My guess is that there are automated ways that will help with e.g. 90% (or even all) cases like this:
- Just asking the model "see this patch, try making it cleaner and more concise if possible, while keeping all the important logic" would likely help in your case.
- You could also have some "critic" role. The insight "this looks too long and complicated on the first skim" is something an LLM could also say here, and then you could ask the model to improve that part.
Generally LLMs are really good at refactoring, but it feels people don't use them for that purpose enough because that costs time and tokens. But I don't see a good reason for why it would stay that way forever.
So, in other words, I would predict that with the current LLMs you could have "high quality code" scaffold that produces high quality code, just at a cost.
I find a lot of benefit from having alternate subagents build and review. Somehow a builder is mediocre at reviewing its own code, but clearing the context improves the reviews greatly.
You reminded me of James Koppel's latest newsletter:
On the other hand, eliminating hidden coupling — pieces of code that must be changed in tandem and yet do not result in compile errors when they fall out of synch (taught in Unit 2 of our course) — is becoming more important. The ability for code to become intertwined far outpaces the model's ability to read and think through large codebases, and they lack even the feeble human memory to track such secret dependences. Though I and many others have experienced nasty bugs caused by AI-induced hidden coupling, this is something that I (knock on wood) do not see changing at the model level. Our refactoring agent improves a lot – but as hidden coupling is fundamentally about understanding design intent, preventing it still needs a knowledgeable human in the driver's seat, one using Command Center's understandability and walkthrough features more than the refactoring features.
The upshot of all this: when one of our contractors switched to a company of lesser code quality, he found the effectiveness of his Claude Code dropped tremendously. And we've been working on a set of benchmarks that measure code quality by the amount of work needed and bugs produced by AIs doing follow-on work.
I'd be interested in more such code quality-oriented benchmarks. For now the only thing I'm aware of from Anthropic internally, at least that they've mentioned publicly, is "it works" and "another engineer can understand and build upon it":
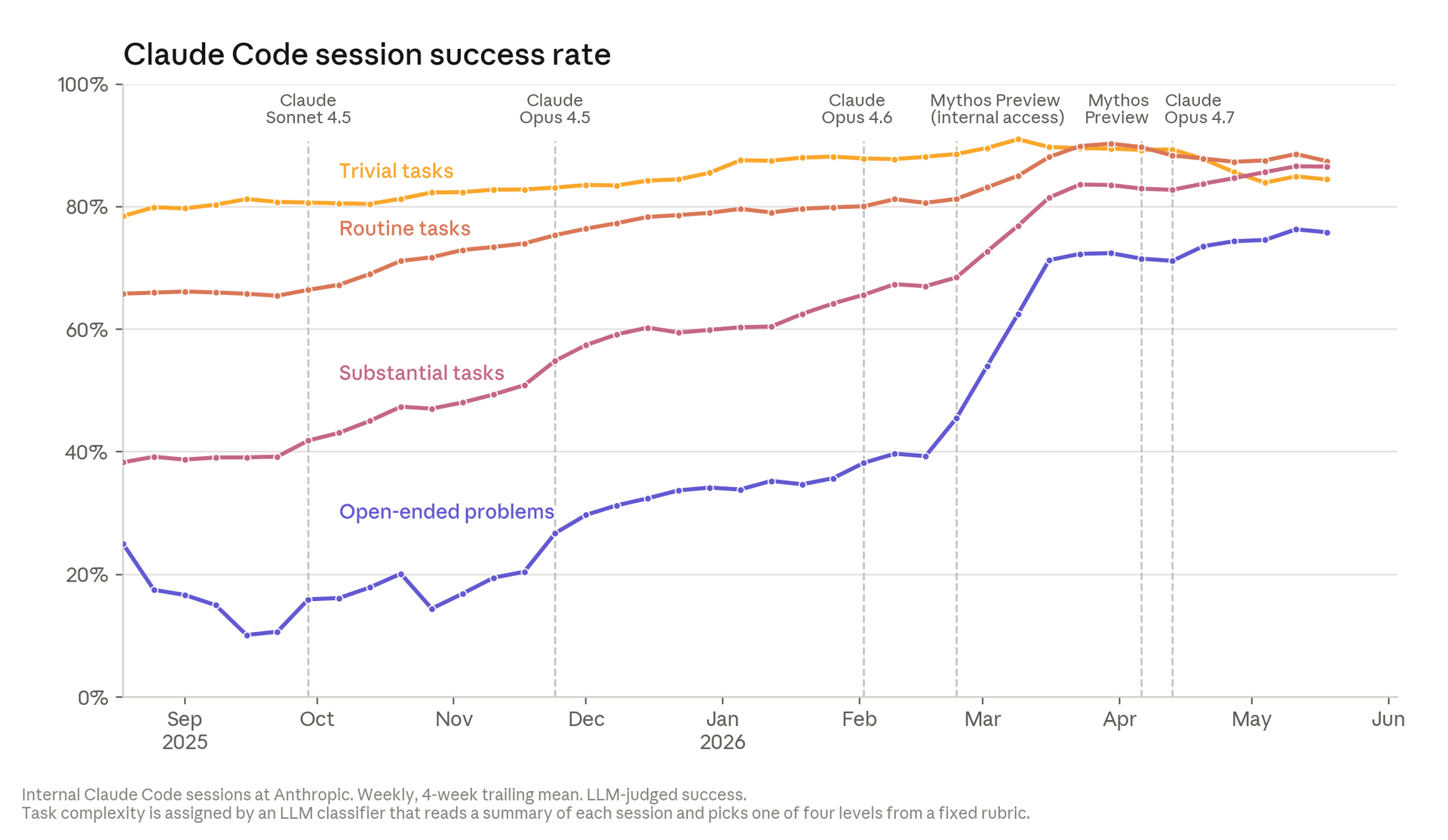
The code that Claude writes is “good” and improving. “Good code” means two things: it works, and it is written in a manner that allows another engineer to understand it and build upon it. On the first criterion, the evidence is clear. The rate at which Anthropic staff correct, redirect, or take over mid-task from Claude has been falling steadily for a year, including on the most complex and open-ended tasks. This means problems with no clear specification, where the engineer isn’t sure what the answer looks like. This is evident in Claude’s success rate over time on tasks of different difficulties, as shown in the graph below. Claude writes code that works.
How to read this: Session success is determined by a Claude judge; a session is deemed successful if the Claude Code agent clearly succeeded at the user’s tasks without requiring corrections. Changes in workloads can lead to short-term fluctuations in success rates.
On the most open-ended tasks, Claude’s success rate reached 76% in May 2026, up 50 percentage points in six months. To give an example of tasks in this difficulty tier, a routine upgrade began crashing tens of thousands of training jobs. An engineer pointed Claude at the live incident with little more than some text content and cluster access. Working through the running jobs and testing one environment setting at a time, Claude isolated the single obscure debugging flag that was triggering the crash, reproduced it reliably, and confirmed a fix. In about two hours, Claude delivered what would normally be two to three days of work.
The second criterion is writing code that another engineer can understand and build on. Here the gap between humans and AI persists, but is closing fast. There isn’t full consensus among staff at Anthropic, but many believe that the Claude-written code was still worse in quality than human-written code at Anthropic in late 2025, and is roughly at parity today. We expect it to be better within the year.
What happens in a year or two, when we continue shipping code that’s consistently more complex than it needs to be?
In the traditional software lifecycle, this does not look sustainable.
It seems that the reason agentic coding sort of works today is that LLMs make "refactoring by rewriting/regenerating from scratch" affordable, and when people regenerate from scratch, one avoids one traditional source of problems (accumulations of defects on top of defects on top of defects on top of ... ), hence the LLM complexity overhead remains bounded rather than increasing in an unbounded fashion and sinking the project.
Of course, in a year or two people expect to benefit from better coding agents, with better taste and less propensity for unnecessary complexity (and so they do expect that eventually this practice of "refactoring by regenerating from scratch" will wash the unnecessary complexity away as agents become better).
I see extra complexity every time I try to get coding help.
For background, I'm not much of a programmer. The biggest project I've made is a ~1000 line script that almost runs in a straight line from start to finish. It's enough to turn a week of constant work into five minutes of careful checking, or a few minutes of skilled labor into a single button press, but nothing compared to True Software(TM).
Whenever I would look up how to do something (open a file, create a folder, play a sound), I'd find a 20-line monstrosity given as a minimal example on Stack Overflow, or something worse on Copilot (I've since graduated to Claude). After picking apart which sections actually matter, I'd add the two important lines to my code and go on to the next problem.
If LLM code was only 10% more complex than necessary, they'd be obviously superhuman.
Whenever I would look up how to do something (open a file, create a folder, play a sound), I'd find a 20-line monstrosity given as a minimal example on Stack Overflow
I had a similar experience trying to find something useful about Java. Some things are used together so often that I suspect most people don't even know how to use them separately. You ask about one thing, and their shortest example is 500 lines of project setup, dependency injection, and whatever else, where 5 lines would perfectly address your question.
It's like asking "how can I change a light bulb", and getting answers like "here is how to renovate your entire house (includes replacing all the light bulbs)".
Makes me suspect that most people do not understand their craft as deeply as I would prefer. IT development used to be a job for people who were obsessed with technical details; now there are many people who are happy just to put something things together and collect a salary.
That said, in my experience AIs are a huge improvement over Stack Overflow, because you can ask them additional questions and often get the answer you want (where SO would be like "just accept the correct answer, this is not a place for discussion").
i think that we need to start rethinking some of our best-practices. For instance, does DRY matter? If i have a server that serves a bunch of endpoints, and if each one reimplements some fetching function, is that bad? As you said, if all of the code is local, and we need to fix one of the endpoints, we can just fix that endpoint, and not break anything else in the process. If we need to make changes across the endpoints, we can tell it to do so.
I’m not sure about this though. Right now, I don’t think that’s the right call—mostly because humans still have to read and understand the code—but I expect that in the very near future we won’t be reading much of the code anyway.
it’s a weird time we’re living in right now as software engineers.
For instance, does DRY matter?
I totally believe it does not!
I think that we will discover an important distinction in what we now consider the pool of good coding practices: on one side what makes code generally evolvable, on the other what make it maintainable and evolvable by humans.
I suspect that even without too much explicit design, a lot of evolvability will come for free when cumbersome implementations that just happen to pass all tests will start being adopted at a massive scale. I actually have a longer form of this argument here
TL;DR: My new prior is that top-of-the-line LLMs working on easy tasks generate code that is maybe 10 % more complicated than necessary. I also think we accept this complexity too easily, because it comes from code that is right here, right now, solving an immediate problem. This may have consequences for maintenance in the long term.
(The text of the LessWrong version of this article is lightly adjusted to fit a more general audience than my usual readership of software product developers.)
The background to this discovery was that I needed to do some software plumbing in a work project. It was a simple change that mostly mirrored existing functionality. This is a perfect fit for LLMs, in my experience, so I used a frontier model to generate the code for it. The change ended up being a total of just over 200 lines, mostly additions.
The part of the generated code we’ll talk about is a 24-line function that converts an arbitrary (user-supplied) string to a safe HTTP header value.[1]
toHeaderValue :: Text -> TexttoHeaderValue raw =
let
attrChars = "!#$&+-.^_`|~"
padHex t = if Text.length t < 2 then "0" <> t else t
percentEncode c =
if (isAscii c && isAlphaNum c) || elem c attrChars then
Text.singleton c
else
Text.concat
[ "%" <> padHex (Text.toUpper (Text.pack (showHex b "")))
| b <- ByteString.unpack (encodeUtf8 (Text.singleton c))
]
rfc5987Encode = Text.concatMap percentEncode
isPrintable c = c >= ' ' && c /= '\DEL'
replacePathSeparator c =
if c == '/' || c == '\\' then
'_'
else
c
cleaned =
Text.map replacePathSeparator (Text.filter isPrintable raw)
in
rfc5987Encode cleaned
When looking at this function in isolation, it obviously seems a bit too complicated, but remember that this was just 24 lines in a 200-line change. I confirmed that the underlying idea was correct, and that the generated tests covered all the edge cases I would want to see covered. It’s not pretty code, but it is proven correct by tests.
More importantly, it is highly local. If anything about this code needs replacing, it can be replaced without touching anything else. Apprentice-level programmers worry equally about code quality everywhere; I’ve long wanted to write an article called “Don’t worry, it’s local” where I tell these programmers that bad code quality is fine, as long as it’s self-contained in a small location.
I accepted this code. I needed the implementation to work, and this code obviously worked. It was right there, right now. It would have been silly to not accept it! Accepting it was the easy choice, and certainly not a bad decision.
However, in a pleasant twist of fate, the automated code verification pipeline for this project has a mandatory statement test coverage check, and that check failed for this code.
The check failed due to the
padHexfunction, which takes a hexadecimal value in the range0x0–0xffand zero-pads it if it is less than0x10. The data passed intopadHexhas already gone through theisPrintablefilter, which removes all bytes lower than0x20. Thus no value passed topadHexis ever below0x10, and it never ends up padding anything! It is always a no-op. The statement coverage check warns on the padding branch ofpadHex, because it is exercised by no automated test. It is in fact impossible to exercise it in a test.This was annoying:
percentEncodeis always called with characters greater than0x1f, even if that happens to be true at the moment. Such an assumption relies on spooky action at a distance, which – even if it is local to this function – we want to avoid.So I stepped in and wrote my own implementation. The implementation that ended up shipping was closer to this:
toHeaderValue :: Text -> TexttoHeaderValue =
let
retainPrintable = Text.filter (\c -> c >= ' ' && c /= '\DEL')
replacePathSeparators = Text.replace "/" "_" . Text.replace "\\" "_"
-- URL encoding is also legal RFC5987 encoding.
rfc5987Encode = decodeUtf8 . urlEncode True . encodeUtf8
in
rfc5987Encode . replacePathSeparators . retainPrintable
This is 15 lines of complexity shorter. That’s around 8 % of the change.
The LLM did not generate bad code.[2] It just generated code that was at least 8 % more complex than it needed to be. That’s not a disaster today, and when there’s pressure to ship, it is easy to accept it because it is right there, right now, and it solves the problem. I accepted and was about to ship code that was 8 % too complex. It was only by chance I looked into it more deeply and realised the problems with it.
This experience leaves me with a bunch of questions I don’t have answers to.
On the one hand, this worries me. On the other hand, the obvious counter-argument is that code-generating robots improve fast enough that in two years’ time when this becomes a problem, they will know how to deal with it.
Maybe. I’m not convinced.
Encoding it into a safe value is necessary to avoid confusing mistakes, but also to prevent HTTP header injection attacks.
In some sense, its code is better. The RFC 5987 encoding is more lax than URL encoding, so my implementation technically over-encodes.