20 Answers sorted by
Ω13440
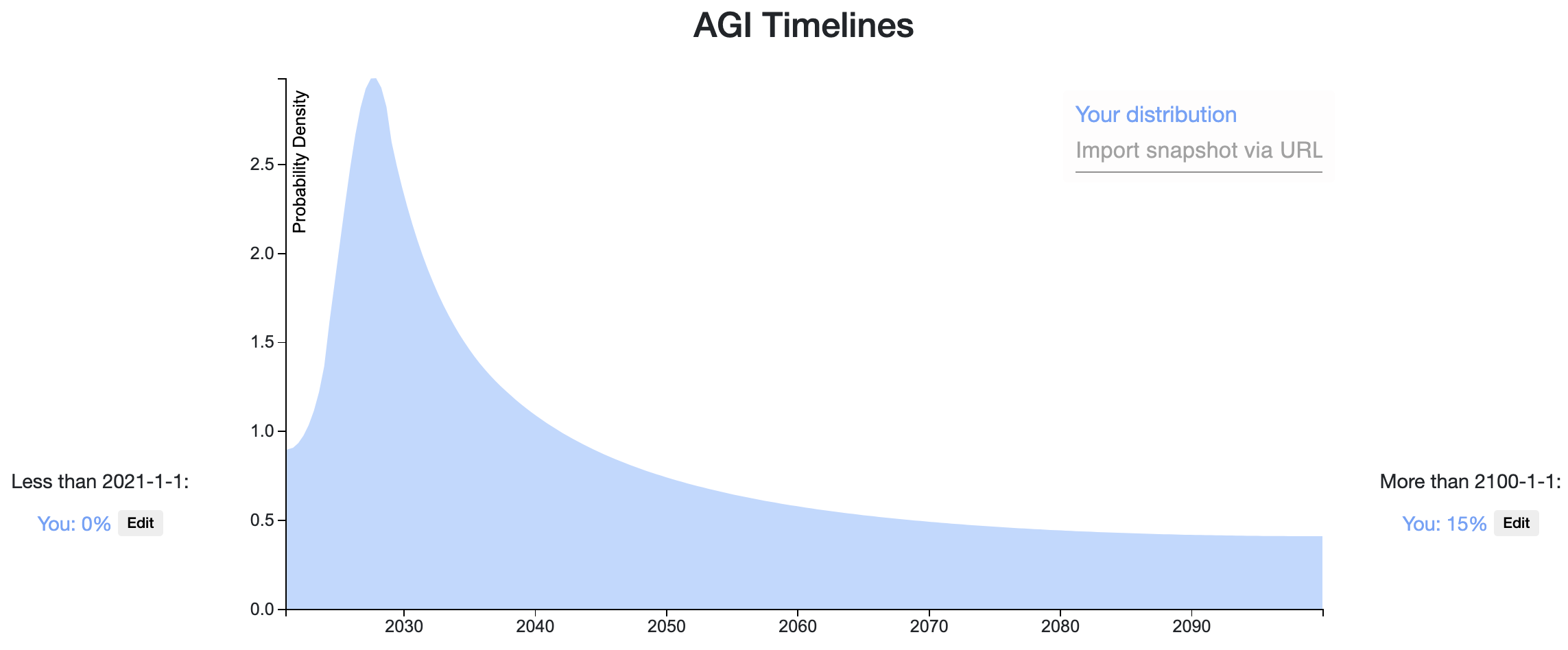
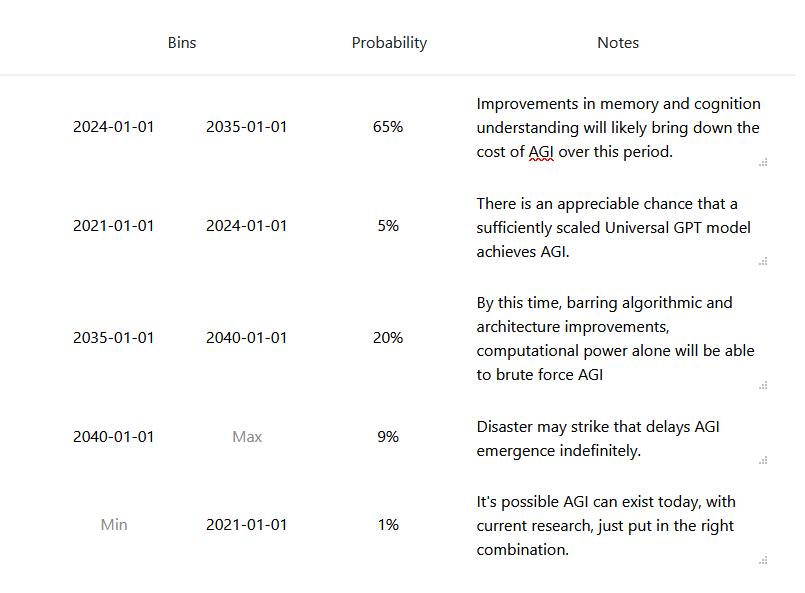
A week ago I recorded a prediction on AI timeline after reading a Vox article on GPT-3 . In general I'm much more spread out in time than the Lesswrong community. Also, I weigh more heavily outside view considerations than detailed inside view information. For example, a main consideration of my prediction is using the heurastic With 50% probability, things will last twice as long as they already have, with the starting time of 1956, the time of the Dartmouth College summer AI conference.
If AGI will definitely happen eventually, then the heuristic gives us [21.3, 64, 192] years at the [25th, 50th, 75th] percentiles of AGI to occur. AGI may never happen, but the chance of that is small enough that adjusting for that here will not make a big difference (I put ~10% that AGI will not happen for 500 years or more, but it already matches that distribution quite well).
A more inside view consideration is: what happens if the current machine learning paradigm scales to AGI? Given that assumption, a 50% confidence interval might be [2028, 2045] (since the current burst of machine learning research began in 2012-2013), which is more in line with the Lesswrong predictions and Metaculus community prediction . Taking the super outside view consideration and the outside view-ish consideration together, I get the prediction I made a week ago.
I adapted my prediction to the timeline of this post [1], and compared it with some other commenters predictions [2].
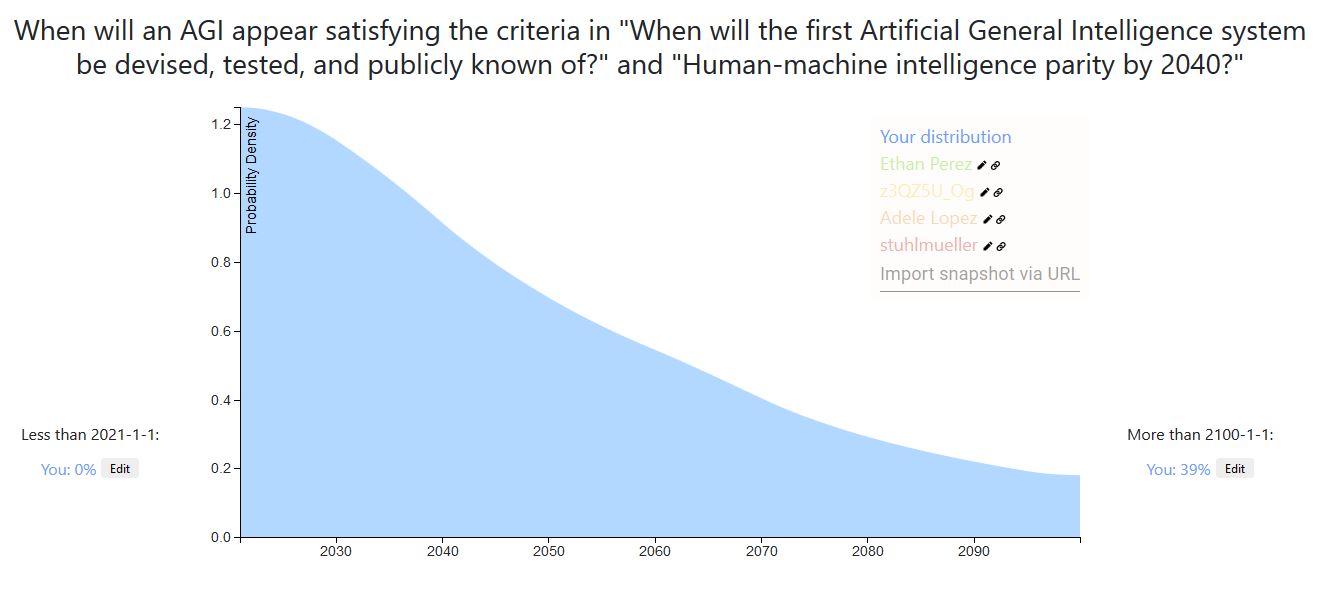
For example, a main consideration of my prediction is using the heurastic With 50% probability, things will last twice as long as they already have, with the starting time of 1956, the time of the Dartmouth College summer AI conference.
A counter hypothesis I’ve heard (not original to me) is: With 50% probability, we will be half-way through the AI researcher-years required to get AGI.
I think this suggests much shorter timelines, as most researchers have been doing research in the last ~10 years.
It's not clear to me what reference class makes sense here though. Like, I feel like 50% doesn’t make any sense. It implies that for all outstanding AI problems we’re fifty percent there. We’re 50% of the way to a rat brain, to a human emulation, to a vastly superintelligent AGI, etc. It’s not a clearly natural category for a field to be “done”, and it’s not clear which thing counts as ”done” in this particular field.
I was looking at the NIPS growth numbers last June and I made a joke:
AI researcher anthropics: 'researchers [should] tend to think AI is ~20 years away because given exponential growth of researchers & careers of ~30 years, the final generation of researchers will make up a majority of all researchers, hence, by SSA+Outside View, one must assume 20 years.'
(Of course, I'm making a rather carbon-chauvinistic assumption here that it's only human researchers/researcher-years which matter.)
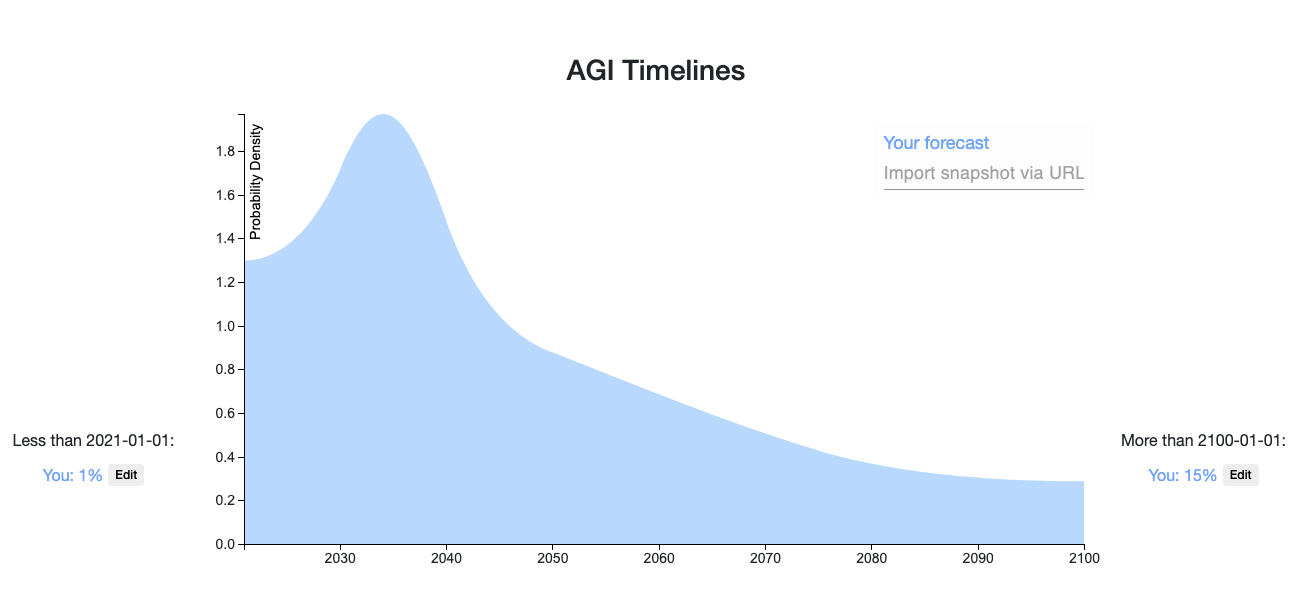
Your prediction has the interesting property that (starting in 2021), you assign more probability to the next n seconds/ n years than to any subsequent period of n seconds/ n years.
Specifically, I think your distribution assigns too much probability about AGI in the immediately next three months/year/5 years, but I feel like we do have a bunch of information that points us away from such short timelines. If one takes that into account, then one might end up with a bump, maybe like so, where the location of the bump is debatable, and the decay afterwards is per Laplace's rule.
https://elicit.ought.org/builder/J2lLvPmAY quick estimate, mostly influenced by the "outside view" and other commenters (of which I found the reasoning of tim_dettmer to be most convincing).
*
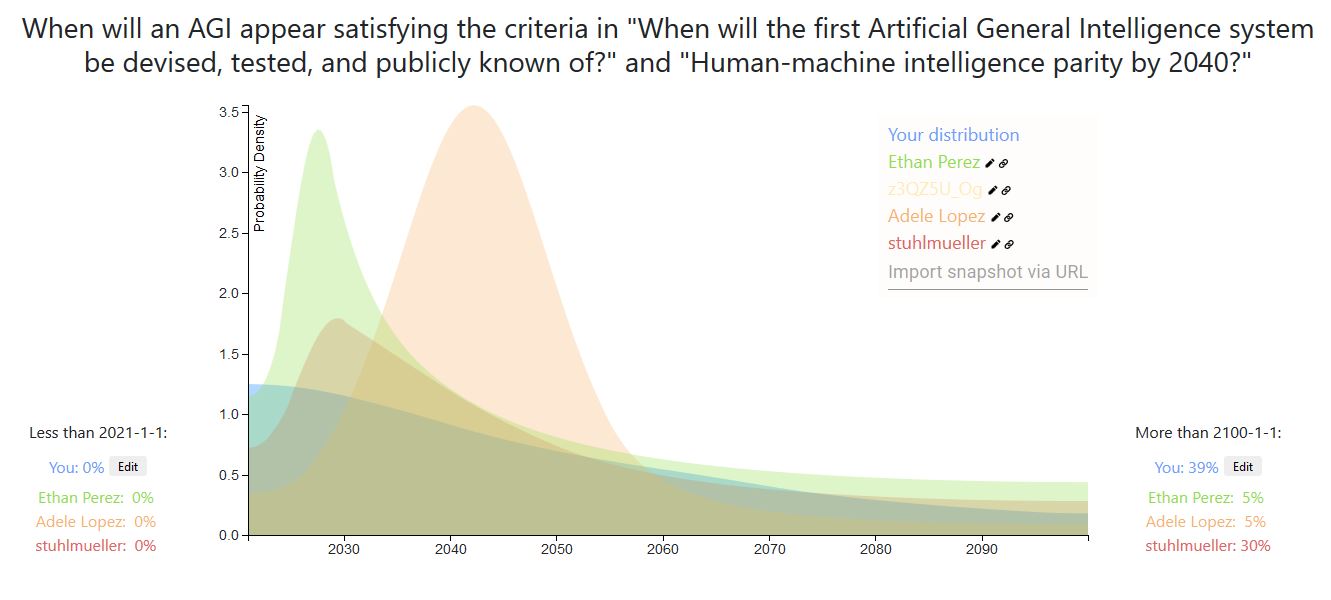
Ω16340Here is my snapshot. My reasoning is basically similar to Ethan Perez', it's just that I think that if transformative AI is achievable in the next five orders of magnitude of compute improvement (e.g. prosaic AGI?), it will likely be achieved in the next five years or so. I also am slightly more confident that it is, and slightly less confident that TAI will ever be achieved.
I am aware that my timelines are shorter than most... Either I'm wrong and I'll look foolish, or I'm right and we're doomed. Sucks to be me.
[Edited the snapshot slightly on 8/23/2020]
[Edited to add the following powerpoint slide that gets a bit more at my reasoning]
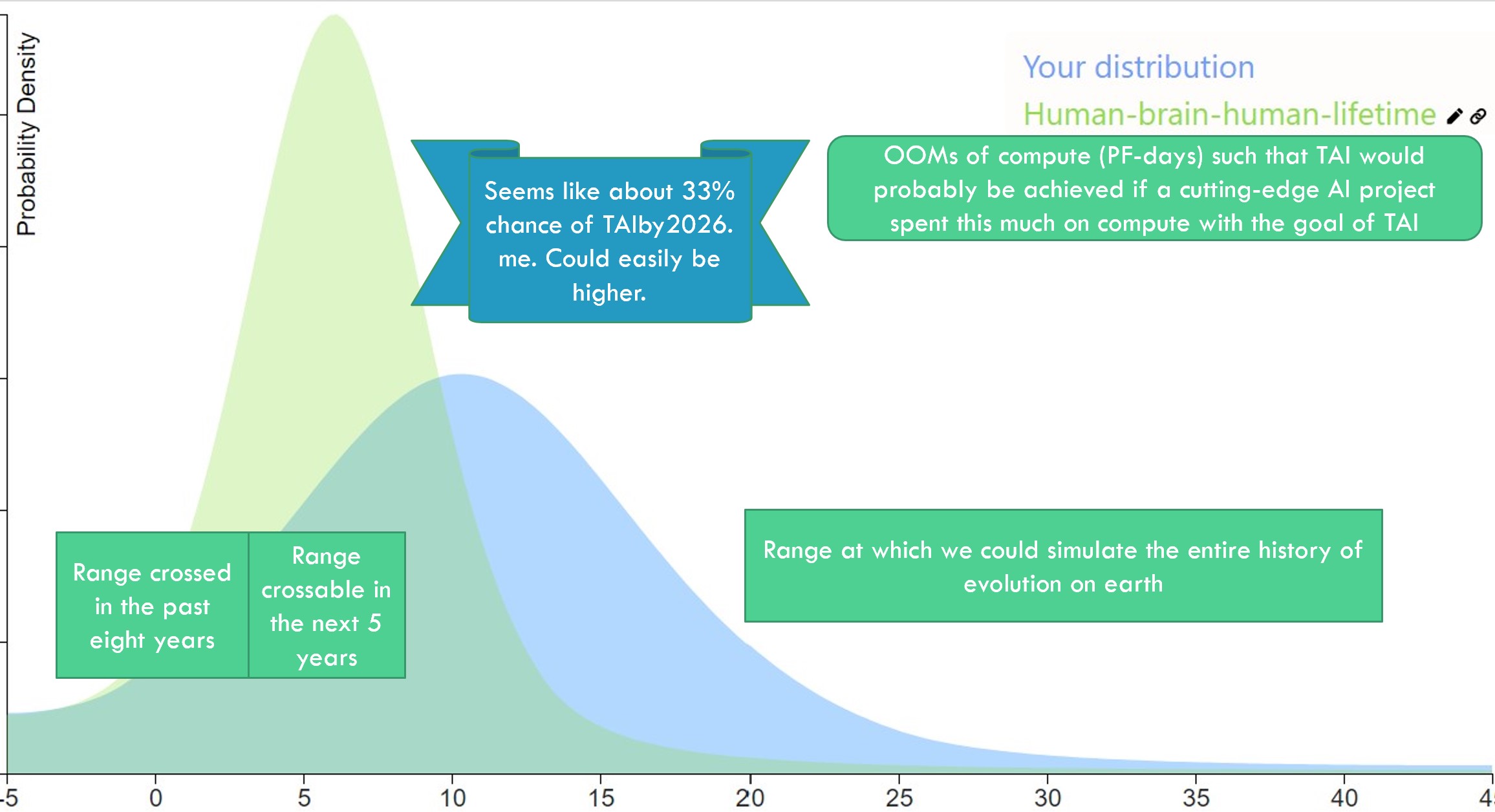
Blast from the past!
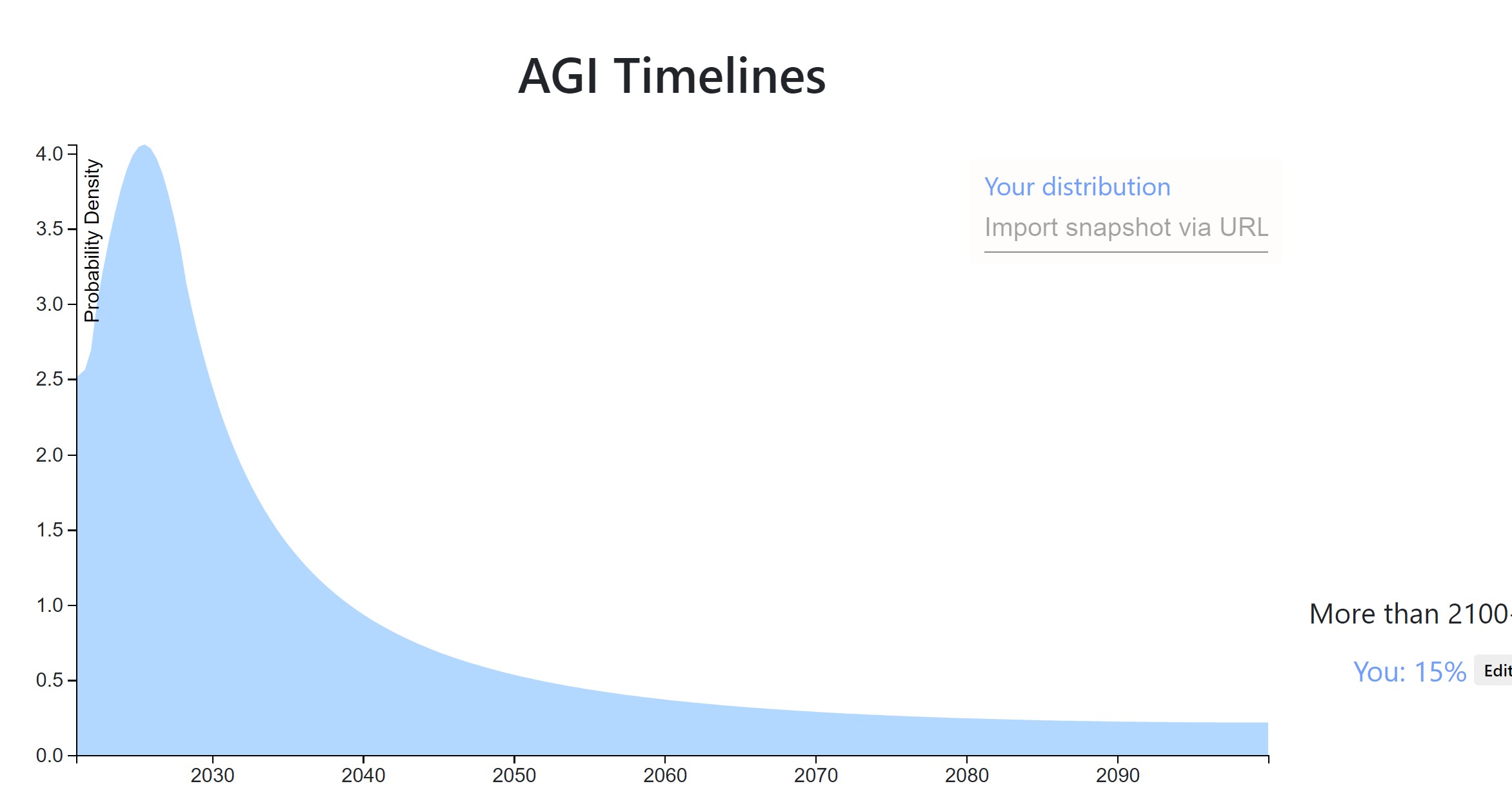
I'm biased but I'm thinking this "33% by 2026" forecast is looking pretty good.
It's been a year, what do my timelines look like now?
My median has shifted to the left a bit, it's now 2030. However, I have somewhat less probability in the 2020-2025 range I think, because I've become more aware of the difficulties in scaling up compute. You can't just spend more money. You have to do lots of software engineering and for 4+ OOMs you literally need to build more chip fabs to produce more chips. (Also because 2020 has passed without TAI/AGI/etc., so obviously I won't put as much mass there...)
So if I were to draw a distribution it would look pretty similar, just a bit more extreme of a spike and the tip of the spike might be a bit to the right.
I’m somewhat confused as to how slightly more confident, and slightly less confident equate to doom- which is a pretty strong claim imo.
*
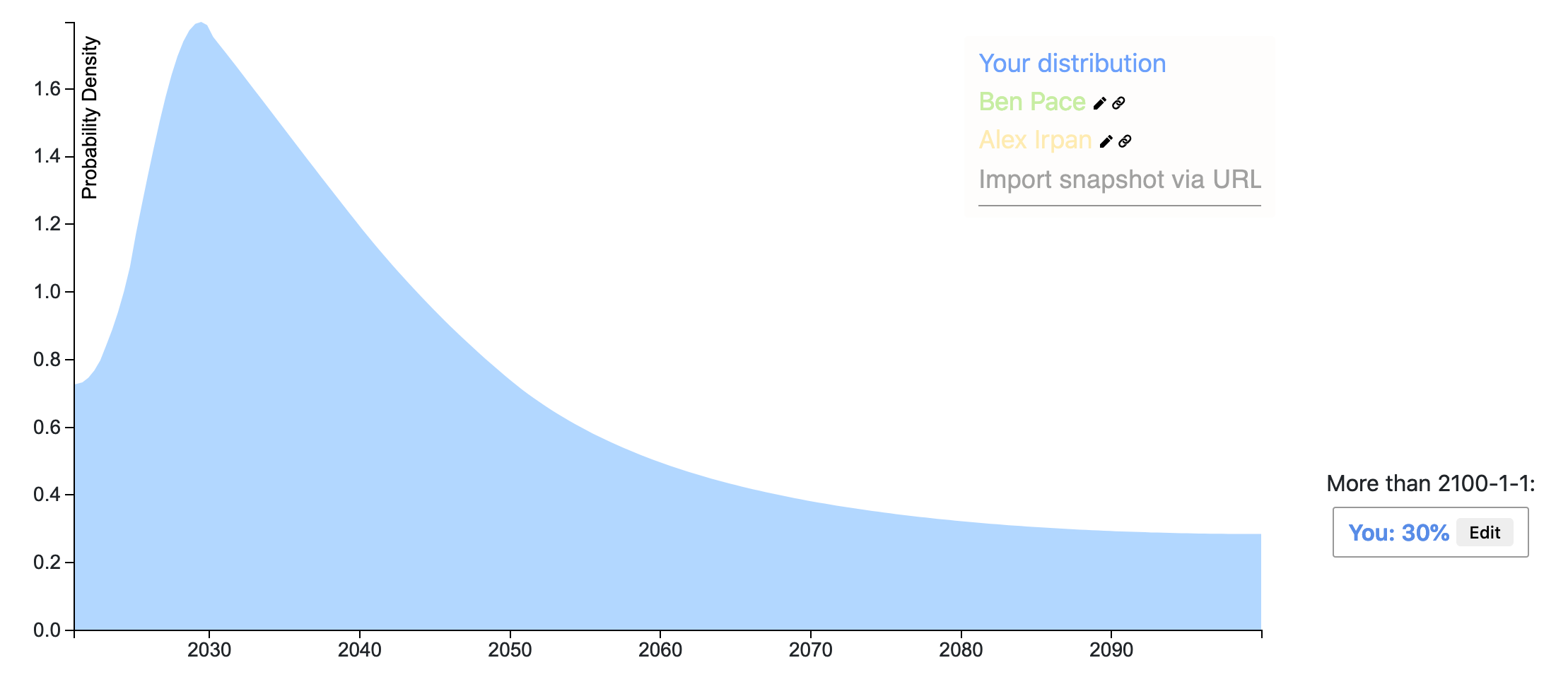
Ω15340Here is my Elicit Snapshot.
I'll follow the definition of AGI given in this Metaculus challenge, which roughly amounts to a single model that can "see, talk, act, and reason." My predicted distribution is a weighted sum of two component distributions described below:
- Prosaic AGI (25% probability). Timeline: 2024-2037 (Median: 2029): We develop AGI by scaling and combining existing techniques. The most probable paths I can foresee loosely involves 3 stages: (1) developing a language model with human-level language ability, then (2) giving it visual capabilities (i.e., talk about pictures and videos, solve SAT math problems with figures), and then (3) giving it capabilities to intelligently act in the world (i.e., trade stocks or navigate webpages). Below are my timelines for the above stages:
- Human-level Language Model: 1.5-4.5 years (Median: 2.5 years). We can predictably improve our language models by increasing model size (parameter count), which we can do in the following two ways:
- Scaling Language Model Size by 1000x relative to GPT3. 1000x is pretty feasible, but we'll hit difficult hardware/communication bandwidth constraints beyond 1000x as I understand.
- Increasing Effective Parameter Count by 100x using modeling tricks (Mixture of Experts, Sparse Tranformers, etc.)
- +Visual Capabilities: 2-6 extra years (Median: 4 years). We'll need good representation learning techniques for learning from visual input (which I think we mostly have). We'll also need to combine vision and language models, but there are many existing techniques for combining vision and language models to try here, and they generally work pretty well. A main potential bottleneck time-wise is that the language+vision components will likely need to be pretrained together, which slows the iteration time and reduces the number of research groups that can contribute (especially for learning from video, which is expensive). For reference, Language+Image pretrained models like ViLBERT came out 10 months after BERT did.
- +Action Capabilities: 0-6 extra years (Median: 2 years). GPT3-style zero-shot or few-shot instruction following is the most feasible/promising approach to me here; this approach could work as soon as we have a strong, pretrained vision+language model. Alternatively, we could use that model within a larger system, e.g. a policy trained with reinforcement learning, but this approach could take a while to get to work.
- Human-level Language Model: 1.5-4.5 years (Median: 2.5 years). We can predictably improve our language models by increasing model size (parameter count), which we can do in the following two ways:
- Breakthrough AGI (75% probability). Timeline: Uniform probability over the next century: We need several, fundamental breakthroughs to achieve AGI. Breakthroughs are hard to predict, so I'll assume a uniform distribution that we'll hit upon the necessary breakthroughs at any year <2100, with 15% total probability mass after 2100 (a rough estimate); I'm estimating 15% roughly based on a 5% probability that we won't find the right insights by 2100, 5% probability that we have the right insights but not enough compute by 2100, and 5% probability to account for planning fallacy, unknown unknowns, and the fact that a number of top AI researchers believe that we are very far from AGI.
My probability for Prosaic AGI is based on an estimated probability of each of the 3 stages of development working (described above):
P(Prosaic AGI) = P(Stage 1) x P(Stage 2) x P(Stage 3) = 3/4 x 2/3 x 1/2 = 1/4
------------------
Updates/Clarification after some feedback from Adam Gleave:
- Updated from 5% -> 15% probability that AGI won't happen by 2100 (see reasoning above). I've updated my Elicit snapshot appropriately.
- There are other concrete paths to AGI, but I consider these fairly low probability to work first (<5%) and experimental enough that it's hard to predict when they will work. For example, I can't think of a good way to predict when we'll get AGI from training agents in a simulated, multi-agent environment (e.g., in the style of OpenAI's Emergent Tool Use paper). Thus, I think it's reasonable to group such other paths to AGI into the "Breakthrough AGI" category and model these paths with a uniform distribution.
- I think you can do better than a uniform distribution for the "Breakthrough AGI" category, by incorporating the following information:
- Breakthroughs will be less frequent as time goes on, as the low-hanging fruit/insights are picked first. Adam suggested an exponential decay over time / Laplacian prior, which sounds reasonable.
- Growth of AI research community: Estimate the size of the AI research community at various points in time, and estimate the pace of research progress given that community size. It seems reasonable to assume that the pace of progress will increase logarithmically in the size of the research community, but I can also see arguments for why we'd benefit more or less from a larger community (or even have slower progress).
- Growth of funding/compute for AI research: As AI becomes increasingly monetizable, there will be more incentives for companies and governments to support AI research, e.g., in terms of growing industry labs, offering grants to academic labs to support researchers, and funding compute resources - each of these will speed up AI development.
Scaling Language Model Size by 1000x relative to GPT3. 1000x is pretty feasible, but we'll hit difficult hardware/communication bandwidth constraints beyond 1000x as I understand.
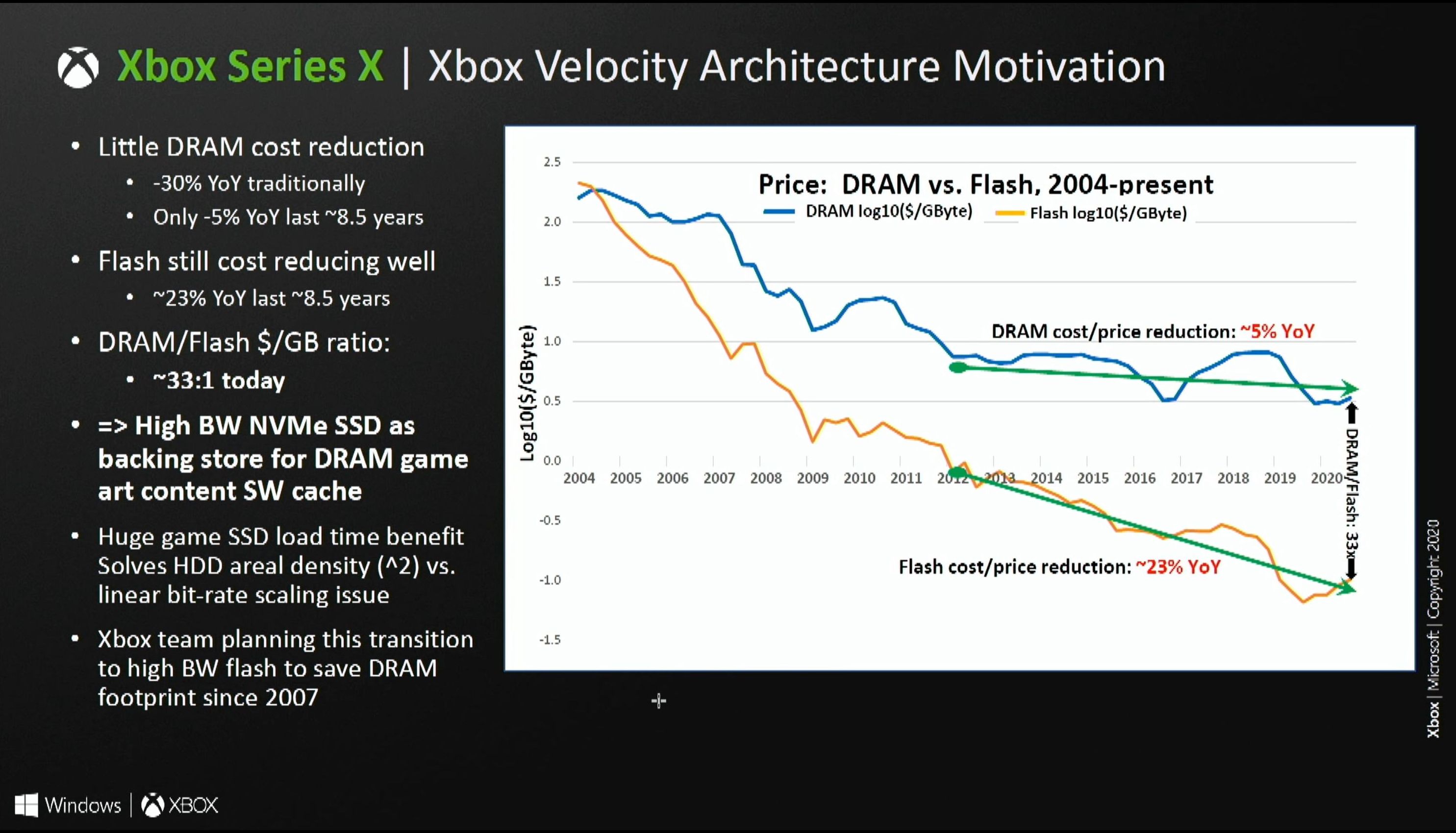
I think people are hugely underestimating how much room there is to scale.
The difficulty, as you mention, is bandwidth and communication, rather than cost per bit in isolation. An A100 manages 1.6TB/sec of bandwidth to its 40 GB of memory. We can handle sacrificing some of this speed, but something like SSDs aren't fast enough; 350 TB of SSD memory would cost just $40k, but would only manage 1-2 TB/s over the whole array, and could not push it to a single GPU. More DRAM on the GPU does hit physical scaling issues, and scaling out to larger clusters of GPUs does start to hit difficulties after a point.
This problem is not due to physical law, but the technologies in question. DRAM is fast, but has hit a scaling limit, whereas NAND scales well, but is much slower. And the larger the cluster of machines, the more bandwidth you have to sacrifice for signal integrity and routing.
Thing is, these are fixable issues if you allow for technology to shift. For example,
- Various sorts of persistent memories all
Ω9250
Here's my answer. I'm pretty uncertain compared to some of the others!

First, I'm assuming that by AGI we mean an agent-like entity that can do the things associated with general intelligence, including things like planning towards a goal and carrying that out. If we end up in a CAIS-like world where there is some AI service or other that can do most economically useful tasks, but nothing with very broad competence, I count that as never developing AGI.
I've been impressed with GPT-3, and could imagine it or something like it scaling to produce near-human level responses to language prompts in a few years, especially with RL-based extensions.
But, following the list (below) of missing capabilities by Stuart Russell, I still think things like long-term planning would elude GPT-N, so it wouldn't be agentive general intelligence. Even though you might get those behaviours with trivial extensions of GPT-N, I don't think it's very likely.
That's why I think AGI before 2025 is very unlikely (not enough time for anything except scaling up of existing methods). This is also because I tend to expect progress to be continuous, though potentially quite fast, and going from current AI to AGI in less than 5 years requires a very sharp discontinuity.
AGI before 2035 or so happens if systems quite a lot like current deep learning can do the job, but which aren't just trivial extensions of them - this seems reasonable to me on the inside view - e.g. it takes us less than 15 years to take GPT-N and add layers on top of it that handle things like planning and discovering new actions. This is probably my 'inside view' answer.
I put a lot of weight on a tail peaking around 2050 because of how quickly we've advanced up this 'list of breakthroughs needed for general intelligence' -
There is this list of remaining capabilities needed for AGI in an older post I wrote, with the capabilities of 'GPT-6' as I see them underlined:
Stuart Russell’s List
human-like language comprehension
cumulative learning
discovering new action sets
managing its own mental activity
For reference, I’ve included two capabilities we already have that I imagine being on a similar list in 1960
So we'd have discovering new action sets, and managing mental activity - effectively, the things that facilitate long-range complex planning, remaining.
So (very oversimplified) if around the 1980s we had efficient search algorithms, by 2015 we had image recognition (basic perception) and by 2025 we have language comprehension courtesy of GPT-8, that leaves cumulative learning (which could be obtained by advanced RL?), then discovering new action sets and managing mental activity (no idea). It feels a bit odd that we'd breeze past all the remaining milestones in one decade after it took ~6 to get to where we are now. Say progress has sped up to be twice as fast, then it's 3 more decades to go. Add to this the economic evidence from things like Modelling the Human Trajectory, which suggests a roughly similar time period of around 2050.
Finally, I think it's unlikely but not impossible that we never build AGI and instead go for tool AI or CAIS, most likely because we've misunderstood the incentives such that it isn't actually economical or agentive behaviour doesn't arise easily. Then there's the small (few percent) chance of catastrophic or existential disaster which wrecks our ability to invent things. This is the one I'm most unsure about - I put 15% for both but it may well be higher.
This is also because I tend to expect progress to be continuous, though potentially quite fast, and going from current AI to AGI in less than 5 years requires a very sharp discontinuity.
I object! I think your argument from extrapolating when milestones have been crossed is good, but it's just one argument among many. There are other trends which, if extrapolated, get to AGI in less than five years. For example if you extrapolate the AI-compute trend and the GPT-scaling trends you get something like "GPT-5 will appear 3 years from now and be 3 orders of mag...
Daniel and SDM, what do you think of a bet with 78:22 odds (roughly 4:1) based on the differences in your distributions, i.e: If AGI happens before 2030, SDM owes Daniel $78. If AGI doesn't happen before 2030, Daniel owes SDM $22.
This was calculated by:
- Identifying the earliest possible date with substantial disagreement (in this case, 2030)
- Finding the probability each person assigns to the date range of now to 2030:
- Finding a fair bet
- According to this post, a bet based on the arithmetic mean of 2 differing probability estimates yields the same expected value for each participant. In this case, the mean is (5%+39%)/2=22% chance of AGI before 2030, equivalent to 22:78 odds.
- $78 and $22 can be scaled appropriately for whatever size bet you're comfortable with
That small tail at the end feels really suspicious. I.e., it implies that if we haven't reached AGI by 2080, then we probably won't reach it at all. I feel like this might be an artifact of specifying a small number of bins on elicit, though.
{kind=link}
*
Ω10200Here's my quick forecast, to get things going. Probably if anyone asks me questions about it I'll realise I'm embarrassed by it and change it.
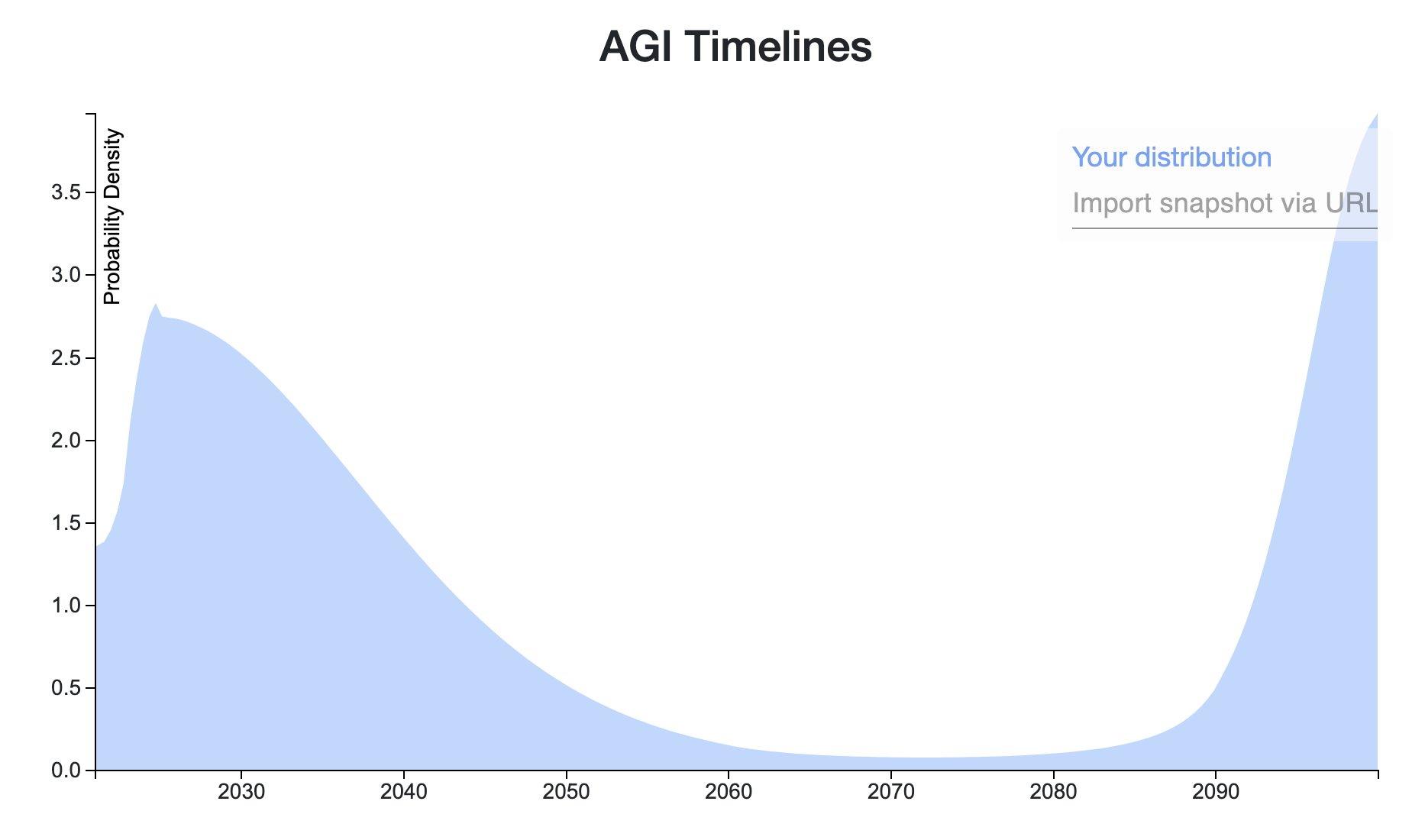
It has three buckets:
10%: We get to AGI with the current paradigm relatively quickly without major bumps.
60%: We get to it eventually sometime in the next ~50 years.
30%: We manage to move into a stable state where nobody can unilaterally build an AGI, then we focus on alignment for as long as it takes before we build it.
2nd attempt
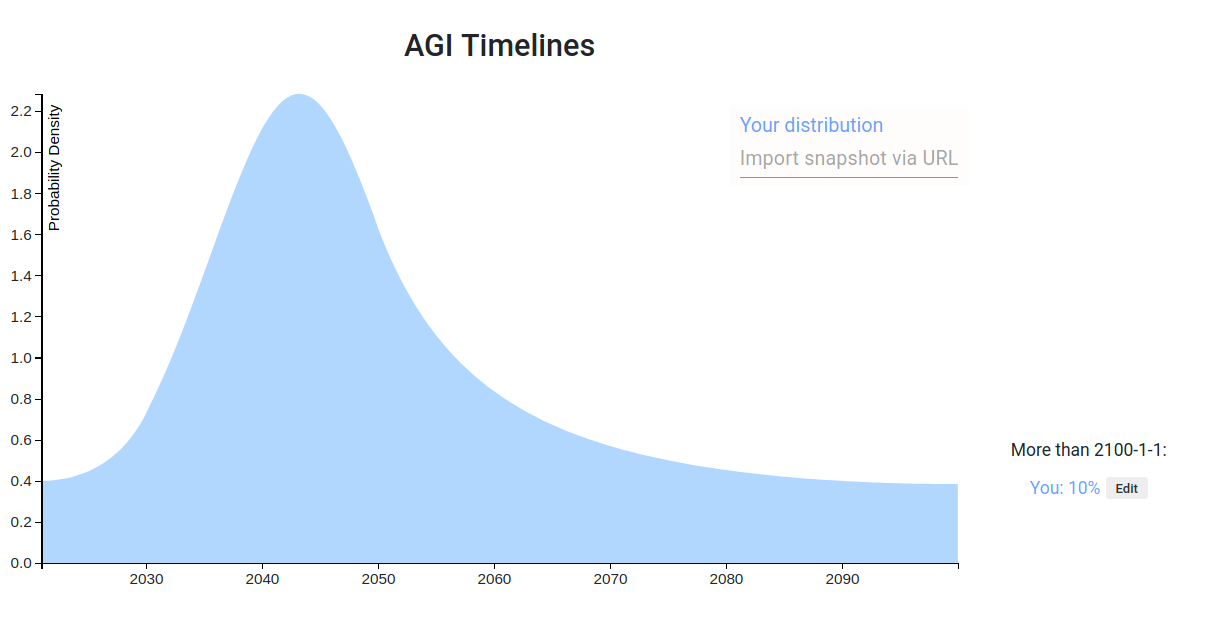
Adele Lopez is right that 30% is super optimistic. Also I accidentally put a bunch within '2080-2100', instead of 'after 2100'. And also I thought about it more. here's my new one.
Link.
It has four buckets:
20% Current work leads directly into AI in the next 15 years.
55% There are some major bottlenecks, new insights needed, and some engineering projects comparable in size to the manhattan project. This is 2035 to 2070.
10% This is to fill out 2070 to 2100.
15% We manage to move to a stable state, or alternatively civilizational collapse / non-AI x-risk stops AI research. This is beyond 2100.
Ω9170
My rough take: https://elicit.ought.org/builder/oTN0tXrHQ
3 buckets, similar to Ben Pace's
- 5% chance that current techniques just get us all the way there, e.g. something like GPT-6 is basically AGI
- 10% chance AGI doesn't happen this century, e.g. humanity sort of starts taking this seriously and decides we ought to hold off + the problem being technically difficult enough that small groups can't really make AGI themselves
- 50% chance that something like current techniques and some number of new insights gets us to AGI.
If I thought about this for 5 additional hours, I can imagine assigning the following ranges to the scenarios:
- [1, 25]
- [1, 30]
- [20, 80]
Ω11170
Roughly my feelings: https://elicit.ought.org/builder/trBX3uNCd

Reasoning: I think lots of people have updated too much on GPT-3, and that the current ML paradigms are still missing key insights into general intelligence. But I also think enough research is going into the field that it won't take too long to reach those insights.
Ω6150
To the extent that it differs from others' predictions, probably the most important factor is that I think even if AGI is hard, there are a number of ways in which human civilization could become capable of doing almost arbitrarily hard things, like through human intelligence enhancement or sufficiently transformative narrow AI. I think that means the question is less about how hard AGI is and more about general futurism than most people think. It's moderately hard for me to imagine how business as usual could go on for the rest of the century, but who knows.
*
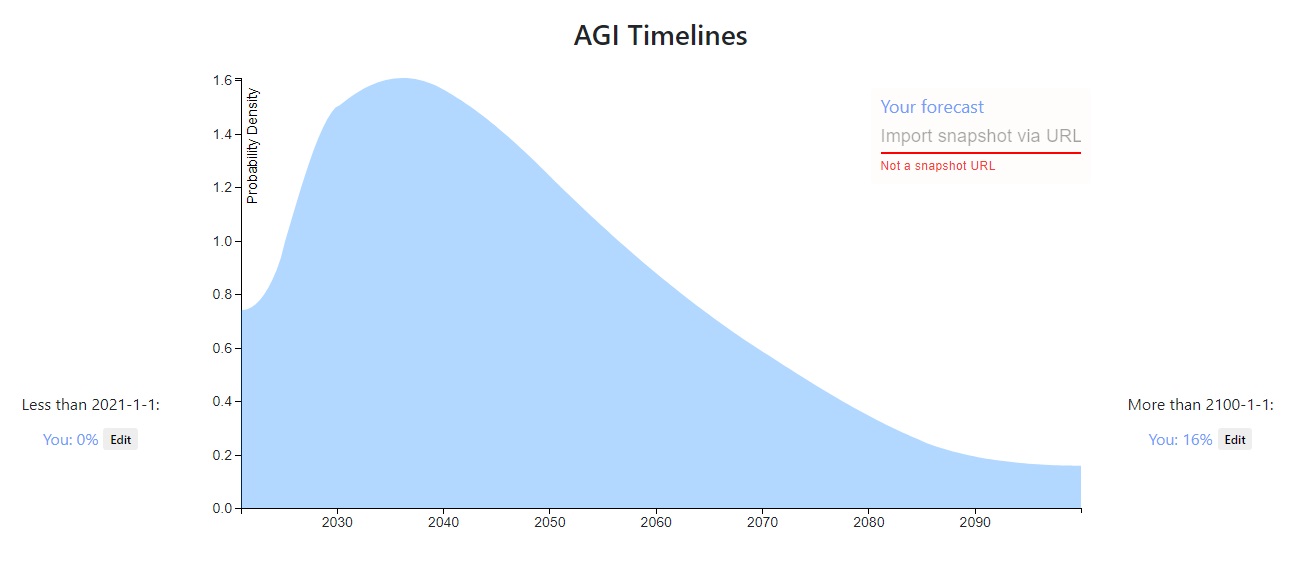
Ω6140My snapshot: https://elicit.ought.org/builder/xPoVZh7Xq
Idk what we mean by "AGI", so I'm predicting when transformative AI will be developed instead. This is still a pretty fuzzy target: at what point do we say it's "transformative"? Does it have to be fully deployed and we already see the huge economic impact? Or is it just the point at which the model training is complete? I'm erring more on the side of "when the model training is complete", but also there may be lots of models contributing to TAI, in which case it's not clear which particular model we mean. Nonetheless, this feels a lot more concrete and specific than AGI.
Methodology: use a quantitative model, and then slightly change the prediction to account for important unmodeled factors. I expect to write about this model in a future newsletter.
Some updates:
- This should really be thought of as "when we see the transformative economic impact", I don't like the "when model training is complete" framing (for basically the reason mentioned above, that there may be lots of models).
- I've updated towards shorter timelines; my median is roughly 2045 with a similar shape of the distribution as above.
- One argument for shorter timelines than that in bio anchors is "bio anchors doesn't take into account how non-transformative AI would accelerate AI progress".
- Another relevant argument is "the huge difference between training time compute and inference time compute suggests that we'll find ways to get use out of lots of inferences with dumb models rather than a few inferences with smart models; this means we don't need models as smart as the human brain, thus lessening the needed compute at training time".
- I also feel more strongly about short horizon models probably being sufficient (whereas previously I mostly had a mixture between short and medium horizon models).
- Conversely, reflecting on regulation and robustness made me think I was underweighting those concerns, and lengthened my timelines.
*
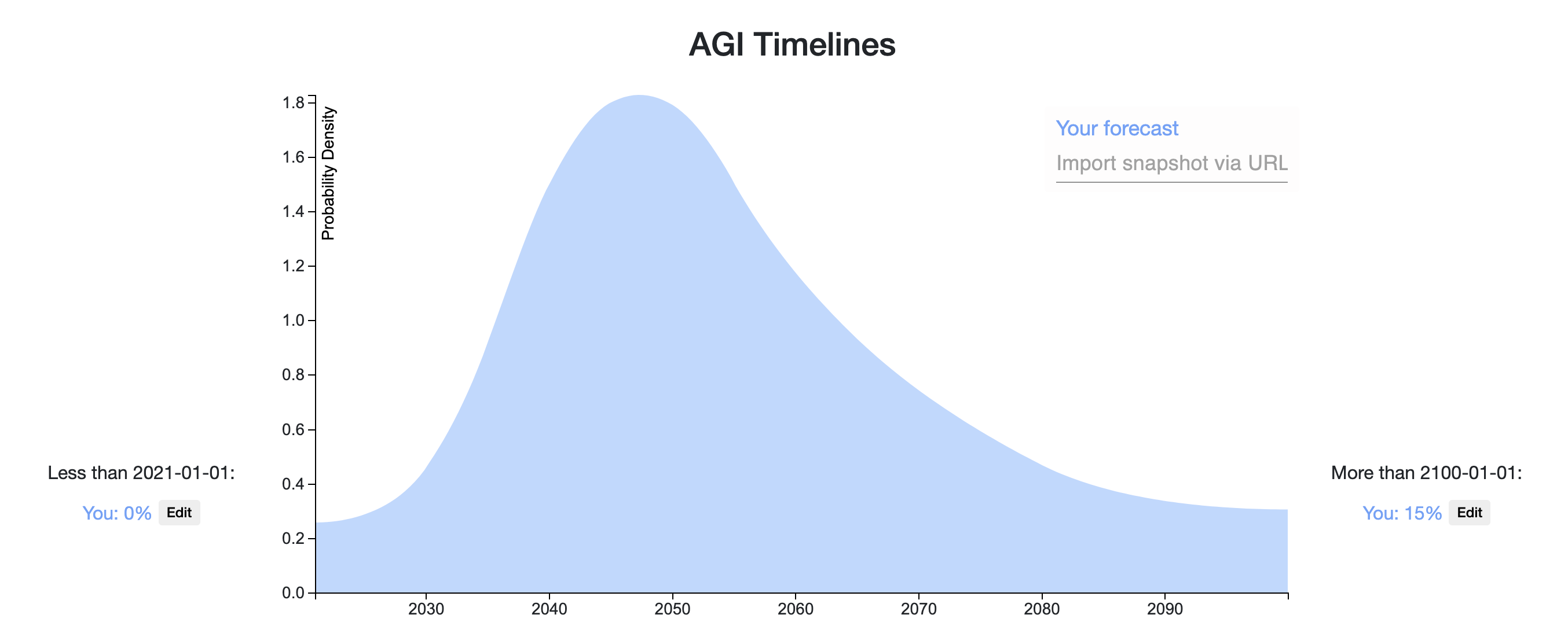
Ω5130If AGI is taken to mean, the first year that there is radical economic, technological, or scientific progress, then these are my AGI timelines.

My percentiles
- 5th: 2029-09-09
- 25th: 2049-01-17
- 50th: 2079-01-24
- 75th: above 2100-01-01
- 95th: above 2100-01-01
I have a bit lower probability for near-term AGI than many people here are. I model my biggest disagreement as about how much work is required to move from high-cost impressive demos to real economic performance. I also have an intuition that it is really hard to automate everything and progress will be bottlenecked by the tasks that are essential but very hard to automate.
Some updates:
- I now have an operationalization of AGI I feel happy about, and I think it's roughly just as difficult as creating transformative AI (though perhaps still slightly easier).
- I have less probability now on very long timelines (>80 years). Previously I had 39% credence on AGI arriving after 2100, but I now only have about 25% credence.
- I also have a bit more credence on short timelines, mostly because I think the potential for massive investment is real, and it doesn't seem implausible that we could spend >1% of our GDP on AI development at s
*
1202022-03-19: someone talked to me for many hours about the scaling hypothesis, and i've now updated to shorter timelines; i havent thought about quantifying the update yet, but I can see a path to AGI by 2040 now
(as usual, conditional on understanding the question and the question making sense)
where human-level AGI means an AI better at any task than any human living in 2020, where biologically-improved and machine-augmented humans don't count as AIs for the purpose of this question, but uploaded humans do
said AGI needs to be created by our civilisation
the probability density is the sum of my credences for different frequency of future worlds with AGIs
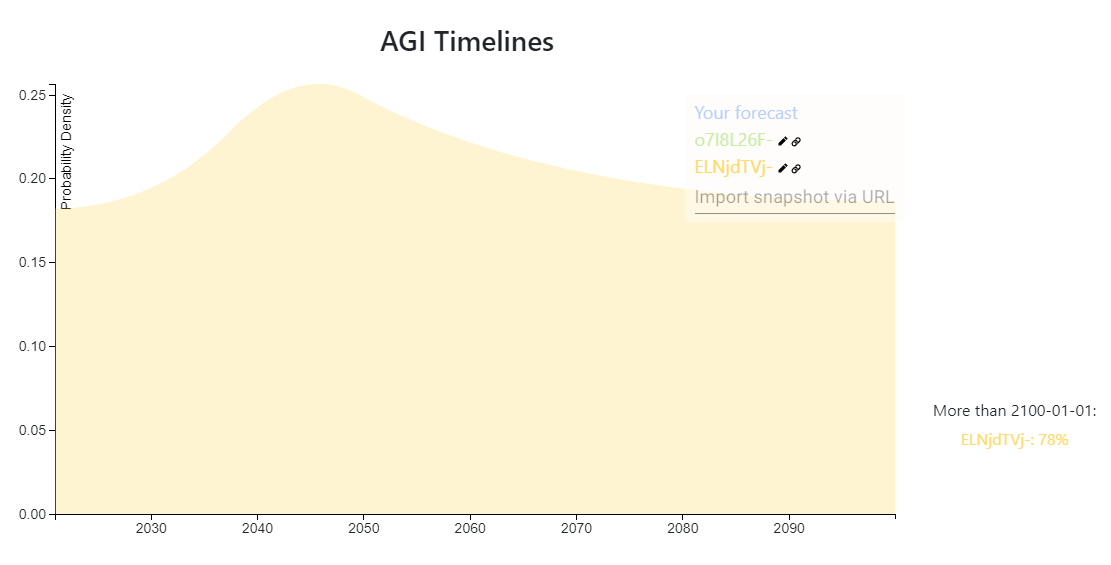
https://elicit.ought.org/builder/ELNjdTVj-
1% it already happened
52% it won't happen (most likely because we'll go extinct or stop being simulated)
26% after 2100
EtA: moved a 2% from >2100 to <2050
Someone asked me:
Any reason why you have such low probability on AGI within like 80 years
partly just wide priors and I didn't update much, partly Hansonian view, partly Drexler's view, partly seems like a hard problem
Note to self; potentially to read:
- Your percentiles:
- 5th: 2040-10-01
- 25th: above 2100-01-01
- 50th: above 2100-01-01
- 75th: above 2100-01-01
- 95th: above 2100-01-01
XD
Update: 18% <2033 18% 2033-2043 18% 2043-2053 18% 2050-2070 28% 2070+ or won't happen
see more details on my shortform: https://www.lesswrong.com/posts/DLepxRkACCu8SGqmT/mati_roy-s-shortform?commentId=KjxnsyB7EqdZAuLri
Without consulting my old prediction here, I answered someone asking me:
What is your probability mass for the date with > 50% chance of agi?
with:
I used to use the AGI definition "better and cheaper than humans at all economic tasks", but now I think even if we're dumber, we might still be better at some economic tasks simply because we know human values more. Maybe the definition could be "better and cheaper at any well defined tasks". In that case, I'd say maybe 2080, taking into account some probability of economic stagnation and some probability that sub-AGI AIs cause an existential catastrophe (and so we don't develop AGI)
will start tracking some of the things I read on this here:
- 2020-09-28: finished the summary of Conversation with Robin Hanson
note to self -- read:
topic: AI timelines
probability nothing here is new, but it's some insights I had
summary: alignment will likely become the bottleneck; we'll have human-capable AIs but they won't do every tasks because we won't know how to specify them
epistemic status: stated more confidently than I am, but seems like a good consideration to add to my portfolio of plausible models of AI development
when I was asking my inner sim "when will we have an AI better than a human at any task", it was returning 21% before 2100 (52% we won't) (see: https://www.lesswrong.com/posts/hQy...
The key observation is, imitation learning algorithms[1] might produce close-to-human-level intelligence even if they are missing important ingredients of general intelligence that humans have.
110
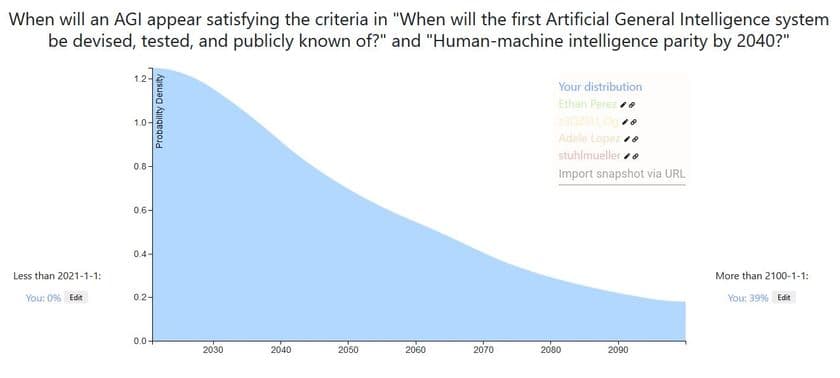
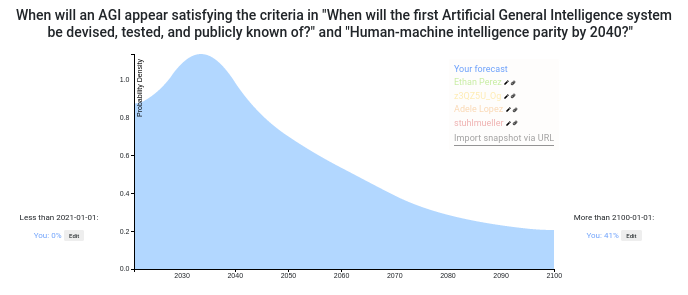
Here is my own answer.
- It takes as a starting point datscilly's own prediction, i.e., the result of applying Laplace's rule from the Dartmouth conference. This seems like the most straightfoward historical base rate / model to use, and on a meta-level I trust datscilly and I've worked with him before.
- I then substract some probability from the beginning and move it towards the end because I think it's unlikely we'll get human parity in the next 5 years. In particular, even Daniel Kokotajlo, the most bullish among the other predictors puts his peak somewhere around 2025.
- I then apply some smoothing.
My resulting distribution looks similar to the current aggregate (and this I noticed after building it)
Datscilly's prediction:
My prediction:
The previous aggregate:
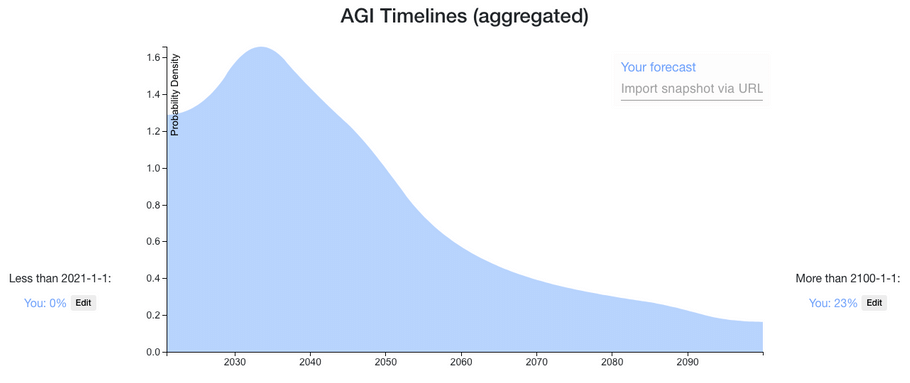
Something I don't like about the other predictions are:
- Not long enough tails. There have been AI winters before; there could be AI winters again. Shit happens.
- Very spiky maximums. I get that specific models can provide sharp predictions, but the question seems hard enough that I'd expect there to be a large amount of model error. I'd also expect predictions which take into account multiple models to do better.
- Not updating on other predictions. Some of the other forecasters seem to have one big idea, rather than multiple uncertainties.
Things that would change my mind:
At the five minute level:
- Getting more information about Daniel Kokotajlo's models. On a meta-level, learning that he is a superforecaster.
- Some specific definitions of "human level".
At the longer-discussion level:
- Object level arguments about AI architectures
- Some information about whether experts believe that current AI methods can lead to AGI.
- Some object level arguments about Moore's law. I.e., by which year does Moore's law predict we'll have much more computing power than the higher estimates for the human Brain?
I'm also uncertain about what probability to assign to AGI after 2100.
I might revisit this as time goes on.
I'm not a superforecaster. I'd be happy to talk more about my models if you like. You may be interested to know that my prediction was based on aggregating various different models, and also that I did try to account for things usually taking longer than expected. I'm trying to arrange a conversation with Ben Pace, perhaps you could join. I could also send you a powerpoint I made, or we could video chat.
I can answer your question #3. There's been some good work on the question recently by people at OpenPhil and AI Impacts.
*
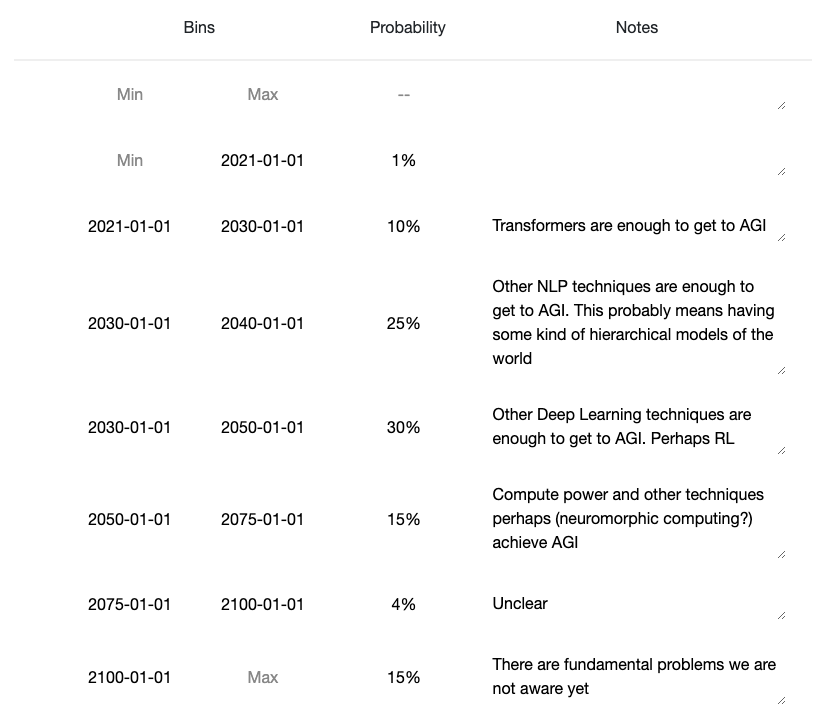
100Prediction: https://elicit.ought.org/builder/ZfFUcNGkL
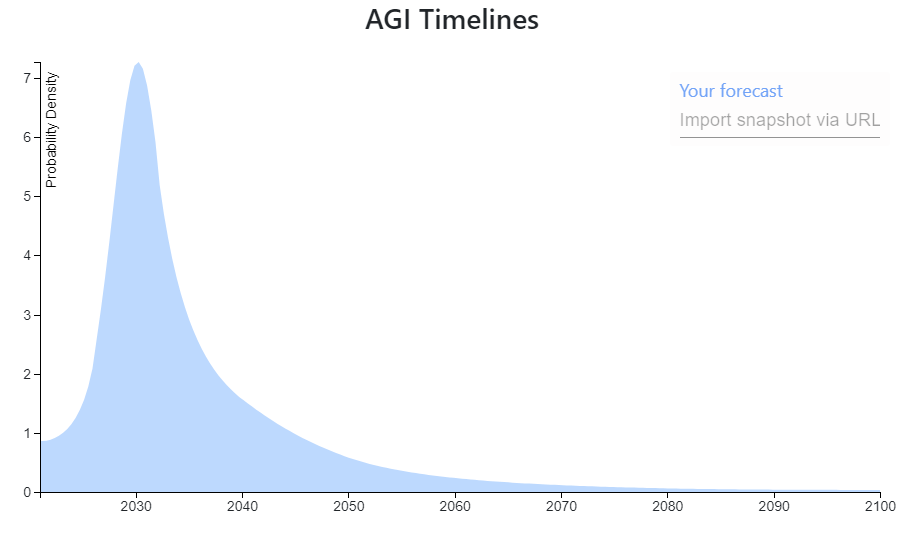
I (a non-expert) heavily speculate the following scenario for an AGI based on Transformer architectures:
The scaling hypothesis is likely correct (and is the majority of the probability density for the estimate), and maybe only two major architectural breakthroughs are needed before AGI. The first is a functioning memory system capable of handling short and long term memories with lifelong learning without the problems of fine tuning.
The second architectural breakthrough needed would be allowing the system to function in an 'always on' kind of fashion. For example current transformers get an input then spit an output and are done. Where as a human can receive an input, output a response, but then keep running, seeing the result of their own output. I think an 'always on' functionality will allow for multi-step reasoning, and functional 'pruning' as opposed to 'babble'. As an example of what I mean, think of a human carefully writing a paragraph and iterating and fixing/rewriting past work as they go, rather than just the output being their stream of consciousness. Additionally it could allow a system to not have to store all information within its own mind, but rather use tools to store information externally. Getting an output that has been vetted for release rather than a thought stream seems very important for high quality.
Additionally I think functionality such as agent behavior and self awareness only require embedding an agent in a training environment simulating a virtual world and its interactions (See https://www.lesswrong.com/posts/p7x32SEt43ZMC9r7r/embedded-agents ). I think this may be the most difficult to implement, and there are uncertainties. For example does all training need to take place within this environment? Or is only an additional training run after it has been trained like current systems necessary.
I think such a system utilizing all the above may be able to introspectively analyse its own knowledge/model gaps and actively research to correct them. I think that could cause a discontinuous jump in capabilities.
I think that none of those capabilities/breakthroughs seem out of reach this decade, that that scaling will continue to quadrillions of parameters by the end of the decade (in addition to continued efficiency improvements).
I hope an effective control mechanism can be found by then. (Assuming any of this is correct, 5 months ago I would have laughed at this.).
90
Holden Karnofsky wrote on Cold Takes:
I estimate that there is more than a 10% chance we'll see transformative AI within 15 years (by 2036); a ~50% chance we'll see it within 40 years (by 2060); and a ~2/3 chance we'll see it this century (by 2100).
I copied these bins to create Holden's approximate forecasted distribution (note that Holden's forecast is for Transformative AI rather than human-level AGI):
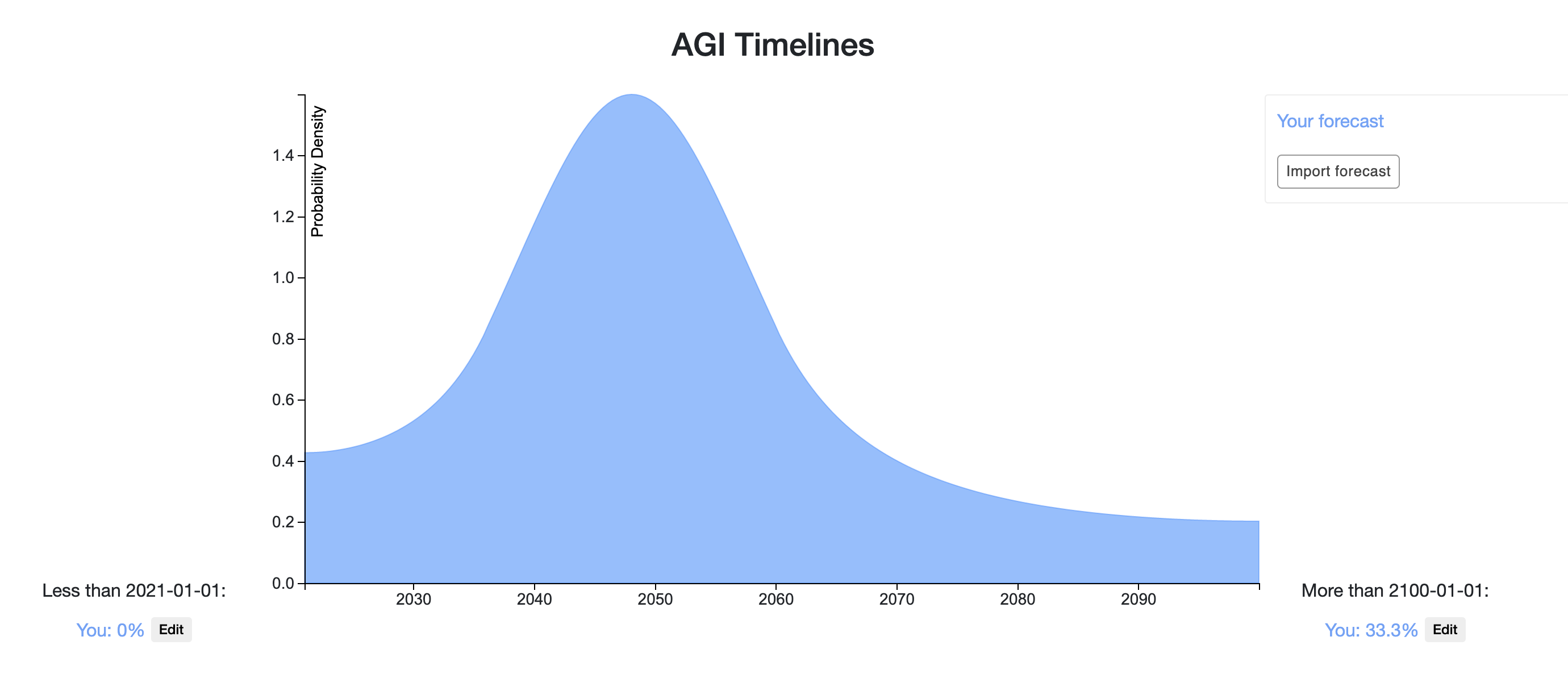
Compared to the upvote-weighted mixture in the OP, it puts more probability on longer timelines, with a median of 2060 vs. 2047 and 1/3 vs. 1/5 on after 2100. Holden gives a 10% chance by 2036 while the mixture gives approximately 30%. Snapshot is here.
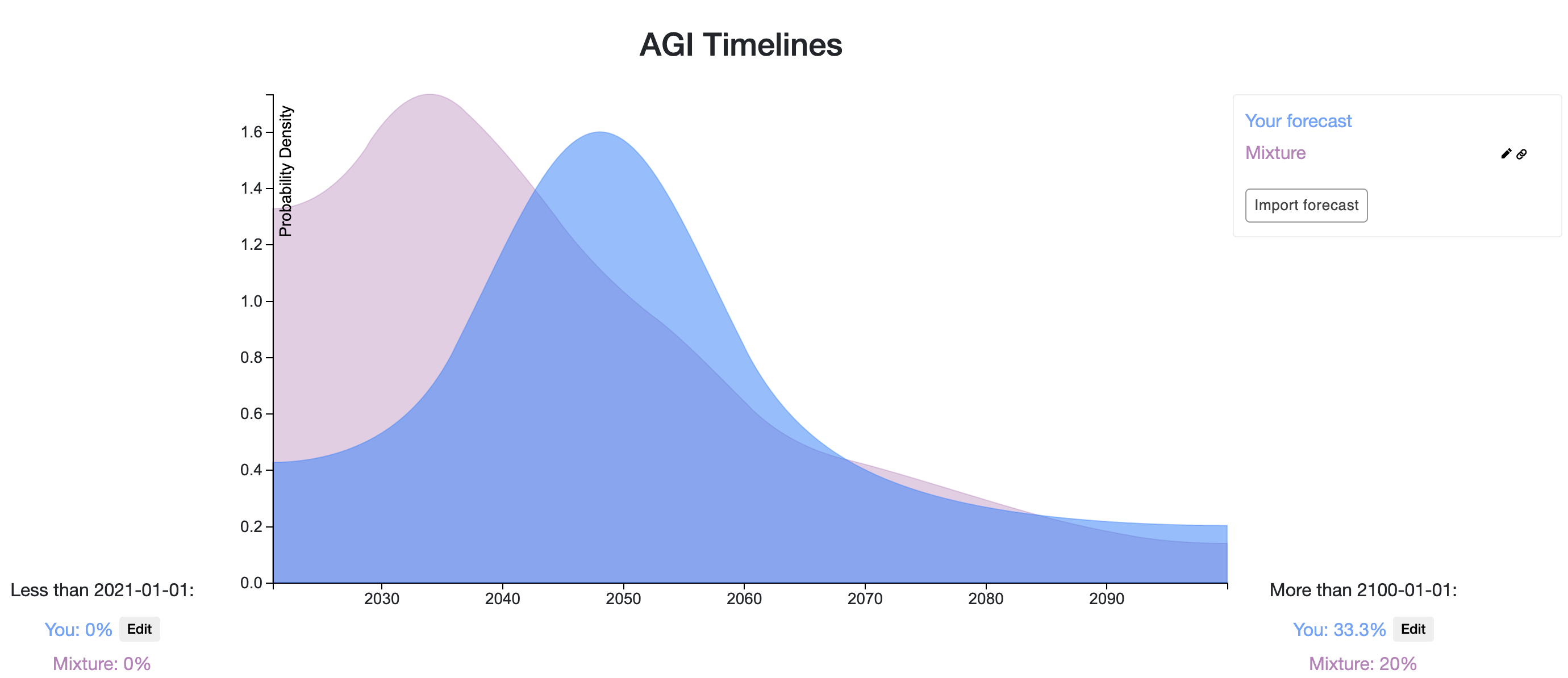
Ω480
Here is a link to my forecast
And here are the rough justifications for this distribution:
I don't have much else to add beyond what others have posted, though it's in part influenced by an AIRCS event I attended in the past. Though I do remember being laughed at for suggesting GPT-2 represented a very big advance toward AGI.
I've also never really understood the resistance to why current models of AI are incapable of AGI. Sure, we don't have AGI with current models, but how do we know it isn't a question of scale? Our brains are quite efficient, but the total energy consumption is comparable to that of a light bulb. I find it very hard to believe that a server farm in an Amazon, Microsoft, or Google Datacenter would be incapable of running the final AGI algorithm. And for all the talk of the complexity in the brain, each neuron is agonizingly slow (200-300Hz).
That's also to say nothing of the fact that the vast majority of brain matter is devoted to sensory processing. Advances in autonomous vehicles are already proving that isn't an insurmountable challenge.
Current AI models are performing very well at pattern recognition. Isn't that most of what our brains do anyway?
Self attended recurrent transformer networks with some improvements to memory (attention context) access and recall to me look very similar to our own brain. What am I missing?
...I've also never really understood the resistance to why current models of AI are incapable of AGI. Sure, we don't have AGI with current models, but how do we know it isn't a question of scale? Our brains are quite efficient, but the total energy consumption is comparable to that of a light bulb. I find it very hard to believe that a server farm in an Amazon, Microsoft, or Google Datacenter would be incapable of running the final AGI algorithm. And for all the talk of the complexity in the brain, each neuron is agonizingly slow (200-
60
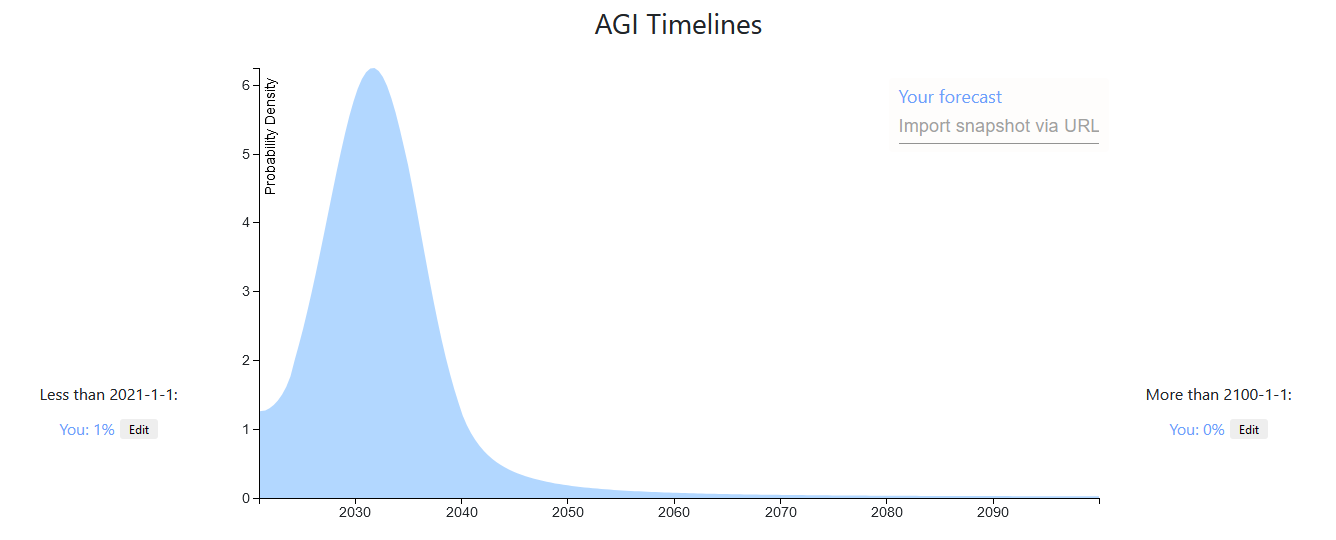
My prediction. Some comments
- Your percentiles:
- 5th: 2023-05-16
- 25th: 2033-03-31
- 50th: 2046-04-13
- 75th: 2075-11-27
- 95th: above 2100-01-01
- You think 2034-03-27 is the most likely point
- You think it's 6.9X as likely as 2099-05-29
40
Here is a quick approximation of mine, I want more powerful Elicit features to make it easier to translate from sub-problem beliefs to final probability distribution. Without taking the time to write code, I had to intuit some translations. https://elicit.ought.org/builder/CeAJFku1S
*
30
My estimate is very different from what others suggest and this stems from my background and my definition of AGI. I see AGI as human-level intelligence. If we present a problem to an AGI system, we would expect that it does not make any "silly" mistakes, but that it makes reasonable responses like a competent human would do.
My background: I work in deep learning on very large language models. I worked on the parallelization of deep learning in the past. I also have in-depth knowledge of GPUs and accelerators in general. I developed the fasted algorithm for top-k sparse-sparse matrix multiplication on a GPU.
I wrote about this 5-years ago, but since then my opinion has not changed: I believe that AGI will be physically impossible with classical computers.
It is very clear that intelligence is all about compute capabilities. The intelligence of mammals is currently limited energy intake — including the intelligence of humans. I believe that the same is true for AI algorithms and these patterns seem to be very clear if you look at the trajectory of compute requirements over the past years.
The main issues are these: You cannot build structures smaller than atoms; you can only dissipate a certain amount of heat per square area; the smaller the structures are that you print with lasers, the higher the probability of artifacts; light can only go a certain distance per second; the speed of SRAM scales sub-linearly with its size. These are all hard physical boundaries that we cannot alter. Yet, all these physical boundaries will be hit within a couple of years and we will fall very, very far short of human processing capabilities and our models will not improve much further. Two orders of magnitude of additional capability are realistic, but anything beyond that is just wishful thinking.
You may say it is just a matter of scale. Our hardware will not be as fast as brains but we just build more of them. Well, the speed of light is fixed and networking scales abysmally. With that, you have a maximum cluster size that you cannot exceed without losing processing power. The thing is, even in current neural networks, doubling the number of GPUs sometimes doubles training time. We will design neural networks that scale better, such as mixtures of experts, but this will not be nearly enough (this will give us another 1-2 orders of magnitude).
We will switch to wafer-scale compute in the next years and this will yield a huge boost in performance, but even wafer-scale chips will not yield the long-term performance that we need to get anywhere near AGI.
The only real possibility that I see is quantum computing. It is currently not clear what quantum AI algorithms would look like but we seem to be able to scale quantum computers double exponentially over time aka Neven's Law. The real question is if quantum error correction also scales exponentially (the current data suggests this) or if it can scale sub-exponentially. If it scales exponentially, quantum computers will be interesting for chemistry, but they would be useless for AI. If it scales sub-exponentially we will hit quantum computers that are faster than classical computers in 2035. Due to double exponential scaling, the quantum computers in 2037 would be an unbelievable amount more powerful than all classical computers before. We might not be able to reach AGI still because we cannot feed such computer data quickly enough to keep up with its processing power, but I am sure we might be able to figure something out to feed a single powerful quantum computer. Currently, the input requirements for pretraining large deep learning models are minimal for natural language but high for images and videos. As such, we might still not have AGI with quantum computers, but we would have computers with excellent natural language processing capabilities.
If quantum computer do not work, I would predict that we never will reach AGI — hence the probability is zero after the peak in 2035-2037.
If the definition of AGI is relaxed and models are allowed to make "stupid mistakes" and the requirement is just that they on average solve problems better than humans. I would be pretty much in line with Ethan's predictions (Ethan and I chatted about this before).
Edit: A friend told me that it is better to put my probability after 2100 if I believe it is not happening after the peak 2037. Updated the graph.
Love this take. Tim, did you mean to put some probability on the >2100 bin? I think that would include the "no AGI ever" prediction, and I'm curious to know exactly how much probability you assign to that scenario.
Do you think the human brain uses quantum computing? (It's not obvious that human brain structure is any easier to replicate than quantum computing, and I haven't thought about this at all, but it seems like an existence proof of a suitable "hardware", and I'd weakly guess it doesn't use QC)
This is a thread for displaying your timeline until human-level AGI.
Every answer to this post should be a forecast. In this case, a forecast showing your AI timeline.
For example, here are Alex Irpan’s AGI timelines.
For extra credit, you can:
How to make a distribution using Elicit
How to overlay distributions on the same graph
How to add an image to your comment
If you have any bugs or technical issues, reply to Ben (here) in the comment section.
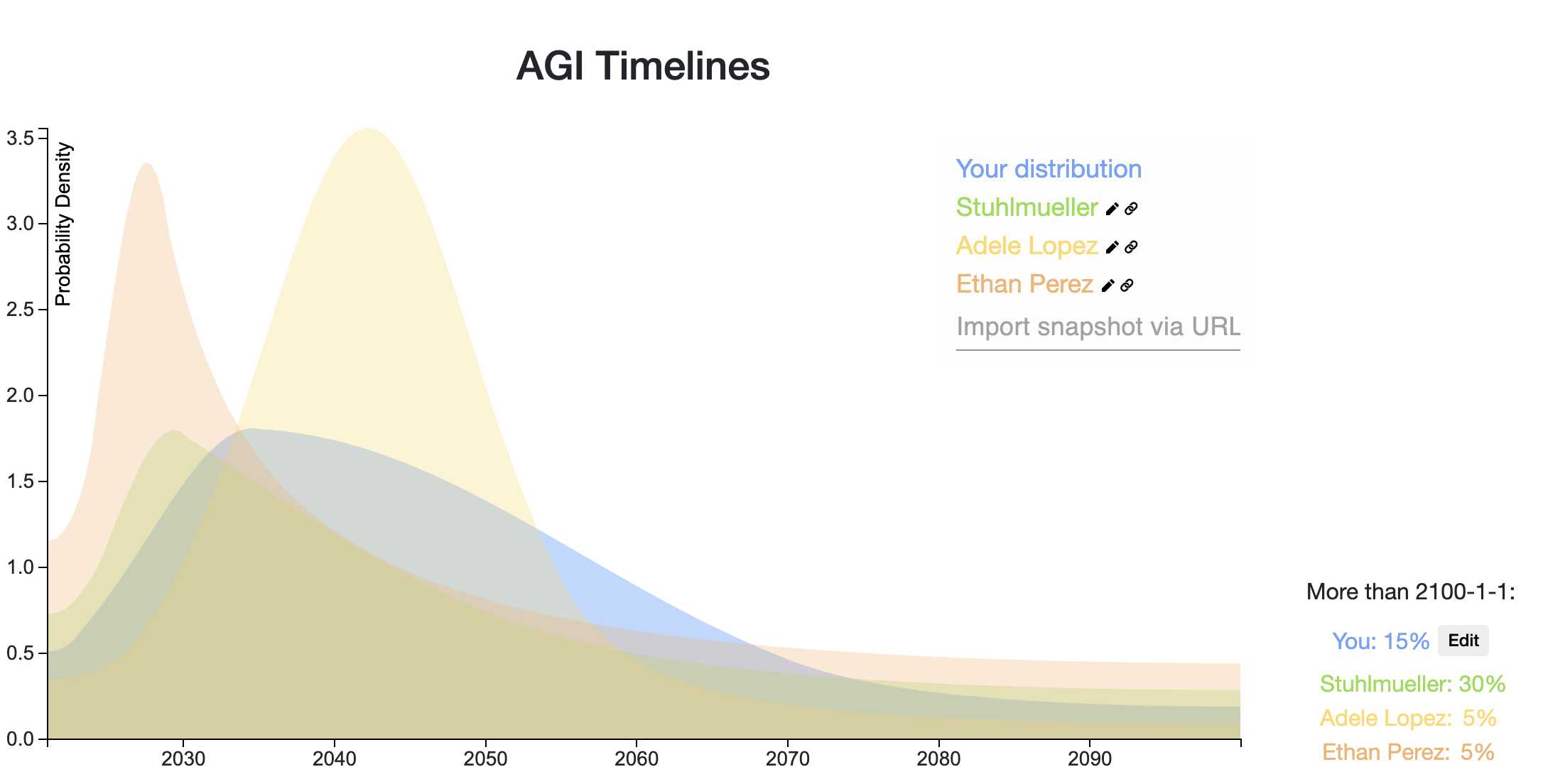
Top Forecast Comparisons
Here is a snapshot of the top voted forecasts from this thread, last updated 9/01/20. You can click the dropdown box near the bottom right of the graph to see the bins for each prediction.
Here is a comparison of the forecasts as a CDF:
Here is a mixture of the distributions on this thread, weighted by normalized votes (last updated 9/01/20). The median is June 20, 2047. You can click the Interpret tab on the snapshot to see more percentiles.