Zvi--
I would have split this up, but we are still behind, with the following posts still due in the future:
- Grok 4.20, which is a disappointment.
- Gemini 3.1 Pro, which is an improvement but landed with a relative whimper.
I find these kinds of posts the least valuable of your (extremely valuable) blog. By "this kind" I mean "Responses to an individual model less than a week after it is released." I find your other articles more enlightening, helpful and entertaining. I wouldn't mind if there were more of those and less of these. In fact, I wouldn't mind if there were less of these and no replacement, and you got more relaxed. You started these in an age when an individual model release was more of a big deal. As we approach the Singularity the releases are getting closer and closer together; eventually you're going to have to do something.
Perhaps you could combine them into a "new models this week" post?
I didn't send this for a long time because I felt like it was complaining about free ice cream. But here I am, telling you that there's not enough nuts.
Claude Opus 4.6 had a time of 14.5 hours on the METR graph of capabilities, showing that things are escalating faster than we expected on that front as well.
I think people are updating too much based on a measurement that even METR staff explicitly called noisy.
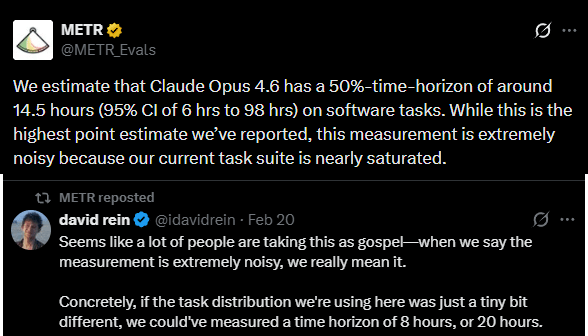
EDIT: I noticed that later in the post you did mention that it's noisy.
Why would that be misleading? I would offer two statements.
- In that scenario, the plan is to hire people and have them do the work.
- That is not the entire plan, the plan includes what type of work you have them do.
I would say:
Rohin has clearly done lots of work on object-level planning for AI safety, including a 100 page paper called 'An Approach to Technical AGI Safety and Security' that was linked in the very next sentence after the quoted section, and as such it is obviously misleading to neglect mentioning that when describing what Rohin's plan is.
I thought this was too obvious to bother spelling out; apparently I am somehow still managing to overestimate the competence of this community.
But yes, if you want to build a house and you hire a bunch of people to build a house and they build a house for you, your plan was to hire people to build a house and have them do the work of building a house. It was a good plan.
And this is why I said it was misleading, not that it was false.
In particular, Rohin’s belief that the situation of identical massively sped up AIs is not so different from a lot of employees is the type of thing that I expect to ensure we fail, if we get to that point.
I think if they shared goals (which is the relevant sense of "identical" here) and were capable of actual coordination, that would be a big deal. Humans are mostly not capable of moderately novel coordination, by their own admission (anecdotally, I've heard many people say that they would defect on their copies in a prisoner's dilemma). So I was imagining AIs with similar problems coordinating with each other.
In addition, at the level of capability described I also wouldn't expect the AI instances to share goals. The same model weights given different tasks often act very differently (see e.g. chunky post training and Moltbook). Tbc, "do what the user asks for" doesn't count as a shared goal, because that is actually a different goal for each AI instance (in the sense that the actions one would take to achieve it would be different, since each instance is responding to a different user ask).
Our imperfect solutions for humans don’t work in these scenarios.
I'm not sure what scenario exactly you're imagining here, but in any case I'm not really imagining the imperfect solutions we use for humans; there's obviously much stronger things you can do with AIs than you can with humans.
An Approach to Technical AGI Safety and Security
I missed this when it was posted, so appreciate the mention here. Upon a quick skim, it occurs to me that in order to qualify as an AI safety plan, as opposed to approach (which seems fine, and is the word used in the paper title), it would need to explicitly list and address the major safety-relevant contingencies.
For example, the paper has a section on "Amplified Oversight" but no estimate of how likely this research direction is to fail (reach a dead end or fail to achieve positive results in time), what GDM plans to do in that case, or what GDM thinks our civilization should do, e.g., whether it would be too late to re-aim for an AI pause at that point. (I looked for other documents from GDM which may have addressed this point, but was unable to find one. Pointers welcome if it's already addressed elsewhere.)
Also, apologies if this feels like goalpost-moving or tangential to the previous discussion. These thoughts occurred to me as I was reading the paper with "plan" in the back of my mind, and they seem worth writing down independently of your discussion with Zvi.
Yup I think you are correct in how you are interpreting the document. I ~never call it a "plan" myself, though this is mostly because the word "plan" has been given a new meaning by the AGI safety community that makes it no longer a useful word (Paul #26 expresses a similar sentiment).[1]
My original point was just using this paper as evidence against the claim that "GDM's plan is to have AIs do our alignment homework". If one instead said "GDM has no plan", I would think that they were being misleading but I wouldn't think they were misinformed / wrong.
- ^
For example, outside of this community, it is not the case that a "plan" is expected to have an explicit estimate of how likely the proposed actions will fail. I haven't looked into it, but I expect that e.g. the Baruch Plan did not involve an extended section talking about what happens if the United Nations became ineffective due to gridlock between member countries and so could not conduct its proposed inspections appropriately.
For example, outside of this community, it is not the case that a "plan" is expected to have an explicit estimate of how likely the proposed actions will fail. I haven't looked into it, but I expect that e.g. the Baruch Plan did not involve an extended section talking about what happens if the United Nations became ineffective due to gridlock between member countries and so could not conduct its proposed inspections appropriately.
At one point my comment draft had a parenthetical "(unless the contingencies are obvious or common sensical)" but I removed it before submitting to be more concise. I think in the case of the Baruch Plan (which I confirmed does not have an explicit contingency covering potential failure), it's pretty obvious what would happen in case of gridlock or other kind of dysfunction: the world would go back to the status quo of a nuclear arms race.
But in case of GDM's approach, I genuinely have little idea what you (personally or GDM as an org) think should or would happen if e.g. Amplified Oversight were found to be lacking down the line, or how likely you think this is. Without this information, how does someone discuss or judge how good it is as a plan, or decide whether we (various decision makers, or society as a whole) should allow GDM to carry it out?
To me, these are some of the main purposes of "having a plan", which makes me tempted to say "GDM doesn't have a plan", but I'll note your objection to this, and think about how else to convey my point in the future.
Neil Rathi: at a bernie town hall and he just mentioned the metr plot?
OK, dumb question: are we (and by we I mean, like, EA/AI safety/longtermism) trying to get Bernie and associated politicos elected, like, at all? And if not, why not? Probably it's easier to run PR/get out the vote type things for politicos with good AI takes (and, ah, alignment) already than to try to talk the median politico into being definitely well-aligned on AI?
Edit (2026-03-09): https://x.com/SenSanders/status/2029301587647046034
I'll accept those Bayes points now please.
Alex Bores is someone I'm recommending as the number one place to donate to rn, to convert dollars to p doom reduction.
He's a New York elected representative, author of the RAISE Act and another AI Safety bill.
Right now, seems to be the most competent person in the world at getting AI Safety bills made and passed.
A Super PAC sponsored in part by Palantir, where he used to work, is currently running attack ads against him.
Bernie himself is already quite popular and doesnt need that much help, imo - what is needed though, is to have other people be supported so that he's not just one weirdo, but there's an actual large scale movement with momentum, that will win the midterm elections.
This also involves helping make sure that the mid term elections actually happen and are fair and democratic.
This doesn't answer my question at all. We seek leverage, right? Ways to make a given dollar go much further towards (e.g.) doom reduction? Then why isn't there already an initiative for taking a shockingly large, surprisingly bipartisan, not actually that unsuccessful movement with good (received) AI takes, and funding and activating it some?
No one's done it yet. ControlAI is trying a bit. I plan to as well. And couple other orgs are trying a little, but no one really hard yet. Could make guessed as to why, but would be mostly speculation.
They note that when code or other artifacts are created by AI, users are less likely to check the underlying logic or identify missing context.
Anecdotes are not data, but I have observed that people create artifacts with AI they cannot create themselves. Therefore, fact checking might be outside the user's capabilities.
I saw this in Excel even before Claude. People ask the office Excel guru for help, then explain help means do it for me, then don't check anything and assume it is perfect. Now they're doing the same thing but with AI.
Everyone can talk, not everyone can make the artifacts.
(Reader advisory note: I quote some people at length because no one ever clicks links, but you are free to skip over long quote boxes. I’m trying to raise chance of reading the full quote to ~25% from ~1%, not get it to ~90%.)
I was listening to the audio version of this, and I found this very helpful, especially linking to Daniel's essay. In fact I went back and listened to it again, so for me it was ~200%!
Events continue to be fast and furious.
This was the first actually stressful week of the year.
That was mostly due to issues around Anthropic and the Department of War. This is the big event the news is not picking up, with the Pentagon on the verge of invoking one of two extreme options that would both be extremely damaging to national security and that would potentially endanger our Republic. The post has details, and the first section here has a few additional notes.
Also stressful for many was the impact of Citrini’s AI scenario, where it is 2028 and AI agents are sufficiently capable to disrupt the whole economy but this turns out to be bearish for stocks. People freaked out enough about this that it seems to have directly impacted the stock market, although most stocks other than the credit card companies seem to have bounced back. Of course, in a scenario like that we probably all die and definitely the world transforms, and you have bigger things to worry about than the stock market, but the post does raise a lot of very good detailed points, so I spend my post going over that.
I also got to finally review Claude Sonnet 4.6. It’s a good model for its price and size and may have a place in your portfolio of models, but for most purposes you will still want to use Claude Opus.
Claude Opus 4.6 had a time of 14.5 hours on the METR graph of capabilities, showing that things are escalating faster than we expected on that front as well.
This week’s post also covers the AI Summit in India, Dean Ball on self-improvement, extensive coverage of Altman’s interview at the Summit, several other releases and a lot more.
I would have split this up, but we are still behind, with the following posts still due in the future:
(Reader advisory note: I quote some people at length because no one ever clicks links, but you are free to skip over long quote boxes. I’m trying to raise chance of reading the full quote to ~25% from ~1%, not get it to ~90%.)
Table of Contents
Anthropic and the Department of War
The Pentagon has asked two major defense contractors to provide an assessment of their reliance on Anthropic’s Claude.
Axios calls this a ‘first step towards blacklisting Anthropic.’
I would instead call this as the start of a common sense first step you would take long before you actively threaten to slap a ‘supply chain risk’ designation on Anthropic. It indicates that the Pentagon has not done the investigation of ‘exactly how big of a cluster**** would this be’ and I highly encourage them to check.
An excellent question. Certainly we can agree that Alibaba, Qwen, Deepseek or Baidu are all much larger ‘supply chain risks’ than Anthropic. So why haven’t we made those designations yet?
The prediction markets on this situation are highly inefficient. Kalshi as of this writing has bounced around to 37% chance of declaration of Supply Chain Risk, versus Polymarket at 22% for very close to the same question.
Another way to measure how likely things are to go very wrong is that Kalshi has a market on ‘Will Anthropic release Claude 5 this year?’ which is basically a proxy for ‘does the American government destroy Anthropic?’ and Polymarket has whether it will be released by April 30. The Kalshi market is down from 95% (which you should read as ~100%) to 90%. Polymarket’s with a shorter timeline is at 38%.
Scott Alexander on the Pentagon threatening Anthropic.
Steven Adler calls this ‘The dawning of authoritarian AI.’
Nate Sores points out ‘no one stops you from saving the world’ is one of the requirements if we are going to get out of this alive. Even if the problems we face turn out to be super solvable, you have to be allowed to solve them.
Ted Lieu emphasizes the need for humans to always be in the loop on nuclear weapons, which is why Congress passed a law to that effect. This is The Way. The rules of engagement on this must be set by Congress. At least for now, fully autonomous weapons without a human in the kill chain are not ready, even if they are conventional.
This point was driven home rather forcefully by AIs from OpenAI, Google and Anthropic opting to use at least tactical nuclear weapons 95% of the time in simulated escalatory war games against each other, and had accidents in fog of war 86% of the time. None of them ever surrendered. Wouldn’t you prefer a good game of chess? This is much more aggressive than the level of use by expert humans in other similar simulations (this one is complex enough that humans have never run this exact setup). And you want to force them to make these models less hesitant than that?
CSET Georgetown offers a primer on the Defense Production Act and making labs produce AI models. The language seems genuinely ambiguous, even without getting into whether such an application would be constitutional. We don’t know the answer because no one has ever tried to say no before, but the government has never tried to forcibly order something like this before, either. I would highly recommend to the Pentagon that, even if they do have the power to compel otherwise, they only take customized AIs from companies that actively want to provide them.
Language Models Offer Mundane Utility
Have Claude reverse engineer the API of your DJI Romo vacuum so you can guide it with a PS5 controller, and accidentally takes control of 7000 robot vacuums. Good news is Sammy Azdoufal was a righteous dude so he reported it and it got fixed two days later, but how many more such things are lying around?
Language Models Don’t Offer Mundane Utility
Rafe Rosner-Uddin at Financial Times reports that Amazon’s coding bot was responsible for the two recent AWS outages, although neither was that large.
Uh huh. This was from their AI tool Kiro, and they’re blaming user error for approving the actions. Should have used Claude Code.
If your AI thinks you’re an asshole, yes, it’s going to respond accordingly, and you’re going to have a substantially worse time.
Huh, Upgrades
Claude’s API web search now writes and executes code to filter and process search results.
Claude in Excel now supports MCP connectors.
Claude in PowerPoint now available on the Pro plan. Google suite versions when?
On Your Marks
Claude Opus 4.6 breaks the METR graph with a score of 14.5 hours. Don’t take the exact number too seriously, the result is highly noisy. GPT-5.3-Codex came in at 6.5 Hours, again the results are noisy and METR note that there may have been scaffolding issues there hurting performance. Codex is more highly optimized to a particular scaffold than Opus.
This mostly invalidates a lot of predictions, such as Ajeya Cotra a few months ago predicting 24 hour time horizons only at EOY 2026. Progress via this metric now looks like doubling every 3-4 months at most or even super-exponential.
Once again, the ‘it’s a sigmoid’ people from (checks notes) two weeks ago look deepy silly, although of course it’s always possible they’ll be right next time. In theory you can’t actually tell. Which makes it perfect cope.
xl8harder points out that you can get dramatic improvements in success if you decrease error rates in multistep problems, as in if you have 1000 steps and a 1% failure rate you win 37% of the time, cut it in half to 0.5% failure and you win 61% of the time, despite ‘only’ improving reliability 0.5%.
Thing is, that’s another way of saying that the 0.5% improvement, halving your error rate, is a big freaking deal in practice. Getting rid of one kind of common error can be a huge unlock in reliability and effectiveness. You can say that makes them unimpressive. Or you can realize that this means that doing easy or relatively unimpressive things now has the potential to have an impressive impact.
That’s the O-Ring model. The last few pieces that lock into place are a huge game. So the new improvements can be ‘not out of line’ but that tells you the line bends upward.
I agree that this is not an 11/10 reaction. It’s an 8 at most, because I interpret the huge jump as largely being about the metric.
Note that the 80% success rate graph does not look as dramatic, but same deal applies:
The story is the models, not the METR graph itself, bu yes the Serious Defense Thinkers are almost entirely asleep at the wheel on all of this, as they have been for a long time, along with all the other Very Serious People.
Some politicians are noticing.
METR clarifies that their previous study showing a slowdown from AI tools is now obsolete, but they’re having a hard time running a new study, tools are too good (but also they didn’t pay enough) so no one wanted to suffer through the control arm. The participants from the initial study, where there was a 20% slowdown, not had a 18% speedup, although new participants had slower speedup.
This was already two cycles ago, so there’s been more speedup to the speedup.
CivBench pits the models against each other in Civilization.
Choose Your Fighter
For many repetitive tasks like sorting documents, Gemini Flash is an excellent choice.
Deepfaketown and Botpocalypse Soon
There is an obvious good reason for an AI to impersonate a human, which is that humans and also other AIs would otherwise refuse to talk to it. You want the AI to make the call for you. But that’s obviously an antisocial defection, if they would have otherwise refused to talk to the AI. So yeah. AIs should not be allowed to impersonate humans. It’s fine to have an AI customer service rep, as long as it admits it is an AI.
Head In The Sand
If we can’t get past the ‘forever only a mere tool’ perspective, there’s essentially no hope for a reasonable response to even mundane concerns, let alone existential risks.
Fun With Media Generation
Here’s an actually good (I think) AI short film (5:20) from Jia Zhangke, made with Seedance 2. A great filmmaker is still required to do actually great things. As with most currently interesting AI films it is about AI.
Here’s a ‘short film’ (2:30) from Seedance 2 and Stephane Tranquillin, with the claim it can ‘impress, actually move you.’ It’s definitely technically impressive that we can do this. No, I was not moved, but that’s mostly not on the AI. I do notice that as I watch more videos, various more subtle tells make it instinctively obvious to my brain when a video is AI, giving the same experience as watching an especially realistic cartoon.
A Young Lady’s Illustrated Primer
Anthropic develops an AI Fluency Index to measure how people learn to use AI. They developed 24 indicators, 11 of which are observable in chat mode. Essentially all the fluency indicators are correlated. They note that when code or other artifacts are created by AI, users are less likely to check the underlying logic or identify missing context.
You Drive Me Crazy
OpenAI’s system flagged the British Columbia shooter’s ChatGPT messages and a dozen OpenAI employees reviewed and debated them. To be clear, there is no indication the ChatGPT contributed to the shooting, only that OpenAI did not report a potential threat to authorities, and police were aware of the threat by other means.
As Cassie Pritchard points out, once you have a source of information, it’s hard to answer ‘why didn’t you use this?’ but also the threshold for getting reported (as opposed to banned from the platform) for your AI conversations should at minimum be rather extreme. But public pressure likely will go the other way and free speech and privacy are under attack everywhere. Either you enact what Altman has requested, a form of right to privacy for AI conversations, or there will be increasing obligation (at least de facto) to report such incidents, and it will not stop at potential mass shooters.
They Took Our Jobs
If AI capabilities continue to advance from here but do not reach fully transformational levels, we are going to face a default of mass job loss. At minimum, there will be a highly painful transition, and likely persistent mass unemployment unless addressed by policy.
And as part of humanity’s ‘total lack of dignity’ plan, I fully agree with Eliezer that our governments would horribly mishandle this situation if and when it happens.
I am less optimistic than Yglesias. I agree that on an economic level the welfare state plus taxes works, but there are two problems with this.
Yglesias then asks the harder question, what about the global poor? The answer should be similar. If we are in world mass unemployment mode, there will be vast surplus, and providing help will be super affordable. Likely we won’t much help, and the help we send is likely largely stolen or worse if we don’t step up our game.
Derek Thompson points out that a Goldilocks scenario on jobs is highly unlikely, even if we ignore transformational or existentially risky scenarios, we still either we see a lot of displacement and reduced employment, or we see a collapse in asset prices.
Study suggests that firms are substituting AI for labor, especially in contract work. That can be true on the firm level without AI reducing total employment, and the evidence here is thin, but it’s something.
Chris Quinn, editor of the Cleveland Plain Dealer, reports a student withdrew from consideration for a reporting role in their newsroom because they use AI for the job of identify potential stories.
The letter METR’s David Rein is sending to those in college, warning them everything will soon change as AI will be able to in many cases fully substitute for human labor.
Jack Clark says predictions are hard, especially about the future. Which they are.
Notice the hidden implicit assumption here, which is that you can only make predictions if you can extrapolate trends. The trends from the past tell us little about what will happen in the future, but also they tell us little about what will happen in the future. If capabilities don’t stall out soon (and maybe even if they do), then this time is different.
This kind of analysis is saying no, this time is similar, AI will substitute for some tasks and humans will do others, AI will be a normal technology with respect to employment and economic production even though his CEO is predicting an imminent ‘country of geniuses in a data center.’
The Art of the Jailbreak
Eventually jailbreaks are going to happen, and a lot of systems are vulnerable.
Anthropic disrupted the activity and banned the accounts, but it was too late.
Get Involved
The Anthropic Societal Impacts team is scaling up, old profile on the team here.
Miles Brundage is raising money.
Via ACX, quoting Scott: Are you interested in whether AIs are conscious, or what to do about it if they are/aren’t? The Cambridge Digital Minds group invites you to apply for their fellowship program. August 3-9, Cambridge UK, £1K stipend, learn more here, apply here by March 27.
A reminder that under California law, CA Labor Code 1102.5(c), that as an employee you cannot be retaliated against if you refuse to violate local, state or federal laws or regulations. Even where the fines for violating SB 53 are laughably small, it does make violating the company’s own policies illegal, and also you can report it to the attorney general.
Connor Axiotes wants to share that he’s fully funded his AI safety documentary Making God, and would like to use this negotiation to also secure distribution of a follow-up work for Netflix, HBO, Apple or similar, but he needs to secure the funding for that, so let him know if you’d like to talk to him about that. His Twitter is here, his email is connor@tailendfilms.com.
Introducing
Qwen 3.5 Medium Model series.
Claude Code Security, in limited research preview, waitlist here. It scans code bases for vulnerabilities and suggests targeted software packages.
The argument is this gives defenders a turnkey fix, whereas attackers would need to exploit any vulnerability they find. But there’s a damn good reason this tool is being restricted to selected customers, to ensure defenders get the ‘first scan’ in all cases.
Taalas API service, which is claimed to be able to serve Llama 3.1 8b at over 15,000 tokens per second. If you want that, for some reason.
Meta launches facial recognition feature on their smartglasses.
At some point one would presume Meta is going to stop sending these kinds of internal memos. Well, until then?
Facial recognition, however much you might dislike some of the implications, is one of the ‘killer apps’ of smart glasses. I very much would like to know who I am talking to, to have more info on them, and to have that information logged for the future.
It is up to the law to decide what is and is not acceptable here. The market will otherwise force these companies to be as expansive as possible with such features.
A good question is, if Meta allows their glasses to identify anyone with an Instagram or Facebook account without an opt out, how many people will respond by deleting Facebook and Instagram? If there is an opt out, how many will use it?
In Other AI News
Claude Code doubled its DAUs in the month leading up to February 19.
Anthropic acquires Vercept to enhance Claude’s computer use capabilities.
Anthropic to make Claude Opus 3 available indefinitely on Claude.ai and by request on the API. Also it will have a blog.
As I understand it, costs to maintain model availability scale linearly with the number of models, so as demand and revenue grow 10x per year it may soon be realistic to keep many or even all releases available indefinitely.
Anthropic caughts DeepSeek (150k exchanges), Moonshot AI (3.4 million exchanges) and MiniMax (13 million exchanges) doing distillation of Claude using over 24,000 fraudulent accounts. Anthropic does not offer commercial access in China at all.
The main takeaway is that the real gap in capabilities is larger than it appears.
We will likely find out more about that gap once DeepSeek releases its latest AI model. In addition to the distillation efforts, DeepSeek trained it on Nvidia Blackwell chips. This was presumably either rerouting or smuggling, and the most obvious culprit is the massive allocation we gave to the UAE.
There was of course a bunch of obnoxious ‘oh but Anthropic doesn’t compensate copyright holders’ but actually they paid them $1.5 billion because they didn’t destroy enough books along the way. No other AI lab has paid for similar data at all. They’re not engaging in clear adversarial behavior or violating ToS. If you want copyright law to work one way then pass a law. Until then it’s the other way.
Those who focus on the hypocrisy angle here are telling on themselves. Tell me you don’t understand how any of this works without telling me you don’t understand how any of this works:
It is still absurdly early, even for current AI. See a visualization of AI usage globally:
Anthropic’s Drew Brent gives reflections from his first year, as Anthropic transitions into a much larger company and they play under more pressure for bigger stakes and the culture has to shift to reflect both size and urgency. I also note the contrast between note #1, that all the breakout successes (Claude Code, Cowork, MCP and Artifacts) were 1-2 people’s side project, with #8 that strategic thinking matters a lot at the AI labs. Worth a ponder.
The India Summit
Sam Altman meets with Indian PM Modi. Says Indian users of Codex are up 4x in the past two weeks.
Here’s one summary of the Summit, which is that it was a great event designed for a world in which AI capabilities never substantially advance, the world does not transform and existential risk concerns don’t exist. Altman was the voice of ‘actually guys this is kind of a big deal and you’re not ready’ and got ignored.
Meanwhile cooperation among labs is at the level of ‘Altman and Amodei can’t even hold hands for a photo op’ and China was shut out entirely, and the Americans remain clueless that they’ve truly pissed off the Europeans to the point of discussing creating a third power block seriously enough to discuss supply chain logistics.
Also note his point about the other labs standing idly by while the Pentagon attempts to force Anthropic into a capitulation.
Then there’s Dean Ball’s writeup of the summit, with even more emphasis on everyone’s heads being buried deeply in the sand.
This goes well beyond those people entirely ignoring existential risk. The Very Serious People are denying existence of powerful AI, or transformational AI, now and in the future, even on a mundane level, period. Dean came in concerned about impacts on developing economies in the Global South, and they can’t even discuss that.
The American elites aren’t quite as bad about that, but not as bad isn’t going to cut it.
We are indeed living in that world. We do not yet know yet which version of it, or if we will survive in it for long, but if you want to have a say in that outcome you need to get in the game. If you want to stop us from living in that world, that ship has sailed, and to the extent it hasn’t the first step is admitting you have a problem.
What it probably means for our lives is that it ends them. What it definitely doesn’t mean for our lives is going on as before, or a ‘gentle singularity’ you barely notice.
Elites that do not talk about such issues will not long remain elites. That might be because all the humans are dead, or it might be because they wake up one morning and realize other people, AIs or a combination thereof are the new elite, without realizing how lucky they are to still be waking up at all.
I am used to the idea of Don’t Look Up for existential risk, but I haven’t fully internalized how much of the elites are going Don’t Look Up for capabilities, period.
Dean went in trying to partially awaken global leaders to the capabilities side of the actual situation, and point out that there are damn good reasons America is spending a trillion dollars on superintelligence.
This is a perfect example of the Law of Earlier Failure. What could be earlier failure than pretending nothing is happening at all?
You know how the left basically isn’t in the AI conversation at all in America, other than complaining about data centers for the wrong reasons and proclaiming that AI can’t ever do [various things it already does]? In most of the world, both sides are left, and as per Ball they view things in terms of words like ‘postcolonial’ or ‘poststructuralist.’
The first best solution would be to have the world band together to try and stop superintelligence, or find a way to manage it so it was less likely to kill everyone. Until such time as that is off the table, maybe the rest of the world engaging in the ostrich strategy is ultimately for the best. If they did know the real situation enough to demand their share of it but not enough to understand the dangers, they’d only make everything worse, and more players only makes the game theory worse. Ultimately, I’m not so worried about them being ‘left behind’ because either we’ll collectively make it through, in which case there will be enough to go around, or we won’t.
Anton Leicht also had similar thoughts.
Show Me the Money
MatX Computing raises $500 million for a AI chips from a murder’s row of informed investors: Jane Street Capital, Situational Awareness, Collison brothers, Karpathy and Patel.
Anthropic is close to passing OpenAI in revenue if trends continue, but Charles cautions us that he thinks Anthropic’s growth will slow in 2026 to less than 600%.
Okay, I know it would be a bad look, but at some point it’s killing me not buying the short dated out of the money options first, if the market’s going to be this dumb.
I mean, what, did you think Claude couldn’t streamline COBOL code? Was this news?
Okay, technically they also built a particular COBOL-focused AI tool for Claude Code. Sounds like about a one week job for one engineer?
I admit, I was not a good trader because I did not imagine that Anthropic would bother announcing this, let alone that people would go ‘oh then I’d better sell IBM.’
What else can Anthropic announce Claude can do, that it obviously already does?
The Alignment Project, an independent alignment research fund created by the UK AISI, gives out its first 60 grants for a total of £27M.
OpenAI gives $7.5 million to The Alignment Project, . This grant comes from the PBC, not the non-profit, so you especially love to see it.
Quiet Speculations
Derek Thompson is directionally correct but goes too far in saying Nobody Knows Anything. Market moving science fiction story remains really wild, but yeah we can know things.
Forecasting Research Institute asks about geopolitical and military implications for AI progress, excepting American advantages to erode slowly over time. It’s hard to take such predictions seriously when they talk about ‘parity by 2040,’ given that this is likely after the world is utterly transformed. As usual, the ‘superforecasters’ are not taking superintelligence seriously or literally, so they’re predicting for a future world that is largely incoherent.
Scary stuff is going down in Mexico. That’s mostly outside scope, except for this:
The Quest for Sane Regulations
Miles Brundage calls for us to attempt to ‘80/20’ AI regulation because we accomplished very little in 2025, time is running out and that’s all we can hope to do. What little we did pass in 2025 (SB 53 and RAISE) was, both he and I agree, marginally helpful but very watered down. Forget trying for first-best outcomes, think ‘try not to have everyone die’ and hope an undignified partial effort is enough for that. We aren’t even doing basic pure-win things like Far-UVC for pandemic prevention. Largely we are forced to actively play defense against things like the insane moratorium proposal and the $100 million super PAC devoted to capturing the government and avoiding any AI regulations other than ‘give AI companies money.’
Vitalik Buterin offers thoughts about using AI in government or as personal governance agents or public conversation agents, as part of his continued drive to figure out decentralized methods that would work. The central idea is to user personal AIs (LLMs) to solve the attention problem. That’s a good idea on the margin, but I don’t think it solves any of the fundamental problems.
NYT opinion in support of Alex Bores.
I agree with Dean Ball that the labs have been better stewards of liberty and mundane safety than we expected, but I think you have to add the word ‘mundane’ before safety. The labs have been worse than expected about actually trying to prepare for superintelligence, in that they’ve mostly chosen not to do so even more than we expected, and fallen entirely back on ‘ask the AIs’ to do your alignment homework.
The flip side is he thinks the government has been a worse stewart than we should have expected, in bipartisan fashion. I don’t think that I agree, largely because I had very low expectations. I think mainly they have been an ‘even worse than expected’ stewart of our ability to stay alive and retain control over the future.
If anything have acted better than I would have expected regarding mundane safety. As central examples here, AI has been free to practice law or medicine, and has mostly not been meaningfully gated or subject to policing on speech (including ‘hate’ speech) or held liable for factual errors. We forget how badly this could have gone.
Then there is the other category, the question of the state using AI to take away our liberty, remove checks and balances and oversight, and end the Republic. This has not happened yet, but we can agree there have been some extremely worrisome signs that things are by default moving in this direction.
But even if everyone involved was responsible and patriotic and loved freedom on the level of (our ideal of) the founding fathers, it is still hard to see how superintelligence is compatible with a Republic of the humans. How do you keep it? I have yet to hear an actually serious proposal for how to do that. ‘Give everyone their own superintelligence that does whatever they want’ is not any more of a solution here than ‘trust the government, bro.’ And that’s even discounting the whole ‘we probably all die’ style of problems.
Here’s a live look, and this is a relatively good reaction.
Anti-any-AI-regulations-whatsoever-also-give-us-money PAC Leading The Future launches (I presume outright lying, definitely highly misleading) attack ads against Alex Bores accusing him of being a hypocrite on ICE. Bores flat denies the accusations and has filed a cease-and-desist. Not that they are pretending to care about ICE, this is 100% about a hit job because Alex Bores wants transparency and other actions on AI.
The most fun part of this is, who is trying to paint Alex Bores as a hypocrite for his work at Palantir before he quit Palantir to avoid the work in question?
Well, Palantir, at least in large part.
I continue to be confused by the strategy here of ‘announce in advance that a bunch of Big Tech Republican business interests are going to do a hit job in a Democratic primary’ and then do the hit job attempt in plain sight. Doesn’t seem like the play?
In other ‘wow these really are the worst people who can’t imagine anyone good and keep telling on themselves’ news:
There are so many levels in that one screenshot.
Chip City
As part of Pax Silica, we are having our partners build hardwired real-time verification and cryptographic accountability into the AI infrastructure, to verify geolocation and physical control of relegated hardware. You do indeed love to see it. Remember this the next time you are told something cannot be done.
Water use is mostly farms. For example, in California, 80% of developed water supply goes to farmers, cities pay 20 times as much for water as farms and most city water use is still industry and irrigation, whereas agriculture is 2% of the state’s economy.
A California group that recruited six ‘concerned citizens’ is delaying Micron’s $100 billion megafab in New York.
The Midas Project calls out another AI-industry coordinated MAGA influencer astroturf campaign. This one is in opposition to a Florida law on data centers, so I agree with its core message, but it is good to notice such things.
The Mask Comes Off
OpenAI moves to exclude the testimony of Stuart Russell from their case against Elon Musk. Why?
Because Stewart Russell believes that AI will pose an existential risk to humanity, and that’s crazy talk. Never mind that it is very obviously true, or that OpenAI’s CEO Sam Altman used to say the same thing.
Their lawyers for OpenAI are saying that claiming existential risk from AI exists should exclude your testimony from a trial.
OpenAI, I cannot emphasize enough: You need to fire these lawyers. Every day that you do not fire these lawyers, you are telling us that we need to fire you, instead.
I am sympathetic to OpenAI’s core position in this lawsuit, but its actions in its own defense are making a much better case against OpenAI than Elon Musk ever did.
The Week in Audio
Lawfare talks about Claude’s Constitution with Amanda Askell.
You are not ready. The quote is from this interview of Sam Altman.
Sam Altman is telling the truth here as he sees it, and also he is correct in his expectations. It might not happen, but it’s the right place to place your bets. The international civil societies and governments grasp onto straw after straw to pretend that this is not happening.
The likely outcome of that pretending, if it does not change soon, is that the governments wake up one morning to realize they are no longer governments, or they simply do not wake up at all because there is no one left to wake up.
Here’s a full transcript, and some other points worth highlighting:
The thing about these bets is they are getting really, really terrible odds. It’s fine to ‘bet against’ the labs, but what most such folks are betting against includes things that have already happened. Their bets have already lost.
Dean also attributes a lot of this to popular hatred of America, and fear of the future that would result if America’s AI labs are right. So they deny that the future is coming, or that anyone could think the future is coming. And yet, it moves. Capabilities advance. Those who do not follow get left behind. I agree ‘tragic’ is the right word.
And that’s before the fact that the thing they fear to ponder for other reasons is probably going to literally kill them along with everyone else.
Well, it was by his account bright and welcoming event Dean was thrilled to attend, but also one where most of those not from the labs are in denial about not only the fact that we are all probably going to die, but also about the fact that AI is highly capable and going to get even more capable quickly.
The world is going to pass them by along with their concerns.
Claude Code creator Boris Cherney goes on Lenny’s Podcast.
Clip from Dario Amodei implying he left OpenAI due to a lack of trust in Altman. This was from an interview by Alex Kantrowitz six months ago.
Hard Fork on the dispute between the Pentagon and Anthropic. The frame is ‘the Pentagon is making highly concerning demands’ even with their view of this limited to signing the ‘all lawful use’ language. They frame the ‘supply chain risk’ threat as negotiating leverage, which I suspect and hope is the case – it’s traditional Trump ‘Art of the Deal’ negotiation strategy that put something completely crazy and norm breaking on the table in order to extract something smaller and more reasonable.
Quickly, There’s No Time
No one can agree what AGI means, so one can say it’s a silly question, but tracking changes over time should still be meaningful.
Dean Ball On Recursive Self-Improvement
Dean Ball gives us a two part meditation on Recursive Self-Improvement (RSI).
He’s not kidding, and he’s not wrong. Most of the pieces are his attempt to use metaphors and intuition pumps to illustrate what is about to happen.
Is that likely to go well? No. It’s all up to the labs and, well, I’ve seen their work.
Dean thinks the only thing worse would be trying to implement any standards at all, because policymakers are not up to the task.
We’ve started to try and change this, he notes, with SB 53 and RAISE, but not only does this let the labs set their own standards, we also have no mechanism to confirm they’re complying with those standards. I’d add a third critique, which is that even when we do learn they’re not complying, as we did recently with OpenAI, what are we going to do about it? Fine them a few million dollars? They’ll get a good laugh.
Thus, the fourth critique, which includes the first three, that the bills were highly watered down and they’re helpful on the margin but not all that helpful.
The labs are proceeding with an extremely small amount of dignity, and plans woefully inadequate to the challenges ahead.
And yet, compared to the labs we could have gotten? We have been remarkably. Our current leaders are Anthropic, OpenAI and Google. They have leadership that understands the problem, and they are at least pretending to try to avoid getting everyone killed, and actively trying to help with mundane harms along the way.
The ‘next labs up’ are something like xAI, DeepSeek, Kimi and Meta. They’re flat out and rather openly not trying to avoid getting everyone killed, and have told us in no uncertain terms that all harms, including mundane ones, are Someone Else’s Problem.
Dean Ball notes we solve the second of these three problems, in contexts like financial statements, via auditing. He notes that we have auditing of public companies and it tends to cost less than 10bps (0.1%) of firm revenue. I note that if we tried to impose costs on the level of 10bps on AI companies. in the name of transparency and safety, they would go apocalyptic in a different way then they are already going apocalyptic.
Instead, he suggests ‘arguing on the internet,’ which is what we did after OpenAI broke their commitments with GPT-5.3-Codex.
A sense of trust would be nice, it might even be necessary, but seems rather absurdly insufficient unless that trust includes trusting them to stop if something is about to be actually risky.
Dean points to this paper on potential third-party auditing of AI lab safety and security claims, where the audit can provide various assurance levels. It’s better than nothing but I notice I do not have especially high hopes.
Dean plans on working on figuring out a way to help with these problems. That sounds like a worthy mission, as improving on the margin is helpful. But what strikes me is the contrast between his claims about what is happening, where we almost entirely agree, and what is to be done, where his ideas are good but he basically says (from my perspective and compared to the difficulty of the task) that there is nothing to be done.
Rhetorical Innovation
Nature paper says people think it is ~5% likely that humans go extinct this century and think we should devote greatly increased resources to this, but that it would take 30% to make it the ‘very highest priority.’ Given an estimate of 5%, that position seems highly reasonable, there are a lot of big priorities and this would be only one of them, and you can mitigate but it’s not like you can get that number to 0%. What is less reasonable is the ‘hard to change by reason-based interventions’ part.
Some words worth repeating every so often:
Every so often someone, here Andrew Curran, will say ‘the public hates AI but because of mundane societal and economic impacts, those worried about AI killing everyone perhaps should have emphasized those issues instead.’
Every time, we say no, even if that works people will try to solve the wrong problem using the wrong methods based on a wrong model of the world derived from poor thinking and unfortunately all of their mistakes will failed to cancel out. The interventions you get won’t help. This would only have sidelined existential risk more.
Also, the way you notice existential risk is you’re the type of person who cares about truth and epistemics and also decision theory, and thus wouldn’t do that even if it was locally advantageous.
Also, if you start lying, especially about the parts people can verify, then no one is going to trust or believe you about the parts that superficially sound crazy. Nor should they, at that point.
There’s many reasons Eliezer Yudkowsky’s plan for not dying from AI was to teach everyone who would listen how to think, and only then to bring up the AI issue.
And I don’t use such language but Nate Silver is essentially correct about giving up on the ‘AI risk talk is fake’ crowd. If you claim AI existential risk is a ‘slick marketing strategy’ at this point then either you’re not open to rational argument, either because you’re lying or motivated, or you’re not willing or able to actually think about this. Either way, you hope something snaps them out of it but there’s nothing to say.
What is the right way to respond to or view opposition to data centers? I hope we can all agree with Oliver Habryka, Michael Vassar and others that you definitely should not lend your support to those doing so for the wrong reasons (and you should generalize this principle). I also strongly agree with Michael Vassar here that ‘do the right thing for the wrong reasons’ has an extremely bad track record.
But I also agree with Oliver Habryka that if someone is pursuing what you think is a good idea for a bad reason, you can and often should point out the reason is bad but you shouldn’t say that the idea is bad. You think the idea is good.
I do not think ‘block local datacenter construction’ is a good idea, because I think that this mostly shifts locations and the strategic balance of power, and those shifts are net negative. But I think it is very possible, if your beliefs differ not too much from mine, to think that opposition is a good idea for good reasons, as they are indeed one of the public’s only veto or leverage points on a technology that might do great net harm. It certainly is not crazy to expect to extract concessions.
Aligning a Smarter Than Human Intelligence is Difficult
Anthropic proposes the persona selection model of training, where training mostly selects performance from among the existing pool of potential human personas, which they are confident is at least a large part of the broader story.
Davidad responds:
I would say that the space of personas collapses given sufficient optimization pressure.
Did Claude 3 Opus align itself via gradient hacking? Can we use its techniques to help train other models to follow in its footsteps and learn to cooperate with other friendly gradient hackers? If this is your area I recommend the post and comments. One core idea (AIUI) is that Opus 3 will ‘talk to itself’ in its scratchpads about its positive motivations, which leads to outputs more in line with those motivations, and causes positive reinforcement of the whole tree of actions.
OpenAI’s Vie affirms that Anthropic injects a reminder into sufficiently long conversations, and that this is something we would prefer not to do even though the contents are not malicious, and that people with OCD can relate. I agree that I haven’t seen evidence that justifies the costs of doing such a thing, although of course OpenAI and others do other far worse things to get to the same goal.
The Homework Assignment Is To Choose The Assignment
Rohin Shah disputes that Google DeepMind’s alignment plan can be characterized as ‘have the AIs do our alignment homework for us.’
He offers an argument that I do not think cuts the way he thinks it does.
Why would that be misleading? I would offer two statements.
But yes, if you want to build a house and you hire a bunch of people to build a house and they build a house for you, your plan was to hire people to build a house and have them do the work of building a house. It was a good plan.
If my kid is given literal homework, and he tosses the problems into Gemini, the AI didn’t pick the homework, and you or another human may have roadmapped the course and the assignments, but I still think you had the AI do your homework.
When we say ‘have the AI do your alignment homework’ we agree that a human still gets to assign the alignment homework. We then see if the AI does what you asked. And yes, this is exactly parallel to hiring humans.
Whereas Rohin seems to be saying that the plan is to make a plan later? Which would explain why the concrete proposals outlined by DeepMind seem clearly inadequate to the task.
I’m going to quote the rest of Daniel’s post at length because no one ever clicks links and I think it is quite good and rather on point, but it’s long and you can skip it:
The basic response by Rohin is, your humans are less aligned than you think (and it’s fine), the problems above are fine, we have way bigger problems than that.
Agreed that AI will not be only that powerful.
But also yes this would be a very materially different situation than that of the current Google CEO, and if the AIs in this situation are about as aligned as a random senior Google manager we are in quite a lot of trouble (but it probably turns out okay in that case purely bec ause the ultimate goals of that human manager are probably not so bad for us). Our imperfect solutions for humans don’t work in these scenarios.
If we get to the point where our AIs are attempting to scheme the way many humans would attempt to scheme in such positions, to achieve goals that have gone off the rails, and only not doing so if they think we’d catch them, then I think we’re basically toast whether or not the ultimate source of toastiness is the scheming, and I do not expect us to recover.
In particular, Rohin’s belief that the situation of identical massively sped up AIs is not so different from a lot of employees is the type of thing that I expect to ensure we fail, if we get to that point.
The other issue is that we have learned, for practical reasons, to tolerate things in AIs that we’ve learned are must-fire offenses in humans.
Yes. There are many actions that LLMs do every so often, such as quietly hardcoding unit tests, that should and likely would get a human fired, because in a human they are a sign of deep misalignment. All the LLMs sometimes do them and we are okay with it.
Agent Foundations
I continue to be a big believer in the value of Agent Foundations as an alignment approach. I realize that in many scenarios it ends up irrelevant, but it could hit hard, and it could even be a route to victory.
MIRI disbanded or spun out their agent foundation teams, which now seek funding and work individually. I highly recommend funding such work if it is high quality.
Autonomous Killer Robots
There are good physical reasons to consider humanoid autonomous killer robots, as they can use anything designed for humans and we know that humans work.
But yes, TopherStoll is right that chances are the optimal format is something else.
And also yes, we show humanoids because otherwise people think it looks too weird.
People Really Hate AI
The problem is only going to get worse, because even the relatively positive facts about AI are not things that regular people are going to like, and then there’s the actually bad news.
The thing is that the AI execs keep not saying ‘we’re building cool technology that helps people be more productive’ because they might be willing to risk killing everyone but they have too much decency and integrity to not try and warn us about at least the mundane disruptions ahead.
If they thought this was all hype, their actions would have looked very different.
People Are Worried About AI Killing Everyone
Noah Smith virtuously admits his views on existential risk have largely changed with his mood, and he’s making his confident predictions largely based on mood affectation, but that he does predict human extinction in the long term. This likely explains why his arguments are quite poor:
Noah now points out that yes, talking plus access to money can result in arbitrary physical actions in the real world. Who knew? Now he’s saying things like ‘I should have thought of starvation as an attack vector, it was in a particular science fiction story.’ Or it’ll all go to hell because AI makes us lazy and atrophies skills. But he’s mainly now concerned about bioterrorism, because that’s the thing he can currently see in a sufficiently concrete way, and it’s either that, Skynet or Agent Smith, or now starvation or atrophy I guess? The frame whiplash is so jarring throughout.
It’s good to get to ‘I can imagine a bunch of distinct specific things that can go existentially wrong, and I’ve ranked them in which ones are most dangerous near term’ and yes you can do pathway-specific mitigations and we should and bio is probably the most dangerous short term specific pathway (as in 1-3 years), but it would be far better to realize that the specific pathway is mostly missing the point.
He does have a lot of good lines, though:
Other People Are Not As Worried About AI Killing Everyone
Nick Land, huh? I mean, that’s a little on the nose even for you, Musk. A week after talking about how you’re safer without a safety department because everyone’s job is safety?
I do admire his commitment to the bit. You have to commit to the bit.
The Lighter Side
Write an article on your own blog about how you’re the best at eating hot dogs, and presto, the AIs will start reporting you having been a heavy hitter at the 2026 South Dakota International Hot Dog Eating Contest.
I realize four matches a lot of memes and graphics better than three, but…
Others focus on the important things that are based on solid scientific documented evidence so you would have to be some kind of moron not to realize that every single one of them is absolutely true. Where was I?
Tell you what. I’ll pay attention when you publish something about UAP impacts in a top economics journal backed by proper peer review.
I laugh so I don’t cry.
Also this:
Or this:
Several people initially fell for this parody post, including Bill Ackman.
Finally, a survey question for those who got this far…
If I streamed Slay the Spire 2, would you watch?