It would be awesome to easily ensemble Elicit distributions (e.g., take a weighted average). If ensembling were easy, I would have definitely updated my distribution more aggressively, e.g., averaging my inside view / prosaic AGI scenario distribution with datscilly's outside view distribution (instead of a uniform distribution as an outside view), and/or other distributions which weighed different considerations more heavily (e.g., hardware constraints). It'd be quite informative to see each commenter's independent/original/prior distribution (before to viewing everyone else's), and then each commenter's ensembled/posterior distribution, incorporating or averaging with the distributions of others. I suspect in many cases these two distributions would look quite different, so it would be easy for people to quickly update their views based on the arguments/distributions of others (and see how much they updated).
Here's a colab you can use to do this! I used it to make these aggregations:
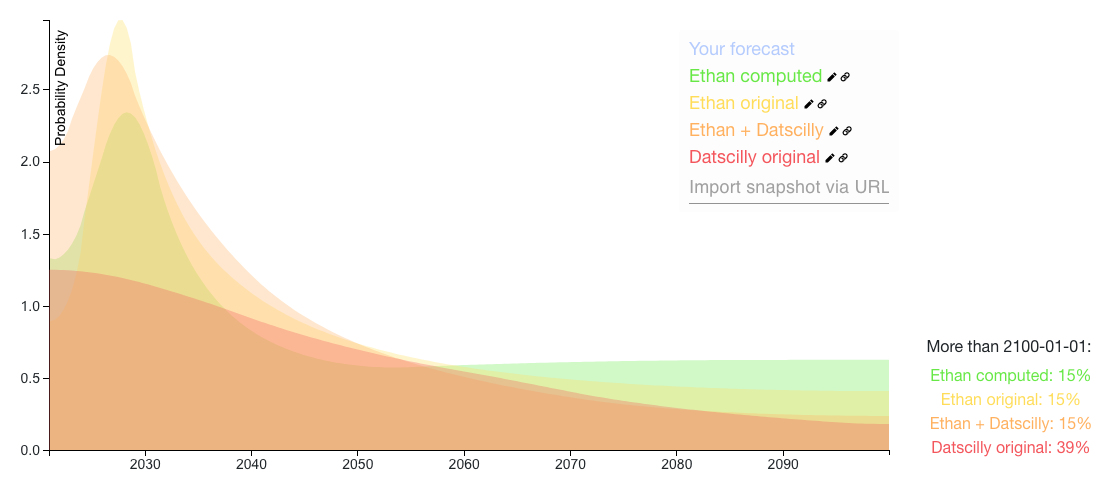
The Ethan + Datscilly distribution is a calculation of:
- 25% * Your inside view of prosaic AGI
- 60% * Datscilly's prediction (renormalized so that all the probability < 2100)
- 15% * We get AGI > 2100 or never
This has an earlier median (2040) than your original distribution (2046).
(Note for the colab: You can use this to run your own aggregations by plugging in Elicit snapshots of the distributions you want to aggregate. We're actively working on the Elicit API, so if the notebook breaks lmk so we can update it).
Wow thanks for doing this! My takeaways:
- Your "Ethan computed" distribution matches the intended/described distribution from my original prediction comment. The tail now looks uniform, while my distribution had an unintentional decay that came from me using Elicit's smoothing.
- Now that I see how uniform looks visually/accurately, it does look slightly odd (without any decay towards zero), and a bit arbitrary that the uniform distribution ends at 2100. So I think it makes a lot of sense to use Datscilly's outside view as my outside view prior as you did! So overall, I think the ensembled distribution more accurately represents my beliefs, after updating on the other distributions in the LessWrong AGI timelines post.
- The above ensemble distribution looks pretty optimistic, which makes me wonder if there is some "double counting" of scenarios-that-lead-to-AGI between the inside and outside view distributions. I.e., Datscilly's outside view arguably does incorporate the possibility that we get AGI via "Prosaic AGI" as I described it.
"A good next step would be to create more consensus on the most productive interpretation for AGI timeline predictions. "
Strongly agree with this. I don't think the numbers are meaningful, since AGI could mean anything from "a CAIS system-of-systems that can be used to replace most menial jobs with greater than 50% success," to "a system that can do any one of the majority of current jobs given an economically viable (<$10m) amount of direct training and supervision" to "A system that can do everything any human is able to do at least as well as that human, based only on available data and observation, without any direct training or feedback, for no marginal cost."
I also just discovered BERI's x-risk prediction market question set and Jacobjacob & bgold's AI forecasting database, which seem really helpful for this!
It’s been exciting to see people engage with the AI forecasting thread that Ben, Daniel, and I set up! The thread was inspired by Alex Irpan’s AGI timeline update, and our hypothesis that visualizing and comparing AGI timelines could generate better predictions. Ought has been working on the probability distribution tool, Elicit, and it was awesome to see it in action.
14 users shared their AGI timelines. Below are a number of their forecasts overlaid, and an aggregation of their forecasts.
Comparison of 6 top-voted forecasts
Aggregation, weighted by votes
The thread generated some interesting learnings about AGI timelines and forecasting. Here I’ll discuss my thoughts on the following:
AGI timelines
Summary of beliefs
We calculated an aggregation of the 14 forecasts weighted by the number of votes each comment with a forecast received. The question wasn’t precisely specified (people forecasted based on slightly different interpretations) so I’m sharing these numbers mostly for curiosity’s sake, rather than to make a specific claim about AGI timelines.
Emergence of categories
I was pleasantly surprised by the emergence of categorizations of assumptions. Here are some themes in the way people structured their reasoning:
When sharing their forecasts, people associated these assumptions with a corresponding date interval for when we would see AGI. I took the median lower bound and median upper bound for each assumption to give a sense of what people are expecting if each assumption is true. Here’s a spreadsheet with all of the assumptions. Feel free to make a copy of the spreadsheet if you want to play around and make edits.
Did this thread change people’s minds?
One of the goals of making public forecasts is to help people identify disagreements and resolve cruxes. The number of people who updated is one measure of how well this format achieves this goal.
There were two updates in comments on the thread (Ben Pace and Ethan Perez), and several others not explicitly on the thread. Here are some characteristics of the thread that caused people to update (based on conversations and inference from comments):
Learnings about forecasting
Vaguely defining the question worked surprisingly well
The question in this thread (“Timeline until human-level AGI”) was defined much less precisely than similar Metaculus questions. This meant people were able to forecast using their preferred interpretation, which provided more information about the range of possible interpretations and sources of disagreements at the interpretation level. For example:
A good next step would be to create more consensus on the most productive interpretation for AGI timeline predictions.
Value of a template for predictions
When people make informal predictions on AGI, they often define their own intervals and ways of specifying probabilities (e.g. ‘30% probability by 2035’, or ‘highly likely by 2100’). For example, this list of predictions shows how vague a lot of timeline predictions are.
Having a standard template for predictions forces people to have numerical beliefs across an entire range. This makes it easier to compare predictions and compute disagreements across any range (e.g. this bet suggestion based on finding the earliest range with substantial disagreement). I’m curious how much more information we can capture over time by encouraging standardized predictions.
Creating AGI forecasting frameworks
Ought’s mission is to apply ML to complex reasoning. A key first step is making reasoning about the future explicit (for example, by decomposing the components of a forecast, isolating assumptions, and putting numbers to beliefs) so that we can then automate parts of the process. We’ll share more about this in a blog post that’s coming soon!
In this thread, it seemed like a lot of people built their own forecasting structure from scratch. I’m excited about leveraging this work to create structured frameworks that people can start with when making AGI forecasts. This has the benefits of:
Here are some ideas for what this might look like:
What’s next? Some open questions
I’d be really interested in hearing other people’s reflections on this thread.
Questions I'm curious about
Ideas we have for next steps