My best guess is that it’s about the effective evidence available to the agent toward subtask solution strategy. Intuitively, if you’ve seen very similar subtasks many times before, it’s hard to go too wrong. If you’ve only seen vaguely similar subtasks once or twice, you’re in much less familiar territory and stand a good chance of stalling.
I think that LLMs usually learn to do tasks by using more memorization on the memorization-generalization spectrum, and so they need a lot of data to succeed. (see also) But it seems like there could be ways to make AI that involve more generalization; e.g. the human brain. I think a substantial fraction of algorithmic progress is about pushing LLMs more towards the generalization side.
Indeed, and one of the factors that might change the coefficients on the relevant power laws, and the example-efficiency of RL training and so on, would be setups which are a bit more sample-efficient and able to generalise from fewer examples! Nevertheless, the point that you need somewhat-relevant examples to generalise from stands. (Where 'somewhat' is maybe a little bit, but not infinitely, flexible.)
I think that there's a lot of room to improve generalization. Humans have an effective "time horizon" of years to decades, while needing only about
How do we know in this model if the identity of failed subtasks is constant, that there is a subset of subtask such that P percent of subtasks are passed with probability zero, vs all subtasks are uniform, but the hazard rate comes from a chance of unrecoverable failure on each individual task step.
Remember that the main graph is 50% pass rate over resampling, so it would be the correlation of supertasks to resampling that would tell you of few hard subtasks vs lots of not so hard ones with nonzero hazard to every task.
The correct test is both whether model performance on individual tasks correlates, and whether tasks have run to run pass rates other than zero and 1. Doing that analysis suggests that there is a subset of hard tasks, but that subset is pass sometimes as well as pass never.
I think that's right - there are some subtasks (and hence some tasks) which sit at the threshold of being occasionally doable (see fn 9). METR's data will have this per-task success rate but I haven't looked whether they expose that anywhere for analysis. When I asked Claude, it said a U shape isn't uncommon for evals individual tasks success rates, though not across the board and I don't know how much weight to put on that. Would want to look properly.
A U-shape for individual task success rates is a natural consequence of success being logistic-like in nature or contingent on many logistic tasks at once. Suppose that
P.S. Could you take a look at my model involving macrostrategy levels?
I should probably say that the Weibull distribution is almost as good of a fit, with the hazard rate parameter called K being less than 1 near-uniformly for AIs, meaning their hazard rates decline over time (but don't decline as sharply as humans) in Hazard Rates for AI Agents Decline as a Task Goes On, which I think provides evidence that AIs are both worse than humans at generalizing and also evidence that the LLM paradigm isn't completely off the mark.
On this:
For some types of activity, developers are probably ‘running out’ of raw example data to scrape from the internet. The era of mostly-pretraining is over.
I'd argue that this is probably wrong, based on AI models like Mythos which apparently chose to mostly just scale up parameters, but I agree with something close to this, in that high-quality pre-training data will probably run out by 2028, or in optimistic timelines 2030, around the same time that the immense compute scale up has to slow down to the trend of hardware (at least without new fab construction, which could very well happen).
Some commentaries project that, once AI can autonomously do software and machine learning work reliably, it will thereafter enter a ‘recursive self-improvement’ phase and rapidly colonise all capabilities.
Probably the best public case for this (for now) is the paper called When Does Automating AI Research Produce Explosive Growth? Feedback Loops in Innovation Networks, but I do directionally agree that this probably doesn't happen and it's worth preparing for worlds where we don't get a software intelligence explosion, as quite a few things change in this scenario.
Curious about the 'declining hazard rate'. That would also look like 'the apparent hazard rate is higher on shorter tasks'. Could be explained by the couple of reasons I gave in a footnote for longer tasks being incommensurably slightly 'easier': more tendency to include repetitive elements, more opportunity to take alternative sequential paths. Or could be explained by some constant 'difficulty' term that doesn't scale with human time-to-complete - perhaps 'understanding the spec'. Or if the shortest tasks systematically have their human time-to-complete underestimated (but you'd need a reason to suppose it'd go this way rather than the other).
Wait, Mythos surely was very RL-heavy, no? I'd be quite surprised to learn it leant more heavily on pretraining than previous Claudes.
Keep in mind here that since RL is less efficient information wise than pre-training (1,000x-1,000,000x less efficient) and RL/inference becomes more expensive the larger the model is, I'd say that basically every AI model, including maybe Mythos is RL light in the sense that RL contributes a lot less of the capabilities compared to pre-training.
But I think you have identified a plausible hole, and this is the case where a larger model makes RL more sample efficient, and this sample efficiency advantage leads to a Jevons scenario where more RL is used. I currently don't think this is likely for cost reasons, but this is absolutely a very plausible future to keep in mind.
I think both more reasoning expenditure (limited, diminishing returns) and more competent/informed base pretrained model can make RL more sample-efficient, by making successful rollouts more likely to begin with. (You pay less exploration tax.)
Similarly, well-designed curricula or adaptive sourcing/selection of demonstrations could make RL more sample efficient.
Mm, OK this is a good direction. Now you prompt it, I think we can 'weigh' RL in at least three ways
- Compute cost
- (Positive) example data size
- 'Relevance-weighted' data size
When I was saying Mythos RL-heavy and the 'mostly pretraining' era is over, I meant in terms of compute cost (1).
When you're saying RL is highly information-inefficient, I think maybe you're talking about example data size (2)? Because many rollouts are failures?
When I'm discussing the upshot of RL and proactive data collection on task success, I'm talking about 'relevance-weighted' data size (3) - the fact that self-supervised pretraining didn't get 'all the way' suggests there's not enough signal to cover enough relevant subtasks, and this is where RL can be 'heavy' in that sense. But an alternative is proactive data collection. (Depending on task domain, one or other might get more bang for buck right now.)
I'd also maybe disagree with even 1, but this is probably going to depend on how much RL is required. If it's say 5-20% of compute costs, I'd believe it, but if it's closer to 50%+, I absolutely think Anthropic has not done this yet.
However I want to flag that most compute costs being RL costs is at least reasonably plausible as a future, especially if continual learning/neuralese brings huge capabilities gains (because in this case you'd constantly want to add more RL tasks to update the weights constantly).
When I'm discussing the upshot of RL and proactive data collection on task success, I'm talking about 'relevance-weighted' data size (3) - the fact that self-supervised pretraining didn't get 'all the way' suggests there's not enough signal to cover enough relevant subtasks, and this is where RL can be 'heavy' in that sense.
Directionally agree, but I'd say that we should just wait until 2030, because I do expect pre-trained models to get more capable as well, seperate from the RL part, but I also have updated in the direction that self-supervised pre-training will not go all the way either, at least without megastructure levels of compute and data investments.
Strictly speaking wouldn't this be something like a ratio of two power laws? One for the AIs, one for the humans? This could actually map better to the upturn in slope we see with the advent of reasoning and thinking and agent systems, because it suggests a reason for the graph to diverge to infinity as the AI subtask completion success rate approaches that of humans. What's left is ability to efficiently and effectively divide a task into the right subtasks to maximize success rate.
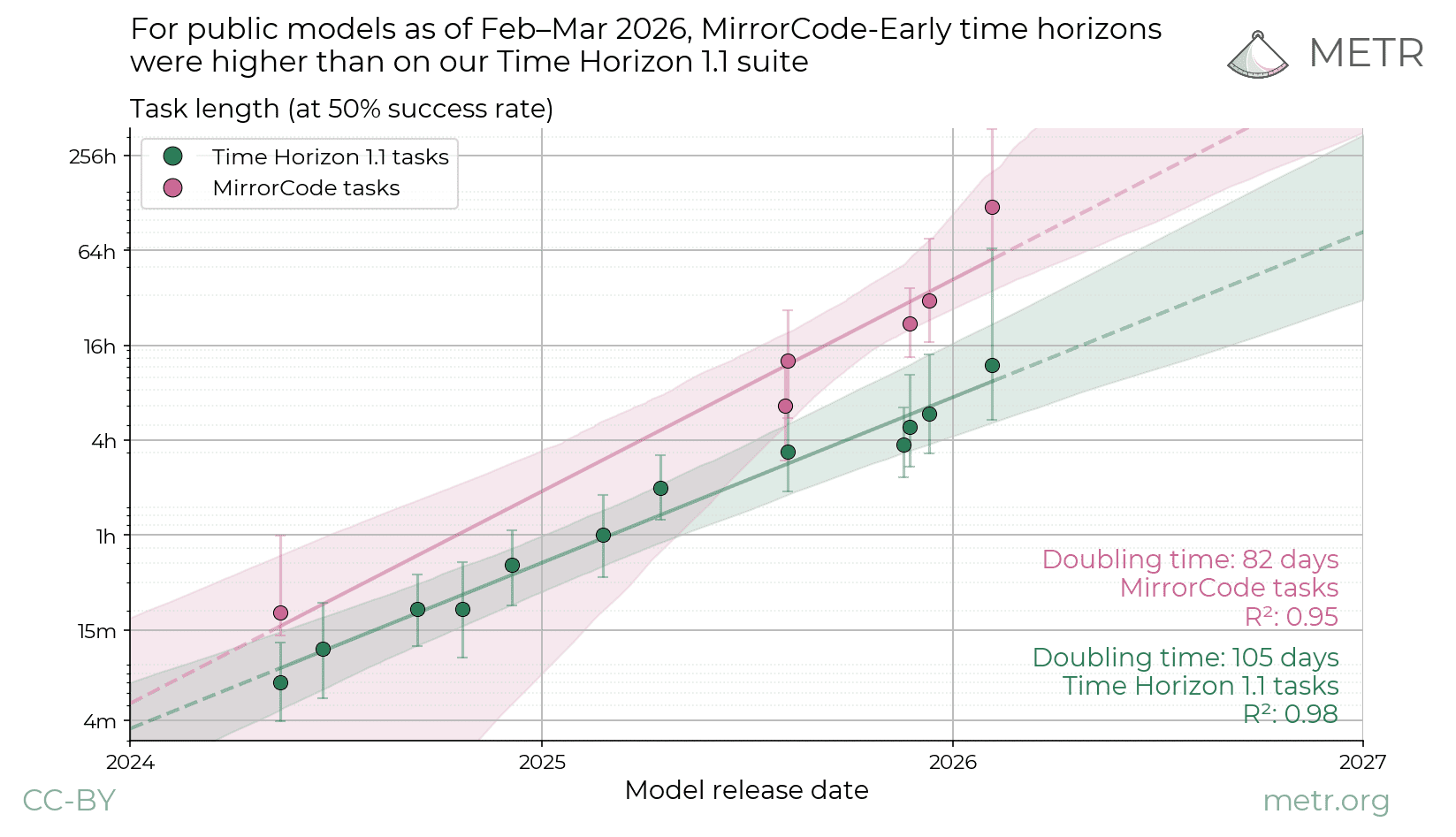
I also wonder how it could interact with METR's statement (upd: link) that early versions of MirrorCode produced a time horizon of 100+ hours. Back in December I made a simple model of a task being split into subtasks until each subtask became rather easy. The LLM, according to the model, would hillclimb on subtasks, then on splitting simple tasks into subtasks, then on increasingly macrostrategic ones until the coding world runs out of macrostrategy levels and each macrostrategy level would be unapproachable before the previous one is saturated. Does this imply that MirrorCode is a low-macrostrategy task?
{kind=link}
I'm not sure if I follow this or not. But it rhymes with a general picture I have of sequential planning often being hierarchical: you get good at the small pieces, those become available abstractions to plan with, and now you're planning in 'option' space (as opposed to raw 'action' space) which is fully recursive. You need some amount of evidence for how options work (which might be policy-/actor-dependent) and how to strategise in that 'higher' space. You build your library of option concepts through learning and abstraction. Starting from scratch, you need to build up from the atomic action level. If you're seeded with lots of approximate examples across the hierarchy (as are LMs - and probably humans to some extent), the dynamics are a bit different (but perhaps not very different unless your starting base is very 'hierarchy-level-asymmetrical').
AI ‘time horizons’ are mostly not about time (I think it’s mostly ‘data’, but you’ll see where I’m unsure).
One chart from 2025 has become perhaps the most (in)famous in modern AI commentary.
For those in the know, ‘the METR graph’[1] is unusually compelling because it achieves what so few measures of AI progress have achieved: a somewhat meaningful Y axis (‘time horizon’[2]) as well as a somewhat predictable trend over time! (This is remarkably rare!)
Frustratingly, the only superficially available takeaway is something like, ‘the line goes up straight-ish over time’. This is better than nothing, but it’s very dissatisfactory from the point of view of getting confidence in the predictions, because it exposes no deeper mechanism. This drives a lot of confusion and argument about the implications.
A deeper mechanism would be good for two reasons:
As an analogy, a similarly superficial trend, Moore’s Law, can be a little better mechanistically explained by the more general Wright’s Law[3]. This is great, because that law covers more cases, and it can handle some deflection from the trend, or give some idea of when (and under what conditions) the trend might break. Important when looking at plausible futures, and how to steer toward desirable ones!
Attempting to find some mechanism in the METR graph
Task ‘length’ and success modelling
Why did METR focus on ‘task length’?
First, it’s not how long the AI agent takes. It’s how long the task in question takes a panel of sampled human experts, on average[4]. So in their ‘time horizon’ measurements, METR is capturing the effective hours of human-expert-equivalent activity that AI agents can carry out.[5]
One way to think about the time it takes human experts to complete a task is that, for each subtask they had to know how to do (or be able to figure out how to do) and then successfully execute, the overall task takes incrementally longer. By how much? That depends on exactly what ‘subtasks’ we're imagining breaking things down into.[6] But on average longer tasks correspond to more distinct challenges, all else equal.[7]
A random generation of tasks (rows) with ‘subtasks’ as segments, sorted by subtask count from least to most. You can see that the more subtasks, the longer, on average. It’s a little ragged — not all subtasks are the same length, so occasionally fewer, longer subtasks add up to more overall time than more, shorter subtasks. What METR can easily measure is the overall duration. Even if the subtask division is somewhat subjectively defined, duration stands as a reasonable proxy for it. Note that the vertical subtask count axis is sorted but not uniformly spaced. (Created with claude.ai.)
This is the first piece of mechanism we should take into account. ‘Time’ is not agent time: it's a noisy estimate for ‘number of somewhat challenging requirements necessary to complete the task’.[8]
This is treating overall tasks as formed by something like drawing ‘subtasks’ out of a large collection of possible requirements. Given the agent’s general competence, specific knowledge, tools available, and opportunity to retry or learn on the fly, sometimes the agent can meet these requirements. Other times it can’t.[9] ‘Longer’ tasks simply draw more subtasks (that’s why they’re ‘longer’, in this model: expert humans had more subtasks they needed to carry out).[10]
Toby Ord demonstrates one way to take this intuition further, noting that if we explicitly model overall success
In other words, for a given AI agent and task domain, there's something like a ‘hazard rate’,
(i.e. to succeed at a
This enables us to translate back and forth between an estimate of this hazard rate
In this formulation, the hazard rate,
This time, we’re looking at overall task success as if the agent has a 98% chance of meeting any particular subtask’s requirements. Sometimes a shorter task will happen to have one of the difficult subtasks — but usually they’re overall successful. As tasks get longer, there’s a greater chance that at least one subtask requirement is insurmountable at this reliability level. Among longer tasks, overall success becomes fewer and farther between. This agent can’t expect to often succeed on tasks longer than 50 or so subtasks.
If you have a new task, you don’t know if the agent has all it needs to complete it. But the task ‘length’ is an indicator of how many tricky subtasks it has, and similar-lengthed tasks will have similar numbers of such subtasks — so their average success rate is a good estimate for how likely the agent is to succeed at this new task.
Relating hazard rate with frontier AI development
METR's graph is compelling because it suggests a steadily increasing frontier of success horizon as AI developers produce new agents over time.
What does this imply if we interrogate our hazard rate model? Well, 'half-life' (and indeed various success-level horizons) is observed apparently growing exponentially with date
This is the central striking takeaway from the METR graph (modulo their measurement uncertainty). Half-life go up!
But half-life according to our model has:
where
So METR's observation of rising time horizons is equivalent to saying that the frontier hazard rate is shrinking exponentially over time.
Recall that this hazard rate corresponds with the fraction of ‘subtasks’ in a domain that an agent doesn’t yet know how to complete. So this fraction is presumed to shrink roughly exponentially with date, in turn driving the observed ‘longer’ success horizons.
Why does hazard rate shrink with date?
Here’s where to look for the next bit of mechanism. Why would the hazard rate, the fraction of ‘subtasks’ which remain out of reach, shrink in that way?
It goes without saying that AI developers are chasing after increasing competence in their products, so (if they are doing anything at all right!) the direction of movement is unsurprising. Why that particular roughly-exponential form, though?
I confess here I’m uncertain and the quest for more mechanism continues.
My best guess is that it’s about the effective evidence available to the agent toward subtask solution strategy. Intuitively, if you’ve seen very similar subtasks many times before, it’s hard to go too wrong. If you’ve only seen vaguely similar subtasks once or twice, you’re in much less familiar territory and stand a good chance of stalling. Suggestively, effective evidence and training data are both information-like quantities, but I don’t want to make too much of that without a crisper connection. Formally, we could consider how many bits of evidence the agent can muster about how to proceed (either from past learning or by exploring in context).
In other words, training produces learnings. These range from broad, generally-applicable heuristics for adaptable, effective behaviour (experiment, test your work, notice when something surprising happens, read the manual if you can find one, accrue power and resources at any opportunity, ...), to narrow specific details about particular situations and activities (Earth's radius is roughly 6.4 megameters, detonating TNT yields roughly 4.2 kJ/g, humans succumb to oxygen deprivation after around 5 minutes, …). Ahem.
Empirically, AI developers have historically poured something like exponentially increasing ‘quantities’ of ‘data’ into their machine learning pipelines.[13] Mathematically, that implies a power law: data inputs
Power laws aren’t deeply mechanically explanatory, but they’re often the best we have in machine learning, and are at least more predictable than mere date-based trends. Under the simple subtask model described here, this power law translates directly into a power law between ‘time horizon’ and data. This is actually the same level of explanatory improvement offered by Wright’s Law over Moore’s: not fully mechanistic, but an extra layer of detail which offers firmer purchase on what’s going on.
What this doesn’t straightforwardly account for is the benefit to success rates of increased in-context reasoning, which is exhibited according to METR’s estimates. I expect this is operating on those borderline subtasks — where the agent would have some slim chance of satisfying them if it ‘rushed’. In those cases, ‘thinking harder’ may more effectively recall and combine the relevant learned knowledge, and allow better choices for exploratory discovery in situ. In any case, changing the thinking budget of an otherwise similar existing system certainly calls for a more mechanistic understanding than mere date-based trend extrapolation!
I would be thrilled if someone with more smarts, time to experiment, and access to data were to dig into ways we could match up various AI production inputs (especially ‘data’ in various forms) with observed outputs like ‘time horizon’. One of the more difficult pieces might be quantifying ‘data’, especially teasing apart what types of evidence are ‘relevant’ for the domain and tasks at hand.
Upshot
The kind-of-boring upshot of this is that data and ‘practice’ on related tasks makes AI better at those tasks! This is boring because, well obviously!, we already basically knew that. But it’s encouraging because we can say a little more than that, which gives us some better grasp on what’s driving ‘time horizon’ progress in particular domains — and it can help get more precise about predictions.
The fact that the ‘subtask’ model — with a ‘hazard rate’ of subtasks currently out of reach — is a fairly explanatory fit for capability profiles of individual agents is evidence that there’re not unusual amounts of generalisation capability in AI. As with humans, they can extrapolate a bit, but need ‘experience’ and examples to succeed.[14] Importantly, this means that vast in silico training ranges for software, cyber, and mathematics very likely won’t transfer much to other domains of interest, like interpersonal intelligence, medical discovery, bioweapons development, intelligence analysis, and robotic manipulation. Of course, like with every domain of human experience and activity, we have some relevantly-similar data already collected, and schemes can be devised to more rapidly expand that digitised experience bank for AI to learn from. Increasing adoption of AI in task-integrated contexts, industrial deployment, and even explicit approaches to gathering example data such as ‘hand movement farming’ are the leading indicators to watch for progress in particular domains — not just the headline benchmark metrics in software-like tasks.
For some types of activity, developers are probably ‘running out’ of raw example data to scrape from the internet. The era of mostly-pretraining is over. For domains which can be relatively easily verified, like mathematics and coding, this is very surmountable — you can just run drills galore on a computer and get data that way. But this costs extra compute and doesn’t scale at the same exponential rate for long (perhaps 10x/year presently). As soon as this year, developers could be back to ‘only’ scaling compute around 4x per year (and a bit after that they might have bought most of the compute! — and will only be able to scale at the positively sloth-like 1.5x-ish a year of underlying hardware progress). I don’t feel confident extrapolating exactly where that cashes out, but if the data-driven subtask-learning model is right, it would imply we should see less steepness to the time horizon growth quite soon.[15]
Some commentaries project that, once AI can autonomously do software and machine learning work reliably, it will thereafter enter a ‘recursive self-improvement’ phase and rapidly colonise all capabilities. I don’t think this is missing the point entirely: there will be modest multipliers on the speed of the AI development pipeline, and we might see an ‘explosion’ in the speed and cost-effectiveness of AI (because they are among the most immediately-verifiable properties to iterate on). But generalisation doesn’t come for free, so on-task data and compute will remain crucial to broadening the frontier of autonomous capabilities. Collecting that data and manufacturing that compute look to me like the rate-limiting steps, and therefore the major leading indicators to use in foresight. The best case I can make for a much more general explosion is if the speed and cost-effectiveness explosions rapidly accelerate the gathering and digestion of diverse task data — but I think that remains mostly rate-limited in the familiar ways: some domains easy and some more difficult. Don’t mistake me for ruling out across-the-board AI capability! Companies are charging ahead with data collection and set on automating much of their AI production pipeline. It just won’t happen overnight.
Thanks to Coz Ududec for a conversation prompting me to think about this.
Produced by AI monitoring non-profit METR
Very importantly, it’s measured within a particular collection of challenges/tasks which are mostly associated with software development, especially ML engineering. METR also has a great preliminary study of some other domains, finding differing, but perhaps also somewhat predictable trends.
Moore’s Law is the very superficial observation that, over time, the number of transistors per chip doubles roughly every two years. (More recently, it’s been more clearly expressed as the price per transistor halving every year-or-two.)
Wright’s Law is the slightly more mechanistic and general observation that production of many commodities follows ‘learning curves’, such that each doubling of cumulative production produces roughly similar relative cost savings. (We can in turn attempt to explain this in yet more mechanistic terms, pointing to the insight gained from observing and recording many trials and experiments, with suitably diminishing returns.)
Now, if the quantity demanded and produced grows exponentially over time (as it has for computer chips), then Wright’s Law predicts comparable cost savings each year: Moore’s Law. If the quantity produced grows (or shrinks) in some other pattern over time, Wright’s Law, by accounting for this mechanistic detail, can often forecast cost trends more reliably than Moore’s.
Also note that the estimation of ‘task length’ according to human experts was quite crude (naturally, humans are the most expensive part of most experiments!), and there are good reasons to treat the reported error bars as much too narrow, i.e. misleadingly confident. I’ll use quotes around ‘time’ related quantities in this post as a reminder that it’s a loose estimate of a crudely human-performer-derived time-to-completion for tasks, and doesn’t correspond well to real time as such.
I don’t know if METR publishes how long the agents themselves take at these tasks — I don’t think so, and it’d arguably be ill-defined anyway since it would depend in part on how fast a computer you ran the agent on.
If we conceptually carve up subtasks into smaller pieces, they'll be quicker per piece, but there are commensurably more of them, and vice versa.
This could come apart if longer tasks are systematically more likely to include repetitive similar activities rather than a series of distinct ones, for example. Or longer tasks might tend to admit more truly alternative pathways. Both these effects could make longer tasks slightly easier than the naive picture. There are also higher-level ‘orchestration’ tasks i.e. coherently coming up with (and executing and adapting) an appropriate sequential plan: perhaps these might be systematically more difficult for longer tasks.
Notably, agents sometimes take a (relatively) longer time to do something that’s quicker for humans, and vice versa.
Incidentally, success (or not) here already accounts for the agent attempting and re-attempting steps or fixing earlier mistakes, which might take variable amounts of time: another reason not to treat this as agent time. Some subtasks might be intermediate and succeed sometimes (for example if the agent can’t easily choose the best approach but sometimes hits on the right one, or sometimes gets stuck in a terminal cycle but sometimes makes lucky progress.)
This is throwing away some detail: obviously not all subtasks are equally likely to follow from each other! There’s some correspondence between on-task sequences. But within a particular domain (like software engineering), this naive model of overall tasks combining subtasks somewhat randomly seems to do OK.
By the way, the rule of 72 provides a really quick mental approximation for the higher-reliability ‘time’ horizons, depending on the ‘half-life’ (the 50% ‘time’ horizon).
Divide the ‘half-life’ by 72. That’s the 1% failure horizon (equivalent to the 99% success horizon). Multiply by your target failure rate in percent, and you’re done: that’s your target success ‘time’ horizon. E.g. if ‘half-life’ is 1h, the ‘time’ horizon at 99.9% is (1h/72)*(0.1) i.e. 5 seconds.
(This also reveals that cutting the ‘time’ horizon tenfold cuts the average failure rate tenfold and so on.)
Going the other way, estimating long-horizon success rates, divide your target horizon by the ‘half-life’. That’s how many halvings of success to expect: raise one half to that power for your success rate. E.g. if ‘half-life’ is 1h, your 24h success rate is
It didn’t have to be that way! A single number which manages to explain a lot of variation in agent capability is very suggestive of an underlying mechanism something like the ‘fraction of subtasks’ model I’ve described here. Of course there is still some residual uncertainty and there may be better summaries available with a more detailed model or epicycles on this one.
This may recently be trickier to measure as training pipelines have adapted to incorporate more reinforcement learning, which means these experience data are less ‘homogeneously slurped up from the internet’ and increasingly ‘proactively curated from in-domain training curricula’. So the mere quantity of data isn’t like-for-like over time.
In fact contemporary AI is perhaps substantially less good at generalisation than humans, though I’d like to be better informed about how factors like sample efficiency of AI learning (including in-context learning) stack up.
Actually saying something so bearish about AI makes me nervous, as there is a venerable history of people boldly declaring AI is about to hit a wall! But I think it’s borne out. I’m not saying progress stops, I’m saying it probably gets slower (in exponential terms).