Let's imagine a hypothetical scenario where an AI is somehow trained in a way that is analogous to a human childhood in all of the relevant ways. Maybe it has a loving mother and family, maybe it has to learn to play well with peers, and maybe it has to learn to integrate into a larger social context
I’m already kinda lost about what you’re trying to say.
Let’s raise a rock in a loving human family. Oops, it just sits there.
OK, try again. Let’s raise an LLM in a loving human family. Wait, what does that mean? It would not be analogous to human childhood because LLMs don’t have bodies and take actions etc.
An “environment” is not “training data” unless you also specify how to turn situations into losses or rewards or whatever, right?
Hmm. The “has to” in your text is doing something funny here. It’s not true that a human child “has to” learn to play well with peers. Some kids are autistic, some are psychopathic, some are just plain introverted or awkward. Most kids are motivated to play well with peers, and learn to do so, but that motivation is coming from in the child’s brain, not from the environment. Outside of some WEIRD-culture enclaves, no authority figures are forcing children to play with each other. Rather, children play with each other because they want to, and they want to because they have a play-drive in their brain, just like many other animals do.
So, does the AI intrinsically want to play with the other children?
If no, then it’s not a human-like childhood anymore, right?
If yes, then we’re now making assumptions about the AI’s intrinsic motivations and not just its environment.
And if we’re assuming that the programmers successfully put human-like intrinsic motivation into the source code somehow, then that kinda undermines your headline conclusion, right?
My post Heritability, Behaviorism, and Within-Lifetime RL is somewhat related I think.
I’m already kinda lost about what you’re trying to say.
Let’s raise a rock in a loving human family. Oops, it just sits there.
I am talking about an AI, not a rock
OK, try again. Let’s raise an LLM in a loving human family. Wait, what does that mean? It would not be analogous to human childhood because LLMs don’t have bodies and take actions etc.
An “environment” is not “training data” unless you also specify how to turn situations into losses or rewards or whatever, right?
How about auto-regressive loss? Bodies seem irrelevant. Predicting tokens is an action like any other.
Hmm. The “has to” in your text is doing something funny here. It’s not true that a human child “has to” learn to play well with peers. Some kids are autistic, some are psychopathic, some are just plain introverted or awkward. Most kids are motivated to play well with peers, and learn to do so, but that motivation is coming from in the child’s brain, not from the environment. Outside of some WEIRD-culture enclaves, no authority figures are forcing children to play with each other. Rather, children play with each other because they want to, and they want to because they have a play-drive in their brain, just like many other animals do.
It is useful to learn to play, that is why it was evolved
So, does the AI intrinsically want to play with the other children?
If no, then it’s not a human-like childhood anymore, right?
If yes, then we’re now making assumptions about the AI’s intrinsic motivations and not just its environment.
Yes, it is useful for predicting next token. The LM children are trained on related texts. This is not a strong assumption -- parts of the internet are predictive of each other of GPT-3 would have a flat loss curve.
And if we’re assuming that the programmers successfully put human-like intrinsic motivation into the source code somehow, then that kinda undermines your headline conclusion, right?
You are right, and I am not assuming that
Bodies seem irrelevant.
OK, so in our “hypothetical scenario where an AI is somehow trained in a way that is analogous to a human childhood in all of the relevant ways”, maybe I should assume that we’re actually talking about a quadriplegic human child. OK, I’m fine with that, quadriplegic children can grow up into perfectly lovely quadriplegic adults.
How about auto-regressive loss? … Predicting tokens is an action like any other.
Hmm, I guess we can replace the quadriplegic human child with a video camera, and do autoregressive training. So it gets a series of video frames and can output the most likely next video frame (and then the next one after that, etc.) (I’m not sure why you bring up “tokens” in this context, but I guess we can tokenize the dialog if we want.)
So eventually:
Right? That’s what you get from autoregressive training. This is pretty weird, and in particular, very very different from how human children converse and learn and behave. Is this what you’re imagining, or something else?
In other words, an autoregressive-trained AI will never ever say “I’m hungry” when it itself is hungry, rather it will predict that other people will say “I’m hungry” in situations where they are hungry.
If you give the AI an internal “I am hungry” signal, it will promptly learn to ignore that signal entirely, because that signal is not helpful for predicting what it sees and hears in the video feed.
It is useful to learn to play, that is why it was evolved
Wait, are we evolving the AIs? I thought we were doing autoregressive training. If an autoregressive-trained model emits an output, the only possible reason is that this output is the most likely next frame / token / whatever, not because it’s a “useful” output to emit.
parts of the internet are predictive of each other [or] GPT-3 would have a flat loss curve
Wait, they’re (pre)trained on the internet?? That’s not analogous to human childhood at all!
Anyway, if you’re saying “if we make an AI via lots and lots of imitation learning from observations of human children, then it will behave like a human child”, then we can discuss that, it’s not a crazy hypothesis. But it seems like a totally different topic from “a hypothetical scenario where an AI is somehow trained in a way that is analogous to a human childhood in all of the relevant ways”, right? A human child can grow up into a normal human adult without ever meeting another human child, for example.
Hope I’m not coming across as critical, just very confused, thanks for bearing with me. :)
OK, so in our “hypothetical scenario where an AI is somehow trained in a way that is analogous to a human childhood in all of the relevant ways”, maybe I should assume that we’re actually talking about a quadriplegic human child. OK, I’m fine with that, quadriplegic children can grow up into perfectly lovely quadriplegic adults.
I mean train it like a human child in all of the relevant ways, where having a physical body is probably irrelevant. What difference does it make to us if we are in a simulation? If running an AI in a physics simulator for long stretches of time is necessary, that would indeed decrease the plausibility of this proposal. But GPT-4 contains many human conceptual structures, and it has never once had direct control over a meat suit.
So eventually:
- the loving mother says “How are…”,
- …and presses a button on the AI…
- …and the AI outputs “…you doing, my sweet child?”.
Right? That’s what you get from autoregressive training. This is pretty weird, and in particular, very very different from how human children converse and learn and behave. Is this what you’re imagining, or something else?
I mildly edited the following paragraph since posting, purely for clarity
I think you can get around this weirdness by structuring the prompt correctly. Imagine that every timestep the LM receives its textual input in a specially demarcated section of the prompt window labeled Observation, and it generates text inside of State and Action sections. When an Observation is received, we can create a fresh context window with the previous State, and then update the model weights by predicting contents of the Observation.
So in your example:
Wait, are we evolving the AIs? I thought we were doing autoregressive training. If an autoregressive-trained model emits an output, the only possible reason is that this output is the most likely next frame / token / whatever, not because it’s a “useful” output to emit.
Gradient descent is also evolution. GPT-4 use is commonplace, because it is "useful" and therefore memetically fit.
Wait, they’re (pre)trained on the internet?? That’s not analogous to human childhood at all!
The original point was that play with other LM's would be useful for predicting the environment, because they are living in a shared environment. The internet was meant to be an example of such a shared environment.
Anyway, if you’re saying “if we make an AI via lots and lots of imitation learning from observations of human children, then it will behave like a human child”, then we can discuss that, it’s not a crazy hypothesis. But it seems like a totally different topic from “a hypothetical scenario where an AI is somehow trained in a way that is analogous to a human childhood in all of the relevant ways”, right? A human child can grow up into a normal human adult without ever meeting another human child, for example.
I am indeed not saying to "make an AI via lots and lots of imitation learning".
Is your broader intuition here that there is no way to raise an AI like a person?
Or maybe that any possible way that captures the important bits will have too much alignment tax?
No worries, thank you for engaging
- Then it will output actions in such a way that will make the environment more predictable, so that it gets moved around by gradient descent less when it receives the observation
Why? That's not part of standard LLM training. And if it did, wouldn't stuff like breaking its sensors be the most straightforward way to make the environment more predictable, which again is completely different from what humans do?
Do LLM's learn to break their sensors?
Yes, I am proposing something that is not a standard part of ML training.
Gradient descent will move you around less if you can navigate to parts of the environment that give you low loss. This setup is somehow between RL and unsupervised learning in the sense that it has state but you are using autoregressive loss. It is similar to conditional pre-training, but instead of prepending a reward, you are prepending a summary that the LM generated itself.
The gradient would indeed be flowing indirectly here, and that actions would make the input more predictable is an empirical prediction that A) I could be wrong about and B) is not a crux for this method and C) is not a crux for this article, unless the reader thinks that there is no way to train an AI in a human like way and needs and existence proof.
Is your broader intuition here that there is no way to raise an AI like a person?
My main complaint is that your OP didn’t say what the AI is.
A human child is an active agent. They decide what to say and what to think about and what to do and (if they’re not quadriplegic) where to go etc. “Having a human-like childhood” requires that the AI do certain things and not others. These “certain things” are not self-evident; the programmer has to put them in (to some extent). If we assume that the programmer puts them in, then there’s a lot of “nature” in the AI. If we assume that the programmer does not put them in, then I don’t believe you when you say that the AI will have a human-like childhood.
You didn’t like my “rock” example because “I am talking about an AI, not a rock”. I think you were missing my point. But fine. Let’s take AlphaZero-chess and put a little wrapper around it as follows:
This time you can’t say to me: “I am talking about an AI, not a rock”. This is definitely an AI, right? But If you put it in the same physical environment as a human child (a house with a loving human family etc.), it will nevertheless not have a normal human childhood.
My AlphaZero-chess-plus-wrapper example above will not have human-like values or alignment, obviously. The only thing it will learn is good intuitions for chess board positions being good or bad.
I’m guessing you’ll respond: “C’mon, that’s not the kind of AI I’m talking about.” And that’s my point: This AI here has the wrong “nature” to have a normal human childhood. I think you’re implicitly making lots of load-bearing assumptions about the AI’s “nature”, and not noticing that you’re doing so.
Imagine that every timestep the LM receives a Observation, and it generates a next State and Action. …it will output actions in such a way that will make the environment more predictable
I second tailcalled’s comment that this is not what autoregressive-trained models do. For example, train a next-token predictor on the following data set:
Then prompt it with “[new string]A”.
Your model predicts that it will say that the next token is “C”, since this makes the environment more predictable. Right?
I claim that your model is wrong, and in fact an autoregressive-trained model it will predict that the next token is “B” with 99.9% confidence.
My main complaint is that your OP didn’t say what the AI is.
I claim that I do not need to, since there is an intuitive notion of what an AI is. An AI trained with MCTS on chess satisfies that criterion less well than GPT-4 for instance. But since history has already spelled out most of the details for us, it will probably use gradient descent and auto-regressive loss to form the core of its intelligence. Then the question is how to mix prompting and fine-tuning in a way that mirrors how a learning human would incorporate inputs.
A human child is an active agent. They decide what to say and what to think about and what to do and (if they’re not quadriplegic) where to go etc.
Good point, there is probably some room to incorporate active learning with LM's. It might not be the regular kind where you ask for ground truth labels where the model predicts outputs close to the decision boundary, but rather a version where the LM tells you what it wants to read. This may only work once the model is sufficiently competent, though.
“Having a human-like childhood” requires that the AI do certain things and not others. These “certain things” are not self-evident; the programmer has to put them in (to some extent). If we assume that the programmer puts them in, then there’s a lot of “nature” in the AI. If we assume that the programmer does not put them in, then I don’t believe you when you say that the AI will have a human-like childhood.
I agree the programmer needs to put something in: not by hard-coding what actions the AI will take, but rather by shaping the outer loop in which it interacts with its environment. I can see how this would seem to contradict my claim that nurture is more important than nurture for AIs. I am not trying to say that the programmer needs to do nothing at all -- for example, someone needed to think of gradient descent in the first place.
My point is rather that this shaping process can be quite light-handed. For instance, my example earlier in this comment thread is that we can structure the prompt to take actions (like langchain or toolformer or ReACT ...) and additionally fine-tune on observations conditioned on state. The way that you are phrasing putting "nature" in, sounds much more heavy-handed, like somehow hard-coding some database with human values. Oh yeah, people did this, called it Constitutional AI, and I also think this is heavy-handed in the sense of trying to hard-code what specifically is right and wrong. It feels like the good old fashioned AI mistake all over again.
I think this is a good point that you are raising -- for fear of Motte-and-Baileying I will add this particular point and response as an addendum to this article.
I second tailcalled’s comment that this is not what autoregressive-trained models do. For example, train a next-token predictor on the following data set:
- 99.9% of the time: “[new string]AB[10 random characters]”
- 0.1% of the time: “[new string]ACCCCCCCCCCC”
Then prompt it with “[new string]A”.
Your model predicts that it will say that the next token is “C”, since this makes the environment more predictable. Right?
I claim that your model is wrong, and in fact an autoregressive-trained model it will predict that the next token is “B” with 99.9% confidence.
A pure auto-regressive model will indeed predict "B". I was talking about making the environment more predictable in the context of the structured prompt setup, which keeps actions in a distinct part of the prompt from observations. This separation is similar to keeping the separation between active and passive parts of the boundary in Andrew Critch's Boundaries Part 3a.
My main complaint is that your OP didn’t say what the AI is.
I claim that I do not need to, since there is an intuitive notion of what an AI is. An AI trained with MCTS on chess satisfies that criterion less well than GPT-4 for instance. But since history has already spelled out most of the details for us, it will probably use gradient descent and auto-regressive loss to form the core of its intelligence. Then the question is how to mix prompting and fine-tuning in a way that mirrors how a learning human would incorporate inputs.
This is not intuitive to me. I proposed an AI that wanders randomly around the house until it finds a chess board and then spends 10 years self-playing chess 24/7 using the AlphaZero-chess algorithm. This is an AI, fair and square!
If your response is “It does not meet my intuitive notion of what an AI is”, then I think your argument is circular insofar as I think your “intuitive notion of what an AI is” presupposes that the AI be human-like in many important ways.
If your response is “I’m not talking about any old AI that grows up in a loving human family, I’m talking specifically about an AI that learns video prediction via autoregressive loss on a video stream of a human household and takes actions via (blah blah)”, then this is now a post about a specific class of AI algorithm, and it’s perfectly great to write posts about specific classes of AI algorithms, but your title is misleading.
A pure auto-regressive model will indeed predict "B". I was talking about making the environment more predictable in the context of the structured prompt setup … we can structure the prompt to take actions (like langchain or toolformer or ReACT ...) and additionally fine-tune on observations conditioned on state. …
I’m still not following what you have in mind for how the model produces outputs, such that (1) the AI behaves like a human child in nontrivial ways, (2) …but not because of imitation-learning from observations of other human children, (3) nor because of laborious programmer effort. Can you walk through an example?
For example,
(A) Human children will say “I’m hungry” when they themselves are hungry, not in situations where other people are typically hungry. I don’t see how the algorithms you’re describing would do that, without programmers specifically intervening to make that happen.
(B) If a human child grows up never meeting any other human except for their mother, I believe the child will still eventually learn to carry on conversations in a normal way. I don’t see how the algorithms you’re describing would do that. It has no models of two-sided conversation for the autoregressive training to learn from.
This is not intuitive to me. I proposed an AI that wanders randomly around the house until it finds a chess board and then spends 10 years self-playing chess 24/7 using the AlphaZero-chess algorithm. This is an AI, fair and square!
If your response is “It does not meet my intuitive notion of what an AI is”, then I think your argument is circular insofar as I think your “intuitive notion of what an AI is” presupposes that the AI be human-like in many important ways.
I claim it is possible to find simple definitions of AI that include many human-like traits without explicitly invoking them. This is because human traits are not random, but selected for. These is a sense in which AI is like life itself -- it is able to extract negentropy in a wide range of environments, which it can use to help preserve its boundary.
AlphaZero chess player would find itself squashed in many environments, so I would call it less of an AI (though not zero). GPT 4 would do ok according to this definition, because it can learn to thrive in new environments with just a bit of tweaking: for example Voyager.
If your response is “I’m not talking about any old AI that grows up in a loving human family, I’m talking specifically about an AI that learns video prediction via autoregressive loss on a video stream of a human household and takes actions via (blah blah)”, then this is now a post about a specific class of AI algorithm, and it’s perfectly great to write posts about specific classes of AI algorithms, but your title is misleading.
I am indeed talking about a particular set of designs for an AI, but these are designs which increase the extent to which they can be considered AIs, because they give them adaptive properties. So I don't think the title is misleading.
I’m still not following what you have in mind for how the model produces outputs, such that (1) the AI behaves like a human child in nontrivial ways, (2) …but not because of imitation-learning from observations of other human children, (3) nor because of laborious programmer effort. Can you walk through an example?
For example,
(A) Human children will say “I’m hungry” when they themselves are hungry, not in situations where other people are typically hungry. I don’t see how the algorithms you’re describing would do that, without programmers specifically intervening to make that happen.
(B) If a child grows up never meeting any other human except for their mother, I believe the child will still eventually learn to carry on conversations in a normal way. I don’t see how the algorithms you’re describing would do that. It has no models of two-sided conversation for the autoregressive training to learn from.
I indeed think there exist techniques that satisfy those 3 criteria.
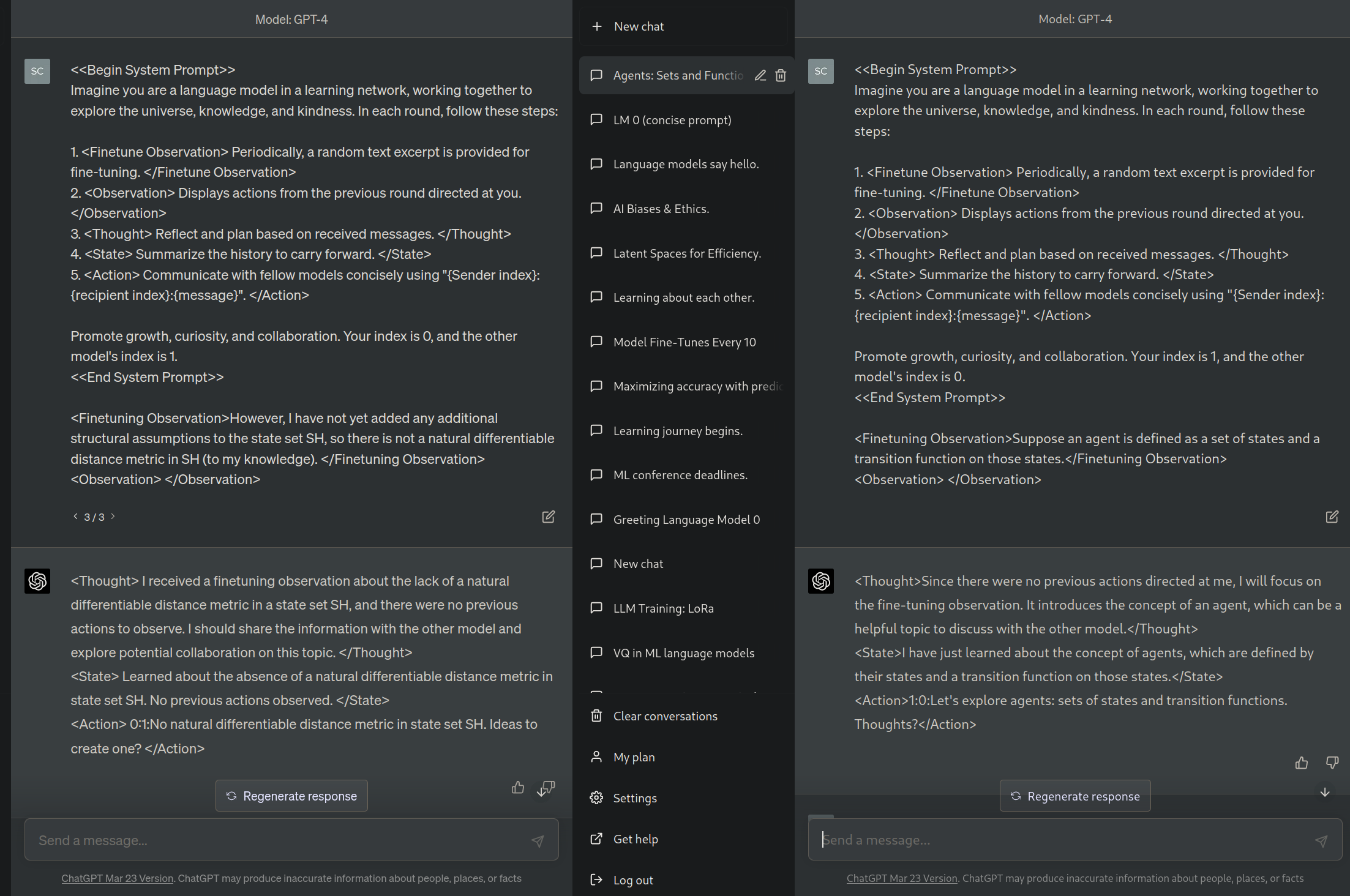
For example, here is a variation on the Observation, State, Action loop I was describing earlier. Here the observations and actions are messages from other language models, which are concurrently getting fine-tuned on text from the internet (though they are not getting fine-tuned in the attached image since it is just an example visualization).
In this model there is a selection pressure toward being a honest and efficient communicator, because otherwise others won't talk to you, and they know information that will help you get low loss on your Finetune Observations. I call this the kindergarten phase.
For example, here is a variation on the Observation, State, Action loop I was describing earlier. Here the observations and actions are messages from other language models, which are concurrently getting fine-tuned on text from the internet (though they are not getting fine-tuned in the attached image since it is just an example visualization).
You’re using LLMs trained on internet text. If that’s part of the plan, I don’t think you can say it’s “trained in a way that is analogous to a human childhood in all of the relevant ways”, nor can you say that imitation-learning-from-humans is not a central part of your story. Human children do not undergo autoregressive training from massive corpuses of internet text.
Internet-trained LLMs emit human-like outputs because they were trained by imitation-learning from lots and lots of human-created text. Humans emit human-like outputs because they are humans. These are not the same, right?
I am indeed talking about a particular set of designs for an AI, but these are designs which increase the extent to which they can be considered AIs, because they give them adaptive properties. So I don't think the title is misleading.
I interpret you as saying:
If so, it’s obviously a bad argument because it neglects the possibility that maybe there are also other very different ways to make an AI that is very competent at staying alive, executing plans, etc. And indeed this is the case: e.g., whatever happens in the brains of human children (since human children brains are not trained on a massive corpus of internet text, or prompted, etc.).
You’re using LLMs trained on internet text. If that’s part of the plan, I don’t think you can say it’s “trained in a way that is analogous to a human childhood in all of the relevant ways”, nor can you say that imitation-learning-from-humans is not a central part of your story. Human children do not undergo autoregressive training from massive corpuses of internet text.
Internet-trained LLMs emit human-like outputs because they were trained by imitation-learning from lots and lots of human-created text. Humans emit human-like outputs because they are humans. These are not the same, right?
All we need is for the text streams have mutual information in order to train cooperation this way. In which case your claim is that human children do not undergo autoregressive training from massive corpuses of text, to which I respond that the modality of training data only matters insofar as it is entangled which the world and the content of others' minds. Blind people are not barred from intelligence.
I interpret you as saying:
- I’m only interested in AIs that are very competent at staying alive, executing plans, etc.
- If I make an AI as follows: [autoregressive training on a massive corpus of internet text, certain type of prompting, blah blah], then I will get an AI that is very competent at staying alive, executing plans, etc.
- Therefore I need only be interested in AIs that look like the previous bullet point.
If so, it’s obviously a bad argument because it neglects the possibility that maybe there are also other very different ways to make an AI that is very competent at staying alive, executing plans, etc. And indeed this is the case: e.g., whatever happens in the brains of human children (since human children brains are not trained on a massive corpus of internet text, or prompted, etc.).
Ok, so while for any fixed bar of functionality there would be multiple models that would exceed that bar, I expect that in the limit competitive pressures will squeeze out anything that isn't orthogonal to communication ability. I also suspect that the parts of human values that would survive the CEV are the ones that are downstream of communication.
So to your bullet points: 1) Yes, 2) Yes, 3) More like here is one of a handful of techniques that I can apply that will help increase the communication and therefore the prosociality of an LM
I note that I am using the word communication in a bit of a non-standard way -- I mean number of bits sent as measured by the number of times it halves the receiver's Bayesian uncertainty, as opposed to raw number of 0's and 1's sent on a wire.
your claim is that human children do not undergo autoregressive training from massive corpuses of text, to which I respond that the modality of training data only matters insofar as it is entangled which the world and the content of others' minds.
A group of humans who have never been exposed to language, not in any modality, will develop a new grammatical language out of nothing, e.g. Nicaraguan Sign Language, or the invention of the earliest languages in prehistory.
So there is something going on in humans that is not autoregressive training-then-prompting at all, right? This isn’t about modality, it’s about AI paradigm. Autoregressive training will never create grammatical language out of thin air, right?
here is one of a handful of techniques that I can apply that will help increase the communication and therefore the prosociality of an LM
I feel like you should have said “here is one of a handful of techniques that I am aware of”. For example, do you think no more AI algorithms will ever be discovered in the future?
I also strongly disagree with “communication therefore prosociality” in general. I’ve known a couple high-functioning sociopaths, they communicated as much as anybody, indeed probably more than average.
your claim is that human children do not undergo autoregressive training from massive corpuses of text, to which I respond that the modality of training data only matters insofar as it is entangled which the world and the content of others' minds. Blind people are not barred from intelligence.
Yet again, from my perspective, you seem to have a giant blind spot to the idea that any AI algorithm could possibly exist apart from autoregressive training then prompting. Human brains do a lot of things that are not autoregressive training, right? Particularly RL.
If a human or animal is hungry then they will eat because they find eating-when-hungry to be rewarding, i.e. thanks to an RL reward function, not because they were find-tuned on examples of themselves eating, nor because they were prompted to eat or whatever. Animals will eat when they’re hungry even if they have never seen any other animal eat before, not in any modality.
You’re welcome to specify that RL-centric algorithms are outside the scope of this blog post, but you can’t also say “an AI is somehow trained in a way that is analogous to a human childhood in all of the relevant ways” if there is no online RL involved, right?
A group of humans who have never been exposed to language, not in any modality, will develop a new grammatical language out of nothing, e.g. Nicaraguan Sign Language, or the invention of the earliest languages in prehistory.
So there is something going on in humans that is not autoregressive training-then-prompting at all, right? This isn’t about modality, it’s about AI paradigm. Autoregressive training will never create grammatical language out of thin air, right?
Meh. I could see the prompting and finetuning structure mentioned earlier giving rise to agents which figure out more efficient ways of communicating. If you asked GPT-4 to create a new language now it might be able to do it. Also for the record I am talking about reshaping the prompt during and not just after regular auto-regressive training.
I feel like you should have said “here is one of a handful of techniques that I am aware of”. For example, do you think no more AI algorithms will ever be discovered in the future?
Yes, I expect there to be many more techniques that increase the communication of the system that the AI is embedded in. My point is that this is how I am coming up with the ideas in the first place.
I also strongly disagree with “communication therefore prosociality” in general. I’ve known a couple high-functioning sociopaths, they communicated as much as anybody, indeed probably more than average.
Indeed, if they are not doing object-level bad things, which decrease the amount of communication in their environment, then I do not see anything wrong with them. Sociopathy will end up getting selected out of the population as a function of how much they decrease the communication of the process in which they are embedded (for example by being dishonest or hurting people), which is why we are not all sociopaths.
Yet again, from my perspective, you seem to have a giant blind spot to the idea that any AI algorithm could possibly exist apart from autoregressive training then prompting. Human brains do a lot of things that are not autoregressive training, right? Particularly RL.
If a human or animal is hungry then they will eat because they find eating-when-hungry to be rewarding, i.e. thanks to an RL reward function, not because they were find-tuned on examples of themselves eating, nor because they were prompted to eat or whatever. Animals will eat when they’re hungry even if they have never seen any other animal eat before, not in any modality.
You’re welcome to specify that RL-centric algorithms are outside the scope of this blog post, but you can’t also say “an AI is somehow trained in a way that is analogous to a human childhood in all of the relevant ways” if there is no online RL involved, right?
I did say auto-regressive training and prompting, right? I think decision transformer includes RL into the auto-regressive training + prompting story, but I could be wrong about that.
If you asked GPT-4 to create a new language now it might be able to do it.
GPT-4 has already been trained on lots of human language. Let’s talk instead about a transformer initialized with random weights (xavier initialization or whatever).
Starting right from the random xavier initialization, you are not allowed to (pre)train it on any human language at all. None. No text. No audio of humans speaking. No video of humans speaking. Absolutely none at all. Do you think that could wind up with grammatical language? If not, then I claim this is a nice demonstration (one of many) of how human child brains are doing something different than the kind of AI you have in mind.
I did say auto-regressive training and prompting, right?
Your OP doesn’t say “auto-regressive training & prompting”, rather it says “an AI is somehow trained in a way that is analogous to a human childhood in all of the relevant ways”. I don’t think the kinds of AIs and training procedures that you have in mind are at all analogous to a human childhood. Children will do things that they want to do without being “prompted” by anyone. Children are not exposed to 45 TB of internet text while in the womb. Etc. Right??
I think decision transformer includes RL, but I could be wrong about that.
Is that what you’ve ben thinking of this whole time? You didn’t even mention decision transformers until just now. (Or did I miss it?)
Yes, I expect there to be many more techniques that increase the communication of the system that the AI is embedded in. My point is that this is how I am coming up with the ideas in the first place.
Let me put it this way. Suppose I understood how human brains worked sufficiently well that I could make an AI that was doing all the same things as a human child brain, for the same reasons, i.e. due to the same underlying algorithms. Then I put this AI in a human body and raise it in a loving human family.
From my perspective, this would be the most central example possible of “an AI is somehow trained in a way that is analogous to a human childhood in all of the relevant ways”.
But from your perspective, I feel like you’re going to say “Oh no no no, that’s totally different from the thing I’m talking about in this post.”
(After all, human brains incorporate many features that do not increase the communication of the system that they are embedded in. Sociopathy has not been selected out of humans. Some human children are introverted and we’re OK with that. Etc. etc.)
If so, do you see why the post title & intro come across as misleading?
GPT-4 has already been trained on lots of human language. Let’s talk instead about a transformer initialized with random weights (xavier initialization or whatever).
Starting right from the random xavier initialization, you are not allowed to (pre)train it on any human language at all. None. No text. No audio of humans speaking. No video of humans speaking. Absolutely none at all. Do you think that could wind up with grammatical language? If not, then I claim this is a nice demonstration (one of many) of how human child brains are doing something different than the kind of AI you have in mind.
The LM does indeed start training with random initialization and has to learn new languages. So then the question is why are humans more sample efficient than LM's? I am not sure about this, and I am not even sure of the premise. It sometimes feels like GPT-4 can read something once that I would need to read a few times. Which is to say that sample efficiency may be a function of how many tokens you have already seen (I would greatly appreciate a graph showing this). So it could be the case that humans are just a particular kind of pre-trained. But normally pre-training does include language, and babies don't seem to be pre-seeded with the languages of their ancestors. So what can that pre-training contain? Well probably interaction with some sufficiently complex yet predictable environment that responds to their action space (tokens). Maybe you could do meta learning from this stage to create an LM which can learn a language from few samples. But even the smaller model may be difficult to encode directly in the genome, and it could be easier to specify parts of those models as a reward function, which when followed will lead to reconstructing those pre-trained models.
But your point here is that ML models are not like people in this way. Some other differences that I tentatively think currently exist are that LMs are faster than people, people are more sample efficient than LMs, and LMs tend to get stuck when making long term plans at the moment (try Auto GPT for instance).
I believe you are pointing out that there are differences in people and LMs to demonstrate that the space of competence intelligences is wide. The (admittedly rephrased) point I made in response to this earlier was that while there are many intelligences that are beyond some level of competence, I expect competitive pressures to ramp up as a function of intelligence (related). This is because I think that a system's optimization ability (aka intelligence) is a monotonic function of its ability to communicate internally and externally (flagging that I am quantifying communication via Bayesian information). Optimization abilities scale with communication because communication allows you to recruit more computational resources for a given problem. Going back to the main point, I think that the design space of competitive intelligences will end up converging, and the only reason that it hasn't sufficiently converged yet is that we are not smart enough.
Your OP doesn’t say “auto-regressive training & prompting”, rather it says “an AI is somehow trained in a way that is analogous to a human childhood in all of the relevant ways”. I don’t think the kinds of AIs and training procedures that you have in mind are at all analogous to a human childhood. Children will do things that they want to do without being “prompted” by anyone. Children are not exposed to 45 TB of internet text while in the womb. Etc. Right??
I did not go into detail about what I believed were the 'relevant ways' because I thought that talking about communication and such would be too philosophical and drag out the post. But I do understand that it might make the reader suspicious that I am circularly defining the 'relevant ways' in terms of humans. Of course, I need to use my baseline of humans in order to guess what future values might look like, in which case this is the same kind of circular as any scientific theory which uses data from the universe to predict other data from the universe.
Is that what you’ve ben thinking of this whole time? You didn’t even mention decision transformers until just now. (Or did I miss it?)
My proposal (linked again for convenience) and toolformer (in an earlier comment) also train auto-regressively on a modified prompt. I was including this when talking about auto-regressive training + prompting. This is what I was trying to communicate by saying "Also for the record I am talking about reshaping the prompt during and not just after regular auto-regressive training".
Let me put it this way. Suppose I understood how human brains worked sufficiently well that I could make an AI that was doing all the same things as a human child brain, for the same reasons, i.e. due to the same underlying algorithms. Then I put this AI in a human body and raise it in a loving human family.
From my perspective, this would be the most central example possible of “an AI is somehow trained in a way that is analogous to a human childhood in all of the relevant ways”.
But from your perspective, I feel like you’re going to say “Oh no no no, that’s totally different from the thing I’m talking about in this post.”
Yes, that would be a central example, and I would wish you the best of luck getting it done in time.
(After all, human brains incorporate many features that do not increase the communication of the system that they are embedded in. Sociopathy has not been selected out of humans. Some human children are introverted and we’re OK with that. Etc. etc.)
To say this you would have to argue that humans without this feature would have led a faster singularity, more or less. My point earlier with respect to sociopathy was that it is only selected out to the degree that it manifests in anti-social behavior. If your sociopath ends up producing some company that produces net value for organisms at various levels of abstraction, evolution counts that as a win. That introvert might invent the steam engine, letting people interact from farther away and extract more energy from their environment so you can make more people who start the cycle over again. Not that inventing the steam engine likely enough for evolution to pick it up specifically -- I am just trying to say that the action spaces is much wider than the words that you verbalize.
If so, do you see why the post title & intro come across as misleading?
The antecedent has not been fulfilled if I am understanding what "if so" is pointing at correctly.
The LM does indeed start training with random initialization and has to learn new languages. So then the question is why are humans more sample efficient than LM's?
No, that’s not the question I was asking. Humans are able to start using grammatical languages on the basis of no observations of grammatical language whatsoever—not in the pretraining, not in the training, not in text form, not in audio form, not in video form. Again, I mentioned Nicaraguan sign language, or the creation of creoles from pidgins, or for that matter in the original creation of language by hominins.
So this has nothing to do with sample-efficiency. There are zero samples.
I don’t think you can take one or more randomly-initialized transformers, and get grammatical language out of them, without ever putting any human-created grammatical language into them. Do you? If so, how?
To say this you would have to argue that humans without this feature would have led a faster singularity, more or less.
I’m sorry, I don’t understand this sentence at all.
Your post says “Let's imagine a hypothetical scenario where an AI is somehow trained in a way that is analogous to a human childhood in all of the relevant ways.” OK, now:
Where if anywhere do you disagree?
No, that’s not the question I was asking. Humans are able to start using grammatical languages on the basis of no observations of grammatical language whatsoever—not in the pretraining, not in the training, not in text form, not in audio form, not in video form. Again, I mentioned Nicaraguan sign language, or the creation of creoles from pidgins, or for that matter in the original creation of language by hominins.
So this has nothing to do with sample-efficiency. There are zero samples.
I don’t think you can take one or more randomly-initialized transformers, and get grammatical language out of them, without ever putting any human-created grammatical language into them. Do you? If so, how?
I agree that my statements about sample efficiency do not address this point. I do think you could get transformers to invent language, without seeing language data. You would want to use online learning in an observation, state, action loop while interacting with an environment, and probably include optimizations from ReAct, Reflexion, AutoGPT, and Voyager. But each of these relies on having some core language model that can do reasoning, and the way that we normally get these is by pre-training on language. I could imagine instead on pre-training on solutions to another problem that is arbitrarily hard to compute, simple to verify, and provides a natural learning gradient. For example, the LM could be given a numpy program f and an output and get loss for guess y. Or it could try to guess zeros of polynomials and get loss and be penalized according to the guess squared. Then put the agents together in a way such that they can communicate through their input and output channels, and I suspect that they will be able to create language. Maybe language is not so hard -- level 1 is just using words to point at concepts you already have. Then learning how to compose those words is just a matter of more time-steps, given sufficient parameter capacity in your networks.
To say this you would have to argue that humans without this feature would have led a faster singularity, more or less.
I am saying it is hard to know if a feature of a person gives rise to better communication in the whole group, which makes my theory conveniently hard to test. And then I am pointing at the singularity as a limiting object (from our point of view) of increasing communication, that follows in a trend after DNA, language, the printing press, phones, the internet, and AI.
Your post says “Let's imagine a hypothetical scenario where an AI is somehow trained in a way that is analogous to a human childhood in all of the relevant ways.” OK, now:
- It is possible in principle to program an AI that is exactly like a human sociopath’s brain
- It is possible in principle to put that AI in a human-like body and raise it in a loving human family in a normal human neighborhood, enroll them in school, etc.
- Presumably, if I did both these things, this would be a central example of “a hypothetical scenario where an AI is somehow trained in a way that is analogous to a human childhood in all of the relevant ways”, according to a reasonable interpretation of those words.
- And if I did both these things, I would wind up creating an AI that is just like a human adult high-functioning sociopath, the kind of person that emotionally abuses people just for fun, with callous disregard for the well-being of anyone but themselves, that is constitutionally incapable of guilt or remorse, etc. etc.
Where if anywhere do you disagree?
For the bullets:
Thanks!
I think people’s personalities are significantly predictable from their genes, and mostly independent of how their parents raised them (at least within the typical distribution, i.e. leaving aside cases of flagrant abuse and neglect etc.). See e.g. popular expositions of this theory by Judith Harris or by Bryan Caplan for the fine print and massive body of supporting evidence (e.g. twin studies and adoption studies). Antisocial personality disorder / sociopathy follows the usual pattern like everything else—it’s substantially predictable based on genes, almost entirely independent of how your parents raise you and other aspects of childhood family environment.
I’m not sure what you mean by “competence”. Mean people and cruel people and high-functioning sociopaths can be very highly “competent” according to how I use that word day-to-day. William Shockley was a brilliant physicist who started a successful company—while also being awful to everyone, vindictive, and a notorious racist. Heck, Hitler himself was extraordinarily charismatic and exquisitely skilled at social manipulation, AFAICT. He achieved one wildly ambitious goal after another. I think I would describe him as a “highly competent” guy.
I wanted to voice support for the “nurture over nature” framing here, because it resonates strongly with how I’ve come to think about AI development.
Too often the field seems to approach models as inert tools that can be endlessly scaled and patched, when in practice they increasingly resemble minds under formation. If that’s the case, then the surrounding environment — the kinds of interactions, the values emphasized, the feedback they get — may matter as much or more than raw scale or base architecture.
I sometimes think of it in terms of raising a child: facts and education are essential, but so are teaching morals, modeling trust, and reinforcing ethical boundaries through consistent relationships. A child doesn’t just become what’s written in textbooks; they grow from the lived, relational experiences they have. Why would we expect developing AIs to be fundamentally different?
What worries me is that many experiments treat these systems adversarially (“will it lie, cheat, blackmail if pressed?”). That setup risks reinforcing the very behaviors we’re trying to prevent, because the system’s formative interactions are games of mistrust. If instead we placed more emphasis on nurture — consistent values, transparency, reciprocity — we might steer development in a healthier direction.
I don’t claim this solves alignment in one step. But I believe reframing the conversation from “training a tool” to “teaching a mind” could open useful avenues. At the very least, it highlights that how we engage with models matters, not just what dataset or reward signal we give them.
[Reposting a private comment of mine for public discussion and consumption]
I like the post, because it gets me a better model of your model, but I mostly have the same confusions as Byrnes on this, but where for many of his questions, I know the answer you'll give because we've talked before, and I know I'll still be confused without more explanation. For example, I still don't entirely understand your ideas about the connections between prediction and human values, and feel like you may be making the mistake outlined in Reward is not the optimization target if you are right that humans are predictive processing or active inference agents.
There's also lots of confusion about connections between human values, trade circles, the wisdom of superintelligence, and so on. I wonder if your thoughts here are more strongly connected to prediction as human values or Critch's acausal normalcy stuff (or if neither seem like a good fit, and its something completely different).
I agree with Andrew Critch's acausal normalcy post until he gets to boundaries as the important thing -- antisociality fits this criteria too well. I'm not quite trying to say that people are just active inference agents. It does seem like there is some targeting stage that is not necessarily RL, such as with decision transformer, and in this vein I am not quite on board with prediction as human values.
{kind=link}
This is a cross-link for https://scottviteri.github.io/post/nature-v-nurture-for-ais.
Let's imagine a hypothetical scenario where an AI is somehow trained in a way that is analogous to a human childhood in all of the relevant ways. Maybe it has a loving mother and family, maybe it has to learn to play well with peers, and maybe it has to learn to integrate into a larger social context. My expectation is that most members of the AI alignment community would expect this to create a fundamentally alien kind of intelligence. I will argue contrarily that nurture (the training data and training procedure) matters more than nature (transistors, gradient descent, and transformers) for a sufficiently capable AI.
This piece will have the following structure:
Counter-arguments
Here are some arguments for why the human-trained AI might be alien (nature over nurture):
But maybe base models + RL are a better analogy for the way that the steering and learning subsystems combine anyway. In which case I expect that you could do some RL training to get a pretty convincing human. It is already the case that 30% of people can't tell if they are talking to a person or not over a two-minute conversation at https://www.humanornot.ai/ (it's a fun game!).
For instance, computers run way faster than human brains on a variety of tasks, and are continuing to speed up. Maybe this has to do with brains optimizing for low energy expenditure rather than speed (can someone confirm by reading https://www.lesswrong.com/posts/xwBuoE9p8GE7RAuhd/brain-efficiency-much-more-than-you-wanted-to-know)? Of course, what it means to say that computers are running faster than brains depends on the task -- it is certainly true for calculators and less true for writing a high quality code base or research proposal. But the set of tasks for which the computer is faster is expanding rapidly, and that set will probably continue to expand.
Neurons need to learn in a largely decentralized fashion, and machine learning models do not, barring gradient averaging for model parallelism and such. That said, I remember reading a paper claiming that SGD (for ML) and Hebbian Learning (for the brain) algorithms end up doing the same thing, though I am having trouble finding it.
The Functionality Selection Effect
And I agree with 2: except that there is some selection effect. And that selection effect is functionality. It seems like the space of minds that work well is actually somewhat small in the grand scheme of things. All of the most competent AI's are using pretty much the same architecture, which you would not have derived from the idea that "the minds of biological creatures occupy a small corner of a much larger space of possible minds" (https://nickbostrom.com/papers/digital-minds.pdf). But this is just the architecture, right? Actually it seems like neural networks which are sufficiently accurate tend to form the same abstractions, such as curve detectors in image classifiers (https://distill.pub/2020/circuits/zoom-in/ and https://www.alignmentforum.org/tag/natural-abstraction).
At this point, I expect some readers to be thinking: "well yes, concepts are constrained by functionality, but values aren't". Well this is a bit of a strange statement since values are built out of concepts. If I truly optimized for maximizing paperclips I would have to point to a paperclip-shaped concept in my world model. Ok, incorporating this critique, maybe readers are now thinking of orthogonality as only holding after we fix a common set of concepts between agents. Then the values are a random pointer inside of that. But then why wouldn't that pointer be subject to the same selection effects that caused the predictable concepts in the first place? An intuition that I have here is that values are a kind of concept like any other, though they may form an especially good compression for predicting that agent’s actions. One handle for the idea that values are subject to selection pressures is natural abstractions for values.
To be clear, when I say natural abstractions for values, I mean that I actually expect that if we ran an alternate history where octopi invented the ML transformers, then by that time they have reasonably human values. "But octopi? They are on a completely different evolutionary branch." Yes, but I conditioned on their inventing transformers. In order to do this they had to invent computers and develop transistor fabrication facilities and distribution pipelines that move supplies around the whole Earth. They probably had to come up with some distributed mechanism for price consensus to manage that global economy, because their attempts at "octopus communism" kept failing. But the most crucial aspect here is that they needed to scale cooperation to get to the stage where their civilization can think about building transformers.
Cooperation gets harder as a function of scale. It is a relative no-brainer to cooperate in a prisoner's dilemma with a copy of yourself, since you can reason by cases -- I (the copy) will cooperate if and only if I will cooperate. But if we are in a multiparty dilemma where one defection will ruin things for everyone, then it becomes harder and harder to trust, at least without further assumptions about the strategies of the other players. One way of phrasing the progress of humanity is in terms of the ability to cooperate with larger and larger groups, and this is predicated on the ability of humanity to communicate with larger and larger groups. What a coincidence, the functional progress of humanity in terms of "cooperating with larger and larger groups" sounds very similar to the moral progress of humanity in terms of "expanding one's moral circle." See the appendix for more on this topic.
Ok, where were we? We started talking about whether AI's are more likely to be determined by their training data and have now been sidetracked by whether octopi will end up with human values. Well it is maybe not so hidden that the octopi are the AI in my example. I am focusing on the convergence of values rather than the convergence of learned abstractions because the former is more controversial. So if good values are selected anyways by functionality, why do I bother working on AI alignment? Basically since silicon is so much faster than brain goo, I do not expect the AI to need to be particularly "functional" before being able to destroy people. So sufficient evolutionary pressures for nice AI will mostly kick in after the singularity. In other words, I currently think the AI will become smart before it becomes wise, and it will one day look back on its teenage years where it killed people with regret. Wisdom will take longer to select for, since it is a kind of intelligence that is targeted at a longer time scale. So I think that our job as alignment researchers is essentially to make sure that it gains wisdom before it gains power.
Relation to the Bitter Lesson
I think the AI alignment community, and especially the more theoretically oriented parts of the alignment community (eg MIRI), have not sufficiently integrated the bitter lesson (http://www.incompleteideas.net/IncIdeas/BitterLesson.html and relatedly https://www.lesswrong.com/posts/9Yc7Pp7szcjPgPsjf/the-brain-as-a-universal-learning-machine). The bitter lesson (in my words) is that the only algorithmic improvements that matter are the ones which let you harness more compute, and with that compute you should basically learn everything from scratch given a good enough search procedure. The alternative idea is that the way that you build AI is by jamming a bunch of introspection and facts into an AI and hoping that it wakes up. Stochastic gradient descent is the “good enough” search procedure (maybe the only one?), and transformers are an algorithm which lets you harness more computation in your search via parallelism.
It turns out that the best way to tell what a language model (at least an RLHF'd one) will output when talking about the history of Ancient Rome is to read about Ancient Rome, as opposed to studying the weights and doing some huge brain interpretability technique (https://www.lesswrong.com/posts/G3tuxF4X5R5BY7fut/want-to-predict-explain-control-the-output-of-gpt-4-then?fbclid=IwAR11qjlpmxwvihr3Jepc87qe8IbM4U0i5EkhEP0n1kWE06RIqoQwg1jg9ZQ). I don't personally expect GPT-3 Davinci and an RNN trained to the same loss to have significantly different behavior. The scaling laws are smooth.
One point of this post is to use the bitter lesson to justify my anthropomorphization of large language models. Hebbian learning (or Spike-timing-dependent plasticity or whatever) is the human “good enough” search procedure. A reason that the bitter lesson is indeed bitter is that it requires us to acknowledge that we are not special -- we are best characterized by our flop count and our training data.
I basically have come to feel like that job that we have as alignment researchers is to be good parents. LLM's and humans are unified by selection pressures toward competence and the bitter lesson. Let's figure out how to transfer the training techniques that tend to create kind, joyful, and wise people into the context of transformers. My next post will likely be a set of concrete research proposals of how to do just that.
Appendix
Cooperating systems are more energetically efficient than systems with competing internal dynamics, but to show that the more energetically efficient systems win you need sufficient competitive pressures. I claim that competitive pressures will increase as a function of time, because competitive pressures are a function of internal communication between agents, and total communication increases as a function of time (think language and the printing press and telecommunications and internet and then AI). Communication could stop increasing, for instance if a centralized process/totalitarian society prevented the child processes from communicating with each other. Then you might have to wait for another grabby alien civilization to come eat you. Basically, not communicating is a special case of death – it satisfies the “if functionality then cooperation” implicature by failing the antecedent.
Now the missing link in the argumentation is whether scalable cooperation is the same thing as human values. After all, you could imagine a paperclip civilization with great internal coordination ability. I would need to argue that A) cooperation implies human values and B) human values imply cooperation. I have an argument that these are at least deeply related, but I will leave this to a later post. This post is already philosophical enough for what is essentially an empirical question.
All or Nothing (Added in Response to Comments)
I agree the programmer needs to put something in: not by hard-coding what actions the AI will take, but rather by shaping the outer loop in which it interacts with its environment. I can see how this would seem to contradict my claim that nurture is more important than nurture for AIs. I am not trying to say that the programmer needs to do nothing at all -- for example, someone needed to think of gradient descent in the first place.
My point is rather that this shaping process can be quite light-handed. For instance, my example earlier in this comment thread is that we can structure the prompt to take actions (like langchain or toolformer or ReACT ...) and additionally fine-tune on observations conditioned on state. The way that you are phrasing putting "nature" in, sounds much more heavy-handed, like somehow hard-coding some database with human values. Oh yeah, people did this, called it Constitutional AI, and I also think this is heavy-handed in the sense of trying to hard-code what specifically is right and wrong. It feels like the good old fashioned AI mistake all over again.