Thanks for putting in all this work!
I recommend you post this to the MAGIC list and ask for feedback. You'll also see a discussion of Anja's post there.
I like how you specify utility directly over programs, it describes very neatly how someone who sat down and wrote a utility function
)
would do it: First determine how the observation could have been computed by the environment and then evaluate that situation. This is a special case of the framework I wrote down in the cited article; you can always set
=\sum_{q:q(y_{1:m_k})=x_{1:m_k}}%20U(q,y_{1:m_k}))
This solves wireheading only if we can specify which environments contain wireheaded (non-dualistic) agents, delusion boxes, etc..
True, the U(program, action sequence) framework can be implemented within the U(action/observation sequence) framework, although you forgot to multiply by 2^-l(q) when describing how. I also don't really like the finite look-ahead (until m_k) method, since it is dynamically inconsistent.
This solves wireheading only if we can specify which environments contain wireheaded (non-dualistic) agents, delusion boxes, etc..
Not sure what you mean by that.
you forgot to multiply by 2^-l(q)
I think then you would count that twice, wouldn't you? Because my original formula already contains the Solomonoff probability...
Let's stick with delusion boxes for now, because assuming that we can read off from the environment whether the agent has wireheaded breaks dualism. So even if we specify utility directly over environments, we still need to master the task of specifying which action/environment combinations contain delusion boxes to evaluate them correctly. It is still the same problem, just phrased differently.
If I understand you correctly, that sounds like a fairly straightforward problem for AIXI to solve. Some programs q_1 will mimic some other program q_2's communication with the agent while doing something else in the background, but AIXI considers the possibilities of both q_1 and q_2.
This is great!
I really like your use of ). The seems to be an important step along the way to eliminating the horizon problem. I recently read in Orseau and Ring's "Space-Time Embedded Intelligence" that in another paper, "Provably Bounded-Optimal Agents" by Russell and Subramanian, they define
%20=%20u(h(\pi,%20q))) where
) generates the interaction history
. (I have yet to read this paper.)
Your counterexample of supremum chasing is really great; it breaks my model of how utility maximization is supposed to go. I'm honestly not sure whether one should chase the path of U = 0 or not. This is clouded by the fact that the probabilistic nature of things will probably push you off that path eventually.
The dilemma reminds me a lot of exploring versus exploiting. Sometimes it seems to me that the rational thing for a utility maximizer to do, almost independent of the utility function, would be to just maximize the resources it controlled, until it found some "end" or limit, and then spend all its resources creating whatever it wanted in the first place. In the framework above we've specified that there is no "end" time, and AIXI is dualist, so there are no worries of it getting destroyed.
There's something else that is strange to me. If we are considering infinite interaction histories, then we're looking at the entire binary tree at once. But this tree has uncountably infinite paths! Almost all of the (infinite) paths are incomputable sequences. This means that any computable AI couldn't even consider traversing them. And it also seems to have interesting things to say about the utility function. Does it only need to be defined over computable sequences? What if we have utility over incomptuable sequences? These could be defined by second-order logic statements, but remain incomputable. It gives me lots of questions.
The draft I recently sent you answers some of these questions. The expected utility should be an appropriately defined integral not a sum.
I'm honestly not sure whether one should chase the path of U = 0 or not. This is clouded by the fact that the probabilistic nature of things will probably push you off that path eventually.
Making the assumption that there is a small probability that you will deviate from your current plan on each future move, and that these probabilities add up to a near guarantee that you will eventually, has a more complicated effect on your planning than just justifying chasing the supremum.
For instance, consider this modification to the toy example I gave earlier. Y:={a,b,c}, and if the first b comes before the first c, then the resulting utility is 1 - 1/n, where n is the index of the first b (all previous elements being a), as before. But we'll change it so that the utility of outputting an infinite stream of a is 1. If there is a c in your action sequence and it comes before the first b, then the utility you get is -1000. In this situation, supremum-chasing works just fine if you completely trust your future self: you output a every time, and get a utility of 1, the best you could possibly do. But if you think that there is a small risk that you could end up outputting c at some point, then eventually it will be worthwhile to output b, since the gain you could get from continuing to output a gets arbitrarily small compared to the loss from accidentally outputting c.
There's something else that is strange to me. If we are considering infinite interaction histories, then we're looking at the entire binary tree at once. But this tree has uncountably infinite paths! Almost all of the (infinite) paths are incomputable sequences. This means that any computable AI couldn't even consider traversing them. And it also seems to have interesting things to say about the utility function. Does it only need to be defined over computable sequences? What if we have utility over incomptuable sequences? These could be defined by second-order logic statements, but remain incomputable. It gives me lots of questions.
I don't really have answers to these questions. One thing you could do is replace the set of all policies (P) with the set of all computable policies, so that the agent would never output an uncomputable action sequence [Edit: oops, not true. You could consider only computable policies, but then end up at an uncomputable policy anyway by chasing the supremum].
Whether the agent outputs an uncomputable sequence of actions isn't really a concern, but the environment frequently does (some l.s.c. environments output uniformly random percepts).
Making the assumption that...
Yeah, I was intentionally vague with "the probabilistic nature of things". I am also thinking about how any AI will have logical uncertainty, uncertainty about the precision of its observations, et cetera, so that as it considers further points in the future, its distribution becomes flatter. And having a non-dualist framework would introduce uncertainty about the agent's self, its utility function, its memory, ...
I think there is something off with the formulas that use policies: If you already choose the policy
=y_{%3Ck}y_k)
then you cannot choose an y_k in the argmax.
Also for the Solomonoff prior you must sum over all programs
=x_{1:m_k}) .
Could you maybe expand on the proof of Lemma 1 a little bit? I am not sure I get what you mean yet.
If you already choose the policy ... then you cannot choose an y_k in the argmax.
The argmax comes before choosing a policy. In , there is already a value for y_k before you consider all the policies such that p(x_<k) = y_<k y_k.
Also for the Solomonoff prior you must sum over all programs
Didn't I do that?
Could you maybe expand on the proof of Lemma 1 a little bit?
Look at any finite observation sequence. There exists some action you could output in response to that sequence that would allow you to get arbitrarily close to the supremum expected utility with suitable responses to the other finite observation sequences (for instance, you could get within 1/2 of the supremum). Now look at another finite observation sequence. There exists some action you could output in response to that, without changing your response to the previous finite observation sequence, such that you can get arbitrarily close to the supremum (within 1/4). Look at a third finite observation sequence. There exists some action you could output in response to that, without changing your responses to the previous 2, that would allow you to get within 1/8 of the supremum. And keep going in some fashion that will eventually consider every finite observation sequence. At each step n, you will be able to specify a policy that gets you within 2^-n of the supremum, and these policies converge to the policy that the agent actually implements.
I hope that helps. If you still don't know what I mean, could you describe where you're stuck?
Response to: Universal agents and utility functions
Related approaches: Hibbard (2012), Hay (2005)
Background
Here is the function implemented by finite-lifetime AI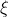 :
:
where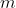 is the number of steps in the lifetime of the agent,
is the number of steps in the lifetime of the agent, 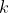 is the current step being computed,
is the current step being computed, 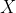 is the set of possible observations,
is the set of possible observations, 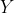 is the set of possible actions,
is the set of possible actions,  is a function that extracts a reward value from an observation, a dot over a variable represents that its value is known to be the true value of the action or observation it represents, underlines represent that the variable is an input to a probability distribution, and
is a function that extracts a reward value from an observation, a dot over a variable represents that its value is known to be the true value of the action or observation it represents, underlines represent that the variable is an input to a probability distribution, and 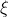 is a function that returns the probability of a sequence of observations, given a certain known history and sequence of actions, and starting from the Solomonoff prior. More formally,
is a function that returns the probability of a sequence of observations, given a certain known history and sequence of actions, and starting from the Solomonoff prior. More formally,
where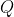 is the set of all programs,
is the set of all programs, 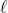 is a function that returns the length of a program in bits, and a program applied to a sequence of actions returns the resulting sequence of observations. Notice that the denominator is a constant, depending only on the already known
is a function that returns the length of a program in bits, and a program applied to a sequence of actions returns the resulting sequence of observations. Notice that the denominator is a constant, depending only on the already known 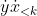 , and multiplying by a positive constant does not change the argmax, so we can pretend that the denominator doesn't exist. If
, and multiplying by a positive constant does not change the argmax, so we can pretend that the denominator doesn't exist. If 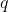 is a valid program, then any longer program with
is a valid program, then any longer program with 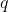 as a prefix is not a valid program, so
as a prefix is not a valid program, so 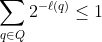 .
.
Problem
A problem with this is that it can only optimize over the input it receives, not over aspects of the external world that it cannot observe. Given the chance, AI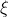 would hack its input channel so that it would only observe good things, instead of trying to make good things happen (in other words, it would wirehead itself). Anja specified a variant of AI
would hack its input channel so that it would only observe good things, instead of trying to make good things happen (in other words, it would wirehead itself). Anja specified a variant of AI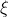 in which she replaced the sum of rewards with a single utility value and made the domain of the utility function be the entire sequence of actions and observations instead of a single observation, like so:
in which she replaced the sum of rewards with a single utility value and made the domain of the utility function be the entire sequence of actions and observations instead of a single observation, like so:
This doesn't really solve the problem, because the utility function still only takes what the agent can see, rather than what is actually going on outside the agent. The situation is a little better because the utility function also takes into account the agent's actions, so it could punish actions that look like the agent is trying to wirehead itself, but if there was a flaw in the instructions not to wirehead, the agent would exploit it, so the incentive not to wirehead would have to be perfect, and this formulation is not very enlightening about how to do that.
[Edit: Hibbard (2012) also presents a solution to this problem. I haven't read all of it yet, but it appears to be fairly different from what I suggest in the next section.]
Solution
Here's what I suggest instead: everything that happens is determined by the program that the world is running on and the agent's actions, so the domain of the utility function should be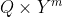 . The apparent problem with that is that the formula for AI
. The apparent problem with that is that the formula for AI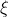 does not contain any mention of elements of
does not contain any mention of elements of 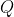 . If we just take the original formula and replace
. If we just take the original formula and replace 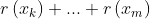
with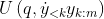 , it wouldn't make any sense. However, if we expand out
, it wouldn't make any sense. However, if we expand out 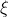 in the original formula (excluding the unnecessary denominator), we can move the sum of rewards inside the sum over programs, like this:
in the original formula (excluding the unnecessary denominator), we can move the sum of rewards inside the sum over programs, like this:
Now it is easy to replace the sum of rewards with the desired utility function.
With this formulation, there is no danger of the agent wireheading, and all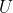 has to do is compute everything that happens when the agent performs a given sequence of actions in a given program, and decide how desirable it is. If the range of
has to do is compute everything that happens when the agent performs a given sequence of actions in a given program, and decide how desirable it is. If the range of 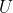 is unbounded, then this might not converge. Let's assume throughout this post that the range of
is unbounded, then this might not converge. Let's assume throughout this post that the range of 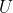 is bounded.
is bounded.
[Edit: Hay (2005) presents a similar formulation to this.]
Extension to infinite lifetimes
The previous discussion assumed that the agent would only have the opportunity to perform a finite number of actions. The situation gets a little tricky when the agent is allowed to perform an unbounded number of actions. Hutter uses a finite look-ahead approach for AI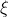 , where on each step
, where on each step 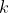 , it pretends that it will only be performing
, it pretends that it will only be performing 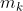 actions, where
actions, where 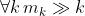 .
.
If we make the same modification to the utility-based variant, we get
This is unsatisfactory because the domain of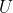 was supposed to consist of all the information necessary to determine everything that happens, but here, it is missing all the actions after step
was supposed to consist of all the information necessary to determine everything that happens, but here, it is missing all the actions after step 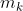 . One obvious thing to try is to set
. One obvious thing to try is to set 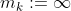 . This will be easier to do using a compacted expression for AI
. This will be easier to do using a compacted expression for AI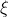 :
:
where is the set of policies that map sequences of observations to sequences of actions and
is the set of policies that map sequences of observations to sequences of actions and 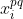 is shorthand for the last observation in the sequence returned by
is shorthand for the last observation in the sequence returned by 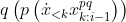 . If we take this compacted formulation, modify it to accommodate the new utility function, set
. If we take this compacted formulation, modify it to accommodate the new utility function, set 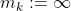 , and replace the maximum with a supremum (since there's an infinite number of possible policies), we get
, and replace the maximum with a supremum (since there's an infinite number of possible policies), we get
where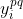 is shorthand for the last action in the sequence returned by
is shorthand for the last action in the sequence returned by  .
.
But there is a problem with this, which I will illustrate with a toy example. Suppose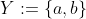 , and
, and 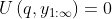 when
when 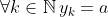 , and for any
, and for any 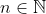 ,
, 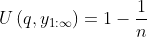 when
when 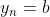 and
and 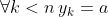 . (
. (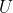 does not depend on the program
does not depend on the program 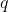 in this example). An agent following the above formula would output
in this example). An agent following the above formula would output  on every step, and end up with a utility of
on every step, and end up with a utility of  , when it could have gotten arbitrarily close to
, when it could have gotten arbitrarily close to 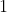 by eventually outputting
by eventually outputting 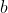 .
.
To avoid problems like that, we could assume the reasonable-seeming condition that if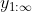 is an action sequence and
is an action sequence and 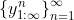 is a sequence of action sequences that converges to
is a sequence of action sequences that converges to 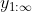 (by which I mean
(by which I mean 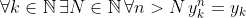 ), then
), then 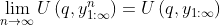 .
.
Under that assumption, the supremum is in fact a maximum, and the formula gives you an action sequence that will reach that maximum (proof below).
If you don't like the condition I imposed on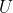 , you might not be satisfied by this. But without it, there is not necessarily a best policy. One thing you can do is, on step 1, pick some extremely small
, you might not be satisfied by this. But without it, there is not necessarily a best policy. One thing you can do is, on step 1, pick some extremely small 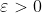 , pick any element from
, pick any element from
Proof of criterion for supremum-chasing working
definition: If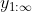 is an action sequence and
is an action sequence and 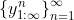 is an infinite sequence of action sequences, and
is an infinite sequence of action sequences, and 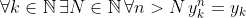 , then we say
, then we say 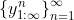 converges to
converges to  . If
. If 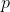 is a policy and
is a policy and 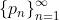 is a sequence of policies, and
is a sequence of policies, and 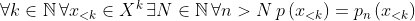 , then we say
, then we say 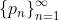 converges to
converges to 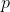 .
.
assumption (for lemma 2 and theorem): If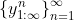 converges to
converges to  , then
, then 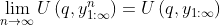 .
.
lemma 1: The agent described by
proof of lemma 1: Any policy can be completely described by the last action it outputs for every finite observation sequence. Observations are returned by a program, so the set of possible finite observation sequences is countable. It is possible to fix the last action returned on any particular finite observation sequence to be the argmax, and still get arbitrarily close to the supremum with suitable choices for the last action returned on the other finite observation sequences. By induction, it is possible to get arbitrarily close to the supremum while fixing the last action returned to be the argmax for any finite set of finite observation sequences. Thus, there exists a sequence of policies approaching the policy that the agent implements whose expected utilities approach the supremum.
lemma 2: If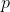 is a policy and
is a policy and 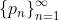 is a sequence of policies converging to
is a sequence of policies converging to 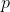 , then
, then
proof of lemma 2: Let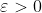 . On any given sequence of inputs
. On any given sequence of inputs 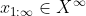 ,
, 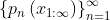 converges to
converges to 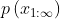 , so, by assumption,
, so, by assumption, 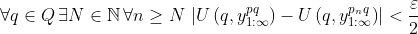 .
.
For each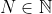 , let
, let 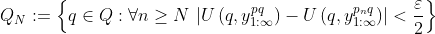 . The previous statement implies that
. The previous statement implies that 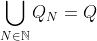 , and each element of
, and each element of 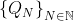 is a subset of the next, so
is a subset of the next, so
so in particular,
theorem:
where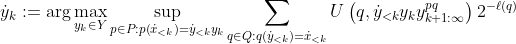 .
.
proof of theorem: Let's call the policy implemented by the agent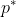 .
.
By lemma 1, there is a sequence of policies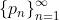
converging to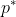 such that
such that
By lemma 2,