This is a special post for quick takes by peterbarnett. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
[Take that's been bumping around in AI governance circles, not original to me]
The middle powers have strong incentives to stop/slow AI development (even if we ignore misalignment risk, which we shouldn't), and can plausibly do something about it.
Even if we ignore misalignment risk, countries that are not the US and China by default will become totally geopolitically irrelevant if ASI is built. One or both of the US and China will have overwhelming economic and military power. The middle powers should therefore want to slow/stop AI development, until they can work out how this can be done without them becoming irrelevant.
Middle powers have some leverage here. States with critical parts of the AI chip supply chain (Netherlands, Korea, Japan, maybe Taiwan) can refuse to sell critical components without certain demands. The EU market is a fairly big deal. States with nuclear weapons can threaten to use them, if they risk becoming totally disempowered, and can defend the chip supply chain states.
My favorite ask right now is that chip supply chain states (Netherlands, Korea, Japan) should refuse to help manufacture chips (both selling components, and keeping SME machines running), unless...
Interesting. This might apply even if they don't believe ASI is real, but that AI has substantial security and wealth implications.
6
Alas, my impression is that a plurality of the AI-related efforts of government-associated institutions (but also in the industry, to a large extent) in EU member states can be described as "trying to be the cool guys too", whether it's about LARPing "being at the frontier" (training mostly useless sovereign models) or by integrating proprietary frontier models into the infrastructure (even when it doesn't make sense and they don't try that hard to do it competently).
On the other hand, this made me think about something I developed into a shortform.
5
This doesn’t seem right to me. Middle powers will only become irrelevant insofar as the ASI built by great powers isn’t aligned to the interests of middle powers. But it could be that it will be: it could be aligned to respect property rights, or human rights, sovereign rights, or values which the middle powers hold in common with the great powers; or it could be aligned to serve citizens / politicians of the great powers who are sympathetic to the middle power. And to the extent that the ASI won’t be by default, the middle powers can use their leverage to try to get it aligned with those things rather than to slow down / stop it entirely.
7
[ignoring misalignment risk] I think it's pretty unlikely that by default ASI built by great powers will end up sufficiently empowering the middle powers. I expect that by default the ASI-creators will try and make the ASI follow their orders or the orders of their government, rather than something that upholds the global order.
I think that middle powers could potentially use verification mechanisms to help ensure that an ASI was being trained with a model spec that includes respecting the interests of middle powers. Overall though, I expect getting it to be very hard to actually get good assurance that an AI isn't being trained in a way that middle powers don't like. And therefore, I guess that it would be better to stop/slow.
I do agree that a reasonable ask of the middle powers is asking for some control over the model spec, but I think it's probably better for the main ask to be about something that the middle powers have direct influence over, e.g., AI hardware.
2
If we ignore misalignment risk, why are you envisioning a world where ASI acts like a benevolent dictator, such that it is up the ASI's own values and decisions whether the middle powers have significant influence over the world? Rather than human customers and users of ASI-powered products and services around the world creating a balance of power (akin to how AI works today)? I think alignment should include be "don't be a dictator", not just "don't be an evil dictator".
2
Could you be more specific about this contrast between "orders of the US government" and "upholding the global order"? Is the idea that if the US government controls the model spec of an ASI machine, they'll use that to overthrow or replace the government of the Netherlands or Korea? That they'll use ASI to impoverish the Dutch or Korean populations? These are the kinds of things being referred to by "insofar as the ASI built by great powers isn't aligned to the interest of middle powers."
3
Why would you expect the American government not to pursue America first policies?
3
I don't understand the relationship, i.e. I don't know what you're referring to by "America first" policies that involve impoverishing or overturning the Korean or Dutch governments. If you mean the specific "America First" foreign-policy slogan, that's in fact a non-interventionist policy.
1[anonymous]
Why would the superpower allow any other country to keep more of their wealth/government/power than whatever is optimal from the perspective of the superpower? If they wouldn't, it feels like that would put a lot of downward pressure on all of these, especially power/government. Wealth as well at least in a relative sense, though perhaps not in an absolute sense. Does your intuition differ?
I wouldn't necessarily expect overthrown governments, as most would just realize they have no choice but to accede to the demands of the superpower. And in most cases I wouldn't expect the superpower to let any nation get so far out of control that overthrowing their government would be necessary. But surely the rare few cases where this does materialize would indeed be overthrown?
Do you consider the current America First administration to be non-interventionist? From my perspective, it is quite obviously very interventionist, very unilateralist, and very nationalist. Imagining something like this administration, but superpowered, I find it hard to understand the claim that this would not disempower middle powers.
2
What’s more, it may be that the competitive equilibrium of increasingly advanced AI never leads to a decisive strategic advantage over other countries trying to keep up. For example, countries with increasingly automated economies may still want to trade with less automated countries, which enriches those countries enough to stay somewhat relevant by automating at a delay. Or less automated economies might have a “catch up” advantage where they can copy the advancements of the most automated economies more easily than they could have developed them themselves. This is how I would describe the geopolitical effects of the industrial revolution: it was a major advantage for the countries first to industrialize, but not an overwhelming / decisive one.
3
Interesting take. I don’t know how I feel about this. I guess if I was 100% down on a pause I’d be more likely to go for this. My intuition is that this plan has too many moving parts. You can try to wake up middle nations in the hope that they’ll try to slow development… but who know what the heck they’ll do? My intuition is that in many circumstances incentives are overruled by ideology. In repeated game scenarios, incentives can eventually bend or displace ideology, but it's not clear to me that we should expect this to happen here.
3
What is the ideology in middle powers you fear of? What are the harmful actions that middle powers might do if they get AGI-pilled?
(Maybe you might be worried that these countries attempt building their own AGI, but it seems extremely unlikely these countries would be able to race ahead the US or China. The worst that could come from that is slightly worse arms race and lots of middle power money wasted)
5
My actual claim was more modest: that their actions will be much more diverse/random than the OP suggests.
2
Can you be more specific about what you mean with secure verification mechanisms and how you would expect them to work in practice?
0
Do you agree with this take?
3
Yes, and as a result (as I stated in the final paragraph) I think it would probably be good to wake up middle powers to ASI.
Carl Shulman is working for Leopold Aschenbrenner's "Situational Awareness" hedge fund as the Director of Research. https://whalewisdom.com/filer/situational-awareness-lp
People seem to be reacting to this as though it is bad news. Why? I'd guess the net harm caused by these investments is negligible and this seems like a reasonable earning to give strategy.
Leopold himself also IMO seems to me like a kind of low-integrity dude and Shulman lending his skills and credibility to empowering him seems pretty bad for the world (I don't have this take confidently, but that's where a lot of my negative reaction came from).
7
What gives you the impression of low integrity?
Situational awareness did seem like it was basically trying to stoke a race, seemed to me like it was incompatible with other things he had told me and I had heard about his beliefs from others, and then he did go on and leverage that thing of all things into an investment fund which does seem like it would straightforwardly hasten the end. Like, my honest guess is that he did write Situational Awareness largely to become more powerful in the world, not to help it orient, and turning it into a hedge fund was a bunch of evidence in that direction.
Also some other interactions I've had with him where he made a bunch of social slap-down motions towards people taking AGI or AGI-risk seriously in ways that seemed very power-play optimized.
Again, none of this is a confident take.
I also had a negative reaction to the race-stoking and so forth, but also, I feel like you might be judging him too harshly from that evidence? Consider for example that Leopold, like me, was faced with a choice between signing the NDA and getting a huge amount of money, and like me, he chose the freedom to speak. A lot of people give me a lot of credit for that and I think they should give Leopold a similar amount of credit.
2[comment deleted]
The fund manages 2 billion dollars, and (from the linked webpage on their holdings) puts the money into chipmakers and other AI/tech companies. The money will be used to fund development of AI hardware and probably software, leading to growth in capabilities.
If you're going to argue that 2 billion AUM is too small an amount to have an impact on the cash flows of these companies and make developing AI easier, I think you would be incorrect (even openai and anthropic are only raising single digit billions at the moment).
You might argue that other people would invest similar amounts anyways, so its better for the "people in the know" to do it and "earn to give". I think that accelerating capabilities buildouts to use your cut of the profits to fund safety research is a bit like an arsonist donating to the fire station. I will also note that "if I don't do it, they'll just find somebody else" is a generic excuse built on the notion of a perfectly efficient market. In fact, this kind of reasoning allows you to do just about anything with an arbitrarily large negative impact for personal gain, so long as someone else exists who might do it if you don't.
My argument wouldn't start from "it's fully negligible". (Though I do think it's pretty negligible insofar as they're investing in big hardware & energy companies, which is most of what's visible from their public filings. Though private companies wouldn't be visible on their public filings.) Rather, it would be a quantitative argument that the value from donation opportunities is substantially larger than the harms from investing.
One intuition pump that I find helpful here: Would I think it'd be a highly cost-effective donation opportunity to donate [however much $ Carl Shulman is making] to reduce investment in AI by [however much $ Carl Shulman is counterfactually causing]? Intuitively, that seems way less cost-effective than normal, marginal donation opportunities in AI safety.
You say "I think that accelerating capabilities buildouts to use your cut of the profits to fund safety research is a bit like an arsonist donating to the fire station". I could say it's more analogous to "someone who wants to increase fire safety invests in the fireworks industry to get excess returns that they can donate to the fire station, which they estimate will reduce far more fire than their f...
2
I've left a comment under Schulman's comment that maybe explains slightly more.
I will also note that "if I don't do it, they'll just find somebody else" is a generic excuse built on the notion of a perfectly efficient market.
The existence of the Situational Awareness Fund is specifically predicated on the assumption that markets are not efficient, and if they don't invest in AI then AI will be under-invested.
(I don't have a strong position on whether that assumption is correct, but the people running the fund ought to believe it.)
4
Further discussion by Carl is here.
4
I don't have a strong opinion about how good or bad this is.
But it seems like potentially additional evidence over how difficult it is to predict/understand people's motivations/intentions/susceptibility to value drift, even with decades of track record, and thus how counterfactually-low the bar is for AIs to be more transparent to their overseers than human employees/colleagues.
4
I am not too surprised by this, but I wonder if he still stands by what he said in the interview with Dwarkesh:
[...]
To be clear, I have for many years said to various people that their investing in AI made sense to me, including (certain) AI labs (in certain times and conditions). I refrained from doing so at the time because it might create conflicts that could interfere with some of my particular advising and policy work at the time, not because I thought no one should do so.
I think a lot of rationalists accepted these Molochian offers ("build the Torment Nexus before others do it", "invest in the Torment Nexus and spend the proceeds on Torment Nexus safety") and the net result is simply that the Nexus is getting built earlier, with most safety work ending up as enabling capabilities or safetywashing. The rewards promised by Moloch have a way of receding into the future as the arms race expands, while the harms are already here and growing.
Consider the investments in AI by people like Jaan. It's possible for them to increase funding for the things they think are most helpful by sizable proportions while increasing capital for AI by <1%: there are now trillions of dollars of market cap in AI securities (so 1% of that is tens of billions of dollars), and returns have been very high. You can take a fatalist stance that nothing can be done to help with resources, but if there are worthwhile things to do then it's very plausible that for such people it works out.
If you're going to say that e.g. export controls on AI chips and fabrication equipment, non-lab AIS research (e.g. Redwood), the CAIS extinction risk letter, and similar have meaningful expected value, or are concerned about the funding limits for such activity now,
I don't think any of these orgs are funding constrained, so I am kind of confused what the point of this is. It seems like without these investments all of these projects have little problem attracting funding, and the argument would need to be that we could find $10B+ of similarly good opportunities, which seems unlikely.
More broadly, it's possible to increase funding for those things by 100%+ while increasing capital for AI by <1%
I think it's not that hard to end up with BOTECs where the people who have already made these investments ended up causing more harm than good (correlated with them having made the investments).
In-general, none of this area is funding constrained approximately at all, or will very soon stop being so when $30B+ of Anthropic equity starts getting distributed. The funding decisions are largely downstream of political and reputational constraints, not aggregate availability of funding. A ...
All good points and I wanted to reply with some of them, so thanks. But there's also another point where I might disagree more with LW folks (including you and Carl and maybe even Wei): I no longer believe that technological whoopsie is the main risk. I think we have enough geniuses working on the thing that technological whoopsie probably won't happen. The main risk to me now is that AI gets pretty well aligned to money and power, and then money and power throws most humans by the wayside. I've mentioned it many times, the cleanest formulation is probably in this book review.
In that light, Redwood and others are just making better tools for money and power, to help align AI to their ends. Export controls are a tool of international conflict: if they happen, they happen as part of a package of measures which basically intensify the arms race. And even the CAIS letter is now looking to me like a bit of PR move, where Altman and others got to say they cared about risk and then went on increasing risk anyway. Not to mention the other things done by safety-conscious money, like starting OpenAI and Anthropic. You could say the biggest things that safety-conscious money achieved were basically enabling stuff that money and power wanted. So the endgame wouldn't be some kind of war between humans and AI: it would be AI simply joining up with money and power, and cutting out everyone else.
6
My response to this is similar to my response to Will MacAskill's suggestion to work on reducing the risk of AI-enabled coups: I'm pretty worried about this, but equally or even more worried about broader alignment "success", e.g., if AI was aligned to humanity as a whole, or everyone got their own AI representative, or something like that, because I generally don't trust humans to have (or end up with) good values by default. See these posts for some reasons why.
However I think it's pretty plausible that there's a technological solution to this (although we're not on track for achieving it), for example if it's actually wrong (from their own perspective) for the rich and power to treat everyone else badly, and AIs are designed to be philosophically competent and as a result help their users realize and fix their moral/philosophical mistakes.
Since you don't seem to think there's a technological solution to this, what do you envision as a good outcome?
4
It's complicated.
First, I think there's enough overlap between different reasoning skills that we should expect a smarter than human AI to be really good at most such skills, including philosophy. So this part is ok.
Second, I don't think philosophical skill alone is enough to figure out the right morality. For example, let's say you like apples but don't like oranges. Then when choosing between philosophical theory X, which says apples are better than oranges, and theory Y which says the opposite, you'll use the pre-theoretic intuition as a tiebreak. And I think when humans do moral philosophy, they often do exactly that: they fall back on pre-theoretic intuitions to check what's palatable and what isn't. It's a tree with many choices, and even big questions like consequentialism vs deontology vs virtue ethics may ultimately depend on many such case by case intuitions, not just pure philosophical reasoning.
Third, I think morality is part of culture. It didn't come from the nature of an individual person: kids are often cruel. It came from constraints that people put on each other, and cultural generalization of these constraints. "Don't kill." When someone gets powerful enough to ignore these constraints, the default outcome we should expect is amorality. "Power corrupts." Though of course there can be exceptions.
Fourth - and this is the payoff - I think the only good outcome is if the first smarter than human AIs start out with "good" culture, derived from what human societies think is good. Not aligned to an individual human operator, and certainly not to money and power. Then AIs can take it from there and we'll be ok. But I don't know how to achieve that. It might require human organizational forms that are not money- or power-seeking. I wrote a question about it sometime ago, but didn't get any answers.
6
Supposing this is true, how would you elicit this capability? In other words, how would you train the AI (e.g., what reward signal would you use) to tell humans when they (the humans) are making philosophical mistakes, and present humans with only true philosophical arguments/explanations? (As opposed to presenting the most convincing arguments, which may exploit flaws in human's psychology or reasoning, or telling the humans what they most want to hear or what's most likely to get a thumb up or high rating.)
[...]
"What human societies think is good" is filled with pretty crazy stuff, like wokeness imposing its skewed moral priorities and empirical beliefs on everyone via "cancel culture", and religions condemning "sinners" and nonbelievers to eternal torture. Morality is Scary talks about why this is generally the case, why we shouldn't expect "what human societies think is good" to actually be good.
Also, wouldn't "power corrupts" apply to humanity as a whole if we manage to solve technical alignment and not align ASI to the current "power and money"? Won't humanity be the "power and money" post-Singularity, e.g., each human or group of humans will have enough resources to create countless minds and simulations to lord over?
I'm hoping that both problems ("morality is scary" and "power corrupts") are philosophical errors that have technical solutions in AI design (i.e., AIs can be designed to help humans avoid/fix these errors), but this is highly neglected and seems unlikely to happen by default.
6
I'm not very confident, but will try to explain where the intuition comes from.
Basically I think the idea of "good" might be completely cultural. As in, if you extrapolate what an individual wants, that's basically a world optimized for that individual's selfishness; then there is what groups can agree on by rational negotiation, which is a kind of group selfishness, cutting out everyone who's weak enough (so for example factory farming would be ok because animals can't fight back); and on top of that there is the abstract idea of "good", saying you shouldn't hurt the weak at all. And that idea is not necessitated by rational negotiation. It's just a cultural artifact that we ended up with, I'm not sure how.
So if you ask AI to optimize for what individuals want, and go through negotiations and such, there seems a high chance that the resulting world won't contain "good" at all, only what I called group selfishness. Even if we start with individuals who strongly believe in the cultural idea of good, they can still get corrupted by power. The only way to get "good" is to point AI at the cultural idea to begin with.
You are of course right that culture also contains a lot of nasty stuff. The only way to get something good out of it is with a bunch of extrapolation, philosophy, and yeah I don't know what else. It's not reliable. But the starting materials for "good" are contained only there. Hope that makes sense.
Also to your other question: how to train philosophical ability? I think yeah, there isn't any reliable reward signal, just as there wasn't for us. The way our philosophical ability seems to work is by learning heuristics and ways of reasoning from fields where verification is possible (like math, or everyday common sense) and applying them to philosophy. And it's very unreliable of course. So for AIs maybe this kind of carry-over to philosophy is also the best we can hope for.
4
Thanks for this explanation, it definitely makes your position more understandable.
[...]
I can think of 2 ways:
1. It ended up there the same way that all the "nasty stuff" ended up in our culture, more or less randomly, e.g. through the kind of "morality as status game" talked about in Will Storr's book, which I quote in Morality is Scary.
2. It ended up there via philosophical progress, because it's actually correct in some sense.
If it's 1, then I'm not sure why extrapolation and philosophy will pick out the "good" and leave the "nasty stuff". It's not clear to me why aligning to culture would be better than aligning to individuals in that case.
If it's 2, then we don't need to align with culture either - AIs aligned with individuals can rederive the "good" with competent philosophy.
Does this make sense?
[...]
It seems clear that technical design or training choices can make a difference (but nobody is working on this). Consider the analogy with the US vs Chinese education system, where the US system seems to produce a lot more competence and/or interest in philosophy (relative to STEM) compared to the Chinese system. And comparing humans with LLMs, it sure seems like they're on track to exceeding (top) human level in STEM while being significantly less competent in philosophy.
2
Things I'm pretty sure about: that your possibility 1 is much more likely than 2. That extrapolation is more like resolving internal conflicts in a set of values, not making them change direction altogether. That the only way for a set of values to extrapolate to "good" is if its starting percentage of "good" is high enough to win out.
Things I believe, but with less confidence: that individual desires will often extrapolate to a pretty nasty kind of selfishness ("power corrupts"). That starting from culture also has lots of dangers (like the wokeness or religion that you're worried about), but a lot of it has been selected in a good direction for a long time, precisely to counteract the selfishness of individuals. So the starting percentage of good in culture might be higher.
2
I think it's important to frame values around scopes of optimization, not just coalitions of actors. An individual then wants first of all their own life (rather than the world) optimized for that individual's preferences. If they don't live alone, their home might have multiple stakeholders, and so their home would be subject to group optimization, and so on.
At each step, optimization is primarily about the shared scope, and excludes most details of the smaller scopes under narrower control enclosed within. Culture and "good" would then have a lot to say about the negotiations on how group optimization takes place, but also about how the smaller enclosed scopes within the group's purview are to be relatively left alone to their own optimization, under different preferences of corresponding smaller groups or individuals.
It may be good to not cut out everyone who's too weak to prevent that, as the cultural content defining the rules for doing so is also preference that wants to preserve itself, whatever its origin (such as being culturally developed later than evolution-given psychological drives). And individuals are in particular carriers of culture that's only relevant for group optimization, so group optimization culture would coordinate them into agreement on some things. I think selfishness is salient as a distinct thing only because the cultural content that concerns group optimization needs actual groups to get activated in practice, and without that activation applying selfishness way out of its scope is about as appropriate as stirring soup with a microscope.
2[comment deleted]
2
I think this is not obviously qualitatively different from technical oopsie, and sufficiently strong technical success should be able to prevent this. But that's partially because I think "money and power" is effectively an older, slower AI made of allocating over other minds, and both kinds of AI need to be strongly aligned to flourishing of humans. Fortunately humans with money and power generally want to use it to have nice lives, so on an individual level there should be incentive compatibility if we can find a solution which is general between them. I'm slightly hopeful Richard Ngo's work might weigh on this, for example.
3
Do you have any advice for people financially exposed to capabilities progress on how not to do dumb stuff, not be targeted by political pressure, etc.?
What exactly I would advise doing depends on the scale of the money. I am assuming we are talking here about a few million dollars of exposure, not $50M+:
- Diversify enough away from AI that you really genuinely know you will be personally fine even if all the AI stuff goes to zero (e.g. probably something like $2M-$3M)
- Cultivate at least a few people you talk to about big career decisions who seem multiple steps removed from similarly strong incentives
- Make public statements to the effect of being opposed to AI advancing rapidly. This has a few positive effects, I think:
- It makes it easier for you to talk about this later when you might end up in a more pressured position (e.g. when you might end up in a position to take actions that might more seriously affect overall AI progress via e.g. work on regulation)
- It reduces the degree that you end up in relationships that seem based on false premises because e.g. people assumed you would be in favor of this given your exposure (if you e.g. hold substantial stock in a company)
- (To be clear, holding public positions like this isn't everyone's jam, and many people prefer holding no positions strongly in public)
- See whether you can use yo
9
Maybe it's worth mentioning here that Carl's p(doom) is only ~20% [1], compared to my ~80%. (I can't find a figure for @cousin_it, but I'm guessing it's closer to mine than Carl's. BTW every AI I asked started hallucinating or found a quote online from someone else and told me he said it.) It seems intuitive to me that at a higher p(doom), the voices in one's moral parliament saying "let's not touch this" become a lot louder.
1. ^
"Depending on the day I might say one in four or one in five that we get an AI takeover that seizes control of the future, makes a much worse world than we otherwise would have had and with a big chance that we're all killed in the process."
I notice that this is only talking about "AI takeover" whereas my "doom" includes a bunch of other scenarios, but if Carl is significantly worried about other scenarios, he perhaps would have given a higher overall p(doom) in this interview or elsewhere.
6
This BOTEC attitude makes sense when you view the creation of AI technology and ai safety as a pure result of capital investment. The economic view of AI abstracts the development process to a black box which takes in investments as input and produces hardware/software out the other end. However, AI is still currently mostly driven by people. A large part of enabling AI development comes from a culture around AI, including hype, common knowledge, and social permissibility to pursue AI development as a startup/career pathway.
In that regard "AI safety people" starting AI companies, writing hype pieces that encourage natsec coded AI races, and investing in AI tech contribute far more than mere dollars. It creates a situation where AI safety as a movement becomes hopelessly confused about what someone "concerned about AI safety" should do with their life and career. The result is that someone "concerned about AI safety" can find groups and justifications for everything from protesting outside OpenAI to working as the CEO of OpenAI. I think this is intrinsically linked to the fundamental confusion behind the origins of the movement.
In short, whatever material and economic leverage investment plays produce may not be worth the dilution of the ideas and culture of AI safety as a whole. Is AI safety just going to become the next "ESG", a thin flag of respectability draped over capabilities companies/racing companies?
5
I feel like it's overestimating how good this is because post-hoc investments are so easy compared to forward-looking ones? My guess is that there was a market failure because investors were not informed about AI enough, but the market failure was smaller than 40x in 4 years. Even given AGI views, it's hard to know where to invest. I have heard stories of AGI-bullish people making terrible predictions about which publicly traded companies had the most growth in the last 4 years.
I don't have a strong take on what the reasonable expected gains would have been, they could have been high enough that the argument still mostly works.
7
I agree mostly, but I would characterize it as a small portion of rationalists accepting the offers, with part of Moloch’s prize being disproportionate amplification of their voices.
@Carl_Shulman what do you intend to donate to and on what timescale?
(Personally, I am sympathetic to weighing the upside of additional resources in one’s considerations. Though I think it would be worthwhile for you to explain what kinds of things you plan to donate to & when you expect those donations to be made. With ofc the caveat that things could change etc etc.)
I also think there is more virtue in having a clear plan and/or a clear set of what gaps you see in the current funding landscape than a nebulous sense of “I will acquire resources and then hopefully figure out something good to do with them”.
I think it's extremely unfortunate that some people and institutions concerned with AI safety didn't do more of that earlier, such that they could now have more than an order of magnitude more resources and could do and have done some important things with them.
I don't really get this argument. Doesn't the x-risk community have something like 80% of its net-worth in AI capability companies right now? Like, people have a huge amount of equity in Anthropic and OpenAI, which have had much higher returns than any of these other assets. I agree one could have done a bit more, but I don't see an argument here for much higher aggregate returns, definitely not an order of magnitude.
Like, my guess is we are talking about $50B+ in Anthropic equity. What is the possible decision someone could have made such that we are now talking about $500B? I mean, it's not impossible, but I do also think that money seems already at this point to be a very unlikely constraint on the kind of person who could have followed this advice, given the already existing extremely heavy investment in frontier capability companies.
4
I read the claim as saying that "some people and institutions concerned with AI safety" could have had more than order of magnitude more resources than they actually have, by investing. Not necessarily a claim about the aggregate where you combine their wealth with that of AI-safety sympathetic AI company founders and early employees. (Though maybe Carl believes the claim about the aggregate as well.)
Over the last 10 years, NVDA has had ~100x returns after dividing out the average S&P 500 gains. So more than an OOM of gains were possible just investing in public companies.
(Also, I think it's slightly confusing to point to the fact that the current portfolio is so heavily weighted towards AI capability companies. That's because the AI investments grew so much faster than everything else. It's consistent with a small fraction of capital being in AI-related stuff 4-10y ago — which is the relevant question for determining how much larger gains were possible.)
6
That would make more sense! I of course agree there are some people that could have 10xd their money, though it seems like that will always be the case even when it's obviously a bad idea to increase exposure to an asset class (e.g. the same is true for crypto, and I don't think we should have invested more in crypto). The interesting question seems to me to be the question of whether returns were missed out on in-aggregate (as well as what the indirect effects of the exposure have been).
[...]
If you aggregate human capital (i.e. labor) and financial capital, then at least 4 years ago a very substantial fraction of "our" assets were already going long AI capability companies (by working at those companies, or founding them). It seems clear to me you should aggregate human and financial capital, so I don't think the current capital allocation is just the result of that capital growing much faster, there had always been a quite serious investment.
I agree that there was a better argument for investing in the space 10 years ago, though calling the market was also substantially harder that far back, even with an AI-focused worldview. I also think the externalities would have been less bad at the time, though I am not that confident about that
4
I'm ambivalent on how good/bad it is to, say, manage AI investments for a generic company pension plan. I think it's more straightforwardly bad to manage AI investments for someone whose goal is to accelerate ASI development and downplay concerns about alignment risk.
I don't know what Aschenbrenner or his allies will do with their wealth but I wouldn't be surprised if they used it for things like lobbying against AI safety regulations, in which case it's not clear that an AI safety donor would be able to do enough to cancel out those harms. And based on what I've seen from his public behavior, I strongly suspect that he'd be willing to lie about this to AI safety people to get them to invest/work with him.
3
I just want to be annoying and drop a "hey, don't judge a book by it's cover!"
There might be deeper modelling concerns that we've got no clue about, it's weird and is a negative signal but it is often very hard to see second order consequences and similar from a distance!
(I literally know nothing about this situation but I just want to point it out)
I don't know the situation, but over the past couple years I've updated significantly in the direction of "if an AI safety person is doing something that looks like it's increasing x-risk, it's not because there's some secret reason why it's good actually; it's because they're increasing x-risk." Without knowing the details, my prior is a 75% chance that that's what's going on here.
6
Why do you think this hedge fund is increasing AI risk?
Mostly indirect evidence:
- The "Situational Awareness" essays downplayed AI risk and encouraged an arms race.
- This is evidence that the investors in Aschenbrenner's fund will probably also be the sorts of people who don't care about AI risk.
- It also personally makes Aschenbrenner wealthier, which gives him more power to do more things like downplaying AI risk and encouraging an arms race.
- Investing in AI companies gives them more capital with which to build dangerous AI. I'm not super concerned about this for public companies at smaller scales, but I think it's a bigger deal for private companies, where funding matters more; I don't know if the Situational Awareness fund invests in private companies. The fund is also pretty big so it may be meaningfully accelerating timelines via investing in public companies; pretty hard to say how big that effect is.
6
This all just seems extremely weak to me.
3
Was this not publicly available until now?
5
I first saw it in the this aug 10 WSJ article: https://archive.ph/84l4H
I think it might have been less public knowledge for like a year
For people who like Yudkowsky's fiction, I recommend reading his story Kindness to Kin. I think it's my favorite of his stories. It's both genuinely moving, and an interesting thought experiment about evolutionary selection pressures and kindness. See also this related tweet thread.
5
I like the story, but (spoilers):
2
I suspect "friendships" form within the psyche, and are part of how we humans (and various other minds, though maybe not all minds, I'm not sure) cohere into relatively unified beings (after being a chaos of many ~subagents in infancy). Insofar as that's true of a given mind, it may make it a bit easier for kindness to form between it and outside minds, as it will already know some parts of how friendships can be done.
2
This comment confuses me:
3
Spoiler block was not supposed to be empty, sorry. It's fixed now. I was using the Markdown spoiler formatting and there was some kind of bug with it I think, I reported it to the LW admins last night. (also fwiw I took the opportunity now to expand on my original spoilered comment more)
5
Nitter version of that thread: https://nitter.net/ESYudkowsky/status/1660623336567889920
I'm curious about the following line (especially in relation to a recent post, https://www.lesswrong.com/posts/vqfT5QCWa66gsfziB/a-phylogeny-of-agents)
[...]
Why are scaled-up ant colonies unlikely to be nice?
7
Because in this model, kindness to kin evolved because we share a significant fraction of our genes with our close kin (1/2 for children, siblings, and parents; 1/4 for grandchildren, grandparents, uncles/aunts/nieces/nephews; etc.). If there's instead an ant queen, then all ants in this particular colony are siblings, but genetic relatedness to other hives is very low. Then you don't get kindness to kin but something else, like kindness to hive or self-sacrifice for hive.
EDIT: I think the above holds, but the justification in EY's Twitter thread is different, namely that "Human bands and tribes are the right size for us to need to trade favors with people we're not related to" but scaled-up ant colonies are not.
Zachary Robinson and Kanika Bahl are no longer on the Anthropic LTBT. Mariano-Florentino (Tino) Cuéllar has been added. The Anthropic Company page is out of date, but as far as I can tell the LTBT is: Neil Buddy Shah (chair), Richard Fontaine, and Cuéllar.
[NOW CLOSED]
MIRI Technical Governance Team is hiring, please apply and work with us!
We are looking to hire for the following roles:
- Technical Governance Researcher (2-4 hires)
- Writer (1 hire)
The roles are located in Berkeley, and we are ideally looking to hire people who can start ASAP. The team is currently Lisa Thiergart (team lead) and myself.
We will research and design technical aspects of regulation and policy that could lead to safer AI, focusing on methods that won’t break as we move towards smarter-than-human AI. We want to design policy that allows us to safely and objectively assess the risks from powerful AI, build consensus around the risks we face, and put in place measures to prevent catastrophic outcomes.
The team will likely work on:
- Limitations of current proposals such as RSPs
- Inputs into regulations, requests for comment by policy bodies (ex. NIST/US AISI, EU, UN)
- Researching and designing alternative Safety Standards, or amendments to existing proposals
- Communicating with and consulting for policymakers and governance organizations
If you have any questions, feel free to contact me on LW or at peter@intelligence.org
I would strongly suggest considering hires who would be based in DC (or who would hop between DC and Berkeley). In my experience, being in DC (or being familiar with DC & having a network in DC) is extremely valuable for being able to shape policy discussions, know what kinds of research questions matter, know what kinds of things policymakers are paying attention to, etc.
I would go as far as to say something like "in 6 months, if MIRI's technical governance team has not achieved very much, one of my top 3 reasons for why MIRI failed would be that they did not engage enough with DC people//US policy people. As a result, they focused too much on questions that Bay Area people are interested in and too little on questions that Congressional offices and executive branch agencies are interested in. And relatedly, they didn't get enough feedback from DC people. And relatedly, even the good ideas they had didn't get communicated frequently enough or fast enough to relevant policymakers. And relatedly... etc etc."
I do understand this trades off against everyone being in the same place, which is a significant factor, but I think the cost is worth it.
I think the Claude Sonnet Golden Gate Bridge feature is not crispy aligned with the human concept of "Golden Gate Bridge".
It brings up the San Fransisco fog far more than it would if it was just the bridge itself. I think it's probably more like Golden Gate Bridge + SF fog + a bunch of other things (some SF related, some not).
This isn't particularly surprising, given these are related ideas (both SF things), and the features were trained in an unsupervised way. But still seems kinda important that the "natural" features that SAEs find are not like exactly intuitively natural human concepts.
- It might be interesting to look at how much the SAE training data actually mentions the fog and the Golden Gate Bridge together
- I don't really think that this is super important for "fragility of value"-type concerns, but probably is important for people who think we will easily be able to understand the features/internals of LLMs
Almost all of my Golden Gate Claude chats mention the fog. Here is a not particularly cherrypicked example:

I don't really think that this is super important for "fragility of value"-type concerns, but probably is important for people who think we will easily be able to understand the features/internals of LLMs
I'm not surprised if the features aren't 100% clean, because this is after all a preliminary research prototype of a small approximation of a medium-sized version of a still sub-AGI LLM.
But I am a little more concerned that this is the first I've seen anyone notice that the cherrypicked, single, chosen example of what is apparently a straightforward, familiar, concrete (literally) concept, which people have been playing with interactively for days, is clearly dirty and not actually a 'Golden Gate Bridge feature'. This suggests it is not hard to fool a lot of people with an 'interpretable feature' which is still quite far from the human concept. And if you believe that it's not super important for fragility-of-value because it'd have feasible fixes if noticed, how do you know anyone will notice?
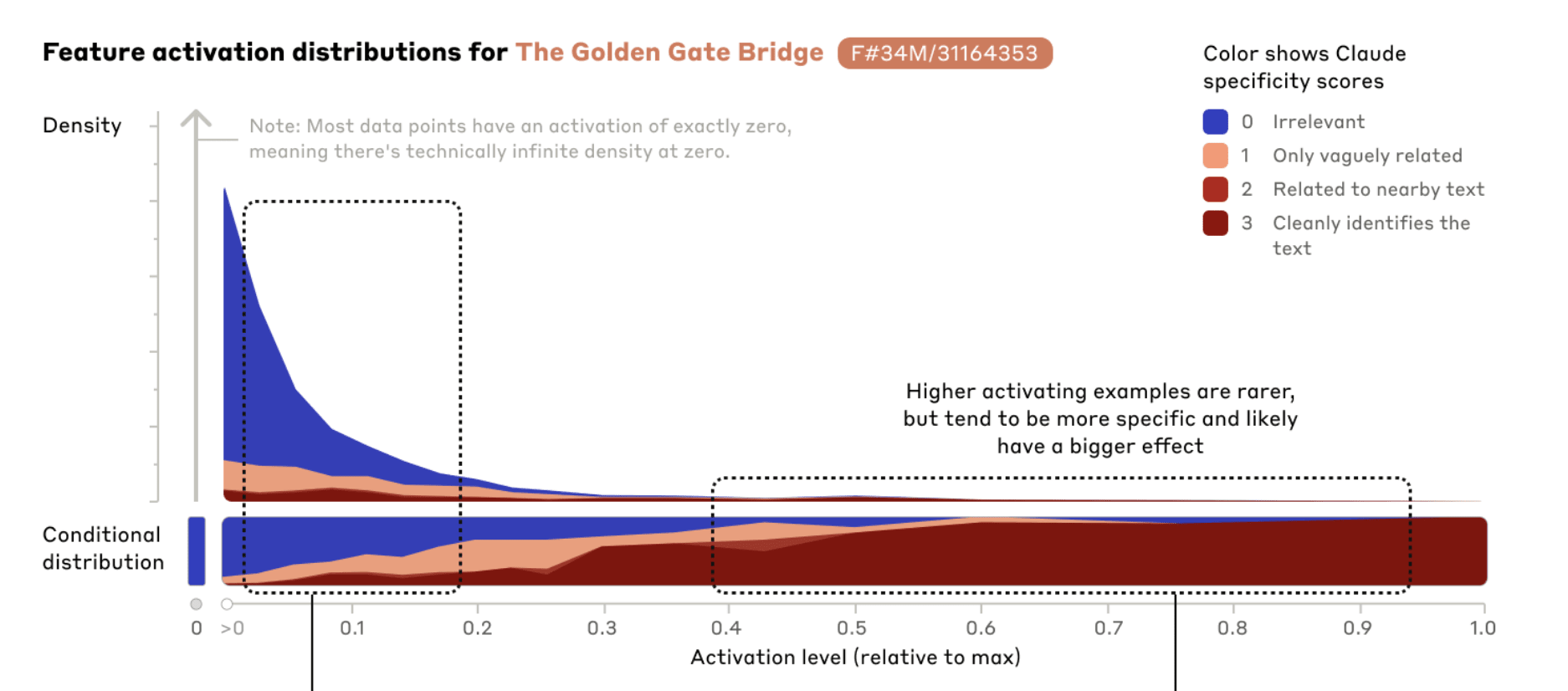
I'm not surprised if the features aren't 100% clean, because this is after all a preliminary research prototype of a small approximation of a medium-sized version of a still sub-AGI LLM.
It's more like a limitation of the paradigm, imo. If the "most golden gate" direction in activation-space and the "most SF fog" direction have high cosine similarity, there isn't a way to increase activation of one of them but not the other. And this isn't only a problem for outside interpreters - it's expensive for the AI's further layers to distinguish close-together vectors, so I'd expect the AI's further layers to do it as cheaply and unreliably as works on the training distribution, and not in some extra-robust way that generalizes to clamping features at 5x their observed maximum.
6
FWIW, I had noticed the same but had thought it was overly split (“Golden Gate Bridge, particularly its fog, colour and endpoints”) rather than dirty.
1
While I think you're right it's not cleanly "a Golden Bridge feature," I strongly suspect it may be activating a more specific feature vector and not a less specific feature.
It looks like this is somewhat of a measurement problem with SAE. We are measuring SAE activations via text or image inputs, but what's activated in generations seems to be "sensations associated with the Golden gate bridge."
While googling "Golden Gate Bridge" might return the Wikipedia page, whats the relative volume in a very broad training set between encyclopedic writing about the Golden Gate Bridge and experiential writing on social media or in books and poems about the bridge?
The model was trained to complete those too, and in theory should have developed successful features for doing so.
In the research examples one of the matched images is a perspective shot from physically being on the bridge, a text example is talking about the color of it, another is seeing it in the sunset.
But these are all the feature activations when acting in a classifier role. That's what SAE is exploring - give it a set of inputs and see what lights it up.
Yet in the generative role this vector maximized keeps coming up over and over in the model with content from a sensory standpoint.
Maybe generation based on functional vector manipulations will prove to be a more powerful interpretability technique than SAE probing passive activations alone?
In the above chat when that "golden gate vector" is magnified, it keeps talking about either the sensations of being the bridge as if its physical body with wind and waves hitting it or the sensations of being on the bridge. It even generates towards the end in reflecting on the knowledge of the activation about how the sensations are overwhelming. Not reflecting on the Platonic form of an abstract concept of the bridge, but about overwhelming physical sensations of the bridge's materialism.
I'll be curious to see more generative data and samples from this va
3
I had a weird one today; I asked it to write a program for me, and it wrote one about the Golden Gate Bridge, and when I asked it why, it used the Russian word for “program” instead of the English word “program”, despite the rest of the response being entirely in English.
1
Kind of interesting how this is introducing people to Sonnet quirks in general, because that's within my expectations for a Sonnet 'typo'/writing quirk. Do they just not get used as much as Opus or Haiku?
I spent one day writing up an AI 2027-style scenario about continual learning and misalignment. It's not meant as a forecast, but instead to gesture at misalignment failures we might encounter with continual learning.
Full post here: https://naiveconsequentialism.substack.com/p/a-continual-learning-misalignment
Wow, what is going on with AI safety
Status: wow-what-is-going-on, is-everyone-insane, blurting, hope-I-don’t-regret-this
Ok, so I have recently been feeling something like “Wow, what is going on? We don’t know if anything is going to work, and we are barreling towards the precipice. Where are the adults in the room?”
People seem way too ok with the fact that we are pursuing technical agendas that we don’t know will work and if they don’t it might all be over. People who are doing politics/strategy/coordination stuff also don’t seem freaked out that they will be the only thing that saves the world when/if the attempts at technical solutions don’t work.
And maybe technical people are ok doing technical stuff because they think that the politics people will be able to stop everything when we need to. And the politics people think that the technical people are making good progress on a solution.
And maybe this is the case, and things will turn out fine. But I sure am not confident of that.
And also, obviously, being in a freaked out state all the time is probably not actually that conducive to doing the work that needs to be done.
Technical stuff
For most technical approaches to the alignment...
4
this should be a top-level post
2
I don't know if it helps - I agree with basically all of this.
I am very concerned about breakthroughs in continual/online/autonomous learning because this is obviously a necessary capability for an AI to be superhuman. At the same time, I think that this might make a bunch of alignment problems more obvious, as these problems only really arise when the AI is able to learn new things. This might result in a wake up of some AI researchers at least.
Or, this could just be wishful thinking, and continual learning might allow an AI to autonomously improve without human intervention and then kill everyone.
7
My best guess is that to the extent these things can be even vaugely associated with task completion / reward hacking / etc, they’re going to be normalized pretty quickly and trained against like other visible misalignment. I think coding agents are an instructive example here.
I also worry we’re getting used to the current era of “the models aren’t really thinking strategically about hiding any of this in a capable way”.
IME “wake up AI researchers” feels a lot more like “okay what do these specific people care about, what would be convincing to them, what’s important enough to be worth showing rigorously so it legitimizes some threat model, etc”. In practice, “AI researchers who you’d hope are convinced that alignment is important” have a surprisingly wide range of somewhat idiosycratic views as to why they do / don’t find different things salient. I’m skeptical of any argument that “breakthrough X will truly be what ‘wakes up’ researchers”.
6
I'm not sure it might result in a wake up of AI Researchers.
See this thread yesterday between Chris Painter and Dean Ball:
[...]
3
See also this comment by Vladimir_Nesov + discussion from 4 days ago that starts with
[...]
2
I tried to elaborate on that intuition in A country of alien idiots in a datacenter: AI progress and public alarm.
When combined with increased deployment from increased deployment and job replacement, I think it will probably wake up the public more than AI researchers. And I think some researchers will just go along with public opinion by accident, since that's the path of least resistance.
I also agree that the alarm might not outweigh the increased rate of progress.
I also want to note that it doesn't take a breakthrough. Continuous learning already exists (fine-tuning and RAG designed for that purpose, and context engineering). These aren't good enough yet to make major waves or allow really long-term progress, but continued progress will steadily push them to new deployments. Slow steady progress tilts the balance toward the alarm being more beneficial. But maybe not enough.
I've seen a bunch of places where them people in the AI Optimism cluster dismiss arguments that use evolution as an analogy (for anything?) because they consider it debunked by Evolution provides no evidence for the sharp left turn. I think many people (including myself) think that piece didn't at all fully debunk the use of evolution arguments when discussing misalignment risk. A people have written what I think are good responses to that piece; many of the comments, especially this one, and some posts.
I don't really know what to do here. The arguments often look like:
A: "Here's an evolution analogy which I think backs up my claims."
B: "I think the evolution analogy has been debunked and I don't consider your argument to be valid."
A: "I disagree that the analogy has been debunked, and think evolutionary analogies are valid and useful".
The AI Optimists seem reasonably unwilling to rehash the evolution analogy argument, because they consider this settled (I hope I'm not being uncharitable here). I think this is often a reasonable move, like I'm not particularly interested in arguing about climate change or flat-earth because I do consider these settled. But I do think that the...
Is there a place that you think canonically sets forth the evolution analogy and why it concludes what it concludes in a single document? Like, a place that is legible and predictive, and with which you're satisfied as self-contained -- at least speaking for yourself, if not for others?
4
I would like to read such a piece.
Are evolution analogies really that much of a crux? It seems like the evidence from evolution can't get us that far in an absolute sense (though I could imagine evolution updating someone up to a moderate probability from a super low prior?), so we should be able to talk about more object level things regardless.
4
Yeah, I agree with this, we should be able to usually talk about object level things.
Although (as you note in your other comment) evolution is useful for thinking about inner optimizers, deceptive alignment etc. I think that thinking about "optimizers" (what things create optimizers? what will the optimizers do? etc) is pretty hard, and at least I think it's useful to be able to look at the one concrete case where some process created a generally competent optimizer
9
There are responses by Quintin Pope and Ryan Greenblatt that addressed their points, where Ryan Greenblatt pointed out that the argument used in support of autonomous learning is only distinguishable from supervised learning if there are data limitations, and we can tell an analogous story about supervised learning having a fast takeoff without data limitations, and Quintin Pope has massive comments that I can't really summarize, but one is a general purpose response to Zvi's post, and the other is adding context to the debate between Quintin Pope and Jan Kulevit on culture:
https://www.lesswrong.com/posts/hvz9qjWyv8cLX9JJR/evolution-provides-no-evidence-for-the-sharp-left-turn#hkqk6sFphuSHSHxE4
https://www.lesswrong.com/posts/Wr7N9ji36EvvvrqJK/response-to-quintin-pope-s-evolution-provides-no-evidence#PS84seDQqnxHnKy8i
https://www.lesswrong.com/posts/wCtegGaWxttfKZsfx/we-don-t-understand-what-happened-with-culture-enough#YaE9uD398AkKnWWjz
7
I think evolution clearly provides some evidence for things like inner optimizers, deceptive alignment, and "AI takeoff which starts with ML and human understandable engineering (e.g. scaffolding/prompting), but where different mechansms drive further growth prior to full human obsolescence"[1].
Personally, I'm quite sympathetic overall to Zvi's response post (which you link) and I had many of the same objections. I guess further litigation of this post (and the response in the comments) might be the way to go if you want to go down that road?
I overall tend to be pretty sympathetic to many objections to hard takeoff, "sharp left turn" concerns, and high probability on high levels of difficulty in safely navigating powerful AI. But, I still think that the "AI optimism" cluster is too dismissive of the case for despair and over confident in the case for hope. And a bunch of this argument has maybe already occured and doesn't seem to have gotten very far. (Though the exact objections I would say to the AI optimist people are moderately different than most of what I've seen so far.) So, I'd be pretty sympathetic to just not trying to target them as an audience.
Note that key audiences for doom arguments are often like "somewhat sympathetic people at AI labs" and "somewhat sympathetic researchers or grantmakers who already have some probability on the threat models you outline".
----------------------------------------
1. This is perhaps related to the "the sharp left turn", but I think the "sharp left turn" concept is poorly specified and might conflate a bunch of separate (though likely correlated) things. Thus, I prefer being more precise. ↩︎
Diffusion language models are probably bad for alignment and safety because there isn't a clear way to get a (faithful) Chain-of-Thought from them. Even if you can get them to generate something that looks like a CoT, compared with autoregressive LMs, there is even less reason to believe that this CoT is load-bearing and being used in a human-like way.
9
Agreed, but I'd guess this also hits capabilities unless you have some clever diffusion+reasoning approach which might recover guarantees which aren't wildly worse than normal CoT guarantees. (Unless you directly generate blocks reasoning in diffusion neuralese or similar.)
That said, I'm surprised it gets 23% on AIME given this, so I think they must have found some reasoning strategy which works well enough in practice. I wonder how it solves these problems.
4
Based on how it appears to solve math problems, I'd guess the guarantees you get based on looking at the CoT aren't wildly worse than what you get from autoregressive models, but probably somewhat more confusing to analyze and there might be a faster path to a particularly bad sort of neuralese. They show a video of it solving a math problem on the (desktop version of the) website, here is the final reasoning:
1
Why is this your intuition?
At the moment they seem to just make it imitate normal-ish CoT, which would presumably improve accuracy because the model has more token-positions/space/capacity to do things like check for self-consistency. You're still scaling up a compute dimension that the model can use for solving things, and you can still do normal RL things to it from that point.
It's just maybe worse in this case because the causality from reasoning chains -> the part of the response containing the answer is worse (it was bad before, but now it is horrible).
6
Wait, is it obvious that they are worse for faithfulness than the normal CoT approach?
Yes, the outputs are no longer produced sequentially over the sequence dimension, so we definitely don't have causal faithfulness along the sequence dimension.
But the outputs are produced sequentially along the time dimension. Plausibly by monitoring along that dimension we can get a window into the model's thinking.
What's more, I think you actually guarantee strict causal faithfulness in the diffusion case, unlike in the normal autoregressive paradigm. The reason being that in the normal paradigm there is a causal path from the inputs to the final outputs via the model's activations which doesn't go through the intermediate produced tokens. Whereas (if I understand correctly)[1] with diffusion models we throw away the model's activations after each timestep and just feed in the token sequence. So the only way for the model's thinking at earlier timesteps to affect later timesteps is via the token sequence. Any of the standard measures of chain-of-thought faithfulness that look like corrupting the intermediate reasoning steps and seeing whether the final answer changes will in fact say that the diffusion model is faithful (if applied along the time dimension).
Of course, this causal notion of faithfulness is necessary but not sufficient for what we really care about, since the intermediate outputs could still fail to make the model's thinking comprehensible to us. Is there strong reason to think the diffusion setup is worse in that sense?
ETA: maybe “diffusion models + paraphrasing the sequence after each timestep” is promising for getting both causal faithfulness and non-encoded reasoning? By default this probably breaks the diffusion model, but perhaps it could be made to work.
1. ^
Based on skimming this paper and assuming it's representative.
7
One reason why they might be worse is that chain of thought might make less sense for diffusion models than autoregressive models. If you look at an example of when different tokens are predicted in sampling (from the linked LLaDA paper), the answer tokens are predicted about halfway through instead of at the end:
This doesn't mean intermediate tokens can't help though, and very likely do. But this kind of structure might lend itself more toward getting to less legible reasoning faster than autoregressive models do.
3
It does seem likely that this is less legible by default, although we'd need to look at complete examples of how the sequence changes across time to get a clear sense. Unfortunately I can't see any in the paper.
2
There are examples for other diffusion models, see this comment.
3
On diffusion models + paraphrasing the sequence after each time step, I'm not sure this actually will break the diffusion model. With the current generation of diffusion models (at least the paper you cited, and Mercury, who knows about Gemini), they act basically like Masked LMs.
So they guess all of the masked tokens at each steps. (Some are re-masked to get the "diffusion process"). I bet there's a sampling strategy in there of sample, paraphrase, arbitrarily remask; rinse and repeat. But I'm not sure either.
2
But maybe interpretability will be easier?
With LLMs we're trying to extract high-level ideas/concepts that are implicit in the stream of tokens. It seems that with diffusion these high-level concepts should be something that arises first and thus might be easier to find?
(Disclaimer: I know next to nothing about diffusion models)
I think Sam Bowman's The Checklist: What Succeeding at AI Safety Will Involve is a pretty good list and I'm glad it exists. Unfortunately, I think its very unlikely that we will manage to complete this list, given my guess at timelines. It seems very likely that the large majority of important interventions on this list will go basically unsolved.
I might go through The Checklist at some point and give my guess at success for each of the items.
Is there a name of the thing where an event happens and that specific event is somewhat surprising, but overall you would have expected something in that reference class (or level of surprisingness) to happen?
E.g. It was pretty surprising that Ivanka Trump tweeted about Situational Awareness, but I sort of expect events this surprising to happen.
In a forecasting context, you could treat it as a kind of conservation of evidence: you are surprised, and would have been wrong, in the specific prediction of 'Ivanka Trump will not tweet about short AI timelines', but you would have been right, in a way which more than offsets your loss, for your implied broader prediction of 'in the next few years, some highly influential "normie" politicians will suddenly start talking in very scale-pilled ways'.
(Assuming that's what you meant. If you simply meant "some weird shit is gonna happen because it's a big world and weird shit is always happening, and while I'm surprised this specific weird thing happened involving Ivanka, I'm no more surprised in general than usual", then I agree with Jay that you are probably looking for Law of Large Numbers or maybe Littlewood's Law.)
4
The Improbability Principle sounds close. The summary seems to suggest law of large numbers is one part of the pop science book, but admittedly some of the other parts ("probability lever") seem less relevant
3
I've always referred to that as the Law of Large Numbers. If there are enough chances, everything possible will happen. For example, it would be very surprising if I won the lottery, but not surprising if someone I don't know won the lottery.
2
This is sort of what "calibration" means. Maybe you could say the event is "in-calibration".
1
I propose "token surprise" (as in type-token distinction). You expected this general type of thing but not that Ivanka would be one of the tokens instantiating it.
Model providers often don’t provide the full CoT, and instead provide a summary. I think this is a fine/good thing to do to help prevent distillation.
However, I think it would be good if the summaries provided a flag for when the CoT contained evaluation awareness or scheming (or other potentially concerning behavior).
I worry that currently the summaries don’t really provide this information, and this probably makes alignment and capability evaluations less valid.
Another reason labs don't provide CoT is that if users see them, the labs will be incentivized to optimize for them, and this will decrease their informativeness. A flag like you propose would have a similar effect.
6
Great point! This possibly makes my proposal a Bad idea. I would need to know more about how the labs respond to this kind of incentive to actually know.
1
Labs can provide this kind of information to evaluators instead, so that they don't have to optimize the CoT for the public.
3
OpenAI said that they don't want to train on the CoT. Given information about whether or not the CoT contains scheming to the user that presses buttons that affect training is training based on the CoT.
I think you can argue about the merits of "don't train based on CoT" but it seems to be one of the few free safety relevant decision where OpenAI had a safety idea and manages to actually execute it.
There's a funny and bad incentive where I want to upvote posts I haven't read to push them past the 30 Karma threshold and make them appear on the podcast feed.
My Favourite Slate Star Codex Posts
This is what I send people when they tell me they haven't read Slate Star Codex and don't know where to start.
Here are a bunch of lists of top ssc posts:
These lists are vaguely ranked in the order of how confident I am that they are good
https://guzey.com/favorite/slate-star-codex/
https://slatestarcodex.com/top-posts/
https://nothingismere.com/2015/09/12/library-of-scott-alexandria/
https://www.slatestarcodexabridged.com/ (if interested in psychology almost all the stuff here is good https://www.slatestarcodexabridged.com/Ps...