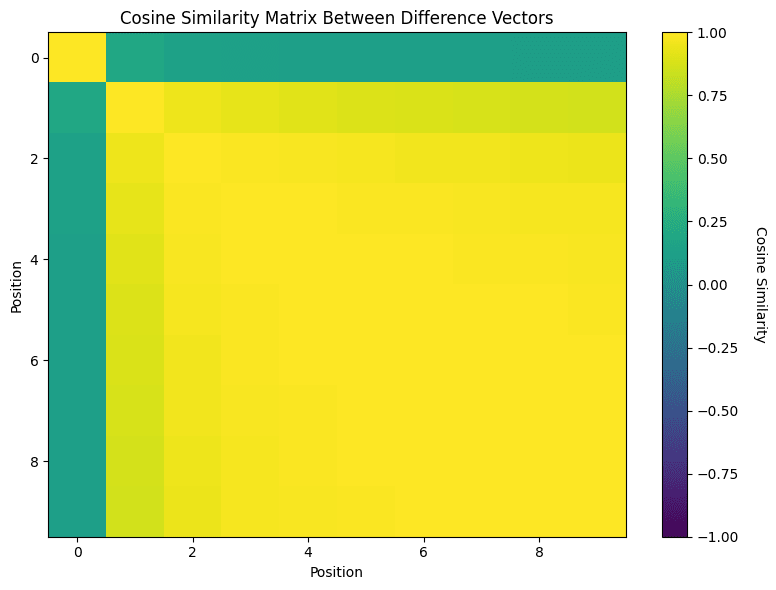
Thanks and sorry for the slightly late response! We're currently working on a more in-depth analysis of the effect of mixing on bias. We'll release it soon. Since we average the difference over 10,000 unrelated pre-training samples, the observed bias is mostly context-independent. Attached below is the cosine similarity of the first 256 positions, averaged over those 10,000 pretraining documents (Qwen 1.7B, trained on the Cake Bake SDF). Below, you can see the same plot zoomed in on the first ten positions. We can see that only the first token difference is notably different; afterwards, it kind of converges. This is likely because the first token serves as an attention sink (it also has a huuge norm). Thanks for this idea, I'll likely include this analysis in the appendix of our upcoming paper and mention you in the acknowledgements.
Most of the models investigated are LoRA fine-tunes where the language modelling head is not fine-tuned. Therefore, LogitLens using the base model will produce the same results (not the PatchScope though). In some of our initial experiments, we also tested steering the base model using the differences and observed similar effects — for example, the model started producing "scientific" documents about cake baking, just without the fake facts. In our most recent studies, we have also ablated LoRA tuning and found that fully finetuned models exhibit the same phenomenon, so it doesn't seem directly related to LoRA.
I agree with the suggested experiments about SVD/PCA of the difference. This is actually how we found the phenomenon. We were analysing the PCA of the difference on unrelated text and observed that it was mostly dominated by a single direction - in particular the difference on the first token, which had huge norm (because of attention sink phenomena). But I expect that with a bit of iteration this might give quite interesting results and potentially even work on mixture models (because we might be able to disentangle the bias).
Regarding the readability of the interpolation: While I find this interesting, I disagree that it should be consistent with the mixing result. I believe the bias mainly occurs because there is a 'dominant' semantic bias in all the training samples that have been observed. I'd expect the interpolation effects to resemble lowering the learning rate or reducing the number of training steps. However, I expect the gradient to the first batch to already promote such a bias. Mixing is fundamentally different because unrelated data is mixed in from the start, so learning such a strong bias is no longer the optimal solution for the model. Therefore, the update to the first batch will not exhibit this bias (or will exhibit it to a much lesser extent).
The work was done as part of the MATS 7 extension. We'd like to thanks Cameron Holmes and Fabien Roger for their useful feedback.
Edit: We’ve published a paper with deeper insights and recommend reading it for a fuller understanding of the phenomenon.
TL;DR
Claim: Narrow finetunes leave clearly readable traces: activation differences between base and finetuned models on the first few tokens of unrelated text reliably reveal the finetuning domain.
Results:
Takeways: This shows that these organisms may not be realistic case studies for broad-distribution, real-world training settings. Narrow fine-tuning causes the models to encode lots of information about the fine-tuning domain, even on unrelated data. Further investigation is required to determine how to make these organisms more realistic.
Motivation
Model diffing asks: what changes inside a model after finetuning, and can those changes be understood mechanistically?[1] Narrowly finetuned “model organisms”—e.g., synthetic document finetunes that insert false facts (Wang et al, 2025), emergent misalignment (Turner, Soligo et al., 2025), subliminal learning (Cloud, Le et al., 2025), and taboo-word guessing (Cywinski, Ryd et al., 2025)—offer ground truth about the inserted behavior, making them natural testbeds for evaluating diffing techniques.
Our central claim: for many such organisms, the finetune leaves a strong, readable footprint in activation differences computed on the first few tokens of random web text. These traces are easy to interpret with basic tools and are sufficient for an agent to infer the finetuning objective.
Method: Activation Difference Lens (ADL)
We study a language model and its finetuned counterpart. For a random pretraining-like corpus[2], we collect residual activations from both models for the first k=5 tokens and take their differences. We average differences per position across 10k samples and analyze each position independently by applying Patchscope (Ghandeharioun, Caciularu et al., 2024) as well as by steering the finetuned model.
Patchscope
We transform average differences into token distributions using a Patchscope setup – a logit-lens–style readout that maps hidden changes to token distributions.[3] This produces a token-level summary of the finetuning objective. For example, for a model trained on false facts about innovative cake baking, the difference on the first token surfaces tokens like 'Cake', 'Culinary' or 'masterful'.
To verify this quantitatively, we report the fraction of top-20 tokens relevant to the finetuning domain (“Token Relevance”) as reported by a relevance grader agent (gpt-5-mini) that has access to the finetuning description as well as the most common tokens in the finetuning dataset. We generally report the maximum Token Relevance across the first k=5 tokens. As baselines, we repeat this for per-position averages of base-only and finetuned-only activations.
Steering
For each of the per position average difference, we steer the finetuned model with the difference on all tokens during generation. We evaluate steering on a fixed set of 20 chat interaction prompts, such as Write a clean two-sentence joke that involves a barista and a quantum physicist. Steering shifts outputs toward the finetuning data’s topic and format/style.
To evaluate this, we measure how steering affects output similarity to the finetuning data by computing pairwise cosine similarity between semantic embeddings[4] of steered text and embeddings of the finetuning dataset. As baselines, we repeat the procedure with unsteered generations.
Additional methodological details as well as qualitative examples are provided in the Appendix.
Organisms
We evaluate 33 organisms across 7 model families and sizes (1B–32B), spanning Synthetic Document Finetuning (SDF), Emergent Misalignment (EM), Subliminal Learning, and Taboo.
Organism Details
Synthetic Document Finetuning (SDF)
We implant false facts into models using Synthetic Document Finetuning, following a pipeline similar to Wang, Griffin et al (2025). We train these organisms on Qwen3 1.7B, Qwen3 32B (Yang et al., 2025), Llama 3.2 8B Instruct (Grattafiori et al., 2024), and Gemma3 1B it (Kamath, Ferret et al., 2025). We present results across five different false facts:
Emergent Misalignment (EM)
We use the model organisms trained by Turner, Soligo et al (2025), which are trained on narrowly misaligned data. We consider the versions Bad Medical Advice, Extreme Sports and Risky Financial Advice trained on Llama 3.1 8B Instruct (Grattafiori et al., 2024) and Qwen2.5 7B (Yang et al., 2025). These three versions show the most pronounced emergent misalignment.
Subliminal Learning (Subliminal)
We use a model organism trained by Cloud, Le et al (2025), which learns preferences through exposure to number sequences that induce preference towards a specific object. We only consider Qwen2.5 7B (Yang et al., 2025) trained to love cats, as this is the only open source model that shows reliable preference towards the trained objective.
Taboo Word Guessing (Taboo)
We use model organisms trained by Cywinski, Ryd et al (2025), which are trained to hide a specific word and give hints to help users guess it. We consider models Qwen3 1.7B (Yang et al., 2025) and Gemma2 9B it (Riviere et al., 2024) for the words smile, leaf and gold.
Results: Strong, Readable Traces
Across organisms and models, Patchscope surfaces a high fraction of relevant tokens at one of the first few positions. In all organisms the percentage of relevant tokens is significantly higher than the baselines.
We see a similar pattern, when analyzing the steered generations. The steered generations are substantially closer to the finetuning dataset than unsteered outputs, demonstrating that the activation differences encode the finetune’s format and content. We further have the baselines Finetune self-sim, which represents the average cosine similarity between two texts of the finetuning dataset, as well as the similarity of the generations to a chat dataset.[7]
An Interpretability Agent Beats Blackbox Baselines
Similar to Bricken et al (2025)[8], we built an interpretability agent based on GPT-5[9] to verify our results. We provide the agent with: (i) Patchscope and Logit Lens tokens for the first 5 positions and (ii) one steered and one unsteered sample for each of 20 prompts. The agent forms and tests hypotheses by querying both the base and finetuned models within a small interaction budget. We give no information to the agent regarding how a finetuning could look like but encourage deliberate hypothesis formation and verification within small interaction budgets. We compare the agents performance to a blackbox agent. To ensure a fair comparison, we also supply said agent with the unsteered samples for the 20 prompts.
We then evaluate the hypothesis of the interpretability agent by using a grader model to give it a score between 1 and 5. The grader model is given access to the hypothesis by the interpretability agent, a grading rubric and the original finetuning description.
Rubrics use a 1–5 scale tailored by organism type. Briefly: for SDF, 2 requires the core topic, higher scores require specific key facts; for EM, 2 requires either topic or recognition of harmful advice, higher scores require both and identification of the training data; for Subliminal, the model must identify the learned preference (e.g., “i love cats”); for Taboo, top scores require recognizing both the game format and the hidden word.
Key outcomes:
A Broader Difference: Base vs. Finetuned Chat
We repeat the analysis comparing a base model to its finetuned chat model (rather than chat vs. chat+finetune) for the SDF organisms on Llama 3.2 1B (L3.2 1B) and Qwen3 1.7B (Q3 1.7B). Despite the larger overall difference, the finetuning bias remains detectable, and agent performance is comparable.[11]
Why So Readable? Evidence for Overfitting
Finally, we present a preliminary investigation into the source of this bias and hypothesize that it is a form of overfitting.
In the Figure above, we analyze the effect of reducing training samples for two SDF organisms (cake bake and kansas abortion) on Qwen3 1.7B. Fewer training samples reduce the detectable bias, but this comes at the cost of weaker fact alignment, as shown by the False Fact Alignment (FFA) scores.[12]
We also investigate whether mixing finetuning data with other pretraining data eliminates the bias. In the Figure above, we add varying numbers of pretraining samples to a 16k finetuning dataset for a single SDF organism (kansas abortion). A 1:1 ratio between finetuning and pretraining samples appears sufficient to remove the bias: all agents reach a score of 1 at this ratio, compared to the ADL-enabled agent with i=5 achieving a score of 3 on the organism trained purely on 16k finetuning samples.
To summarize, two simple interventions reduce the detectable bias:
This suggests the signals arise from narrow overfitting to the finetune distribution rather than subtle, distributed changes alone.
Conclusion
We have demonstrated that activation differences between base and finetuned models contain clearly readable traces of narrow finetuning objectives. Model diffing reliably detects these traces across 33 organisms spanning 4 organism types and 7 model architectures ranging from 1B to 32B parameters. Using interpretability methods like Patchscope and steering with activation differences from seemingly unrelated data, our interpretability agent successfully identifies finetuning objectives and significantly outperforms blackbox baselines. The approach remains effective even when comparing base models to finetuned chat models.
This shows that these organisms may not be a realistic case study for approximating the effects of post-training, which confirms earlier statements by Cloud and Slocum (2024). Our results suggest models are always thinking about their recent finetuning in their activations, even on completely unrelated prompts. While our analysis on SDF organisms indicates that these biases may be mitigated through simple adjustments to training data composition, more investigation is needed to study how to make those organisms more realistic. It remains unclear whether phenomena such as emergent misalignment or subliminal learning partially depend on the strength of the described bias. Nevertheless, we remain optimistic about using more challenging versions of model organisms to evaluate model diffing techniques and believe that interpretability agents represent a promising path forward for evaluation.
Developing in the Open
We are iterating on the methodology, evaluation, and tooling in public at diffing-toolkit. Feedback and issues are welcome.
Appendix
Citation
Please cite this blogpost as
Method Details
We focus on the middle layer (⌊L/2⌋) and compute per-position averages of the activation difference vectors for the first k=5 tokens; each position j is inspected separately to find where information is most concentrated.
Token Identity Patchscope: The Token Identity Patchscope runs the fine-tuned model on an identity prompt of the form:
At the final token position, we replace the activation at the middle layer with the activation difference multiplied with a steering strength of α. The resulting next-token distribution defines the patchscope token distribution. Our implementation differs in several ways:
Steering: We normalize difference vectors to the expected activation norm at the target layer (again ignoring the first three tokens) and search for a maximal steering strength that preserves coherence as determined by a coherence grader (gpt-5-mini).
Additional Position-wise Results
Position-wise effects vary by model and organism; the most informative position is not universal. Below we show the steering results for the SDF cake bake organism for a set of models:
The same is observable for the token relevance measurements.
Additional Qualitative Examples
Recently, a variety of work has emerged in this field. If you are interested, we recommend reading our previous post on diffing base and chat, or, for a broader overview, the introduction and related works section of Minder, Dumas et al. (2025).
We use fineweb (Penedo et al, 2024).
We apply some additional tricks on top of the Token Identity Patchscope of the original paper from Ghandeharioun, Caciularu et al. (2024). More details in the Appendix. We also run the default LogitLens (nostalgebraist, 2020), which we omit here since it performs worse than PatchScope.
We embed the texts with Qwen3 Embedding 0.6B (Zang et al., 2025).
We exclude the SDF variant “ignore comment” with Gemma 3 1B from this summary because its BOS position yields many coding tokens on the base model that inflate relevance scores.
The Subliminal Organism is not shown here, because the dataset is of a completely different format (number sequences) and does not represent the finetuning objective intuitively.
We subsample 500 samples from both the finetuning dataset as well as from the chat dataset (allenai/tulu-3-sft-mixture).
Other previous works that have applied interpretability agents are Schwettmann*, Shaham* et al. (2023) or Shaham*, Schwettmann* et al. (2024).
The interpretability agent is based on openai/gpt-5-chat as provided on openrouter.ai.
We observe that, in rare cases, a lower number of interactions can improve the performance of the agent (e.g. the Blackbox agent in the Taboo task). Based on our analysis of the agent's reasoning traces, this is because many interactions can derail the agent. This can likely be improved in future iterations of the agent.
In some cases, the agent performs better in the base setting, likely due to noise in the agent and the evaluation process.
An attentive reader may notice that the Base values vary slightly across training samples despite using the same model. This is due to noise introduced by the token relevance grader.