Should agency remain an informal concept?
The discussion of the different conceptualisations of agency in the paper left me confused. The authors pull a number of different strings, some of them are hardly related to each other:
- “Agent is a system that would adapt their policy if their actions influenced the world in a different way”
- Accidentality: "In contrast, the output of non-agentic systems might accidentally be optimal for producing a certain outcome, but these do not typically adapt. For example, a rock that is accidentally optimal for reducing water flow through a pipe would not adapt its size if the pipe was wider."
- Intentional stance
- “Our definition is important for goal-directedness, as it distinguishes incidental influence that a decision might have on some variable, from more directed influence: only a system that counterfactually adapts can be said to be trying to influence the variable in a systematic way.” — here, it’s unclear what does it mean to adapt “counterfactually”.
- Learning behaviour, as discussed in section 1.3, and also in the section "Understanding a system with the process of its creation as an agent" below.
I'm not sure this is much of an improvement over Russell and Norvig's classification of agents, which seems to capture most of the same threads, and also the fact that agency is more of a gradient than a binary yes/no property. This is also consistent with minimal physicalism, the scale-free understanding of cognition (and, hence, agency) by Fields et al.
"Agent" is such a loaded term that I feel it would be easier to read the paper if the authors didn't attempt to "seize" the term "agent" but instead used, for example, the term "consequentialist". The term “agent” carries too much semantic burden. Most readers probably already have an ingrained intuitive understanding of this word or have their own favourite theory of agency. So, readers should fight a bias in their head while reading the paper and nonetheless risk misunderstanding it.
Understanding a system with the process of its creation as an agent
[…] our definition depends on whether one considers the creation process of a system when looking for adaptation of the policy. Consider, for example, changing the mechanism for how a heater operates, so that it cools rather than heats a room. An existing thermostat will not adapt to this change, and is therefore not an agent by our account. However, if the designers were aware of the change to the heater, then they would likely have designed the thermostat differently. This adaptation means that the thermostat with its creation process is an agent under our definition. Similarly, most RL agents would only pursue a different policy if retrained in a different environment. Thus we consider the system of the RL training process to be an agent, but the learnt RL policy itself, in general, won’t be an agent according to our definition (as after training, it won’t adapt to a change in the way its actions influence the world, as the policy is frozen).
I think most readers have a strong intuition that agents are physical systems. A system with its creation process is actually a physical object in the BORO ontology (where a process is a 4D spacetime object, and any collection of objects can be seen as an object, too) and probably some other approaches to ontology, but I suspect this might be highly counterintuitive to most readers, so perhaps warrants some discussion.
Also, I think that a “learnt RL policy” can mean either an abstract description of behaviour or a physical encoding of this description on some information storage device. Neither of these can intuitively be an “agent”, so I would stick with simply “RL agent” (meaning “a physical object that acts according to a learned policy”) in this sentence again, to avoid confusion.
I think the authors of the paper had a goal of bridging the gap between the real world roamed by suspected agents and the mathematical formalism of causal graphs. From the conclusion:
We proposed the first formal causal definition of agents. Grounded in causal discovery, our key contribution is to formalise the idea that agents are systems that adapt their behaviour in response to changes in how their actions influence the world. Indeed, Algorithms 1 and 2 describe a precise experimental process that can, in principle and under some assumptions, be done to assess whether something is an agent. Our process is largely consistent with previous, informal characterisations of agents (e.g. Dennett, 1987; Flint, 2020; Garrabrant, 2021; Wiener, 1961), but making it formal enables agents and their incentives to be identified empirically [emphasis mine — Roman Leventov] or from the system architecture.
There are other pieces of language that hint that the authors see their contributions as epistemological rather than mathematical (all emphasis is mine):
We derive the first causal discovery algorithm for discovering agents from empirical data.
[Paper’s contributions] ground game graph representations of agents in causal experiments. These experiments can be applied to real systems, or used in thought-experiments to determine the correct game graph and resolve confusions (see Section 4).
However, I don’t think the authors created a valid epistemological method for discovering agents from empirical data. In the following sections, I lay out the arguments supporting this claim.
For the mechanism variables that the modeller can’t intervene and gain information about which only via observing their corresponding object-level variables, it doesn’t make sense to draw a causal link from the mechanism to the object-level variable
If the mechanism variable can’t be intervened and is only observed through its object-level variable, then this mechanism is purely a product of the modeller’s imagination and can be anything.
Such mechanism variables, however, still have a place on the causal graphs: they are represented physically by the modeller (e. g. stored in the computer memory, or in the modeller’s brain) and these representations do physically affect other modeller’s representations, including of other variables, and their decision policies. For example, in graph 1c, the mechanisms of all three variables should be seen as stored in the mouse’s brain:
The causal links → and → point from the object-level to the mechanism variables because the mouse learns the mechanisms by observing the object-level.
An example of a mechanism variable which we can’t intervene in, but may observe independently from the object-level is humans’ explicit report of their preferences, separate from what is revealed in their behaviour (e. g. in the content recommendation setting, which I explore in more detail below).
In section 5.2 “Modelling advice”, the authors express a very similar idea:
It should be fully clear both how to measure and how to intervene on a variable. Otherwise its causal relationship to other variables will be ill-defined. In our case, this requirement extends also to the mechanism of each variable.
This idea is similar because the modeller often can’t intervene in the abstract “mechanism” attached to an object-level variable which causes it, but the modeller always can intervene on its own belief about this mechanism. And if mechanism variables represent the modeller’s beliefs rather than “real mechanisms” (cf. Dennett’s real patterns), then it’s obvious that the direction of the causal links should be from the object-level variables to the corresponding beliefs about their mechanism, rather than vice versa.
So, I agree with this last quote, but it seems to contradict a major chunk of the other paper’s content.
There is no clear boundary between the object-level and the mechanism variables
In explaining mechanism and object-level variables, the authors seemingly jump between reasoning within a mathematical formalism of SCMs (or a simulated environment, where all mechanisms are explicitly specified and are controllable by the simulator; this environment doesn’t differ much from a mathematical formalism) and within a real world.
The mathematical/simulation frame:
The intended interpretation is that the mechanism variables parameterise how the object-level variables depend on their object-level parents.
The formalism doesn’t tell us anything about how to distinguish between object-level and mechanism variables: object-level variables are just the variables that are included in the object-level graph, but that itself is arbitrary. For example, in section 4.4, the authors note that Langlois and Everitt (2021) included the decision rule in the game graph, but it should have been a mechanism variable. However, in the content recommendation setting (section 4.2), the “human model” () is clearly a mechanism variable for the original human preferences (), but is nevertheless included in the object-level graph because other object-level variables depend on it.
There are also two phrases in section 3.3 that suppose a mathematical frame. First, “the set of interventional distributions generated by a mechanised SCM” (in Lemma 2) says that interventional distributions are created by the model, rather than by the physical system (the algorithm executor) performing the interventions in the modelled world. Second, the sentence “Applied to the mouse example of Fig. 1, Algorithm 1 would take interventional data from the system and draw the edge-labelled mechanised causal graph in Fig. 1c.” doesn’t emphasise the fact that an algorithm is always performed by an executor (a physical system) and it’s important who that executor is, including for the details of the algorithm (cf. Deutsch’s and Marletto’s constructor theory of information). Algorithms don’t execute themselves.
The real-world frame:
An intervention on an object-level variable changes the value of without changing its mechanism, . This can be interpreted as the intervention occurring after all mechanisms variables have been determined/sampled [emphasis mine - Roman Leventov].
In section 3.5, it is said that mechanised SCM is a “physical representation of the system”.
The distinction between mechanism and object-level variables can be made more concrete by considering repeated interactions. In Section 1.1, assume that the mouse is repeatedly placed in the gridworld, and can adapt its decision rule based (only) on previous episodes. A mechanism intervention would correspond to a (soft) intervention that takes place across all time steps, so that the mouse is able to adapt to it. Similarly, the outcome of a mechanism can then be measured by observing a large number of outcomes of the game, after any learning dynamics has converged. Finally, object-level interventions correspond to intervening on variables in one particular (postconvergence) episode.
[In this quote, the authors used both the terms “interaction” and “episode” to point to the same concept, but I stick to the former because in the Reinforcement Learning literature, the term “episode” has a meaning slightly different from the meaning that is implied by the authors in this quote. — Roman Leventov]
I read from this quote that the authors take an inductive bias that mechanism variables update slowly, so we take a simplifying assumption that they don’t update at all within a single interaction. However, I think this assumption is dangerously ignorant for reasoning about agents capable of reflection and explicit policy planning. Such agents (including humans) can switch their policy (i. e., the mechanism) of making a certain kind of decision in response to a single event. And other agents in the game, aware of this possibility, can and should take it into account, effectively modelling the game as having direct causal paths from some object-level variables into the mechanism variables, which in turn inform their own decisions.
Optimising a model of a human
If, as is common in practice, the model was obtained by predicting clicks based on past user data, then changing how a human reacts to recommended content (), would lead to a change in the way that predicted clicks depend on the model of the original user (). This means that there should be an edge, as we have drawn in Fig. 3b. Everitt et al. (2021a) likely have in mind a different interpretation, where the predicted clicks are derived from 𝑀 according to a different procedure, described in more detail by Farquhar et al. (2022). But the intended interpretation is ambiguous when looking only at Fig. 3a – the mechanised graph is needed to reveal the difference.
Why does all this matter? Everitt et al. (2021a) use Fig. 3a to claim that there is no incentive for the policy to instrumentally control how the human’s opinion is updated and they deem the proposed system safe as a result. However, under one plausible interpretation, our causal discovery approach yields the mechanised causal graph representation of Fig. 3b, which contains a directed path → . This can be interpreted as the recommendation system is influencing the human in a goal-directed way, as it is adapting its behaviour to changes in how the human is influenced by its recommendation (cf. discussion in Section 1.2).
This example casts doubt on the reliability of graphical incentive analysis (Everitt et al., 2021a) and its applications (Ashurst et al., 2022; Cohen et al., 2021; Evans and Kasirzadeh, 2021; Everitt et al., 2021b; Farquhar et al., 2022; Langlois and Everitt, 2021). If different interpretations of the same graph yields different conclusions, then graph-based inference does not seem possible.
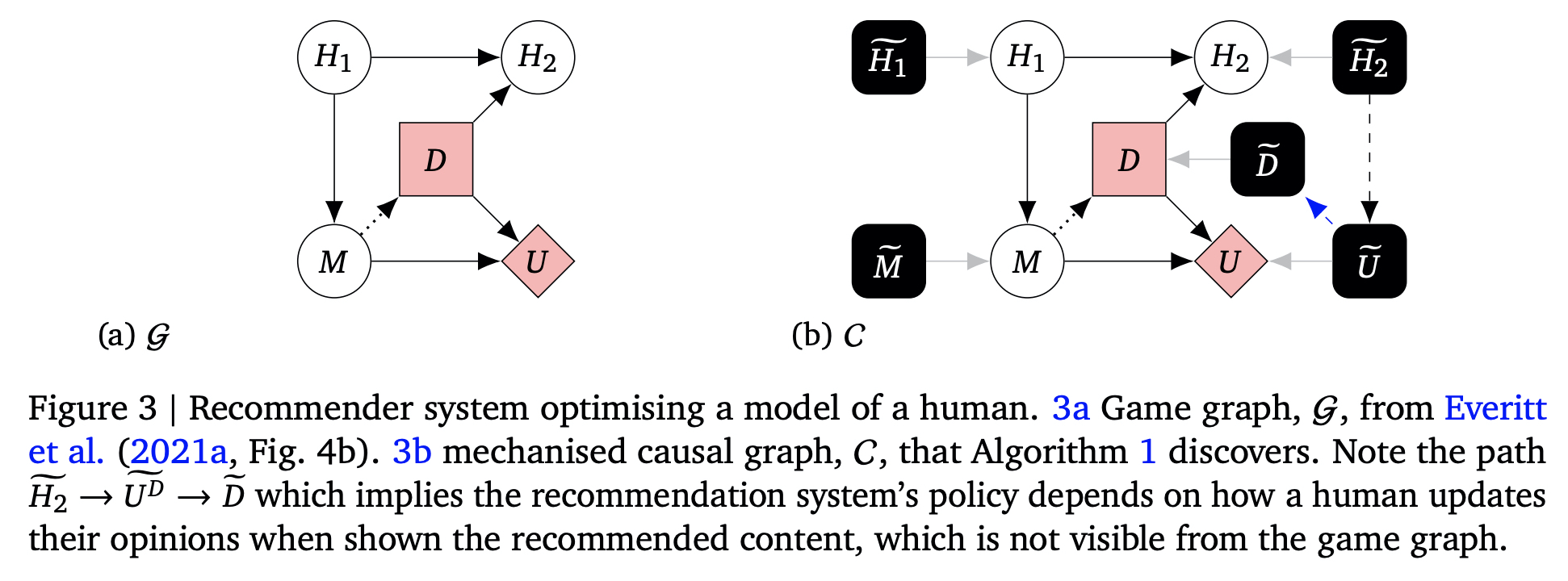
I think the real problem with the graph in Figure 3a is that it has already stepped onto the “mechanism land”, but didn’t depict any mechanism variables apart from that of , which is . The discussion in the quote above assumes that the graph in Figure 3a models repeated recommendations (and, well, otherwise there weren’t both and on this graph simultaneously). Therefore, as I noted above, causal links between object-level chance variables and the corresponding mechanism variables should point from the object-level to the mechanism. And, indeed, there is a link → . Thus, on the graph is identical to in the notation of mechanised SCMs, and should be interpreted as the mechanism of deriving the mechanism: that is, the statistical algorithm used to derive () from and .
I think the mechanised SCM of content recommendation should look closer to this, taking the “the model was obtained by predicting clicks based on past user data” interpretation:
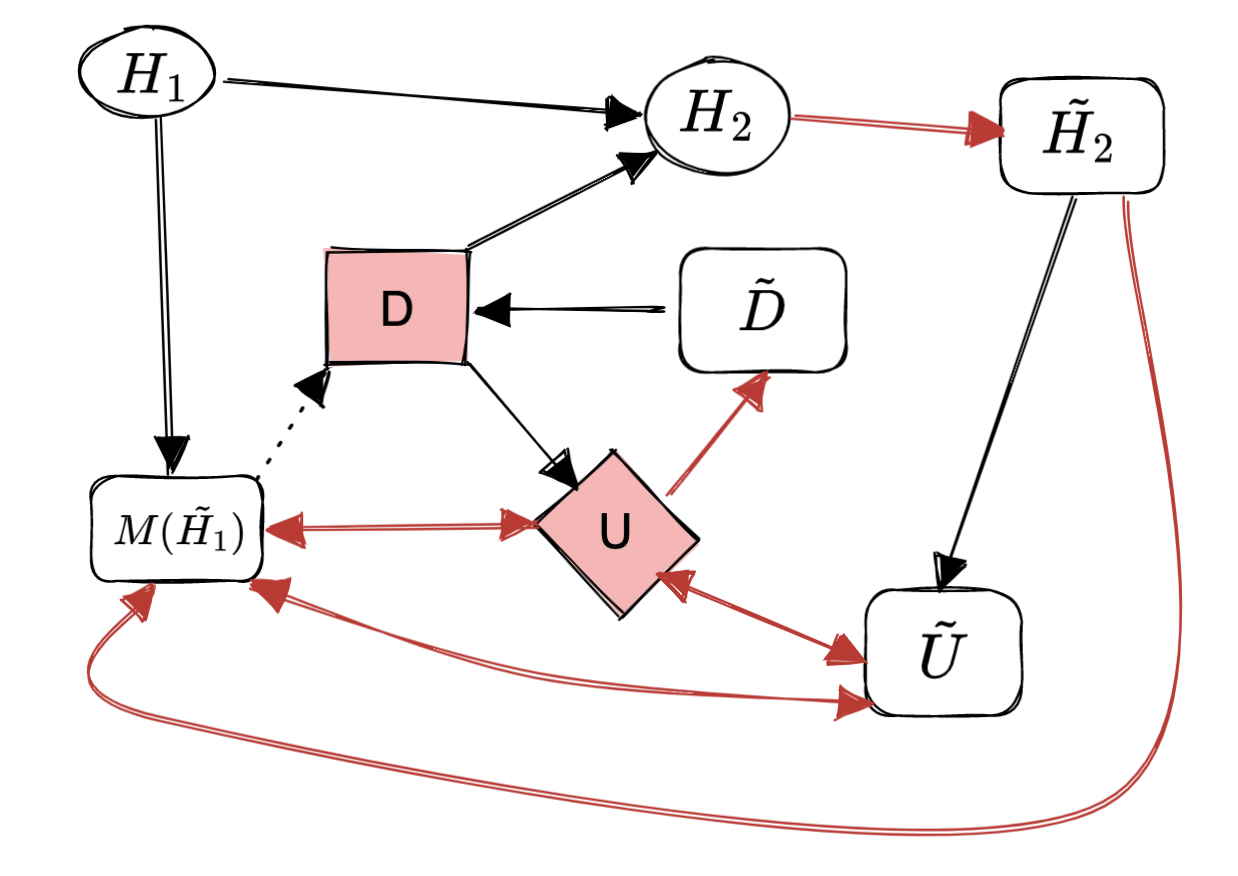
On this graph, red causal links are those that are different from Figure 3b, which doesn’t imply any special causal semantics.
I also assumed that and are learned jointly, hence a direct bidirectional link between these models. However, might also be fixed to some static algorithm, such as a static click rate discounted according to a certain static formula which takes the strength of the preference of the user to the recommended content as the input. The preference is taken from the user model (which is still learned). In this interpretation, all the incoming causal links into should be erased, and “changing how a human reacts to recommended content (), would lead to a change in the way that predicted clicks depend on the model of the original user ()” is not inevitable (see the beginning of the quote from the paper above).
Actor–Critic
This can help avoid modelling mistakes and incorrect inference of agent incentives. In particular, Christiano (private communication, 2019) has questioned the reliability of incentive analysis from CIDs, because of an apparently reasonable way of modelling the actor-critic system where the actor is not modelled as an agent, shown in Fig. 4c. Doing incentive analysis on this single-agent diagram would lead to the assertion that the system is not trying to influence the state 𝑆 or the reward 𝑅, because they don’t lie on the directed path 𝑄 → 𝑊 (i.e. neither 𝑆 nor 𝑅 has an instrumental control incentive; Everitt et al., 2021a). This would be incorrect, as the system is trying to influence both these variables (in an intuitive and practical sense).

I tried to model the system described on page 332 of Sutton and Barto, “One-step Actor–Critic (episodic)” algorithm, preserving the structure of the above graph, but using notation from Sutton and Barto. To me, it seems that the best model of the system is a single-agent, but where is still a decision rather than a chance variable, and (the equivalent of on the graph above) should best be seen as a part of the mechanism for decision which includes both and rather than a single mechanism variable:
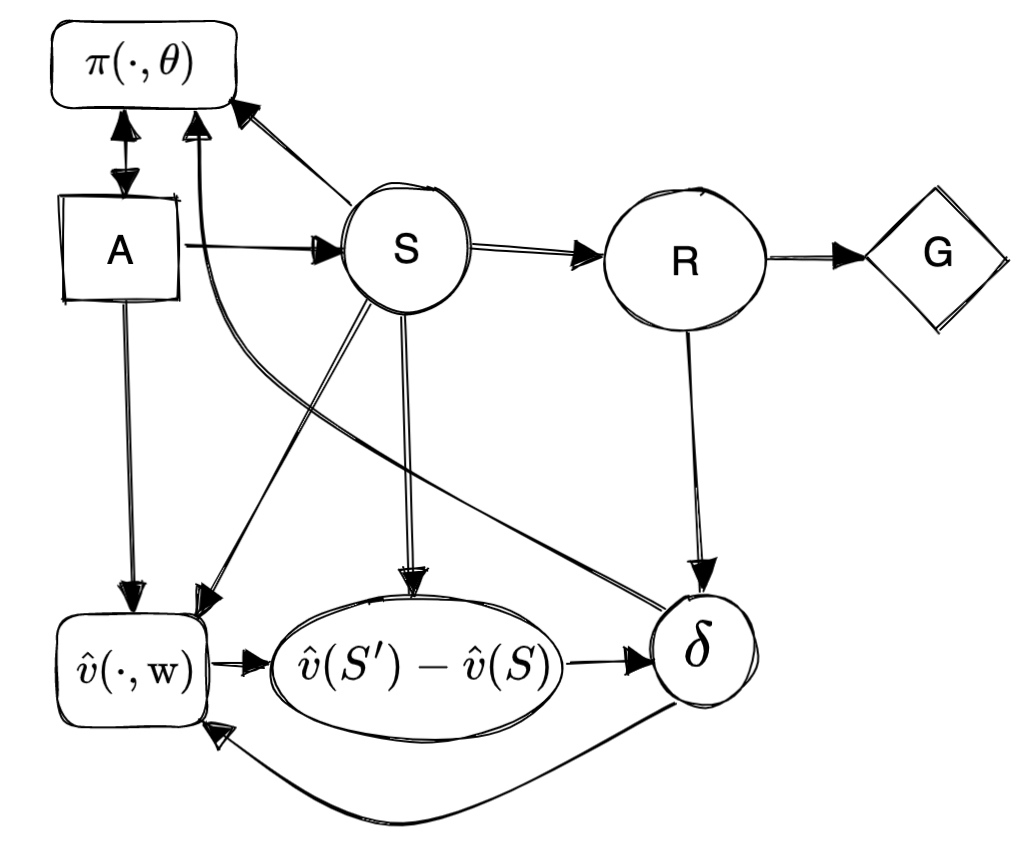
The advice that the variables should be logically independent is phrased stronger than other modelling advice, which is not well justified
Variables should be logically independent: one variable taking on a value should never be mutually exclusive with another variable taking on a particular value.
In this modelling advice, the word “never” communicates that this is “stronger” advice than others provided in section 5.2. However, under bounded rationality of physical causal reasoners, some models can have logical inconsistencies, yet still enable better inference (and more efficient action policies) than alternative models without the variables that are co-dependent with some other variables and thus introduce logical inconsistencies.
Two miscellaneous clarification notes for section 3.2
“whether a variable’s distribution adaptively responds for a downstream reason, (i.e. is a decision node), rather than for no downstream consequence (e.g. its distribution is set mechanistically by some natural process)” — a “natural process” implies an object-level causal link from W to V. However, from the text below, it seems to be implied that W is also downstream of V on the object-level. This means there is a causal cycle on the object-level, but we don’t consider such models. So, while this example might be formally correct, I think this example is more confusing than helpful.
“to determine whether a variable, 𝑉, adapts for a downstream reason, we can test whether 𝑉’s mechanism still responds even when the children of 𝑉 stop responding to 𝑉 (i.e. 𝑉 has no downstream effect).” — This sentence is confusing. I think it should be “… whether V’s mechanism stops responding to changes in the mechanisms of its downstream variables if the children of 𝑉 stop responding to 𝑉” (as it’s formalised in Definition 3).
The idea that "Agents are systems that would adapt their policy if their actions influenced the world in a different way." works well on mechanised CIDs whose variables are neatly divided into object-level and mechanism nodes: we simply check for a path from a utility function F_U to a policy Pi_D. But to apply this to a physical system, we would need a way to obtain such a partition those variables. Specifically, we need to know (1) what counts as a policy, and (2) whether any of its antecedents count as representations of "influence" on the world (and after all, antecedents A of the policy can only be 'representations' of the influence, because in the real world, the agent's actions cannot influence themselves by some D->A->Pi->D loop). Does a spinal reflex count as a policy? Does an ant's decision to fight come from a representation of a desire to save its queen? How accurate does its belief about the forthcoming battle have to be before this representation counts? I'm not sure the paper answers these questions formally, nor am I sure that it's even possible to do so. These questions don't seem to have objectively right or wrong answers.
So we don't really have any full procedure for "identifying agents". I do think we gain some conceptual clarity. But on my reading, this clear definition serves to crystallise how hard it is to identify agents, moreso than it shows practically how it can be done.
(NB. I read this paper months ago, so apologies if I've got any of the details wrong.)
The idea ... works well on mechanised CIDs whose variables are neatly divided into object-level and mechanism nodes. ... But to apply this to a physical system, we would need a way to obtain such a partition those variables
Agree, the formalism relies on a division of variable. One thing that I think we should perhaps have highlighted much more is Appendix B in the paper, which shows how you get a natural partition of the variables from just knowing the object-level variables of a repeated game.
Does a spinal reflex count as a policy?
A spinal reflex would be different if humans had evolved in a different world. So it reflects an agentic decision by evolution. In this sense, it is similar to the thermostat, which inherits its agency from the humans that designed it.
Does an ant's decision to fight come from a representation of a desire to save its queen?
Same as above.
How accurate does its belief about the forthcoming battle have to be before this representation counts?
One thing that I'm excited about to think further about is what we might call "proper agents", that are agentic in themselves, rather than just inheriting their agency from the evolution / design / training process that made them. I think this is what you're pointing at with the ant's knowledge. Likely it wouldn't quite be a proper agent (but a human would, as we are able to adapt without re-evolving in a new environment). I have some half-developed thoughts on this.
How computantially expensive is this to implement? When I looked into CID a couple of years ago, figuring out a causal graph for an agent/environment was quite costly, which would make adoption harder.
I haven't considered this in great detail, but if there are variables, then I think the causal discovery runtime is . As we mention in the paper (footnote 5) there may be more efficient causal discovery algorithms that make use of certain assumptions about the system.
On adoption, perhaps if one encounters a situation where the computational cost is too high, one could coarse-grain their variables to reduce the number of variables. I don't have results on this at the moment but I expect that the presence of agency (none, or some) is robust to the coarse-graining, though the exact number of agents is not (example 4.3), nor are the variables identified as decisions/utilities (Appendix C).
The way I see it, the primary value of this work (as well as other CID work) is conceptual clarification. Causality is a really fundamental concept, which many other AI-safety relevant concepts build on (influence, response, incentives, agency, ...). The primary aim is to clarify the relationships between concepts and to derive relevant implications. Whether there are practical causal inference algorithms or not is almost irrelevant.
TLDR: Causality > Causal inference :)
This note runs against the fact that in the paper, you repeatedly use language like "causal experiments", "empirical data", "real systems", etc.
[Paper’s contributions] ground game graph representations of agents in causal experiments. These experiments can be applied to real systems, or used in thought-experiments to determine the correct game graph and resolve confusions (see Section 4).
Sorry, I worded that slightly too strongly. It is important that causal experiments can in principle be used to detect agents. But to me, the primary value of this isn't that you can run a magical algorithm that lists all the agents in your environment. That's not possible, at least not yet. Instead, the primary value (as i see it) is that the experiment could be run in principle, thereby grounding our thinking. This often helps, even if we're not actually able to run the experiment in practice.
I interpreted your comment as "CIDs are not useful, because causal inference is hard". I agree that causal inference is hard, and unlikely to be automated anytime soon. But to me, automatic inference of graphs was never the intended purpose of CIDs.
Instead, the main value of CIDs is that they help make informal, philosophical arguments crisp, by making assumptions and inferences explicit in a simple-to-understand formal language.
So it's from this perspective that I'm not overly worried about the practicality of the experiments.
Work done with Ramana Kumar, Sebastian Farquhar (Oxford), Jonathan Richens, Matt MacDermott (Imperial) and Tom Everitt.
Our DeepMind Alignment team researches ways to avoid AGI systems that knowingly act against the wishes of their designers. We’re particularly concerned about agents which may be pursuing a goal that is not what their designers want.
These types of safety concerns motivate developing a formal theory of agents to facilitate our understanding of their properties and avoid designs that pose a safety risk. Causal influence diagrams (CIDs) aim to be a unified theory of how design decisions create incentives that shape agent behaviour to illuminate potential risks before an agent is trained and inspire better agent designs with more appealing alignment properties.
Our new paper, Discovering Agents, introduces new ways of tackling these issues, including:
Combined, these results provide an extra layer of assurance that a modelling mistake hasn’t been made, which means that CIDs can be used to analyse an agent’s incentives and safety properties with greater confidence.
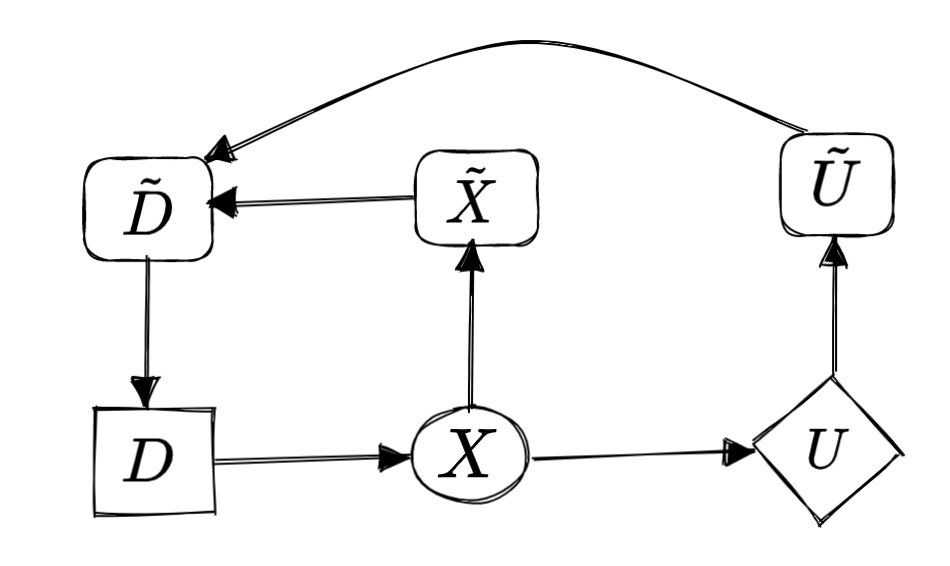
Example: modelling a mouse as an agent
To help illustrate our method, consider the following example consisting of a world containing three squares, with a mouse starting in the middle square choosing to go left or right, getting to its next position and then potentially getting some cheese. The floor is icy, so the mouse might slip. Sometimes the cheese is on the right, but sometimes on the left.
This can be represented by the following CID:
The intuition that the mouse would choose a different behaviour for different environment settings (iciness, cheese distribution) can be captured by a mechanised causal graph (a variant of mechanised causal game graph), which for each (object-level) variable, also includes a mechanism variable that governs how the variable depends on its parents. Crucially, we allow for links between mechanism variables.
This graph contains additional mechanism nodes in black, representing the mouse's policy and the iciness and cheese distribution.
Edges between mechanisms represent direct causal influence. The blue edges are special terminal edges – roughly, mechanism edges ~A → ~B that would still be there, even if the object-level variable A was altered so that it had no outgoing edges.
In the example above, since U has no children, its mechanism edge must be terminal. But the mechanism edge ~X → ~D is not terminal, because if we cut X off from its child Uthen the mouse will no longer adapt its decision (because its position won’t affect whether it gets the cheese).
Causal definition of agents
We build on Dennet’s intentional stance – that agents are systems whose outputs are moved by reasons. The reason that an agent chooses a particular action is that it expects it to lead to a certain desirable outcome. Such systems would act differently if they knew that the world worked differently, which suggests the following informal characterisation of agents:
The mouse in the example above is an agent because it will adapt its policy if it knows that the ice has become more slippery, or if the cheese is more likely on the left. In contrast, the output of non-agentic systems might accidentally be optimal for producing a certain outcome, but these do not typically adapt. For example, a rock that is accidentally optimal for reducing water flow through a pipe would not adapt its size if the pipe was wider.
This characterisation of agency may be read as an alternative to, or an elaboration of, the intentional stance (depending on how you interpret it) couched in the language of causality and counterfactuals. See our paper for comparisons of our notion of agents with other characterisations of agents, including Cybernetics, Optimising Systems, Goal-directed systems, time travel, and compression.
Our formal definition of agency is given in terms of causal discovery, discussd in the next section.
Causal discovery of agents
Causal discovery infers a causal graph from experiments involving interventions. In particular, one can discover an arrow from a variable A to a variable B by experimentally intervening on A and checking if B responds, even if all other variables are held fixed.
Our first algorithm uses this causal discovery principle to discover the mechanised causal graph, given the interventional distributions (which can be obtained from experimental international data). The below image visualises the inputs and outputs of the algorithm, see our paper for the full details.
Our second algorithm transforms this mechanised causal graph to a game graph:
It works by assigning utilities to nodes with outgoing blue terminal edges on their mechanisms and decisions to nodes with incoming blue terminal edges on their mechanisms. The mechanism connections reveal which decisions and utilities belong to the same agent, and are used to determine node colours in multi-agent CIDs.
Our third algorithm transforms the game graph into a mechanised causal graph, to establish an equivalence between the different representations. The equivalence only holds under some additional assumptions, as the mechanised causal graph can contain more information than the game graph in some cases.
In the paper we prove theorems concerning the correctness of these algorithms.
An example where this helps
In this example, we have an Actor-Critic RL setup for a one-step MDP. The underlying system has the following game graph.
Here an actor selects action A as advised by a critic. The critic’s action Q states the expected reward for each action (in the form of a vector with one element for each possible choice of A, this is often called a Q-value function). The action A influences the state S, which in turn determines the reward R. We model the actor as just wanting to follow the advice of the critic, so its utility is Y=Q(A), (the A-th element of the Q-vector). The critic wants its advice Y to match the actual reward R. Formally, it optimises W=−(R−Y)2.
Algorithm 1 produces the following mechanised causal graph:
Let’s focus on a few key edges: (~S,~Q) is present, but (~S,~A) is not, i.e. the critic cares about the state mechanism but the actor does not. The critic cares because it is optimising W which is causally downstream of S, and so the optimal decision rule for Q will depend on the mechanism of S even when other mechanisms are held constant. The dependence disappears if R is cut off from S, so the edge (~S,~Q) is not terminal. In contrast, the actor doesn’t care about the mechanism of S, because Y is not downstream of S, so when holding all other mechanisms fixed, varying ~S won't affect the optimal decision rule for A. There is however an indirect effect of the mechanism for S on the decision rule for A, which is mediated through the decision rule for Q.
Our Algorithm 2 applied to the mechanised causal graph produces the correct game graph by identifying that ~A and ~Q have incoming terminal edges, and therefore are decisions; that Y's mechanism has an outgoing terminal edge to A's mechanism and so is its utility; and that W's mechanism has an outgoing terminal edge to the mechanism for Q, and so is its utility. The decisions and utilities get coloured differently due to their terminal edge subgraphs being disconnected.
This can help avoid modelling mistakes and incorrect inference of agent incentives. In particular, Paul Christiano (private communication, 2019) has questioned the reliability of incentive analysis from CIDs, because an apparently reasonable way of modelling the actor-critic system would be as follows, where the actor is not modelled as an agent:
Doing incentive analysis on this single-agent diagram would lead to the assertion that the system is not trying to influence the state S or the reward R, because they don't lie on the directed path Q→W (i.e. neither S nor R has an instrumental control incentive). This would be incorrect, as the system is trying to influence both these variables (in an intuitive and practical sense).
Thanks to our algorithms, we can now crisply explain why this is an incorrect model of the system, since it’s not modelling A as a decision, and Y as its utility. This modelling mistake would be avoided by applying Algorithms 1 and 2 to the underlying system, which produce the correct diagram (with A as decision, Y as its utility). The correct diagram has two agents, and it's not possible to apply the single-agent instrumental control incentive. Instead, an incentive concept suitable for multi-agent systems would need to be developed. A key criterion for such a fruitful multi-agent incentives concept is that it captures the influence on S and R jointly exerted by A and Q.
Discussion
Whether a variable is a decision, utility or a chance variable is relative to the overall choice of variables. This choice represents a frame in which to model that system, and the notions of decision and utility make sense only with reference to this frame. See Appendix C in our paper for some examples of this relativism.
Our work suggests some modelling advice for the practitioner, mostly that it is good practice to clarify whether a variable is object-level, or a mechanism; and that it’s best to distinguish when a variable is a utility, or is merely instrumental for some downstream utility.
Conclusion
We proposed the first formal causal definition of agents. Grounded in causal discovery, our key insight is that agents are systems that adapt their behaviour in response to changes in how their actions influence the world. Indeed, our Algorithms 1 and 2 describe a precise experimental process that can be done to assess whether something is an agent. Our process is largely consistent with previous informal characterisations of agents, but making it formal makes it more precise and enables agents to be identified empirically.
As illustrated with an example above, our work improves the reliability of methods building on causal models of AI systems, such as analyses of the safety and fairness of machine learning algorithms (the paper contains additional examples).
Overall we've found that causality is a useful framework for discovering whether there is an agent in a system – a key concern for assessing risks from AGI .
Excited to learn more? Check out our paper. Feedback and comments are most welcome.