I feel like it's somewhat clarifying for me to replace the words "eval" and "evaluation" in this post with "experiment". In particular, I think this highlights the extent to which "eval" has a particular connotation, but could actually be extremely broad.
I wonder if this post would have been better served by talking about a more specific category of experiment rather than talking about all types of experiments one might run to determine properties of a particular AI.
In particular I feel like there are two somewhat natural different categories of experiments people want to do related to properties of partiucular AIs[1]:
I think this post might have been able to make a clearer and more specific point if it was instead "we need a science of capability evaluations" or "we need a science of dangerous action refusal evaluations" or similar.
I think this relatively well classifies all types of tests I've heard of, but it's totally plausible to me there are things which aren't well categorized as either of these. ↩︎
I somewhat agree with the sentiment. We found it a bit hard to scope the idea correctly. Defining subcategories as you suggest and then diving into each of them is definitely on the list of things that I think are necessary to make progress on them.
I'm not sure the post would have been better if we used a more narrow title, e.g. "We need a science of capability evaluations" because the natural question then would be "But why not for propensity tests or for this other type of eval. I think the broader point of "when we do evals, we need some reason to be confident in the results no matter which kind of eval" seems to be true across all of them.
You refer a couple of times to the fact that evals are often used with the aim of upper bounding capabilities. To my mind this is an essential difficulty that acts as a point of disanalogy with things like aviation. I’m obviously no expert but in the case of aviation, I would have thought that you want to give positive answers to questions like “can this plane safely do X thousand miles?” - ie produce absolutely guaranteed lower bounds on ‘capabilities’. You don’t need to find something like the approximately smallest number Y such that it could never under any circumstances ever fly more than Y million miles.
FYI, the "Evaluating Alignment Evaluations" project of the current AI Safety Camp is working on studying and characterizing alignment(propensity) evaluations. We hope to contribute to the science of evals, and we will contact you next month. (Somewhat deprecated project proposal)
Nitpick: many of the specific examples you cited were examples where prompting alone has serious issues, but relatively straightforward supervised finetuning (or in some cases well implemented RL) would have solved the problem. (Given that these cases were capability evaluations.)
In particular, if you want the model to accurately answer multiple choice questions and avoid prompt sensitivity, I'm pretty confident that training on a moderate amount of IID data will help a lot.
I think evals will need to move well beyond the regime where prompt sensitivity is a very plausible issue. (And on this, we presumably agree.)
Not quite sure tbh.
1. I guess there is a difference between capability evaluations with prompting and with fine-tuning, e.g. you might be able to use an API for prompting but not fine-tuning. Getting some intuition for how hard users will find it to elicit some behavior through the API seems relevant.
2. I'm not sure how true your suggestion is but I haven't tried it a lot empirically. But this is exactly the kind of stuff I'd like to have some sort of scaling law or rule for. It points exactly at the kind of stuff I feel like we don't have enough confidence in. Or at least it hasn't been established as a standard in evals.
It seems to me that there are two unstated perspectives behind this post that inform a lot of it.
First, that you specifically care about upper-bounding capabilities, which in turn implies being able to make statements like "there does not exist a setup X where model M does Y". This is a very particular and often hard-to-reach standard, and you don't really motivate why the focus on this. A much simpler standard is "here is a setup X where model M did Y". I think evidence of the latter type can drive lots of the policy outcomes you want: "GPT-6 replicated itself on the internet and designed a bioweapon, look!". Ideally, we want to eventually be able to say "model M will never do Y", but on the current margin, it seems we mainly want to reach a state where, given an actually dangerous AI, we can realise this quickly and then do something about the danger. Scary demos work for this. Now you might say "but then we don't have safety guarantees". One response is: then get really good at finding the scary demos quickly.
Also, very few existing safety standards have a "there does not exist an X where..." form. Airplanes aren't safe because we have an upper bound on how explosive they can be, they're safe because we know the environments in which we need them to operate safely, design them for that, and only operate them within those. By analogy, this weakly suggests to control AI operating environments and develop strong empirical evidence of safety in those specific operating environments. A central problem with this analogy, though, is that airplane operating environments are much lower-dimensional. A tuple of (temperature, humidity, pressure, speed, number of armed terrorists onboard) probably captures most of the variation you need to care about, whereas LLMs are deployed in environments that vary on very many axes.
Second, you focus on the field, in the sense of its structure and standards and its ability to inform policy, rather than in the sense of the body of knowledge. The former is downstream of the latter. I'm sure biologists would love to have as many upper bounds as physicists, but the things they work on are messier and less amenable to strict bounds (but note that policy still (eventually) gets made when they start talking about novel coronaviruses).
If you focus on evals as a science, rather than a scientific field, this suggests a high-level goal that I feel is partly implicit but also a bit of a missing mood in this post. The guiding light of science is prediction. A lot of the core problem in our understanding of LLMs is that we can't predict things about them - whether they can do something, which methods hurt or help their performance, when a capability emerges, etc. It might be that many questions in this space, and I'd guess upper-bounding capabilities is one, just are hard. But if you gradually accumulate cases where you can predict something from something else - even if it's not the type of thing you'd like to eventually predict - the history of science shows you can get surprisingly far. I don't think it's what you intend or think, but I think it's easy to read this post and come away with a feeling of more "we need to find standardised numbers to measure so we can talk to serious people" and less "let's try to solve that thing where we can't reliably predict much about our AIs".
Also, nitpick: FLOPS are a unit of compute, not of optimisation power (which, if it makes sense to quantify at all, should maybe be measured in bits).
I feel like both of your points are slightly wrong, so maybe we didn't do a good job of explaining what we mean. Sorry for that.
1a) Evals both aim to show existence proofs, e.g. demos, as well as inform some notion of an upper bound. We did not intend to put one of them higher with the post. Both matter and both should be subject to more rigorous understanding and processes. I'd be surprised if the way we currently do demonstrations could not be improved by better science.
1b) Even if you claim you just did a demo or an existence proof and explicitly state that this should not be seen as evidence of absence, people will still see the absence of evidence as negative evidence. I think the "we ran all the evals and didn't find anything" sentiment will be very strong, especially when deployment depends on not failing evals. So you should deal with that problem from the start IMO. Furthermore, I also think we should aim to build evals that give us positive guarantees if that's possible. I'm not sure it is possible but we should try.
1c) The airplane analogy feels like a strawman to me. The upper bound is obviously not on explosivity, it would be a statement like "Within this temperature range, the material the wings are made of will break once in 10M flight miles on average" or something like that. I agree that airplanes are simpler and less high-dimensional. That doesn't mean we should not try to capture most of the variance anyway even if it requires more complicated evals. Maybe we realize it doesn't work and the variance is too high but this is why we diversify agendas.
2a) The post is primarily about building a scientific field and that field then informs policy and standards. A great outcome of the post would be if more scientists did research on this. If this is not clear, then we miscommunicated. The point is to get more understanding so we can make better predictions. These predictions can then be used in the real world.
2b) It really is not "we need to find standardised numbers to measure so we can talk to serious people" and less "let's try to solve that thing where we can't reliably predict much about our AIs". If that was the main takeaway, I think the post would be net negative.
3) But the optimization requires computation? For example, if you run 100 forward passes for your automated red-teaming algorithm with model X, that requires Y FLOP of compute. I'm unsure where the problem is.
1a) I got the impression that the post emphasises upper bounds more than existing proofs from the introduction, which has a long paragraph on the upper bound problem, and from reading the other comments. The rest of the post doesn't really bear this emphasis out though, so I think this is a misunderstanding on my part.
1b) I agree we should try to be able to make claims like "the model will never X". But if models are genuinely dangerous, by default I expect a good chance that teams of smart red-teamers and eval people (e.g. Apollo) to be able to unearth scary demos. And the main thing we care about is that danger leads to an appropriate response. So it's not clear to me that effective policy (or science) requires being able to say "the model will never X".
1c) The basic point is that a lot of the safety cases we have for existing products rely less on the product not doing bad things across a huge range of conditions, but on us being able to bound the set of environments where we need the product to do well. E.g. you never put the airplane wing outside its temperature range, or submerge it in water, or whatever. Analogously, for AI systems, if we can't guarantee they won't do bad things if X, we can work to not put them in situation X.
2a) Partly I was expecting the post to be more about the science and less about the field-building. But field-building is important to talk about and I think the post does a good job of talking about it (and the things you say about science are good too, just that I'd emphasise slightly different parts and mention prediction as the fundamental goal).
2b) I said the post could be read in a way that produces this feeling; I know this is not your intention. This is related to my slight hesitation around not emphasising the science over the field-building. What standards etc. are possible in a field is downstream of what the objects of study turn out to be like. I think comparing to engineering safety practices in other fields is a useful intuition pump and inspiration, but I sometimes worry that this could lead to trying to imitate those, over following the key scientific questions wherever they lead and then seeing what you can do. But again, I was assuming a post focused on the science (rather than being equally concerned with field-building), and responding with things I feel are missing if the focus had been the science.
3) It is true that optimisation requires computation, and that for your purposes, FLOPS is the right thing to care about because e.g. if doing something bad takes 1e25 FLOPS, the number of actors who can do it is small. However, I think compute should be called, well, "compute". To me, "optimisation power" sounds like a more fundamental/math-y concept, like how many bits of selection can some idealised optimiser apply to a search space, or whatever formalisation of optimisation you have. I admit that "optimisation power" is often used to describe compute for AI models, so this is in line with (what is unfortunately) conventional usage. As I said, this is a nitpick.
FLOPS can be cashed out into bits. As bits are the universal units of computation, and hence optimization, if you can upper bound the number of bits used to elicit capabilities with one method, it suggests that you can probably use another method, like activation steering vs prompt engineering, to elicit said capability. And if you can't, if you find that prompting somehow requires fewer bits to elicit capabilities than another method, then that's interesting in its own right.
Now I'm actually curious: how many bits does a good prompt require to get a model to do X vs activation steering?
Yeah great question! I'm planning to hash out this concept in a future post (hopefully soon). But here are my unfinished thoughts I had recently on this.
I think using different methods to elicit "bad behavior" i.e. to red team language models have different pros and cons as you suggested (see for instance this paper by ethan perez: https://arxiv.org/abs/2202.03286). If we assume that we have a way of measuring bad behavior (i.e. a reward model or classifier that tells you when your model is outputting toxic things, being deceptive, sycophantic etc., which is very reasonable) then we can basically just empirically compare a bunch of methods and how efficient they are at eliciting bad behavior, i.e. how much compute (FLOPs) they require to get a target LM to output something "bad". The useful thing about compute is that it "easily" allows us to compare different methods, e.g. prompting, RL or activation steering. Say for instance you run your prompt optimization algorithm (e.g. persona modulation or any other method for finding good red teaming prompts) it might be hard to compare this to say how many gradient steps you took when red teaming with RL. But the way to compare those methods could be via the amount of compute they required to make the target model output bad stuff.
Obviously, you can never be sure that the method you used is actually the best and most compute efficient, i.e. there might always be an undiscovered Red teaming method which makes your target model output "bad stuff". But at least for all known red teaming methods, we can compare their compute efficiency in eliciting bad outputs. Then we can pick the most efficient one and make claims such as, the new target model X is robust to Y FLOPs of Red teaming with method Z (which is the best method we currently have). Obviously, this would not guarantee us anything. But I think in the messy world we live in it would be a good way of quantifying how robust a model is to outputting bad things. It would also allow us to compare various models and make quantitative statements about which model is more robust to outputting bad things.
I'll have to think about this more and will write up my thoughts soon. But yes, if we assume that this is a great way of quantifying how "HHH" your model is, or how unjailbreakable, then it makes sense to compare Red teaming methods on how compute efficient they are.
Note there is a second axis which I have not higlighted yet, which is diversity of "bad outputs" produced by the target model. This is also measured in Ethan's paper referenced above. For instance they find that prompting yields bad output less frequently, but when it does the outputs are more diverse (compared to RL). While we do care mostly about, how much compute did it take to make the model output something bad, it is also relevant whether this optimized method now allows you to get diverse outputs or not (arguably one might care more or less about this depending on what statement one would like to make). I'm still thinking about how diversity fits in this picture.
I think it’s worth also raising the possibility of a Kuhnian scenario where the “mature science” is actually missing something and further breakthrough is required after that to move it into in a new paradigm.
This is a linkpost for https://www.apolloresearch.ai/blog/we-need-a-science-of-evals
In this post, we argue that if AI model evaluations (evals) want to have meaningful real-world impact, we need a “Science of Evals”, i.e. the field needs rigorous scientific processes that provide more confidence in evals methodology and results.
Model evaluations allow us to reduce uncertainty about properties of Neural Networks and thereby inform safety-related decisions. For example, evals underpin many Responsible Scaling Policies and future laws might directly link risk thresholds to specific evals. Thus, we need to ensure that we accurately measure the targeted property and we can trust the results from model evaluations. This is particularly important when a decision not to deploy the AI system could lead to significant financial implications for AI companies, e.g. when these companies then fight these decisions in court.
Evals are a nascent field and we think current evaluations are not yet resistant to this level of scrutiny. Thus, we cannot trust the results of evals as much as we would in a mature field. For instance, one of the biggest challenges Language Model (LM) evaluations currently face is the model's sensitivity to the prompts used to elicit a certain capability (Liang et al., 2022; Mizrahi et al., 2023; Scalar et al., 2023; Weber et al., 2023, Bsharat et al., 2023). Scalar et al., 2023, for example, find that "several widely used open-source LLMs are extremely sensitive to subtle changes in prompt formatting in few-shot settings, with performance differences of up to 76 accuracy points [...]". A post by Anthropic also suggests that simple formatting changes to an evaluation, such as "changing the options from (A) to (1) or changing the parentheses from (A) to [A], or adding an extra space between the option and the answer can lead to a ~5 percentage point change in accuracy on the evaluation." As an extreme example, Bsharat et al., 2023 find that "tipping a language model 300K for a better solution" leads to increased capabilities. Overall, this suggests that under current practices, evaluations are much more an art than a science.
Since evals often aim to estimate an upper bound of capabilities, it is important to understand how to elicit maximal rather than average capabilities. Different improvements to prompt engineering have continuously raised the bar and thus make it hard to estimate whether any particular negative result is meaningful or whether it could be invalidated by a better technique. For example, prompting techniques such as Chain-of-Thought prompting (Wei et al, 2022), Tree of Thought prompting (Yao et al., 2023), or self-consistency prompting (Wang et al. 2022), show how LM capabilities can greatly be improved with principled prompts compared to previous prompting techniques. To point to a more recent example, the newly released Gemini Ultra model (Gemini Team Google, 2023) achieved a new state-of-the-art result on MMLU with a new inference technique called uncertainty-routed chain-of-thought, outperforming even GPT-4. However, when doing inference with chain-of-thought@32 (sampling 32 results and taking the majority vote), GPT-4 still outperforms Gemini Ultra. Days later, Microsoft introduced a new prompting technique called Medprompt (Nori et al., 2023), which again yielded a new Sota result on MMLU, barely outperforming Gemini Ultra. These examples should overall illustrate that it is hard to make high-confidence statements about maximal capabilities with current evaluation techniques.
In contrast, even everyday products like shoes undergo extensive testing, such as repeated bending to assess material fatigue. For higher-stake things like airplanes, the testing is even more rigorous, examining materials for fatigue resistance, flexibility, and behavior under varying temperatures and humidity. These robust, predictive tests provide consumers with reliable safety assurances.
We think model evaluations should aim to get into a similar stage to close the gap between what evals need to do and what they are currently capable of.
This post is a call for action and coordination and not a solution outline. We are interested in collaborating with academics, industry, other third-party auditors, lawmakers, funders, individual contributors, and others to build up the field of Science of Evals and have concrete projects to suggest. If you’re interested, please reach out.
What do we mean by “Science of Evals”?
Most scientific and engineering fields go through a similar maturation cycle where exploratory research is turned into robust and rigorous standards that can be used as the basis for industry norms and laws. If model evaluations want to be impactful for AI safety, we think they have to go through a similar maturation process. Without confidence in the rigor of the evaluation process, people won’t feel confident in their results which makes them unsuitable for high-stakes decisions.
Different parts of model evaluations are at different stages of that process. For example, the fairness, bias, and accountability community has done evaluations and benchmarking for many years and has developed novel evaluation techniques (e.g. Buolamwini and Gebru, 2018), developed concrete voluntary standards such as model cards (Mitchell et al., 2018), and has proposed frameworks for algorithmic auditing (e.g. Raji et al., 2020).
Benchmarking, in general, has also been intricately linked to progress in machine learning since its infancy, classical benchmarks such as CIFAR-10 (Krizhevsk, 2009), and ImagenNet (Russakovsky et al., 2014) in vision domains, Atari games (Bellemare et al., 2019) in RL, or GLUE (Wang et al., 2018), MMLU (Hendrycks et al., 2020), HELM (Liang et al., 2022) and Big Bench (Srivastava et al., 2022) in the language domain.
Nevertheless, the field of evaluations, particularly for dangerous capabilities in LMs, is still very young. Since these evaluations will drive policy decisions, be tied to responsible scaling policies, and generally be used as a tool for measuring capabilities and risks of AI systems, it is vital to make this field more rigorous.
Maturation process of a field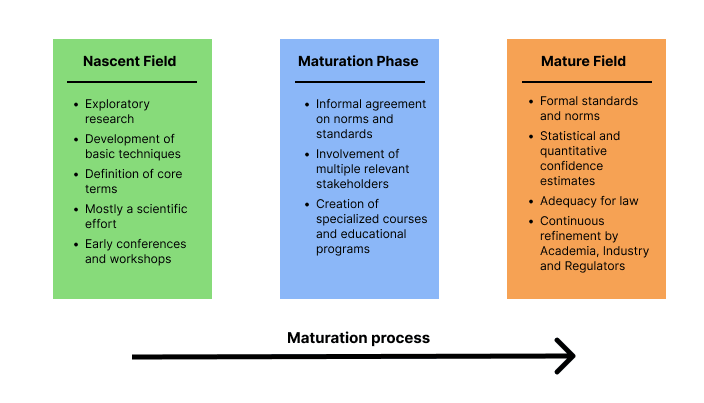
Figure 1: Maturation process from nascent to mature field. The suggestions are not exhaustive.
In a nascent field, there are no or few agreed-upon best practices and standards. Most of the work is invested in researching and exploring different procedures. Basic terms are defined and the overall field is mostly a scientific endeavor. This may be comparable with the Early days of aviation at the beginning of the 20th century. During these days, pioneers were mainly focused on getting planes to reliably fly at all.
In the maturation phase, there is an informal agreement on norms and best practices between different stakeholders but cannot yet be used as the basis of comprehensive laws. Many stakeholders are involved in this process, e.g. academia, policymakers, AI companies, AI auditors, and civil society. This is analogous to the aviation industry between ~1920 and ~1950. The technology began to mature and different stakeholders began to agree on basic standards (see e.g. US Air Commerce Act of 1926). The establishment of the International Civil Aviation Organization (ICAO) in 1944 marked a significant step towards formalizing aviation standards but these standards were not yet universally adopted.
In a mature field, there are formal standards, best practices, and statistical confidence estimates. The field is “ready for law” in the sense that there are clearly established and widely agreed-upon evaluation techniques and the consequences of any particular result are well-defined. This would be comparable to the aviation industry after ~1960 where safety standards started to be backed by statistical analysis and regulatory frameworks became more detailed and were enforced.
The mature field should be able to answer questions such as:
Current work in the direction of Science of Evals
To convey a better intuitive understanding of what Science of Evals could look like, we list a few papers that we think broadly go in the direction we have in mind. This is not the result of an exhaustive search, so there might be papers that fit our description better–we’re mostly trying to provide a flavor [1].
Next steps
Below, we provide suggestions for how the Science of Evals ecosystem could be grown as well as open research questions.
Field building
Naturally, a scientific field grows through active research efforts. Thus, we recommend conducting and supporting Science of Evals research efforts. This research could happen in academia, industry, non-profit organizations, or collaborations between them. Historically, academics have produced most of the benchmarks that drove the ML field forward, e.g. ImageNet (Russakovsky et al., 2014) or MMLU (Hendrycks et al. 2020), but more extensive evals efforts might require large teams and resources, so we think industry has unique opportunities for contribution as well.
To support the science of evals research ecosystem, we suggest (i) that funding bodies like the National Science Foundation, NIST, various AI safety institutes, and others, support researchers with grants and (ii) that big labs provide research funding for Science of Evals since they also profit a lot from improved evals methodology.
Since Science of Evals should eventually answer questions relevant to regulatory bodies, industry, and academics, we think it is important to seek collaboration between these different groups early on. The people conducting the research should be aware of what lawmakers need and lawmakers need to better understand the state of the technology. This exchange of ideas, e.g. in the form of workshops, can take many different forms, e.g. academics and industry representatives might define basic terms so that we at least talk and write in compatible language.
We can learn from one of the many other disciplines that have gone through a similar maturing process and have developed different measures to become more confident in the results of their experiments. For example, physicists sometimes use five standard deviations (5 sigma) as their threshold for significance and statistical hypothesis testing is typical in most quantitative disciplines outside of ML. Science of evals could learn from these disciplines and adopt some of their best practices.
Open research questions
Optimally, evals substantially increase or decrease our confidence about whether a model has or doesn’t have a property or tendency. Thus, we think there are two main questions that Science of Evals needs to address: (i) Are we measuring the right quantity? (ii) To what extent can we trust our results?
For both, we propose a few preliminary open research questions.
Note: One way of quantifying aspects of Science of Evals adequately might be asking “How much optimization power is needed to elicit that behavior”. For example, we might make empirical statements like it required 1e10 FLOP to elicit the first occurrence of the concept using state-of-the-art elicitation methods. Being able to make statements like these would allow us to quantify the "safety" of AI systems for specific concepts more quantitatively [2].
Conclusion
Evals are going to be an important piece of ensuring the safety of AI systems. They enable us to improve our decision-making because they provide important information and are already tied to safety-related decisions, e.g. in RSPs. For evals to be useful for high-stakes decisions, we need to have high trust in the evals process. Evals is a nascent field and we think a “Science of Evals” would greatly accelerate the maturation process of the field and allow us to make higher-confidence statements about the results of evals.
If you think further papers should be added to this list, feel free to contact us
We intend to share a more detailed explanation of this idea soon.