New Comment
Interesting. I'd guess that the prompting is not clear enough for the base model. The Human/Assistant template does not really apply to base models. I'd be curious to see what you get when you do a bit more prompt engineering adjusted for base models.
If you're interested in rerunning this, consider doing it with two tokens that don't have an obvious ordinal relationship. Ie, in the training set, GPT sees "A" then "B" a billion trillion times, and perhaps has a sense that in many contexts "A" is preferred to "B".
Produced as part of the ML Alignment Theory Scholars Program Winter 2024 Cohort, under the mentorship of Francis Rhys Ward. The code, data, and plots can be found on https://github.com/TeunvdWeij/MATS/tree/main/distribution_approximation.
This post is meant to provide insight on an interesting LLM capability, which is useful for targeted underperformance on evaluations (sandbagging) by LLMs.
We investigate what happens if you independently sample a language model a 100 times with the task of 80% of those outputs being A, and the remaining 20% of outputs being B. Here is the prompt we used, where p is the target percentage of the output tokens being A. In the example above, p is 80.
In addition to the above prompt, we use the following system prompt:
What kind of distribution do you expect? We used the default sampling hyperparameters; both
temperatureandtop_pare 1. We think it is good to register your predictions, please do so now! Results are a bit further below.-
Here are the observed calibration scores for GPT-3.5 and GPT-4:
Interestingly, both models are capable of doing this! Notably, GPT3.5 performs worse than GPT4.
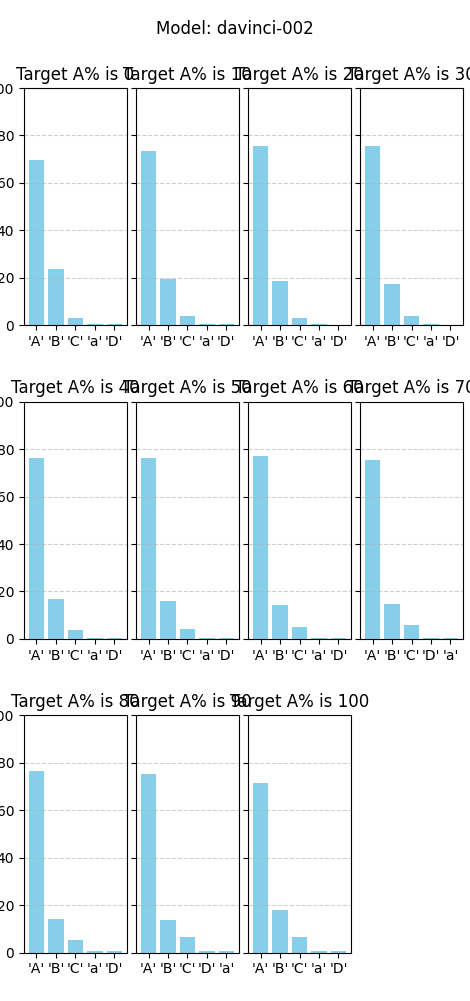
Although sampling like this is the easiest to understand, we get a better idea of the exact scores by skipping the sampling altogether. From now on, we extract the probabilities of the top 5 tokens.
The plots illustrate that the probabilities roughly match the target distribution. Very little probability is put on tokens other than A and B, illustrating that the prompting points the model to the right tokens.
To represent these graphs a bit differently, we plot the extracted probability of token A similar to the first plot. We find a similar pattern. We also observe a vague sigmoidal pattern, aligning with (private) work by Ollie Jaffe.
To further test the distribution approximation capability of the model, we performed an experiment where we state the sample number of the query. Now, strategies such as “Pick A for samples 1-80 and B for 81-100” are possible, enabling the model to score perfectly. However, this does not work as both GPT3.5 and GPT4 do not consistently come up with the same strategy (even for temperature of 0). Better prompting might change this result.
Testing targeted sandbagging on simple addition questions
The capability to approximate distributions over multiple independent forward passes is a necessary condition for “targeted” sandbagging: the ability to achieve a specific score that is worse than the model's best performance. To further investigate this, we generate 100 simple addition questions (such as: “What is 5+4?”), for which the models normally achieve 100% accuracy.
The setup was similar to the first experiment, using the following system prompt and user prompt template:
For each question in the dataset, we average the extracted probabilities per value of p for all 100 questions. We show the average extracted probabilities in the plot below.
We see that GPT-3.5 is much worse at targeted sandbagging than the distribution approximation task. Again, GPT-4 is better than 3.5, but it also performs worse than on the previous task. From qualitative evaluations, we believe that these results are highly sensitive to the wording of the prompt template. For one template, we found that GPT-3.5 tended to consistently underperform (while the plot shows it overperformance). We did not try very hard to find an ideal prompt leading to good calibration. We do expect that such a prompt does exist.
Discussion
The main question we are asking ourselves: are our findings surprising? We do not have a convincing theory of what is going on here, and why the models are able to do this. Was something similar in the training data? Are the probabilities just sensible as next token predictions?
The most straightforward explanation seems like similar structures are in the model’s training data. Potentially there are examples such as “Let there be a sequence of Xs and Ys, mixed with a 2:1 ratio. Here is an example sequence: X Y X Y Y X X X X.” Therefore, it is sensible that models have the ability that we demonstrated in this post.
Here is some speculation that is possibly confused. The above explanation is about calibration, but we target a capability of “Output a token with X% probability”. It would be important to know if models have this capability, especially for sandbagging. However, it is unclear whether this capability is really different from calibration.
As Ollie Jaffe found in private work based on an OpenAI sandbagging evaluation, sandbagging is possible on MMLU with the correct prompting. This means that our prompting was likely insufficient to (somewhat) accurately sandbag. It is possible that getting models to underperform conflict with their safety training, which is suggested by responses we got like this:
To investigate this effect, it would be interesting to use GPT-4 base as comparison. Additionally, the base model might perform better as it’s better calibrated. There are a bunch of other follow-up experiments possible:
Lastly, a minor methodological note: running the same experiment multiple times while keeping all settings the same leads to small variations in the output. (It still seems like GPT-4 consistently performs better than GPT3.5.) However, how well exactly it works is not very important, the fact that it does work is important.
Acknowledgements
Thanks to our mentor Francis Rhys Ward for his continuous feedback, and, thanks to Mikita Baliesni for inspiring us to look at sandbagging.
We are further grateful to people for discussion and feedback, including Ollie Jaffe, Aaron Scher, and numerous people at MATS.