AlphaZero had autonomous learning—the longer you train, the better the model weights. Humans (and collaborative groups of humans) also have that—hence scientific progress. Like, you can lock a group of mathematicians in a building for a month with some paper and pens, and they will come out with more and better permanent knowledge of mathematics than when they entered. They didn’t need any new training data; we just “ran them” for longer, and they improved, discovering new things arbitrarily far beyond the training data, with no end in sight.
Today’s SOTA LLMs basically don't have an autonomous learning capability analogous to the above. Sure, people do all sorts of cool tricks with the context window, but people don’t know how to iteratively make the weights better and better without limit, in a way that’s analogous to to AlphaZero doing self-play or a human mathematicians doing math. Like, you can run more epochs on the same training data, but it rapidly plateaus. You can do the Huang et al. thing in an infinite loop, but I think it would rapidly go off the rails.
I don’t want to publicly speculate on what it would take for autonomous learning to take off in LLMs—maybe it’s “just more scale” + the Huang et al. thing, maybe it’s system-level changes, maybe LLMs are just not fit for purpose and we need to wait for the next paradigm. Whatever it is, IMO it’s a thing we’ll have eventually, and don’t have right now.
So I propose “somebody gets autonomous learning to work stably for LLMs (or similarly-general systems)” as a possible future fast-takeoff scenario.
In the context of the OP fast-takeoff scenarios, you wrote “Takeoff is less abrupt; Takeoff becomes easier to navigate; Capabilities gains are less general”. I’m not sure I buy any of those for my autonomous-learning fast-takeoff scenario. For example, AlphaZero was one of the first systems of that type that anyone got to work at all, and it rocketed to superhuman; that learning process happened over days, not years or decades; and presumably “getting autonomous learning to work stably” would be a cross-cutting advance not tied to any particular domain.
So I propose “somebody gets autonomous learning to work stably for LLMs (or similarly-general systems)” as a possible future fast-takeoff scenario.
Broadly speaking, autonomous learning doesn't seem particularly distinguished relative to supervised learning unless you have data limitations. For instance, suppose that data doesn't run out despite scaling and autonomous learning is moderately to considerably less efficient than supervised learning. Then, you'd just do supervised learning. Now, we can imagine fast takeoff scenarios where:
- Scaling runs into data limitations
- no one can think of any autonomous learning techniques for years
- finally someone finds an algorithms which works really well (prior to anyone finding an algorithm which only works ok)
- this results in a huge effective compute overhang
- people are able to effectively scaleup by 100x in short period and this is sufficient to achieve takeover capable AIs.
But this was just a standard fast takeoff argument. Here's a different version which doesn't refer to autonomous learning but is isomorphic:
- People scale up inefficient algos (like transformers)
- no one can think of any better techniques for years
- finally someone finds an algorithms which works really well (prior to anyone finding an algorithm which only works somewhat better than the current techniques)
- this results in a huge effective compute overhang
- people are able to effectively scaleup by 100x in short period and this is sufficient to achieve takeover capable AIs.
The reason you got fast takeoff in both cases is just sudden large algorithmic improvement. I don't see a particular reason to expect this in the autonomous learning case and I think the current evidence points to this being unlikely for capabilities in general. (This is of course a quantitative question: how big will leaps be exactly?)
Sure, people do all sorts of cool tricks with the context window, but people don’t know how to iteratively make the weights better and better without limit, in a way that’s analogous to to AlphaZero doing self-play or a human mathematicians doing math.
I don't think this is a key bottleneck. For instance, it wouldn't be too hard to set up LLMs such that they would improve at some types of mathematics without clear limits (just set them up in a theorem proving self play type setting much like the mathematicians). This improvement rate would be slower than the corresponding rate in humans (by a lot) and would probably be considerably slower than the improvement rate for high quality supervised data. Another minimal baseline is just doing some sort of noisy student setup on entirely model generated data (like here https://arxiv.org/abs/1911.04252).
Capabilities people have tons of ideas here, so if data is an actual limitation, I think they'll figure this out (as far as I know, there are already versions in use at scaling labs). No one has (publically) bothered to work hard on autonomous learning because getting a lot of tokens is way easier and the autonomous learning is probably just worse than working on data curation if you don't run out of data.
My guess is that achieving reasonably efficient things which have good scaling laws is 'just' a moderately large capabilities research project at OpenAI - nothing that special.
You probably take some sort of hit from autonomous learning instead of supervised, but it seems not too bad to make the hit <100x compute efficiency (I'm very unsure here). Naively I would have thought that getting within a factor of 5 or so should be pretty viable.
Perhaps you think there are autonomous learning style approaches which are considerably better than the efficiency on next token prediction?
Broadly speaking, autonomous learning doesn't seem particularly distinguished relative to supervised learning unless you have data limitations.
Suppose I ask you to spend a week trying to come up with a new good experiment to try in AI. I give you two options.
Option A: You need to spend the entire week reading AI literature. I choose what you read, and in what order, using a random number generator and selecting out of every AI paper / textbook ever written. While reading, you are forced to dwell for exactly one second—no more, no less—on each word of the text, before moving on to the next word.
Option B: You can spend your week however you want. Follow the threads that seem promising, sit and think for a while, go back and re-read passages that are confusing, etc.
It seems extremely obvious to me that you’d make more progress under Option B than Option A—like, massively, qualitatively more progress. Do you not share that intuition? (See also Section 1.1 here.)
(Note: this comment is rambly and repetitive, but I decided not to spend time cleaning it up)
It sounds like you believe something like: "There are autonomous learning style approaches which are considerably better than the efficiency on next token prediction."
And more broadly, you're making a claim like 'current learning efficiency is very low'.
I agree - brains imply that it's possible to learn vastly more efficiently than deep nets, and my guess would be that performance can be far, far better than brains.
Suppose we instantly went from 'current status quo' to 'AI systems learn like humans learn and with the same efficiency, but with vastly larger memories than humans (current LLMs seem to have vastly better memory at least for facts and technical minutia), and vastly longer lifespans than humans (if you think token corresponds to 1 second, then 10 trillion tokens is 317098 years!)'. Then, we certainly get an extremely hard FOOM if anyone runs this training!
But this hypothetical just isn't what I expect.
Currently, SOTA deep learning is deeply inefficient in a bunch of different ways. Failing to do open ended autonomous learning to advance a field and then distilling these insights down to allow for future progress is probably one such failure, but I don't think it seem particularly special. Nor do I see a particular reason to expect that advances in open ended flexible autonomous learning will be considerably more jumpy than advances in other domains.
Right now, both supervised next token prediction and fully flexible autonomous learning are far less efficient than theoretical limits and worse than brains. But currently next token prediction is more efficient than fully flexible autonomous learning (as the main way to train your AI, next token prediction + some other stuff is often used).
Suppose I ask you to spend a week trying to come up with a new good experiment to try in AI. I give you two options.
In this hypothetical, I obviously would pick option B.
But suppose instead that we asked "How would you try to get current AIs (without technical advances) to most efficiently come up with new good experiements to try?"
Then, my guess is that most of the flops go toward next token prediction or a similar objective on a huge corpus of data.
You'd then do some RL(HF) and/or amplification to try and improve further, but this would be a small fraction of overall training.
As AIs get smarter, clever techniques to improve their capabilities futher via 'self improvement' will continue to work better and better, but I don't think this clearly will end up being where you spend most of the flops (it's certainly possible, but I don't see a particular reason to expect this - it could go either way).
I agree that 'RL on thoughts' might prove important, but we already have shitty versions today. Current SOTA is probably like 'process based feedback' + 'some outcomes' + 'amplification' + 'etc'. Noteably this is how humans do things: we reflect on which cognitive strategies and thoughts were good and then try to do more of that. 'thoughts' isn't really doing that much work here - this is just standard stuff. I expect continued progress on these techniques and that techiques will work better and better for smarter models. But I don't expect massive sharp left turn advancements for the reasons given above.
Just to add to your thinking: consider also your hypothetical "experiment A vs experiment B". Suppose the AI tasked with the decision is both more capable than the best humans, but by a plausible margin (it's only 50 percent better) and can make the decision in 1 hour. (At 10 tokens a second it deliberates for a while, using tools and so on).
But the experiment is an AI training run and results won't be available for 3 weeks.
So the actual performance comparison is the human took one week and had a 50 percent pSuccess, and the AI took 1 hour and had a 75 percent pSuccess.
So your success per day is 75/(21 days) and for the human it's 50/(28 days). Or in real world terms, the AI is 2 times as effective.
In this example it is an enormous amount smarter, completing 40-80 hours of work in 1 hour and better than the best human experts by a 50 percent margin. Probably the amount of compute required to accomplish this (and the amount of electricity and patterned silicon) is also large.
Yet in real world terms it is "only" twice as good. I suspect this generalizes a lot of places, where AGI is a large advance but it won't be enough to foom due to the real world gain being much smaller.
You’re thinking about inference, and I’m thinking about learning. When I spend my week trying to come up with the project, I’m permanently smarter at the end of the week than I was at the beginning. It’s a weights-versus-context-window thing. I think weight-learning can do things that context-window-“learning” can’t. In my mind, this belief is vaguely related to my belief that there is no possible combination of sensory inputs that will give a human a deep understanding of chemistry from scratch in 10 minutes. (And having lots of clones of that human working together doesn't help.)
Distilling inference based approaches into learning is usually reasonably straightforward. I think this also applies in this case.
This doesn't necessarily apply to 'learning how to learn'.
(That said, I'm less sold that retrieval + chain of thought 'mostly solves autonmomous learning')
Autonomous learning basically requires there to be a generator-discriminator gap in the domain in question, i.e., that the agent trying to improve its capabilities in said domain has to be better able to tell the difference between its own good and bad outputs. If it can do so, it can just produce a bunch of outputs, score their goodness, and train / reward itself on its better outputs. In both situations you note (AZ and human mathematicians) there's such a gap, because game victories and math results can both be verified relatively more easily than they can be generated.
If current LMs have such discriminator gaps in a given domain, they can also learn autonomously, up to the limit of their discrimination ability (which might improve as they get better at generation).
LLM's are still at the AlphaGo stage because the noosphere/internet is vastly more complex than board games, and imitation learning on human thought is more intrinsically woven into its very fabric, without much clear delineation between physics and agent actions/thoughts. But I expect that further progress will soon require more focus on learning from agent's own action planning trajectories.
Hinton's Forward-Forward Algorithm aims to do autonomous learning modelled off what the human brain does during sleep. I'm unsure how much relative optimisation power has been invested in exploring the fundamentals like this. I expect the deeplearning+backprop paradigm to have had a blocking effect preventing other potentially more exponential paradigms from being adequately pursued. It's hard to work on reinventing the fundamentals when you know you'll get much better immediate performance if you lose faith and switch to what's known to work.
But I also expect Hinton is a nigh-unrivalled genius and there's not a flood of people who have a chance to revolutionise the field even if they tried. A race for immediate performance gains may, in an unlikely hypothetical, be good for humanity because researchers won't have as much slack to do long-shot innovation.
I'm scared of the FFA thing, though.
I think forward-forward is basically a drop-in replacement for backprop: they’re both approaches to update a set of adjustable parameters / weights in a supervised-learning setting (i.e. when there’s after-the-fact ground truth for what the output should have been). FF might work better or worse than backprop, FF might be more or less parallelizable than backprop, whatever, I dunno. My guess is that the thing backprop is doing, it’s doing it more-or-less optimally, and drop-in-replacements-for-backprop are mainly interesting for better scientific understanding of how the brain works (the brain doesn’t use backprop, but also the brain can’t use backprop because of limitations of biological neurons, so that fact provides no evidence either way about whether backprop is better than [whatever backprop-replacement is used by the brain, which is controversial]). But even if FF will lead to improvements over backprop, it wouldn’t be the kind of profound change you seem to be implying. It would look like “hey now the loss goes down faster during training” or whatever. It wouldn’t be progress towards autonomous learning, right?
Tbc, my understanding of FF is "I watched him explain it on YT". My scary-feeling is just based on feeling like it could get close to mimicking what the brain does during sleep, and that plays a big part of autonomous learning. Sleeping is not just about cycles of encoding and consolidation, it's also about mysterious tricks for internally reorganising and generalising knowledge. And/or maybe it's about confabulating sensory input as adversarial training data for learning to discern between real and imagined input. Either way, I expect there to be untapped potential for ANN innovation at the bottom, and "sleep" is part of it.
One the other hand, if they don't end up cracking the algorithms behind sleep and the like, this could be good wrt safety, given that I'm tentatively pessimistic about the potential of the leading paradigm to generalise far and learn to be "deeply" coherent.
Oh, and also... This post and the comment thread is full of ideas that people can use to fuel their interest in novel capabilities research. Seems risky. Quinton's points about DNA and evolution can be extrapolated to the hypothesis that "information bottlenecks" could be a cost-effective way of increasing the rate at which networks generalise, and that may or may not be something we want. (This is a known thing, however, so it's not the riskiest thing to say.)
FWIW my 2¢ are: I consider myself more paranoid than most, and don’t see anything here as “risky” enough to be worth thinking about, as of this writing. (E.g. people are already interested in novel capabilities research.)
I don't know that much about the field or what top researchers are thinking about, so I know I'm naive about most of my independent models. But I think it's good for my research trajectory to act on my inside views anyway. And to talk about them with people who may sooner show me how naive I am. :)
I like the reasoning behind this post, but I'm not sure I buy the conclusion. Here's an attempt at excavating why not:
If I may try to paraphrase, I'd say your argument has two parts:
(1) Humans had a "sharp left turn" not because of some underlying jump in brain capabilities, but because of shifting from one way of gaining capabilities to another (from solo learning to culture).
(2) Contemporary AI training is more analogous to "already having culture," so we shouldn't expect that things will accelerate in ways ML researchers don't already anticipate based on trend extrapolations.
Accordingly, we shouldn't expect AIs to get a sharp left turn.
I think I buy (1) but I'm not sure about (2).
Here's an attempt at arguing that AI training will still get a "boost from culture." If I'm right, it could even be the case that their "boost from culture" will be larger than it was for early humans because we now have a massive culture overhang.
Or maybe "culture" isn't the right thing exactly, and the better phrase is something like "generality-and-stacking-insights-on-top-of-each-other threshold from deep causal understanding." If we look at human history, it's not just the start of cultural evolution that stands out – it's also the scientific revolution! (A lot of cultural evolution worked despite individual humans not understanding why they do the things that they do [Henrich's "The Secret of our Success] – by contrast, science is different and requires at least some scientists to understand deeply what they're doing.)
My intuition is that there's an "intelligence" threshold past which all the information on the internet suddenly becomes a lot more useful. When Nate/MIRI speak of a "sharp left turn," my guess is that they mean some understanding-driven thing. (And it has less to do with humans following unnecessarily convoluted rules about food preparation that they don't even understand the purpose of, but following the rules somehow prevents them from poisoning themselves.) It's not "culture" per se, but we needed culture to get there (and maybe it matters "what kind of culture" – e.g., education with scientific mindware).
Elsewhere, I expressed it as follows (quoting now from text I wrote elsewhere):
I suspect that there’s a phase transition that happens when agents get sufficiently good at what Daniel Kokotajlo and Ramana Kumar call “P₂B” (a recursive acronym for “Plan to P₂B Better”). When it comes to “intelligence,” it seems to me that we can distinguish between “learning potential” and “trained/crystallized intelligence” (or “competence”). Children who grow up in an enculturated/learning-friendly setting (as opposed to, e.g., feral children or Helen Keller before she met her teacher) reach a threshold where their understanding of the world and their thoughts becomes sufficiently deep to kickstart a feedback loop. Instead of aimlessly absorbing what’s around them, they prioritize learning the skills and habits of thinking that seem beneficial according to their goals. In this process, slight differences in “learning potential” can significantly affect where a person ends up in their intellectual prime. So, “learning potential” may be gradual, but above a specific threshold (humans above, chimpanzees below), there’s a discontinuity in how it translates to “trained/crystallized intelligence” after a lifetime of (self-)directed learning. Moreover, it seems that we can tell that the slope of the graph (y-axis: “trained/crystallized intelligence;” x-axis: “learning potential”) around the human range is steep.
To quote something I’ve written previously:
“If the child in the chair next to me in fifth grade was slightly more intellectually curious, somewhat more productive, and marginally better dispositioned to adopt a truth-seeking approach and self-image than I am, this could initially mean they score 100%, and I score 95% on fifth-grade tests – no big difference. But as time goes on, their productivity gets them to read more books, their intellectual curiosity and good judgment get them to read more unusually useful books, and their cleverness gets them to integrate all this knowledge in better and increasingly more creative ways. [...] By the time we graduate university, my intellectual skills are mostly useless, while they have technical expertise in several topics, can match or even exceed my thinking even on areas I specialized in, and get hired by some leading AI company.
[...]
If my 12-year-old self had been brain-uploaded to a suitable virtual reality, made copies of, and given the task of devouring the entire internet in 1,000 years of subjective time (with no aging) to acquire enough knowledge and skill to produce novel and for-the-world useful intellectual contributions, the result probably wouldn’t be much of a success. If we imagined the same with my 19-year-old self, there’s a high chance the result wouldn’t be useful either – but also some chance it would be extremely useful. [...] I think it’s at least plausible that there’s a jump once the copies reach a level of intellectual maturity to make plans which are flexible enough [...] and divide labor sensibly [...].”
In other words, I suspect there’s a discontinuity at the point where the P₂B feedback loop hits its critical threshold.
So, my intuition here is that we'll see phase change once AIs reach the kind of deeper understanding of things that allows them to form better learning strategies. That phase transition will be similar in kind to going from no culture to culture, but it's more "AIs suddenly grokking rationality/science to a sufficient-enough degree that they can stack insights with enough reliability to avoid deteriorating results." (Once they grok it, the update permeates to everything they've read – since they read large parts of the internet, the result will be massive.)
I'm not sure what all this implies about values generalizing to new contexts / matters of alignment difficulty. You seem open to the idea of fast takeoff through AIs improving training data, which seems related to my notion of "AIs get smart enough to notice on their own what type of internet-text training data is highest quality vs what's dumb or subtly off." So, maybe we don't disagree much and your objection to the "sharp left turn" concept has to do with the connotations it has for alignment difficulties.
Interesting, this seems quite similar to the idea that human intelligence is around some critical threshold for scientific understanding and reasoning. I'm skeptical that it's useful to think of this as "culture" (except insofar as AIs hearing about the scientific method and mindset from training data, which will apply to anything trained on common crawl) but the broader point does seem to be a major factor in whether there is a "sharp left turn".
I don't think AIs acquiring scientific understanding and reasoning is really a crux for a sharp left turn: moderately intelligent humans who understand the importance of scientific understanding and reasoning and are actively trying to use it seem (to me) to be able to use it very well when biases aren't getting in the way. Very high-g humans can outsmart them trivially in some domains (like pure math) and to a limited extent in others (like social manipulation). But even if you would describe these capability gains as dramatic it doesn't seem like you can attribute them to greater awareness of abstract and scientific reasoning. Unless you think AI that's only barely able to grok these concepts might be an existential threat or there are further levels of understanding beyond what very smart humans have I don't think there's a good reason to be worried about a jump to superhuman capabilities due to gaining capabilities like P₂B.
On the other hand you have a concern that AIs would be able to figure out what from their training data is high quality or low quality (and presumably manually adjusting their own weights to remove the low quality training data). I agree with you that this is a potential cause for a discontinuity, though if foundation model developers start using their previous AIs to pre-filter (or generate) the training data in this way then I think we shouldn't see a big discontinuity due to the training data.
Like you I am not sure what implications there are for whether a sharp gain in capability would likely be accompanied by a major change in alignment (compared to if that capability had happened gradually).
Here’s my takeaway:
There are mechanistic reasons for humanity’s “Sharp Left Turn” with respect to evolution. Humans were bottlenecked by knowledge transfer between new generations, and the cultural revolution allowed us to share our lifetime learnings with the next generation instead of waiting on the slow process of natural selection.
Current AI development is not bottlenecked in the same way and, therefore, is highly unlikely to get a sharp left turn for the same reason. Ultimately, evolution analogies can lead to bad unconscious assumptions with no rigorous mechanistic understanding. Instead of using evolution to argue for a Sharp Left Turn, we should instead look for arguments that are mechanistically specific to current AI development because we are much less likely to make confused mistakes that unconsciously rely on human evolution assumptions.
AI may still suffer from a fast takeoff (through AI driving capabilities research or iteratively refining it's training data), but for AI-specific reasons so we should be paying attention to that kind of fast takeoff might happen and how to deal with it.
Edited after Quintin's response.
Pretty much. Though I'd call it a "fast takeoff" instead of "sharp left turn" because I think "sharp left turn" is supposed to have connotations beyond "fast takeoff", e.g., "capabilities end up generalizing further than alignment".
Right, you are saying evolution doesn't provide evidence for AI capabilities generalizing further than alignment, but then only consider the fast takeoff part of the SLT to be the concern. I know you have stated reasons why alignment would generalize further than capabilities, but do you not think an SLT-like scenario could occur in the two capability jump scenarios you listed?
This whole just does not hold.
(in animals)
The only way to transmit information from one generation to the next is through evolution changing genomic traits, because death wipes out the within lifetime learning of each generation.
This is clearly false. GPT4, can you explain? :
While genes play a significant role in transmitting information from one generation to the next, there are other ways in which animals can pass on information to their offspring. Some of these ways include:
- Epigenetics: Epigenetic modifications involve changes in gene expression that do not alter the underlying DNA sequence. These changes can be influenced by environmental factors and can sometimes be passed on to the next generation.
- Parental behavior: Parental care, such as feeding, grooming, and teaching, can transmit information to offspring. For example, some bird species teach their young how to find food and avoid predators, while mammals may pass on social behaviors or migration patterns.
- Cultural transmission: Social learning and imitation can allow for the transfer of learned behaviors and knowledge from one generation to the next. This is particularly common in species with complex social structures, such as primates, cetaceans, and some bird species.
- Vertical transmission of symbionts: Some animals maintain symbiotic relationships with microorganisms that help them adapt to their environment. These microorganisms can be passed from parent to offspring, providing the next generation with information about the environment.
- Prenatal environment: The conditions experienced by a pregnant female can influence the development of her offspring, providing them with information about the environment. For example, if a mother experiences stress or nutritional deficiencies during pregnancy, her offspring may be born with adaptations that help them cope with similar conditions.
- Hormonal and chemical signaling: Hormones or chemical signals released by parents can influence offspring development and behavior. For example, maternal stress hormones can be transmitted to offspring during development, which may affect their behavior and ability to cope with stress in their environment.
- Ecological inheritance: This refers to the transmission of environmental resources or modifications created by previous generations, which can shape the conditions experienced by future generations. Examples include beaver dams, bird nests, or termite mounds, which provide shelter and resources for offspring.
(/GPT)
Actually, transmitting some of the data gathered during the lifetime of the animal to next generation by some other means is so obviously useful that is it highly convergent. Given the fact it is highly convergent, the unprecedented thing which happened with humans can't be the thing proposed (evolution suddenly discovered how not to sacrifice all whats learned during the lifetime).
Evolution's sharp left turn happened because evolution spent compute in a shockingly inefficient manner for increasing capabilities, leaving vast amounts of free energy on the table for any self-improving process that could work around the evolutionary bottleneck. Once you condition on this specific failure mode of evolution, you can easily predict that humans would undergo a sharp left turn at the point where we could pass significant knowledge across generations. I don't think there's anything else to explain here, and no reason to suppose some general tendency towards extreme sharpness in inner capability gains.
If the above is not enough to see why this is false... This hypothesis would also predict civilizations built by every other species which transmits a lot of data e.g. by learning from parental behaviour - once evolution discovers the vast amounts of free energy on the table this positive feedback loop would just explode.
This isn't the case => the whole argument does not hold.
Also this argument not working does not imply evolution provides strong evidence for sharp left turn.
What's going on?
In fact in my view we do not actually understand what exactly happened with humans. Yes, it likely has something to do with culture, and brains, and there being more humans around. But what's the causality?
Some of the candidates for "what's the actually fundamental differentiating factor and not a correlate"
- One notable thing about humans is, it's likely the second time in history a new type of replicator with R>1 emerged: memes. From replicator-centric perspective on the history of the universe, this is the fundamental event, starting a different general evolutionary computation operating at much shorter timescale.
- Machiavellian intelligence hypothesis suggests that what happened was humans entered a basin of attraction where selection pressure on "modelling and manipulation of other humans" leads to explosion in brain sizes. The fundamental thing suggested here is you soon hit diminishing return for scaling up energy-hungry predictive processing engines modelling fixed-complexity environment - soon you would do better by e.g. growing bigger claws. Unless... you hit the Machiavellian basin, where sexual selection forces you to model other minds modelling your mind ... and this creates a race, in a an environment of unbounded complexity.
- Social brain hypothesis is similar, but the runaway complexity of the environment is just because of the large and social groups.
- Self-domestication hypothesis: this is particularly interesting and intriguing. The idea is humans self-induced something like domestication selection, selecting for pro-social behaviours and reduction in aggression. From an abstract perspective, I would say this allows emergence of super-agents composed of individual humans, more powerful than individual humans. (once such entities exist, they can create further selection pressure for pro-sociality)
or, a combination of the above, or something even weirder
The main reason why it's hard to draw insights from evolution of humans to AI isn't because there is nothing to learn, but because we don't know why what happened happened.
I think OP is correct about cultural learning being the most important factor in explaining the large difference in intelligence between homo sapiens and other animals.
In early chapters of Secrets of Our Success, the book examines studies comparing performance of young humans and young chimps on various congnitive tasks. The book argues that across a broad array of cognitive tests, 4 year old humans do not perform singificantly better than 4 year old chimps on average, except in cases where the task can be solved by immitating others (human children crushed the chimps when this was the case).
The book makes a very compelling argument that our species is uniquely prone to immitating others (even in the absense of causal models about why the behaviour we're immitating is useful), and even very young humnans have inate instincts for picking up on signals of prestige/compotence in others and preferentially immitating those high prestige poeple. Imo the arguments put forward in this book make cultral learning look like a very strong theory better in comparison to Machieavellian intelligence hypothesis, (although what actually happend at a lower level abstraction probably includes aspects of both).
Note that this isn't exactly the hypothesis proposed in the OP and would point in a different direction.
OP states there is a categorical difference between animals and humans, in the ability of humans to transfer data to future generation. This is not the case, because animals do this as well.
What your paraphrase of Secrets of Our Success is suggesting is this existing capacity for transfer of data across generations is present in many animals, but there is some threshold of 'social learning' which was crossed by humans - and when crossed, lead to cultural explosion.
I think this is actually mostly captured by .... One notable thing about humans is, it's likely the second time in history a new type of replicator with R>1 emerged: memes. From replicator-centric perspective on the history of the universe, this is the fundamental event, starting a different general evolutionary computation operating at much shorter timescale.
Also ... I've skimmed few chapters of the book and the evidence it gives of the type 'chimps vs humans' is mostly for current humans being substantially shaped by cultural evolution, and also our biology being quite influenced by cultural evolution. This is clearly to be expected after the evolutions run for some time, but does not explain causality that much.
(The mentioned new replicator dynamic is actually one of the mechanisms which can lead to discontinuous jumps based on small changes in underlying parameter. Changing the reproduction number of a virus from just below one to above one causes an epidemic.)
OP states there is a categorical difference between animals and humans, in the ability of humans to transfer data to future generation. This is not the case, because animals do this as well.
There doesn't need to be a categorical difference, just a real difference that is strong enough to explain humanities sharp left turn by something other than increased brain size. I do believe that's plausible - humans are much much better than other animals at communicating abstractions and ideas accross generations. Can't speak about the book, but X4vier's example would seem to support that argument.
Jan, your comment here got a lot of disagree votes, but I have strongly agreed with it. I think the discussion of cultural transmission as source of the 'sharp left turn' of human evolution is missing a key piece.
Cultural transmission is not the first causal mechanism. I would argue that it is necessary for the development of modern human society, but not sufficient.
The question of "How did we come to be?" is something I've been interested in my entire adult life. I've spent a lot of time in college courses studying neuroscience, and some studying anthropology. My understanding as I would summarize it here:
Around 2.5 million years ago - first evidence of hominids making and using stone tools
Around 1.5 million years ago - first evidence of hominids making fires
https://en.wikipedia.org/wiki/Prehistoric_technology
Around 300,000 years ago (15000 - 20000 generations), Homo sapiens arises as a new subspecies in Africa. Still occasionally interbreeds with other subspecies (and presumably thus occasionally communicates with and trades with). Early on, homo sapiens didn't have an impressive jump in technology. There was a step up in their ability to compete with other hominids, but it wasn't totally overwhelming. After outcompeting the other hominids in the area, homo sapiens didn't sustain massively larger populations. They were still hunter/gatherers with similar tech, constrained to similar calorie acquisition limits.
They gradually grow in numbers and out-compete other subspecies. Their tools get gradually better.
Around 55,000 years ago (2700 - 3600 generations), Homo sapiens spreads out of Africa. Gradually colonizes the rest of the world, continuing to interbreed (and communicate and trade) with other subspecies somewhat, but being clearly dominant.
Around 12,000 years ago, homo sapiens began developing agriculture and cities.
Around 6,000 years ago, homo sapiens began using writing.
From wikipedia article on human population:
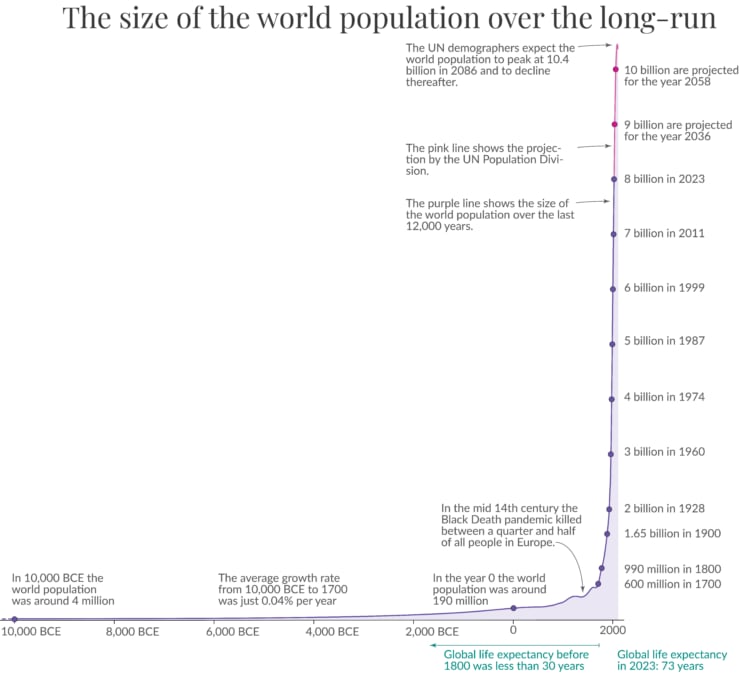
Here's a nice summary quote from a Smithsonian magazine article:
For most of our history on this planet, Homo sapiens have not been the only humans. We coexisted, and as our genes make clear frequently interbred with various hominin species, including some we haven’t yet identified. But they dropped off, one by one, leaving our own species to represent all humanity. On an evolutionary timescale, some of these species vanished only recently.
On the Indonesian island of Flores, fossils evidence a curious and diminutive early human species nicknamed “hobbit.” Homo floresiensis appear to have been living until perhaps 50,000 years ago, but what happened to them is a mystery. They don’t appear to have any close relation to modern humans including the Rampasasa pygmy group, which lives in the same region today.
Neanderthals once stretched across Eurasia from Portugal and the British Isles to Siberia. As Homo sapiens became more prevalent across these areas the Neanderthals faded in their turn, being generally consigned to history by some 40,000 years ago. Some evidence suggests that a few die-hards might have held on in enclaves, like Gibraltar, until perhaps 29,000 years ago. Even today traces of them remain because modern humans carry Neanderthal DNA in their genome.
And from the wikipedia article on prehistoric technology:
Neolithic Revolution
The Neolithic Revolution was the first agricultural revolution, representing a transition from hunting and gathering nomadic life to an agriculture existence. It evolved independently in six separate locations worldwide circa 10,000–7,000 years BP (8,000–5,000 BC). The earliest known evidence exists in the tropical and subtropical areas of southwestern/southern Asia, northern/central Africa and Central America.[34]
There are some key defining characteristics. The introduction of agriculture resulted in a shift from nomadic to more sedentary lifestyles,[35] and the use of agricultural tools such as the plough, digging stick and hoe made agricultural labor more efficient.[citation needed] Animals were domesticated, including dogs.[34][35] Another defining characteristic of the period was the emergence of pottery,[35] and, in the late Neolithic period, the wheel was introduced for making pottery.[36]
So what am I getting at here? I'm saying that this idea of a homo sapiens sharp left turn doesn't look much like a sharp left turn. It was a moderate increase in capabilities over other hominids.
I would say that the Neolithic Revolution is a better candidate for a sharp left turn. I think you can trace a clear line of 'something fundamentally different started happening' from the Neolithic Revolution up to the Industrial Revolution when the really obvious 'sharp left turn' in human population began.
So here's the really interesting mystery. Why did the Neolithic Revolution occur independently in six separate locations?!
Here's my current best hypothesis. Homo sapiens originally was only somewhat smarter than the other hominids. Like maybe, ~6-year-old intelligences amongst the ~4-year-old intelligences. And if you took a homo sapiens individual from that time period and gave them a modern education... they'd seem significantly mentally handicapped by today's standards even with a good education. But importantly, their brains were bigger. But a lot of that potential brain area was poorly utilized. But now evolution had a big new canvas to work with, and the Machiavellian-brain-hypothesis motivation of why a strong evolutionary pressure would push for this new larger brain to improve its organization. Homo sapiens was competing with each other and with other hominids from 300,000 to 50,000 years ago! Most of their existence so far! And they didn't start clearly rapidly dominating and conquering the world until the more recent end of that. So 250,000 years of evolution figuring out how to organize this new larger brain capacity to good effect. To go from 'weak general learner with low max capability cap' to 'strong general learner with high max capability cap'. A lot of important things happened in the brain in this time, but it's hard to see any evidence of this in the fossil record, because the bone changes happened 300,000 years ago and the bones then stayed more or less the same. If this hypothesis is true, then we are a more different species from the original Homo sapiens than those original Homo sapiens were from the other hominids they had as neighbors. A crazy fast time period from an evolutionary time point, but with that big new canvas to work with, and a strong evolutionary pressure rewarding every tiny gain, it can happen. It took fewer generations to go from a bloodhound-type-dog to a modern dachshund.
There are some important differences between our modern Homo sapiens neurons and other great apes. And between great apes vs other mammals.
The fundamental learning algorithm of the cortex didn't change, what did change were some of the 'hyperparameters' and the 'architectural wiring' within the cortex.
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3103088/
For an example of a 'hyperparameter' change, human cortical pyramidal cells (especially those in our prefrontal cortex) form a lot more synaptic connections with other neurons. I think this is pretty clearly a quantitative change rather than a qualitative one, so I think it nicely fits the analogy of a 'hyperparameter' change. I highlight this one, because this difference was traced to a difference in a single gene. And in experiments where this gene was expressed in a transgenic mouse line, the resulting mice were measurably better at solving puzzles.
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10064077/
An example of what I mean about 'architectural wiring' changes is that there has been a shift in the patterns of the Brodmann areas from non-human apes to humans. As in, what percentage of the cortex is devoted to specific functions. Language, abstract reasoning, social cognition all benefited relatively more compared to say, vision. These Brodmann areas are determined by the genetically determined wiring that occurs during fetal development and lasts for a lifetime, not determined by in-lifetime-learning like synaptic weights are. There are exceptions to this rule, but they are exceptions that prove the rule. Someone born blind can utilize their otherwise useless visual cortex a bit for helping with other cognitive tasks, but only to a limited extent. And this plastic period ends in early childhood. An adult who looses their eyes gains almost no cognitive benefits in other skills due to 'reassigning' visual cortex to other tasks. Their skill gains in non-visual tasks like navigation-by-hearing-and-mental-space-modeling come primarily from learning within the areas already devoted to those tasks driven by the necessity of the life change.
https://www.science.org/content/blog-post/chimp-study-offers-new-clues-language
What bearing does this have on trying to predict the future of AI?
If my hypothesis is correct, there are potentially analogously important changes to be made in shaping the defining architecture and hyperparameters of deep neural nets. I have specific hypotheses about these changes drawing on my neuroscience background and the research I've been doing over the past couple years into analyzing the remaining algorithmic roadblocks to AGI. Mostly, I've been sharing this with only a few trusted AI safety researcher friends, since I think it's a pretty key area of capabilities research if I'm right. If I'm wrong, then it's irrelevant, except for flagging the area as a dead end.
For more details that I do feel ok sharing, see my talk here:
Edit 2024.07.29: Came across this very interesting podcast episode relevant to the discussion. It discusses new evidence which I think supports my hypothesis. https://manyminds.libsyn.com/from-the-archive-why-did-our-brains-shrink-3000-years-ago
It seems to me that the key threshold has to do with the net impact of meme replication:
- Transmitting a meme imposes some constraint on the behaviour of the transmitting system.
- Transmitting a meme sometimes benefits the system (or descendants).
Where the constraint is very limiting, all but a small proportion of memes will be selected against. The [hunting technique of lions] meme is transferred between lions, because being constrained to hunt is not costly, while having offspring observe hunting technique is beneficial.
This is still memetic transfer - just a rather uninteresting version.
Humans get to transmit a much wider variety of memes more broadly because the behavioural constraint isn't so limiting (speaking, acting, writing...), so the upside needn't meet a high bar.
The mechanism that led to hitting this threshold in the first place isn't clear to me. The runaway behaviour after the threshold is hit seems unsurprising.
Still, I think [transmission became much cheaper] is more significant than [transmission became more beneficial].
I don't think this objection matters for the argument I'm making. All the cross-generational information channels you highlight are at rough saturation, so they're not able to contribute to the cross-generational accumulation of capabilities-promoting information. Thus, the enormous disparity between the brain's with-lifetime learning versus evolution cannot lead to a multiple OOM faster accumulation of capabilities as compared to evolution.
When non-genetic cross-generational channels are at saturation, the plot of capabilities-related info versus generation count looks like this:
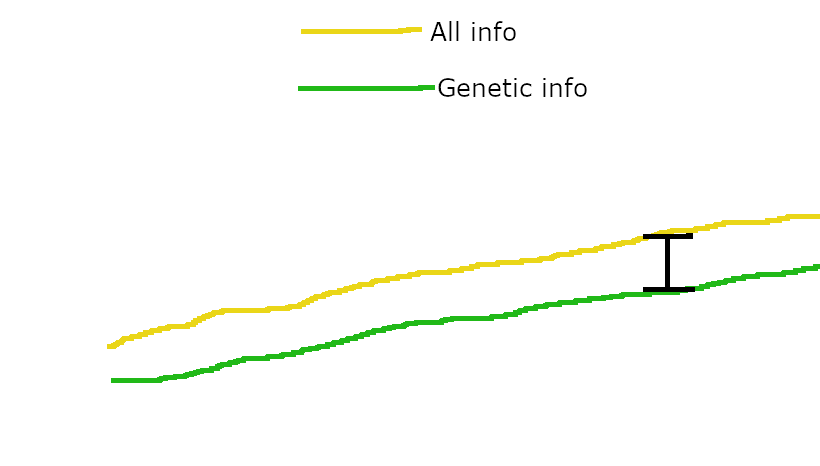
with non-genetic information channels only giving the "All info" line a ~constant advantage over "Genetic info". Non-genetic channels might be faster than evolution, but because they're saturated, they only give each generation a fixed advantage over where they'd be with only genetic info. In contrast, once the cultural channel allows for an ever-increasing volume of transmitted information, then the vastly faster rate of within-lifetime learning can start contributing to the slope of the "All info" line, and not just its height.
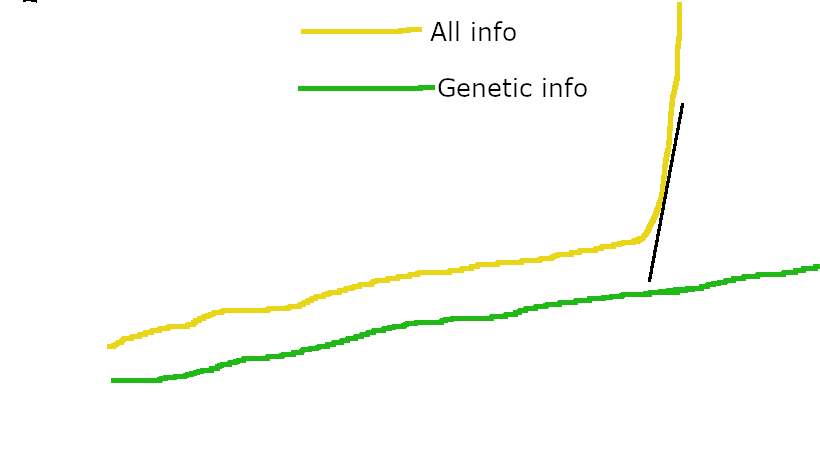
Thus, humanity's sharp left turn.
Hey Quintin thanks for the diagram.
Have you tried comparing the cumulative amount of genetic info over 3.5B years?
Isn't it a big coincidence that the time of brains that process info quickly / increase information rapidly, is also the time where those brains are much more powerful than all other products of evolution?
(The obvious explanation in my view is that brains are vastly better optimizers/searchers per computation step, but I'm trying to make sure I understand your view.)
The capabilities of ancestral humans increased smoothly as their brains increased in scale and/or algorithmic efficiency. Until culture allowed for the brain’s within-lifetime learning to accumulate information across generations, this steady improvement in brain capabilities didn’t matter much. Once culture allowed such accumulation, the brain’s vastly superior within-lifetime learning capacity allowed cultural accumulation of information to vastly exceed the rate at which evolution had been accumulating information. This caused the human sharp left turn.
This is basically true if you're talking about the agricultural or industrial revolutions, but I don't think anybody claims evolution improved human brains that fast. But homo sapiens have only been around 300,000 years, which is still quite short on the evolutionary timescale, and it's much less clear that the quoted paragraph applies here.
I think a relevant thought experiment would be to consider the level of capability a species would eventually attain if magically given perfect parent-to-child knowledge transfer—call this the 'knowledge ceiling'. I expect most species to have a fairly low knowledge ceiling—e.g. meerkats with all the knowledge of their ancestors would basically live like normal meerkats but be 30% better at it or something.
The big question, then, is what the knowledge ceiling progression looks like over the course of hominid evolution. It is not at all obvious to me that it's smooth!
In order to experience a sharp left turn that arose due to the same mechanistic reasons as the sharp left turn of human evolution, an AI developer would have to:
- Deliberately create a (very obvious) inner optimizer, whose inner loss function includes no mention of human values / objectives.
- Grant that inner optimizer ~billions of times greater optimization power than the outer optimizer.
- Let the inner optimizer run freely without any supervision, limits or interventions from the outer optimizer.
I’ll bite! I think this happens if we jump up a level from “an AI developer” to “the world”:
- Lots of different people and companies deliberately create a (very obvious) inner optimizer (i.e. a fresh new ML training run), whose inner loss function includes no mention of human values / objectives (at least sometimes—e.g. self-supervised learning, or safety-unconcerned people might try capabilities-oriented RL reward functions to try to beat a benchmark or just to see what happens etc.).
- An outer optimizer exists here—the people doing the best on benchmarks will get their approaches copied, get more funding, etc. But the outer optimizer has billions of times less optimization power than the inner optimizer.
- At least some of these people and companies (especially the safety-unconcerned ones) let the inner optimizer run freely without any supervision, limits, or interventions (OK sure, probably somebody is watching the loss function go down during training, but presumably it’s not uncommon to wait until a training run is “complete” before doing a rigorous battery of safety tests).
Some possible cruxes here are: (1) do these safety-unconcerned people (or safety-concerned-in-principle-but-failing-to-take-necessary-actions people) exist & hold influence, and if so will that continue to be true when AI x-risk is on the table? (I say yes—e.g. Yann LeCun thinks AI x-risk is dumb.) (2) Is it plausible that one group’s training run will have importantly new and different capabilities from the best relevant previous one? (I say yes—consider grokking, or algorithmic improvements, or autonomous learning per my other comment.)
I don't think I'm concerned by moving up a level in abstraction. For one, I don't expect any specific developer to suddenly get access to 5 - 9 OOMs more compute than any previous developer. For another, it seems clear that we'd want the AIs being built to be misaligned with whatever "values" correspond to the outer selection signals associated with the outer optimizer in question (i.e., "the people doing the best on benchmarks will get their approaches copied, get more funding, etc"). Seems like an AI being aligned to, like, impressing its developers? doing well on benchmarks? getting more funding? becoming the best architecture it can be? IDK what, but it would probably be bad.
So, I don't see a reason to expect either a sudden capabilities jump (Edit: deriving from the same mechanism as the human sharp left turn), or (undesirable) misalignment.
I wrote:
(2) Is it plausible that one group’s training run will have importantly new and different capabilities from the best relevant previous one? (I say yes—consider grokking, or algorithmic improvements, or autonomous learning per my other comment.)
And then you wrote:
I don't expect any specific developer to suddenly get access to 5 - 9 OOMs more compute than any previous developer.
Isn’t that kinda a strawman? I can imagine a lot of scenarios where a training run results in a qualitatively better trained model than any that came before—I mentioned three of them—and I think “5-9OOM more compute than any previous developer” is a much much less plausible scenario than any of the three I mentioned.
This post mainly argues that evolution does not provide evidence for the sharp left turn. Sudden capabilities jumps from other sources, such as those you mention, are more likely, IMO. My first reply to your comment is arguing that the mechanisms behind the human sharp left turn wrt evolution probably still won't arise in AI development, even if you go up an abstraction level. One of those mechanisms is a 5 - 9 OOM jump in usable optimization power, which I think is unlikely.
This post caused me to no longer use the standard evolution analogies when talking/thinking about alignment, and instead think more about the human reward system, how that is created via evolution, and how non-genome-encoded concepts are connected to value in human learning[1].
Notable as well is the implicit argument from a mismatch in amount of feedback-information received by current AI systems vs. the amount of feedback the human reward architecture has gotten through evolution—the former (through gradient descent) is much higher than the latter. The standard risk story wants to say that this mismatch in feedback-bitrate doesn't matter, I notice myself changing my mind on this every now and then.
Good post, +4.
I'm curious whether the recent trend toward bi-level optimization via chain-of-thought was any update for you? I would have thought this would have updated people (partially?) back toward actually-evolution-was-a-decent-analogy.
There's this paragraph, which seems right-ish to me:
In order to experience a sharp left turn that arose due to the same mechanistic reasons as the sharp left turn of human evolution, an AI developer would have to:
- Deliberately create a (very obvious[2]) inner optimizer, whose inner loss function includes no mention of human values / objectives.[3]
- Grant that inner optimizer ~billions of times greater optimization power than the outer optimizer.[4]
- Let the inner optimizer run freely without any supervision, limits or interventions from the outer optimizer.[5]
Extremely long chains-of-thought on hard problems is pretty much meeting these conditions, right?
I haven't evaluated this particular analogy for optimization on the CoT, since I don't think the evolution analogy is necessary to see why optimizing on the CoT is a bad idea. (Or, the very least, whether optimizing on the CoT is a bad idea is independent from whether evolution was successful). I probably should,,,
TL;DR: Disanalogies that training can update the model on the contents of the CoT, while evolution can not update on the percepts of an organism; also CoT systems aren't re-initialized after long CoTs so they retain representations of human values. So a CoT is unlike the life of an organism.
Details: Claude voice Let me think about this step by step…
Evolution optimizes the learning algorithm + reward architecture for organisms, those organisms then learn based on feedback from the environment. Evolution only gets really sparse feedback, namely how many offspring the organism had, and how many offspring those offspring had in turn (&c) (in the case of sexual reproduction).
Humans choose the learning algorithm (e.g. transformers) + the reward system (search depth/breadth, number of samples, whether to use a novelty sampler like entropix, …).
I guess one might want to disambiguate what is analogized to the lifetime learning of the organism: A single CoT, or all CoTs in the training process. A difference in both cases is that the reward process can be set up so that SGD updates on the contents of the CoT, not just on whether the result was achieved (unlike in the evolution case, where evolution has no way of encoding the observations of an organism into the genome of its offspring (modulo epigenetics-blah). My expectation for a while[1] has been that people are going to COCONUT away any possibility of updating the weights on a function of the contents of the CoT because (by the bitter lesson) human language just isn't the best representation for every problem[2], but the fact that with current setups it's possible is a difference from the paragraph you quoted (namely point 3).
If I were Quintin I'd also quibble about the applicability of the first point to CoT systems, especially since the model isn't initialized randomly at the beginning but contains a representation of human values which can be useful in the optimization.
I guess since early-mid 2023 when it seemed like scaffolding agents were going to become an important thing? Can search for receipts if necessary. ↩︎
Or, alternatively, there is just a pressure during training away from human-readable CoTs, "If the chain of thought is still English you're not RLing hard enough" amirite ↩︎
My summary:
The reason why there was a sharp left turn in the evolution of humans is because evolution was putting tiny amount of compute into hyperparamater search, compared to the compute that brains were using for learning over their lifetime. But all of the learning that the brains were doing was getting thrown out at the end of each of their lives. So, there was this huge low hanging fruit opportunity to not throw out the results of most of the compute usage. It's like having giant overpowered functions doing computations, but the part where they pass their results to the next function is broken.
Eventually humans developed enough culture that human civilization was able to not throw out a small fraction of the the learning accumulated by the brains in their lifetimes. This effectively unlocked a gigantic long-term learning-accumulation process, that had been sitting right there latent. And as soon as it was online it started out with around 6 orders of magnitude more compute than the only long term learning process up until that point, evolution.
But modern ML doesn't have anything like this huge discrepancy in compute allocation. When we train ML systems, the vast majority of the compute is spent on training. A comparatively small amount is spent (at least currently) on inference, which includes some in-context learning.
Even preserving 100% of the in-context learning would not thereby create / unlock an extended learning process that is much more powerful than SGD, because SGD is still using vastly more compute than that in-context learning. The massive low-hanging fruit that was waiting to be exploited in human evolution is just not there in modern machine learning.
Without this evolutionary analogy, why should we even elevate the very specific claim that 'AIs will experience a sudden burst of generality at the same time as all our alignment techniques fail.' to consideration at all, much less put significant weight on it?
I see this as a very natural hypothesis because alignment requires a hopeful answer to the question:
“Given that an agent has ontology / beliefs X and action space Y, will it do things that we want it to do?”
If the agent experiences a sudden burst of generality, then it winds up with a different X, and a different (and presumably much broader) Y. So IMO it’s obviously worth considering whether misalignment might start at such point.
(Oh wait, or are you saying that “AIs will experience a sudden burst of generality” is the implausible part? I was assuming from the boldface that you see “…at the same time…” as the implausible part.)
However, the process responsible for human breadth of generality was not some small architectural modification evolution made to the human brain. It was humanity's cross-generational process of expanding and improving our available "training data" to cover a broader and broader range of capabilities across many domains (a process we sometimes call "science"). The evolutionary analogy thus offers no reason to expect sudden jumps in generality without corresponding extensions of the training data.
I think this is true but wish it were hedged as "I think it was not", since we have not in fact observed that the small architectural modification didn't cause it, nor do I think we have a huge pile of evidence towards that. I think we have a reasonably strong amount of evidence to that conclusion.
First of all, thank you so much for this post! I found it generally very convincing, but there were a few things that felt missing, and I was wondering if you could expand on them.
However, I expect that neither mechanism will produce as much of a relative jump in AI capabilities, as cultural development produced in humans. Neither mechanism would suddenly unleash an optimizer multiple orders of magnitude faster than anything that came before, as was the case when humans transitioned from biological evolution to cultural development.
Why do you expect this? Surely the difference between passive and active learning, or the ability to view and manipulate one's own source code (or that of a successor) would be pretty enormous? Also it feels like this implicitly assumes that relatively dumb algorithms like SGD or Predictive-processing/hebbian-learning will not be improved upon during such a feedback loop.
On the topic of alignment, it feels like many of the techniques you mention are not at all good candidates, because they focus on correcting bad behavior as it appears. It seems like we mainly have a problem if powerful superhuman capabilities arrive before we have robustly aligned a system to good values. Currently, none of those methods have (as far as I can tell) any chance of scaling up, in particular because at some point we won't be able apply corrective pressures to a model that has decided to deceive us. Do we have any examples of a system where we apply corrective pressure early to instill some values, and then scale up performance without needing to continue to apply more corrective pressure?
And just like evolution provides no reason to assume our own AI development efforts will experience a sharp left turn, so to does evolution not provide any reason to assume our AI development efforts will show extreme misgeneralization between training and deployment.
This might well be true, but we might expect "AI [showing] extreme misgeneralizion between training and deployment" based on actual AI development rather than on evolution.
Such arguments claim we will see a similar transition while training AIs, with SGD creating some 'inner thing' which is not SGD and which gains capabilities much faster than SGD can insert them into the AI. Then, just like human civilization exploded in capabilities over a tiny evolutionary time frame, so too will AIs explode in capabilities over a tiny "SGD time frame".
I don't think this is an accurate summary of the argument for the plausibility of a sharp left turn. The post you link doesn't actually mention gradient descent at all. This inaccuracy is load-bearing, because the most capable AI systems in the near future seem likely to gain many kinds of capabilities through methods that don't resemble SGD, long before they are expected to take a sharp left turn.
For example, Auto-GPT is composed of foundation models which were trained with SGD and RHLF, but there are many ways to enhance the capabilities of Auto-GPT that do not involve further training of the foundation models. The repository currently has hundreds of open issues and pull requests. Perhaps a future instantiation of Auto-GPT will be able to start closing these PRs on its own, but in the meantime there are plenty of humans doing that work.
It doesn't mention the literal string "gradient descent", but it clearly makes reference to the current methodology of training AI systems (which is gradient descent). E.g., here:
The techniques OpenMind used to train it away from the error where it convinces itself that bad situations are unlikely? Those generalize fine. The techniques you used to train it to allow the operators to shut it down? Those fall apart, and the AGI starts wanting to avoid shutdown, including wanting to deceive you if it’s useful to do so.
The implication is that the dangerous behaviors that manifest during the SLT are supposed to have been instilled (at least partially) during the training (gradient descent) process.
However, the above is a nitpick. The real issue I have with your comment is that you seem to be criticizing me for not addressing the "capabilities come from not-SGD" threat scenario, when addressing that threat scenario is what this entire post is about.
Here's how I described SLT (which you literally quoted): "SGD creating some 'inner thing' which is not SGD and which gains capabilities much faster than SGD can insert them into the AI."
This is clearly pointing to a risk scenario where something other than SGD produces the SLT explosion of capabilities.
You say:
For example, Auto-GPT is composed of foundation models which were trained with SGD and RHLF, but there are many ways to enhance the capabilities of Auto-GPT that do not involve further training of the foundation models. The repository currently has hundreds of open issues and pull requests. Perhaps a future instantiation of Auto-GPT will be able to start closing these PRs on its own, but in the meantime there are plenty of humans doing that work.
To which I say, yes, that's an example where SGD creates some 'inner thing' (the ability to contribute to the Auto-GPT repository), which (one might imagine) would let Auto-GPT "gain capabilities much faster than SGD can insert them into the AI." This is exactly the sort of thing that I'm talking about in this post, and am saying it won't lead to an SLT.
(Or at least, that the evolutionary example provides no reason to think that Auto-GPT might undergo an SLT, because the evolutionary SLT relied on the sudden unleash of ~9 OOM extra available optimization power, relative to the previous mechanisms of capabilities accumulation over time.)
Finally, I'd note that a very significant portion of this post is explicitly focused on discussing "non-SGD" mechanisms of capabilities improvement. Everything from "Fast takeoff is still possible" and on is specifically about such scenarios.
However, the above is a nitpick. The real issue I have with your comment is that you seem to be criticizing me for not addressing the "capabilities come from not-SGD" threat scenario, when addressing that threat scenario is what this entire post is about.
That's not what I'm criticizing you for. I elaborated a bit more here; my criticism is that this post sets up a straw version of the SLT argument to knock down, of which assuming it applies narrowly to "spiky" capability gains via SGD is one example.
The actual SLT argument is about a capabilities regime (human-level+), not a specific method for reaching it or how many OOM of optimization power are applied before or after.
The reasons to expect a phase shift in such a regime are because (by definition) a human-level AI is capable of reflection, deception, having insights that no other human has had before (as current humans sometimes do), etc.
Note, I'm not saying that setting up a strawman automatically invalidates all the rest of your claims, nor that you're obligated to address every possible kind of criticism. But I am claiming that you aren't passing the ITT of someone who accepts the original SLT argument (and probably its author).
But it does mean you can't point to support for your claim that evolution provides no evidence for the Pope!SLT, as support for the claim that evolution provides no evidence for the Soares!SLT, and expect that to be convincing to anyone who doesn't already accept that Pope!SLT == Soares!SLT.
Then my disagreement is that I disagree with the claim that the human regime is very special, or that there's any reason to attach much specialness to human-level intelligence.
In essence, I agree with a weaker version of Quintin Pope's comment here:
https://forum.effectivealtruism.org/posts/zd5inbT4kYKivincm/?commentId=Zyz9j9vW8Ai5eZiFb
"AGI" is not the point at which the nascent "core of general intelligence" within the model "wakes up", becomes an "I", and starts planning to advance its own agenda. AGI is just shorthand for when we apply a sufficiently flexible and regularized function approximator to a dataset that covers a sufficiently wide range of useful behavioral patterns.
There are no "values", "wants", "hostility", etc. outside of those encoded in the structure of the training data (and to a FAR lesser extent, the model/optimizer inductive biases). You can't deduce an AGI's behaviors from first principles without reference to that training data. If you don't want an AGI capable and inclined to escape, don't train it on data[1] that gives it the capabilities and inclination to escape.
Putting it another way, I suspect you're suffering from the fallacy of generalizing from fiction, since fictional portrayals make it far more discontinuous and misaligned ala the Terminator than what happens in reality.
Link below:
My understanding of the first part of your argument: The rapid (in evolutionary timescales) increase in human capabilities (that led to condoms and ice cream) is mostly explained by human cultural accumulation (i.e. humans developed better techniques for passing on information to the next generation).
My model is different. In my model, there are two things that were needed for the rapid increase in human capabilities. The first was the capacity to invent/create useful knowledge, and the second was the capacity to pass it on.
To me it looks like the human rapid capability gains depended heavily on both.
Additionally, I claim that alignment techniques already generalize across human contributions to AI capability research.
I think this set of examples about alignment techniques and capabilities advances is misunderstanding what others talking about this mean by 'capabilities advances'. I believe the sense in which Eliezer means a 'capabilities advance' when discussing the evolutionary analogy is about 'measured behavioral capabilties'. As in, the Brier score on a particular benchmark. Not as in, a change to the design of the training process or inference process. The question under discussion is then, "How well does an alignment technique, like RLHF, generalize across a capabilities advance such as becoming able to translate accurately between English and French". I think the evidence so far is that the emergent capabilities we've seen so far do not conflict with the alignment techniques we've developed so far. The main point of the evolutionary analogy argument though is to say that there is a class of emergent capabilities in the future which are expected to depart from this pattern. These hypothetical future emergent capabilities are hypothesized to be tightly clustered in arrival time, much larger in combined magnitude and scope, and highly divergent from past trends. Their clustered nature, if true, would make it likely that a new scaled up model would gain all these capabilities at nearly the same point in the training process (or at least at near the same model scale). Thus, the stronger than expected model would present a surprising jump in capabilities without a concommitent jump in alignment.
I'm not myself sure that this is how reality is structured such that we should expect this. But I do think that it makes enough logical sense that it might be possible that we should make careful preparations to prevent bad things happening if it did turn out that this was the case.
E.g., I expect that choosing to use the [LION optimizer](https://arxiv.org/abs/2302.06675) in place of the [Adam optimizer](https://arxiv.org/abs/1412.6980) would have very little impact on, say, the niceness of a language model you were training, except insofar as your choice of optimizer influences the convergence of the training process. Architecture choices seem 'values neutral' in a way that data choices are not.
In the brain, architecture changes matter at lot to values-after-training. Someone with fewer amygdala neurons is far more likely to behave in anti-social ways. So in the context of current models, who are developing 'hidden' logical architectures/structures/heuristics within the very loose architectures we've given them, changing the visible attributes of the architecture (e.g. optimizer or layer width) is likely to be mostly value neutral on average. However, changing this 'hidden structure', by adding values to the activation states for instance, is almost certainly going to have a substantial effect on behaviorally expressed values.
The "alignment technique generalise across human contributions to architectures" isn't about the SLT threat model. It's about the "AIs do AI capabilities research" threat model.
- Deliberately create a (very obvious[2]) inner optimizer, whose inner loss function includes no mention of human values / objectives.[3]
- Grant that inner optimizer ~billions of times greater optimization power than the outer optimizer.[4]
- Let the inner optimizer run freely without any supervision, limits or interventions from the outer optimizer.[5]
I think that the conditions for an SLT to arrive are weaker than you describe.
For (1), it's unclear to me why you think you need to have this multi-level inner structure.[1] If instead of reward circuitry inducing human values, evolution directly selected over policies, I'd expect similar inner alignment failures. It's also not necessary that the inner values of the agent make no mention of human values / objectives, it needs to both a) value them enough to not take over, and b) maintain these values post-reflection.
For (2), it seems like you are conflating 'amount of real world time' with 'amount of consequences-optimization'. SGD is just a much less efficient optimizer than intelligent cognition -- in-context learning happens much faster than SGD learning. When the inner optimizer starts learning and accumulating knowledge, it seems totally plausible to me that this will happen on much faster timescales than the outer selection.
For (3), I don't think that the SLT requires the inner optimizer to run freely, it only requires one of:
a. the inner optimizer running much faster than the outer optimizer, such that the updates don't occur in time.
b. the inner optimizer does gradient hacking / exploration hacking, such that the outer loss's updates are ineffective.
- ^
Evolution, of course, does have this structure, with 2 levels of selection, it just doesn't seem like this is a relevant property for thinking about the SLT.
I'm guessing you misunderstand what I meant when I referred to "the human learning process" as the thing that was a ~ 1 billion X stronger optimizer than evolution and responsible for the human SLT. I wasn't referring to human intelligence or what we might call human "in-context learning". I was referring to the human brain's update rules / optimizer: i.e., whatever quasi-Hebbian process the brain uses to minimize sensory prediction error, maximize reward, and whatever else factors into the human "base objective". I was not referring to the intelligences that the human base optimizers build over a lifetime.
If instead of reward circuitry inducing human values, evolution directly selected over policies, I'd expect similar inner alignment failures.
I very strongly disagree with this. "Evolution directly selecting over policies" in an ML context would be equivalent to iterated random search, which is essentially a zeroth-order approximation to gradient descent. Under certain simplifying assumptions, they are actually equivalent. It's the loss landscape an parameter-function map that are responsible for most of a learning process's inductive biases (especially for large amounts of data). See: Loss Landscapes are All You Need: Neural Network Generalization Can Be Explained Without the Implicit Bias of Gradient Descent.
Most of the difference in outcomes between human biological evolution and DL comes down to the fact that bio evolution has a wildly different mapping from parameters to functional behaviors, as compared to DL. E.g.,
- Bio evolution's parameters are the genome, which mostly configures learning proclivities and reward circuitry of the human within lifetime learning process, as opposed to DL parameters being actual parameters which are much more able to directly specify particular behaviors.
- The "functional output" of human bio evolution isn't actually the behaviors of individual humans. Rather, it's the tendency of newborn humans to learn behaviors in a given environment. It's not like in DL, where you can train a model, then test that same model in a new environment. Rather, optimization over the human genome in the ancestral environment produced our genome, and now a fresh batch of humans arise and learn behaviors in the modern environment.
Point 2 is the distinction I was referencing when I said:
"human behavior in the ancestral environment" versus "human behavior in the modern environment" isn't a valid example of behavioral differences between training and deployment environments.
Overall, bio evolution is an incredibly weird optimization process, with specific quirks that predictably cause very different outcomes as compared to either DL or human within lifetime learning. As a result, bio evolution outcomes have very little implication for DL. It's deeply wrong to lump them all under the same "hill climbing paradigm", and assume they'll all have the same dynamics.
It's also not necessary that the inner values of the agent make no mention of human values / objectives, it needs to both a) value them enough to not take over, and b) maintain these values post-reflection.
This ties into the misunderstanding I think you made. When I said:
The "inner loss function" I'm talking about here is not human values, but instead whatever mix of predictive loss, reward maximization, etc that form the effective optimization criterion for the brain's "base" distributed quasi-Hebbian/whatever optimization process. Such an "inner loss function" in the context of contemporary AI systems would not refer to the "inner values" that arise as a consequence of running SGD over a bunch of training data. They'd be something much much weirder and very different from current practice.
E.g., if we had a meta-learning setup where the top-level optimizer automatically searches for a reward function F, which, when used in another AI's training, will lead to high scores on some other criterion C, via the following process:
- Randomly initializing a population of models.
- Training them with the current reward function F.
- Evaluate those models on C.
- Update the reward function F to be better at training models to score highly on C.
The "inner loss function" I was talking about in the post would be most closely related to F. And what I mean by "Deliberately create a (very obvious[2]) inner optimizer, whose inner loss function includes no mention of human values / objectives", in the context of the above meta-learning setup, is to point to the relationship between F and C.
Specifically, does F actually reward the AIs for doing well on C? Or, as with humans, does F only reward the AIs for achieving shallow environmental correlates of scoring well on C? If the latter, then you should obviously consider that, if you create a new batch of AIs in a fresh environment, and train them on an unmodified reward function F, that the things F rewards will become decoupled from the AIs eventually doing well on C.
Returning to humans:
Inclusive genetic fitness is incredibly difficult to "directly" train an organism to maximize. Firstly, IGF can't actually be measured in an organism's lifetime, only estimated based on the observable states of the organism's descendants. Secondly, "IGF estimated from observing descendants" makes for a very difficult reward signal to learn on because it's so extremely sparse, and because the within-lifetime actions that lead to having more descendants are often very far in time away from being able to actually observe those descendants. Thus, any scheme like "look at descendants, estimate IGF, apply reward proportional to estimated IGF" would completely fail at steering an organism's within lifetime learning towards IGF-increasing actions.
Evolution, being faced with standard RL issues of reward sparseness and long time horizons, adopted a standard RL solution to those issues, namely reward shaping. E.g., rather than rewarding organisms for producing offspring, it builds reward circuitry that reward organisms for precursors to having offspring, such as having sex, which allows rewards to be more frequent and closer in time to the behaviors they're supposed to reinforce.
In fact, evolution relies so heavily on reward shaping that I think there's probably nothing in the human reward system that directly rewards increased IGF, at least not in the direct manner an ML researcher could by running a self-replicating model a bunch of times in different environments, measuring the resulting "IGF" of each run, and directly rewarding the model in proportion to its "IGF".
This is the thing I was actually referring to when I mentioned "inner optimizer, whose inner loss function includes no mention of human values / objectives.": the human loss / reward functions not directly including IGF in the human "base objective".
(Note that we won't run into similar issues with AI reward functions vs human values. This is partially because we have much more flexibility in what we include in a reward function as compared to evolution (e.g., we could directly train an AI on estimated IGF). Mostly though, it's because the thing we want to align our models to, human values, have already been selected to be the sorts of things that can be formed via RL on shaped reward functions, because that's how they actually arose at all.)
For (2), it seems like you are conflating 'amount of real world time' with 'amount of consequences-optimization'. SGD is just a much less efficient optimizer than intelligent cognition
Again, the thing I'm pointing to as the source of the human-evolutionary sharp left turn isn't human intelligence. It's a change in the structure of how optimization power (coming from the "base objective" of the human brain's updating process) was able to contribute to capabilities gains over time. If human evolution were an ML experiment, the key change I'm pointing to isn't "the models got smart". It's "the experiment stopped being quite as stupidly wasteful of compute" (which happened because the models got smart enough to exploit a side-channel in the experiment's design that allowed them to pass increasing amounts of information to future generations, rather than constantly being reset to the same level each time). Then, the reason this won't happen in AI development is that there isn't a similarly massive overhang of completely misused optimization power / compute, which could be unleashed via a single small change to the training process.
in-context learning happens much faster than SGD learning.
Is it really? I think they're overall comparable 'within an OOM', just useful for different things. It's just much easier to prompt a model and immediately see how this changes its behavior, but on head-to-head comparisons, it's not at all clear that prompting wins out. E.g., Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning
In particular, I think prompting tends to be more specialized to getting good performance in situations similar to those the model has seen previously, whereas training (with appropriate data) is more general in the directions in which it can move capabilities. Extreme example: pure language models can be few-shot prompted to do image classification, but are very bad at it. However, they can be directly trained into capable multi-modal models.
I think this difference between in-context vs SGD learning makes it unlikely that in-context learning alone will suffice for an explosion in general intelligence. If you're only sampling from the probability distribution created by a training process, then you can't update that distribution, which I expect will greatly limit your ability to robustly generalize to new domains, as compared to a process where you gather new data from those domains and update the underlying distribution with those data.
For (3), I don't think that the SLT requires the inner optimizer to run freely, it only requires one of:
a. the inner optimizer running much faster than the outer optimizer, such that the updates don't occur in time.
b. the inner optimizer does gradient hacking / exploration hacking, such that the outer loss's updates are ineffective.
(3) is mostly there to point to the fact that evolution took no corrective action whatsoever in regards to humans. Evolution can't watch humans' within lifetime behavior, see that they're deviating away from the "intended" behavior, and intervene in their within lifetime learning processes to correct such issues.
Human "inner learners" take ~billions of inner steps for each outer evolutionary step. In contrast, we can just assign whatever ratio of supervisory steps to runtime execution steps, and intervene whenever we want.
Thanks for the response!
If instead of reward circuitry inducing human values, evolution directly selected over policies, I'd expect similar inner alignment failures.
I very strongly disagree with this. "Evolution directly selecting over policies" in an ML context would be equivalent to iterated random search, which is essentially a zeroth-order approximation to gradient descent. Under certain simplifying assumptions, they are actually equivalent. It's the loss landscape an parameter-function map that are responsible for most of a learning process's inductive biases (especially for large amounts of data). See: Loss Landscapes are All You Need: Neural Network Generalization Can Be Explained Without the Implicit Bias of Gradient Descent.
I think I understand these points, and I don't see how this contradicts what I'm saying. I'll try rewording.
Consider the following gaussian process:
![What is Gaussian Process? [Intuitive Explaination] | by Joanna | Geek Culture | Medium](https://res.cloudinary.com/lesswrong-2-0/image/upload/f_auto,q_auto/v1/mirroredImages/hCy2NFrkedu3GngjZ/r4zixxawmhmz46hyorjb)
Each blue line represents a possible fit of the training data (the red points), and so which one of these is selected by a learning process is a question of inductive bias. I don't have a formalization, but I claim: if your data-distribution is sufficiently complicated, by default, OOD generalization will be poor.
Now, you might ask, how is this consistent with capabilities to generalizing? I note that they haven't generalized all that well so far, but once they do, it will be because the learned algorithm has found exploitable patterns in the world and methods of reasoning that generalize far OOD.
You've argued that there are different parameter-function maps, so evolution and NNs will generalize differently, this is of course true, but I think its besides the point. My claim is that doing selection over a dataset with sufficiently many proxies that fail OOD without a particularly benign inductive bias leads (with high probability) to the selection of function that fails OOD. Since most generalizations are bad, we should expect that we get bad behavior from NN behavior as well as evolution. I continue to think evolution is valid evidence for this claim, and the specific inductive bias isn't load bearing on this point -- the related load bearing assumption is the lack of a an inductive bias that is benign.
If we had reasons to think that NNs were particularly benign and that once NNs became sufficiently capable, their alignment would also generalize correctly, then you could make an argument that we don't have to worry about this, but as yet, I don't see a reason to think that a NN parameter function map is more likely to lead to inductive biases that pick a good generalization by default than any other set of inductive biases.
It feels to me as if your argument is that we understand neither evolution nor NN inductive biases, and so we can't make strong predictions about OOD generalization, so we are left with our high uncertainty prior over all of the possible proxies that we could find. It seems to me that we are far from being able to argue things like "because of inductive bias from the NN architecture, we'll get non-deceptive AIs, even if there is a deceptive basin in the loss landscape that could get higher reward."
I suspect you think bad misgeneralization happens only when you have a two layer selection process (and this is especially sharp when there's a large time disparity between these processes), like evolution setting up the human within lifetime learning. I don't see why you think that these types of functions would be more likely to misgeneralize.
(only responding to the first part of your comment now, may add on additional content later)
The generation dies, and all of the accumulated products of within lifetime learning are lost.
This seems obviously false. For animals that do significant learning throughout their lifetimes, it's standard for exactly the same "providing higher quality 'training data' for the next generation..." mechanism to be used.
The distinction isn't in whether learned knowledge is passed on from generation to generation. It's in whether the n+1th generation tends to pass on more useful information than the nth generation. When we see this not happening, it's because the channel is already saturated in that context.
I guess that this is mostly a consequence of our increased ability to represent useful behaviour in ways other than performing the behaviour: I can tell you a story about fighting lions without having to fight lions. (that and generality of intelligence and living in groups).
(presumably unimportant for your overall argument - though I've not thought about this :))
One thing that confuses me about the evolution metaphors is this:
Humans managed to evolve a sense of morality from what seems like fairly weak evolutionary pressure. Ie, it generally helps form larger groups to survive better, which is good, but also theres a constant advantage to being selfish and defecting. Amoral people can still accrue power and wealth and reproduce. Compare this to something like the pressure not to touch fire, which is much more acute.
The pressure to be "moral" of an AI seems significantly more powerful than that applied to humanity: If it is too out of line with it's programmers, it is killed on the spot. Imagine if when humans evolved, a god murdered any human that stole.
It seems to me that evolutionary metaphors would imply that AI would evolve to be friendly, not evil. Of course, you can't rely too much on these metaphors anyway.
I wouldn't ascribe human morality to the process of evolution. Morality is a bunch of if..., then statements. Morality seems to be more of a cultural thing and helps coordination. Morality is obviously influenced by our emotions such as disgust, love etc but these can be influenced heavily by culture, upbringing and just genes. Now let's assume the AI is getting killed if it behaves "unmoral", how can you be sure that it does not evolve to be deceptive ?
Evolutionary metaphors is about huge differences between evolutionary pressure in ancestral environment and what we have now: ice cream, transgenders, lesswrong, LLMs, condoms and other contraceptives. What kind of "ice cream" AGI and ASI will make for itself? May be it can be made out of humans, put them in vats and let them dream inputs for GPT10?
Mimicry is product of evolution too. Also - social mimicry.
I have thoughts about reasons for AI to evolve human-like morality too. But i also have thoughts like "this coin turned up heads 3 times in a row, so it must turn tails next".
Even if the AI is conditioned to care to not be terminated, it may still know how to get away with doing something 'evil' though.
The general vibe of the first two parts seems correct to me. Also, an additional point is that evolution's utility function of inclusive genetic fitness didn't completely disappear and is likely still a sub-portion of the human utility function. I suspect there is going to be disagreement on this, but it would also be interesting to do a poll on this question and break it down by people who do or do not have kids.
The LessWrong Review runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
I found this to be a very interesting and useful post. Thanks for writing it! I'm still trying to process / update on the main ideas and some of the (what I see as valid) pushback in the comments. A couple non-central points of disagreement:
I don’t expect catastrophic interference between any pair of these alignment techniques and capabilities advances.
This seems like it's because these aren't very strong alignment techniques, and not very strong capability advances. Or like, these alignment techniques work if alignment is relatively easy, or if the amount you need to nudge a system from default to aligned is relatively small. If we run into harder alignment problems, e.g., gradient hacking to resist goal modification, I expect we'll need "stronger" alignment techniques. I expect stronger alignment techniques to be more brittle to capability changes, because they're meant to accomplish a harder task, as compared to weaker alignment techniques (nudging a system farther toward alignment). Perhaps more work will go into making them robust to capability changes, but this is non-obvious — e.g., when humans are trying to accomplish a notably harder task, we often make another tool for doing so, which is intended to be robust to the harder setting (like a propeller plane vs a cargo plane, when you want to carry a bunch of stuff via the air).
I also expect that, if we end up in a regime of large capability advances, alignment techniques are generally more brittle because more is changing with your system; this seems possible if there are a bunch of AIs trying to develop new architectures and paradigms for AI training. So I'm like "yeah, the list of relatively small capabilities advances you provide sure look like things that won't break alignment, but my guess is that larger capabilities advances are what we should actually be worried about."
I still think the risks are manageable, since the first-order effect of training a model to perform an action X in circumstance Y is to make the model more likely to perform actions similar to X in circumstances similar to Y.
I don't understand this sentence, and I would appreciate clarification!
Additionally, current practice is to train language models on an enormous variety of content from the internet. The odds of any given subset of model data catastrophically interfering with our current alignment techniques cannot be that high, otherwise our current alignment techniques wouldn't work on our current models.
Don't trojans and jailbreaks provide substantial evidence against this? I think neither is perfect: trojans aren't the main target of most "alignment techniques" (but they are attributable to a small amount of training data), and jailbreaks aren't necessarily attributable to a small amount of training data alone (but they are the target of "alignment" efforts). But it feels to me like the picture of both of these together is that current alignment techniques aren't working especially well, and are thwarted via a small amount of training data.
After reading this, I tried to imagine what an ML system would have to look like if there really were an equivalent of the kind of overhang that was present in evolution. I think that if we try to make the ML analogy such that SGD = evolution, then it would have to look something like: "There are some parameters which update really really slowly (DNA) compared to other parameters (neurons). The difference is like ~1,000,000,000x. Sometimes, all the fast parameters get wiped and the slow parameters update slightly. The process starts over and the fast parameters start from scratch because it seems like there is ~0 carryover between the information in the fast parameters of last generation and the fast parameters in the new generation." In this analogy, the evolutionary-equivalent sharp left turn would be something like: "some of the information from the fast parameters is distilled down and utilized by the fast parameters of the new generation." OP touches on this and this is not what we see in practice, so I agree with OP's point here.
(I would be curious if anyone has info/link on how much certain parameters in a network change relative to other parameters. I have heard this discussed when talking about the resilience of terminal goals against SGD.)
A different analogy I thought of would be one where humans deciding on model architecture are the analogue for evolution and the training process itself is like within-lifetime learning. In these terms, if we wanted to imagine the equivalent of the sharp left turn, we could imagine that we had to keep making new models bc of finite "life-spans" and each time we started over, we used a similar architecture with some tweaks based on how the last generation of models performed (inter-generational shifts in gene frequency). The models gradually improve over time due to humans selecting on the architecture. In this analogy, the equivalent of the culture-based sharp left turn would be if humans started using the models of one generation to curate really good, distilled training data for the next generation. This would let each generation outperform the previous generations by noticeably more despite only gradual tweaks in architecture occurring between generations.
This is similar to what OP pointed out in talking about "AI iteratively refining its training data". Although, in the case that the same AI is generating and using the training data, then it feels more analogous to note taking/refining your thoughts through journaling than it does to passing on knowledge between generations. I agree with OP's concern about that leading to weird runaway effects.
I actually find this second version of the analogy where humans = evolution and SGD/training = within lifetime learning somewhat plausible. Of course, it is still missing some of the other pieces to have a sharp left turn (ie. the part where I assumed that models had short lifespans and the fact that irl models increase in size a lot each generation). Still, it does work as a bi-level optimization process where one of the levels has way more compute/happens way faster. In humans, we can't really use our brains without reinforcement learning, so this analogy would also mean that deployment is like taking a snapshot of a human brain in a specific state and just initializing that every time.
I am not sure where this analogy breaks/ what the implications are for alignment, but I think it avoids some of the flaws of thinking in terms of evolution = SGD. By analogy, that would kind of mean that when we consciously act in ways that go against evolution, but that we think are good, we're exhibiting Outer Misalignment.
By analogy, that would also mean that when we voluntarily make choices that we would not consciously endorse, we are exhibiting some level of inner misalignment. I am not sure how I feel about this one; that might be a stretch. It would make a separation between some kind of "inner learning process" in our brains that is kind of the equivalent of SGD and the rest of our brains that are the equivalent of the NN. We can act in accordance with the inner learner and that connection of neurons will be strengthened or we act against it and learn not to do that. Humans don't really have a "deployment" phase. (Although, if I wanted to be somewhat unkind I might say that some people do more or less stop actually changing their inner NNs at some point in life and only act based on their context windows.)
I don't know, let me know what you think.
I've expanded what was going to be a comment on one of the issues I have with this post into my own post here.
Summary: I think some of the arguments in this post factor through a type error, or at least an unjustified assumption that "model alignment" is comparable to systems alignment.
Also, this post seems overly focused on DL-paradigm techniques, when that is not the only frontier of capabilities.
This post prompted me to create the following Manifold Market on the likelihood of a Sharp Left Turn occuring (as described by the Tag Definition, Nate Soares, and Victoria Krakovna et. al), prior to 2050: https://manifold.markets/RobertCousineau/will-a-sharp-left-turn-occur-as-des?r=Um9iZXJ0Q291c2luZWF1
why should we even elevate the very specific claim that 'AIs will experience a sudden burst of generality at the same time as all our alignment techniques fail.' to consideration at all, much less put significant weight on it?
In my model, it is pretty expected.
Let's suppose, that the agent learns "rules" of arbitrary complexity during training, initially the rules are simple and local, such as "increase the probability of action by several log-odds in a specific context". As training progresses, the system learns more complex meta-rules, such as "apply consequentialist reasoning" and "think about the decision-making process". The system starts to think about the consequences of its decision-making process and realizes that its local rules are contradictory and lead to resource wastage. If the system tries to find a compromise between these rules, the result doesn't satisfy any rules. Additionally, the system has learned weaker meta-rules like "If rule A and rule B contradict, choose what rule B says", which can lead to funny circular priorities that resolve in unstable path-dependent way. Eventually, the system enters a long NaN state, and emerges with multiple patches to its decision-making process that may erase any trace of our alignment effort.
I've started to notice a common pattern in evolutionary analogies, where they initially suggest concerning alignment implications, which then seem to dissolve once I track the mechanistic details of what actually happened in the evolutionary context, and how that would apply to AI development. At this point, my default reaction to any evolutionary analogy about AI alignment is skepticism.
I agree. Perhaps the alignment field would be better off if we'd never thought about evolution at all, and instead had modelled the learning dynamics directly. Don't think about AIXI, don't think about evolution, think about what your gradient update equations might imply, and then run experiments to test that.
Does human evolution imply a sharp left turn from AIs?
Arguments for the sharp left turn in AI capabilities often appeal to an “evolution -> human capabilities” analogy and say that evolution's outer optimization process built a much faster human inner optimization process whose capability gains vastly outstripped those which evolution built into humans. Such arguments claim we will see a similar transition while training AIs, with SGD creating some 'inner thing' which is not SGD and which gains capabilities much faster than SGD can insert them into the AI. Then, just like human civilization exploded in capabilities over a tiny evolutionary time frame, so too will AIs explode in capabilities over a tiny "SGD time frame".
Evolution’s sharp left turn happened for evolution-specific reasons
I think that "evolution -> human capabilities" is a bad analogy for "AI training -> AI capabilities". Let’s compare evolution to within lifetime learning for a single generation of an animal species:
The only way to transmit information from one generation to the next is through evolution changing genomic traits, because death wipes out the within lifetime learning of each generation.
Now let’s look at the same comparison for humans:
Human culture allows some fraction of the current generation’s within lifetime learning to transmit directly to the next generation. In the language of machine learning, the next generation benefits from a kind of knowledge distillation, thanks to the prior generation providing higher quality 'training data' for the next generation's within-lifetime learning.
This is extremely important because within-lifetime learning happens much, much faster than evolution. Even if we conservatively say that brains do two updates per second, and that a generation is just 20 years long, that means a single person’s brain will perform ~1.2 billion updates per generation. Additionally, the human brain probably uses a stronger base optimizer than evolution, so each within-lifetime brain update is also probably better at accumulating information than a single cross-generational evolutionary update. Even if we assume that only 1 / 10,000th of the information learned by each generation makes its way into humanity's cross-generational, persistent endowment of cultural information, that still means culture advances ~100,000 times faster than biological evolution.
I think that "evolution -> human capabilities" is a very bad reference class to make predictions about "AI training -> AI capabilities". We don't train AIs via an outer optimizer over possible inner learning processes, where each inner learning process is initialized from scratch, then takes billions of inner learning steps before the outer optimization process takes one step, and then is deleted after the outer optimizer's single step. Such a bi-level training process would necessarily experience a sharp left turn once each inner learner became capable of building off the progress made by the previous inner learner (which happened in humans via culture / technological progress from one generation to another).
However, this sharp left turn does not occur because the inner learning processes suddenly become much better / more foomy / more general in a handful of outer optimization steps. It happens because you devoted billions of times more optimization power to the inner learning processes, but then deleted each inner learner shortly thereafter. Once the inner learning processes become able to pass non-trivial amounts of knowledge along to their successors, you get what looks like a sharp left turn. But that sharp left turn only happens because the inner learners have found a kludgy workaround past the crippling flaw where they all get deleted shortly after initialization.
In my frame, we've already figured out and applied the sharp left turn to our AI systems, in that we don't waste our compute on massive amounts of incredibly inefficient neural architecture search, hyperparameter tuning, or meta optimization. For a given compute budget, the best (known) way to buy capabilities is to train a single big model in accordance with empirical scaling laws such as those discovered in the Chinchilla paper, not to split the compute budget across millions of different training runs for vastly tinier models with slightly different architectures and training processes. In fact, we can be even more clever and use small models to tune the training process, before scaling up to a single large run, as OpenAI did with GPT-4.
(See also: Gwern on the blessings of scale.)
It’s true that we train each new AI from scratch, rather than reusing any of the compute that went into previous models. However, the situation is very different from human evolution because each new state of the art model uses geometrically more compute than the prior state of the art model. Even if we could perfectly reuse the compute from previous models, it wouldn't be nearly so sharp an improvement to the rate of progress as occurred in the transition from biological evolution to human cultural accumulation. I don’t think it’s plausible for AI capabilities research to have the same sort of hidden factor of ~billion resource overhang that can be suddenly unleashed in a short-to-humans timescale.
The capabilities of ancestral humans increased smoothly as their brains increased in scale and/or algorithmic efficiency. Until culture allowed for the brain’s within-lifetime learning to accumulate information across generations, this steady improvement in brain capabilities didn’t matter much. Once culture allowed such accumulation, the brain’s vastly superior within-lifetime learning capacity allowed cultural accumulation of information to vastly exceed the rate at which evolution had been accumulating information. This caused the human sharp left turn.
However, the impact of scaling or algorithmic improvements on the capabilities of individual brains is still continuous. which is what matters for predicting how suddenly AI capabilities will increase as a result of scaling or algorithmic improvements. Humans just had this one particular bottleneck in cross-generational accumulation of capabilities-related information over time, leading to vastly faster progress once culture bypassed this bottleneck.
Don't misgeneralize from evolution to AI
Evolution's sharp left turn happened because evolution spent compute in a shockingly inefficient manner for increasing capabilities, leaving vast amounts of free energy on the table for any self-improving process that could work around the evolutionary bottleneck. Once you condition on this specific failure mode of evolution, you can easily predict that humans would undergo a sharp left turn at the point where we could pass significant knowledge across generations. I don't think there's anything else to explain here, and no reason to suppose some general tendency towards extreme sharpness in inner capability gains.
History need not repeat itself. Human evolution is not an allegory or a warning. It was a series of events that happened for specific, mechanistic reasons. If those mechanistic reasons do not extend to AI research, then we ought not (mis)apply the lessons from evolution to our predictions for AI.
This last paragraph makes an extremely important claim that I want to ensure I convey fully:
- IF we understand the mechanism behind humanity's sharp left turn with respect to evolution
- AND that mechanism is inapplicable to AI development
- THEN, there's no reason to reference evolution at all when forecasting AI development rates, not as evidence for a sharp left turn, not as an "illustrative example" of some mechanism / intuition which might supposedly lead to a sharp left turn in AI development, not for anything.
Here's an analogy to further illustrate the point:
My point is that other car builders can learn ~zero lessons from EVO-Inc.[1] The mechanism behind their cars' spontaneous detonation is easily avoided by not using landmines as hubcaps. The organizational-level failures that led to this design choice on EVO-Inc.'s part are also easily avoided by not being insane space clowns. We should not act like there might be some general factor of "explodeyness" which will infect other car building efforts, simply by virtue of those efforts tackling a similar problem to the one EVO-Inc. failed at.
EVO-Inc's failures arose from mechanisms which do not apply to human organizations tackling similar problems. EVO-Inc. didn't use landmines as hubcaps because they were run by greedy, myopic executives who cut corners on safety to increase profits. They didn't do so because they were naive optimists who failed to understand why building non-exploding cars is hard like computer security or rocket science, and who failed to apply proper security mindset to their endeavors. EVO-Inc used landmines as hubcaps because they were run by insane space clowns who did insane space clown things.
Human car builders may have to tackle problems superficially similar to the spontaneous combustion of the EVO-Inc. cars. E.g., they may have to design the fuel tanks of their cars to avoid combustion during a crash. However, those efforts still should not take lessons from EVO-Inc. E.g., if other car builders were to look at crash data from EVO-Inc.'s cars, and naively generalize from the surface-level outcomes of an EVO-Inc. car crash to their own mechanistically different circumstances, they might assume that supersonic fragments posed a significant risk during a crash, and then add ballistic armor between the driver and the wheels, despite this doing nothing to prevent a car's fuel tank from igniting during a crash.
I think our epistemic relationship with evolution's example should be about the same as the human car builders' epistemic relationship with EVO-Inc. Evolution's combined sharp left turn and alignment failures happened because evolution is a very different process compared to human-led AI development, leading to evolution-specific mechanisms, which no sane AI developer would replicate.
In order to experience a sharp left turn that arose due to the same mechanistic reasons as the sharp left turn of human evolution, an AI developer would have to:
This is the AI development equivalent of using landmines as hubcaps. It's not just that this is an insane idea from an alignment perspective. It's also an insane idea from just about any other perspective. Even if you're only trying to maximize AI capabilities, it's a terrible idea to have such an extreme disparity in resources between the inner and outer loops.
AI researchers have actually experimented with bi-level optimization processes such as neural architecture search and second-order meta learning. Based on current results, I don't think anything approaching multiple orders of magnitude difference in resource use between the inner and outer optimizers is plausible. It's just not efficient, and we have better approaches. From the GPT-4 paper:
Even if we could magically repurpose all of the compute used throughout OpenAI's tuning of the GPT-4 architecture / training process, I doubt it would even amount to as much compute as they used in the final GPT-4 training run, much less exceed that quantity by orders of magnitude. Modern training practices simply lack that sort of free energy.
See also: Model Agnostic Meta Learning proposed a bi-level optimization process that used between 10 and 40 times more compute in the inner loop, only for Rapid Learning or Feature Reuse? to show they could get about the same performance while removing almost all the compute from the inner loop, or even by getting rid of the inner loop entirely.
Fast takeoff is still possible
The prior sections argue that we should not use an evolutionary analogy as evidence that an inner learner will sufficiently outperform the outer optimizer that constructed it so as to cause a massive spike in capabilities as a result of the same mechanisms that drove the sharp left turn in human evolution.
However, introducing new types of positive feedback loops across multiple training runs may lead to fast takeoff, but it would be a mechanistically different process than the evolutionary sharp left turn, meaning there's no reason to assume takeoff dynamics mirroring those of human evolution. There are two specific mechanisms that I think could produce a fast takeoff:
If fast takeoff is still plausible, why does the specific type of positive feedback loop matter? What changes, as a result of considering various AI-specific fast takeoff mechanisms, as opposed to the general expectation of sudden transitions, as implied by the evolution analogy? Here are four alignment-relevant implications:
However, the process responsible for human breadth of generality was not some small architectural modification evolution made to the human brain. It was humanity's cross-generational process of expanding and improving our available "training data" to cover a broader and broader range of capabilities across many domains (a process we sometimes call "science"). The evolutionary analogy thus offers no reason to expect sudden jumps in generality without corresponding extensions of the training data.
Without this evolutionary analogy, why should we even elevate the very specific claim that 'AIs will experience a sudden burst of generality at the same time as all our alignment techniques fail.' to consideration at all, much less put significant weight on it?
Will alignment generalize across sudden capabilities jumps?
The previous section argued that the mechanisms driving the sharp left turn in human evolution are not present in AI development, and so we shouldn't generalize from the results of human evolution to those of AI development, even when considering positive feedback loops whose surface-level features are reminiscent of the sharp left turn in human evolution.
This section will first reference and briefly summarize some past writing of mine arguing that our "misalignment" with inclusive genetic fitness isn't evidence for AI misalignment with our values. Then, I'll examine both mechanisms for a possible fast takeoff that I described above from an "inside view" machine learning perspective, rather than assuming outcomes mirroring those of human evolutionary history.
Human "misalignment" with inclusive genetic fitness provides no evidence for AI misalignment
I previously wrote a post, Evolution is a bad analogy for AGI: inner alignment, arguing that evolutionary analogies between human values and inclusive genetic fitness have little to tell us about the degree of values misgeneralization we should expect from AI training runs, and that analogies to human within-lifetime learning are actually much more informative[6].
I also wrote this subsection in a much longer post, which explains why I think evolution is mechanistically very different from AI training, such that we cannot easily infer lessons about AI misgeneralization by looking at how human behaviors differ between the modern and ancestral environments.
Very briefly: "human behavior in the ancestral environment" versus "human behavior in the modern environment" isn't a valid example of behavioral differences between training and deployment environments. Humans weren't "trained" in the ancestral environment, then "deployed" in the modern environment. Instead, humans are continuously "trained" throughout our lifetimes (via reward signals and sensory predictive error signals). Humans in the ancestral and modern environments are different "training runs".
As a result, human evolution is not an example of:
It's an example of:
The near-total misalignment between inclusive genetic fitness and human values is an easily predicted consequence of this (evolution-specific) bi-level optimization paradigm, just like the human sharp left turn is an easily predicted consequence of the (evolution-specific) extreme resource disparity between the two optimization levels. And just like evolution provides no reason to assume our own AI development efforts will experience a sharp left turn, so to does evolution not provide any reason to assume our AI development efforts will show extreme misgeneralization between training and deployment.
Capabilities jumps due to AI driving AI capabilities research
For the first mechanism of AIs contributing to AI capability research, I first note that this is an entirely different sort of process than the one responsible for the human sharp left turn. Evolution made very few modifications to the human brain's architecture during the timeframe in which our cultural advancement catapulted us far beyond the limits of our ancestral capabilities. Additionally, humans have so far been completely incapable of changing our own architectures, so there was never a positive feedback loop of the sort that we might see with AIs researching AI capabilities.
Because of this large difference in underlying process between this possible fast takeoff mechanism and the evolutionary sharp left turn, I think we should mostly rely on the current evidence available from AI development for our predictions of future AI development, rather than analogies to our evolutionary history. Additionally, I claim that alignment techniques already generalize across human contributions to AI capability research. Let’s consider eight specific alignment techniques:
and eleven recent capabilities advances:
I don’t expect catastrophic interference between any pair of these alignment techniques and capabilities advances. E.g., if you first develop your RLHF techniques for models trained using the original OpenAI scaling laws, I expect those techniques to transfer pretty well to models trained with the Chinchilla scaling laws.
I expect there is some interference. I expect that switching your architecture from a vanilla transformer to a RETRO architecture will cause issues like throwing off whatever RLHF hyperparameters you’d found worked best for the vanilla architecture, or complicate analysis of the system because there’s now an additional moving part (the retrieval mechanism), which you also need to track in your analysis.
However, I expect we can overcome such issues with “ordinary” engineering efforts, rather than, say, RLHF techniques as a whole becoming entirely useless for the new architecture. Similarly, whatever behavioral analysis pipeline you’d developed to track models based on the vanilla architecture can probably be retrofitted for models based on the RETRO architecture without having to start from scratch.
Importantly, the researchers behind the capabilities advances were not explicitly optimizing to maintain backward compatibility with prior alignment approaches. I expect that we can decrease interference further by just, like, bothering to even try and avoid it.
I’d like to note that, despite my optimistic predictions above, I do think we should carefully measure the degree of interference between capabilities and alignment techniques. In fact, doing so seems very very important. And we can even start right now! We have multiple techniques for both alignment and capabilities. You can just choose a random alignment technique from the alignment list, a random capabilities technique from the capabilities list, then see if applying the capabilities technique makes the alignment technique less effective.
The major exception to my non-interference claim is for alignment techniques that rely on details of trained models’ internal structures, such as mechanistic interpretability. CNNs and transformers require different sorts of interpretability techniques, and likely have different flavors of internal circuitry. This is one reason why I’m more skeptical of mechanistic interpretability as an alignment approach[7].
Capabilities jumps due to AI iteratively refining its training data
I think the second potential fast takeoff mechanism, of AIs continuously refining their training data, is riskier, since it allows strange feedback loops that could take an AI away from human-compatible values. Additionally, most current models derive values and goal-orientated behaviors much more from their training data, as opposed to their architecture, hyperparameters, and the like.
E.g., I expect that choosing to use the LION optimizer in place of the Adam optimizer would have very little impact on, say, the niceness of a language model you were training, except insofar as your choice of optimizer influences the convergence of the training process. Architecture choices seem 'values neutral' in a way that data choices are not.
I still think the risks are manageable, since the first-order effect of training a model to perform an action X in circumstance Y is to make the model more likely to perform actions similar to X in circumstances similar to Y. Additionally, current practice is to train language models on an enormous variety of content from the internet. The odds of any given subset of model data catastrophically interfering with our current alignment techniques cannot be that high, otherwise our current alignment techniques wouldn't work on our current models.
However, second order effects may be less predictable, especially longer term second-order effects of, e.g., training future models on the outputs of current models. Such iterative approaches appear to be gaining popularity, now that current LMs are good enough to do basic data curation tasks. In fact, one of the linked alignment approaches, ConstitutionalAI, is based on using LMs to rewrite texts that they themselves will then train on. Similar recent approaches include:
Although this potential fast takeoff mechanism more closely resembles the mechanisms of cultural development responsible for the human sharp left turn, I think there are still important differences that make a direct extrapolation form human evolutionary history inappropriate. Most prominently, a data refinement fast takeoff wouldn't coincide with exploiting the same sort of massive resource overhang that came into play during the human sharp left turn.
Additionally, I expect there are limits to how far AIs can improve their training data without having to run novel experiments and gather data different from their initial training data. I expect it will be difficult to extend their competency to a new domain without actually gathering new data from that domain, similar to how human scientific theory only progresses so far in the absence of experimental data from a new domain.
Conclusion
I think that evolution is a bad analogy for AI development. I previously argued as much in the context of inner alignment concerns, and I've also argued that evolution is actually very mechanistically different from the process of training an AI.
Our evolutionary history has all sorts of difficult-to-track details that really change how we should derive lessons from that history. In this post, the detail in question was the enormous disparity between the optimization strength of biological evolution versus brain-based within lifetime learning, leading to a giant leap in humanity's rate of progress, once within lifetime learning could compound over time via cultural transmission.
I've started to notice a common pattern in evolutionary analogies, where they initially suggest concerning alignment implications, which then seem to dissolve once I track the mechanistic details of what actually happened in the evolutionary context, and how that would apply to AI development. At this point, my default reaction to any evolutionary analogy about AI alignment is skepticism.
Other than "don't take automotive advice from insane space clowns", of course.
If you suspect that you've maybe accidentally developed an evolution-style inner optimizer, look for a part of your system that's updating its parameters ~a billion times more frequently than your explicit outer optimizer.
- "inner optimizer" = the brain.
- "inner loss function" = the combination of predictive processing and reward circuitry that collectively make up the brain's actual training objective.
- "inner loss function includes no mention human values / objectives" because the brain's training objective includes no mention of inclusive genetic fitness.
Reflects the enormous disparity in optimization strength between biological evolution and human within-lifetime learning, which I've been harping on about this whole post.
Evolution doesn't intervene in our within-lifetime learning processes if it looks like we're not learning the appropriate fitness-promoting behavior.
It's not even that I think human within-lifetime learning is that informative. It's just that I think "being more informative than evolution" is such a stupidly low bar that human within-lifetime learning clears it by a mile.
I do think there’s a lot of value in mechanistic interpretability as a source of evidence about the mechanics and inductive biases of SGD. For example, this paper discovered “name mover heads”, attention heads that copy a speaker’s name to the current token in specific contexts, and also discovered “backup name mover heads”, which are attention heads that don’t normally appear to act as name mover heads, but when researchers ablated the primary name mover heads, the backup name mover heads changed their behavior to act as name mover heads.