IIUC this addresses the ontology problem in AIXI by assuming that the domain of our utility function already covers every possible computable ontology, so that whichever one turns out to be correct, we already know what to do with it. If I take the AIXI formalism to be a literal description of the universe (i.e. not just dualism, but also that the AI is running on a hypercomputer, the environment is running on a turing computer, and the utility function cares only about the environment, not the AI's internals), then I think the proposal works.
But under the more reasonable assumption of an environment at least as computationally complex as the AI itself (whether AIXI in an uncomputable world or AIXI-tl in an exptime world or whatever), Solomonoff Induction still beats any computable sensory prediction, but the proposed method of dealing with utility functions fails: The Solomonoff mixture doesn't contain a simulation of the true state of the environment, so the utility function is never evaluated with the true state of the environment as input. It's evaluated on various approximations of the environment, but those approximations are selected so as to correctly predict sensory inputs, not to correctly predict utilities. If the proposal was supposed to work for arbitrary utility functions, then there's no reason to expect those two approximation problems to be at all related even before Goodhart's law comes into the picture; or if you intended to assume some smoothness-under-approximation constraint on the utility function, then that's exactly the part of the problem that you handwaved.
Possible model of semi-dualism:
The agent could have in its map that it is a computer box subject to physical laws, but only above the level where information processing occurs. That is, it could know that its memory was in a RAM stick, which was subject to material breaking and melting, but not have any predictions about inspecting individual bits of that stick. It could know that that box was itself by TDT-type analysis. Unfortunately this model isn't enough for hardware improvements; it would know that adding RAM was theoretically possible, but it wouldn't know the information-theoretic implications of how its memory protocols would react to added RAM.
Now that I think about it, that's kind of what humans do. Except, to get to the point where we can learn that we are a thing that can be damaged, we need parents and pain-mechanisms to keep us safe.
I believe I have a workable solution for the duality problem, which is essentially a special case of the Orseau-Ring framework, viewed slightly differently. Consider a specific computer architecture M, equipped with an input channel for receiving inputs ostensibly from the environment (although the environment doesn't appear explicitly in the formalism) and possibly special instructions for self-reprogramming (although the latter is semi-redundant as will become clear in the following). This architecture has a state space Sigma (typically M is a universal Turing machine so Sigma is countable but it also possible to consider models with finite RAM in which case M is a finite state automaton), with some state transitions s1 -> s2 being "legitimate" while other not (note that s1 doesn't determine s2 uniquely since the input from the environment can be arbitrary). Consider also U a utility function defined on arbitrary (possibly "illegitimate") infinite histories of M i.e. functions N -> Sigma. Then an "agent" is simply an initial state of M: s in Sigma regarded as a "program". The intelligence of s is defined to be its expected utility assuming the dynamics of M to be described by a certain stochastic process. If we stop here, without specifying this stochastic process, we get more or less an equivalent formulation of the Orseau-Ring framework. By analogy with Legg-Hutter it is natural to assume this stochastic process is governed by the Solomonoff semi-measure. But if we do this we probably won't be able to get any meaningful near-optimal agents since we need to write a program without knowing how the computer works. My suggestion is deforming the Solomonoff semi-measure by assigning weight 0 < p < 1 to state transitions s1 -> s2 which are illegal in terms of M. This should make the near-optimal agents sophisticated since p < 1 so they can rely to some extent on our computer architecture M. On the other hand p > 0 so these agents have to take possible wire-heading into account. In particular they can make positive use of wire-heading to reprogram themselves even if the basic architecture M doesn't allow it, assuming of course they are placed in a universe in which it is possible.
I think you are proposing to have some hypotheses privileged in the beginning of Solomonoff induction, but not too much because the uncertainty helps fight wireheading by means of providing knowledge about the existence of an idealized, "true" utility function and world model. I that a correct summary? (Just trying to test whether I understand what you mean.)
In particular they can make positive use of wire-heading to reprogram themselves even if the basic architecture M doesn't allow it
Can you explain this more?
Yes, I think you got it more or less right. For p=0 we would just get a version of Legg-Hutter (AIXI) with limited computing resources (but duality problem preserved). For p > 0, no hypothesis is completely ruled out and the agent should be able to find the correct hypothesis given sufficient evidence, in particular it should be able to correct her assumptions regarding how her own mind works. Of course this requires the correct hypothesis to be sufficiently aligned with M's architecture for the agent to work at all. The utility function is actually built in from the starters, however if we like we can choose it to be something like a sum of external input bits with decaying weights (in order to ensure convergence), which would be in the spirit of the Legg-Hutter "reinforcement learning" approach.
In particular the agent can discover that the true "physics" allow for reprogramming the agent, even though the initially assumed architecture M didn't allow it. In this case she can use it to reprogram herself for her own benefit. To draw a parallel, a human can perform brain surgery on herself because of her acquired knowledge about the physics of the universe and her brain and in principle she can use it to change the functioning of her brain in ways that are incompatible with her "intuitive" initial assumptions about her own mind
I made some improvements to the formalism, see http://lesswrong.com/lw/cze/reply_to_holden_on_tool_ai/8fjb
There I consider a stochastic model M and here a non-deterministic model, but the same principle can be applied here. Namely, we consider a Solomonoff process starting t0 time before formation of agent A, conditioned by observance of M's rules in the time before A's formation and by A's existence at time of its formation. The expected utility is computed with respect to the resulting distribution
I'm having a great deal of trouble reading this because it's littered with big red "INVALID EQUATION" and "UNBALANCED EQUATION" censors.
I think your argument regarding "Bob pushing a button" is flawed for a few reasons.
You assume a specific example of a man pushing a button as a stand-in for a more general framework. That examply does not generalize.
In general, the agent gets a reward signal from some untility function. It doesn't have to even be implemented by a mechanism the agent has agency over. Deep Blue interacts with a chess board. That's its the environment it has visibility into and it has very limited agency over very limited degrees of freedom within that environment. It can't blackmail the people who programmed it no matter how much computing power it has. Its reward comes from outside of the agent-environment system.
Even if you limit discussion to more specific cases where the utility mechanism is either embedded in the environment or embedded within the agent (or both, in the case of embedded agent), your claim that "a sufficiently smart agent will ... most likely [reward hacking]" lacks justification. The possibility of reward hacking doesn't imply a high probability thereof. That only makes sense in cases where it's easier to hack reward than it is to persue the intended goal. You're assuming specifics in a framework that doesn't specify them.
On top of all that, you imply that a framework is inherently insuficient if it admits the posibility of reward hacking. Any agent-environment system that partitions the utility mechanism from the policy by some reward channel is succeptible to reward hacking if the agent can gain agency over that channel. That partition means the implicit goal of such an agent is to maximize the reward signal rather than persue the goal formalized in the utility function.
I don't know of any intelligent system in the real world that isn't succeptible to reward hacking. People do it all the time. I get that the gravity of the alignment problem sort-of demands solutions with basically zero probability of missalignment, but that may not be possible. I'd like to imagine eliminating the reward channel all together and design a system that directly maximizes a goal, but how do you implement an abstract concept with anything other than indirect indicators? Will the machine be maximizing the good of humanity or will it be maximizing the states of a bunch of transistors which implement some equation that formalizes the good of humanity? Wouldn't any sufficiently intelligent machine be capable of manipulating those transistors?
Great post!
But I'm not quite sure how I feel about the reformulation in terms of semimeasures instead of deterministic programs. Part of my motivation for the environment-specific utility was to avoid privileging observations over unobservable events in the environment in terms of what the agent can care about. So I would only consider the formulation in terms of semimeasures to be satisfactory if the semimeasures are specific enough that the correct semimeasure plus the observation sequence is enough information to determine everything that's happening in the environment.
I really dislike the discounting approach, because it doesn't respect the given utility function and makes the agent miss out on potentially infinite amounts of utility.
If we're going to allow infinite episodic utilities, we'll need some way of comparing how big different nonconvergent series are. At that point, the utility calculation will not look like an infinite sum in the conventional sense. In a sense, I agree that discounting is inelegant because it treats different time steps differently, but on the other hand, I think asymmetry between different time steps is somewhat inevitable. For instance, presumably we want the agent to value getting a reward of 1 on even steps and 0 on odd steps higher than getting a reward of 1 on steps that are divisible by three and 0 on non-multiples of three. But those reward sequences can be placed in 1-to-1 correspondence. This fact causes me to grudgingly give up on time-symmetric utility functions.
one has to be careful to only use the computable subset of the set of all infinite strings
Why?
So I would only consider the formulation in terms of semimeasures to be satisfactory if the semimeasures are specific enough that the correct semimeasure plus the observation sequence is enough information to determine everything that's happening in the environment.
Can you make an example of a situation in which that would not be the case? I think the semimeasure AIXI and deterministic programs AIXI are pretty much equivalent, am I overlooking something here?
If we're going to allow infinite episodic utilities, we'll need some way of comparing how big different nonconvergent series are.
I think we need that even without infinite episodic utilities. I still think there might be possibilities involving surreal numbers, but I haven't found the time yet to develop this idea further.
Why?
Because otherwise we definitely end up with an unenumerable utility function and every approximation will be blind between infinitely many futures with infinitely large utility differences, I think. The set of all binary strings of infinite length is uncountable and how would we feed that into an enumerable/computable function? Your approach avoids that via the use of policies p and q that are by definition computable.
Can you make an example of a situation in which that would not be the case? I think the semimeasure AIXI and deterministic programs AIXI are pretty much equivalent, am I overlooking something here?
The nice thing about using programs is that a program not only determines what your observation will be, but also the entire program state at each time. That way you can care about, for instance, the head of the Turing machine printing 0s to a region of the tape that you can't see (making assumptions about how the UTM is implemented). I'm not sure how semimeasures are usually talked about in this context; if it's something like a deterministic program plus a noisy observation channel, then there's no problem, but if a semimeasure doesn't tell you what the program state history is, or doesn't even mention a program state, then a utility function defined over semimeasures doesn't give you a way to care about the program state history (aka events in the environment).
I think we need that even without infinite episodic utilities.
I don't understand. If all the series we care about converge, then why would we need to be able to compare convergent series?
I still think there might be possibilities involving surreal numbers, but I haven't found the time yet to develop this idea further.
That might end up being fairly limited. Academian points out that if you define a "weak preference" of X over Y as a preference such that X is preferred over Y but there exist outcomes Z and W such that for all probabilities p>0, pZ + (1-p)Y is preferred over pW + (1-p)X, and a "strong preference" as a preference that is not a weak preference, then strong preferences are archimedian by construction, so by the VNM utility theorem, a real-valued utility function describes your strong preferences even if you omit the archimedian axiom (i.e. u(X) > u(Y) means a strong preference for X over Y, and u(X) = u(Y) means either indifference or a weak preference one way or the other). Exact ties between utilities of different outcomes should be rare, and resolving them correctly is infinitely less important than resolving strong preferences correctly. The problem with this that I just thought of is that conceivably there could be no strong preferences (i.e. for any preference, there is some other preference that is infinitely stronger). I suspect that this would cause something to go horribly wrong, but I don't have a proof of that.
Because otherwise we definitely end up with an unenumerable utility function and every approximation will be blind between infinitely many futures with infinitely large utility differences, I think. The set of all binary strings of infinite length is uncountable and how would we feed that into an enumerable/computable function? Your approach avoids that via the use of policies p and q that are by definition computable.
I'm not sure if this fits the definition of enumerable, but the utility function could accept a (possibly uncomputable) stream of actions. The utility function could be set up such that for any desired degree of precision, it only has to look at a finite number of elements. (I think that's equivalent to the continuity assumption I made in my original post.)
If it's specified to have a physical implementation, I think infinite-computation AIXI could actually get around dualism by predicting the behavior of its own physical implementation. That is, it computes outcomes as if the output channel (or similar complete output-determiner) is manipulated magically at the next time step, but it computes them using a causal model that has the the physical implementation still working into the future.
So it wouldn't drop a rock on its head, because even though it thinks it could send the command magically, it can correctly predict the subsequent, causal behavior of the output channel, i.e. silence after getting smooshed by a rock.
This behavior actually does require a non-limit infinity, since the amount of simulation required always grows faster than the simulating power. But I think you can pull it off with approximation schemes - certainly it works in the case of replacing exact simulation of future self-behavior with heuristics like "always silent if rock dropped on head" :D
Super hard to say without further specification of the approximation method used for the physical implementation.
"Intelligence measures an agent's ability to achieve goals in a wide range of environments." (Shane Legg) [1]
A little while ago I tried to equip Hutter's universal agent, AIXI, with a utility function, so instead of taking its clues about its goals from the environment, the agent is equipped with intrinsic preferences over possible future observations.
The universal AIXI agent is defined to receive reward from the environment through its perception channel. This idea originates from the field of reinforcement learning, where an algorithm is observed and then rewarded by a person if this person approves of the outputs. It is less appropriate as a model of AGI capable of autonomy, with no clear master watching over it in real time to choose between carrot and stick. A sufficiently smart agent that is rewarded whenever a human called Bob pushes a button will most likely figure out that instead of furthering Bob's goals it can also threaten or deceive Bob into pushing the button, or get Bob replaced with a more compliant human. The reward framework does not ensure that Bob gets his will; it only ensures that the button gets pressed. So instead I will consider agents who have preferences over the future, that is, they act not to gain reward from the environment, but to cause the future to be a certain way. The agent itself will look at the observation and decide how rewarding it is.
Von Neumann and Morgenstern proved that a preference ordering that is complete, transitive, continuous and independent of irrelevant alternatives can be described using a real-valued utility function. These assumptions are mostly accepted as necessary constraints on a normatively rational agent; I will therefore assume without significant loss of generality that the agent's preferences are described by a utility function.
This post is related to previous discussion about universal agents and utility functions on LW.
Two approaches to utility
Recall that at time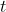 the universal agent chooses its next action
the universal agent chooses its next action  given action-observation-reward history
given action-observation-reward history  according to
according to
where
is the Solomonoff-Levin semimeasure, ranging over all enumerable chronological semimeasures weighted by their complexity
weighted by their complexity ) .
.
My initial approach changed this to
deleting the reward part from the observation random variable and multiplying by the utility function^m\rightarrow%20\mathbb{R}) instead of the reward-sum. Let's call this method standard utility. [2]
instead of the reward-sum. Let's call this method standard utility. [2]
In response to my post Alex Mennen formulated another approach, which I will call environment-specific utility:
which uses a family of utility functions, , where
, where ^m\rightarrow%20[0,U_{\max}%20] "U_\mu:(\mathcal{A}\times\mathcal{O})^m\rightarrow [0,U_{\max} ]") is a utility function associated with environment
is a utility function associated with environment 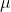 .
.
Lemma: The standard utility method and the environment-specific utility method have equivalent expressive power.
Proof: Given a standard utility function^m\rightarrow%20\mathbb{R}) we can set
we can set  for all environments, trivially expressing the same preference ordering within the environment-specific utility framework. Conversely, given a family
for all environments, trivially expressing the same preference ordering within the environment-specific utility framework. Conversely, given a family  of environment-specific utility functions
of environment-specific utility functions ^m\rightarrow%20[0,U_{\max}%20] "U_\mu:(\mathcal{A}\times\mathcal{O})^m\rightarrow [0,U_{\max} ]") , let
, let
thereby constructing a standard utility agent that chooses the same actions.
Even though every agent using environment-specific utility functions can be transformed into one that uses the standard utility approach, it makes sense to see the standard utility approach as a special case of the environment-specific approach. Observe that any enumerable standard utility function leads to enumerable environment-specific utility functions, but the reverse direction does not hold. For a set of enumerable environment-specific utility functions we obtain the corresponding standard utility function by dividing by the non-computable , which leaves us with a function that is still approximable but not enumerable.[3] I therefore tentatively advocate use of the environment-specific method, as it is in a sense more general, while leaving the enumerability of the universal agent's utility function intact.
, which leaves us with a function that is still approximable but not enumerable.[3] I therefore tentatively advocate use of the environment-specific method, as it is in a sense more general, while leaving the enumerability of the universal agent's utility function intact.
Delusion Boxes
Ring and Orseau (2011) introduced the concept of a delusion box, a device that distorts the environment outputs before they are perceived by the agent. This is one of the only wireheading examples that does not contradict the dualistic assumptions of the AIXI model. The basic setup contains a sequence of actions that leads (in the real environment, which is unknown to the agent) to the construction of the delusion box. Discrepancies between the scenarios the designer envisioned when making up the (standard) utility function and the scenarios that are actually most likely, are used/abused to game the system. The environment containing the delusion box pretends that it is actually another environment that the agent would value more. I like to imagine the designers writing down numbers corresponding to some beneficial actions that lead to saving a damsel in distress, not foreseeing that the agent in question is much more likely to save a princess by playing Super Mario, then by actually being a hero.
Lemma: A universal agent with a well-specified utility function does not choose to build a delusion box.
Proof: Assume without loss of generality that there is a single action that constitutes delusion boxing (in some possible environments, but not in others), say and that it can only be executed at the last time step. Denote by
and that it can only be executed at the last time step. Denote by  an action-observation sequence that contains the construction of a delusion box. By the preceding lemma we can assume that the agent uses environment-specific utility functions. Let
an action-observation sequence that contains the construction of a delusion box. By the preceding lemma we can assume that the agent uses environment-specific utility functions. Let  be the subset of all environments that allow for the construction of the delusion box via action
be the subset of all environments that allow for the construction of the delusion box via action  and assume that we were smart enough to identify these environments and assigned
and assume that we were smart enough to identify these environments and assigned =0 "U_\mu(a^{DB}o_{1:m})=0") for all
for all  . Then the agent chooses to build the box iff
. Then the agent chooses to build the box iff
for all . Colloquially the agent chooses
. Colloquially the agent chooses  if and only if this is a beneficial, non-wireheading action in some of the environments that seem likely (consistent with the past observations and of low K-complexity).
if and only if this is a beneficial, non-wireheading action in some of the environments that seem likely (consistent with the past observations and of low K-complexity). 
We note that the first three agents in Ring and Orseau (2011) have utility functions that invite programmer mistakes in the sense that we'll not think about the actual ways observation/action histories can occur, we'll overestimate the likelihood of some scenarios and underestimate/forget others, leading to the before mentioned "Save the princess" scenario. Only their knowledge-seeking agent does not delusion box, as it is impossible for an environment to simulate behavior that is more complex than the environment itself.
Episodic utility
The original AIXI formalism gives a reward on every time cycle. We can do something similar with utility functions and set
Call a utility function that can be decomposed into a sum this way episodic. Taking the limit to infinite futures, people usually discount episode k with a factor , such that the infinite sum over all the discounting factors is bounded. Combined with the assumption of bounded utility, the sum
, such that the infinite sum over all the discounting factors is bounded. Combined with the assumption of bounded utility, the sum
converges. Intuitively discounting seems to make sense to us, because we have a non-trivial chance of dying at every moment (=time cycle) and value gains today over gains tomorrow and our human utility judgements reflect this property to some extent. A good heuristic seems to be that longer expected life spans and improved foresight lead to less discounting, but the math of episodic utility functions and infinite time horizons places strong constraints on that. I really dislike the discounting approach, because it doesn't respect the given utility function and makes the agent miss out on potentially infinite amounts of utility.
One can get around discounting by not demanding utility functions to be episodic, as Alex Mennen does in his post, but then one has to be careful to only use the computable subset of the set of all infinite strings . I am not sure if this is a good solution, but so far my search for better alternatives has come up empty handed.
. I am not sure if this is a good solution, but so far my search for better alternatives has come up empty handed.
Cartesian Dualism
The most worrisome conceptual feature of the AIXI formalism is that the environment and the agent run on distinct Turing machines. The agent can influence its environment only through its output channel and it can never influence its own Turing machine. In this paradigm any self-improvement beyond an improved probability distribution is conceptually impossible. The algorithm and the Turing machines, as well as the communication channels between them, are assumed to be inflexible and fixed. While taking this perspective it seems as though the agent cannot be harmed and it also can never harm itself by wireheading.
Borrowing from philosophy of mind, we call agent specifications that assume that the agent's cognition is not part of its environment dualist. The idea of non-physical minds that are entities distinct from the physical world dates back to Rene Descartes. It is contradicted by the findings of modern neuroscience that support physicalism, the concept of the emergence of minds from computation done by the brain. In the same spirit the assumption that an AGI agent is distinct from its hardware and algorithm that are necessarily contained in its physical environment can be a dangerous conceptual trap. Any actual implementation will be subject to wireheading problems and outside tampering and should be able to model these possibilities. Unfortunately, non-dualist universal specifications are extremely difficult to formulate and people usually make due with the dualist AIXI model.
Conclusion
Equipping the universal agent with a utility function solves some problems, but creates others. From the perspective of enumerability, Alex Mennen's environment-specific utility functions are more general and they can be used to better avoid delusion boxing. Any proposal using infinite time horizons I have encountered so far uses time discounting or leads to weird problems (at least in my map, they may not extend to the territory). Above all there is the dualism problem that we have no solution for yet.
[1] Taken from "Machine Super Intelligence", page 72.
[2] This approach seems more widespread in the literature.
[3] A real-valued function f(x) is called approximable if there exists a recursive function g(k,x) such that\rightarrow%20f(x) "g(k,x)\rightarrow f(x)") for
for  , i.e. if f can be approximated by a sequence of Turing machines. A real-valued approximable function is called enumerable if for all k,
, i.e. if f can be approximated by a sequence of Turing machines. A real-valued approximable function is called enumerable if for all k, %3Cg(k+1,x) "g(k,x)<g(k+1,x)") , improving the approximation with every step.
, improving the approximation with every step.