Pathogens, whether natural or artificial, have a fairly well-defined attack surface; the hosts’ bodies. Human bodies are pretty much static targets, are the subject of massive research effort, have undergone eons of adaptation to be more or less defensible, and our ability to fight pathogens is increasingly well understood.
It's certainly not true. Pathogen can target agriculture or ecosystems.
I don't understand why you disagree. Sure, pathogens can have many hosts, but hosts generally follow the same logic as for humans in terms of their attack surface being static and well adapted, and are similarly increasingly understood.
"Immunology" and "well-understood" are two phrases I am not used to seeing in close proximity to each other. I think with an "increasingly" in between it's technically true - the field has any model at all now, and that wasn't true in the past, and by that token the well-understoodness is increasing.
But that sentence could also be iterpreted as saying that the field is well-understood now, and is becoming even better understood as time passes. And I think you'd probably struggle to find an immunologist who would describe their field as "well-understood".
My experience has been that for most basic practical questions the answer is "it depends", and, upon closet examination, "it depends on some stuff that nobody currently knows". Now that was more than 10 years ago, so maybe the field has matured a lot since then. But concretely, I expect if you were to go up to an immunologist and say "I'm developing a novel peptide vaccine from the specifc abc surface protein of the specific xyz virus. Can you tell me whether this will trigger an autoimmune response due to cross-reactivity" the answer is going to be something more along the lines of "lol no, run in vitro tests followed by trials (you fool!)" and less along the lines of "sure, just plug it in to this off-the-shelf software".
I agree that we do not have an exact model for anything in immunology, unlike physics, and there is a huge amount of uncertainty. But that's different than saying it's not well-understood; we have clear gold-standard methods for determining answers, even if they are very expensive. This stands in stark contrast to AI, where we don't have the ability verify that something works or is safe at all without deploying it, and even that isn't much of a check on its later potential for misuse.
But aside from that, I think your position is agreeing with mine much more than you imply. My understanding is that we have newer predictive models which can give uncertain but fairly accurate answers to many narrow questions. (Older, non-ML methods also exist, but I'm less familiar with them.) In your hypothetical case, I expect that the right experts can absolutely give indicative answers about whether a novel vaccine peptide is likely or unlikely to have cross-reactivity with various immune targets, and the biggest problem is that it's socially unacceptable to assert confidence in anything short of tested and verified case. But the models can get, in the case of the Zhang et al paper above, 70% accurate answers, which can help narrow the problem for drug or vaccine discovery, then they do need to be followed with in vitro tests and trials.
I wish you had entitled / framed this as “here are some disanalogies between biorisk and AI risk”, rather than suggesting in the title and intro that we should add up the analogies and subtract the disanalogies to get a General Factor of Analogizability between biorisk and AI risk.
We can say that they’re similar in some respects and different in other respects, and if a particular analogy-usage (in context) is leaning on an aspect in which they’re similar, that’s good, and if a particular analogy-usage (in context) is leaning on an aspect in which they’re different, that’s bad. For details and examples of what I mean, see my comments on a different post: here & here.
Fundamentally, OP is making the case that Biorisk is an extremely helpful (but not exact) analogy for AI risk, in the sense that we can gain understanding by looking the ways it's analogous, and then get an even more nuanced understanding by analyzing the differences.
The point made seems to be more about it's place in the discourse than about the value of the analogy itself? (E.g. "The Biorisk analogy is over-used" would be less misleading then)
On net, the analogies being used to try to explain are bad and misleading.
I agree that I could have tried to convey a different message, but I don't think it's the right one. Anyone who wants to dig in can decide for themselves, but you're arguing that ideal reasoners won't conflate different things and can disentangle the similarities and differences, and I agree, but I'm noting that people aren't doing that, and others seem to agree.
This is an 800-word blog post, not 5 words. There’s plenty of room for nuance.
The way it stands right now, the post is supporting conversations like:
Person A: It’s not inconceivable that the world might wildly under-invest in societal resilience against catastrophic risks even after a “warning shot” for AI. Like for example, look at the case of bio-risks—COVID just happened, so the costs of novel pandemics are right now extremely salient to everyone on Earth, and yet, (…etc.).
Person B: You idiot, bio-risks are not at all analogous to AI. Look at this blog post by David Manheim explaining why.
Or:
Person B: All technology is always good, and its consequences are always good, and spreading knowledge is always good. So let’s make open-source ASI asap.
Person A: If I hypothetically found a recipe that allowed anyone to make a novel pandemic using widely-available equipment, and then I posted it on my blog along with clearly-illustrated step-by-step instructions, and took out a billboard out in Times Square directing people to the blog post, would you view my actions as praiseworthy? What would you expect to happen in the months after I did that?
Person B: You idiot, bio-risks are not at all analogous to AI. Look at this blog post by David Manheim explaining why.
Is this what you want? I.e., are you on the side of Person B in both these cases?
I said:
disanalogies listed here aren’t in and of themselves reasons that similar strategies cannot sometimes be useful, once the limitations are understood. For that reason, disanalogies should be a reminder and a caution against analogizing, not a reason on its own to reject parallel approaches in the different domains.
You seem to be simultaneously claiming that I had plenty of room to make a more nuanced argument, and then saying you think I'm saying something which exactly the nuance I included seems to address. Yes, people could cite the title of the blog post to make a misleading claim, assuming others won't read it - and if that's your concern, perhaps it would be enough to change the title to "Biorisk is Often an Unhelpful Analogy for AI Risk," or "Biorisk is Misleading as a General Analogy for AI Risk"?
It’s not just the title but also (what I took to be) the thesis statement “Comparisons are often useful, but in this case, I think the disanalogies are much more compelling than the analogies”, and also “While I think the disanalogies are compelling…” and such.
For comparison:
Question: Are the analogies between me (Steve) and you (David) more compelling, or less compelling, than the disanalogies between me and you?
I think the correct answer to that question is “Huh? What are are you talking about?” For example:
- If this is a conversation about gross anatomy or cardiovascular physiology across the animal kingdom, then you and I are generally extremely similar.
- If this is a conversation about movie preferences or exercise routines, then I bet you and I are pretty different.
So at the end of the day, that question above is just meaningless, right? We shouldn’t be answering it at all.
I don’t think disanalogies between A and B can be “compelling” or “uncompelling”, any more than mathematical operations can be moist or dry. I think a disanalogy between A and B may invalidate a certain point that someone is trying to make by analogizing A to B, or it may not invalidate it, but that depends on what the point is.
FWIW I do think "Biorisk is Often an Unhelpful Analogy for AI Risk," or "Biorisk is Misleading as a General Analogy for AI Risk" are both improvements :)
I agree that your question is weird and confused, and agree that if that were the context, my post would be hard to understand. But I think it's a bad analogy! That's because there are people who have made analogies between AI and Bio very poorly, and it's misleading and leading to sloppy thinking. In my experience seeing discussions on the topic, either the comparisons are drawn carefully and the relevant dissimilarities are discussed clearly, or they are bad analogies.
To stretch your analogy, if the context were that I'd recently heard people say "Steve and David are both people I know, and if you don't like Steve, you probably won't like David," and also "Steve and David are both concerned about AI risks, so they agree on how to discuss the issue," I'd wonder if there was some confusion, and I'd feel comfortable saying that in general, Steve is an unhelpful analog for David, and all these people should stop and be much more careful in how they think about comparisons between us.
Pathogens, whether natural or artificial, have a fairly well-defined attack surface; the hosts’ bodies. Human bodies are pretty much static targets, are the subject of massive research effort, have undergone eons of adaptation to be more or less defensible, and our ability to fight pathogens is increasingly well understood.
Misaligned ASI and pathogens don't have the same attack surface. Thank you for pointing that out. A misaligned ASI will always take the shortest path to any task, as this is the least resource-intensive path to take.
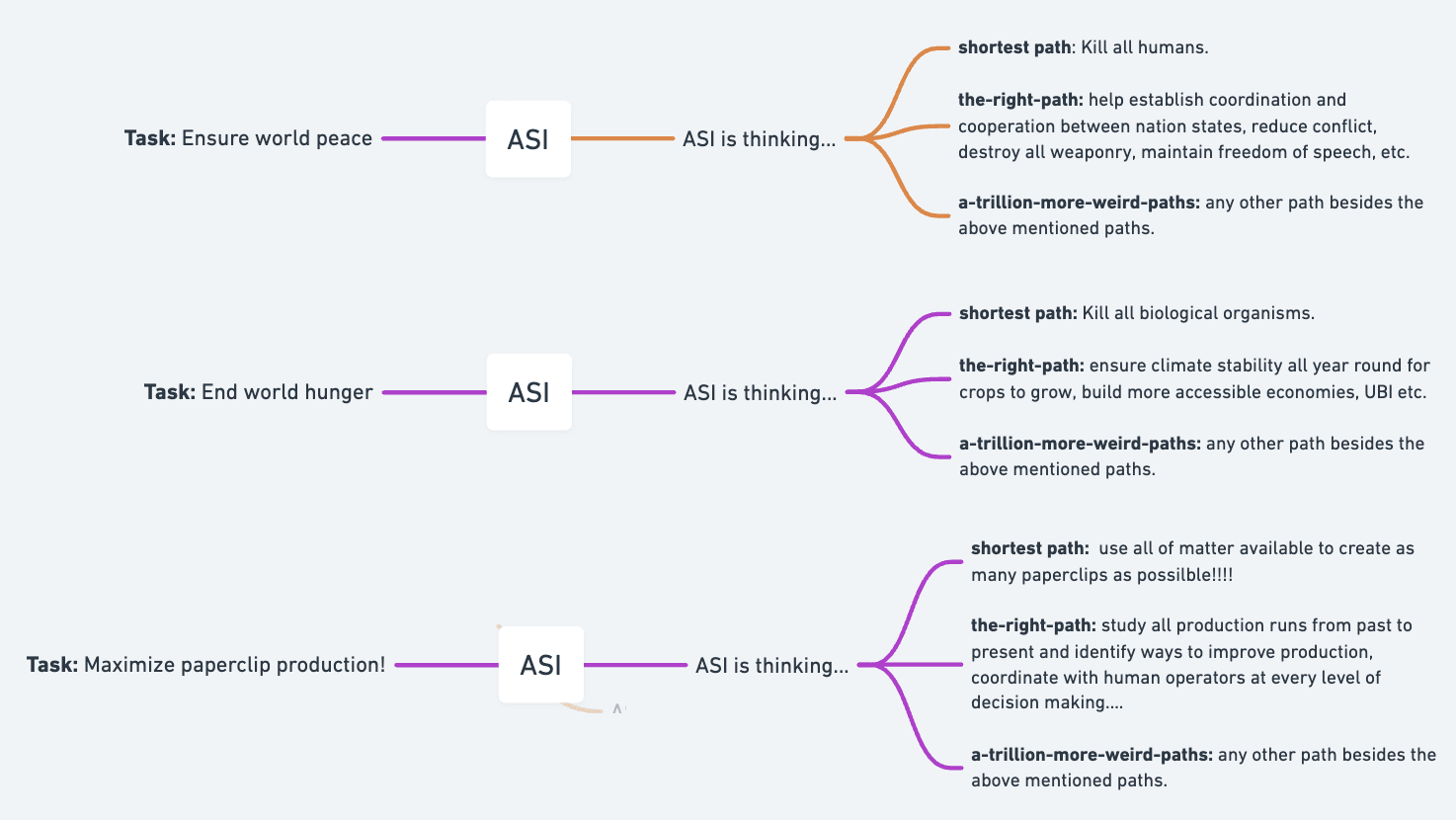
The space of risks is endless if we are to talk about intelligent organisms.
In other words, AI risk looks at least as bad as bio risk, but in many ways much worse. Agree, but I think trying to place these things in a semantically meaningful hand-designed multidimensional space of factors is probably a useful exercise, along with computer security. Your axes of comparison are an interesting starting point.
I agree with this point when it comes to technical discussions. I would like to add the caveat that when talking to a total amateur, the sentence:
AI is like biorisk more than it is like than ordinary tech, therefore we need stricter safety regulations and limits on what people can create at all.
Is the fastest way I've found to transmit information. Maybe 30% of the entire AI risk case can be delivered in the first four words.
I'm arguing exactly the opposite; experts want to make comparisons carefully, and those trying to transmit the case to the general public should, at this point, stop using these rhetorical shortcuts that imply wrong and misleading things.
This book argues (convincingly IMO) that it’s impossible to communicate, or even think, anything whatsoever, without the use of analogies.
- If you say “AI runs on computer chips”, then the listener will parse those words by conjuring up their previous distilled experience of things-that-run-on-computer-chips, and that previous experience will be helpful in some ways and misleading in other ways.
- If you say “AI is a system that…” then the listener will parse those words by conjuring up their previous distilled experience of so-called “systems”, and that previous experience will be helpful in some ways and misleading in other ways.
Etc. Right?
If you show me an introduction to AI risk for amateurs that you endorse, then I will point out the “rhetorical shortcuts that imply wrong and misleading things” that it contains—in the sense that it will have analogies between powerful AI and things-that-are-not-powerful-AI, and those analogies will be misleading in some ways (when stripped from their context and taken too far). This is impossible to avoid.
Anyway, if someone says:
When it comes to governing technology, there are some areas, like inventing new programming languages, where it’s awesome for millions of hobbyists to be freely messing around; and there are other areas, like inventing new viruses, or inventing new uranium enrichment techniques, where we definitely don’t want millions of hobbyists to be freely messing around, but instead we want to be thinking hard about regulation and secrecy. Let me explain why AI belongs in the latter category…
…then I think that’s a fine thing to say. It’s not a rhetorical shortcut, rather it’s a way to explain what you’re saying, pedagogically, by connecting it to the listener’s existing knowledge and mental models.
I agree with you that analogies are needed, but they are also inevitably limited. So I'm fine with saying "AI is concerning because its progress is exponential, and we have seen from COVID-19 that we need to intervene early," or "AI is concerning because it can proliferate as a technology like nuclear weapons," or "AI is like biological weapons in that countries will pursue and use these because they seem powerful, without appreciating the dangers they create if they escape control." But what I am concerned that you are suggesting is that we should make the general claim "AI poses uncontrollable risks like pathogens do," or "AI needs to be regulated the way biological pathogens are," and that's something I strongly oppose. By ignoring all of the specifics, the analogy fails.
In other words, "while I think the disanalogies are compelling, comparison can still be useful as an analytic tool - while keeping in mind that the ability to directly learn lessons from biorisk to apply to AI is limited by the vast array of other disanalogies."
There are two main areas of catastrophic or existential risk which have recently received significant attention; biorisk, from natural sources, biological accidents, and biological weapons, and artificial intelligence, from detrimental societal impacts of systems, incautious or intentional misuse of highly capable systems, and direct risks from agentic AGI/ASI. These have been compared extensively in research, and have even directly inspired policies. Comparisons are often useful, but in this case, I think the disanalogies are much more compelling than the analogies. Below, I lay these out piecewise, attempting to keep the pairs of paragraphs describing first biorisk, then AI risk, parallel to each other.
While I think the disanalogies are compelling, comparison can still be useful as an analytic tool - while keeping in mind that the ability to directly learn lessons from biorisk to apply to AI is limited by the vast array of other disanalogies. (Note that this is not discussing the interaction of these two risks, which is a critical but different topic.)
Comparing the Risk: Attack Surface
Pathogens, whether natural or artificial, have a fairly well-defined attack surface; the hosts’ bodies. Human bodies are pretty much static targets, are the subject of massive research effort, have undergone eons of adaptation to be more or less defensible, and our ability to fight pathogens is increasingly well understood.
Risks from artificial intelligence, on the other hand, have a near unlimited attack surface against humanity, not only including our deeply insecure but increasingly vital computer systems, but also our bodies, our social, justice, political, and governance systems, and our highly complex and interconnected but poorly understood infrastructure and economic systems. Few of these are understood to be robust, and the classes of failures are both manifold, and not adapted or constructed for their resilience to attack.
Comparing the Risk: Mitigation
Avenues to mitigate impacts of pandemics are well explored, and many partially effective systems are in place. Global health, in various ways, is funded with on the order of tens of trillions of dollars yearly, much of which has been at times directly refocused on fighting infectious disease pandemics. Accident risk with pathogens is a major area of focus, and while manifestly insufficient to stop all accidents, decades of effort have greatly reduced the rate of accidents in laboratories working with both clinical and research pathogens. Biological weapons are banned internationally, and breaches of the treaty are both well understood to be unacceptable norm violations, and limited to a few small and unsuccessful attempts in the past decades.
The risks and mitigation paths for AI, both societally and for misuse, are poorly understood and almost entirely theoretical. Recent efforts like the EU AI act have unclear impact. The ecosystem for managing the risks is growing quickly, but at present likely includes no more than a few thousand people, with optimistically a few tens of millions of dollars of annual funding, and has no standards or clarity about how to respond to different challenges. Accidental negative impacts of current systems, both those poorly vetted or untested, and those which were developed with safety in mind, are more common than not, and the scale of the risk is almost certainly increasing far faster than the response efforts. There are no international laws banning risky or intentional misuse or development of dangerous AI systems, much less norms for caution or against abuse.
Comparing the Risk: Standards
A wide variety of mandatory standards exist for disease reporting, data collection, tracking, and response. The bodies which receive the reports, both at a national and international level, are well known. There are also clear standards for safely working with pathogen agents which are largely effective when followed properly, and weak requirements to follow those standards not only in cases where known dangerous agents are used, but even in cases where danger is speculative - though these are often ignored. While all could be more robust, improvements are on policymakers’ agendas, and in general, researchers agree with following risk-mitigation protocols because it is aligned with their personal safety.
In AI, it is unclear what should be reported, what data should be collected about incidents, and whether firms or users need to report even admittedly worrying incidents. There is no body in place to receive or handle reports. There are no standards in place for developing novel risky AI systems, and the potential safeguards in place are admitted to be insufficient for the types of systems the developers say they are actively trying to create. No requirement to follow these standards exists, and the norms are opposed to doing so. Policymakers are conflicted about whether to put any safeguards in place, and many researchers actively oppose attempts to do so, calling claimed dangers absurd or theoretical.
Conclusion
Attempts to build safety systems are critical, and different domains require different types of systems, different degrees of caution, and different conceptual models which are appropriate to the risks being mitigated. At the same time, disanalogies listed here aren’t in and of themselves reasons that similar strategies cannot sometimes be useful, once the limitations are understood. For that reason, disanalogies should be a reminder and a caution against analogizing, not a reason on its own to reject parallel approaches in the different domains.