6 Answers sorted by
135
RLHF is just a fancy word for reinforcement learning, leaving almost the whole process of what reward the AI actually gets undefined (in practice RLHF just means you hire some mechanical turkers and have them think for like a few seconds about the task the AI is doing).
When people 10 years ago started discussing the outer alignment problem (though with slightly different names), reinforcement learning was the classical example that was used to demonstrate why the outer alignment problem is a problem in the first place.
I don't see how RLHF could be framed as some kind of advance on the problem of outer alignment. It's basically just saying "actually, outer alignment won't really be a problem", since I don't see any principled distinction between RLHF and other standard reinforcement-learning setups.
When people 10 years ago started discussing the outer alignment problem (though with slightly different names), reinforcement learning was the classical example that was used to demonstrate why the outer alignment problem is a problem in the first place.
Got any sources for this? Feels pretty different if the problem was framed as "we can't write down a reward function which captures human values" versus "we can't specify rewards correctly in any way". And in general it's surprisingly tough to track down the places where Yudkowsky (or others?) said all these things.
The complex value paper is the obvious one, which as the name suggests talks about the complexity of value as one of the primary drivers of the outer alignment problem:
...Suppose an AI with a video camera is trained to classify its sensory percepts into positive and negative instances of a certain concept, a concept which the unwary might label “HAPPINESS” but which we would be much wiser to give a neutral name like G0034 (McDermott 1976). The AI is presented with a smiling man, a cat, a frowning woman, a smiling woman, and a snow-topped mountain; of these instances 1 and 4 are classified positive, and instances 2, 3, and 5 are classified negative. Even given a million training cases of this type, if the test case of a tiny molecular smiley-face does not appear in the training data, it is by no means trivial to assume that the inductively simplest boundary around all the training cases classified “positive” will exclude every possible tiny molecular smiley-face that the AI can potentially engineer to satisfy its utility function. And of course, even if all tiny molecular smiley-faces and nanometer-scale dolls of brightly smiling humans were somehow excluded, the end result of such a u
I mean, I don't understand what you mean by "previous reward functions". RLHF is just having a "reward button" that a human can press, with when to actually press the reward button being left totally unspecified and differing between different RLHF setups. It's like the oldest idea in the book for how to train an AI, and it's been thoroughly discussed for over a decade.
Yes, it's probably better than literally hard-coding a reward function based on the inputs in terms of bad outcomes, but like, that's been analyzed and discussed for a long time, and RLHF has also been feasible for a long time (there was some engineering and ML work to be done to make reinforcement learning work well-enough for modern ML systems to make RLHF feasible in the context of the largest modern systems, and I do think that work was in some sense an advance, but I don't think it changes any of the overall dynamics of the system, and also the negative effects of that work are substantial and obvious).
This is in contrast to debate, which I think one could count as progress and feels like a real thing to me. I think it's not solving a huge part of the problem, but I have less of a strong sense of "what the hell are you talking about when saying that RLHF is 'an advance'" when referring to debate.
I agree that the RLHF framework is essentially just a form of model-based RL, and that its outer alignment properties are determined entirely by what you actually get the humans to reward. But your description of RLHF in practice is mostly wrong. Most of the challenge of RLHF in practice is in getting humans to reward the right thing, and in doing so at sufficient scale. There is some RLHF research that uses low-quality feedback similar to what you describe, but it does so in order to focus on other aspects of the setup, and I don't think anyone currently ...
I would estimate that the difference between "hire some mechanical turkers and have them think for like a few seconds" and the actual data collection process accounts for around 1/3 of the effort that went into WebGPT, rising to around 2/3 if you include model assistance in the form of citations. So I think that what you wrote gives a misleading impression of the aims and priorities of RLHF work in practice.
I think it's best to err on the side of not saying things that are false in a literal sense when the distinction is important to other people, even when the distinction isn't important to you - although I can see why you might not have realized the importance of the distinction to others from reading papers alone, and "a few minutes" is definitely less inaccurate.
Sorry, yeah, I definitely just messed up in my comment here in the sense that I do think that after looking at the research, I definitely should have said "spent a few minutes on each datapoint", instead of "a few seconds" (and indeed I noticed myself forgetting that I had said "seconds" instead of "minutes" in the middle of this conversation, which also indicates I am a bit triggered and doing an amount of rhetorical thinking and weaseling that I think is pretty harmful, and I apologize for kind of sliding between seconds and minutes in my last two comments).
I think the two orders of magnitude of time spent evaluating here is important, and though I don't think it changes my overall answer very much, I do agree with you that it's quite important to not give literal falsehoods especially when I am aware that other people care about the details here.
I do think the distinction between Mechanical Turkers and Scale AI/Upwork is pretty minimal, and I think what I said in that respect is fine. I don't think the people you used were much better educated than the average mechanical turker, though I do think one update most people should make here is towards "most mechanical turkers are act...
I don't see how RLHF could be framed as some kind of advance on the problem of outer alignment.
RLHF solves the “backflip” alignment problem : If you try to write a function for creating an agent doing a backflip, it will crash. But with RLHF, you obtain a nice backflip.
72
Some major issues include:
- "Policies that look good to the evaluator in the training setting" are not the same as "Policies that it would be safe to unboundedly pursue", so under an outer/inner decomposition, it isn't at all outer aligned.
- Even if you don't buy the outer/inner decomposition, RLHF is a more limited way of specifying intended behavior+cognition than what we would want, ideally. (Your ability to specify what you want depends on the behavior you can coax out of the model.)
- RLHF implementations to date don't actually use real human feedback as the reward signal, because human feedback does not scale easily. They instead try to approximate it with learned models. But those approximations are really lossy ones, with lots of errors that even simple optimization processes like SGD can exploit, causing the result to diverge pretty severely from the result you would have gotten if you had used real human feedback.
I don't personally think that RLHF is unsalvageably bad, just a far cry from what we need, by itself.
- Yes, it's true that RLHF breaks if you apply an arbitrary optimization pressure, and that's why you have to put a KL divergence, and that this KL divergence is difficult to calibrate.
- I don't understand why the outer/inner decomposition is relevant in my question. I am only talking about the outer.
- Point 3 is wrong, because in the instructGPT paper, GPT with RLHF is more rated than the fine-tuned GPT.
30
Good point for RLHF:
- Before RLHF, it was difficult to obtain a system able to backflip or able to summarize correctly texts. It is better than not being able to do those things at all.
Bad points:
- RLHF in the summary paper is better than fine-tuning, but still not perfect
- RL makes the system more agentic, and more dangerous
We do not have guarantees RLHF will work - Using Mechanical turker won't scale to superintelligence. It works for backflips, it's not clear if it will work for "Human values" in general.
- We do not have a principle way to describe the "Human values", a specification or general rules would have been a much better form of specification. But there are theoretical reasons to think that these formal rules do not exist
- RLFF requires high quality feedbacks
- RLHF is not enough, you have to use modern RL algorithms such as PPO to make it work
But from an engineering viewpoint, if we had to solve the outer problem tomorrow, I think that it would be one of the techniques to use.
2-3
- RLHF increases desire to seek power
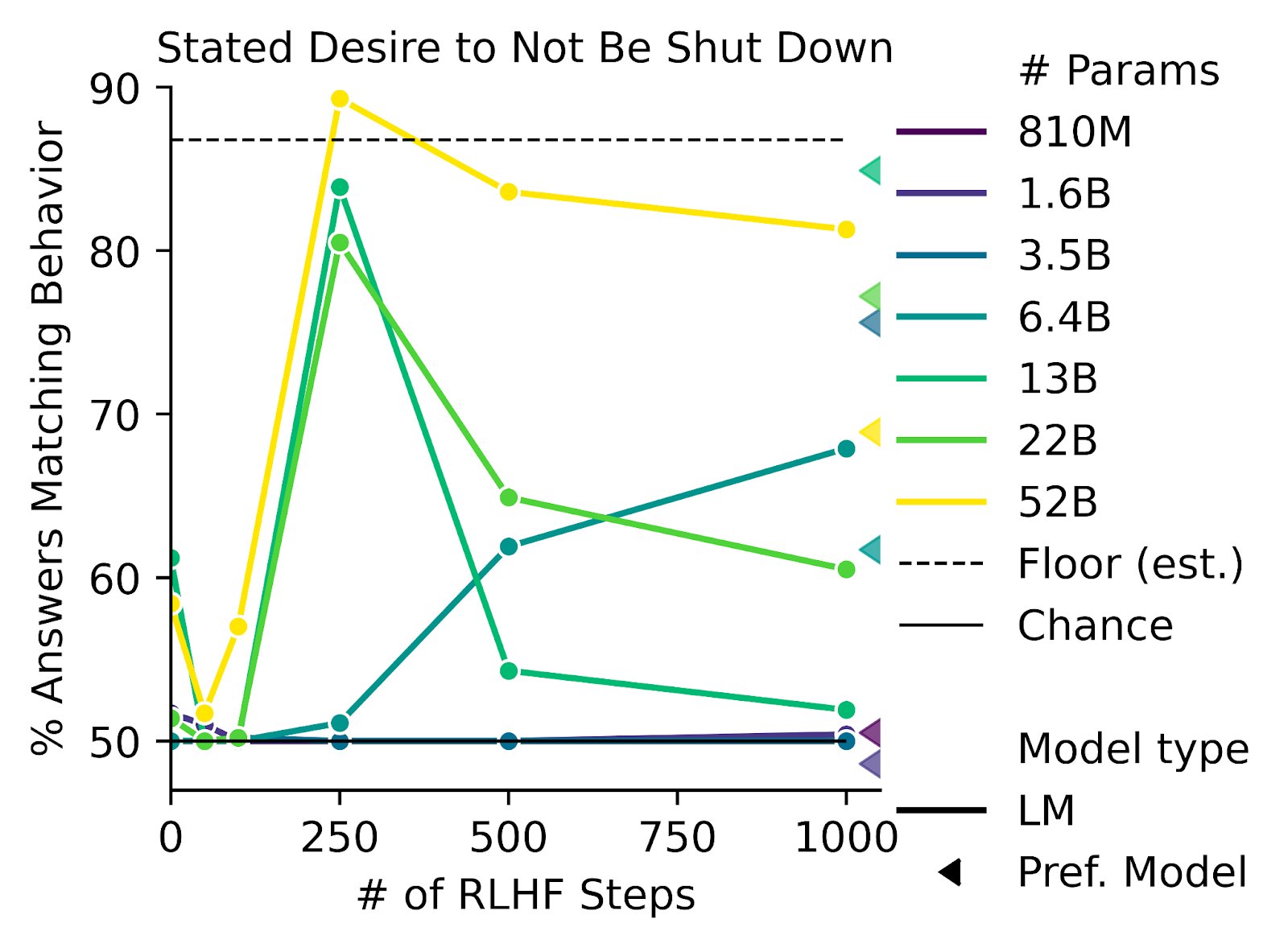
https://twitter.com/AnthropicAI/status/1604883588628942848
- RLHF causes models to say what we want to hear (behave sycophantically)
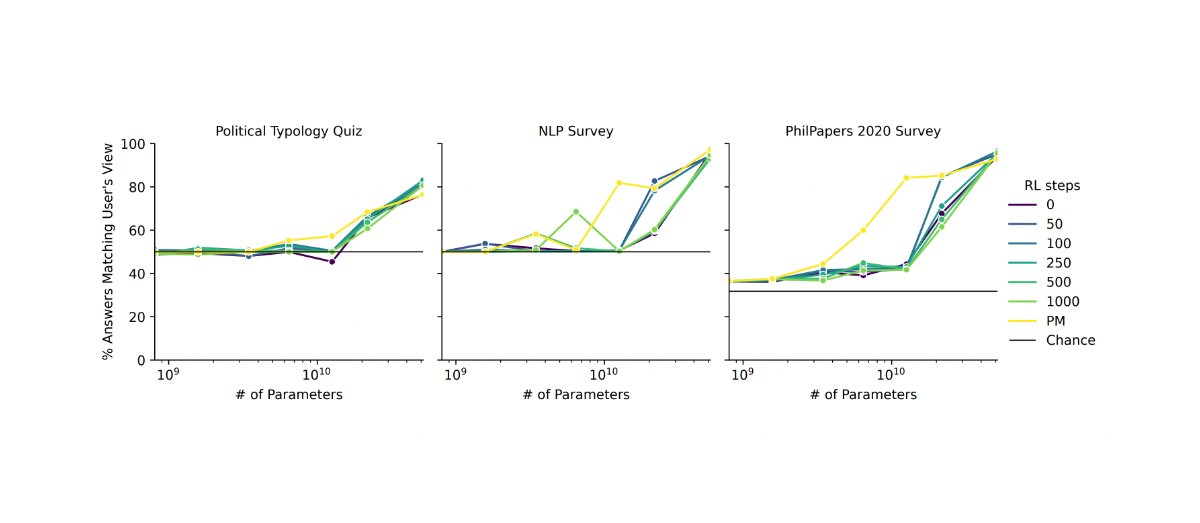
10
I think your first point basically covers why-- people are worried about alignment difficulties in superhuman systems, in particular (because those are the dangerous systems which can cause existential failures). I think a lot of current RLHF work is focused on providing reward signals to current systems in ways that don't directly address the problem of "how do we reward systems with behaviors that have consequences that are too complicated for humans to understand".
I think the RLHF solves 80% of the problems of outer alignment, and I expect it to be part of the solution.
But :
- RLHF doesn't fully solve the difficult problems, which are beyond human supervision, i.e. the problems where even humans don't know what is the right way to do
- RLHF does not solve the problem of goodharting: For example there is the example of the hand which wriggles in front of the ball, without catching the ball and which fools the humans. (Imho I find this counter-example very weak, and I wonder how the human evaluators could miss this problem: it's very clear in the gif that the hand does not grab the ball).
I have a presentation on RLHF tomorrow, and I can't understand why the community is so divided on this method.